
Под динамической загрузкой понимается загрузка подпрограммы в память при первом обращении к ней из пользовательской программы. Это весьма полезный принцип, если требуется сэкономить память , поскольку никакой «лишний» код в этом случае в память не загружается. При статической линковке объем исполняемого кода может оказаться очень большим, именно за счет того, что к файлу бинарного кода добавлен полностью код всех используемых библиотек. При динамической загрузке никакой специальной поддержки от ОС не требуется на этапе разработки программы.
С динамической загрузкой вызываемых подпрограмм тесно связан другой родственный механизм – динамическая линковка: линковка во время исполнения программы. Разумеется, это не означает, что во время выполнения область кода программы расширяется, и к ней добавляется код динамически линкуемой подпрограммы. Используется иная схема.
В коде программы размещается заглушка для исполнения (execution stub) – небольшой фрагмент кода, выполняющий системный вызов модуля ОС, размещающего в памяти код динамически линкуемой библиотечной подпрограммы. При первом вызове заглушка заменяет себя на код обращения по адресу динамически размещенной в памяти подпрограммы. Операционная система при вызове динамически линкуемого модуля должна проверить, размещен ли его код в адресном пространстве процесса . Очевидно, что динамическая линковка наиболее целесообразна для библиотек. Файл бинарного кода динамически линкуемой библиотеки имеет в системе UNIX расширение имени .so ( аббревиатура термина shared object ), в системе Windows – расширение имени .dll (аббревиатура от dynamically linked library ).
Системные прерывания грузят процессор? Разгрузи проц и дай ПК нормально работать!
Возникает, однако, вовсе не философский вопрос: каково должно быть оптимальное соотношение статической и динамической линковки в системе? Следует ли ограничиваться только статической или только динамической загрузкой и линковкой? На наш взгляд, следует соблюдать «золотую середину».
В операционных системах прошлых лет в этом отношении принимались подчас самые экзотические решения. В ОС «Эльбрус», например, разработчики пошли по чересчур радикальному, на наш взгляд, пути – вообще исключили статическую линковку и все независимые программы загружали только динамически (с помощью механизма ПРОГР, который в «Эльбрусе» назывался открытием программы,или динамическим знакомством ). К чему это привело на практике, хорошо помнят мои коллеги из СПбГУ – разработчики математических пакетов прикладных программ , которые мы с ними в 1980-х гг. переносили с ЕС ЭВМ на «Эльбрус». Они быстро освоили новую конструкцию ПРОГР и обращения ко всем независимо компилируемым модулям оформили именно таким образом. В результате очень сильно замедлилось суммарное время выполнения программы. Это и понятно: реализация каждой математической функции как динамически загружаемой программы – слишком «дорогая» операция, требующая вмешательства ОС, по крайней мере, при первом обращении к каждой такой программе, по сравнению с обычным обращением, например, к функции sin как к подпрограмме (процедуре), элементу статически линкуемой библиотеки, обычной машинной командой вызова процедуры.
Программируйте мозг пока Вы спите
Оверлейная структура программы
Как мы уже отмечали во вводных лекциях, в ранних ОС, в особенности – для персональных компьютеров, для пользовательского процесса были вынужденно введены очень жесткие ограничения по памяти, — например, в MS DOS – не более 640 килобайт . При таком дефиците основной памяти, если программа оказывается настолько велика, что полностью не помещается в память максимально разрешенного объема, необходимо предпринимать специальные меры при разработке программы, чтобы разбить ее на непересекающиеся группы модулей, такие. что в каждой группе модули логически взаимосвязаны и должны присутствовать в памяти одновременно, модули же разных групп не обязательно должны вместе загружаться в память . Во время исполнения такой программы должен использоваться специальный системный механизм, называемый оверлейная структура ( overlay ,дословно – наложение ), обеспечивающий поочередную загрузку в одну и ту же область памяти то одной, то другой исполняемой группы модулей. Простая программа , которая выполняет эти действия, называется драйвер оверлея ( overlay driver ).Интегрированная среда разработки Турбо Паскаль обеспечивала специальные опции компилятора, которые позволяли явно указывать модули, входящие в каждый оверлей.
Типичный для ранних компьютеров и ОС пример программы с оверлейной структурой – двухпросмотровый ассемблер . На первом просмотре он преобразует исходный ассемблерный код в промежуточное представление , которое программа второго просмотра ассемблера получает на входе. Полностью весь ассемблер (оба просмотра) в память не помещался, и пришлось применить оверлейную структуру. Данный пример иллюстрируется на рис. 15.3.
Источник: intuit.ru
Загрузка программ. Относительная загрузка.
Существует два основных способа хранения информации в оперативной памяти. Первый заключается в использовании глобальных и локальных переменных. Второй способ, которым С++ может хранить информацию, заключается в использовании системы динамического распределения. При этом способе память распределяется для информации из свободной области памяти по мере необходимости. Область свободной памяти находится между кодом программы с ее постоянной областью памяти и стеком.
Динамическая память – это память, выделяемая программе для ее работы за вычетом сегмента данных, стека, в котором размещаются локальные переменные подпрограмм и собственно тела программы.
Краткие итоги
1. В ходе выполнения программ выделяются статическая и динамическая области
2. Возможны три варианта работы с динамической памятью: указатель определяется как локальный объект автоматической или статической памяти, указатель является глобальным объектом для блока памяти.
3. Доступ к участкам динамической памяти осуществляется через динамические переменные.
4. Работа с динамической памятью начинается с выделения участка памяти, а завершается освобождением ранее выделенного участка.
5. Выделение и освобождение динамической памяти выполняется с помощью операций или функций для работы с динамической памятью.
New и delete используются для выделения и освобождения блоков памяти. Область памяти, в которой размещаются эти блоки, называется свободной памятью.
Операция new позволяет выделить и сделать доступным свободный участок в основной памяти, размеры которого соответствуют типу данных, определяемому именем типа.
new ИмяТипа [Инициализатор];
Синтаксис применения операции:
Указатель = new ИмяТипа [Инициализатор];
Для освобождения выделенного операцией new участка памяти используется операции:
Указатель адресует освобождаемый участок памяти, ранее выделенный с помощью операции new. Например:
2. Распределение памяти. Динамическое выделение памяти. Работа с динамической памятью с помощью библиотечных функций malloc (calloc) и free
Средства для динамического выделения и освобождения памяти описаны в заголовочных файлах malloc.h и stdlib.h стандартной библиотеки (файл malloc.h ).
Функции выделения и освобождения памяти
| Функция | Прототип и краткое описание |
| malloc | void * malloc (unsigned s); возвращает указатель на начало области (блока) динамической памяти длинной в s байт. При неудачном завершении возвращает значение NULL. |
| calloc | void * calloc (unsigned n, unsigned m); возвращает указатель на начало области (блока) обнуленной динамической памяти, выделенной для размещения n элементов по m байт каждый. При неудачном завершении возвращает значение NULL. |
| realloc | void * realloc (void * bl, unsigned ns); изменяет размер блока ранее выделенной динамической памяти до размера ns байт, bl – адрес начала изменяемого блока. Если bl равен NULL (память не выделялась), то функция выполняется как malloc. |
| free | void * free (void * bl); освобождает ранее выделенный участок (блок) динамической памяти, адрес первого байта которого равен значению bl. |
Функции malloc(), calloc() и realloc() динамически выделяют память в соответствии со значениями параметров и возвращают адрес начала выделенного участка памяти. Для универсальности тип возвращаемого значения каждой из этих функций есть void *. Этот указатель можно преобразовать к указателю любого типа с помощью операции явного приведения типа ( тип * ).
Функция free() освобождает память, выделенную перед этим с помощью одной из трех функций malloc(), calloc() или realloc(). Сведения об участке памяти передаются в функцию free() с помощью указателя – параметра типа void *. Преобразование указателя любого типа к типу void * выполняется автоматически, поэтому вместо формального параметра void *bl можно подставить в качестве фактического параметра указатель любого типа без операции явного приведения типов.
3 Динамически загружаемые библиотеки
В довольно ранних версиях операционных систем наряду со статическими библиотеками объектных модулей появились динамически загружаемые библиотеки с расширением .dll (от Dynamic-link libraries). Динамически загружаемые библиотеки Windows могут иметь и другие расширения – .exe или .drv.
Основная разница между статическими и динамическими библиотеками заключается в следующем. Если используется статическая библиотека, то на стадии редактирования связей в состав исполняемого модуля включаются все функции, для которых обнаружено обращение из текста исходной программы. В отличие от этого вызов модуля из динамической библиотеки происходит только на стадии выполнения программы. При таком подходе библиотечные функции не включаются в состав исполняемого модуля, его размеры становятся меньше и, тем самым, экономится место, занимаемое исполняемыми файлами на диске.
У каждого из этих подходов есть свои плюсы и минусы. При использовании статических библиотек размер исполняемого модуля возрастает, т.к. к нему подключаются все функции, упомянутые в программе. Однако такой модуль можно выполнить на любом компьютере независимо от того, установлена ли там соответствующая система программирования или нет.
При использовании динамически загружаемых библиотек размер исполняемого модуля не так велик, но для его работы требуется присутствие в оперативной памяти динамической библиотеки, из которой в случае необходимости потребуется запустить тот или иной модуль. Поэтому при переносе программы на другой компьютер придется кроме исполняемого модуля захватить и всю цепочку задействованных динамических библиотек. Правда, в разумных системах программирования предусмотрен режим компиляции с включением всех вызываемых функций в состав исполняемого модуля.
4 Загрузка программ. Абсолютная загрузка.
Существуют два типа адресов памяти. Адреса первого типа называются виртуальными, или логическими. Это то число, которое вы увидите, если, скажем, распечатаете значение указателя. Говоря точнее, это тот адрес, который видит ваша программа, номер ячейки памяти в ее собственном адресном пространстве.
Адреса другого типа называются физическими. Это тот адрес, который передается по адресным линиям шины процессора, когда этот процессор считывает или записывает данные в ОЗУ.
Вообще говоря, эти два адреса могут не иметь между собой ничего общего. Теоретически, могут существовать адреса физической памяти, которым не соответствует никакой виртуальный адрес ни у какой из программ. Это может просто означать, что в данный момент эта память никем не используется.
Более интересная ситуация — это виртуальные адреса, которым не соответствует никакой физический адрес. Такая ситуация часто возникает в системах, использующих так называемую страничную подкачку (page swapping или просто paging). В этой ситуации сумма объемов адресных пространств всех программ в системе может превышать объем доступной физической памяти, то есть на машине с четырьмя мегабайтами ОЗУ вы можете исполнять программы, требующие 8 и более мегабайт.
Для начала попробуем рассмотреть загрузку программы в виртуальную память. Для простоты мы будем считать, что эта виртуальная память представляет собой непрерывное адресное пространство. Кроме того, будем считать, что программа была заранее собрана в некий единый самодостаточный объект, называемый загрузочным или загружаемым модулем. В ряде операционных систем программа собирается в момент загрузки из большого числа отдельных модулей, содержащих ссылки друг на друга.
Первый, самый простой, вариант состоит в том, что мы всегда будем загружать программу с одного и того же адреса. Это возможно в следующих случаях:
1) система может предоставить каждой программе свое адресное пространство
2)система может исполнять в каждый момент только одну программу
Подобный программный модуль называется абсолютным загрузочным модулем или абсолютной программой.
Абсолютная загрузка используется, например, в системе UNIX на 32-разрядных машинах.
Загрузка программ. Относительная загрузка.
Существуют два типа адресов памяти. Адреса первого типа называются виртуальными, или логическими. Это то число, которое вы увидите, если, скажем, распечатаете значение указателя. Говоря точнее, это тот адрес, который видит ваша программа, номер ячейки памяти в ее собственном адресном пространстве.
Адреса другого типа называются физическими. Это тот адрес, который передается по адресным линиям шины процессора, когда этот процессор считывает или записывает данные в ОЗУ.
Вообще говоря, эти два адреса могут не иметь между собой ничего общего. Теоретически, могут существовать адреса физической памяти, которым не соответствует никакой виртуальный адрес ни у какой из программ. Это может просто означать, что в данный момент эта память никем не используется.
Более интересная ситуация — это виртуальные адреса, которым не соответствует никакой физический адрес. Такая ситуация часто возникает в системах, использующих так называемую страничную подкачку (page swapping или просто paging). В этой ситуации сумма объемов адресных пространств всех программ в системе может превышать объем доступной физической памяти, то есть на машине с четырьмя мегабайтами ОЗУ вы можете исполнять программы, требующие 8 и более мегабайт.
Для начала попробуем рассмотреть загрузку программы в виртуальную память. Для простоты мы будем считать, что эта виртуальная память представляет собой непрерывное адресное пространство. Кроме того, будем считать, что программа была заранее собрана в некий единый самодостаточный объект, называемый загрузочным или загружаемым модулем. В ряде операционных систем программа собирается в момент загрузки из большого числа отдельных модулей, содержащих ссылки друг на друга.
Относительная загрузка
Этот способ загрузки состоит в том, что мы грузим программу каждый раз с нового адреса. Очевидно, что при этом она должна быть настроена на новые адреса. В этом случае весьма существенное значение приобретают используемые в программе способы адресации. Если для адресации операндов используется прямая (абсолютная) адресация, то подобная перенастройка выливается в процесс изменения всех используемых в программе абсолютных адресов. То есть, если мы захотим «сдвинуть» программу по адресам виртуальной памяти так, чтобы она начиналась, скажем, не с адреса 01000, а с адреса 02000, то мы должны будем найти все команды с абсолютными адресными полями и прибавить ко всем этим полям разность нового и старого адресов.
Если же используется относительная (базовая) адресация или ее разновидности, то задача значительно упрощается. В этом случае для перемещения программы нам нужно только изменить значения базовых регистров, и программа даже не узнает, что загружена с другого адреса.
6. Загрузка программ. Позиционно-независимый код
Существуют два типа адресов памяти. Адреса первого типа называются виртуальными, или логическими. Это то число, которое вы увидите, если, скажем, распечатаете значение указателя. Говоря точнее, это тот адрес, который видит ваша программа, номер ячейки памяти в ее собственном адресном пространстве.
Адреса другого типа называются физическими. Это тот адрес, который передается по адресным линиям шины процессора, когда этот процессор считывает или записывает данные в ОЗУ.
Вообще говоря, эти два адреса могут не иметь между собой ничего общего. Теоретически, могут существовать адреса физической памяти, которым не соответствует никакой виртуальный адрес ни у какой из программ. Это может просто означать, что в данный момент эта память никем не используется.
Более интересная ситуация — это виртуальные адреса, которым не соответствует никакой физический адрес. Такая ситуация часто возникает в системах, использующих так называемую страничную подкачку (page swapping или просто paging). В этой ситуации сумма объемов адресных пространств всех программ в системе может превышать объем доступной физической памяти, то есть на машине с четырьмя мегабайтами ОЗУ вы можете исполнять программы, требующие 8 и более мегабайт.
Для начала попробуем рассмотреть загрузку программы в виртуальную память. Для простоты мы будем считать, что эта виртуальная память представляет собой непрерывное адресное пространство. Кроме того, будем считать, что программа была заранее собрана в некий единый самодостаточный объект, называемый загрузочным или загружаемым модулем. В ряде операционных систем программа собирается в момент загрузки из большого числа отдельных модулей, содержащих ссылки друг на друга.
Позиционно-независимый код
Кроме рассмотренных ранее основных способов адресации существует весьма интересная разновидность относительной адресации, когда адрес получается сложением адресного поля команды и адреса самой этой команды — значения счетчика команд. Очевидно, что модуль, в котором используется только такая адресация, можно грузить с любого адреса без всякой перенастройки. Такой код называется позиционно-независимым.
Кроме того, на многих процессорах, например, Intel 8080/8085 или многих современных RISC-процессорах позиционно-независимый код вообще невозможен — эти процессоры не поддерживают соответствующий режим адресации для данных. Возникают серьезные неудобства при сборке программы из нескольких модулей. Поэтому такой стиль программирования используют только в особых случаях. Например, многие вирусы под MS DOS написаны именно таким образом.
Дата добавления: 2018-05-09 ; просмотров: 655 ; Мы поможем в написании вашей работы!
Источник: studopedia.net
Как ваша программа использует память

Программирование на языках, которые позволяют взаимодействовать с памятью на более низком уровне, как например в C и C++, иногда доставляет немало проблем, с которыми вы раньше не сталкивались, например: segfaults(ошибки сегментации). Такие ошибки очень раздражают, и могут стать причиной множества проблем; часто они свидетельствуют о том, что вы используете память, которую не следует использовать.
Одна из самых распространённых проблем — это попытка получить доступ к памяти, которая уже освобождена. Эту память вы могли освободить сами ― функцией free , или её автоматически освободила программа (например, из стека).
Поняв некоторые аспекты, связанные с памятью, вы станете действительно лучше и умнее в программировании!
Как разделена память
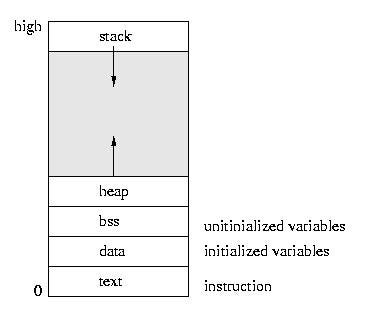
Память разделена на несколько сегментов, два из наиболее важных (для этой статьи) — это стек и heap. Стек — это упорядоченная область внедрения, а heap полностью произвольная ― вы резервируете память там, где это возможно.
Стек память обладает набором средств и операций для собственной работы (это место, где сохраняется информация регистров процессора). Здесь хранится информация, касающаяся работы программы, например о вызванных функциях и созданных переменных и т.д. Этой памятью управляет программа, а не разработчик.
Сегмент heap часто используется для резервирования большого объёма памяти. Этот резерв существует столько, сколько потребуется разработчику. Другими словами, контроль памяти в сегменте heap предоставлен разработчику. Разрабатывая сложные программы, часто приходится резервировать большие части памяти. Именно для этого и предназначен сегмент heap.
Мы называем это ― Динамическая память.
Каждый раз, когда вы используете malloc , чтобы разместить что-либо в памяти – вы обращаетесь к сегменту heap. Любой другой вызов, например int i; , относится к стек памяти. Очень важно это понимать, чтобы с лёгкостью находить ошибки, в том числе ошибки сегментации.
Понимание стека
Ваша программа постоянно резервирует стек память, вы об этом даже не задумываетесь. Каждая функция и локальная переменная, которую вы вызываете, попадает в стек. Большинство из того, что можно сделать со стеком ― вам следует избегать, например переполнение буфера или некорректный доступ к памяти и т.д.
Как это работает изнутри?
Стек имеет структуру данных LIFO (Last-In-First-Out) ― «последним пришёл –первым ушёл». Представьте аккуратную стопку книг. В этой стопке вы можете взять первой, ту книгу, которую положили последней. Такая структура позволяет программе управлять своими операциями и пространствами, двумя простыми командами: push и pop. Команда push добавляет значение сверху стека, а pop наоборот ― изымает значение.
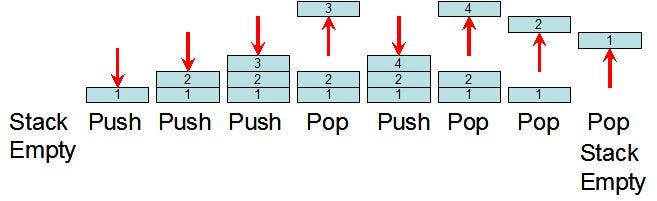
Для отслеживания текущего места в памяти существует специальный регистр процессора ― Stack Pointer (указатель стека). Например, переменные или обратный адрес из функции при сохранении попадают в стек и stack pointer перемещается вверх. Завершение функции означает, что всё изымается из стека, начиная с текущего положения stack pointer, до сохранённого обратного адреса из функции. Всё просто!
Чтобы проверить, всё ли вы поняли, давайте используем следующий пример (попробуйте найти ошибку самостоятельно ☺️):

Если запустить программу, она выдаст ошибку сегментации. Почему так происходит? Кажется, что всё на своих местах! За исключением… стека.
Когда мы вызываем функцию createArray , стек сохраняет обратный адрес, создаёт arr в памяти стека и возвращает arr (массив — это просто указатель на область памяти с этой информацией). Но, так как мы не использовали malloc , arr остаётся в стек памяти. После того как мы возвращаем указатель, так как мы не контролируем операции стека, программа изымает информацию из стека и использует её для своих нужд. Когда мы пытаемся заполнить массив, после того как вернули его из функции, мы повреждаем память и получаем ошибку сегментации.
Понимание кучи (heap)
В отличии от стека, в куче сохраняется что-либо, независимо от функций и пространств, в течение необходимого времени. Для использования этой памяти, в языке C есть библиотека stdlib с функциями malloc и free .
Malloc (memory allocation) запрашивает у системы необходимый объем памяти и возвращает указатель на начальный адрес. Free сообщает системе, что запрошенная память больше не нужна и может быть использована для других задач. Выглядит действительно просто ― до тех пор, пока вы избегаете ошибок.
Поскольку система не может перезаписать то, что запросил разработчик, мы должны сами управлять этим процессом с помощью этих двух функций. Это создаёт опасность возникновения утечек памяти.
Утечка произойдёт, если память не освободить вовремя, до завершения выполнения программы или если указатели на расположение этой памяти были потеряны. Программа будет использовать больше памяти чем должна. Чтобы этого не случалось, мы должны освобождать выделенную в куче память, когда она нам не нужна.

На изображении видно, как в «bad» версии кода, мы не освобождаем память. Это приводит к растрачиванию 20 * 4 байт (размер int 64-бит) = 80 байт. Может показаться, что это незначительно, но, если это большая программа, речь может идти о гигабайтах!
Чтобы программа эффективно использовала память — важно контролировать память кучи. В тоже время, делать это нужно с осторожностью. Если память была освобождена, то попытка получения доступа к ней или её использование может привести к ошибке сегментации.
Бонус: Struct и куча
Одна из распространённых ошибок при использовании struct заключается в том, что мы просто освобождаем struct. Всё прекрасно до тех пор, пока мы не выделяем память для указателей, внутри struct. В этом случае нам нужно сначала очистить их, а потом struct.
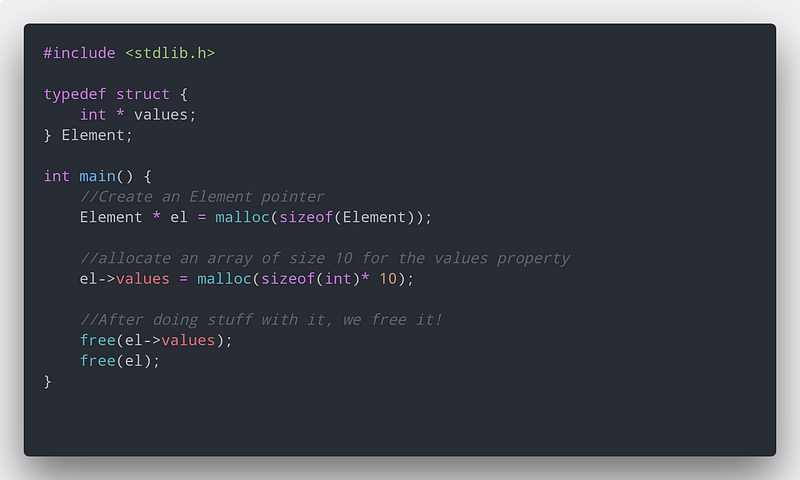
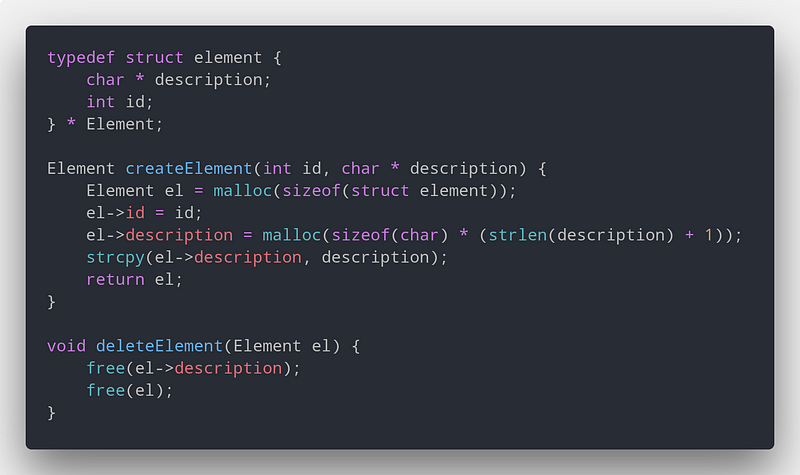
Как я устраняю утечки памяти
Программируя на C, я часто использую struct, поэтому у меня всегда под рукой две необходимые функции: конструктор и деструктор. Это единственные функции, для которых я использую mallocs и frees в struct. Это упрощает решение проблем с утечкой памяти.
- ТЭГИ
- Computer Science
- Software Development
Источник: nuancesprog.ru