
Инструмент очень прост в использовании и предоставляет множество встроенных функций, которые используются для сохранения текстового файла в формате mp3.
Нам не нужно использовать нейронную сеть и обучать модель, поскольку этого сложно добиться. Вместо этого мы будем использовать API для выполнения задачи.
API gTTS предоставляет возможность конвертировать текстовые файлы на разные языки, такие как английский, хинди, немецкий, тамильский, французский и многие другие. Мы также можем воспроизводить звуковую речь в быстром или медленном режиме.
Однако в последнем обновлении мы не можем изменить речевой файл; он будет генерироваться системой и не подлежит изменению.
Чтобы совершать преобразование в текстовых файлах, мы будем использовать другую автономную библиотеку под названием pyttsx3.
Установка gTTS API
Введите следующую команду в терминале, чтобы установить gTTS API.
pip install gTTS
Затем установите дополнительный модуль для работы с gTTS.
Голосовой помощник на python
pip install playsound
Затем установите pyttsx3.
pip install pyttsx3
Давайте разберемся в работе gTTS API
import gtts from playsound import playsound
Как мы видим, им очень легко пользоваться; нам нужно импортировать его и передать объект gTTS, который является интерфейсом API переводчика Google.
# make a request to google to get synthesis t1 = gtts.gTTS(«Welcome to javaTpoint»)
В приведенной выше строке мы отправили данные в текстовом виде и получили фактическую звуковую речь. Теперь сохраните этот аудиофайл как welcome.mp3.
# save the audio file t1.save(«welcome.mp3»)
Он сохранится в каталоге, мы можем прослушать этот файл следующим образом:
# play the audio file playsound(«welcome.mp3»)
Включите системную громкость, слушайте текст, как мы сохранили его ранее.
Теперь мы определим полную программу для преобразования текста в речь в Python.
# Import the gTTS module for text # to speech conversion from gtts import gTTS # This module is imported so that we can # play the converted audio from playsound import playsound # It is a text value that we want to convert to audio text_val = ‘All the best for your exam.’ # Here are converting in English Language language = ‘en’ # Passing the text and language to the engine, # here we have assign slow=False. Which denotes # the module that the transformed audio should # have a high speed obj = gTTS(text=text_val, lang=language, slow=False) #Here we are saving the transformed audio in a mp3 file named # exam.mp3 obj.save(«exam.mp3») # Play the exam.mp3 file playsound(«exam.mp3»)
В приведенном выше коде мы импортировали API и используем функцию gTTS. Функция gTTS() принимает три аргумента:
- Первый аргумент – это текстовое значение, которое мы хотим преобразовать в речь.
- Второй – указанный язык. Он поддерживает множество языков. Мы можем преобразовать текст в аудиофайл.
- Третий аргумент представляет скорость речи. Мы передали значение slow как false; это означает, что речь будет идти с нормальной скоростью.
# Синтез речи
Познакомимся, как использовать Python для преобразования текста в речь с использованием кроссплатформенной библиотеки pyttsx3 . Этот пакет работает в Windows, Mac и Linux. Он использует родные драйверы речи, когда они доступны, и работает в оффлайн режиме.
Простой искусственный интеллект на Python. Распознавание голоса на Python
Использует разные системы синтеза речи в зависимости от текущей ОС:
- в Windows — SAPI5,
- в Mac OS X — nsss,
- в Linux и на других платформах — eSpeak.
Есть функции, которые здесь не рассматриваются, такие как система событий. Вы можете подключить движок к определенным событиям:
- можно посчитать, сколько слов сказано, и обрезать его,
- можно проверить каждое слово и отрезать его, если есть неуместные слова.
Всегда обращайтесь к официальной документации для получения наиболее точной, полной и актуальной информации https://pyttsx3.readthedocs.io/en/latest/
# Установка пакетов в Windows
Используйте pip для установки пакета. В Windows, вам понадобится дополнительный пакет pypiwin32 , который понадобится для доступа к собственному речевому API Windows.
pip install pyttsx3 pip install pypiwin32 # Только для Windows
# Преобразование текста в речь
Для первой программой озвучивания текста используем код:
import pyttsx3 engine = pyttsx3.init() # инициализация движка # зададим свойства engine.setProperty(‘rate’, 150) # скорость речи engine.setProperty(‘volume’, 0.9) # громкость (0-1) engine.say(«I can speak!») # запись фразы в очередь engine.say(«Я могу говорить!») # запись фразы в очередь # очистка очереди и воспроизведение текста engine.runAndWait() # выполнение кода останавливается, пока весь текст не сказан
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
В примере программы даны две фразы на английском и на русском языке. Существует голосовой набор по умолчанию, поэтому вам не нужно выбирать голос. В зависимости от версии windows будет озвучена соответствующая фраза. Например для английской версии windows услышим: «I can speak!»
# Доступные синтезаторы по умолчанию
Доступные голоса будут зависеть от версии установленной систем. Вы можете получить список доступных голосов на вашем компьютере. Обратите внимание, что голоса, имеющиеся у вас на компьютере, могут отличаться от чьей-либо машины.
У каждого голоса есть несколько параметров, с которыми можно работать:
- id (идентификатор в операционной системе),
- name (имя),
- languages (поддерживаемые языки),
- gender (пол),
- age (возраст).
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Получить список доступных голосов можно так:
1
2
3
4
5
6
7
8
9
10
11
12
Результат будет примерно таким:
Имя: Microsoft Hazel Desktop — English (Great Britain) ID: HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_EN-GB_HAZEL_11.0 Язык(и): [] Пол: None Возраст: None —— Имя: Microsoft David Desktop — English (United States) ID: HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_EN-US_DAVID_11.0 Язык(и): [] Пол: None Возраст: None —— Имя: Microsoft Zira Desktop — English (United States) ID: HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_EN-US_ZIRA_11.0 Язык(и): [] Пол: None Возраст: None
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID.
# Установка дополнительных голосов в Windows
При желании можно установить дополнительные языковые пакеты согласно инструкции https://support.microsoft.com/en-us/help/14236/language-packs#lptabs=win10
Для этого выполните указанные ниже действия.
- Нажмите кнопку Пуск , затем выберите Параметры >Время и язык >Язык.
- В разделе Предпочитаемые языки выберите Добавить язык.
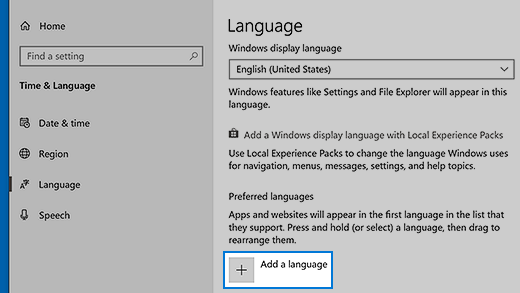
- В разделе Выберите язык для установки выберите или введите название языка, который требуется загрузить и установить, а затем нажмите Далее.
- В разделе Установка языковых компонентов выберите компоненты, которые вы хотите использовать на языке.
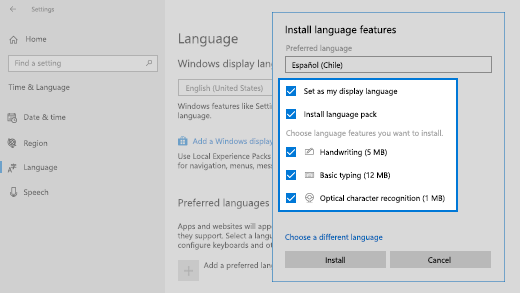
- ВНИМАНИЕ: отключите первый пакет: «Install language pack and set as my Windows display language» — «Установите языковой пакет и установите мой язык отображения Windows»
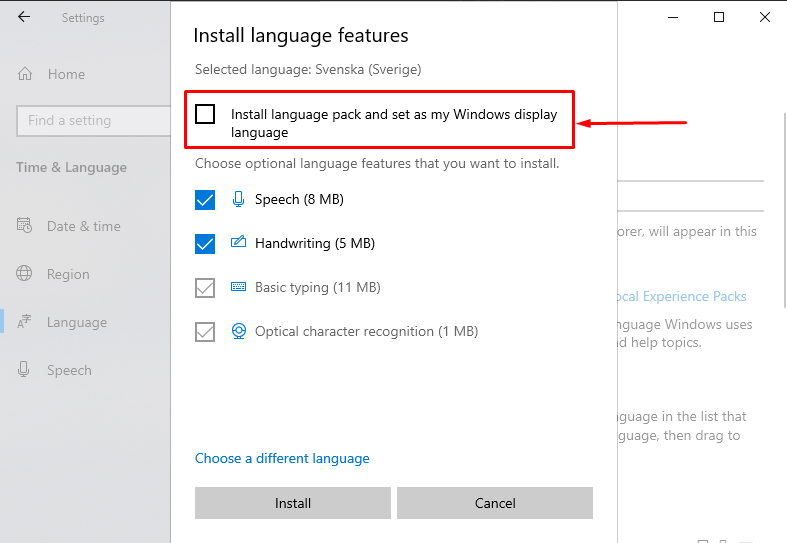 Иначе переустановиться язык отображения операционной системы.
Иначе переустановиться язык отображения операционной системы. - Нажмите Установить.
После установки нового языкового пакета перезагрузка не требуется. Запустив код проверки установленных языков. Новый язык должен отобразиться в списке.
Не все языковые пакеты поддерживают синтез речи. Для этого опция Speech должны быть в описании установки.
# Выбор голоса
Установить голос можно методом setProperty() . Например, используя голосовые идентификаторы, найденные ранее, вы можете настроить голос. В примере показано, как настроить один голос, чтобы сказать что-то, а затем использовать другой голос из другого языка, чтобы сказать что-то другое.
В Windows идентификатором служит адрес записи в системном реестре:
import pyttsx3 engine = pyttsx3.init() en_voice_id = «HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_EN-US_ZIRA_11.0» ru_voice_id = «HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_RU-RU_IRINA_11.0» # Use female English voice engine.setProperty(‘voice’, en_voice_id) engine.say(‘Hello with my new voice.’) # Use female Russian voice engine.setProperty(‘voice’, ru_voice_id) engine.say(‘Привет. Я знаю несколько языков.’) engine.runAndWait()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Как озвучить системное время в Windows
Пример консольного приложения которое будет называть неточное время может быть реализованно следующим кодом:
from datetime import datetime, date, time import pyttsx3 import time ru_voice_id = «HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_RU-RU_IRINA_11.0» engine = pyttsx3.init() engine.setProperty(‘voice’, ru_voice_id) def say_time(msg): engine.say(msg) engine.runAndWait() time_checker = datetime.now() say_time(f’Не точное Мурманское время: time_checker.hour> часа time_checker.minute> плюс минус 7 минут’)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Привер риложения которое каждую минуту проговаривает текущее время по системным часам. Точнее, оно сообщает время при каждой смене минуты. Например, если вы запустите скрипт в 14:59:59, программа заговорит через секунду.
Программа будет отслеживать и называть время, пока вы не остановите ее сочетанием клавиш Ctrl+C в Windows.
from datetime import datetime, date, time import pyttsx3 import time ru_voice_id = «HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_RU-RU_IRINA_11.0» engine = pyttsx3.init() engine.setProperty(‘voice’, ru_voice_id) def say_time(msg): engine.say(msg) engine.runAndWait() while True: time_checker = datetime.now() if time_checker.second == 0: say_time(f’Мурманское время: time_checker.hour> часа time_checker.minute> минут’) time.sleep(55)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Посмотрите на алгоритм: чтобы уловить смену минуты, следим за значением секунд и ждем, когда оно будет равно нулю. После этого объявляем время и, чтобы поберечь ресурсы производительности, отправляем программу спать на 55 секунд. После этого она снова начнет проверять текущее время и ждать нулевой секунды.
Для дальнейшего изучения библиотеки pyttsx3 вы можете заглянуть в англоязычную документацию, в том числе справку по классу и примеры.
# Упражнения tkinter
- Напишите программу часы, которая показывает текущее время и имеет кнорку, при нажатии на которую можно ушлышать текуще время.
- Внесите измеения с программу что бы при произненсении времени программа корректно склоняла слова: «часы» и «минуты».
- Добавьте с помощью радиокнопки выбор языка озвучки часов.
# Озвучиваем текст из файла
Не будем довольствоваться текстами в коде программы — пора научиться брать их извне. Тем более, это очень просто. В папке, где хранится только что рассмотренный нами скрипт, создайте файл test.txt с текстом на русском языке и в кодировке UTF-8. Теперь добавьте в конец кода такой блок:
text_file = open(«test.txt», «r») data = text_file.read() engine.say(data, sync=True) text_file.close()
Открываем файл на чтение, передаем содержимое в переменную data, затем воспроизводим голосом все, что в ней оказалось, и закрываем файл.
# Упражнения tkinter
- Напишите программу текстовым полем и кнопкой которая будет озвучивать написанное.
- Добавьте меню выбора голоса с возможностью управлять такими параметрами, как высота голоса, громкость и скорость речи.
# Модуль Google TTS — голоса из интернета
Google предлагает онлайн-озвучку текста с записью результата в mp3-файл. Это не для каждой задачи:
- постоянно нужен быстрый интернет;
- нельзя воспроизвести аудио средствами самого gtts;
- скорость обработки текста ниже, чем у офлайн-синтезаторов.
Что касается голосов, английский и французский звучат очень реалистично. Русский голос Гугла — девушка, которая немного картавит и вдобавок произносит «ц» как «ч». По этой причине ей лучше не доверять чтение аудиокниг, имен и топонимов.
Еще один нюанс. Когда будете экспериментировать с кодом, не называйте файл «gtts.py» — он не будет работать! Выберите любое другое имя, например use_gtts.py.
Для работы необходимо установить пакет:
pip install gtts
Простейший код, который сохраняет текст на русском в аудиофайл:
from gtts import gTTS tts = gTTS(‘И это тоже интересно!’, lang=’ru’) tts.save(‘sound_ru.mp3′) tts = gTTS(«It’s amazing!», lang=’en’) tts.save(‘sound_en.mp3’)
1
2
3
4
5
6
После запуска этого кода в директории, где лежит скрипт, появится запись. Для воспроизведения в питоне придется использовать pygame или pyglet.
# Упражнения tkinter
- Напишите программу состояющую из текстового поля, кнопки выбора языка, кнопки «получить аудио». Программа должна преобразовывать текст набранный в текстовом поле в аудио файл, который будет сохраняться в папке с программой.
- Добавьте текстовое поле, куда можно ввести имя для получаемого файла. И сохранять полученный файл с заданным иметем. Реализуйте проверку полей и выводом диалогового окна с сообщением о соотвествующей ошибке.
- Добавьте в программу кнопку выбора каталога для сохранения файла.
Источник: learn4kid-python.firebaseapp.com
Python: простейший голосовой помощник

Для создания голосового помощника не нужно обладать большими знаниями в программировании, главное понимать каким функционалом он должен владеть. Многие компании создают их на первой линии связи с клиентом для удобства, оптимизации рабочих процессов и наилучшей классификации звонков. В данной статье представлена программа, которая может стать основой для Вашего собственного чат-бота, а если точнее – голосового помощника для распознавания голоса и последующего выполнения команд. С ее помощью мы сможем понять принцип работы наиболее часто встречаемых голосовых помощников.
Для начала объявим необходимые нам библиотеки:
#Необходимые библиотеки import speech_recognition as sr import os import sys import webbrowser import pyttsx3 as p from datetime import datetime import time import datetime import random
Также не забудем вести лог файл, который понадобится нам, если же мы все-таки решим улучшить бота для работы с нейронной сетью. Многие компании использую нейронную сеть в своих голосовых помощниках для понимания эмоций клиента и соответствующего реагирования на них. Также стоит не забывать, что с помощью анализа логов, мы сможем понять слабые места алгоритма бота и улучшить взаимодействие с клиентами.
#Создаем лог chat_log = [[‘SESSION_ID’, ‘DATE’, ‘AUTHOR’, ‘TEXT’, ‘AUDIO_NUM’]] #Узнаем номер сессии i = 1 exit = 0 while exit == 0: session_id = str(i) if session_id not in os.listdir(): os.mkdir(session_id) exit = 1 else: i = i + 1 #Первое сообщение пишет bot author = ‘Bot’ text = ‘Привет! Чем я могу вам помочь?’
В лог файл мы записываем время сообщения, автора (бот или пользователь) и собственно сам сказанный текст.
#Добавляем данные к логу с помощью этой процедуры def log_me(author, text, audio): now = datetime.datetime.now() i = 1 exit = 0 while exit == 0: audio_num = str(i)+’.wav’ if audio_num not in os.listdir(session_id): exit = 1 else: i = i + 1 os.chdir(session_id) with open(audio_num , «wb») as file: file.write(audio.get_wav_data()) chat_log.append([now.strftime(«%Y-%m-%d %H:%M:%S»), author, text, audio_num])
Выводим первое сообщение за авторством бота: Привет! Чем я могу вам помочь?
# Выводим первое сообщение на экран и записываем в лог print(«Bot: «+ text) log_me(author, text, audio)
А с помощью такой процедуры в Jupyter Notebook мы можем озвучить через устройство воспроизведения, настроенное по умолчанию, сказанные слова:
#Произношение words def talk(words): engine.say(words) engine.runAndWait()
Как озвучивать текст мы рассмотрели выше, но как же мы свой голос сможем превратить в текст? Тут нам поможет распознавание речи от Google и некоторые манипуляции с микрофоном.
#Настройка микрофона def command(): rec = sr.Recognizer() with sr.Microphone() as source: #Бот ожидает нашего голоса print(‘Bot: . ‘) #Небольшая задержка в записи rec.pause_threshold = 1 #Удаление фонового шума с записи rec.adjust_for_ambient_noise(source, duration=1) audio = rec.listen(source) try: #Распознание теста с помощью сервиса GOOGLE text = rec.recognize_google(audio, language=»ru-RU»).lower() #Вывод сказанного текста на экран print(‘Вы: ‘ + text[0].upper() + text[1:]) log_me(‘User’, text, audio) #Если не распознался тест из аудио except sr.UnknownValueError: text = ‘Не понимаю. Повторите.’ print(‘Bot: ‘ + text) talk(text) #Начинаем заново слушать text = command() log_me(‘Bot’, text, , Null) return text
Что может сделать наш помощник кроме того, чтобы нас слушать? Все ограничено нашей фантазией! Рассмотрим несколько интересный примеров.
Начнем с простого, пусть при команде открыть сайт – он откроет сайт (не ожидали?).
#Тут расписаны действия, которые будут выполнятся при наличии некоторых словосочетаний def makeSomething(text): if ‘открой сайт’ in text: print(‘Bot: Открываю сайт NewTechAudit.’) talk(‘Открываю сайт NewTechAudit.’) log_me(‘Bot’,’Открываю сайт NewTechAudit.’, Null) webbrowser.open(‘https://newtechaudit.ru/’)
Иногда полезно послушать свои слова, да чужими устами. Пусть бот еще умеет и повторять за нами:
#Повторение фразы пользователя elif ‘произнеси’ in text or ‘скажи’ in text or ‘повтори’ in text: print(‘Bot: ‘ + text[10].upper() + text[11:]) talk(text[10:]) log_me(‘Bot’, text[10].upper() + text[11:] , Null)
Пусть еще и собеседником будет, но начнем мы пока только со знакомства:
#Ответ на вопрос elif ‘своё имя’ in text or ‘как тебя зовут’ in text or ‘назови себя’ in text: print(‘Bot: Меня зовут Bot.’) talk(‘Меня зовут Bot’) log_me(‘Bot’, ‘Меня зовут Bot’, Null)