
Существуют задачи, не решаемые на серийных персональных компьютерах за приемлемое время[1], к примеру прогнозирование погоды, моделирование процессов разрушения в механике (crash-тесты).
Для решения таких задач используют многопроцессорные (параллельные) вычислители, множество архитектур которых весьма обширно. Для параллельных вычислительных систем необходимо создавать специальные программы. В тексте такой программы определяются части (ветки), которые могут выполнятся параллельно, а также алгоритм их взаимодействия. Параллельные программы, вообще говоря, являются архитектурно зависимыми. Средства параллельных вычислений можно разделить на три уровня (рис.1).
Параллельное программирование. Лекция 14c. Разработка, отладка и запуск параллельных программ (MPI)
Основной характеристикой при классификации параллельных вычислительных систем является способ организации памяти[ 2]. Все множество архитектур можно разделить на две группы: системы с общей памятью и системы с распределенной памятью.
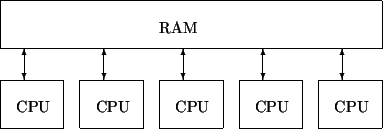 |
Системы с общей памятью — все процессоры работают в едином адресном пространстве с равноправным доступом к памяти(рис.2). В эту группу попадают симметричные мультипроцессорные системы(SMP). В таких системах наличие общей памяти упрощает взаимодействие процессоров между собой, однако возникает необходимость в механизме разрешения конфликтов между процессорами за доступ к памяти, что накладывает сильные ограничения на число процессоров (обычно не более 32). Таким образом, при всем удобстве использования, производительность систем с общей памятью ограничена.
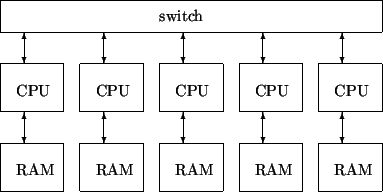 |
Системы с распределенной памятью — каждый процессор имеет собственную локальную памятью, и прямой доступ к этой памяти других процессоров невозможен(рис.3). Этой группе принадлежат системы массового параллелизма(MPP) и их менее дорогой вариант кластеры. Такая система обычно состоит из нескольких самостоятельных вычислительных узлов.
Для связи узлов используется определенная сетевая технология. Системы с распределенной памятью сложнее программировать, поскольку необходимо делить обрабатываемые данные на части и рассылать их по вычислительным узлам. Общее число процессоров в таких системах теоретически не ограничено.
- Библиотеки использующие модель общей памяти . Например, OpenMP — программный интерфейс для программирования компьютеров с общей памятью (симметричные мультипроцессоры).
- Библиотеки построенные по модели обмена сообщениями . Здесь наиболее популярный стандарт это Message Passing Interface(MPI). Этот стандарт используется для построения параллельных программ по модели обмена сообщениями. Существуют реализации почти для всех суперкомпьютерных платформ, а также для сетей рабочих станций UNIX и MS Windows.
Параллельные программы можно писать »вручную», непосредственно вставляя в нужные места вызовы коммуникационной библиотеки. Этот путь требует от программиста специальной подготовки. Альтернативой является использование систем автоматического и полуавтоматического распараллеливания последовательных программ[ 4]. Например, Adaptor — одна из реализаций спецификации High Performance Fortran (HPF) или BERT77 — средство автоматического распараллеливания Fortran-программ. Такие системы так же могут помочь пользователю выяснить, можно ли распараллелить данную задачу, оценить время ее выполнения, определить оптимальное число процессоров.
Лекция 2. Основные функции библиотеки MPI.
- В первую очередь это теоретическая возможность неограниченного наращивания производительности путем добавления новых узлов.
- Гибкость технологии. Системы этого класса могут строится на разнородной аппаратной базе, иметь оптимальную для данной задачи топологию соединительной сети и допускают различные формы организации работы параллельных процессов.
- Хороший показатель цена/производительность. Вычислительные системы сверхвысокой производительности стоят дорого. За счет гибкости устройства часто можно построить кластерную систему по доступной цене, которая обеспечит требуемую производительность. Можно использовать уже существующую сеть рабочих станций (системы такого типа иногда называют COW — Cluster Of Workstations). При этом узлы могут иметь различную архитектуру, производительность, работать под управлением разных OC (MS Windows, Linux, FreeBSD). Если узлы планируется использовать только в составе кластера, то их можно существенно облегчить (отказаться от жёстких дисков, видеокарт, мониторов и т.п.). В облегчённом варианте узлы будут загружаться и управляться через сеть с головной машины. Количество узлов и требуемая пропускная способность сети определяется задачами, которые планируется запускать на кластере.
Для программирования кластеров применяются библиотеки построенные по модели обмена сообщениями. Основным стандартом здесь является MPI : Message Passing Interface [ 5]. На настоящий момент существуют две основные версии этого стандарта: MPI-1 и MPI-2, причем MPI-1 является частным случаем MPI-2. Стандарт MPI-1 описывает статическое распараллеливание, т.е. количество параллельных процессов фиксировано.
Он позволяет описывать обмены типа точка-точка, широковещательные(коллективные) обмены, групповые обмены а также позволяет организовывать топологии взаимодействия процессов. Стандарт MPI-2 помимо функциональности MPI-1 содержит возможность динамического порождения процессов и управления ими.
Разными коллективами разработчиков написано несколько программных пакетов, удовлетворяющих спецификациям MPI (MPICH, MPICH2, LAM, OpenMPI, HPVM, etc.). Существуют стандартные »привязки» MPI к языкам С, С++, Fortran 77/90, а также реализации почти для всех суперкомпьютерных платформ и сетей рабочих станций.
В данной работе для экспериментов был использован кластер на основе сети персональных компьютеров и библиотека MPICH2 [ 6]. Этот пакет можно получить и использовать бесплатно. В состав MPICH2 входит библиотека программирования, загрузчик приложений, утилиты.
- Прежде всего необходимо скачать и установить на все узлы кластера пакет MPICH2. Исходные тексты или уже скомпилированные пакеты под разные платформы можно получить на сайте [ 6]. В данном случае MPICH2 v.1.0.3 собирался из исходных текстов для ОС FreeBSD v.5.3 на процессоре Intel Pentium III. Процесс инсталляции библиотеки описан в MPICH2 Installer’s Guide.
- MPICH2 использует rsh (remote shell). Поэтому необходимо запустить на каждом узле rshd (remote shell server) и согласовать права доступа, т.е. по команде rsh mynode система должна сразу »пускать» вас не спрашивая пароль. Для обеспечения более высокого уровня сетевой безопасности можно использовать ssh — OpenSSH remote login client.
- Компиляция MPI-программы на языке С выполняется утилитой mpicc , представляющей собой надстройку над C-компилятором, установленным в данной ОС. Так же есть аналогичные утилиты для языков С++ — mpiCC и FORTRAN77 — mpif77 .
mpicc myprog.c -o myprog mpiCC myprog.cpp -o myprog mpif77 myprog.f -o myprog
- на головной машине запускаем NFS-сервер и открываем каталог с myprog
- на каждом рабочем узле кластера, монтируем NFS головной машины, используя единый для всех узлов локальный путь.
mpdboot —totalnum=2 —file=hosts.mpd —user=mechanoid —verbose
где hosts.mpd — текстовый файл со списком используемых узлов кластера. Проверка состояния mpd выполняется при помощи mpdtrace :
$ mpdtrace -l node2.home.net_51160 (192.168.0.2) node1.home.net_53057 (192.168.0.1)
Завершение работы mpd выполняется при помощи mpdexit
$ mpdexit node2.home.net_51160
mpiexec -n N myprog
Параллельная программа описывает некоторое количество процессов (веток параллельной программы) и порядок их взаимодействия.
В статической модели стандарта MPI-1 количество таких веток фиксировано и задается при запуске программы.
MPI-программа начинается с вызова функции MPI_INIT() , которая включает процесс в среду MPI, и завершается вызовом функции MPI_FINALIZE() . При запуске каждая ветка параллельной программы получает MPI-идентификатор — ранг, который можно узнать при помощи функции MPI_COMM_RANK() . Для обмена данными между процессами в рамках MPI существует много разных функций: MPI_SEND() — обмен точка-точка, посылка сообщения для одного процесса, MPI_RECV() — обмен точка-точка, прием сообщения, MPI_BCAST() — широковещательная посылка один-всем, MPI_REDUCE() — сбор и обработка данных, посылка все-одному и еще много других.
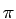
Приведем пример статической MPI-программы вычисления числа как суммы ряда на языке FORTRAN77, текст программы [здесь].
Результаты работы программы, на кластере из двух PC на процессоре Pentium III 700MHz, сеть FAST ETHERNET 100Mbs, размер интервала, на котором считали сумму, равен 10 8
-
один узел, время работы — 47 секунд
$ mpiexec -n 1 ./pi Process 0 of 1 started on node2.home.net pi = 3.1415926
$ time mpiexec -n 2 ./pi Process 0 of 2 started on node2.home.net Process 1 of 2 started on node1.home.net pi = 3.1415926
Теперь займемся динамическим порождением процессов. Стандарт MPI-2 предусматривает механизмы порождения новых ветвей из уже запущенных в процессе выполнения параллельные программы. В MPI-2 это происходит путем запуска файлов программ (аналогично функциям exec() стандарта POSIX.1) с помощью функции MPI_COMM_SPAWN() или MPI_COMM_SPAWN_MULTIPLE() , первая запускает заданное количество копий одной программы, вторая может запускать несколько разных программ.
Запущенные с помощью MPI_COMM_SPAWN процессы не принадлежат группе родителя ( MPI_COMM_WORLD ) и выполняются в отдельной среде. Порожденные процессы имеют свои ранги которые могут совпадать с рангами группы, в которой выполнялся родительский процесс. Обмен сообщениями между процессами родительской и дочерней групп происходит с использованием так называемого интеркоммуникатора, который возвращается процессу-родителю функцией MPI_COMM_SPAWN() . Дочерние процессы могут получить интеркоммуникатор группы родителя с помощью функции MPI_COMM_GET_PARENT() . Значение интеркоммуникатора используется функциями обмена сообщениями MPI_SEND() , MPI_RECV() и другими.
Приведем пример динамической MPI-программы на языке FORTRAN77. Здесь один родительский процесс порождает три дочерних, затем один дочерний процесс посылает остальным дочерним процессам широковещательное сообщение( MPI_BCAST() ), после чего один дочерний процесс посылает сообщение родителю ( MPI_SEND() ) и принимает от него ответ ( MPI_RECV() ). Дочерние процессы запускаются родительским с параметром командной строки » —slave «, текст программы [здесь].
Результат работы программы:
$ mpiexec -n 1 ./spawn master 0 on node2.home.net : start slave 1 on node2.home.net : start slave 0 on node1.home.net : start slave 2 on node1.home.net : start slave 1 on node2.home.net : broadcast from slave 2 slave 0 on node1.home.net : broadcast from slave 2 slave 2 on node1.home.net : broadcast from slave 2 master 0 on node2.home.net : message from slave 2 slave 2 on node1.home.net : message from master 0
2 Основные классы современных параллельных компьютеров — http://parallel.ru/computers/classes.html
5 Message Passing Interface Forum — http://www.mpi-forum.org
Evgeny S. Borisov
2006-03-07
Источник: mechanoid.su
Основы MPI
Прочитал статью «Основы MPI для «чайников»» и понял, что статья новичка способна отпугнуть.
Теория
Начнем с начала
Первое время не было единого стандарта (API) для параллельных вычислений и программистам приходилось писать для каждого кластера архитектурно-специфический код. Но, как известно, программисты люди рациональные и быстро было решено организовать стандарты (самые известные — MPI, OpenMP).
MPI — Message Passing Interface. Это специфический API, который реализуют производители кластеров для того, чтобы можно было легко переносить программы с кластера на кластер не изменяя ни байта исходного кода(!).
Параллельная программа должна эффективно использовать вычислительные мощности и коммуникационную среду. В MPI вся работа по распределению нагрузки на узлы и сеть ложатся на программиста и для максимальной производительности необходимо знать особенности конкретного кластера. MPI очень элегантно решает вопрос топологии сети: имеются понятия коммуникаторов — группы процессов, которые можно пронумеровать в соответствии с топологией сети (для этого используется функция MPI_Cart_create, которая позволяет задать любую топологию от решётки до гиперкуба).
Целесообразность распараллеливания
Некоторые примеры в учебных пособиях весьма синтетические — в них считается какой-нибудь ряд в пределах стандартного типа (например, double), что на практике вычисляется за время много меньшее того, которое тратится на инициализацию и передачу чего-либо по сети (вычисление числа pi в double на двух компьютерах с Gigabit Ethernet примерно в два раза медленнее вычисления на одном компьютере). Однако, MPI позволяет использовать многоядерные процессоры (что почему-то многие забывают), а между ядрами скорость передачи совершенно другого порядка, поэтому всегда нужно знать архитектуру и топологию системы.
Практика
Про теорию можно много писать, но лучше постигать теорию соразмерно с практикой.
Для начала установим какую-нибудь реализацию MPI на свой компьютер. Одной из самых распространённых реализаций MPI является MPICH (MPI Chameleon).
Установка
В убунте устанавливается в одну строчку:
sudo apt-get install mpich2
Напишем простенькую программку, которая ничего полезного не делает:
#include
#include
int main ( int argc, char* argv[])
int errCode;
if (myRank == 0)
printf( «It works!n» );
>
MPI_Finalize();
return 0;
>
* This source code was highlighted with Source Code Highlighter .
Скомпилируем эту программку:
mpicc -o test.bin ./test.c
И (если еще не настроили демон mpd) получим сообщение о том, что демон mpd не запущен.
mpiexec: cannot connect to local mpd (/tmp/mpd2.console_valery); possible causes:
1. no mpd is running on this host
2. an mpd is running but was started without a «console» (-n option)
In case 1, you can start an mpd on this host with:
mpd https://habr.com/ru/articles/121925/» target=»_blank»]habr.com[/mask_link]Матричный метод решения СЛАУ (распараллеливание с MPI)
Алгоритм матричного метода решения СЛАУ подробно описан в теме: Матричный метод решения СЛАУ (распараллеливание с openMP).
Распараллелим этот алгоритм с использованием библиотеки MPI (в отлчии от OpenMP она реализует параллелизм процессов, а не потоков и ориентирована на архитектуру ЭВМ с распределенной памятью (в т.ч. кластерного типа).Программа тестировалась на СЛАУ из 200 уравнений.
В данной лабораторные использовались коллективные функции, такие как MPI_Scatter и MPI_Gather.
Было принято решение распараллелить циклы:
1) Деления элементов строки на элемент, лежащий на главной диагонали.
Исходный код данного распараллеленного цикла представлен в листинге 1.1:
MPI_Scatter(matrix[k], num_iter, MPI_DOUBLE, mini_segmentM, num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Scatter(E[k], num_iter, MPI_DOUBLE, mini_segmentE, num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Bcast( for (int j = 0; j < num_iter; j++) < mini_segmentM[j] /= div; mini_segmentE[j] /= div; >MPI_Gather(mini_segmentM, num_iter, MPI_DOUBLE, matrix[k], num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Gather(mini_segmentE, num_iter, MPI_DOUBLE, E[k], num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD);
Здесь, в первом MPI_Scatter каждому процессу отправляется часть строки матрицы A равной num_iter, в которой необходимо поделить элементы.
Во втором MPI_Scatter каждому процессу отправляется часть строки единичной матрицы E равной num_iter, в которой необходимо поделить элементы.
Сам элемент, который является делителем отправляется всем процессам с помощью MPI_Bcast.
Далее с помощью функций MPI_Gather происходит “сбор” строки обратно в процессе 0.
2) Зануление элементов ниже главной диагонали.
Исходный код данного распараллеленного цикла представлен в листинге 1.2:
if (rank == 0) < for (int i = 0; i < size; i++) < segmentMK[i] = matrix[k][i]; segmentEK[i] = E[k][i]; >> MPI_Bcast(segmentMK, size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Bcast(segmentEK, size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Scatter(matrix, num_iter * size, MPI_DOUBLE, segmentM, num_iter * size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Scatter(E, num_iter * size, MPI_DOUBLE, segmentE, num_iter * size, MPI_DOUBLE, 0, MPI_COMM_WORLD); for (int i = 0; i < num_iter; i++) < if ((rank * num_iter) + i > MPI_Gather(segmentM, size * num_iter, MPI_DOUBLE, matrix, size * num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Gather(segmentE, size * num_iter, MPI_DOUBLE, E, size * num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD);
Здесь в процессе с номером 0 в массивах segmentMK и segmentEK запоминаются строки, которые будут отниматься от строк, лежащих ниже данной (k-ой), матриц A и E соответственно.
Таким образом, данные массивы отправляются всем процессам с помощью функций MPI_Bcast.
С помощью функций MPI_Scatter каждый процесс получает свою часть матриц A и Е.
В цикле с параметром i происходит обход строк полученных матриц. Если строка лежит выше и равна той, которая была отправлена функцией MPI_Bcast, то данная итерация цикла пропускается. Иначе от очередной строки отнимается строка, которая была отправлена функцией MPI_Bcast умноженная на элемент очередной строки, который находится ниже элемента, лежащего на главной диагонали. Таким образом, зануляются элементы, находящиеся ниже элемента, лежащего на главной диагонали, в этом же столбце.
Далее с помощью функций MPI_Gather, в процессе 0 матрицы A и E собираются из частей, которые были изменены в процессах.
3) Зануление элементов выше главной диагонали.
Исходный код данного распараллеленного цикла представлен в листинге 1.3:
for (int k = size — 1; k > 0; k—) < if (rank == 0) < for (int i = 0; i < size; i++) < segmentMK[i] = matrix[k][i]; segmentEK[i] = E[k][i]; >> MPI_Bcast(segmentMK, size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Bcast(segmentEK, size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Scatter(matrix, num_iter * size, MPI_DOUBLE, segmentM, num_iter * size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Scatter(E, num_iter * size, MPI_DOUBLE, segmentE, num_iter * size, MPI_DOUBLE, 0, MPI_COMM_WORLD); for (int i = num_iter — 1; i > -1; i—) < if ((rank * num_iter) + i >= k) continue; multi = segmentM[i][k]; for (int j = 0; j < size; j++) < segmentM[i][j] -= multi * segmentMK[j]; segmentE[i][j] -= multi * segmentEK[j]; >> MPI_Gather(segmentM, size * num_iter, MPI_DOUBLE, matrix, size * num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Gather(segmentE, size * num_iter, MPI_DOUBLE, E, size * num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); >
Здесь происходит “обратный ход”. То есть зануляются элементы выше главной диагонали. В результате прямого хода была получена верхнетреугольная матрица из матрицы A (элементы на главной диагонали равны 1, элементы ниже главной диагонали равны 0).
Ход вычислений тот же, что и в обратном ходе, но проход строк идет снизу вверх.
Таким образом, функциями MPI_Bcast отправляются строки, которые будет отниматься от очередных строк. Функциями MPI_Scatter каждому процессу отправляется своя часть матриц A и E.
После вычислений новая матрица собирается в процессе с номером 0 из частей, с помощью функции MPI_Gather.
4) Вычисление неизвестных переменных X.
Исходный код вычисления неизвестных переменных X представлен в листинге 1.4:
MPI_Bcast(B, size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Scatter(E, num_iter * size, MPI_DOUBLE, segmentE, num_iter * size, MPI_DOUBLE, 0, MPI_COMM_WORLD); // Вычисление X for (int i = 0; i < num_iter; i++) < segmentX[i] = 0; for (int j = 0; j < size; j++) segmentX[i] += segmentE[i][j] * B[j]; >MPI_Gather(segmentX, num_iter, MPI_DOUBLE, X, num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD);
Здесь, с помощью функции MPI_Bcast каждому процессу отправляется матрица-столбец свободных членов B.
Так как в результате элементарных преобразований матрица A трансформировалась в единичную, а матрица E трансформировалась в обратную матрицу A, то с помощью функции MPI_Scatter каждому процессу отправляется своя часть обратной матрицы.
После того как каждый процесс вычислил свою часть неизвестных X, происходит “сбор” частей в одну часть в процессе 0, с помощью функции MPI_Gather.
Тестирование программы:
Для начала программа тестировалась на 5 процессах:
Рисунок 1 – результат выполнения программы на 5 процессах
Позже программа была протестирована на 8 процессах (рис.2), 4х (рис.3) и 2х (рис.4):
Рисунок 2 – результат выполнения программы на 8 процессах
Рисунок 3 – результат выполнения программы на 4 процессах
Рисунок 4 – результат выполнения программы на 2 процессах
Как видно из рисунков 1-4, быстрее всего программа работала на 2х процессах (скорее всего потому, что использовалась на двуядерном процессоре).
Исходный код программы целиком:
#include #include #include #include using namespace std; double random(const int min, const int max) < if (min == max) return min; return min + rand() % (max — min); >int main(int argc, char* argv[]) < setlocale(LC_ALL, «RUS»); const int size = 200; int size_proc, rank; MPI_Status status; MPI_Request request; MPI_Init(argv); MPI_Comm_size(MPI_COMM_WORLD, MPI_Comm_rank(MPI_COMM_WORLD, const int num_iter = 100; double matrix[size][size]; double B[size]; double E[size][size]; double segmentM[num_iter][size]; double segmentE[num_iter][size]; double segmentMK[size]; double segmentEK[size]; double mini_segmentM[num_iter]; double mini_segmentE[num_iter]; //Заполнение матрицы A, B и E if (rank == 0) < for (int i = 0; i < size; i++) < for (int j = 0; j < size; j++) < matrix[i][j] = random(0, 100); if (i == j) E[i][j] = 1.0; else E[i][j] = 0.0; >B[i] = random(0, 100); > > // Прямой ход double t = clock(); double div, multi; for (int k = 0; k < size; k++) < if (rank == 0) < if (matrix[k][k] == 0.0) < bool changed = false; for (int i = k + 1; i < size; i++) < if (matrix[i][k] != 0) < swap(matrix[k], matrix[i]); swap(E[k], E[i]); changed = true; break; >> if (!changed) < cout > div = matrix[k][k]; > MPI_Scatter(matrix[k], num_iter, MPI_DOUBLE, mini_segmentM, num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Scatter(E[k], num_iter, MPI_DOUBLE, mini_segmentE, num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Bcast( for (int j = 0; j < num_iter; j++) < mini_segmentM[j] /= div; mini_segmentE[j] /= div; >MPI_Gather(mini_segmentM, num_iter, MPI_DOUBLE, matrix[k], num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Gather(mini_segmentE, num_iter, MPI_DOUBLE, E[k], num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); if (rank == 0) < for (int i = 0; i < size; i++) < segmentMK[i] = matrix[k][i]; segmentEK[i] = E[k][i]; >> MPI_Bcast(segmentMK, size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Bcast(segmentEK, size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Scatter(matrix, num_iter * size, MPI_DOUBLE, segmentM, num_iter * size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Scatter(E, num_iter * size, MPI_DOUBLE, segmentE, num_iter * size, MPI_DOUBLE, 0, MPI_COMM_WORLD); for (int i = 0; i < num_iter; i++) < if ((rank * num_iter) + i > MPI_Gather(segmentM, size * num_iter, MPI_DOUBLE, matrix, size * num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Gather(segmentE, size * num_iter, MPI_DOUBLE, E, size * num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); > //Обратный ход for (int k = size — 1; k > 0; k—) < if (rank == 0) < for (int i = 0; i < size; i++) < segmentMK[i] = matrix[k][i]; segmentEK[i] = E[k][i]; >> MPI_Bcast(segmentMK, size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Bcast(segmentEK, size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Scatter(matrix, num_iter * size, MPI_DOUBLE, segmentM, num_iter * size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Scatter(E, num_iter * size, MPI_DOUBLE, segmentE, num_iter * size, MPI_DOUBLE, 0, MPI_COMM_WORLD); for (int i = num_iter — 1; i > -1; i—) < if ((rank * num_iter) + i >= k) continue; multi = segmentM[i][k]; for (int j = 0; j < size; j++) < segmentM[i][j] -= multi * segmentMK[j]; segmentE[i][j] -= multi * segmentEK[j]; >> MPI_Gather(segmentM, size * num_iter, MPI_DOUBLE, matrix, size * num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Gather(segmentE, size * num_iter, MPI_DOUBLE, E, size * num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); > /*if (rank == 0) < for (int i = 0; i < size; i++) < for (int j = 0; j < size; j++) cout >*/ double X[size]; double segmentX[num_iter]; MPI_Bcast(B, size, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Scatter(E, num_iter * size, MPI_DOUBLE, segmentE, num_iter * size, MPI_DOUBLE, 0, MPI_COMM_WORLD); // Вычисление X for (int i = 0; i < num_iter; i++) < segmentX[i] = 0; for (int j = 0; j < size; j++) segmentX[i] += segmentE[i][j] * B[j]; >MPI_Gather(segmentX, num_iter, MPI_DOUBLE, X, num_iter, MPI_DOUBLE, 0, MPI_COMM_WORLD); /*if (rank == 0) < for (int i = 0; i < size; i++) < for (int j = 0; j < size; j++) cout >*/ if (rank == 0) < cout MPI_Finalize(); return 0; >
sfdsfgadgsdfghsdfh
День добрый. Компилирую так «mpicxx -o prog mpi.cpp» запускаю так «mpirun -np 5 ./prog» в итоге выводит это »
= BAD TERMINATION OF ONE OF YOUR APPLICATION PROCESSES
= EXIT CODE: 139
= CLEANING UP REMAINING PROCESSES
= YOU CAN IGNORE THE BELOW CLEANUP MESSAGES»
Как решить проблему?
[doublepost=1515153742,1515152654][/doublepost]Решил проблему указав 6 уравнений (const int size = 6 и (const int num_iter = 3, но в итоге я не понял, какую роль несёт параметр num_iter, то есть как правильно подбирать под количество уравненийИсточник: codeby.net