

Способов идентифицировать человека по голосу появляется все больше. И параллельно исследователи придумывают, как обойти эти механизмы — и для защиты собственной персональной информации, и для взлома защищенных таким образом систем. Я решил разобраться в самых последних достижениях ученых в этой сфере, чтобы об этом рассказать вам.
Генерация голоса
Голос человека — результат движения связок, языка, губ. В распоряжении компьютера только числа, изображающие записанную микрофоном волну. Как же компьютер создает звук, который мы можем услышать из динамиков или наушников?
Текст в речь
Один из самых популярных и исследованных методов генерации звуков — прямое преобразование текста, который нужно воспроизвести, в звук. Самые первые программы такого рода склеивали отдельные буквы в слова, а слова — в предложения.
КАК ПОДДЕЛАТЬ ГОЛОС и стать Билли Айлиш | НЕОЖИДАННЫЙ ПОДАРОК ОТ YouTube
С развитием программ-синтезаторов набор заранее записанных на микрофон букв стал набором слогов, а затем и целых слов.
Преимущества таких утилит очевидны: они просты в написании, использовании, поддержке, могут воспроизводить все слова, какие только есть в языке, предсказуемы — все это в свое время стало причиной их коммерческого использования. Но качество голоса, созданного таким методом, оставляет желать лучшего. Все мы помним отличительные черты такого генератора — бесчувственная речь, неправильное ударение, оторванные друг от друга слова и буквы.
Звуки в речь
Этот способ генерации речи относительно быстро заменил собой первый, поскольку лучше имитировал человеческую речь: мы произносим не буквы, а звуки. Именно поэтому системы, основанные на международном фонетическом алфавите — IPA, более качественны и приятны на слух.
В основу этого метода легли заранее записанные в студии отдельные звуки, которые склеиваются в слова. По сравнению с первым методом заметно качественное улучшение: вместо простого склеивания аудиодорожек используются методы смешивания звуков как на основе математических законов, так и на основе нейронных сетей.
Речь в речь
Относительно новый подход полностью основан на нейронных сетях. Рекурсивная архитектура WaveNet, построенная исследователями из DeepMind, позволяет преобразовывать звук или текст в другой звук напрямую, без привлечения заранее записанных строительных блоков (научная статья).
Ключ к этой технологии — правильное использование рекурсивных нейронов Long Short-Term Memory, которые сохраняют свое состояние не только на уровне каждой отдельной клетки нейронной сети, но и на уровне всего слоя.
В целом эта архитектура работает с любым видом звуковой волны, вне зависимости от того, музыка это или голос человека.
На основе WaveNet есть несколько проектов.
- A WaveNet for speech denoising — уничтожение шумов в записи голоса;
- Tacotron 2 (статья в блоге Google) — генерация звука из мел-спектрограммы;
- WaveNet Voice Enhancement — улучшение качества голоса в записи.
Для воссоздания речи такие системы используют генераторы звуковой нотации из текста и генераторы интонаций (ударения, паузы), чтобы создать натурально звучащий голос.
Это самая передовая технология создания речи: она не просто склеивает или смешивает непонятные машине звуки, но самостоятельно создает переходы между ними, делает паузы между словами, меняет высоту, силу и тембр голоса в угоду правильному произношению — или любой другой цели.
Создание поддельного голоса
Для самой простой идентификации, про которую я рассказывал в своей предыдущей статье, подойдет практически любой метод — особенно удачливым хакерам может хватить даже необработанных пяти секунд записанного голоса. Но для обхода более серьезной системы, построенной, например, на нейросетях, нам понадобится настоящий, качественный генератор голоса.
Принцип работы имитатора голоса
Для создания правдоподобной модели «голос в голос», основанной на WaveNet, потребуется множество усилий: нужно записать большое количество текста, сказанного двумя разными людьми, причем так, чтобы все звуки совпадали секунда в секунду, — а сделать это сложновато. Однако есть и другой метод.
Основываясь все на тех же принципах, что и технология синтеза звука, можно достичь не менее реалистичной передачи всех параметров голоса. Так, была создана программа, которая клонирует голос на основе небольшой записи речи. Именно ее мы с тобой и используем.
Сама программа состоит из нескольких важных частей, которые работают последовательно, поэтому разберемся поэтапно.
Кодирование голоса
Голос каждого человека обладает рядом характеристик — их не всегда можно распознать на слух, но они важны. Чтобы точно отделять одного говорящего от другого, будет правильным создать специальную нейронную сеть, формирующую свои наборы признаков для разных людей.
Этот кодировщик позволяет в дальнейшем не только переносить голос, но и сравнивать результаты с желаемыми.

Создание спектрограммы
На основе этих характеристик можно из текста создать мел-спектрограмму звука. Этим занимается синтезатор, в основе которого лежит Tacotron 2, использующий WaveNet.

Сгенерированная спектрограмма содержит всю информацию о паузах, звуках и произношении, и в ней уже заложены все заранее вычисленные характеристики голоса.
Синтез звука
Теперь другая нейронная сеть — основанная на WaveRNN — будет постепенно создавать из мел-спектрограммы звуковую волну. Эта звуковая волна и станет воспроизводиться как готовый звук.
Все характеристики основного голоса сохраняются в синтезированном звуке, который, пусть и не без трудностей, воссоздает исходный голос человека на любом тексте.
Тестирование метода
Теперь, зная, как создать правдоподобную имитацию голоса, давайте попробуем применить это на практике. В прошлой статье я рассказывал про два очень простых, но рабочих метода идентификации человека по голосу: с использованием анализа мел-кепстральных коэффициентов и с помощью нейронных сетей, специально обученных определять одного человека. Давайте узнаем, насколько хорошо мы можем обмануть эти системы поддельными записями.
Возьмем пятисекундную запись голоса мужчины и создадим две записи с помощью нашего инструмента.
Сравним эти записи с помощью мел-кепстральных коэффициентов.

Разница в коэффициентах также видна и в числах:
Источник: tech-geek.ru
Как сделать голос как у другого человека программа

Другие компании стараются обойти стороной этический вопрос за счёт использования вместо клонирования голоса нейросетевых систем синтеза-смешения множества голосов. Таким коммерческим продуктом является, например, Yandex SpeechKit.
В связи с тем, что данная технология представляет конкурентный интерес для множества IT-компаний, проекты с открытым исходным кодом крайне редки. В этой статье мы остановимся на редком свободном проекте Real-Time Voice Cloning. Этот открытый репозиторий является результатом применения технологии переноса обучения SV2TTS, описанной в научной публикации (сэмплы, полученные в результате применения подхода).
Автор библиотеки с июня 2019 участвует в упомянутом выше коммерческом проекте Resemble.AI и уделяет репозиторию меньше времени, но ничто не мешает вам сделать собственный форк проекта.
Алгоритм клонирования голоса
Чтобы компьютер мог читать вслух текст, ему нужно понимать две вещи: что он читает и как это произнести. Поэтому в проекте Real-Time Voice Cloning система клонирования принимает два входных источника: текст, который необходимо озвучить, и образец голоса, которым этот текст должен быть прочитан.

С технической точки зрения система разбита на три компонента:
- Переданный аудиофайл с образцом речи, записанным в виде звуковой дорожки, преобразуется кодером речи (speaker encoder) в векторное представление фиксированной размерности.
- Переданный текст также кодируется в векторное представлении кодером текста (text encoder). Объединение речевого вектора и вектора текста декодируется в спектрограмму. Кодер текста, конкатенатор векторов и декодер (на схеме объединены синим цветом) представляют собой структуру синтезатора речи.
- Вокодер (vocoder, виртуальное устройство синтеза речи) преобразует спектрограмму в звуковую форму.
Модели трёх выделенных компонентов обучаются независимо друг от друга.
Где взять данные?
Объёмы информации, необходимой для качественного обучения системы клонирования, составляют десятки и сотни Гб. В рассматриваемой библиотеке для хранения датасетов служит одна общая директория. Все сценарии предварительной обработки данных выводят результаты в новый каталог SV2TTS , создаваемый в корневом каталоге датасетов. Внутри этой директории появится каталог для каждой модели: кодера, синтезатора и вокодера.
Для обучения кодера речи можно обратиться к следующим библиотекам:
- LibriSpeech (зеркало): набор данных train-other-500 (извлеките как LibriSpeech/train-other-500 ).
- VoxCeleb1: наборы данных Dev A–D, в том числе набор метаданных (извлеките как VoxCeleb1/wav и VoxCeleb1/vox1_meta.csv ).
- VoxCeleb2: наборы данных Dev A–H (извлеките как VoxCeleb2/dev ).
Для обучения синтезатор и вокодера:
- LibriSpeech: наборы данных train-clean-100 (зеркало) и train-clean-360 (зеркало) – извлеките как LibriSpeech/train-clean-100 and LibriSpeech/train-clean-360
- LibriSpeech alignments (только если у вас уже есть LibriSpeech): объедините структуру каталогов с загруженными вами наборами данных LibriSpeech
Официальным хостингом наиболее популярных наборов данных LibriSpeech служит openslr.org, который из-за популярности темы постоянно находится под существенной нагрузкой. Поэтому выше мы приложили ссылки на «зеркала» архивов.
Если вы решили с головой погрузиться в данную тему, обратите внимание на библиотеку Python для работы с аудиодатасетами audiodatasets:
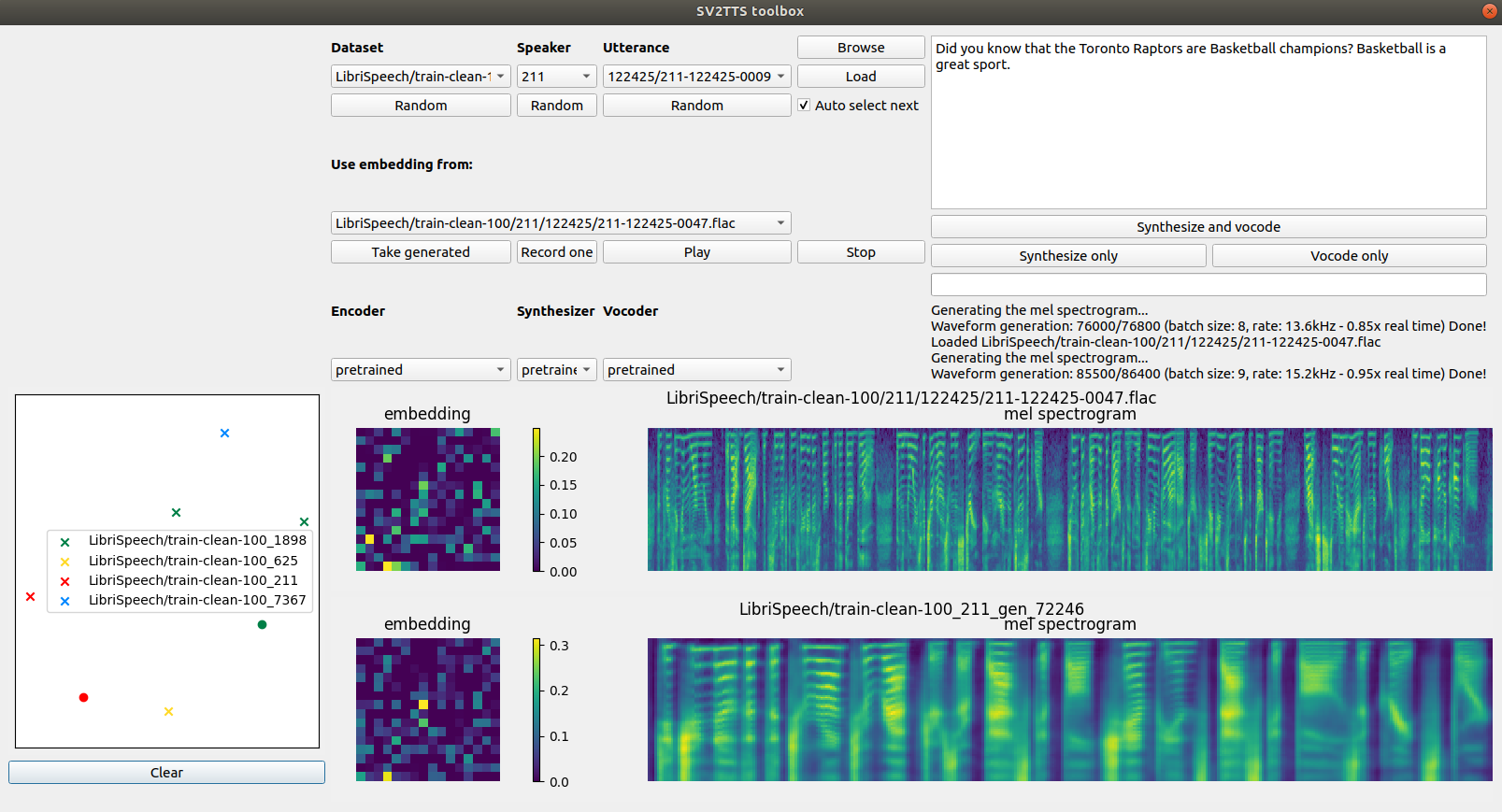
Для первой пробы вы можете нажать под каждым разделом кнопки Random , чтобы выбрать случайный аудиопример, затем Load , чтобы загрузить голосовой ввод в систему. Выпадающий список Dataset служит для выбора набора данных, Speaker – для выбора персоны, Utterance – для произносимой фразы. Чтобы услышать как звучит отрывок, просто нажмите Play . Для запуска алгоритма нажмите Synthesize and vocode . С помощью кнопки Record one можно записать свой собственный сэмпл.
Пример работы с интерфейсом без обучения нейросетей представлен в следующем видеоролике:
При необходимости вы можете отключить окружение с помощью аргумента —no_visdom .
python3 encoder_train.py my_run
Далее запускаем два скрипта, генерирующих данные для синтезатора. Начинаем с аудиофайлов:
python3 synthesizer_preprocess_audio.py
python3 synthesizer_preprocess_embeds.py /synthesizer
Теперь вы можете обучить синтезатор:
python3 synthesizer_train.py my_run /synthesizer
Синтезатор будет выводить сгенерированные аудио и спектрограммы в каталог моделей. Используем синтезатор для генерации обучающих данных вокодера:
python3 vocoder_preprocess.py
Наконец, обучаем вокодер:
python3 vocoder_train.py
Вокодер выводит сгенерированные аудиофайлы в директорию модели.
При возникновении вопросов относительно работы библиотеки мы также рекомендуем ознакомиться с диссертацией автора. Там же приведены ссылки на научные работы, посвящённые теме клонирования и изменения голоса.
Источник: proglib.io
Бесплатное изменение голоса
Хотелось бы вам услышать себя со стороны, когда у вас гелиевый голос? Или наоборот — сделать голос грубым, независимо от того, парень вы или девушка? Сейчас я расскажу об одной бесплатной программе, которая это делает, причем на высоком уровне.
Программа имеет название «Audacity«. Помимо
изменения голоса, этот аудиоредактор выполняет ряд других функций:
— импорт и экспорт файлов, имеющих расширение не только .mp3
— воспроизведение множества дорожек одновременно;
— запись с микрофона;
— создание эха и десятка других эффектов и т.д.
Официальный сайт: http://audacity.sourceforge.net/
Посмотреть видео урок про бесплатное изменение голоса можно ниже…

Понравился пост? Нажми любую кнопку:
Интересные статьи:
Похожие записи:
6 комментариев

Макс 24.07.2012
До этого и я так баловался,но сейчас требуется прога через которую можно сделать свой голос похожий на чей-то другой.Не обязательно такой же,но чтобы был похож.Есть возможность записать оригинальный голос человека.Чтобы потом как-то из этого плясать.Или ты не знаешь ?Может форум какой-то о звуке знаете или ещё что-то по этому поводу?Буду благодарен за ответ! Ответить

Admin 24.07.2012
Когда разберусь — обязательно дам ответ. Ответить
Людмила 07.03.2012
Здравствуйте, посмотрела Ваш видеоурок, спасибо, подскажите, если Вы знаток этой программы, если мы подгрузили диктофонную запись, на которой голоса слышны тихо даже на максимальной громкости на компьютере и в этой программе, как с помощью этой программы усилить звук голоса(какой функцией)? в каком диапазоне(очень нужно). Спасибо. Ответить
Admin 07.03.2012
Людмила, здравствуйте. Попробуйте усилить сигнал через эффекты — усиление сигнала.
Если будет очень плохо с качеством, то можно удалить шум через эффекты — удаление шума.
Это не сильно — но все-таки даст свои плоды. Ответить
Евгений 31.01.2012
Для изменения голоса ради приколов и розыгрышей этих программ вполне достаточно. Для того, чтобы изменить голос радикально так, чтобы и эксперт был заморочен, абсолютно не достаточно. Даже если там и есть функции, позволяющие изменять не только тембр и высоту, то лишь фоно-специалист сможет толково их использовать.
Голос столь же уникален и не повторим как и папиллярные узоры на пальцах, как рисунок радужной оболочки. Ответить
Motoviloff 18.01.2012
вообще это и в Sony Vegas можно сделать и много где еще.
а минус аудасити в том, что в мп3 нельзя конвертить Ответить
Источник: teweb.ru