

Хорошо спроектированные API = довольные разработчики.
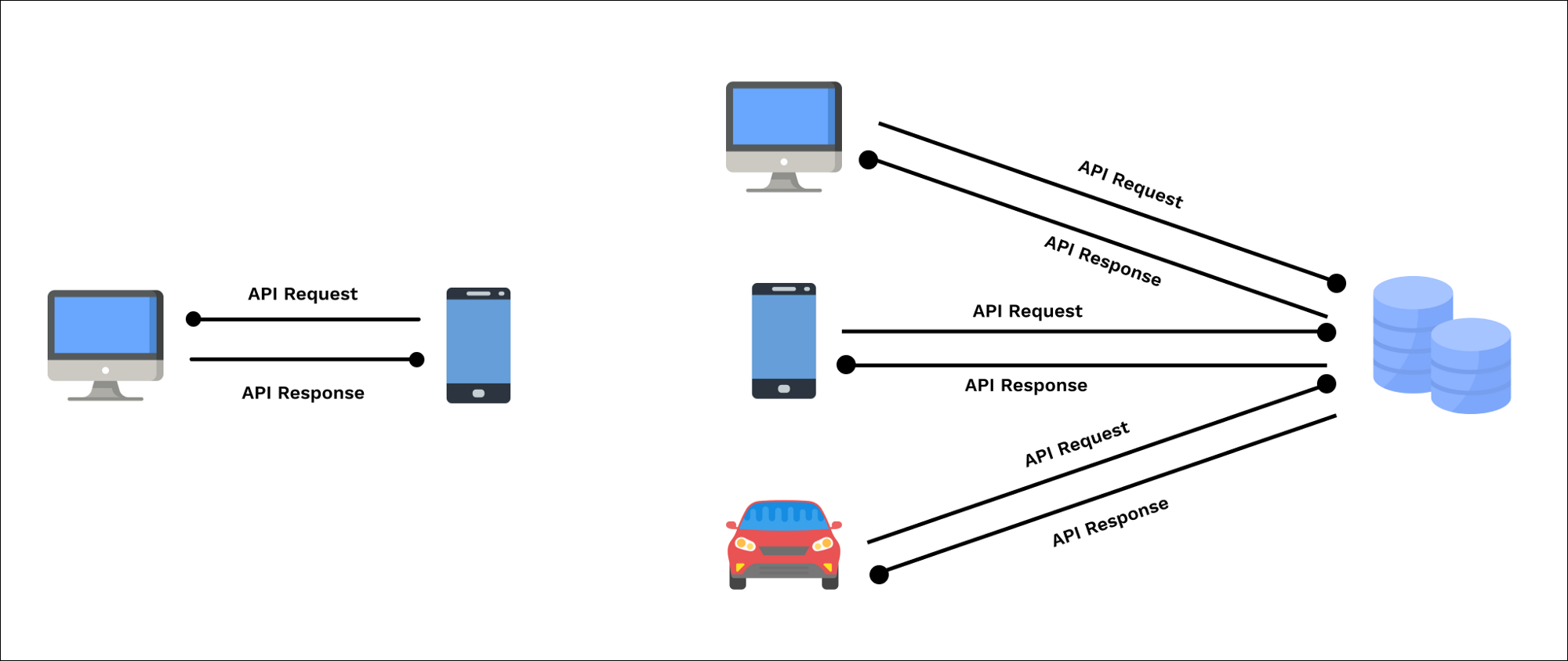
Прикладные программные интерфейсы (Application Programming Interfaces, API) — это интерфейсы, облегчающие использование в приложениях данных и ресурсов других приложений. Они жизненно необходимы для успеха продукта или даже компании.
Без API большинства ваших любимых программ попросту не существовало бы. Например, API Google Maps позволяет вам использовать карты Google в вашем мобильном или веб-приложении. Без него вам пришлось бы разрабатывать вашу собственную базу данных с картами! Только представьте, сколько времени это заняло бы.
Почему мы используем API?
- API обеспечивают сторонний доступ к вашим ресурсам.
- API расширяют возможности вашего приложения.
- API позволяют разработчикам повторно использовать логику приложения.
- API «платформонезависимы», т. е., они могут доставлять данные, не оглядываясь на особенности запрашивающей платформы.
Как сделать API на Python #1
В большинстве жизненных сценариев модель данных уже будет существовать, но поскольку мы собираемся обсудить лучшие подходы к проектированию API, давайте начнем с самого начала.
Моделирование и структурирование данных
Моделирование данных с оглядкой на будущий API это первый шаг на пути к его легкому созданию, поддержке и обновлению.
При проектировании API всегда старайтесь использовать общие термины, а не сложную бизнес-терминологию, которая может быть неизвестна за пределами вашей организации.
Ваши API могут использоваться внутри вашей компании, но могут и быть открыты для стороннего использования, чтобы другие разработчики могли применять их в своих проектах. Используя общие термины, исходите из того, что они должны быть понятны этим «другим разработчикам», чтобы они могли побыстрее разобраться с вашим API и его интеграцией в свой продукт.
Представьте, что вы строите портал, где пользователи смогут просматривать информацию по книгам различных авторов. В вашей компании могут использоваться свои, специфические термины, например, Storytellers, creations, series (букв. авторы рассказов, произведения, серии), при том, что имеются в виду Authors, books и series (авторы, книги, серии). Для простоты и чтобы сторонние разработчики могли использовать ваши API, имеет смысл придерживаться более общей терминологии при создании путей API.
https://api.domain.com/authors https://api.domain.com/authors//books
Таким образом любой разработчик сможет куда быстрее разобраться, что из себя представляет ваш API.
Написание ресурсо-ориентированных API
Приложения, использующие ваши API, хотят получить доступ к вашим ресурсам. Поддержка иерархии ресурсов поможет лучше структурировать ваш API. Каждый узел в вашем пути, содержащий какой-либо ресурс или коллекцию ресурсов, должен занимать определнное место в иерархии.
API для начинающих. Пример VK. [1/5]
Ресурсом может быть отдельный кусочек данных, скажем, информация об авторе (если продолжать использовать пример, приведенный выше). Коллекцией ресурсов в нашем случае может быть список книг, написанных отдельным автором.
Иерархия ресурсов при этом может выглядеть следующим образом:
Base Path -> Authors (collection) -> profile (resource) Base Path -> Authors (collection) -> books (collection) -> book (resource)
В иерархии должно поддерживаться постоянство, чтобы у разработчиков не возникало лишних вопросов при интеграции вашего API и их приложения.
Вот несколько советов по поддержке постоянства и простоты:
- В именах коллекций и ресурсов используйте американский английский (например, color, а не colour).
- Следите за правописанием.
- Используйте более простые, широко употребимые слова, чтобы все было максимально ясно (например, delete, а не remove).
- Если используете те же ресурсы, что и в другом API, используйте ту же терминологию.
- Для коллекций используйте множественные формы (например, authors, books и т. п.).
REST
REST (Representational State Transfer) — это наиболее широко используемый стандарт для отправки HTTP-запросов к API. Суть этого подхода в том, что каждый URL представляет объект.
У API может быть одно из следующих назначений:
- Создание данных.
- Чтение данных.
- Обновление данных.
- Удаление данных.
Да, вы угадали, это CRUD!
Назначения API регулируются набором HTTP-слов, определяющих природу запроса и то, что он должен делать.
Слово GET ассоциируется с получением данных от API. Оно запрашивает представление данных. Запрос GET может включать параметры запроса для фильтрации результатов, полученных от API.
Слово POST связано с отправкой информации к API, в результате чего в базе данных будет создан ресурс.
Слово PUT обычно используется для обновления уже имеющихся на сервере ресурсов.
Слово DELETE служит для удаления ресурса с сервера.
Разбираемся с минорными и мажорными обновлениями
Когда вы не вносите изменений, способных сломать приложение вашего клиента, можно обойтись минорными обновлениями. Речь идет о таких вещах как добавление опциональных полей или включение поддержки дополнительных параметров. В таких случаях вы инкрементируете номер минорной версии вашего API.
Мажорные обновления с большей вероятностью способны сломать приложение. К таким обновлениям можно отнести добавление нового обязательного параметра в полезную нагрузку запроса или изменения полей в ответе.
Есть несколько способов версионирования ваших API.
Самый распространенный способ — включение версии в URI.
https://api.domain.com/v1.0/authors
В основе следующего способа лежит дата. При этом в URI включается дата выпуска версии. Преимущество этого способа в том, что любой разработчик сможет сразу увидеть, насколько часто вы обновляете ваш API.
https://api.domain.com/2020-06-15/authors
Третий способ — включение версии API в заголовки.
https://api.domain.com/authors x-api-version: v1
Самый рекомендуемый и приемлемый вариант версионирования — использовать имя версии в URI.
Разбивка на страницы
В мире все возрастающего количества точек данных становится нереальным отображать все данные на одном экране одновременно. Поэтому важно дать возможность пользователям получать определенное количество документов, прежде чем запрашивать новые. Это называется разбивкой на страницы (или пагинацией), а возвращаемый набор данных называется страницей.
Чтобы сделать возможной разбивку на страницы в вашем API, рекомендуется использовать особые фразы в полезной нагрузке запроса и ответа:
- STRING page_token (отправляется в запросе)
- STRING next_page_token (возвращается API)
- INT page_size (отправляется в запросе)
page_token указывает, какую именно страницу должен вернуть API. Обычно это строка. Для первого вызова API page_token = “1” .
page_size определяет, сколько записей должно вернуться в ответе. Например, page_size = 100 вернет максимум 100 записей по одному вызову API.
next_page_token определяет следующий токен в серии. Если после page_token=»1″ есть дополнительные данные, возвращается значение next_page_token=”2” . Если же данных больше нет, т. е., пользователь исчерпал их до конца, возвращается пустое значение next_page_token=”” .
Вот и все! Это были лучшие подходы, благодаря которым ваши API будут надежными, последовательными и простыми в интеграции с другими приложениями.
Источник: techrocks.ru
Проектирование Web API в 7 шагов

Разработка веб API это нечто большее чем просто URL, HTTP статус-коды, заголовки и содержимое запроса. Процесс проектирования – то, как будет выглядеть и восприниматься ваш API – очень важен и является хорошей инвестицией в успех вашего дела. Эта статья кратко описывает методологию для проектирования API с опорой на преимущества веба и протокола HTTP, в частности.
Но не стоит думать, что это применимо только для HTTP. Если по какой-то причине вам необходимо реализовать работу ваших сервисов используя WebSockets, XMPP, MQTT и так далее – применяя большую часть всех рекомендаций вы получите практически тот же API, который будет хорошо работать. К тому же полученный API позволит легче разработать и поддерживать работу поверх нескольких протоколов.
Хороший дизайн затрагивает URL, статус-коды, заголовки и содержимое запроса
Обычно руководства по проектированию Web API фокусируются на общих концепциях: как проектировать URL, как правильно использовать HTTP статус-коды, методы, что передавать в заголовках и как спроектировать дизайн содержимого, которое представлено сериализованными данными или графом объектов. Это всё очень важные детали реализации, но не настолько в смысле общего проектирования API. Проектирование API – это то, как сама суть сервиса будет описана и представлена, то что вносит значительный вклад в успех и удобность использования Web API.
Хороший процесс проектирования или методология предоставляют набор согласованных и воспроизводимых шагов для создания компонентов сервисов, которые будут доступны в виде Web API. Это значит, что такая прозрачная методология может быть использована разработчиками, дизайнерами и архитекторами для координации своих действий по реализации ПО. Использованная методология так же может уточнятся со временем по мере того, как улучшается и автоматизируется процесс без ущерба для деталей методологии. На самом деле, детали реализации могут меняться (например, платформа, ОС, фреймворки и стиль UI) независимо от процесса проектировки, когда эти две активности полностью разделены и задокументированы.
Проектирование API в 7 шагов.
Далее следует краткий обзор методологии описанной в книге «RESTful Web APIs» за авторством Ричардсона и Амундсена (Richardson and Amundsen). Статья не предполагает детального разбора каждого шага, но постарается дать общее понимание что делается на каждом шаге. Также, читатели могут использовать этот обзор как руководство для разработки процесса проектирования Web API, который учитывает специфику ваших знаний и целей бизнеса.
Заметки на полях: Да, руководство в семь шагов может выглядеть достаточно большим, но реально тут только 5 шагов по проектированию и 2 как дополнения, касающиеся реализации и публикации сервисов. Эти два дополнения построены вокруг процессов и описывают весь процесс от начала до конца.
В своём плане вы должны учесть возможную итеративную природу процесса создания сервиса. Например, вы можете проходить через Шаг 2 (Создание диаграмм состояний) и понять, что надо еще кое-чего сделать в Шаге 1 (Перечислить все компоненты). Когда вы будете писать код (Шаг 6), вы можете обнаружить, что пропустили пару моментов в Шаге 5 (Создание семантического профиля), и так далее. Ключевой момент заключается в использовании руководства для обнаружения как можно большего количества деталей и желании возвращаться на шаг-два назад, чтобы описать пропущенные моменты. Итеративность – ключ к построению наиболее полного представления вашего сервиса и видению как он может быть использован клиентскими приложениями.
Шаг 1: Перечислить все компоненты
Первым шагом предлагается перечислить все типы данных, которые клиентское приложение может захотеть получить или передать с помощью сервиса. Мы зовём это семантическим описанием. Семантическое – потому что отображает значение данных в приложении, и описание – потому что содержит описание того, что происходит в самом приложении. Заметьте, что вы должны работать с точки зрения клиентского приложения, а не сервиса. Важно разработать удобный API для использования клиентом.
- id – уникальный идентификатор для каждой записи в системе
- title – название для каждого «дела»
- dateDue – дата, к которому «дело» должно быть завершено
- complete – «да/нет» флажок, который показывает завершено ли «дело»
Шаг 2: Нарисовать диаграмму состояний
Следующим шагом будет нарисовать диаграмму состояний для предполагаемого API. Каждый блок на диаграмме представляет возможное состояние – документ который включает одно или более семантических дескрипторов, найденных на первом шаге. Вы можете использовать стрелки для обозначения переходов от одного блока к другому, от одного состояния к следующему. Эти переходы инициируются запросами.
Пока не стоит беспокоится на счёт определения какой метод используется для каждого перехода. Просто укажите является ли переход безопасным (HTTP GET), небезопасный/не идемпотентный (HTTP POST) или небезопасный/идемпотентный (PUT)
Заметки на полях: Идемпотентные действия – такие, которые можно повторять без неожиданных сайд-эффектов. Например, HTTP PUT является идемпотентным потому что спецификация говорит, что сервер должен использовать значения состояния, полученные от клиента, для замены любых значений в целевом ресурсе. В то время как HTTP POST не идемпотентен, так как спецификация HTTP указывается что значения, переданные с помощью POST должны быть добавлены к существующим ресурсам, а не замещены.
В нашем случае, клиентское приложение для простейшего «Списка дел» может потребовать доступ к пунктам списка, возможность фильтрации, просматривать отдельные пункты и отмечать их как завершённые. Многие из этих действий используют значения состояний для передачи данных между клиентом и сервером. Например, действие «добавить элемент» позволяет клиенту передавать значения состояний title и dueDate. Ниже диаграмма, которая иллюстрирует основные действия:
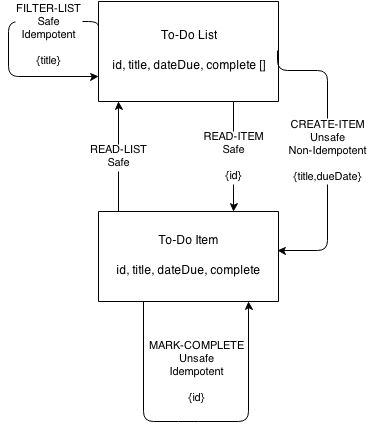
- read-list
- filter-list
- read-item
- create-item
- mark-complete
Как только вы пройдёте пару раз через эти два шага у вас будет хорошее понимание всех данных и действий в которых нуждается клиент для взаимодействия с вашим сервисом.
Шаг 3: Согласование магических строк
- schema.org
- microformats.org
- Dublin Core
- IANA Link Relation Values
Заметки на полях: Использование общих имён для дескрипторов может быть хорошей идеей для внешнего интерфейса, однако вас никто не заставляет использовать их для ваших внутренних нужд. Имеются ввиду, например, имена для баз данных. Сервис самостоятельно может использовать карту соответствий между внешними и внутренними именами без каких-либо проблем.
Для To-Do сервиса из примера, у меня получилось найти приемлемые существующие имена для всех дескрипторов кроме одного – «create-item». В этом случае, я обратился к созданию уникального URI на основе правил из Web-Linking RFC 5988. Во время выбора конвенционных имён для интерфейса вас всегда будут преследовать компромиссы. Редко когда удаётся найти идеальное попадание к внутренним именам и это нормально.
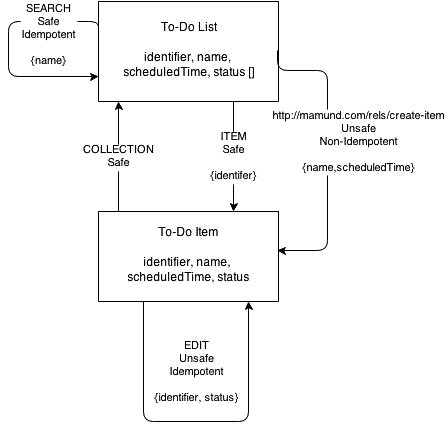
Вот что у меня получилось:
- id ->identifier from Dublin Core
- title ->name from Schema.org
- dueDate ->scheduledTime from Schema.org
- complete ->status from Schema.org
- read-list ->collection from IANA Link Relation Values
- filter-list ->search from IANA Link Relation Values
- read-item ->item from IANA Link Relation Values
- create-item ->http://mamund.com/rels/create-item using RFC5988
- mark-complete ->edit from IANA Link Relation Values
Итак, вот как стала выглядеть диаграмма после использования согласования имён:
Шаг 4: Выбор типа гипермедиа
Следующим шагом в процессе проектирования вашего API будет выбор типа данных, который будет использоваться для передачи сообщений между сервером и клиентом. Одним из отличительных знаков сети является то, что данные передаются стандартизированными документами через общий интерфейс. Очень важно выбрать такой тип, который поддерживает одинаково дескрипторы данных («identifier», «status») и действий («search», «edit»). Таких форматов достаточно мало.
- HyperText Markup Language (HTML)
- Hypertext Application Language (HAL)
- Collection+JSON (Cj)
- Siren
- JSON-API
- Uniform Basis for Exchanging Representations (UBER)
Заметки на полях: Диаграмма состояний сейчас показывает «редактирование» как идемпотентное (HTTP PUT), но HTML до сих пор не имеет встроенной поддержки для PUT. Однако я могу добавить дополнительное поле чтобы эмулировать идемпотентный HTML POST.
Отлично, теперь я могу «опробовать» интерфейс основываясь на состояниях из диаграммы. Для нашего примера, нам надо описать только две вещи: «To-Do List» и «To-Do Item»:
Коллекция «To-Do List» в HTML представлении
Коллекция «To-Do Item» в HTML представлении
Помните о том, что, работая с примерной реализацией вашей диаграммы состояний, вы можете обнаружить, что что-то пропущено и вам надо вернуться на шаг-два назад. Это нормально и не надо этого пугаться. Сейчас самое время все это опробовать в тестовых примерах – до того, как вы начнёте реализовывать всё в коде.
Когда вы будете довольны тем как всё представлено, остаётся последний шаг перед началом кодирования – создание семантического профиля.
Шаг 5: Создание семантического профиля
Семантический профиль – это документ который перечисляет все дескрипторы в вашем решении и описывает детали каждого из них, чтобы помочь разработчикам создать как клиентскую, так и серверную реализацию.
Следует чётко понимать, что это руководство по реализации, а не инструкция по реализации.
Форматы описания сервиса
Форматы для описания сервиса существуют достаточно давно и оказываются очень кстати, когда вы захотите сгенерировать код или задокументировать существующую реализацию сервиса.
- Web Service Definition Language (WSDL)
- Atom Service Description (AtomSvc)
- Web Application Description Language (WADL)
- Blueprint
- Swagger
- RESTful Application Modeling Language (RAML)
Форматы для описания профиля
- Application-Level Semantic Profiles (ALPS)
- JSON-LD+ Hydra
Так как идея документа заключается в том, чтобы описать реальные аспекты проблемной области (а не частное решение), формат весьма отличается от типичных описательных форматов:
ALPS profile for InfoQ article on «API Design Methodology»