
Когда вы запускаете программу на своей машине, она работает в своем собственном “пузыре”, который полностью отделен от других программ, которые активны в то же время. Этот “пузырь” называется process и включает в себя все , что необходимо для управления этим вызовом программы.
Например, эта так называемая среда процесса включает в себя страницы памяти , используемые процессом, файловые дескрипторы, открытые этим процессом, права доступа пользователя и группы, а также весь вызов командной строки, включая заданные параметры.
Эта информация хранится в файловой системе процесса вашей системы UNIX/Linux, которая является виртуальной файловой системой, и доступна через каталог /proc . Записи сортируются по идентификатору процесса, который уникален для каждого процесса. Пример 1 показывает это для произвольно выбранного процесса с идентификатором процесса #177.
Пример 1: Информация, доступная процессу
[email protected]:/proc/177# ls attr cpuset limits net projid_map statm autogroup cwd loginuid ns root status auxv environ map_files numa_maps sched syscall cgroup exe maps oom_adj sessionid task clear_refs fd mem oom_score setgroups timers cmdline fdinfo mountinfo oom_score_adj smaps uid_map comm gid_map mounts pagemap stack wchan coredump_filter io mountstats personality stat
Структурирование программного кода и данных
Чем сложнее становится программа, тем чаще ее удобно делить на более мелкие части. Это относится не только к исходному коду, но и к коду, который выполняется на вашем компьютере. Одним из решений этой проблемы является использование подпроцессов в сочетании с параллельным выполнением. Мысли, стоящие за этим, таковы:
Распараллеливание вычислений на python. multiprocessing.
- Один процесс охватывает фрагмент кода, который может выполняться отдельно
- Некоторые разделы кода могут выполняться одновременно и в принципе допускают распараллеливание
- Используя возможности современных процессоров и операционных систем, например каждое ядро процессора, мы можем сократить общее время выполнения программы
- Чтобы уменьшить сложность вашей программы/кода и передать часть работы на аутсорсинг специализированным агентам, действующим в качестве подпроцессов
Использование подпроцессов требует переосмысления способа выполнения программы-от линейного к параллельному. Это похоже на изменение перспективы работы в компании с обычного работника на менеджера – вам придется следить за тем, кто что делает, сколько времени занимает один шаг и каковы зависимости между промежуточными результатами.
Это поможет вам разбить код на более мелкие фрагменты, которые могут быть выполнены агентом, специализирующимся только на этой задаче. Если это еще не сделано, подумайте о том, как структурирован ваш набор данных, чтобы он мог эффективно обрабатываться отдельными агентами. Это приводит к следующим вопросам:
- Почему вы хотите распараллелить код? В вашем конкретном случае и с точки зрения усилий имеет ли смысл думать об этом?
- Предназначена ли ваша программа для запуска только один раз или она будет работать регулярно на аналогичном наборе данных?
- Можете ли вы разделить свой алгоритм на несколько этапов выполнения?
- Позволяют ли ваши данные вообще распараллеливаться? Если еще нет, то каким образом должна быть адаптирована организация ваших данных?
- Какие промежуточные результаты ваших вычислений зависят друг от друга?
- Какие изменения в аппаратном обеспечении необходимы для этого?
- Есть ли узкое место в аппаратном обеспечении или алгоритме, и как можно избежать или минимизировать влияние этих факторов?
- Какие еще побочные эффекты распараллеливания могут возникнуть?
Возможный вариант использования-это основной процесс и демон, работающий в фоновом режиме (ведущий/ведомый), ожидающий активации. Кроме того, это может быть основной процесс, который запускает рабочие процессы, работающие по требованию. На практике основным процессом является процесс подачи, который управляет двумя или более агентами, которые подают части данных и выполняют вычисления на данной части.
МНОГОПОТОЧНОСТЬ НА PYTHON | МОДУЛЬ THREADING
Имейте в виду, что распараллеливание является дорогостоящим и трудоемким процессом из-за накладных расходов на подпроцессы, необходимые вашей операционной системе. По сравнению с выполнением двух или более задач линейным способом, делая это параллельно, вы можете сэкономить от 25 до 30 процентов времени на каждый подпроцесс, в зависимости от вашего варианта использования. Например, две задачи, каждая из которых занимает 5 секунд, требуют в общей сложности 10 секунд, если они выполняются последовательно, и могут потребовать в среднем около 8 секунд на многоядерной машине при распараллеливании. 3 из этих 8 секунд могут быть потеряны для накладных расходов, ограничивая ваши улучшения скорости.
Запуск функции параллельно с Python
Python предлагает четыре возможных способа справиться с этим. Во-первых, вы можете выполнять функции параллельно с помощью модуля multiprocessing . Во-вторых, альтернативой процессам являются потоки. Технически это легкие процессы, и они выходят за рамки данной статьи. Для дальнейшего чтения вы можете взглянуть на Python threading module . В-третьих, вы можете вызывать внешние программы с помощью метода system() модуля os или методов, предоставляемых модулем subprocess , и впоследствии собирать результаты.
Модуль multiprocessing охватывает хороший выбор методов для обработки параллельного выполнения подпрограмм. Это включает процессы, пулы агентов, очереди и каналы.
Листинг 1 работает с пулом из пяти агентов, которые обрабатывают фрагмент из трех значений одновременно. Значения числа агентов и размера блока выбираются произвольно для демонстрационных целей. Отрегулируйте эти значения в соответствии с количеством ядер в вашем процессоре.
Метод Pool.map() требует трех параметров – функции, вызываемой для каждого элемента набора данных, самого набора данных и chunksize . В Листинге 1 мы используем функцию с именем square и вычисляем квадрат заданного целочисленного значения. Кроме того, размер chunk может быть опущен. Если явно не задано значение по умолчанию размер блока равен 1.
Обратите внимание, что порядок выполнения агентов не гарантирован, но результирующий набор находится в правильном порядке. Он содержит квадратные значения в соответствии с порядком элементов исходного набора данных.
Листинг 1: Параллельное выполнение функций
from multiprocessing import Pool def square(x): # calculate the square of the value of x return x*x if __name__ == ‘__main__’: # Define the dataset dataset = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] # Output the dataset print (‘Dataset: ‘ + str(dataset)) # Run this with a pool of 5 agents having a chunksize of 3 until finished agents = 5 chunksize = 3 with Pool(processes=agents) as pool: result = pool.map(square, dataset, chunksize) # Output the result print (‘Result: ‘ + str(result))
Запуск этого кода должен привести к следующему результату:
$ python3 pool_multiprocessing.py Dataset: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] Result: [1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144, 169, 196]
Примечание : Для этих примеров мы будем использовать Python 3.
Запуск нескольких функций с помощью очереди
В Листингах 2.1-2.7 мы используем очередь FIFO. Он реализован в виде списка, который уже предоставлен соответствующим классом из модуля multiprocessing . Кроме того, модуль time загружается и используется для имитации рабочей нагрузки.
Листинг 2.1: Используемые модули
import multiprocessing from time import sleep
Далее определяется рабочая функция ( Листинг 2.2 ). Эта функция фактически представляет агента и требует трех аргументов. Имя процесса указывает, какой это процесс, и оба задачи и результаты ссылаются на соответствующую очередь.
Внутри рабочей функции находится бесконечный цикл while . И задачи , и результаты – это очереди, определенные в основной программе. tasks.get() возвращает текущую задачу из очереди задач для обработки. Значение задачи меньше 0 завершает цикл while и возвращает значение -1. Любое другое значение задачи выполнит вычисление (квадрат) и вернет это значение. Возврат значения в основную программу осуществляется как results.put() . Это добавляет вычисленное значение в конец очереди results .
Листинг 2.2: Рабочая функция
# define worker function def calculate(process_name, tasks, results): print(‘[%s] evaluation routine starts’ % process_name) while True: new_value = tasks.get() if new_value < 0: print(‘[%s] evaluation routine quits’ % process_name) # Indicate finished results.put(-1) break else: # Compute result and mimic a long-running task compute = new_value * new_value sleep(0.02*new_value) # Output which process received the value # and the calculation result print(‘[%s] received value: %i’ % (process_name, new_value)) print(‘[%s] calculated value: %i’ % (process_name, compute)) # Add result to the queue results.put(compute) return
Следующим шагом является основной цикл (см. Листинг 2.3 ). Во-первых, определяется менеджер для межпроцессной коммуникации (IPC). Затем добавляются две очереди – одна для хранения задач, а другая для результатов.
Листинг 2.3: IPC и очереди
if __name__ == «__main__»: # Define IPC manager manager = multiprocessing.Manager() # Define a list (queue) for tasks and computation results tasks = manager.Queue() results = manager.Queue()
Выполнив эту настройку, мы определяем пул процессов с четырьмя рабочими процессами (агентами). Мы используем класс multiprocessing.Pool () и создайте его экземпляр. Далее мы определяем пустой список процессов (см. Листинг 2.4 ).
Листинг 2.4: Определение пула процессов
# Create process pool with four processes num_processes = 4 pool = multiprocessing.Pool(processes=num_processes) processes = []
В качестве следующего шага мы инициируем четыре рабочих процесса (агента). Для простоты они называются от “P0” до “P3”. Создание четырех рабочих процессов выполняется с помощью multiprocessing.Process() . Это связывает каждую из них с рабочей функцией, а также с задачей и очередью результатов. Наконец, мы добавим вновь инициализированный процесс в конец списка процессов и запустим новый процесс с помощью new_process.start() (см. Листинг 2.5 ).
Листинг 2.5: Подготовка рабочих процессов
# Initiate the worker processes for i in range(num_processes): # Set process name process_name = ‘P%i’ % i # Create the process, and connect it to the worker function new_process = multiprocessing.Process(target=calculate, args=(process_name,tasks,results)) # Add new process to the list of processes processes.append(new_process) # Start the process new_process.start()
Наши рабочие процессы ждут работы. Мы определяем список задач, которые в нашем случае являются произвольно выбранными целыми числами. Эти значения добавляются в список задач с помощью tasks.put() . Каждый рабочий процесс ожидает выполнения задач и выбирает следующую доступную задачу из списка задач. Это обрабатывается самой очередью (см. Листинг 2.6 ).
Листинг 2.6: Подготовка очереди задач
# Fill task queue task_list = [43, 1, 780, 256, 142, 68, 183, 334, 325, 3] for single_task in task_list: tasks.put(single_task) # Wait while the workers process sleep(5)
Через некоторое время мы хотели бы, чтобы наши агенты закончили. Каждый рабочий процесс реагирует на задачу со значением -1. Он интерпретирует это значение как сигнал завершения и после этого умирает. Вот почему мы помещаем столько -1 в очередь задач, сколько у нас запущено процессов.
Перед смертью процесс, который завершается, помещает -1 в очередь результатов. Это должно быть сигналом подтверждения для основного контура, что агент завершает работу.
В основном цикле мы читаем из этой очереди и считаем число -1. Основной цикл завершается, как только мы насчитали столько подтверждений завершения, сколько у нас процессов. В противном случае мы выводим результат расчета из очереди.
Листинг 2.7: Завершение и вывод результатов
# Quit the worker processes by sending them -1 for i in range(num_processes): tasks.put(-1) # Read calculation results num_finished_processes = 0 while True: # Read result new_result = results.get() # Have a look at the results if new_result == -1: # Process has finished num_finished_processes += 1 if num_finished_processes == num_processes: break else: # Output result print(‘Result:’ + str(new_result))
Пример 2 отображает выходные данные программы Python. Запустив программу несколько раз, вы можете заметить, что порядок запуска рабочих процессов так же непредсказуем, как и сам процесс, который выбирает задачу из очереди. Однако после завершения порядок элементов очереди результатов совпадает с порядком элементов очереди задач.
$ python3 queue_multiprocessing.py [P0] evaluation routine starts [P1] evaluation routine starts [P2] evaluation routine starts [P3] evaluation routine starts [P1] received value: 1 [P1] calculated value: 1 [P0] received value: 43 [P0] calculated value: 1849 [P0] received value: 68 [P0] calculated value: 4624 [P1] received value: 142 [P1] calculated value: 20164 result: 1 result: 1849 result: 4624 result: 20164 [P3] received value: 256 [P3] calculated value: 65536 result: 65536 [P0] received value: 183 [P0] calculated value: 33489 result: 33489 [P0] received value: 3 [P0] calculated value: 9 result: 9 [P0] evaluation routine quits [P1] received value: 334 [P1] calculated value: 111556 result: 111556 [P1] evaluation routine quits [P3] received value: 325 [P3] calculated value: 105625 result: 105625 [P3] evaluation routine quits [P2] received value: 780 [P2] calculated value: 608400 result: 608400 [P2] evaluation routine quits
Примечание : Как уже упоминалось ранее, ваш вывод может не совсем соответствовать показанному выше, так как порядок выполнения непредсказуем.
Использование метода os.system()
Метод system() является частью модуля os , который позволяет выполнять внешние программы командной строки в отдельном процессе от вашей программы Python. Метод system() является блокирующим вызовом, и вы должны ждать, пока вызов не будет завершен и не вернется. Как фетишист UNIX/Linux, вы знаете, что команда может быть запущена в фоновом режиме и записать вычисленный результат в выходной поток, который перенаправляется в такой файл (см. Пример 3 ):
Пример 3: Команда с перенаправлением вывода
$ ./program >> outputfile ./program >> outputfile )
Этот системный вызов создает процесс, который выполняется параллельно вашей текущей программе Python. Получение результата может стать немного сложным, потому что этот вызов может завершиться после окончания вашей программы Python – вы никогда не знаете.
Использование этого метода намного дороже, чем предыдущие методы, которые я описал. Во-первых, накладные расходы намного больше (переключатель процессов), а во-вторых, он записывает данные в физическую память, например на диск, что занимает больше времени. Хотя это лучший вариант, если у вас ограниченная память (например, с ОЗУ), и вместо этого вы можете иметь массивные выходные данные, записанные на твердотельный диск.
Использование модуля подпроцесса
Этот модуль предназначен для замены вызовов os.system() и os.spawn () . Идея подпроцесса состоит в том, чтобы упростить процессы нереста, связываясь с ними через каналы и сигналы и собирая выходные данные, которые они производят, включая сообщения об ошибках.
Начиная с Python 3.5, подпроцесс содержит метод subprocess.run() для запуска внешней команды, которая является оболочкой для базового подпроцесса.Popen() класс. В качестве примера мы запускаем команду UNIX/Linux df-h , чтобы узнать, сколько дискового пространства все еще доступно в разделе home/| вашей машины. В программе Python вы выполняете этот вызов, как показано ниже ( Листинг 4 ).
Листинг 4: Базовый пример выполнения внешней команды
import subprocess ret = subprocess.run([«df», «-h», «/home»]) print(ret)
Это основной вызов, очень похожий на команду df-h/home , выполняемую в терминале. Обратите внимание, что параметры разделены в виде списка, а не одной строки. Результат будет похож на Пример 4 . По сравнению с официальной документацией Python для этого модуля, он выводит результат вызова в stdout , в дополнение к возвращаемому значению вызова.
Пример 4 показывает результат нашего вызова. Последняя строка вывода показывает успешное выполнение команды. Вызов subprocess.run() возвращает экземпляр класса Completed Process , который имеет два атрибута с именем args (аргументы командной строки) и returncode (возвращаемое значение команды).
Пример 4: Запуск скрипта Python из листинга 4
$ python3 diskfree.py Filesystem Size Used Avail Capacity iused ifree %iused Mounted on /dev/sda3 233Gi 203Gi 30Gi 88% 53160407 7818407 87% /home CompletedProcess(args=[‘df’, ‘-h’, ‘/home’], returncode=0)
Чтобы подавить вывод в stdout и перехватить как вывод , так и возвращаемое значение для дальнейшей оценки, вызов subprocess.run() должен быть немного изменен. Без дальнейших изменений subprocess.run() отправляет выходные данные выполненной команды в stdout , который является выходным каналом базового процесса Python. Чтобы захватить выходной сигнал, мы должны изменить его и установить выходной канал на предопределенное значение подпроцесса.PIPE . Листинг 5 показывает, как это сделать.
Листинг 5: Захват выходного сигнала в трубе
import subprocess # Call the command output = subprocess.run([«df», «-h», «/home»], stdout=subprocess.PIPE) # Read the return code and the output data print («Return code: %i» % output.returncode) print («Output data: %s» % output.stdout)
Как объяснялось ранее subprocess.run() возвращает экземпляр класса Завершенный процесс . В Листинге 5 этот экземпляр представляет собой переменную с простым именем output . Код возврата команды хранится в атрибуте output.return code , а вывод, напечатанный в stdout , можно найти в атрибуте output.stdout . Имейте в виду, что это не распространяется на обработку сообщений об ошибках, потому что мы не изменили выходной канал для этого.
Вывод
Параллельная обработка-это прекрасная возможность использовать мощь современного оборудования. Python предоставляет вам доступ к этим методам на очень сложном уровне. Как вы уже видели ранее, как модуль multiprocessing , так и модуль subprocess позволяют вам легко погрузиться в эту тему.
Признание
Автор хотел бы поблагодарить Герольда Рупрехта за его поддержку и критику при подготовке этой статьи.
Читайте ещё по теме:
- Наборы в Python
- Введение в модуль коллекций Python
- Python для НЛП: Классификация текста с несколькими метками с помощью Keras
- Python: вечеринка со строками
- 3-Мерные графики в Python с использованием Matplotlib
- WXPYPHON: Создание собственного монитора процесса поперечного платформа с PsUtil
- Python numpy.argmax (): Сообщение для начинающих
Источник: pythobyte.com
Параллельный цикл for в Python

- Используйте модуль multiprocessing для распараллеливания цикла for в Python
- Используйте модуль joblib для распараллеливания цикла for в Python
- Используйте модуль asyncio для распараллеливания цикла for в Python
Распараллеливание цикла означает параллельное распределение всех процессов с использованием нескольких ядер. Когда у нас много заданий, каждое вычисление не дожидается завершения предыдущего в параллельной обработке. Вместо этого для завершения используется другой процессор.
В этой статье мы распараллелим цикл for в Python.
Используйте модуль multiprocessing для распараллеливания цикла for в Python
Чтобы распараллелить цикл, мы можем использовать пакет multiprocessing в Python, поскольку он поддерживает создание дочернего процесса по запросу другого текущего процесса.
Модуль multiprocessing можно использовать вместо цикла for для выполнения операций над каждым элементом итерации. Можно использовать объект multiprocessing.pool() , поскольку использование нескольких потоков в Python не даст лучших результатов из-за глобальной блокировки интерпретатора.
import multiprocessing def sumall(value): return sum(range(1, value + 1)) pool_obj = multiprocessing.Pool() answer = pool_obj.
map(sumall,range(0,5)) print(answer)
0, 1, 3, 6, 10
Используйте модуль joblib для распараллеливания цикла for в Python
Модуль joblib использует многопроцессорность для запуска нескольких ядер ЦП для выполнения распараллеливания цикла for . Он предоставляет легкий конвейер, который запоминает шаблон для простых и понятных параллельных вычислений.
Чтобы выполнить параллельную обработку, мы должны установить количество заданий, а количество заданий ограничено количеством ядер в ЦП или количеством доступных или простаивающих в данный момент.
Функция delayed() позволяет нам указать Python, чтобы через некоторое время был вызван конкретный упомянутый метод.
Функция Parallel() создает параллельный экземпляр с указанными ядрами (в данном случае 2).
Нам нужно создать список для выполнения кода. Затем список передается в параллельную систему, которая формирует два потока и раздает им список задач.
from joblib import Parallel, delayed import math def sqrt_func(i, j): time.sleep(1) return math.sqrt(i**j) Parallel(n_jobs=2)(delayed(sqrt_func)(i, j) for i in range(5) for j in range(2))
[1.0, 0.0, 1.0, 1.0, 1.0, 1.4142135623730951, 1.0, 1.7320508075688772, 1.0, 2.0]
Используйте модуль asyncio для распараллеливания цикла for в Python
Модуль asyncio является однопоточным и запускает цикл обработки событий, временно приостанавливая сопрограмму с помощью методов yield from или await .
Приведенный ниже код будет выполняться параллельно при его вызове, не влияя на ожидание основной функции. Цикл также выполняется параллельно с основной функцией.
ended execution for 4 ended execution for 8 ended execution for 0 ended execution for 3 ended execution for 6 ended execution for 2 ended execution for 5 ended execution for 7 ended execution for 9 ended execution for 1
Сопутствующая статья — Python Loop
- Как получить доступ к индексу в Foreach петлях на Python
- Итерировать в обратном направлении в Python
- Уменьшение цикла в Python
Источник: www.delftstack.com
Python: как сделать многопоточную программу
Когда-то давно мы делали простой таймер с напоминанием на Python. Он работал так:
- Мы спрашивали пользователя, о чём ему напомнить и через сколько минут.
- Программа на это время засыпала и ничего не делала.
- Как только время сна заканчивалось, программа просыпалась и выводила напоминание.
У такой схемы есть минус: мы не можем пользоваться программой и выделенными на неё ресурсами до тех пор, пока она не проснётся. Процессор по кругу гоняет пустые команды и ждёт, когда можно будет продолжить полезную работу. Чтобы процессор и программа могли во время работы таймера делать что-то ещё, используют потоки.
Что такое поток
В упрощённом виде потоки — это параллельно выполняемые задачи. По умолчанию используется один поток — это значит, что программа делает всё по очереди, линейно, без возможности делать несколько дел одновременно.
Но если мы сделаем в программе два потока задач, то они будут работать параллельно и независимо друг от друга. Одному потоку не нужно будет становиться на паузу, когда в другом что-то происходит.
Важно понимать, что поток — это высокоуровневое понятие из области программирования. На уровне вашего «железа» эти потоки всё ещё могут обсчитываться последовательно. Но благодаря тому, что они будут обсчитываться быстро, вам может показаться, что они работают параллельно.
Многопоточность
Представим такую ситуацию:
- У вас на руке смарт-часы, которые собирают данные о вашем пульсе, УФ-излучении и движениях. На смарт-часах работает программа, которая обрабатывает эти данные.
- Программа состоит из четырёх функций. Первая собирает данные с датчиков. Три другие обрабатывают эти данные и делают выводы.
- Пока первая функция не собрала нужные данные, ничего другого не происходит.
- Как только данные введены, запускаются три оставшиеся функции. Они не зависят друг от друга и каждая считает своё.
- Как только все три функции закончат работу, программа выдаёт нужный результат.
А теперь давайте посмотрим, как это выглядит в однопоточной и многопоточной системе. Видно, что если процессор позволяет делать несколько дел одновременно, в многопоточном режиме программа будет работать быстрее:
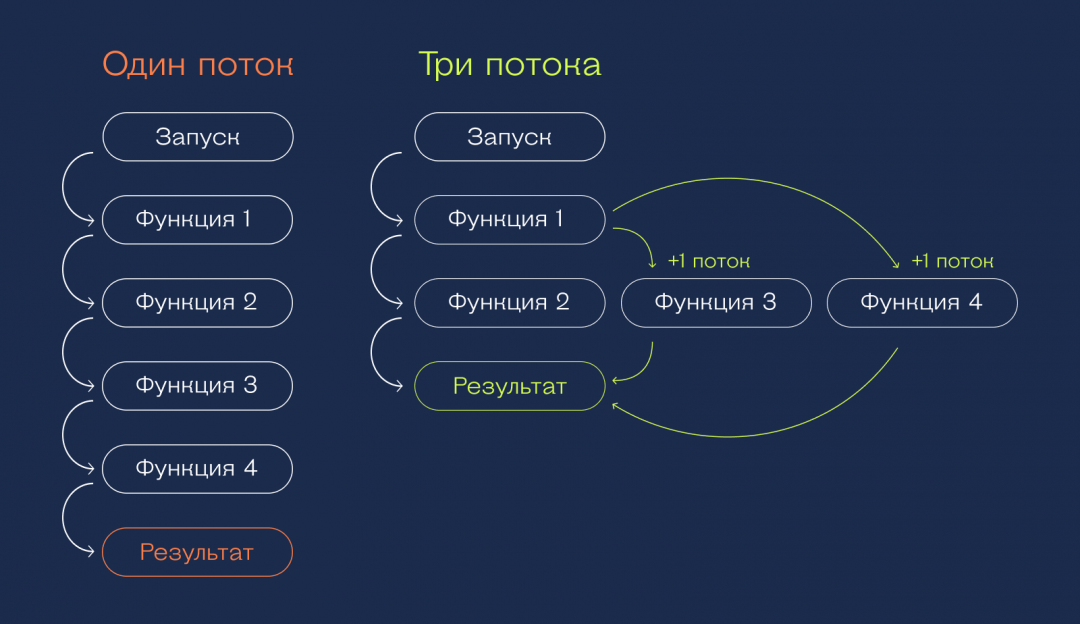
Многопоточность на Python
За потоки в Python отвечает модуль threading, а сам поток можно создать с помощью класса Thread из этого модуля. Подключается он так:
from threading import Thread
После этого с помощью функции Thread() мы сможем создать столько потоков, сколько нам нужно. Логика работы такая:
- Подключаем нужный модуль и класс Thread.
- Пишем функции, которые нам нужно выполнять в потоках.
- Создаём новую переменную — поток, и передаём в неё название функции и её аргументы. Один поток = одна функция на входе.
- Делаем так столько потоков, сколько требует логика программы.
- Потоки сами следят за тем, закончилась в них функция или нет. Пока работает функция — работает и поток.
- Всё это работает параллельно и (в теории) не мешает друг другу.
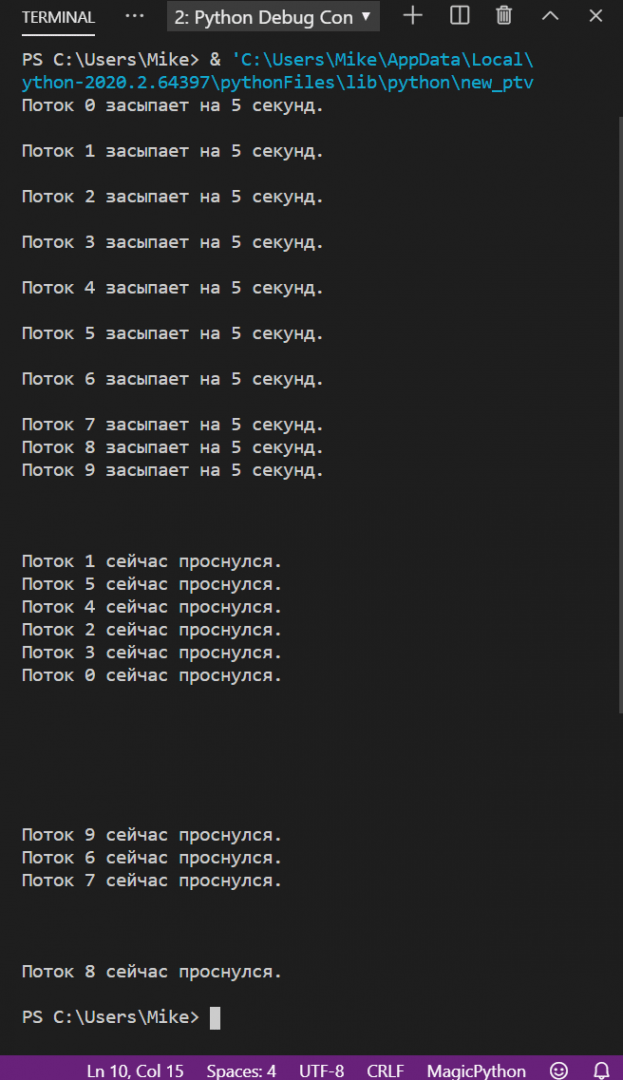
Для иллюстрации запустим такой код:
import time from threading import Thread def sleepMe(i): print(«Поток %i засыпает на 5 секунд.n» % i) time.sleep(5) print(«Поток %i сейчас проснулся.n» % i) for i in range(10): th = Thread(target=sleepMe, args=(i, )) th.start()
А вот как выглядит результат. Обратите внимание — потоки просыпаются не в той последовательности, как мы их запустили, а в той, в какой их выполнил процессор. Иногда это может помешать работе программы, но про это мы поговорим отдельно в другой статье.
Добавляем потоки в таймер
Первое, что нам нужно сделать, — вынести код таймера-напоминания в отдельную функцию, чтобы создать с ней поток. Для этого используем команду def :
# Делаем отдельную функцию с напоминанием def remind(): # Спрашиваем текст напоминания, который нужно потом показать пользователю print(«О чём вам напомнить?») # Ждём ответа пользователя и результат помещаем в строковую переменную text text = str(input()) # Спрашиваем про время print(«Через сколько минут?») # Тут будем хранить время, через которое нужно показать напоминание local_time = float(input()) # Переводим минуты в секунды local_time = local_time * 60 # Ждём нужное количество секунд, программа в это время ничего не делает time.sleep(local_time) # Показываем текст напоминания print(text)
Теперь сделаем новый поток, в который отправим выполняться нашу новую функцию. Так как аргументов у нас нет, то и аргументы передавать не будем, а напишем args=().
# Создаём новый поток
th = Thread(target=remind, args=())
# И запускаем его
th.start()
Нам осталось убедиться в том, что пока поток работает, мы можем выполнять в программе что-то ещё и наше засыпание в потоке на это не повлияет. Для этого мы через 20 секунд после запуска выведем сообщение на экран. За 20 секунд пользователь успеет ввести напоминание и время, после чего таймер уйдёт в новый поток и там уснёт на нужное количество минут. Но это не помешает работе основной программы — она тоже будет выполнять свои команды параллельно с потоком.
# Пока работает поток, выведем что-то на экран через 20 секунд после запуска
time.sleep(20)
print(«Пока поток работает, мы можем сделать что-нибудь ещё.n»)
# Подключаем модуль для работы со временем import time # Подключаем потоки from threading import Thread # Делаем отдельную функцию с напоминанием def remind(): # Спрашиваем текст напоминания, который нужно потом показать пользователю print(«О чём вам напомнить?») # Ждём ответа пользователя и результат помещаем в строковую переменную text text = str(input()) # Спрашиваем про время print(«Через сколько минут?») # Тут будем хранить время, через которое нужно показать напоминание local_time = float(input()) # Переводим минуты в секунды local_time = local_time * 60 # Ждём нужное количество секунд, программа в это время ничего не делает time.sleep(local_time) # Показываем текст напоминания print(text) # Создаём новый поток th = Thread(target=remind, args=()) # И запускаем его th.start() # Пока работает поток, выведем что-то на экран через 20 секунд после запуска time.sleep(20) print(«Пока поток работает, мы можем сделать что-нибудь ещё.n»)
Потоки — это ещё не всё
В Python кроме потоков есть ещё очереди (queue) и управление процессами (multiprocessing). Про них мы поговорим отдельно.
Источник: thecode.media