
Следующие издания опубликованы учебным отделом SPSS. Стоимость каждой из них (была когда-то) 99 долларов США:
- Introduction to Syntax Using SPSS (Введение в синтаксис SPSS)
- Programming with SPSS Syntax NEW>SYNTAX (это откроет новое окно синтаксиса)
- Проверьте лог (журнал) в окне результатов, он должен содержать запись GET FILE=’C:Program FilesSPSSEmployee data.sav’ . (Разумеется, конкретные пути в вашей системе могут быть другими). Если журнал не ведётся, обратитесь к совету Ведите журнал! за инструкциями.
- Дважды щёлкните мышью на записи журнала в окне результатов (в правой части этого окна), скопируйте в буфер обмена команду GET FILE .
- Вставьте её в редактор синтаксиса.
- Выберите меню ANALYZE>DESCRIPTIVE>FREQUENCIES , поместите переменную jobcat в список Variable(s) .
- Щёлкните на кнопку Paste . Соответствующая команда появится в окне синтаксиса.
- Сохраните файл синтаксиса (используя меню окна синтаксиса): FILE>SAVE (или используйте сочетание клавиш Ctrl-S )
- документирование (синтаксис сам собой говорит, что было сделано, каким путём вы добились тех или иных результатов)
- воспроизводимость результатов (это следствие предыдущего: попробуйте переделать час работы через меню!)
- пакетная обработка (для затратных по времени и ресурсам задач синтаксис можно запустить на выполнения в то время, когда система более производительна)
- открывает дверь в мир макросов (ведь для работы с макросами надо сначала познакомиться с синтаксисом)
- позволяет пользоваться всеми возможностями SPSS (некоторые возможности доступны только через синтаксис)
- эффективный метод коммуникации в профессиональном сообществе (В списке рассылки SPSSX-L и новостных группах синтаксис используется как в вопросах, так и в ответах. Ответы в виде синтаксиса понятны людям, использующим локализованные версии SPSS).
- Удалим незначащие головные нули (или любые другие символы)
- Заменим точки на запятые (или любой символ «x» на символ «y»)
- Удалим «/» и всё, что левее. (или любые другие… понимаете, о чём я?)
- Удалим»/» и всё, что правее
- Объединим строки str1 и str2
- Создаём переменную формата даты из числовой, такой как 19901204 (см. п. 6 для обратной операции)
- Создаём переменную формата даты из 3 числовых переменных, содержащих день, месяц и год
- Переводим строчную переменную в формат даты (см. также п. 7)
- Рассчитываем возраст
- Наращиваем дату на 1 день
- Создаём числовую переменную, такую как 19901204, из даты
- Создаём строковую переменную, такую как 19901204, из даты
- Имя переменной должно начинаться с буквы, иметь длину не более 64 символов, не содержать пробелы, подробнее см. здесь;
- Тип:
- Ширина задает количество символов в столбце, содержащем данную переменную;
- Десятичные определяет количество десятичных знаков;
- Метка задает метку переменной длиной до 256 символов;
- Значения устанавливает соответствие числовых значений и категорий; например, 1 для мужчин и 2 для женщин;
- Пропущенные – указывает, как обращаться с пропущенными значениями;
- Ширина столбца определяет количество символов, выделенное для переменной в окне представления данных;
- Выравнивание – определяет, как будут выровнены данные в ячейке (влево, вправо, по центру);
- Мера – определяет шкалу измерения, которая лучше всего описывает переменную (номинальная, порядковая или интервальная);
- Роль – определяет роль, которую играет переменная в анализе (входная, целевая и т.д.).
- убедитесь, что файл, который вы хотите напечатать, находится в активном окне;
- кликните Файл –>Печать;
- откроется диалоговое окно печати (рис. 17);
- выберите, что вы хотите распечатать: файл целиком или выделенный фрагмент (если предварительно фрагмент не был выбран, эта опция неактивна); нажмите Ok.
- кликните Файл –>Сохранить;
- задайте имя для окна вывода и папку;
- нажмите Ok; вывод сохранится в файле с расширением *.spo.
Для подробного описания того, как пользоваться окном синтаксиса, журналом SPSS, записываемым в отдельный файл и выводимым в окно результатов, см. страницу Syntax Editor Window на веб-сайте Центрального университета Мичигана
Работа с SPSS
GET FILE=’C:program filesspssemployee data.sav’. FREQUENCIES VARIABLES=jobcat /ORDER= ANALYSIS.
Полезность синтаксиса сложно переоценить. Чем больше вы используете SPSS, тем чаще синтаксис будет заменять работу с меню.
Допустим, некая Мария Геннадьевна копается с меню чтобы осуществить кое-какие преобразования с данными по объёмам продаж, добавить метки переменных и значений и произвести примерно 50 различных процедур обработки. После того, как она закончит с этой работой, сценарии развития ситуации могут быть такими, например:
a) Начальник Марии Геннадьевны сочтёт результаты столь интересными, что…
— попросит проделать такой же анализ, но по отдельным филиалам
— прикажет отныне проводить такой анализ еженедельно
b) данные по продажам за некоторые периоды были пропущены (или неправильно введены), и теперь надо переделать анализ.
Если все свои операции до этого Мария Геннадьевна сохранила в файле синтаксиса, ей потребуется на переделку примерно 2-3% от того времени, которое она затратила бы, переделывая анализ «вручную» (пользуясь меню). Очевидно, таким образом, что синтаксис ведёт к громадному увеличению производительности и экономии времени.
Даже если Мария Геннадьевна и не сохранила всё в файл синтаксиса, она может этот синтаксис восстановить из отдельно ведущегося файла журнала. См страницу Syntax Editor Window на веб-сайте Центрального университета Мичигана, если не знаете, как это сделать.
Прочие преимущества использования файлов синтаксиса:
Список рассылки SPSSX-L
Разумеется, хороший способ изучения синтаксиса — посмотреть на уже готовые решения. Просматривайте их, даже если они не кажутся вам полезными в настоящее время.
Ввод данных в SPSS ч 1
Упражнения
Манипуляция строками (см. также Поэлементный разбор и маркировка данных)
Разберём здесь синтаксис Упражнение по преобразованию строк.SPS. Выполним последовательно следующие операции:
* Упражнение по преобразованию строк. * Замена / удаление определённых символов в строках, объединение строк. * Raynald Levesque.
Сначала создадим пример набора данных.
DATA LIST FIXED /name 1-25 (A). BEGIN DATA 000John Doe /10.14.12 0Mary Poppins /17.21 Billy Joe /21.25 000000Peter Pan /10.35 END DATA. LIST.
При выполнении команды DATA LIST SPSS сообщает, что:
Data List will read 1 records from the command file
Система также выводит информацию о координатах начала и окончания данных, относимых к каждой из читаемых переменных:
Variable Rec Start End Format
name 1 1 25 A25
Результат выполнения команды LIST :
name 000John Doe /10.14.12 0Mary Poppins /17.21 Billy Joe /21.25 000000Peter Pan /10.35 Number of cases read: 4 Number of cases listed: 4
Определим имена и метки переменных, которые будут содержать «исправленные» строки:
STRING name1 TO name4 (A25). VARIABLE LABELS name ‘Исходное значение’ name1 ‘Без головных нулей’ name2 ‘Замена . на ,’ name3 ‘Удалено все до «/» включительно’ name4 ‘Удалено все после «/» включительно’.
1. Удаляем ведущие нули
COMPUTE name1=LTRIM(name,»0″). LIST name name1.
name name1 000John Doe /10.14.12 John Doe /10.14.12 0Mary Poppins /17.21 Mary Poppins /17.21 Billy Joe /21.25 Billy Joe /21.25 000000Peter Pan /10.35 Peter Pan /10.35 Number of cases read: 4 Number of cases listed: 4
2. Заменим точки «.» на запятые «,»
Цикл LOOP позволяет, оставаясь на текущем наблюдении, необходимое число раз проверить наличие оставшихся точек в строке, заменяя очередную найденную точку на запятую. Цикл прекращается после того, как функция INDEX не найдет больше точек в строке. После этого SPSS переходит к обработке следующего наблюдения. Знак «-» обеспечивает работоспособность кода в случае использования команды INCLUDE .
COMPUTE name2=name1. LOOP IF INDEX(name2,».»)>0. — COMPUTE SUBSTR(name2,INDEX(name2,».»),1)=»,». END LOOP. LIST name1 name2.
name1 name2 John Doe /10.14.12 John Doe /10,14,12 Mary Poppins /17.21 Mary Poppins /17,21 Billy Joe /21.25 Billy Joe /21,25 Peter Pan /10.35 Peter Pan /10,35 Number of cases read: 4 Number of cases listed: 4
Это выглядит довольно просто. Три строчки кода и все точки (или другие символы) заменены. Но захотите ли вы использовать такое же решение для замены точек в 400 переменных? См. решение в Упражнениях по макросам.
3. Удаляем «/» и всё, что левее
COMPUTE name3=SUBSTR(name1,INDEX(name1,»/»)+1). LIST name1 name3.
name1 name3 John Doe /10.14.12 10.14.12 Mary Poppins /17.21 17.21 Billy Joe /21.25 21.25 Peter Pan /10.35 10.35 Number of cases read: 4 Number of cases listed: 4
4. Удаляем «/» и всё, что правее
COMPUTE name4=SUBSTR(name1,1,INDEX(name1,»/»)-1). LIST name1 name4.
name1 name4 John Doe /10.14.12 John Doe Mary Poppins /17.21 Mary Poppins Billy Joe /21.25 Billy Joe Peter Pan /10.35 Peter Pan Number of cases read: 4 Number of cases listed: 4
5. Объединяем строки str1 и str2
STRING str1 str2 str3 str4 (A2). COMPUTE str1=»A».
COMPUTE str2=»B».
Обратите внимание, это бы НЕ сработало:
COMPUTE str3=CONCAT(str1,str2).
Это бы не сработало, поскольку, фактически, str1 равно A с пробелом справа. Аналогично, str2 равна B с пробелом справа.
Поэтому CONCAT(str1, str2) даст строку из 4 символов «A B » , которая усечётся до 2 символов «A » чтобы «влезть» в двухсимвольный формат переменной str3 , заданный выше.
А это БУДЕТ работать:
COMPUTE str4=CONCAT(RTRIM(str1),str2). LIST str1 str2 str3 str4.
str1 str2 str3 str4 A B A AB A B A AB A B A AB A B A AB Number of cases read: 4 Number of cases listed: 4
Упражнения на работу с датами, временем и возрастом
Последовательно проделаем следующие манипуляции:
NB! Цель этих примеров — помочь вам понять, как это всё делается, а не написать наиболее короткий и «красивый» код.
1. Создаём переменную формата даты из числовой, такой как 19901204
DATA LIST LIST /date1. BEGIN DATA 19901204 20000131 END DATA. LIST. COMPUTE day1=MOD(date1,100). COMPUTE month1=MOD(TRUNC(date1/100),100).
COMPUTE year1=TRUNC(date1/10000). COMPUTE date2=DATE.DMY(day1,month1,year1). FORMATS date2(SDATE10). VARIABLE WIDTH date2(11). EXECUTE.
2. Создаём переменную формата даты из 3 числовых переменных, содержащих день, месяц и год
DATA LIST LIST /year1 month1 day1.
BEGIN DATA 1999 12 07 2000 10 18 2000 07 10 2001 02 02 END DATA. LIST. COMPUTE mydate=DATE.DMY(day1,month1,year1). FORMATS mydate(DATE11). VARIABLE WIDTH mydate(11).
EXECUTE.
Для разнообразия приведём пример другого формата даты:
COMPUTE mydate2=mydate. FORMATS mydate2(ADATE11). VARIABLE WIDTH mydate2(11). EXECUTE.
3. Переводим строчную переменную в формат даты
DATA LIST LIST /datestr(A10).
BEGIN DATA 11/26/1966 01/15/1981 END DATA. LIST.
Метод 1 (общий)
COMPUTE mth=NUMBER(SUBSTR(datestr,1,2),F8.0). COMPUTE day=NUMBER(SUBSTR(datestr,4,2),F8.0). COMPUTE yr=NUMBER(SUBSTR(datestr,7),F8.0).
COMPUTE mydate=DATE.DMY(day,mth,yr). FORMAT mydate(SDATE11). VARIABLE WIDTH mydate (11). EXECUTE.
Дата в заданной выше переменной записана в виде mm/dd/yyyy (мм/дд/гггг). Этот код будет работать и в случае, если исходный формат будет mm.dd.yyyy или mm-dd-yyyy.
Но не составляет труда сделать определённые модификации, чтобы конвертировать и из таких форматов, как yyyy/mm/dd, dd/mm/yyyy.
Метод 2
Он сработает лишь если формат записи даты в строчной переменной соответствует формату даты в SPSS. Тогда мы просто преобразовываем с помощью функции Number .
COMPUTE mydate=NUMBER(datestr,ADATE10). FORMATS mydate(ADATE10). VARIABLE WIDTH mydate(10).
Цель последней команды отобразить все 4 цифры года в окне редактора данных.
EXECUTE.
4. Рассчитываем возраст
Переменные даты содержат число секунд, прошедших с 14 октября 1582 год. (Эта «странная» дата означает начало григорианского календаря). Внутреннее значение переменной даты одно и то же, независимо от того, какой формат её отображения используется. Например, для переменной, содержащей дату 26.11.1966:
внутр. знач. формат что на экране 12121574400 ADATE11 11/26/1966 12121574400 SDATE11 1966/11/26 12121574400 MOYR8 NOV 1966 12121574400 WKYR8 48 WK 66
COMPUTE agesec=DATE.DMY(1,7,2001) — dtbirth.
подсчитает количество секунд между датой рождения (dtbirth) и 1 июля 2001 года.
Чтобы пересчитать это количество в целые года и часть года, разделим это на количество секунд в году:
COMPUTE age1=agesec/(365.25*24*60*60).
В инструкции выше продолжительность года полагается равной 365.25 дням, чтобы учесть високосные года.
Лучшим способом будет сначала конвертировать возраст в дни, а затем разделить их на 365.25:
COMPUTE age2=CTIME.DAYS(DATE.DMY(1,1,2001) — dtbirth)/365.25.
Если вам нужна категориальная переменная (скажем, agegr), такая, что agegr равно 0, если возраст попадает в интервал 0- 4.99, 1, если возраст между 5 и 9.99, и т.д., то делайте следующее:
COMPUTE agegr=TRUNC(age2/5). VALUE LABELS agegr 0 ‘0-4.99’ 1 ‘5-9.99′ 2 ’10-14.99’.
5. Наращиваем дату на 1 день
COMPUTE date1=date1 + 60*60*24.
6. Создаём числовую переменную, такую как 19901204, из даты
COMPUTE numb1=XDATE.YEAR(date1)*10000 + XDATE.MONTH(date1)*100 + XDATE.MDAY(date1).
7. Создаём строковую переменную, такую как 19901204, из даты
* (продолжение примера 6). STRING str1(A8). COMPUTE str1=STRING(numb1,F8.0).
Конвертация (преобразование) строчных переменных в числовые
Следующие ниже примеры взяты из этого файла синтаксиса.
*Пример 1. DATA LIST FIXED /mydata 1-10 (A). BEGIN DATA 6,188 400 12,125.25 END DATA. LIST. COMPUTE nb=NUMBER(mydata,COMMA10). LIST.
* Пример 2. DATA LIST FIXED /mydata 1-10 (A). BEGIN DATA 6188 400 12125.25 END DATA. LIST. COMPUTE nb=NUMBER(mydata,F10). LIST. * Пример 3. DATA LIST FIXED /mydata 1-10 (A). BEGIN DATA 6.188 400 12.125,25 END DATA. LIST. COMPUTE nb=NUMBER(mydata,DOT10). LIST.
* Пример 4. DATA LIST FIXED /mydata 1-10 (A). BEGIN DATA $6,188 $400 $12,125.25 END DATA. LIST. COMPUTE nb=NUMBER(mydata,DOLLAR10). LIST. * Пример 5. DATA LIST FIXED /mydata 1-10 (A). BEGIN DATA 6.188% 400% 12.12525% END DATA. LIST.
COMPUTE nb=NUMBER(mydata,PCT10). LIST. FORMATS nb(PCT10.5). LIST.
Источник: spsstools.net
SPSS Statistics быстрый старт
Основным инструментом анализа и визуализации статистических данных для меня всегда был Excel. Я работаю с ним ежедневно. По нему написал больше всего заметок и прочитал наибольшее число книг. Пожалуй, лучшее сочетание статистики и Excel я нашел в книге Левин. Статистика для менеджеров с использованием Microsoft Excel.
Вторым инструментом, к которому я только прикоснулся, был R (см., например, Алексей Шипунов. Наглядная статистика. Используем R!). А недавно прочитал любопытную книгу Нил Дж. Салкинд. Статистика для тех, кто (думает, что) ненавидит статистику. В ней автор все примеры иллюстрирует в программе SPSS.
Так что я решил попробовать и этот продукт.
На сайте IBM доступна пробная версия, которая будет работать на вашем ПК 14 дней. Регистрируетесь и скачиваете программу SPSS Statistics. При регистрации запомните пароль. Он вам пригодится для входа в программу. После запуска появляется приветственное окно:
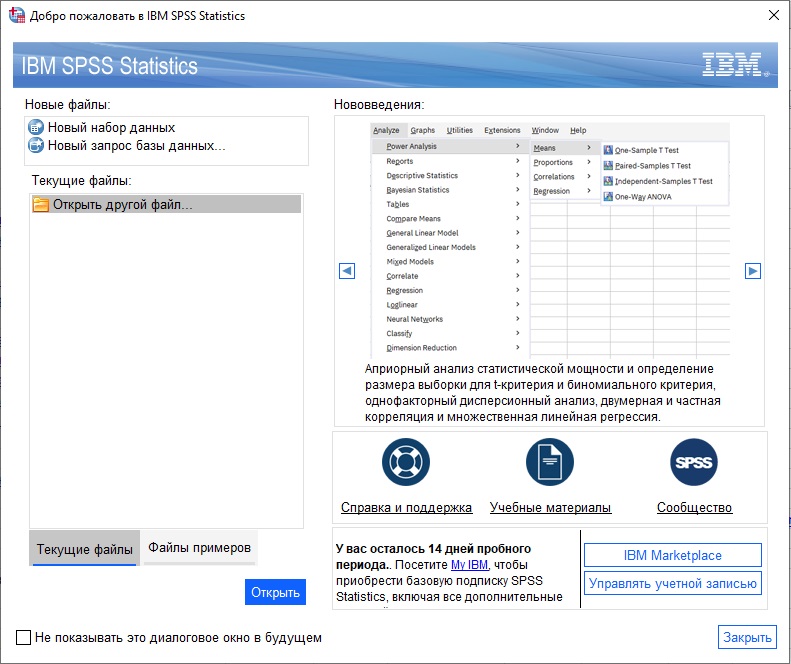
Рис. 1. Приветственное окно SPSS; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Скачать заметку в формате Word или pdf, примеры в формате SPSS
Если вы не хотите видеть этот экран каждый раз при запуске SPSS, то в левом нижнем углу окна кликните Не показывать это диалоговое окно в будущем.
Кликните Закрыть в правом нижнем углу экрана. Появится окно Редактор данных. По виду и функционалу Редактор похож на электронную таблицу, как лист Excel.
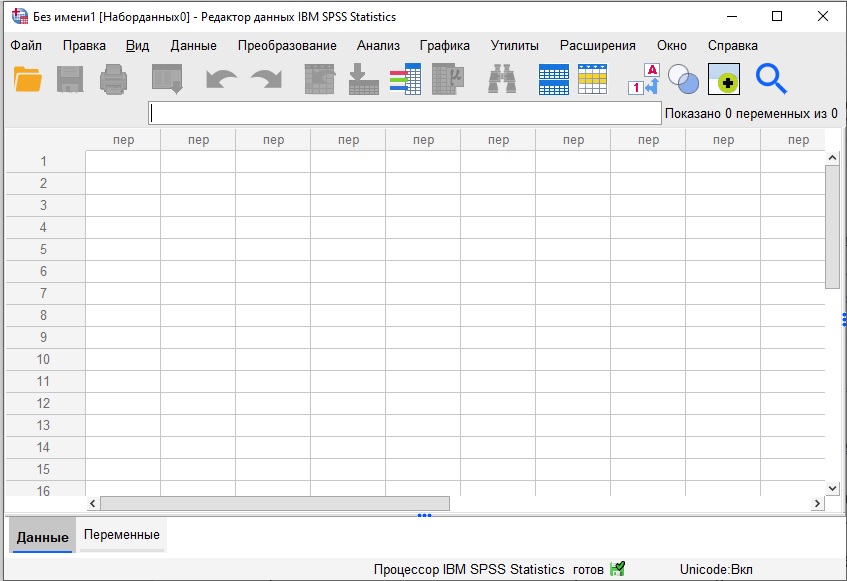
Рис. 2. Редактор данных
Хотя этого и не видно, когда SPSS открывается в первый раз, но есть еще одно открытое (хотя и неактивное) окно. Это Окно вывода (Viewer). Оно показывает создаваемые вами статистические результаты и графики. Набор данных создается при помощи Редактора данных, а после анализа или построения графиков вы изучаете результаты анализа в Окне вывода.
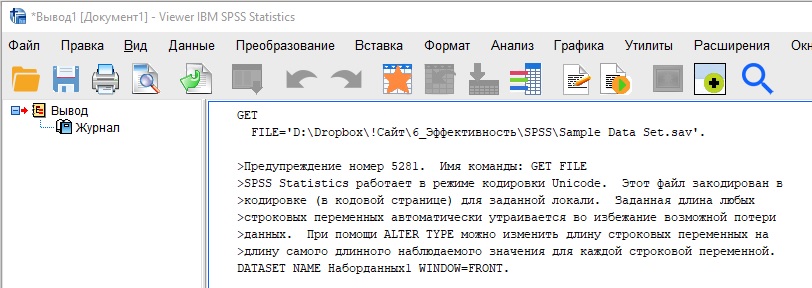
Рис. 3. Окно вывода
Панель инструментов и строка состояния
Если вы хотите узнать, что делает иконка на панели инструментов, просто наведите на нее указатель мыши. Некоторые кнопки на панели инструментов затенены. Это означает, что они не активны.

Рис. 4. Панель инструментов
В нижней части окна расположена Строка состояния. Она показывает, какие действия выполняет SPSS. Например, сообщение «Процессор IBM SPSS Statistics готов» говорит о том, что SPSS готова к вашим указаниям или вводу данных.

Рис. 5. Строка состояния
Использование справки
Справка настолько подробна, что может указать вам путь, даже если вы новичок в работе с программой. Меню Справка содержит 10 разделов.
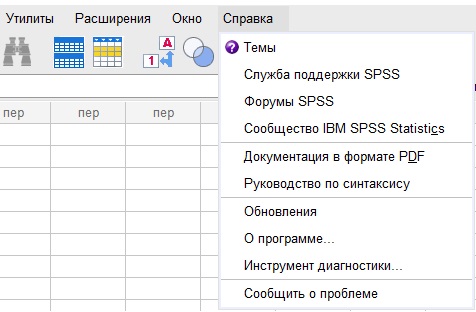
Рис. 6. Меню справки
Нажмите Темы, и перейдете в браузер на страницу центра знаний IBM на русском языке. Здесь представлена собственно справка, а также Учебное пособие, Разбор конкретных случаев, Инструктор по статистике, Разделы для подключаемых модулей Python и R.
Открытие файла
Вы можете импортировать данные из Excel, или ввести значения в таблицу, после чего сохранить в новом файле SPSS, или открыть готовый файл. В этой заметке мы используем файл Sample Data Set.sav. Пройдите по меню Файл –> Открыть –> Данные. Выберите файл. Данные загрузятся в окно редактора:
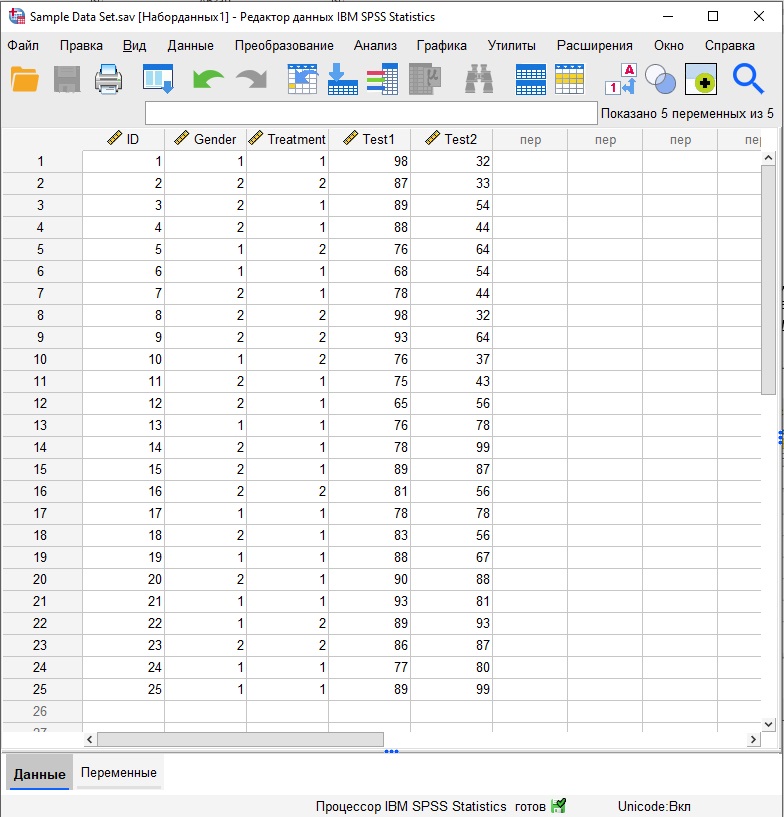
Рис. 7. Данные загружены из файла в окно редактора
Таблица и диаграмма
Допустим, мы хотим посчитать, сколько мужчин и женщин находится в нашей выборке, и вывести результат в виде столбчатой диаграммы. В окне Редактора данных пройдите по меню Анализ –> Описательные статистики –> Частоты. В открывшемся окне Частоты, выберите Gender, нажмите кнопку для переноса переменной в правое окно (или дважды кликните на Gender).
Нажмите копку Диаграммы. Выберите Столбчатые. Нажмите Продолжить. Нажмите Ok.
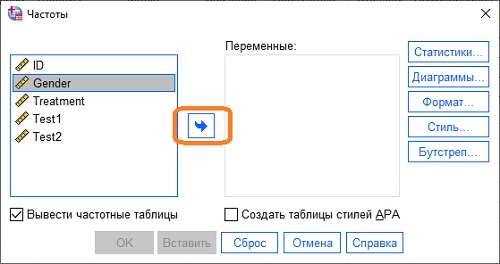
Рис. 8. Выбор переменной для анализа частоты
В окне вывода появится таблица и диаграмма:
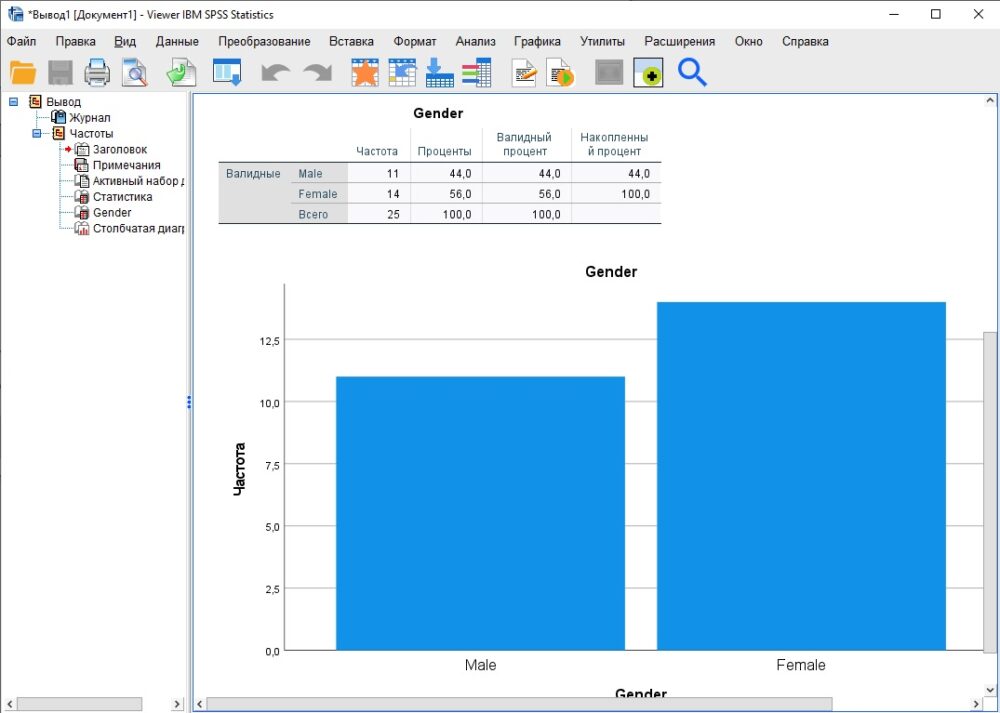
Рис. 9. Таблица и диаграмма в окне вывода
Оценка t-критерия
Давайте проверим, отличаются ли средние значения результатов Test 1 у мужчин и женщин. Этот анализ основан на t-критерии для независимых выборок. В редакторе данных пройдите по меню Анализ –> Сравнение средних –> Т-критерий для независимых выборок. В открывшемся окне переместите переменную Test1 в область Проверяемые параметры, а переменную Gender – в область Группировать по:
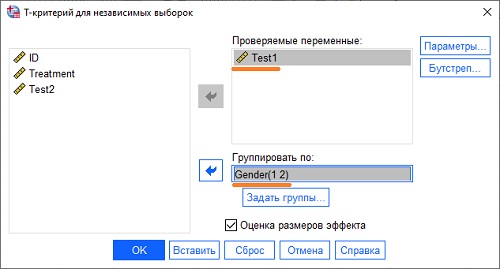
Рис. 10. Настройка расчета t-критерия для независимых выборок
Нажмите Ok. Программа сформирует таблицы проверки по t-критерию, и покажет их в окне вывода:
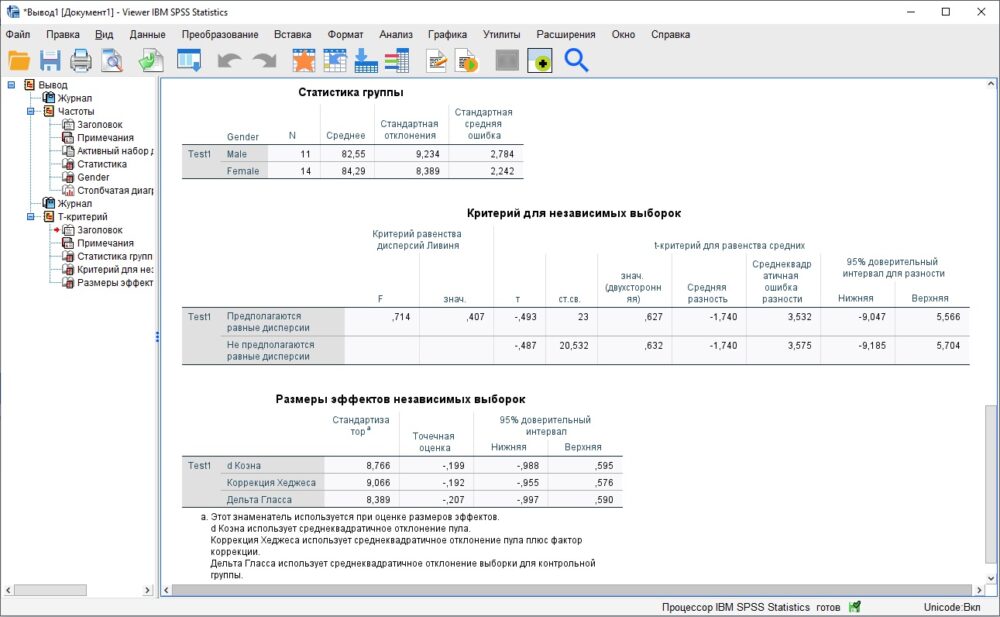
Рис. 11. Результаты проверки t-критерия для независимых выборок
T-тест показал, что различие между мужчинами и женщинами при прохождении Test1 незначимо.
Создание и редактирование файла данных
Давайте создадим набор данных, который только что загрузили из файла Sample Data Set.sav. Сначала определим переменные, а затем введем данные. В окне Редактора данных пройдите по меню Файл –> Создать –> Данные. Откроется новое окно Редактора данных. Обратите внимание, что окно открылось на вкладке Переменные (SPSS подсказывает, что сначала надо заняться ими).
Если вы поместите курсор в первую ячейку в колонке Имя, введёте любое имя и нажмёте Enter, SPSS для всех характеристик переменной автоматически проставит значения по умолчанию (см. строку 1 на рис. ниже).
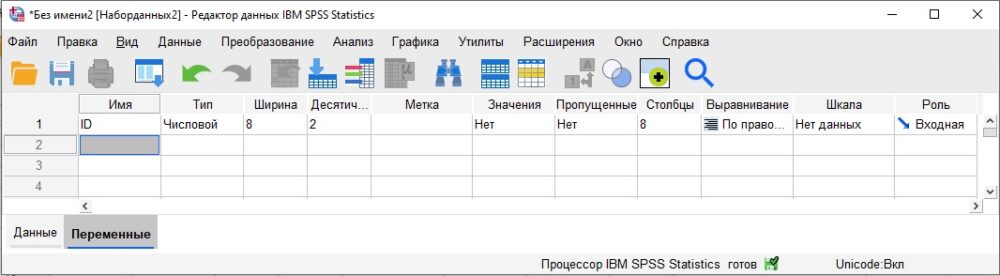
Рис. 12. Параметры по умолчанию
Подробнее о параметрах переменной:
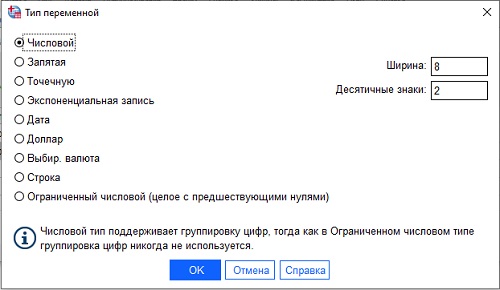
Рис. 13. Типы переменных
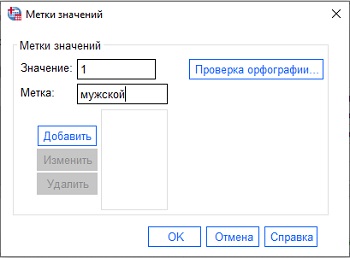
Рис. 14. Введение значений для категорийных переменных
Категорийные переменные в SPSS можно вводить в виде текстовых строк, например, Male и Female, а можно назначить им значения. Когда дело дойдет до анализа, окажется, что очень трудно работать с нечисловыми записями. Но при визуальном просмотре файла, наоборот, имена (метки) нагляднее. Окно Метки значений позволяет вводить в SPSS числа, а выводить на экран метки: и волки сыты, и овцы целы. Чтобы это работало, находясь в Редакторе данных на закладке Данные, перейдите в меню Вид, и поставьте галочку напротив Метки значений.
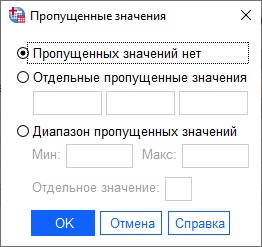
Рис. 15. Управление пропущенными значениями
Определите следующие переменные:
Рис. 16. Пять переменных в окне Редактора данных на закладке Переменные
Теперь вы можете переключиться на вкладку Данные и просто ввести все данные, которые представлены на рис. 7.
Печать из SPSS
Чтобы распечатать весь файл данных или его часть:
Рис. 17. Диалоговое окно печати
Создание диаграммы в SPSS
Воспользуемся данными из файла Sample Data Set.sav. Откройте файл, на вкладке Данные, кликните меню Графика. Выберите одну из опций: Мастер диаграмм, Панель выбора диаграмм, Устаревшие диалоговые окна. Последняя опция позволяет выбрать один из стандартных типов диаграмм. Первые две опции проведут вас по пути создания диаграммы, наиболее подходящей к выбранным данным.
Рис. 18. Типы диаграмм
Выберите Столбцы, откроется диалоговое окно, предлагающее несколько вариантов оформления:

Рис. 19. Виды столбчатой диаграммы
Выберите Простая и Итоги по группам наблюдений. Нажмите Задать. Откроется окно Простые столбцы. Задайте, что будет анализировать диаграмма:
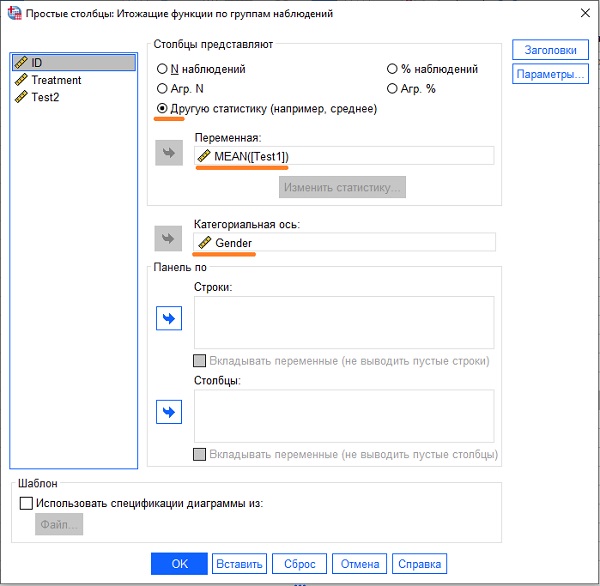
Рис. 20. Параметры аналитики диаграммы
Нажмите Ok. В окне вывода появится диаграмма: среднее значение Test1 раздельно по полу:
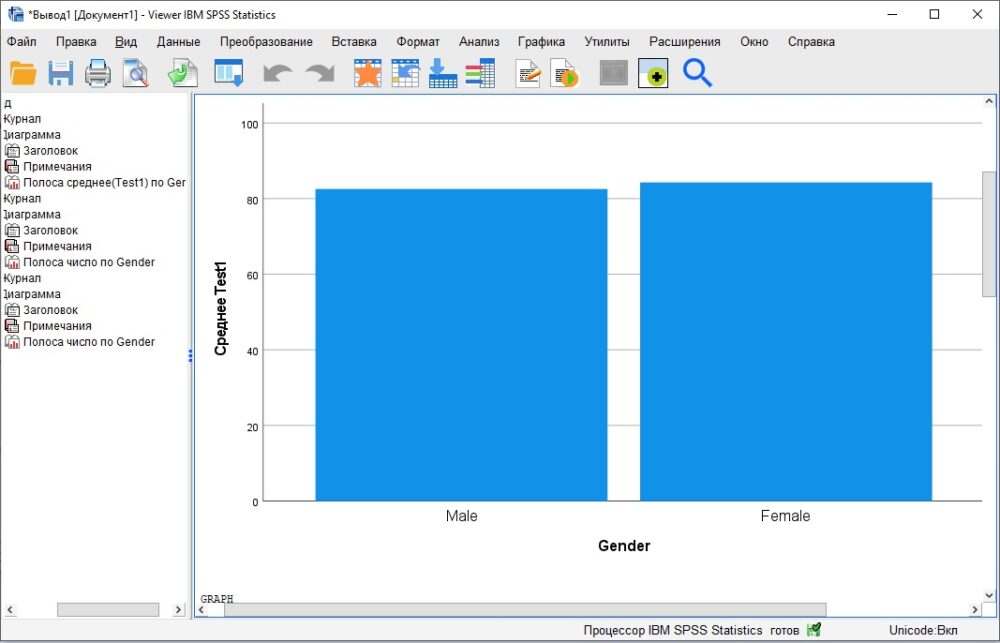
Рис. 21. Средние результаты Теста 1
Сохранение диаграммы
Диаграмма является частью окна вывода. В этом окне сохраняется любой выполняемый вами анализ. Диаграмма не является самостоятельной сущностью, и ее нельзя сохранить в качестве таковой. Для того чтобы сохранить диаграмму, вам нужно сохранить содержимое всего окна вывода. Для этого:
Редактирование диаграммы
Для изменения диаграммы используйте Редактор диаграмм. Чтобы вызвать его дважды кликните на диаграмме в окне вывода.
Чтобы добавить заголовок кликните на соответствующей иконке на панели инструментов Редактора диаграмм:
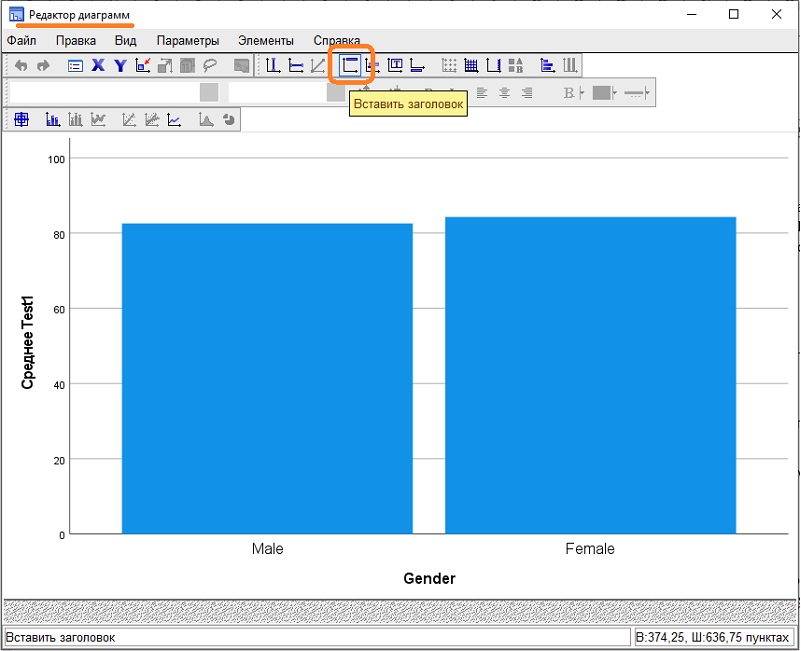
Рис. 22. Кнопка Редактор диаграмм
На диаграмме появится область для ввода заголовка и окно Свойства, где можно выбрать шрифты, границы и заливку. Для добавления подзаголовка (или даже нескольких) кликните на иконке Вставить заголовок повторно.
Для изменения любого элемента дважды щелкните на нем. Можно отдельно щелкнуть на названии оси, подписях и самой оси. В первых двух случаях можно будет отредактировать шрифты и стили оформления, а в последнем – масштаб.
Чтобы выйти из Редактора диаграмм просто кликните на крестике окна или пройдите Файл –> Закрыть.
Описание данных
Частоты и сопряженные таблицы. Частоты подсчитывают количество случаев возникновения определенного значения. Сопряженные таблицы позволяют подсчитать количество случаев возникновения определенного значения с разбивкой по одной или более категориям, например, по полу и возрасту.
Для вычисления частот перейдите в окно Редактора данных, кликните Анализ –> Описательные статистики –> Частоты. Откроется диалоговое окно Частоты (см. выше рис. 8). Дважды щелкните мышью по переменным, для которых вы хотите посчитать частоты. В нашем случае это Test 1 и Test 2:
Рис. 23. Диалоговое окно Частоты
Щелкните по кнопке Статистики. Откроется диалоговое окно Частоты: статистики. В разделе Разброс отметьте Стандартное отклонение. В разделе Положение центра распределения отметьте Среднее:
Рис. 24. Диалоговое окно Частоты: Статистики
Нажмите Продолжить, а затем Ok.
В окне вывода появится три таблицы: обобщенная, и подробная для каждой переменной – Test 1 и Test 2:
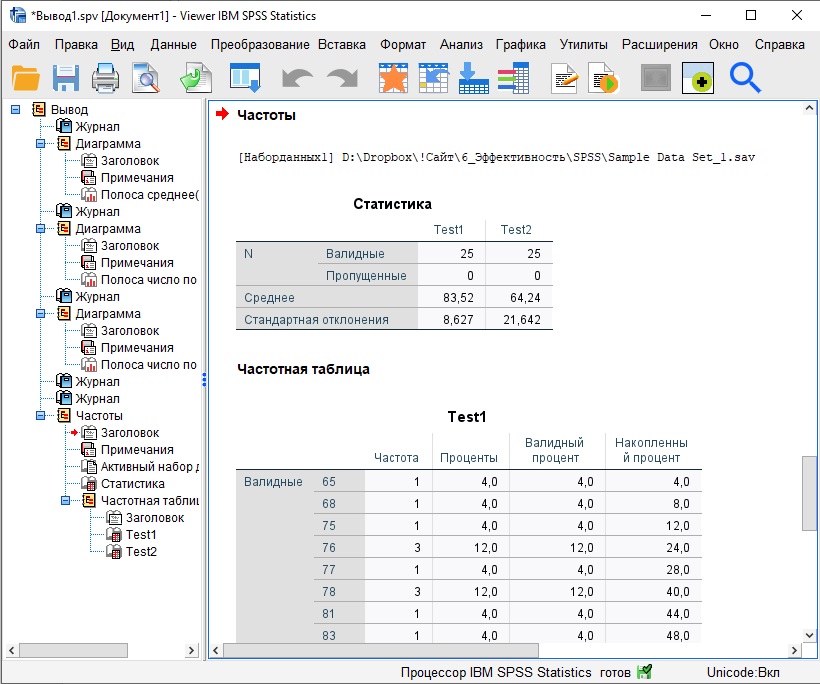
Рис. 25. Обобщенная статистика частот и фрагмент подробной таблицы частот Test 1
Выход из SPSS
Кликните Файл –> Выход. SPSS позаботится о том, чтобы сохранить все не сохраненные ранее или отредактированные окна, а затем закроется.
Только что вы кратко познакомились с SPSS. Однако эти навыки ничего не значат, если вы не понимаете смысла того, что делаете. Так что не восхищайтесь своими или чужими навыками пользования такими программами, как SPSS. Восхищайтесь, когда люди могут рассказать, что означает тот или иной вывод и какой ответ он дает на поставленный вопрос. И особенно восхищайтесь, если вы сами можете это сделать!
Источник: baguzin.ru
Основы работы в SPSS
Прежде чем непосредственно приступать к обработке данных проведенного исследования в программе SPSS, необходимо грамотно организовать ввод данных.
Заведение данных исследования в программу можно условно разделить на 2 основных этапа:
· Подготовка основы анкеты
· Непосредственный ввод данных
Рассмотрим подробнее эти процедуры.
Этап подготовки основы анкеты. В SPSS данные вводятся в определенном формате. Для того чтобы подготовить форму для ввода и дальнейшей обработки данных, нужно изначально ввести шаблон анкеты в приемлемом для программы виде. Общий вид окна программы выглядит, как показано на рисунке 1.
Рис. 1. Общий вид программы SPSS после запуска.
Когда программа запускается первый раз, пользователю предлагается дополнительное диалоговое окно, в котором предлагается осуществить выбор действий, связанных с редактированием существующей базы, открытию существующего файла и т.п. Как правило, в большинстве случаев это окно не несет существенной нагрузки.
По этой причине рекомендуем поставить внизу галочку напротив «Don`t show this dialog in the future». Общий начальный вид программы в принципе стандартен для большинства программ, разработанных под операционную систему Windows. Общая навигационная панель, вид окна и управление окнами практически полностью идентичны большинству программ офисных приложений. По этой причине мы остановимся именно на отличительных особенностях самой программы SPSS.
Рис.2. Рабочее поле программы SPSS.
В программе SPSS существует 2 поля, организованные в виде закладок, аналогичных программе Excel. Вместе с тем эти поля далеко не равнозначны. На рисунке 2 показано рабочее поле программы, в которое пользователь непосредственно вводит данные из анкет (data view). Однако прежде чем осуществлять ввод данных необходимо создать в программе шаблон анкеты, ее основу.
Ввод анкетного шаблона осуществляется в поле определения переменных – Variable View. В SPSS данные вводятся в определенном формате. В SPSS все переменные (при вводе) располагаются вертикально, а горизонтально – наблюдение. Рассмотрим подробнее поле Variable View (рисунок 3).
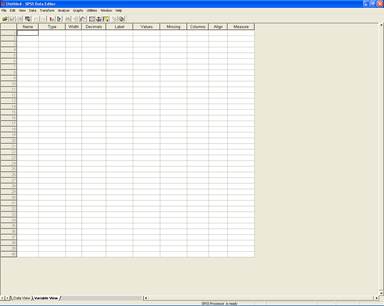
Рис.3. Вид окна переменных.
Каждая переменная – это вопрос в анкете. В программе SPSS по умолчанию установлены 10 основных характеристик, которыми может быть описана переменная: name, type, width, decimals, label, values, missing, columns, align и measure. В принципе, по значимости и важности заполнения эти переменные можно разделить на те, которые относятся к параметрам определения переменной и те, которые отвечают за удобство вывода.
Основные значения параметров переменной:
Name – имя переменной, которое будет отображаться в поле ввода. Это же имя использует программа для идентификации переменной. Имя не должно превышать 8 символов и быть только на английском. (В более поздних версиях программы можно использовать русский текст)
Type – определение типа переменной. Другими словами – какая информация вводится в качестве значений: число, дата, случайное значение, запятая и т.п. Чаще всего используются форматы «числовой» (Nymeric), дата (Date) и строковый (текст, String). В первом случае в качестве значения может приниматься любое число, во втором – дата в определенном формате, в последнем – текст.
Width – длина переменной. Количество разрядов, которые могут уместиться в ячейке.
Decimals – число десятичных разрядов после запятой.
Label – имя, метка, переменной для пользователя, более подробное описание переменной. Обычно формулируется именно как сам вопрос анкеты. Используется в отчетах и позволяет использовать любой шрифт.
Values – метки значений переменной, которые переменная может принимать. В SPSS данные представлены преимущественно в числовом формате, т.к. текстовый формат не поддается статистическому анализу. Например, пол, можно закодировать как 1 – мужской, 0 – женский.
При вводе значений очень важно соблюдать последовательность при определении ранговой шкалы – значения должны идти по возрастанию. Чуть ниже будет рассмотрен пример некорректного ввода данных. Для определения метрической шкалы, значения можно не указывать.
Метки значений вводятся в дополнительном окне.
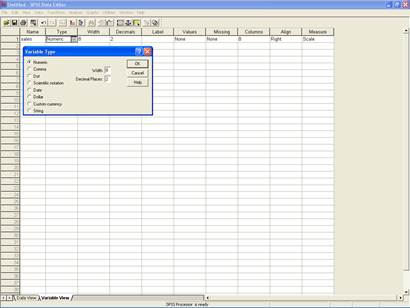
Рис.4. Определение типа переменной.
Missing – определение пропущенных значений. Могут задаваться системой автоматически (System-defined missing values) или пользователем (User-defined missing values).
Columns – определение ширины столбца.
Align – выравнивание в ячейке (левый край, правый, центр).
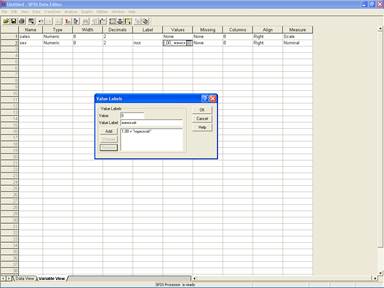
Рис. 5. Определение значения переменной.
Measure – определение шкалы переменной. Scale – число, метрическая шкала; ordinal – ранговая шкала; nominal – номинальная. Чрезвычайно важная характеристика, так как именно от корректного выбора типа шкалы будет зависеть обработка. В программе заложена графическая подсказка – пиктограмма напротив каждого типа шкалы (линейка – как результат измерения – число; возрастающая гистограмма – определение ранга; круги множеств – несравнимые характеристики, обозначающие непересекающиеся множества).
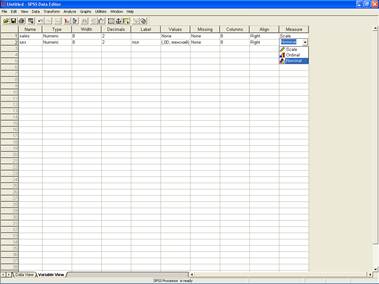
Рис. 6. Выбор типа шкалы в SPSS.
Остановимся на типах измерительных шкал чуть подробнее.
В принципе, сам тип шкалы определяется исследователем уже на этапе поиска эмпирических индикаторов измеряемых признаков во время составления программы социологического исследования. В окончательном виде шкала воплощается непосредственно в вопросе анкеты. Очень важно соблюдать требования, предъявляемые к формулировке альтернативных вариантов. С точки зрения программы SPSS наиболее важное требование – непересекаемость полученных подмножеств, формируемых альтернативными вопросами. В противном случае довольно сложно при обработке данных (точнее при вводе данных) определить именно тот интервал, то подмножество, к которому респондент действительно отнес данный вопрос.
Например, в качестве альтернативных вариантов ответа на вопрос о возрасте могут быть указаны такие интервалы, как до 15 лет, 15-20, 20-25, 25-30, 30 и старше. При такой формулировке возникает проблема в отношении таких результатов, когда респонденту оказывается 15, 20, 25 и 30 лет – т.е. когда он попадает в границу. Респондент может в случайном порядке, на основании каких-то своих предубеждений) отмечать любой интервал — как более высокий, так и более низкий. При обработке данных этот факт способен исказить действительную картину. Если рассматривать общую классификацию шкал, то ее можно представить в виде следующей схемы.
Рис. 7. Классификация шкал.
Пунктиром на рисунке отмечены стрелки, ведущие к интервальной шкале. Дело в том, что интервальная шкала не является в строгом смысле метрической, а относиться к неметрическим. Однако, в некоторых случаях, например, когда интервалы равны, можно осуществлять с ней некоторые математические операции, характерных для метрической шкалы.
С точки зрения проведения исследования и обработки данных очень важно понимать возможности и ограничения применения того или иного типа измерительной шкалы. Важно понимать, что метрические шкалы, в SPSS – тип scale, обладают самой мощной измерительной способностью с точки зрения аналитических возможностей, т.к. к этой шкале могут быть применены практически без ограничений все статистические процедуры. Номинальные (nominal) – напротив, предоставляют самые слабые возможности. По большому счету – это просто частотное распределение и мода, как показатель меры центральной тенденции.
На практике чрезвычайно важно правильно выбирать измерительную шкалу уже на этапе проектирования анкетного опроса. Важно понимать, что чем больше мы хотим получить информации именно поданному типу вопросов, тем больше нужно стремиться к использованию метрической шкалы. Идеальная анкета с точки зрения возможностей ее обработки представляет собой список вопросов, каждый из которых измеряется количественно. С другой стороны – это практически не реализуемо на практике как в силу невозможности «оцифровать» переменные (например, нереально полностью перевести в метрическую шкалу вопрос относительно пола респондента), так и на основе принципов драматургии самого анкетного инструментария – однообразные вопросы снижают мотивацию респондента и надежность получаемых данных.
Возвращаясь к особенностям определения параметров переменной в программе SPSS, можно отметить, что к параметрам, которые в большей степени ответственны за удобство представления информации относятся: columns (ширина столбца), align (выравнивание в ячейке) и в какой-то мере width (длина) и decimals (число десятичных знаков). Эти параметры в большинстве случаев можно просто не изменять, согласившись с предложенными значениями. А вот относительно остальных параметров определения переменных нужно быть аккуратным, так как именно они окажут существенное влияние на процесс ввода и обработки информации.
После определения переменных в программе SPSS можно непосредственно переходить к вводу данных, которые вводятся в поле data view в виде чисел или других символов (в зависимости от типа переменной). В следующем разделе будет рассмотрен подробный алгоритм определения переменных и ввода значений.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник: studopedia.ru