
Между тем, искусственный интеллект не дремлет. Все новые и новые возможности ему подвластны. И если отбросить в сторону теорию масонского или другого заговора, то очень даже хорошие возможности. И полезные. Во всяком случае, для тех, кто работает с музыкой.
Появился сервис, который легко и просто в любом треке разделит музыку и вокал. Запустила его компания Open Media, называется он Lalal.ai. И сразу из преимуществ: инструмент бесплатный и доступный в России.
Работа сервиса основана как раз на алгоритмах искусственного интеллекта по определению голоса. Для обучения были задействованы 20 ТБ музыкальных данных студийного качества. И теперь в любой композиции ИИ легко распознает голос и может его как бы снять оттуда. В итоге получается две дорожки: инструментальная и вокал.
Более того, Lalal.ai может работать не только с песнями, но и с другим материалом. Можно вырезать голос из подкастов или любых видео, будь то фильмы, сериалы, клипы и прочие ролики. Достаточно просто загрузить файл на сайт. Поддерживаются практически все форматы, самые общедоступные так точно.
Как Петь Вторым Голосом | ПОЮ НА КАМЕРУ БЕЗ ПОДГОТОВКИ | Научиться Петь Двухголосие
Впрочем, стоит отметить, что работает программа все же не идеально. На инструментальной дорожке слышны голоса, только сильно замазанные как будто, а за вокалом вполне пробивается музыкальная часть. С другой стороны, как уже сказали, сервис бесплатный. Каждый может развлекаться, как ему вздумается, куда и как применять полученный материал – на волю творящего.
А, может, 20 ТБ просто мало для нормального обучения искусственного интеллекта, и надо в разы больше. Но в этом случае полностью распадаются все теории захвата людей машинами – слишком долго воспитывать. Так что да, во всем есть плюсы.
Эта статья доступна у нас на сайте: GTF.CLUB
Если ты крутишься в музыкальной индустрии и делаешь это качественно — вступай в наш клуб!
Источник: dzen.ru
Разделить 2 голоса записанные на один микрофон?! (1 онлайн
Статус В этой теме нельзя размещать новые ответы.
panmusicman
Well-Known Member
30 Янв 2008 1.499 1.754 113 40 Казань vk.com
Всем привет.
Друзья, меня сегодня с утра озадачила вопросом одна тётушка. У неё запись с 2 голосами, понимаю там речь, разговор. Цель — надо эти голоса сделать индивидуальными, то есть полностью отделить один от другого.
Вроде бы это не реально сделать? Или в RX может как-то ручками пошаманить? В любом случае, я с таким на практике не сталкивался и вроде по логике вещей это сделать невозможно, но может быть я отстал от продвинутых технологий и это делается на раз да еще да еще и нажатием одной кнопки?)
Прикрепляю фрагмент нашей переписки ВК.
Вложения

67,7 KB Просмотры: 269

Тренируемся петь В ДВА ГОЛОСА
53,6 KB Просмотры: 254

48,9 KB Просмотры: 224
Последнее редактирование: 17 Апр 2020
squarebel
Well-Known Member
4 Июн 2011 3.418 1.109 113
«Коллеги криминалисты разделяли». Но так ли это на самом деле?) Если в записи были мужской бас и женский сопрано, тогда может и реально. А если в одном диапазоне, то такой технологии вроде не существует, хотя хрен их знает этих криминалистов, может изобрели уже чего по принципу отпечатков пальцев. Берут образцы от каждого первоисточника и спец плагином отделяют.
LilColt
Well-Known Member
29 Ноя 2011 1.521 987 113 Маркс
Отправляйте к коллегам криминалистам.
panmusicman
Well-Known Member
30 Янв 2008 1.499 1.754 113 40 Казань vk.com
Все таки без вариантов?
мелодайн вроде работает на полифонии, получпется как то умеет различать разные партии?! (Правда я в нем в полифоническом режиме тож не работаю обычно, но так мысли вслух.. вдруг тут есть какое то решение?)
Завадский Алексей
Member
24 Янв 2016 59 26 18 31
На ум приходит мелодайн. Если пели что-то да вышло бы. Но разговор. Точно не идеально, хотя от исходника зависит
Talula
Member
29 Авг 2009 87 73 18
на маке Audionamix TRAX PRO 3 SP думаю справится, правда с продаж всю линейку сняли, да и стоила она 999 баксов.
panmusicman
Well-Known Member
30 Янв 2008 1.499 1.754 113 40 Казань vk.com
Типа решил помочь. Спец тему тут открыл. Ребят, вам послание..
Страничка этой ненормальной звукооператорши
Можете передать привет
ВКонтакте | ВКонтакте
Вложения
562,6 KB Просмотры: 294
234,1 KB Просмотры: 278
panmusicman
Well-Known Member
30 Янв 2008 1.499 1.754 113 40 Казань vk.com
Я реально офигел. То есть это не клиент и не коммерческий какой то заказ, просто попросила совета и помощи
Начиналось так.
Вложения
170,1 KB Просмотры: 310
167,3 KB Просмотры: 296

159,4 KB Просмотры: 295
162,4 KB Просмотры: 281
Talula
Member
29 Авг 2009 87 73 18
нормально. она не знает как сделать необходимое ей, но долбоящеры — все вокруг, кроме неё. далеко пойдёт!
видимо, её коллеги-криминалисты тоже в списке долбоящеров, из-за чего связь с ними она и потеряла
Alexander Yakuba
Opposition Member
31 Мар 2008 6.984 3.712 113 Пенза vk.com
Был опыт пару раз, поэтому теперь всегда спрашиваю «речь или музыка?». Всегда ответ «речь». «Тогда вам к криминалистам», отвечаю.
Без вариантов.
Methafuzz
Loading. Please, wait.
16 Май 2006 7.304 5.063 113 55 Калуга
Руками в Изотопе можно в общем, я пару раз куски таких вкраплений удалял из нужных записей. Но гемор был такой, что больше ни за какие деньги не возьмусь )
Alx_g
Active Member
15 Окт 2011 395 233 43 Пенза
У коллег криминалистов мог быть и «мультитрек», они ведь тоже не дураки
Talula
Member
29 Авг 2009 87 73 18
блин, сейчас опыт работы на тв вспомнил. короче, звук с 2 микрофонов всегда писали в разные каналы. грубо говоря, ведущий в левом канале, гоость в правом канале, а на монтаже их уже складывали в псевдо стерео и так это шло в эфир. но в исходниках видео (или же записи с рекордера) они так и оставались — каждый голос на своём канале.
так вот я то подумал. может мадам просто не понимает, как из исходников каждый канал отдельно сохранить (моно, например), чтобы получилось 2 файла с разными голосами? ну и объяснить толком не смогла по незнанию терминов.
LilColt
Well-Known Member
29 Ноя 2011 1.521 987 113 Маркс
Типа решил помочь. Спец тему тут открыл. Ребят, вам послание..
Страничка этой ненормальной звукооператорши
Можете передать привет
ВКонтакте | ВКонтакте
Стрёмная баба
Lena Schestera
New Member
18 Апр 2020 8 0 1 41
блин, сейчас опыт работы на тв вспомнил. короче, звук с 2 микрофонов всегда писали в разные каналы. грубо говоря, ведущий в левом канале, гоость в правом канале, а на монтаже их уже складывали в псевдо стерео и так это шло в эфир. но в исходниках видео (или же записи с рекордера) они так и оставались — каждый голос на своём канале.
так вот я то подумал. может мадам просто не понимает, как из исходников каждый канал отдельно сохранить (моно, например), чтобы получилось 2 файла с разными голосами? ну и объяснить толком не смогла по незнанию терминов.
Спасибо! Под исходником Вы подразумеваете звуковой файл? То есть я имела в виду, что в звуковом файле можно как-то разделять голоса — и да, сохранить их потом в разных файлах. Это возможно?
Lena Schestera
New Member
18 Апр 2020 8 0 1 41
У коллег криминалистов мог быть и «мультитрек», они ведь тоже не дураки
Нет, у них не было никакого мультитрека.
Lena Schestera
New Member
18 Апр 2020 8 0 1 41
Руками в Изотопе можно в общем, я пару раз куски таких вкраплений удалял из нужных записей. Но гемор был такой, что больше ни за какие деньги не возьмусь )
Спасибо! А можете просветить, что за изотоп такой?! Впервые слышу. Работала в Praat, Sis, Adob Audition, Speech Analyzer, Wave Assistant.
Добавлено: 18 Апр 2020
Стрёмная баба
Ну не всем же быть такими красавцами, как ты
Lena Schestera
New Member
18 Апр 2020 8 0 1 41
нормально. она не знает как сделать необходимое ей, но долбоящеры — все вокруг, кроме неё. далеко пойдёт!
видимо, её коллеги-криминалисты тоже в списке долбоящеров, из-за чего связь с ними она и потеряла
Ну во-первых, не все. А во-вторых, он первый начал вести себя странно. В-третьих, я извинилась за эмоции. Остальное Ваши домыслы. Но если Вам так интересно, уточню: из всех криминалистов, которых я знала в двух разных городах, только один умел так делать.
Остальные нет.
Последнее редактирование: 18 Апр 2020
Got Zilla
Well-Known Member
18 Янв 2020 1.875 1.782 113 56 Киев
Обратите внимание, пользователь заблокирован на форуме.
Вам так интересно, уточню: из всех криминалистов, которых я знала в двух разных городах, только один умел так делать. Остальные нет.
Враньё это.
Methafuzz
Loading. Please, wait.
16 Май 2006 7.304 5.063 113 55 Калуга
Спасибо! А можете просветить, что за изотоп такой?!
Izotope RX 5 Advanced, я в ней делал. Сейчас уже 7 версия вышла, но пока не обновлялся, мне старой хватает
panmusicman
Well-Known Member
30 Янв 2008 1.499 1.754 113 40 Казань vk.com
А во-вторых, он первый начал вести себя странно.
Судя по всему это неизлечимо.. Хоть как-то но себя надо выгородить!
Дело было так.
Я этой дамочке рассказал и про возможный вариант с Ozone RX, по части чистки шумов про Audition или Waves. после этого открыл тут тему. параллельно ей скинул ответы людей и вариант с Мелодайном. Вместо того что бы задуматься над информацией последовали обзывательства.
Мне просто принципиально охота, что бы люди понимали с кем имеют дело. Да, она извинилась, зайдя с какой-то фейковой другой странички (потому что основную я заблокировал).. Думаю, ну слава богу, наверно в человеке что-то вменяемое осталось. Захожу сюда и вижу, что всё таки Я первый оказался неадекватом
Вложения
171,3 KB Просмотры: 179
164,3 KB Просмотры: 172

161,7 KB Просмотры: 167
166,1 KB Просмотры: 172

151 KB Просмотры: 160
425,1 KB Просмотры: 172
415,2 KB Просмотры: 169
374,1 KB Просмотры: 176
234,1 KB Просмотры: 162
Последнее редактирование: 18 Апр 2020
fewa-w
Active Member
21 Фев 2020 404 241 43 23
можете небольшой образец скинуть? попробую разделить
Talula
Member
29 Авг 2009 87 73 18
Спасибо! Под исходником Вы подразумеваете звуковой файл? То есть я имела в виду, что в звуковом файле можно как-то разделять голоса — и да, сохранить их потом в разных файлах. Это возможно?
выложите уже кусок файла с разными голосами.
КГБ СССР
Member
8 Мар 2020 22 44 13 82
Последнее редактирование: 19 Апр 2020
LilColt
Well-Known Member
29 Ноя 2011 1.521 987 113 Маркс
Ну не всем же быть такими красавцами, как ты
Я не про вашу внешность
StoneJungle
Well-Known Member
13 Авг 2011 1.011 1.030 113 Екатеринбург
Нет никаких спецов- криминалистов) Специально придумала ,что есть, якобы доказательство, что раз один спец смог, то и другой спец сможет. Вот зачем ментам и другим спецслужбам подобной фигней заниматься? Инфа полученная таким образом не является юридически ценной. Просто подозреваемого за жопу возьмут , в бараний рог свернут, сам всё расскажет или подождут пока с поличным спалится. Девушке надо поменьше детективов про шпиёнов смотреть.
Меня раз в год подобные персонажи атакуют.
С полгода назад такой персонаж был:
Приветствия опущу.
Ну и на всякий,чтоб по терминам в гугле шариться:
Субвокализа́ция — это мысленное проговаривание текста при чтении про себя, позволяющее читателю вообразить звучание слов как при чтении вслух. Это естественный процесс при чтении, помогающий читателю распознавать слова по их звучанию, и тем самым уменьшить когнитивную нагрузку. Также это помогает лучше понять и запомнить прочитанное. Субвокализация вызывает непроизвольные микродвижения мышц, связанных с говорением, хотя в большинстве случаев эти микродвижения можно обнаружить только при помощи аппаратуры.
Зак : Интересное задание для звукорежиссера ,бюджет 30к ,нужно компетентно ответить на ряд вопросов.
Сегодня получу список вопросов и задам первые из них вам. Всего 15 не самых больших вопросов, но ответы нужны достоверные.
Зак: И еще такой момент. Честно говоря хотелось бы получить выполнение небольшого тестового задания. Ответ на тестовое задание много времени не займет (минута), а мне позволит понять стоит ли иметь с вами и дело.
Могу выслать тестовый вопрос?
зак: На каком диапазоне частот (ГЦ) и на какой громкости (ДБ) происходит
проговаривание «про себя» тех или иных слов и предложений, т. е. так
называемая субвокализация. Интересует разброс в ГЦ и ДБ от и до, т. е. нижние и верхние границы.
Подчеркну. Речь идет не о тихом шепоте, а о проговаривании про себя.
С ответом на этот вопрос не тороплю
я: Интересный вопрос) О каких технических параметрах может идти речь при проговаривании мысленно?
зак : Как бы подобная речь не называлась, но колебания связок при таком
проговаривании существует и звук издается. Человеческое ухо, даже
стоящего вблизи человека, подобное уловить не в состоянии, но в целом,
определенной аппаратурой, это сделать возможно.
Вопрос не самый сложный. Подготовьте на него ответ, я сверю имеющимся и обсудим сотрудничество.
Нас интересует подобного рода информация (понятное дело не только по
субвокализации) в плане защиты офиса по приказу начальства. Вопросы
будут касаться лишь параметром речи человека.
я: Это к звукорежессуре никакого отношения не имеет, это скорее к британским ученым.
К сожалению, в этой теме помочь ничем не можем.
Источник: rmmedia.ru
Нейросеть разделяет голоса спикеров на аудиозаписи
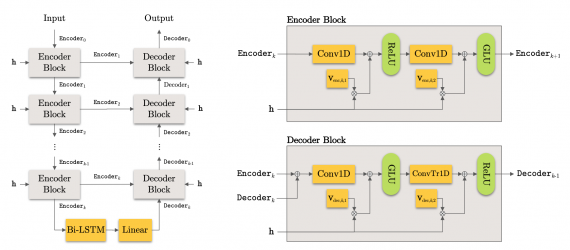
Cone of Silence — это нейросетевая модель, которая разделяет спикеров на аудиозаписи, записанной с нескольких микрофонов. Модель выдает аудиодорожку с речью спикера и предсказывает расположение спикера относительно микрофонов. Нейросеть справляется с аудиозаписями, где спикеры говорят одновременно и перебивают друг друга.
Нейросеть изолирует источники звука для отдельного угла. Экспоненциально уменьшая угол, модель локализует и разделяет источники звука за логарифмическое время. Алгоритм работает на аудиозаписях с любым числом передвигающихся спикеров. По результатам экспериментов, модель выдает state-of-the-art результаты и на задаче локализации источника шума, и на задаче разделения спикеров.
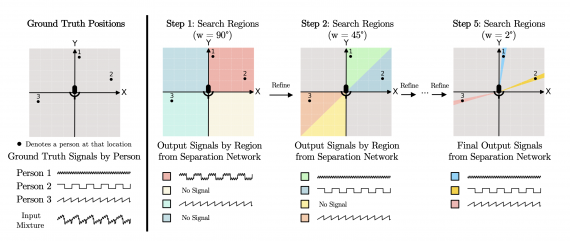
Подробнее про работу модели
На первом этапе алгоритм делит аудиозапись на регионы в 90 градусов. Части аудиозаписи без звука не учитываются. Алгоритм продолжает делить аудиозапись на меньшие части, пока не достигнет итогового шага, где регион охватывает 2 градуса.
Тестирование работы нейросети
Работу модели сравнивали с state-of-the-art подходами. Ниже видно, что предложенная архитектура обходит предыдущие модели, основанные на данных звуковых волн и на спектрограммах.
Источник: neurohive.io