

Этот пример будет иллюстрировать один из других методов кластеризации: метод k средних. Как описано в разделе Вводный обзор, целью алгоритма является оптимальное «разбиение» всего набора объектов на k кластеров. Эта процедура будет перемещать объекты из одного кластера в другой, чтобы минимизировать внутрикластерную дисперсию и максимизировать межкластерную. В Примере 1, вы нашли три кластера во множестве данных об автомобилях (Cars.sta). Теперь посмотрим, какого сорта решение получим с помощью метода k средних в предположении, что в данных имеется всего три кластера.
Спецификация анализа. Выберите Кластерный анализ в меню Анализ — Многомерный разведочный анализ для отображения стартовой панели модуля Кластерный анализ. В появившемся диалоге выберите Кластеризация методом К средних и нажмите кнопку OK для отображения диалогового окна Кластерный анализ: кластеризация методом К средних. В этом диалоге выберите вкладу Дополнительно.
Кластерный анализ

Нажмите кнопку Переменные, в появившемся окне Выбор переменных выберите все переменные. Далее, нажмите кнопку OK, чтобы вернуться во вкладку Дополнительно диалогового окна Кластерный анализ: кластеризация методом К средних. Как и в Примере 1 вы можете кластеризовать объекты или переменные. В этом случае выберите Наблюдения (строки) в поле Кластер для того, чтобы кластеризовать автомобили. Чтобы получить результаты для трех кластеров, изменим Число кластеров на 3.
Начальные центры кластеров. Эти опции управляют способом вычисления начальных центров кластеров. Результаты метода k средних зависят в известной мере от начальной конфигурации (т.е. от средних или центров кластеров). В частности, это происходит, когда формируется много маленьких отчетливо различающихся кластеров (с несколькими объектами). Для дальнейшей информации об этих опциях обратитесь к вкладке Дополнительно диалогового окна Кластерный анализ: категоризация методом К средних.
В этом примере выберите, по умолчанию, метод Сортировать расстояния и выбрать набл. на постоянных интервалах и затем нажмите кнопку OK, чтобы начать анализ.
Результаты. После завершения анализа появляется диалоговое окно Результаты метода K средних.

Дисперсионный анализ. В разделе Вводный обзор — Метод k средних этот метод был назван «дисперсионным анализом наоборот». В дисперсионном анализе межгрупповая дисперсия сравнивается с внутригрупповой дисперсией для принятия решения, являются ли средние для отдельных переменных в разных совокупностях значимо различными.
Даже, несмотря на то, что тестирование в этом случае не вполне корректно (во многом вы рассчитываете на везение), вы можете, тем не менее, принимать во внимание результаты дисперсионного анализа, сравнивая для каждого измерения средние (т.е. измерения характеристик) между совокупностями (кластерами автомобилей). Нажмите на кнопку Дисперсионный анализ для отображения приведенной выше таблицы.
Кластеризация марок автомобилей с помощью иерархической классификации

Исходя из амплитуды (и уровней значимости) F-статистики, переменные Управляемость — Handling, Тормоз — Braking и Цена — Price являются главными при решении вопроса о распределении объектов по кластерам.
Идентификация кластеров. Теперь посмотрим, как программа назначает автомобили в кластеры с использованием этого критерия. Для того чтобы понять, из каких членов состоит каждый кластер, нажмите на кнопку Элементы кластеров и расстояния во вкладке Дополнительно диалогового окна Результаты метода К средних для получения таблиц результатов (по одной для каждого кластера). Кластер 1 состоит из Акура — Acura, Бьюик — Buick, Крайслер — Chrysler, Додж — Dodge, Хонда — Honda, Мицубиси — Mitsubishi, Ниссан — Nissan, Олдс — Olds, Понтиак — Pontiac, Сааб — Saab, Тойота — Toyota, Фольксваген — VW и Вольво — Volvo.

Следующая таблица содержит члены кластера 2:

Второй кластер содержит Ауди — Audi, БМВ — BMW, Корвет — Corvette, Форд — Ford, Мазду — Mazda, Мерседес — Mercedes и Порше — Porsche. Последний кластер приведен в третьей таблице ниже. Этот кластер состоит из Игл — Eagle и Исузу — Isuzu.

Эти результаты не полностью аналогичны кластерам, найденным в предшествующем анализе. Однако различия между кластерами экономичный седан и роскошный седан по-прежнему кажутся устойчивыми. Автомобили Игл — Eagle и Исузу — Isuzu были, вероятно, помещены в собственную категорию, так как они не «подходят» куда-либо ещё, и поскольку любое другое перераспределение автомобилей не улучшает решение (т.е. увеличивает межгрупповые суммы квадратов).
Описательные статистики для каждого кластера. Другим способом определения природы кластеров является проверка средних значений для каждого кластера и для каждого измерения. Вы можете или отобразить описательные статистики отдельно (нажмите на кнопку Описат. статистики для каждого кластера), или отобразить средние для всех кластеров и расстояний (евклидовых и квадратов евклидовых, см. ниже) между кластерами в отдельную таблицу результатов (нажмите на кнопку Средние кластеров и евклидовы расстояния), или вывести диаграмму этих средних (нажмите на кнопку График средних). Обычно, этот график дает наилучшее представление результатов.
Взглянем, например, на линию для кластера экономичный седан (Кластер 1) и сравним её с кластером роскошный седан (Кластер 2) на графике ниже. Можно заметить, что и в самом деле, автомобили в последнем классе:
— являются более дорогими;
— имеют меньше время разгона (вероятно из-за большего веса);
— имеют приблизительно тот самый тормозной путь;
— являются одинаковыми с точки зрения управляемости;
— имеют меньший расход топлива.

Наиболее различающим признаком автомобилей из третьего кластера (Игл — Eagle и Исузу — Isuzu) в соответствии с этим графиком, является их более короткий тормозной путь и плохая управляемость.
Расстояния между кластерами. Другой полезный результат проверки — евклидовы расстояния между кластерами (нажмите на кнопку Средние кластеров и евклидовы расстояния). Эти расстояния (евклидовы и их квадраты) вычисляются по средним каждой переменной в кластере.

Отметим, что кластеры 1 и 2 относительно близки друг к другу (евклидово расстояние = 0.97) по отношению к расстояниям от кластера 3 до кластеров 1 и 2.
Этот пример взят из справочной системы ППП STATISTICA фирмы StatSoft
Источник: www.statproject.ru
Пример использования кластерного анализа STATISTICA в автостраховании
В STATISTICA реализованы классические методы кластерного анализа, включая методы k-средних, иерархической кластеризации и двухвходового объединения.
Данные могут поступать как в исходном виде, так и в виде матрицы расстояний между объектами.
Наблюдения и переменные можно кластеризовать, используя различные меры расстояния (евклидово, квадрат евклидова, манхэттеновское, Чебышева и др.) и различные правила объединения кластеров (одиночная, полная связь, невзвешенное и взвешенное попарное среднее по группам и др.).
Постановка задачи
Исходный файл данных содержит следующую информацию об автомобилях и их владельцах:

- марка автомобиля – первая переменная;
- стоимость автомобиля – вторая переменная;
- возраст водителя – третья переменная;
- стаж водителя – четвертая переменная;
- возраст автомобиля – пятая переменная;
Целью данного анализа является разбиение автомобилей и их владельцев на классы, каждый из которых соответствует определенной рисковой группе. Наблюдения, попавшие в одну группу, характеризуются одинаковой вероятностью наступления страхового случая, которая впоследствии оценивается страховщиком.
Использование кластер-анализа для решения данной задачи наиболее эффективно. В общем случае кластер-анализ предназначен для объединения некоторых объектов в классы (кластеры) таким образом, чтобы в один класс попадали максимально схожие, а объекты различных классов максимально отличались друг от друга. Количественный показатель сходства рассчитывается заданным способом на основании данных, характеризующих объекты.
Масштаб измерений
Все кластерные алгоритмы нуждаются в оценках расстояний между кластерами или объектами, и ясно, что при вычислении расстояния необходимо задать масштаб измерений.
Поскольку различные измерения используют абсолютно различные типы шкал, данные необходимо стандартизовать (в меню Данные выберете пункт Стандартизовать), так что каждая переменная будет иметь среднее 0 и стандартное отклонение 1.
Таблица со стандартизованными переменными приведена ниже.

Шаг 1. Иерархическая классификация
На первом этапе выясним, формируют ли автомобили «естественные» кластеры, которые могут быть осмыслены.
Выберем Кластерный анализ в меню Анализ — Многомерный разведочный анализ для отображения стартовой панели модуля Кластерный анализ. В этом диалоге выберем Иерархическая классификация и нажмем OK.

Нажмем кнопку Переменные, выберем Все, в поле Объекты выберем Наблюдения (строки). В качестве правила объединения отметим Метод полной связи, в качестве меры близости – Евклидово расстояние. Нажмем ОК.

Метод полной связи определяет расстояние между кластерами как наибольшее расстояние между любыми двумя объектами в различных кластерах (т.е. «наиболее удаленными соседями»).
Мера близости, определяемая евклидовым расстоянием, является геометрическим расстоянием в n- мерном пространстве и вычисляется следующим образом:
Наиболее важным результатом, получаемым в результате древовидной кластеризации, является иерархическое дерево. Нажмем на кнопку Вертикальная дендрограмма.

Вначале древовидные диаграммы могут показаться немного запутанными, однако после некоторого изучения они становятся более понятными. Диаграмма начинается сверху (для вертикальной дендрограммы) с каждого автомобиля в своем собственном кластере.
Как только вы начнете двигаться вниз, автомобили, которые «теснее соприкасаются друг с другом» объединяются и формируют кластеры. Каждый узел диаграммы, приведенной выше, представляет объединение двух или более кластеров, положение узлов на вертикальной оси определяет расстояние, на котором были объединены соответствующие кластеры.
Шаг 2. Кластеризация методом К средних
Исходя из визуального представления результатов, можно сделать предположение, что автомобили образуют четыре естественных кластера. Проверим данное предположение, разбив исходные данные методом К средних на 4 кластера, и проверим значимость различия между полученными группами.
В Стартовой панели модуля Кластерный анализ выберем Кластеризация методом К средних.

Нажмем кнопку Переменные и выберем Все, в поле Объекты выберем Наблюдения (строки), зададим 4 кластера разбиения.

Метод K-средних заключается в следующем: вычисления начинаются с k случайно выбранных наблюдений (в нашем случае k=4), которые становятся центрами групп, после чего объектный состав кластеров меняется с целью минимизации изменчивости внутри кластеров и максимизации изменчивости между кластерами.
Каждое следующее наблюдение (K+1) относится к той группе, мера сходства с центром тяжести которого минимальна.
После изменения состава кластера вычисляется новый центр тяжести, чаще всего как вектор средних по каждому параметру. Алгоритм продолжается до тех пор, пока состав кластеров не перестанет меняться.
Когда результаты классификации получены, можно рассчитать среднее значение показателей по каждому кластеру, чтобы оценить, насколько они различаются между собой.
В окне Результаты метода К средних выберем Дисперсионный анализ для определения значимости различия между полученными кластерами.
Нажмем кнопку Элементы кластеров и расстояния для просмотра наблюдений, входящих в каждый из кластеров. Опция также позволяет отобразить евклидовы расстояния объектов от центров (средних значений) соответствующих им кластеров.
Итак, в каждом из четырех кластеров находятся объекты со схожим влиянием на процесс убытков.
Шаг 3. Описательные статистики
Знание описательных статистик в каждой группе, безусловно, является важным для любого исследователя.
Отображение статистик для каждого кластера из диалога Результаты метода К средних в данном случае не представляет интереса, т.к. данные были стандартизованы.
Нажмем кнопку Сохранить классификацию и расстояния.

Таблица стандартизованных данных дополнилась информацией о кластере, к которому принадлежит наблюдение, евклидовом расстоянии и номере наблюдения.
Скопируем переменную КЛАСТЕР в исходную таблицу данных.

Теперь для каждого кластера можно вычислить основные описательные статистики.
В меню Анализ – Основные статистики и таблицы выберем опцию Группировка и Однофакторный ДА.
Ниже приведены таблицы описательных статистик для каждого из показателей:
Знание основных описательных статистик в каждом кластере может быть использовано экспертом для оценки убытков страховой компании.
Построим график средних и доверительных интервалов для переменных в каждом кластере.
Итак, для каждого кластера экспертом может быть определена вероятность наступления страхового случая.
Источник: statsoft.ru
Поисковая геохимия
В данном посте расскажу как объединять пробы в кластеры методом иерархической кластеризации. Но подход подойдет и для выделения ассоциаций переменных. Метод не относится к статистическим методам. Чистая математика. Берем меру расстояния между объектами, и выбираем метод объединения.
Все объекты объединяются шаг за шагом пока не будет один кластер. Так что надо решить на каком шаге выделить кластеры.
В каждом новом посте я использую приемы форматирования и редактирования, которые обсуждал в предыдущих постах. Например, как импортировать данные из Excel в Statistica, как добавить переменную, и др. Так что читайте или задавайте вопросы.

Рис. 1. Импортируем данные и присваиваем имена каждой пробы из столбца ID (v1). У меня номера проб текстовые, не числовые.

Рис. 2. Для кластерного анализа необходимо стандартизовать данные. Стандартизация – это когда берется все наблюдения по определенному хим. элементу, из каждого наблюдения вычитается среднее значение в столбце и разница делится на стандартное отклонение. Зачем это нужно?
Дело в том, что одни перменные имеют очень высокие содержания (например, сотни грамм на тонну), а другие ультранизкие (микрограммы на тонну). Соответственно первые имеют “высокий вес”. Но нам важны все в относительном порядке. Поэтому процедура стандартизации их уравнивает. Кстати, для кластерного анализа не нужно определять тип распределения и подгонять данные.
Это по желанию.

Рис. 3. Выбираем переменные и щелкаем ОК. Исходные данные станут стандартизированными. Каждое наблюдение будет иметь значение стандартного отклонения и распределено относительно нуля.

Рис. 4. Выбираем вкладку Statistics – Mult/Exploratory – Cluster.
На заметку. В Статистике есть два вида анализов: подтверждающий и разведочный. Разведочный – когда ищем закономерности в данных, а подтверждающий когда их применяем для анализа. Некоторые методы могут быть одновременно и разведочными и подтверждающими.
Например, дискриминантный метод и ищет почему известные группы разделяются, и дает постериорное разделение наблюдений по группам по уже найденным закономерностям. Так кластерные анализы тоже могут быть и теми и другими. Иерархическая кластеризация – разведочный метод.

Рис. 5. Выбираем метод Объедиенения (Иерархической кластеризации, Joining). Другие методы рассмотрим позже. Каждая проба сама по себе является кластером, и мы их (пробы) пошагово объединяем пока не будет один кластер – вся выборка. Как вы можете догадаться, можно не объединять пошагово, а разделять из одной выборки в маленькие.
Да, но в Statistica такой метод не реализован.

Рис. 6. Открываем вкладку Расширенные настройки (Advanced).
Input file: raw data — Входные данные: сырые данные. Другой выбор – корреляционная матрица. Но об этом в следующий раз.
Cluster: Cases (rows) – Кластеризовать: Наблюдения (строки). Еще можно найти группы переменных.
Amalgamation (linkage) rule: Ward’s method – Правило объединения: метод Варда. Данный метод пытается минимизировать дисперсию в выбранных группах. Поэтому он старается создать маленькие кластеры. Метод дает интересные результаты, поэтому часто используется. Выбор правила объединения стоит за исследователем. Поэтому просто постарайтесь представить какие у вас кластеры.
Например, они они имеют разный размер (редкие аномальные объеты на неоднородном фоне), то можно попробовать взвешенный центроидный метод (Weighted centroid method (Median)). В нем расстояния между кластерами вычисляется как геометрическое расстояние между центрами тяжести с учетом весов (по размерам кластеров). Центр тяжести – координата соответствующая медианам всех наблюдений.
То есть выбросы для него несущественны. Пробуйте разные методы и сравнивайте. Как поговаривают геохимики “Настоящую аномалию закопать невозможно”.
Distance measure: Euclidean distances – Мера расстояния: Эвклидово расстояние. Мера расстояния – краеугольный камень кластерного анализа. Тема не на один пузырь и одну докторскую. Собственно, в кластерном анализе мы измеряем расстояние между пробами (и кластерами) с помощью некоторой его меры. Эвклидово расстояние – это кратчайшее геометрическое расстояние.
Помните про гиппотенузу и катеты: “Пифагововы штаны на все стороны равны, а квадрат гиппотенузы равен сумме квадратов катетов”?. Это полезно когда кластеры имеют форму шаров.
Если кластеры сильно вытянуты, то необходимо использовать расстояния Махаланобиса. К сожалению, они тут не реализованы. Но можно попробовать метод Single Linkage (Объединение ближайших соседей).
Так же, для геохимии вполне подойдут Расстояния Манхэтанна (не чувстивтельно к выборосам), и Квадрат Евклидово Расстояния (усливает расстоние между кластерами путем возведения в квадрат).
Выбор сделан, щелкаем ОК.

Рис. 7. Переходим во вкладку Расширенное (Advanced). Сначала строим график объединения проб Vertical icicle plot, а потом выведем его табличный аналог – Amalgamation Shedule.

Рис. 8. Вертикальная дендрограмма кластеризации.
Смотрим на данный график как на кисть винограда. Выделяем крупные кисти в объеме до 4-5 штук. Это и будут наши кластеры. Помните про стадийный подход и принципы системного анализа: выделяем обобщенные кластеры, а потом уточняем интересующий кластер отдельно.

Рис. 9. Тот же график. Только я тут убрал заголовки, подписи. Изменил максимальное значение расстояния на 200. Собственно, выделяются три крупных кластера.
Причем два соединяются.

Рис. 10. Передумал и решил сделать шесть кластеров.

Рис. 11. Рисуем красные прямоугольники и дважды щелкаем на них. Задаем динамическое изменение масштаба.
Красные прямоугольники рисуем, что бы было удобнее потом масштабировать график на определнном кластере. Это нужно, что бы навести мышкой на границу объединения и получить более точное значение уровня на котором произошло объединение субкластеров.

Рис. 12. Масштабируем график на первом кластере. Навелем мышкой на горизонтальную линию, которая из сединяет. Значение приблизительно 25,9.
Тут надо деликатно делать. Часто эти значения близки. И если сомневаеетесь, то еще масштабируйте график.

Рис. 13.Открываем таблицу объединения (Amalgamation Shedule). В самом левом столбце показаны определенные уровни на которых произошло объединение конкретных кластеров. Я решил выделить шесть кластеров. На рис.
12 первый кластер был объединен на уровне приблизительно 25,9. Найдем его.
Кстати, у меня использована относительно небольшая выборка 549 проб. При использовании тысяч проб, будет затруднительно работать. Не расслабляйтесь.

Рис. 14. Находим первый кластер. Уровень 25,97356. Выделяем строку. В ней перечислены все пробы из кластера. Строку копируем и вставляем в Excel.
А что? Удобная программа.

Рис. 15. Копируем строку и….

Рис. 16. Вставляем с транспонированием. Для этого на ячейке щелкаем правой клавищей и выбираем “Специальная вставка”.
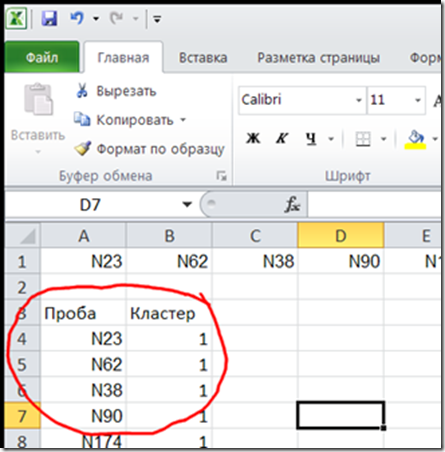
Рис. 17. Получили. Назвачаем пробам первый кластер.
Повторяем все с остальными кластерами. Далее в Statistica и Excel соритруем данные по столбцу номера пробы. И добавляем столбец с кластерами из Excel в Statistica. Немного муторно, но работает.
Скажу сразу. Я эту работу делал в два этапа и объединил результаты. Поэтому у меня шесть кластеров с номерами от 0 до 5.

Рис. 18.

Рис. 19. Теперь у проб есть группирующая переменная “Кластер”. Определим, чем же они отличаются. Для этого построим графики типа Ящик-с-усами для всех переменных.
Как строить данные графики смотрите предыдущие посты.
Если взглянуть на рис 9 и 10, то увидим, что кластеры 0 и 1 объединяются в один более крупный кластер, тоже с остальными кластерами.
Кластеры 0, и 3 скорее всего соответствуют рудной минерализации. Потому что у них повышенно содеражние рудных компонентов;
Кластер 1 совождает кластер 0, а кластер 2 сопровождает кластер 3;
Кластер 5 – имеет фоновые содержания по всем компонентам. А кластер 4 – соотствует выносу элементов;
Кластер 5 можно использовать в качестве подвыборки фоновых проб для определения различий распределения хим. элементов в зависимости от ландшафта. Только надо взять пробы, которые удалены от явных аномалий. Поскольку это нормально, когда часть фоновых проб попадают в контур аномалии.

Рис. 20. Построим график распределения кластеров в пространстве.

Рис. 21. График распределения кластеров в пространстве.
На севере концентрируется кластеры 0 и 1, они окружены кластером 2. Кластер 2 все таки ближе к 0 и 1, чем к 3-му. В центре расположен кластер 3, он так же соседствует с кластером 2.

Рис. 22. Построим график опять, но выделим лишь более интересные кластеры 0, 1, 2, которые предположительно соответствуют рудной минерализации. Самые высокие содержания имеет кластер 0. В кластере 1 меньше, и еще меньше в кластере 2. Зональность – хорошее качество.
Вообще я бы не стал говорить “Бурить тут!”, а дал бы рекомендации к заверке аномалии поисковыми маршрутами, детализации геохимическими методами и изучению с помощью геофизических методов.
Рекомендую прочитать:
Буреева Н.Н. Многомерный статистический анализ с использованием ППП “STATISTICA”. Учебно-методический материал по программе повышения квалификации «Применение программных средств в научных исследованиях и преподавании математики и механики». Нижний Новгород, 2007, 112 с.;
Дэвис Дж. С. Статистической анализ данных в геологии: Пер. с англ. В 2 кн./Пер. В.А. Голубевой; Под. ред. Д.А.
Родионова. Кн. 1. – М.: Недра, 1990. – 319 с.: ил. ISBN 5-247-02122-3;
Источник: sosninep.blogspot.com