
В этой статье мы создадим программу, тестирующую скорость набора текста пользователем с помощью базового приложения с графическим интерфейсом пользователя, использующего язык Python. Здесь библиотеки Python, такие как Tkinter и Timeit , используются для графического интерфейса и расчета времени для тестирования скорости соответственно. Кроме того, функция Random используется для выборки случайных слов для расчета проверки скорости. Следующая команда используется для установки вышеупомянутых библиотек:
pip install tkintertable pip установить pytest-timeit
Во-первых, импортируются все библиотеки, которые установлены, как указано выше, и с использованием восходящего подхода создается программа для тестирования скорости набора текста с использованием python.
Below is the implementation.
Источник: progler.ru
Профилирование Python-программ и анализ их производительности
Профилирование — это неотъемлемая часть любых работ по оптимизации кода или производительности программ. Любой опыт, любые знания в сфере оптимизации производительности, которые уже у вас есть, не принесут особой пользы в том случае, если вы не знаете о том, где их применить. В результате оказывается, что поиск узких мест приложений может помочь в деле решения проблем производительности, поможет сделать это быстро и приложив не слишком много усилий.
Как создать программу на Python для проверки скорости набора текста в 6.09.22

В этом материале мы обсудим инструменты и методы работы, которые способны обнаруживать и конкретизировать проблемы с производительностью кода, связанные и с ресурсами процессора, и с потреблением памяти. Здесь же мы поговорим о том, как реализовывать (почти безо всяких усилий) простые механизмы, позволяющие бороться с проблемами производительности. Эти механизмы используются в тех случаях, когда даже точно просчитанные изменения кода больше не позволяют улучшить ситуацию.
Идентификация узких мест
В деле оптимизации производительности программ лениться — это хорошо. Вместо того чтобы пытаться понять то, какая именно часть кодовой базы замедляет приложение, можно просто воспользоваться инструментами профилирования кода. Они позволят найти те места приложения, на которые стоит обратить внимание, такие, которые нуждаются в более глубоком исследовании.
Самый распространённый инструмент, который используют для этих целей Python-разработчики — это cProfile . Это — стандартный модуль, который способен измерять время выполнения функций.
Рассмотрим следующую функцию, которая возводит (медленно) e в степень X :
# some-code.py from decimal import * def exp(x): getcontext().prec += 2 i, lasts, s, fact, num = 0, 0, 1, 1, 1 while s != lasts: lasts = s i += 1 fact *= i num *= x s += num / fact getcontext().prec -= 2 return +s exp(Decimal(3000))
Исследуем этот медленный код с помощью cProfile :
Самый БЫСТРЫЙ стандартный цикл Python − Интеграция с языком Си
python -m cProfile -s cumulative some-code.py 1052 function calls (1023 primitive calls) in 2.765 seconds Ordered by: cumulative timek ncalls tottime percall cumtime percall filename:lineno(function) 5/1 0.000 0.000 2.765 2.765 1 0.000 0.000 2.765 2.765 some-code.py:1() 1 2.764 2.764 2.764 2.764 some-code.py:3(exp) 4/1 0.000 0.000 0.001 0.001 :986(_find_and_load) 4/1 0.000 0.000 0.001 0.001 :956(_find_and_load_unlocked) 4/1 0.000 0.000 0.001 0.001 :650(_load_unlocked) 3/1 0.000 0.000 0.001 0.001 :842(exec_module) 5/1 0.000 0.000 0.001 0.001 :211(_call_with_frames_removed) 1 0.000 0.000 0.001 0.001 decimal.py:2() .
Тут мы воспользовались опцией -s cumulative для сортировки выходных данных по суммарному времени, затраченному на выполнение каждой из функций. Это упрощает поиск проблемных участков кода. Видно, что почти всё время (примерно 2,764 секунды) в ходе одного сеанса выполнения программы было потрачено в функции exp .
Профилирование подобного рода может принести пользу, но его, к сожалению, не всегда достаточно. cProfile снабжает нас информацией лишь о вызовах функций, но не об отдельных строках кода. Если вызвать какую-то особую функцию, вроде append , в разных местах, то сведения обо всех её вызовах будут собраны в одной строке отчёта cProfile . То же самое относится и к скриптам, вроде того, который мы исследовали выше. Он содержит единственную функцию, которая вызывается лишь один раз, в результате у cProfile оказывается не особенно много данных для формирования отчёта.
Иногда такая роскошь, как локальная отладка проблемного кода, программисту не доступна. Или бывает так, что нужно проанализировать проблему с производительностью, что называется, «на лету», когда она возникает в продакшн-окружении. В таких ситуациях можно воспользоваться пакетом py-spy . Это — профилировщик, способный исследовать программы, которые уже запущены. Например — приложения, работающие в продакшне, или на любой удалённой системе:
pip install py-spy python some-code.py PATH=$PATH» py-spy top —pid 1129587
В этом фрагменте кода мы сначала устанавливаем py-spy , а потом, в фоне, запускаем программу, которая выполняется длительное время. Это приводит к автоматическому показу идентификатора процесса (PID), но если мы его не знаем, можно, для его выяснения, воспользоваться командой ps . И, наконец, мы запускаем py-spy в режиме top , передавая ему PID. Это ведёт к выводу данных, очень похожих на те, что выводит Linux-утилита top .

Тут, правда, в нашем распоряжении оказывается не так много данных, так как скрипт представляет собой всего лишь одну функцию, выполняющуюся длительное время. Но в реальных случаях, вероятнее всего, подобный отчёт будет содержать сведения о многих функциях, совместно использующих процессорное время. А это может помочь несколько прояснить ситуацию с существующими проблемами производительности программы.
Более глубокое исследование кода
Профилировщики, о которых мы только что говорили, должны помочь вам в деле обнаружения функций, которые вызывают проблемы, связанные с производительностью. Но если это не приведёт к обнаружению конкретных строк кода, которые надо доработать, это значит, что мы можем обратиться к профилировщикам, которые позволяют исследовать программы на более глубоком уровне.
Первый из таких инструментов представлен пакетом line_profiler . Он, как можно судить по его названию, может использоваться для выяснения того, сколько времени уходит на выполнение каждой конкретной строки кода:
Но даже если построчно проанализировать функцию, первоисточник проблем с производительностью можно и не обнаружить. Например, такое бывает в том случае, если в конструкциях while или if используются условия, составленные из множества выражений. В подобных случаях имеет смысл переписать проблемные фрагменты, разбить одну строку кода на несколько. Это позволит получить более полные и понятные результаты анализа.
Если же вы — по-настоящему ленивый разработчик (как я), и чтение текстового вывода в интерфейсе командной строки — это для вас уже слишком — тогда вот вам ещё один инструмент — pyheat . Это — профилировщик, основанный на pprofile , ещё одном построчном профилировщике, создатели которого черпали вдохновение из кода line_profiler . Этот профилировщик генерирует тепловую карту для строк/областей кода, выполнение которых занимает основную долю времени выполнения программы:
pip install py-heat pyheat some-code.py —out image_file.png
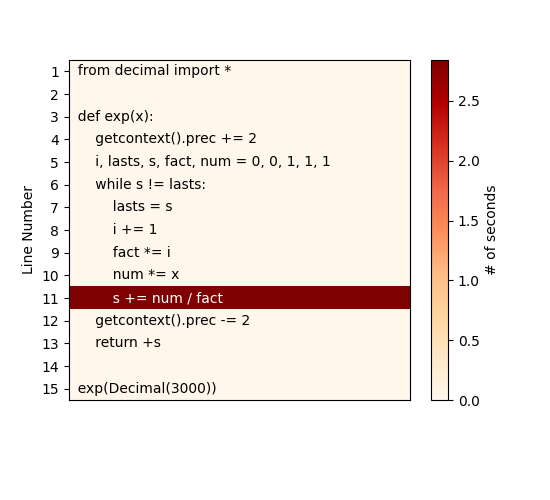
Учитывая простоту кода нашего примера, отчёт, выводимый на экран с помощью kernprof , который мы видели, выглядит достаточно понятным. Но вышеприведённая тепловая карта ещё лучше идентифицирует узкое место нашей функции.
До сих пор мы говорили лишь о профилировании, имеющем отношение к ресурсам процессора. Но то, как программа пользуется CPU, не всегда является тем, что волнует разработчика. Оперативная память — дешёвый ресурс, поэтому программисты обычно не задумываются о её использовании. По крайней мере — до тех пор, пока программа не исчерпает доступную память.
Даже если ваша программа не попала в ситуацию, когда ей не хватает памяти, всё равно, то, как приложение пользуется памятью, стоит исследовать. Сделать это можно для того чтобы узнать, можно ли оптимизировать код с прицелом на экономию памяти, или можно ли дать программе больше памяти ради повышения её производительности. Для анализа использования памяти можно воспользоваться инструментом memory_profiler . Он похож на уже известный вам line_profiler :
Это испытание мы проводим на другом фрагменте кода.
Тут видно, что для обычного списка, содержащего значения None , было выделено более 100 МиБ памяти. Анализируя эти данные, правда, надо учитывать то, что они отражают не реальное использование памяти, а то, сколько памяти было выделено при выполнении каждой из строк функции. В данном случае это значит, что переменные, хранящие списки, на самом деле, не занимают столько памяти. Здесь отражён лишь тот факт, что Python-объекты list , вероятнее всего, выделяют память с запасом, чтобы подстроиться под ожидаемый рост объёма данных, которые могут попасть в список.
Как мы уже видели, Python-списки часто потребляют сотни мегабайт или даже гигабайты памяти. Быстро улучшить ситуацию можно, прибегнув к оптимизации, которая заключается в переходе на обычные объекты array . Они эффективнее хранят данные примитивных типов, вроде int или float . Кроме того, можно ограничить использование памяти, выбирая типы с меньшей точностью, применяя параметр typecode . Воспользуйтесь командой help(array) чтобы посмотреть таблицу, в которой перечислены доступные варианты типов и их требования к памяти.
Если же даже подобные инструменты, дающие точную и детализированную информацию, не позволяют найти узкие места кода, можно попытаться дизассемблировать код и выйти на реальный байт-код, используемый интерпретатором Python. А если и дизассемблирование не помогает решить имеющуюся проблему — тогда полезным может оказаться выяснение и понимание того, какие операции выполняются в недрах Python при вызове некоей функции. Вооружившись знаниями, полученными в ходе таких исследований, в будущем вы сможете писать более производительный код.
Дизассемблированный вариант кода можно сгенерировать, воспользовавшись встроенным модулем dis , передав функцию методу dis.dis(. ) . Он сгенерирует и выведет список инструкций байт-кода, выполняемого при вызове функции.
from math import e def exp(x): return e**x # math.exp(x) import dis dis.dis(exp)
В этом материале мы всё время исследовали очень медленную реализацию возведения e в степень X . Выше же представлена простейшая функция, которая решает эту задачу с высокой скоростью. Теперь мы можем сравнить результаты дизассемблирования быстрой и медленной функций. Результаты их дизассемблирования окажутся совершенно различными. Их изучение делает ещё более очевидным тот факт, что одна функция гораздо медленнее другой.
Вот как выглядит быстрая функция:
2 0 LOAD_GLOBAL 0 (e) 2 LOAD_FAST 0 (x) 4 BINARY_POWER 6 RETURN_VALUE
А вот — наша старая функция, которая работает медленно:
4 0 LOAD_GLOBAL 0 (getcontext) 2 CALL_FUNCTION 0 4 DUP_TOP 6 LOAD_ATTR 1 (prec) 8 LOAD_CONST 1 (2) 10 INPLACE_ADD 12 ROT_TWO 14 STORE_ATTR 1 (prec) 5 16 LOAD_CONST 2 ((0, 0, 1, 1, 1)) 18 UNPACK_SEQUENCE 5 20 STORE_FAST 1 (i) 22 STORE_FAST 2 (lasts) 24 STORE_FAST 3 (s) 26 STORE_FAST 4 (fact) 28 STORE_FAST 5 (num) 6 >> 30 LOAD_FAST 3 (s) 32 LOAD_FAST 2 (lasts) 34 COMPARE_OP 3 (!=) 36 POP_JUMP_IF_FALSE 80 . 100 RETURN_VALUE
Для того чтобы лучше разобраться в том, что именно тут происходит — рекомендую взглянуть на этот ответ со StackOverflow, в котором раскрывается смысл столбцов, по которым распределены эти данные.
Подходы к решению проблем
Тот, кто занимается оптимизацией программы, рано или поздно доведёт её до такого состояния, когда изменения в коде или в алгоритмах начнут давать совсем небольшие улучшения. В этот момент хорошо будет обратить внимание на внешние инструменты, способные дать дополнительный прирост производительности.
Верный способ улучшить скорость работы кода заключается в компиляции его в виде C-программы. Это можно сделать, воспользовавшись различными инструментами. Например — PyPy или Cython. Первый из них — это JIT-компилятор, который можно использовать как непосредственную замену CPython. Он может дать, не требуя никаких усилий от программиста, значительный рост производительности кода.
Его применение вполне может стать достойным решением некоей проблемы с производительностью. Для того чтобы воспользоваться PyPy — достаточно загрузить соответствующий архив, распаковать его и запустить с помощью PyPy свой код:
# Загрузить архив можно с https://www.pypy.org/download.html tar -xjf pypy3.8-v7.3.7-linux64.tar.bz2 cd pypy3.8-v7.3.7-linux64/bin ./pypy some-code.py
Просто чтобы доказать то, что благодаря PyPy можно, не прилагая особых усилий, сразу же улучшить производительность программы, устроим небольшое испытание скрипта, запущенного с помощью CPython и PyPy:
time python some-code.py real 0m2,861s user 0m2,841s sys 0m0,016s time pypy some-code.py real 0m1,450s user 0m1,422s sys 0m0,009s
PyPy, помимо вышеозначенных плюсов, отличается ещё и тем, что для его использования не нужно вносить в код никаких изменений. Он, кроме того, поддерживает все встроенные модули и функции Python.
Всё это звучит просто замечательно, но использование PyPy означает необходимость идти на кое-какие компромиссы. Этот инструмент поддерживает проекты, нуждающиеся в C-привязках, такие, как numpy , но это создаёт значительную дополнительную нагрузку на систему, что сильно замедляет соответствующие библиотеки, сводя на нет другие улучшения производительности. PyPy, кроме того, не решает проблем с производительностью в ситуациях, когда применяются внешние библиотеки, или в случаях, когда речь идёт о работе с базами данных. И, аналогично, если речь идёт о программах, производительность которых привязана к подсистеме ввода/вывода, не стоит ожидать значительной выгоды от применения PyPy.
Если PyPy вам не помогает — можете попробовать Cythoh. Это — компилятор, который использует C-подобные аннотации типов (не подсказки по типам, применяемые в Python) для создания компилируемых модулей расширения Python. Cython, кроме прочего, использует AOT-компиляцию, что может дать значительный прирост производительности благодаря уходу от холодного запуска приложений. Но использование Cython требует переработки существующего кода с использованием особого синтаксиса, что приводит к усложнению программ.
Если вы не против перейти на Python-синтаксис, немного отличающийся от обычного, тогда вам, возможно, интересно будет взглянуть на prometeo — встраиваемый язык, отражающий специфику конкретной предметной области, основанный на Python. Он, в частности, ориентирован на научные вычисления. Программы, написанные на prometeo , транспилируются в чистый C-код. Их производительность сравнима со скоростью работы программ, изначально написанных на C.
Если же ни одно из представленных тут решений не позволит вам выйти на нужный уровень производительности, тогда вам, возможно, стоит писать свой оптимизированный код на C или Fortran, а для вызова этого кода из Python использовать EFI. Среди библиотек, которые способны вам в этом помочь, можно отметить ctypes и cffi для языка C, и f2py для Fortran.
Итоги
Первое правило оптимизации заключается в том, чтобы ничего не оптимизировать. Если же вам действительно это нужно — оптимизируйте то, что имеет смысл оптимизировать. Используйте инструменты для профилирования кода, о которых мы говорили — это позволит вам избежать пустой траты времени на улучшение малозначимых фрагментов программ. Ещё, занимаясь оптимизацией, полезно создавать воспроизводимые тесты производительности для улучшаемого фрагмента кода. Это позволит оценить реальное воздействие оптимизаций на производительность.
Эта статья нацелена на то, чтобы помочь всем желающим в поиске источников проблем с производительностью. Но вот исправление таких проблем — это уже совсем другая история. Кое-какие идеи на эту тему можно найти в одной из моих предыдущих статей, посвящённой методам значительного ускорения Python-кода.
О, а приходите к нам работать?
Профилирование кода Python
Область применения:![]() Visual Studio
Visual Studio![]() Visual Studio для Mac
Visual Studio для Mac ![]() Visual Studio Code
Visual Studio Code
Вы можете профилировать приложение Python при использовании интерпретаторов на основе CPython. (Сведения о доступности этой функции для разных версий Visual Studio см. в разделе Матрица возможностей — профилирование.)
Профилирование для интерпретаторов на основе CPython
Профилирование запускается с помощью команды меню Отладка>Запустить профилирование Python, которая открывает диалоговое окно настройки:

Когда вы нажмете кнопку ОК, запустится профилировщик, в котором откроется отчет о производительности. Из отчета вы узнаете, сколько времени выполнялось ваше приложение:
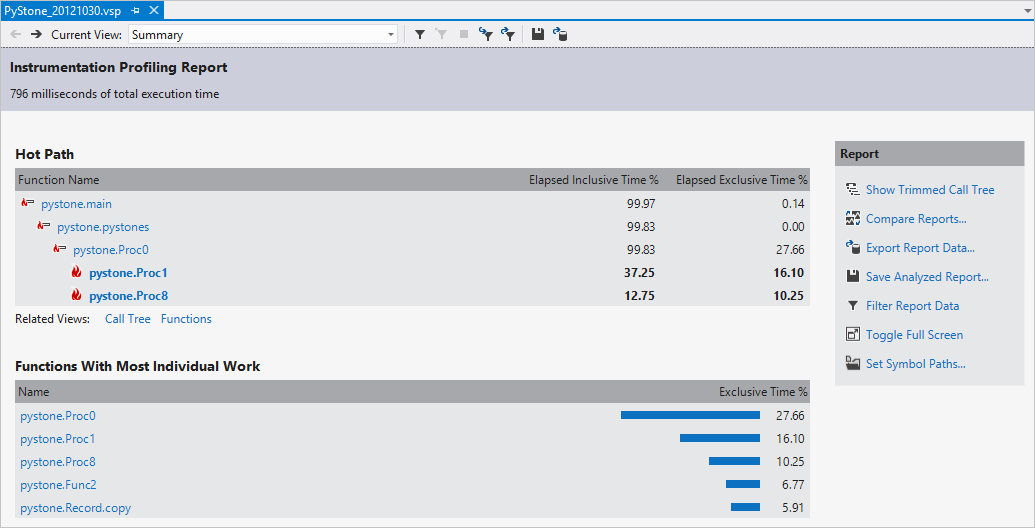

При профилировании приложения Python Visual Studio собирает данные за время существования процесса. Мы хотим получить ваши отзывы о будущих возможностях. Используйте кнопку Отзыв о продукте внизу страницы.
Профилирование для IronPython
Интерпретатор IronPython не основан на CPython, поэтому функция профилирования для него не работает.
Вместо этого используйте профилировщик Visual Studio .NET, запустив ipy.exe непосредственно в качестве целевого приложения с аргументами, чтобы запустить нужный скрипт загрузки. Включите в командную строку параметр -X:Debug , чтобы обеспечить отладку и профилирование для всего кода Python. Этот аргумент создает отчет о производительности, где указывается время, затраченное на выполнение IronPython и основного кода. Для вашего кода используются искаженные имена.
Кроме того, IronPython имеет некоторые встроенные средства профилирования, но пока для них нет хорошего средства визуализации. В разделе о профилировщике IronPython (на сайте блогов MSDN) вы можете узнать, какие средства доступны.
Источник: learn.microsoft.com