
Статистический графический пакет STATGRAPHICS, разработанный американской корпорацией Manugistics (до 1 мая 1992 года называвшейся Scientific Time Sharing Corp.) для IBM-совместимых компьютеров, по признанию многих авторитетных журналов (Infoworld, Software Digest и др.) является на сегодняшний день одной из наиболее эффективных систем статистического анализа данных. Столь высокую оценку STATGRAPHICS заслужил главным образом благодаря удачному соединению научных методов обработки разнотипных данных с современной интерактивной графикой. Этот альянс подкреплен широкими возможностями взаимодействия с другими программными продуктами (электронными таблицами, базами данных) и периферийными устройствами. Дружественный интерфейс и тщательно отшлифованная документация способствуют быстрому освоению пакета как специалистами в области математической статистики, так и представителями других сфер деятельности (бизнеса, производства, экономики, медицины, химии, биологии, психологии и др.).
В DOS-версию пакета включено более 250 процедур обработки данных по следующим разделам математической статистики:
Statgraphics Centurion Version XVII Overview
- Анализ вариаций (дисперсионный анализ)
- Анализ временных рядов
- Дескриптивная (описательная) статистика
- Контроль качества
- Многомерный анализ
- Непараметрический анализ
- Планирование эксперимента
- Подбор распределений
- Прогнозирование
- Разведочный анализ
- Регрессионный анализ
В России STATGRAPHICS хорошо известен; давно и интенсивно применяется. Пользователи пакета знакомы в основном с его ранними версиями, имевшими свободное распространение. Самая популярная версия 3.0 была создана еще в 1988 году. С тех пор пакет модернизировался почти ежегодно и в более поздних версиях претерпел значительные изменения. Мы пользуемся программой Statgraphics 5.1 portable version.
Эта программа не требует инсталляции, запускается со сменного носителя, причем готовые расчеты (сохраненные файлы) необходимо хранить на том же диске, где находится сама программа. В Statgraphics 5 введены значительные изменения, претерпел раздел планирования эксперимента. Пользователю предоставляется полный каталог стандартных вариантов дробных планов и процедур конструирования поверхностей отклика, а также возможность создавать свои собственные варианты и процедуры. Кроме того, новый редактор позволяет формировать разнообразные рабочие таблицы, распечатывать их и использовать для сбора экспериментальных данных.
Улучшен раздел дисперсионного анализа; процедура многофакторного дисперсионного анализа стала допускать выборочное исключение и добавление взаимодействий любого порядка.
В данной версии пакета полностью была переработана документация. Она включила три основных руководства, дополненных инструкцией по инсталляции и кратким справочником.
Будем решать задачу однофакторного дисперсионного анализа. Для этого открываем Statgraphics 5 нажатием на пиктограмму
Tutorials of Statgraphics

,
После чего открывается окно, изображенное на рис.10, нажимаем на правую кнопку мыши для Col_1 и изменяем столбец. Название данных — data, тип данных- numeric (цифры). Затем точно также настраиваем Col_2 (рис. 11).
После этого вводим данные для однофакторного анализа следующим образом: Вводим в колонку данных сначала количество кинозалов, а в факторы номера фирм, а потом количество кинотеатров и номера фирм, все данные взяты из табл.3 (рис. 12). Далее нажимаем: Compare> Analyze Of Variance>One-Way ANOVA>OK (ANOVA – analyze of variance (дисперсионный анализ)), см. рис.13. Результаты расчета однофакторного дисперсионного анализа для данных табл.3 приведены на этом рис.14. Очевидно, что результаты совпали с ранее полученными.
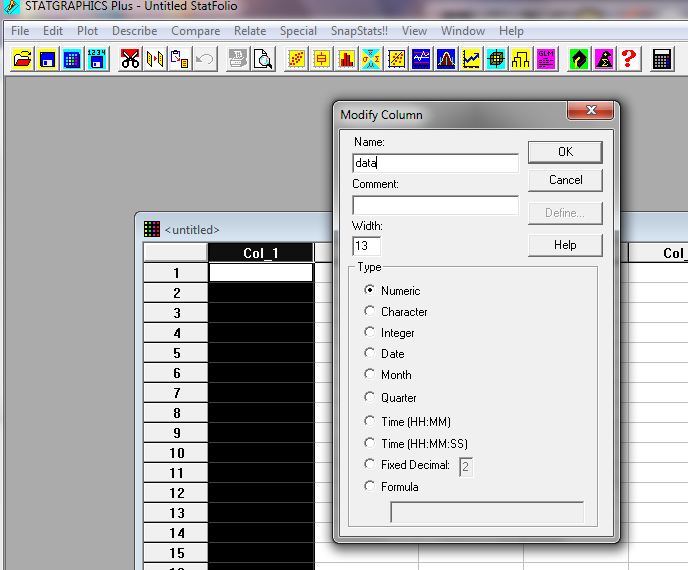
Рис. 10 Окно statgraphics для Col_1

Рис. 10 Окно statgraphics для Col_2

Рис.12 Ввод данных для однофакторного анализа
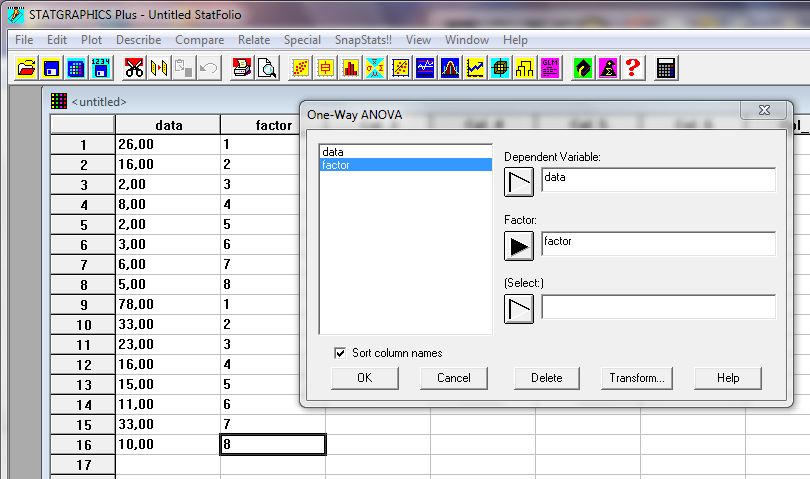
Рис.13 Запуск однофакторного дисперсионного анализа.

Рис. 14. Результаты расчета однофакторного дисперсионного анализа для данных табл.3

Рис.15. Ввод данных для задачи двухфакторного анализа
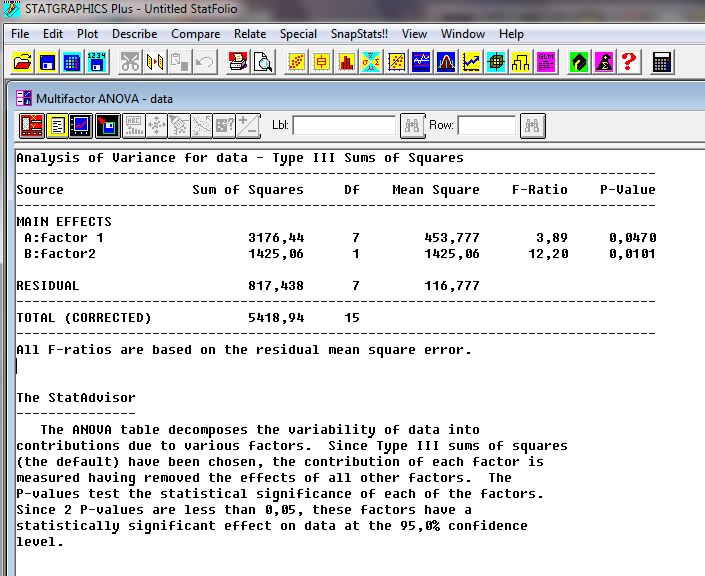
Рис. 16 Решение задачи двухфакторного анализа
На рис. 15 и 16 изображены ввод данных и решение задачи двухфакторного анализа для данных таблицы 3.1. Обратим особое внимание на рис. 15 показано, что номер фактора вводится по матричному принципу: фактор соответствует данным по номеру строки и столбца табл.1.3
В заключение исследуем факторное влияние по статистике цифровых релизов, приведенных в табл.1.4 (данные были заимствованы в НЕВАФИЛЬМ DIGITAL).
Ввод данных и результаты однофакторного и двухфакторного дисперсионного анализа представлены на рис.17-20.
· Гипотеза вторая принимается для однофакторного анализа;
· Гипотеза первая справедлива для двухфакторного анализа по каждому фактору с доверительной вероятностью 0,1.

Рис.17 Ввод данных однофакторного дисперсионного анализа для данных таблицы 1.4

Рис.18 Результаты однофакторного дисперсионного анализа для данных таблицы 1.4

Рис.19 Ввод данных двухфакторного дисперсионного анализа для данных таблицы 1.4

Рис.20 Результаты двухфакторного дисперсионного анализа для данных таблицы 1.4
Дата добавления: 2015-08-21 ; просмотров: 338 | Нарушение авторских прав
Читайте в этой же книге: Дисперсионный анализ | Решение задачи дисперсионного анализа в ППП Excel MS Office 2010 | Предложенная задача продемонстрирована для показа пользования методикой, рассмотрим более развернутую задачу из того же материала |
| | | следующая страница ==> | |
| Двухфакторный дисперсионный анализ | | | Современный кинематограф как плюс и минус для человека |
mybiblioteka.su — 2015-2023 год. (0.008 сек.)
Источник: mybiblioteka.su
Приложение а (справочное) Работа с пакетом statgraphics Plus for Windows
1.2 В разделе «Программы» выбрать «STATGRAPHICS Plus».
1.3. В разделе «STATGRAPHICS Plus» выбрать «Sgwin». Откроется рабочее окно пакета STATGRAPHICS (рисунок А.1).
Рисунок А.1 – Рабочее окно пакета STATGRAPHICS
2 Создание файла выборок значений исследуемых величин
2.1 Для ввода значений элементов выборок развернуть окно исходных данных «untitled» (см. рисунок А.1).
2.2 В столбцах открывшегося окна (рисунок А.2) ввести значения элементов одной или нескольких выборок.
2.3 Для изменения имени и формата значений элементов выборки, принятых по умолчанию, выделить столбец-выборку нажатием левой клавиши мыши на заголовке колонки. Затем нажать правую клавишу мыши и в появившемся всплывающем меню выбрать пункт «Modify Column». В появившемся окне «Modify Column» (см. рисунок А.2) задать новые желаемые значения.
Рисунок А.2 – Ввод исходных данных
2.4 Для записи файла данных на диск, в главном меню выбрать пункт «File»«Save As…»«Save Data File As…». В стандартном диалоговом окне Windows указать каталог и имя создаваемого файла данных. Созданный файл данных получит расширение «sf3» или «sf».
2.5 Пакет STATGRAPHICS позволяет наряду с файлом данных сохранять настройки и результаты анализа данных в файле проекта исследования. Для этого необходимо выбрать в главном меню пункт «File»«Save As…»«Save StatFolio As…». В стандартном диалоговом окне Windows указать каталог и имя создаваемого файла проекта. Созданный файл будет иметь расширение «sfp».
3 Использование существующего файла данных
3.1 Для открытия и использования существующего файла данных в главном меню выбрать раздел «File»«Open»«Open Data File…».
3.2 В стандартном диалоговом окне Windows указать каталог и имя существующего файла данных. При этом данные автоматически будут помещены в окно исходных данных (см. рисунок А.1).
3.3 Если наряду с исходными данными был сохранен файл проекта статистического исследования (файл «sfp»), то вместо пункта «File»«Open»«Open Data File…» следует выбрать пункт «File» «Open» «Open StatFolio…». Файл исходных данных будет открыт при этом автоматически.
4 Вычисление оценок числовых характеристик и построение гистограммы (столбцовой диаграммы) исследуемой случайной величины
4.1 Создать новый или открыть существующий файл исходных данных (элементов выборки исследуемой величины).
4.2 В главном меню выбрать раздел «Describe»«Numeric Data»«One-Variable Analysis» (одномерный анализ).
4.3 В появившемся окне «One-Variable Analysis» (рисунок А.3) выбрать (из списка) для исследования одну из доступных выборок, указав ее имя в поле «Data». Нажать кнопку «OK».
Рисунок А.3 – Окно указания исследуемой выборки (выбора переменной)
4.4 В появившемся окне результатов одномерного анализа (рисунок А.4) нажать кнопку выбора таблиц. В появившемся окне «Tabular Options» выбрать пункт «Summary Statistics» (основные статистики), выделение других пунктов отменить. Нажать кнопку «OK».
4.5 В окне результатов одномерного анализа (см. рисунок А.4) нажать кнопку выбора графиков. В появившемся окне «Graphical Options» выбрать пункт «Frequency Histogram» (частотная гистограмма/столбцовая диаграмма), выделение других пунктов отменить. Нажать кнопку «OK». Окно результатов одномерного анализа примет вид, соответствующий рисунку А.5.
4.6 Для определения оценок числовых характеристик следует на панели «Summary Statistics» нажать правую кнопку мыши и во всплывающем меню выбрать пункт «Pane Options».
4.7 В появившемся окне (рисунок А.6) следует указать интересующие исследователя числовые характеристики. Для оценки всех основных числовых характеристик нажать кнопку «All». Выбор завершить нажатием кнопки «OK», после чего на панели «Summary Statistics» окна результатов одномерного анализа (см. рисунок А.5) «One-Variable Analysis» появятся значения оценок указанных числовых характеристик. Перевод англоязычных статистических терминов представлен в таблице А.1.
Рисунок А.4 – Одномерный анализ данных
Рисунок А.5 – Окно результатов одномерного анализа
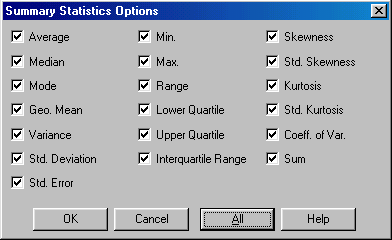
Рисунок А.6 – Окно выбора оцениваемых числовых характеристик
Таблица А.1 – Перевод англоязычных терминов одномерного статистического анализа
Источник: studfile.net
Компонентный анализ в среде StatGraphics
Для проведения расчетов в среде StatGraphics нужно занести данные на электронный лист, например, скопировать через буфер обмена с листа Excel. Лучший вариант – сохранение данных в формате листа Excel ранних версий. Рассмотрим ключевые этапы работы для примера с морфологической изменчивостью гадюк.
Открыть в среде StatGraphics файл следует командой меню или кнопкой Open Data File.
 |
Чтобы имена переменных, назначенных в Excel, автоматически становились именами столбцов, они должны даваться латиницей; в окошке запроса отметить, что имена переменных в первом ряду есть.
 |
Результаты экспорта данных можно посмотреть в окне данных, специально распахнув окно иконки, лежащей на сером поле слева в нижнем углу.
 |
 |
Запустить программу компонентного анализа можно только командой меню Special Multivariate Methods Principal Components.
 |
Выбрав мышкой имена нужных переменных, кнопкой Data: их нужно скопировать в правое окно, ОК. Для дальнейшей идентификации объектов, их метки следует поместить в окно Point Labels:.
 |
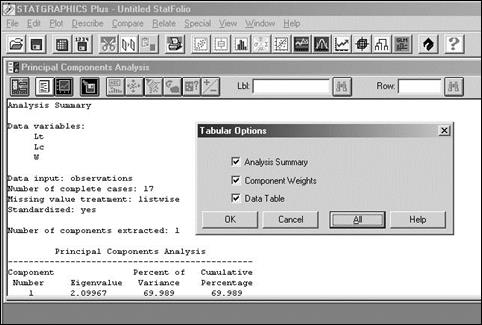
В появившемся окне Principal Component Analysis четыре кнопки играют важную роль. Первая слева кнопка Input Dialog позволяет вернуться на предыдущий шаг и переопределить список анализируемых переменных. Кнопка Tabular Options обеспечивает доступ ко всем результатам анализа (All, OK). Окно Analysis Summary выводит значения дисперсий главных компонент, окно Table of Component Weights дает значения факторных нагрузок, в окно Table of Principal Components выведены значения главных компонент.
Кнопка Graphical Options раскрывает окна с графическими иллюстрациями (All, OK).
 |
 |
Все окно результатов компонентного анализа предстает в виде десяти небольших окошек; распахнуть любое из них позволяет двойной клик левой кнопкой мыши.
 |
Полнота результатов вычислений во многом определяется установками в окне Principal Components Options, которое вызывается командой контекстного меню Analysis options… (правый клик на любом окне анализа). Минимально необходимый объем информации появляется, если в блоке Extract by … Number of Components задать число 2 (т. е. выводить результаты для двух компонент); кроме того, можно задать иное минимальное значение дисперсии главной компоненты (Eigenvalue), чем принятое по умолчанию значение 1. В результате на графиках и в таблицах будут отображаться данные по компонентам, дисперсия которых превышает заданный уровень.
 |
Диаграмма факторных нагрузок (Plot of Component Weights) копирует таблицу Table of Component Weights и призвана наглядно представить степень коррелированности соответствующих признаков.
График Scree Plot отражает изменение дисперсий компонент и (пунктиром) минимальный уровень значимых компонент.

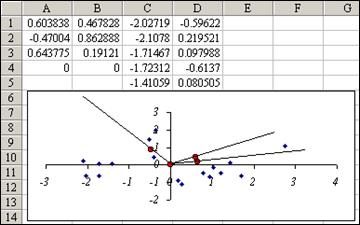
Наиболее интересна диаграмма Scatterplot, где представлена ординация объектов в осях компонент,

а также Biplot, где к диаграмме Scatterplot добавлена диаграмма Plot of Component Weights в форме лучей.

Каждый из этих лучей построен по двум опорным точкам: в месте пересечения осей компонент (0,0) и в точке с координатами факторных нагрузок двух первых компонент (a1j,a2j) (здесь j – номер соответствующего признака). Это возможно потому, что и компоненты, и факторные нагрузки есть безразмерные признаки. Биплот наглядно показывает направления изменчивости данных, за которые ответственны определенные признаки. По промерам гадюк видно, что первое направление изменчивости (выявленное первой главной компонентой) определяет отличие особей по массе (W) и длине тела (Lt), а второе (вторая компонента) связано в основном с отличиями по длине хвоста (Lc).
Результаты расчетов можно поместить на электронный лист (с помощью кнопки Save results, поставив галочки в нужных окошках), через буфер обмена скопировать на лист Excel, и воспользоваться его богатыми графическими возможностями.
 |
 |
В частности, чтобы понять принцип построения биплота, следует объединить (копированием) две точечные диаграммы, построенные раздельно по значениям главных компонент и факторных нагрузок, соединив лучами точки нагрузок с пересечением осей.
 |
10
Имитационное моделирование в среде Excel
Вообще говоря, любая мысль об окружающем мире есть его модель. Имитационная модель – это компьютерная программа, которая служит для количественного отображения поведения реальных объектов в разных условиях. Смысл построения имитационных моделей состоит, во-первых, в том, чтобы установить (выразить уравнением) количественные закономерности протекания явлений природы, во-вторых, – оценить модельные параметры (коэффициентов пропорциональности между переменными уравнений). Параметры моделей часто имеют биологический смысл, поскольку выражают существо отношений между характеристиками объектов исследования.
Моделирование пока не столь широко распространено, как того требуют сложные задачи современной биологии, особенно экологии. На наш взгляд, одним из препятствий этому служит распространенное мнение, что «полноценными» могут быть лишь дающие прогноз аналитические модели; сопряженные с этим сложности построения системы дифференциальных уравнений и их решения оказываются серьезным препятствием для большинства биологов. Однако изучаемые экологические явления сначала нужно понять, дать им объяснение, а уж затем, при необходимости, и прогнозировать.