
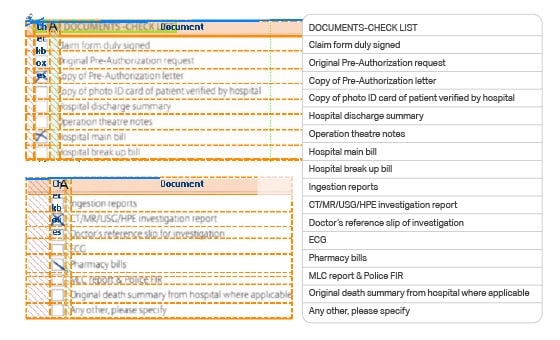
Койнова, Т. А. Алгоритмы распознавания символов / Т. А. Койнова. — Текст : непосредственный // Молодой ученый. — 2022. — № 18 (413). — С. 73-76. — URL: https://moluch.ru/archive/413/91060/ (дата обращения: 24.06.2023).
Статья посвящена рассмотрению существующих на сегодняшний день вариантов решения проблемы распознавания символов печатного текста. В процессе исследования отдельное внимание уделено системе оптического распознавания символов, а именно специализированным алгоритмам. В частности, рассмотрен алгоритм на основе грамматик, алгоритм линейного распределения, алгоритм контурного анализа, алгоритм на основе нейронных сетей. Также выделены возможности этих алгоритмов, особенности их работы, достоинства и недостатки.
Ключевые слова : алгоритм, текст, символ, распознавание, грамматика, контур, анализ, обработка, нейронная сеть.
The article is devoted to the consideration of the currently existing options for solving the problem of recognizing characters in printed text. In the process of research, special attention is paid to the system of optical character recognition, namely, specialized algorithms. In particular, an algorithm based on grammars, a linear distribution algorithm, and a contour analysis algorithm are considered. The possibilities of these algorithms, the features of their work, advantages and disadvantages are also highlighted.
САМОЕ БЫСТРОЕ РАСПОЗНАВАНИЕ РЕЧИ БЕЗ ИНТЕРНЕТА НА PYTHON
Keywords: algorithm, text, symbol, recognition, grammar, contour, analysis, processing, neural network.
Сегодня существует большой спрос на хранение в цифровом виде текстовой информации, размещенной в печатных, графических или рукописных документах, с целью дальнейшей ее обработки, редактирования и анализа. Кроме того, обширное распространение инструментов сканирования и оцифровки способствовало стремительному развитию методов и способов детектирования текста, которые в целом получили название системы оптического распознавания символов (OCR). Эти системы дают возможность в автоматическом режиме проводить анализ различных документов, подготавливать текстовые данные в редактируемых форматах для их дальнейшей обработки [3].
Необходимо отметить, что в последние годы системы распознавания печатного текста стали достаточно эффективными. В тоже время, текущие технологии все еще имеют ряд ограничений, чтобы распознавать текстовые изображения разных стилей и языков ввода. Также актуальной остается проблема обеспечения качества обработки в зависимости от таких факторов как: цвет, шрифт, расстояние между символами.
Обозначенные обстоятельства обуславливают необходимость проведения дальнейших исследования в данной предметной области, что и предопределило выбор темы этой статьи.
Описанию технологии оптического распознавания символов уделяется большое внимание в работах отечественных и зарубежных авторов. Так, в трудах Коноваленко И. А., Полевого Д. В., Николаева Д. П., Qamar, Faizan; Al-Sheikh, Idris исследуются этапы и методы распознавания текста.
Распознавание текста с картинки на Python | Оптическое распознавание символов Tesseract
Однако, несмотря на активные разработки и внимание к исследуемым вопросам, появление новых цифровых технологий и возможностей предопределяет необходимость актуализации имеющихся наработок и их регулярного пересмотра.
Таким образом, с учетом вышеизложенного, цель статьи заключается в проведении анализа современных алгоритмов распознавания символов печатного текста.
На сегодняшний день создан уже достаточно широкий спектр разнообразных алгоритмов (шаблонные, структурные, признаковые, статистические), которые незначительно отличаются по функционалу, но могут существенно различаться по качеству обработки текста. Некоторые допускают довольно много ошибок в распознавании, тогда как другие идентифицируют символы практически идеально.
Рассмотрим некоторые алгоритмы более подробно.
Алгоритм на основе грамматик . Грамматики представляют собой набор определенных правил распознавания символов.
Можно выделить следующие методы создания грамматик:
– использование теории графов. Текст представлен в виде размеченного графа. Задачи распознавания символов ставятся как задачи нахождения изоморфизма эталонного и входного графов, или изоморфизма их подграфов;
– методы теории формальных языков и грамматик. Символ рассматривается в некотором формальном языке, который задается с помощью конструкций, являющихся обобщениями грамматик Хомского. Распознавание заключается в отыскании лучшего в определенном смысле вывода изображения в заданной грамматике [1].
Особую популярность сегодня получили двумерные контекстно-свободные грамматики. В тоже время заложенная в них постановка задачи на точное совпадение, очевидно, имеет ряд недостатков, существенно ограничивающих их практическое применение для распознавания символов:
– с точки зрения распознавания символов формализм двумерных контекстно-свободных грамматик не всегда позволяет найти реальное изображение, которое можно разделить на прямоугольные фрагменты;
– чрезмерная детализация правил грамматики: для каждого символа следует указывать, каким образом он состоит из меньших частей вплоть до уровня отдельных пикселей.
Алгоритм линейного распределения . Процедура линейного разделения текста разбивает строки на слова, а слова — на отдельные буквы. После этого, по принципу IPA (integrity, purposefulness, adaptability) формируется набор гипотез (т. е. возможных вариантов идентификации каждого символа) и, обеспечив оценку вероятности, результат передается на вход системы распознавания [2].
В соответствии с первым принципом целостности (integrity) объект (символ) рассматривается как единое целое, которое состоит из нескольких взаимосвязанных частей. Принцип целеполагания (purposefulness): любая интерпретация данных должна иметь некую цель. Т. е. распознавание представляет собой процесс формулировки гипотез об объекте и их подтверждение или опровержение. Третий принцип — адаптивность (adaptability) — предполагает способность системы самостоятельно обучаться и использовать в дальнейшем ранее собранную информацию. Полученные в ходе распознавания данные упорядочиваются, хранятся и используются впоследствии для решения аналогичных задач.
Алгоритм контурного анализа . Основным преимуществом алгоритмов данной группы является их простота и скорость работы, а также минимальное влияние внешних факторов на результаты работы программных систем с элементами контурного анализа. Суть алгоритма контурного анализа при распознавании символов сводится к точному представлению границ для чего используется четыре модели кривых и методы подгонки моделей к краевым точкам. Модели включают: отрезки линий; круговые дуги; конические сечения; кубические сплайны. Алгоритм в процессе распознавания решает два вопроса: какой метод применяется для подгонки кривой к краям и как измеряется точность передачи контура.
Алгоритм на основе нейронной сети . Алгоритм распознавания текста с использованием нейронной сети заключается в следующем: на вход нейронной сети подается растровое изображение текста. В начале по входному тексту рассчитываются определенные признаки. Результатом расчетов является некоторый вектор значений признаков. Каждый выход нейронной сети соответствует определенной букве алфавита, а получаемое в итоге значение представляет собой уровень принадлежности буквы конкретному нечеткому множеству.
Задачей алгоритма является обобщение информации, поступающей в виде нечетких входных множеств и вычисление на их основе исходного нечеткого подмножества множественного числа распознавания символов. На последнем этапе принимается решение о выборе наиболее правдоподобного варианта прочтения слова.
Проанализируем на конкретном примере особенности работы нейронной сети для распознавания печатного текста.
Рассмотрим сверточную нейронную сеть, которая обучается по методу обратного распространения ошибки (back propagation) см. рис. 1.
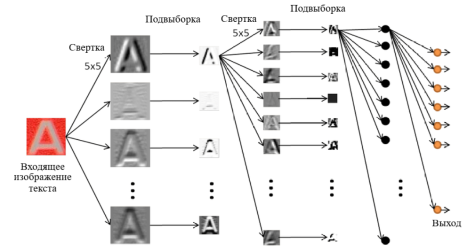
Рис. 1. Архитектура сверточной нейронной сети для распознавания текста
Такая архитектура предполагает прохождение трех взаимосвязанных этапов распознавания текста.
- Обработка изображения и распознавание текста в целом. Этот этап необходим для обнаружения границ текста. Данная процедура происходит с помощью фильтров изображения для обнаружения того, где находится текст, а где изображены обычные «шумовые» предметы (ручка, карандаш, точки на изображении и др.).
Каждый фрагмент изображения текста поэлементно умножается на матрицу весов (ядро), после чего результат суммируется. Эта сумма является пикселем исходного изображения, называемого картой признаков. После этого взвешенная сумма входов пропускается через функцию активации:
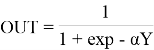
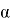
— параметр наклона сигмоидальной функции активации. Изменяя этот параметр, можно построить функции с разной крутизной.
- Обработка каждого отдельного слова посредством определения отступлений между словами. Главной проблемой этого этапа может быть перепутывание буквы в слове с отдельным словом. Для решения этой проблемы нейронная сеть должна научиться приспосабливаться к отдельным шрифтам и языкам.
- Выявление отдельных букв в слове и определения, на какие из алфавита они больше всего похожи (см. рис. 2).

Рис. 2. Пример распознанных текстов
Зеленые дуги обозначают символы, расположенные между последовательными «точными» сегментациями, а красные дуги представляют различные возможные конфигурации, связанные с «рискованными сегментациями», синие — кадрированные символы.
Таким образом, в процессе исследования рассмотрены различные алгоритмы распознавания символов в печатном тексте. Для распознавания текстовых документов с высоким качеством (низкий процент шумов, четкий шрифт и т. д.) целесообразно использовать алгоритмы на основе грамматик, линейного распределения. Структурные алгоритмы (алгоритмы контурного анализа, алгоритмы на основе нейронной сети) будут эффективны при распознавании сложных символов.
- Text analytics: an introduction to the science and applications of unstructured information analysis / John Atkinson-Abutridy. Boca Raton: Chapman https://moluch.ru/archive/413/91060/» target=»_blank»]moluch.ru[/mask_link]
Технологии распознавания текста (Необходимость в системах распознавания символов)
Оптическое распознавание символов
Оптическое распознавание символов (англ. optical character recognition, OCR) — это механический или электронный перевод изображений рукописного, машинописного или печатного текста в последовательность кодов, использующихся для представления в текстовом редакторе. Распознавание широко используется для конвертации книг и документов в электронный вид, для автоматизации систем учета в бизнесе или для публикации текста на веб-странице. Оптическое распознавание текста позволяет редактировать текст, осуществлять поиск слова или фразы, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тесту электронный перевод, форматирование или преобразование в речь. Оптическое распознавание текста является исследуемой проблемой в областях распознавания образов, искусственного интеллекта и компьютерного зрения.
Системы оптического распознавания текста требуют калибровки для работы с конкретным шрифтом; в ранних версиях для программирования было необходимо изображение каждого символа, программа одновременно могла работать только с одним шрифтом. В настоящее время больше всего распространены так называемые «интеллектуальные» системы, с высокой степенью точности распознающие большинство шрифтов. Некоторые системы оптического распознавания текста способны восстанавливать исходное форматирование текста, включая изображения, колонки и другие нетекстовые компоненты.
В 1929 году Густав Таушек получил патент на метод оптического распознавания текста в Германии, после чего за ним последовал Гендель, получив патент на свой метод в США в 1933. В 1935 году Таушек также получил патент США на свой метод. Машина Таушека представляла собой механическое устройство, которое использовало шаблоны и фотодетектор.
В 1950 году Дэвид Х. Шепард, криптоаналитик из агентства безопасности вооружённых сил Соединённых Штатов, проанализировав задачу преобразования печатных сообщений в машинный язык для обработки компьютером, построил машину, решающую данную задачу. После того как он получил патент США, он сообщил об этом в «Вашингтон Дэйли Ньюз» (27 апреля 1951) и в «Нью-Йорк Таймс» (26 декабря 1953). Затем Шепард основал компанию, разрабатывающую интеллектуальные машины, которая вскоре выпустила первые в мире коммерческие системы оптического распознавания символов.
Первая коммерческая система была установлена на «Ридерс Дайджест» в 1955 году. Вторая система была продана компании «Стэндарт Ойл» для чтения кредитных карт для работы с чеками. Другие системы, поставляемые компанией Шепарда, были проданы в конце 1950-х годов, в том числе сканер страниц для национальных воздушных сил США, предназначенный для чтения и передачи по телетайпу машинописных сообщений. IBM позже получила лицензию на использование патентов Шепарда.
Примерно в 1965 году «Ридерс Дайджест» и «Ар-Си-Эй» начали сотрудничество с целью создать машину для чтения документов, использующую оптическое распознавание текста, предназначенную для оцифровки серийных номеров купонов «Ридерс Дайджест», вернувшихся из рекламных объявлений. Для печати на документах барабанным принтером «Ар-Си-Эй» был использован специальный шрифт OCR-A. Машина для чтения документов работала непосредственно с компьютером RCA 301 (один из первых массивных компьютеров). Скорость работы машины была 1500 документов в минуту: она проверяла каждый документ, исключая те, которые она не смогла обработать правильно.
Почтовая служба Соединённых Штатов с 1965 года для сортировки почты использует машины, работающие по принципу оптического распознавания текста, созданные на основе технологий, разработанных исследователем Яковом Рабиновым. В Европе первой организацией, использующей машины с оптическим распознаванием текста, был британский почтамт.
Почта Канады использует системы оптического распознавания символов с 1971 года. На первом этапе в центре сортировки системы оптического распознавания символов считывают имя и адрес получателя и печатают на конверте штрих-код. Он наносится специальными чернилами, которые отчётливо видимы в ультрафиолетовом свете. Это делается, чтобы избежать путаницы с полем адреса, заполненным человеком, которое может быть в любом месте на конверте.
В 1974 году Рэй Курцвейл создал компанию «Курцвейл Компьютер Продактс», и начал работать над развитием первой системы оптического распознавания символов, способной распознать текст, напечатанный любым шрифтом. Курцвейл считал, что лучшее применение этой технологии — создание машины чтения для слепых, которая позволила бы слепым людям иметь компьютер, умеющий читать текст вслух. Данное устройство требовало изобретения сразу двух технологий — ПЗС планшетного сканера и синтезатора, преобразующего текст в речь. Конечный продукт был представлен 13 января 1976 во время пресс-конференции, возглавляемой Курцвейлом и руководителями национальной федерации слепых.
В 1978 году компания «Курцвейл Компьютер Продактс» начала продажи коммерческой версии компьютерной программы оптического распознавания символов. Два года спустя Курцвейл продал свою компанию корпорации «Ксерокс», которая были заинтересована в дальнейшей коммерциализации систем распознавания текста. «Курцвейл Компьютер Продактс» стала дочерней компанией «Ксерокс», известной как «Скансофт».
1. Необходимость в системах распознавания символов
С помощью сканера достаточно просто получить изображение страницы текста в графическом файле. Но работать с текстом невозможно по определённым причинам:
— страница с текстом представляет собой графический файл — обычную картинку;
— текст нельзя редактировать и форматировать;
— необходимо преобразовать элементы графического изображения в последовательности текстовых символов.
2. Основной метод
Основным методом перевода бумажных документов в электронную форму является сканирование:
— в результате сканирования получается графическое изображение, состоящее из точек;
— количество точек определяется размером изображения и разрешением сканера.
3. Преобразование документа
В электронный вид происходит в три основных этапа:
2. Сегментация и распознавание текста
3. Проверка орфографии и передача текстового документа в нужное приложение для дальнейшей работы или сохранение в файл.
Каждый из этих этапов может выполняться программами как автоматически, так и под контролем пользователя.
4. Программы распознавания текста
Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition — OCR).
Наиболее распространенные системы оптического распознавания символов:
a) BBYY FineReader
b) CuneiForm от Cognitive
а). ABBYY FineReader
FineReader — омнифонтовая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты, набранные практически любыми шрифтами, без предварительного обучения. Особенностью программы FineReader является высокая точность распознавания и малая чувствительность к дефектам печати.
OCR-технологии от компании ABBYY также поддерживают зональное распознавание (распознавание на уровне полей), необходимое во многих ключевых бизнес-процессах, таких как классификация по ключевым словам, индексирование по ключевым словам и ввод данных с форм. L, PDF/A, searchable PDF, CSV и текстовые (plain text) файлы.
Интерфейс
Пользователь может настроить рабочее пространство по своему усмотрению:
— Изменить расположение и размер окон
— Настроить панель быстрого доступа, предназначенную для доступа к наиболее часто используемым командам
— Настроить горячие клавиши — можно как заменить предустановленные сочетания, так и добавить свои горячие клавиши для выполнения команд программы
— Выбрать нужный язык интерфейса и др.
Возможности:
— позволяет извлекать текстовые данные из цифровых изображений;
— полученное в результате распознавания может быть сохранено в различных форматах.
Дополнительные возможности:
-Распознавание с обучением;
-Создание новых языков и группы языков;
-Коллективная работа в сети.
b). CuneiForm
оптический символ текст интерфейс
CuneiForm — это программа для оптического распознавания текста документов в редактируемый вид. Результаты работы программы можно редактировать в офисных программах и текстовых редакторах и сохранять в популярных форматах, проводить по ним полнотекстовый поиск.
CuneiForm является предшественницей систем промышленного распознавания и понимания документов. Многие технологические ноу-хау, результаты научных исследований, положенные в основу CuneiForm, успешно применяются и совершенствуются по сей день в коммерческих продуктах Cognitive Technologies.
Возможности:
— при распознавании с помощью CuneiForm сохраняется структура документа и его форматирование;
— программа распознает таблицы любой структуры и сложности, в том числе и без отображения линий табличной сетки;
— распознаются любые печатные шрифты: книги, газеты, журналы, распечатки с лазерных и матричных принтеров, тексты с пишущих машинок;
— алгоритмы оптического распознавания (OCR, Optical Character Recognition), встроенные в программу позволяют распознавать текст с матричного принтера, плохих ксерокопий и факсов;
— распознавание документов более чем на 20 языках: на русском, английском, немецком, французском, испанском, итальянском, шведском, украинском и других;
— для повышения качества распознавания в программе используется словарная проверка. При этом стандартный словарь можно расширить за счет импорта новых слов из текстовых файлов.
Достоинства CuneiForm:
— практически единственная бесплатная OCR-программа профессионального уровня.
— большое количество языков распознавания.
— простой и понятный интерфейс.
— на русском языке.
5. Эксперты о CuneiForm и FineReader
CHIP Special 2/2002 «Наиболее сильным соперником FineReader является программа CuneiForm, которая долгие годы успешно с ним конкурировала. Следует отметить, что CuneiForm первой получила признание на Западе, будучи встроена в популярный CorelDraw, а также установлена во многих госструктурах США, например, в аппарате президента, ФБР, ЦРУ, Министерстве обороны и т.д.
Но постепенно, начиная с четвертой версии, лидерство FineReader становилось все более очевидным…»
6. Автоматический перевод текста
Программные средства автоматического перевода можно условно разделить на две основные категории:
1. Компьютерные словари. Назначение их — предоставить значения неизвестных слов быстро и удобно для пользователя.
2. Системы автоматического перевода — позволяют выполнять автоматический перевод связного текста. В ходе работы программа использует словари и наборы грамматических правил, обеспечивающих наилучшее качество перевода.
- Стратегические преимущества внедрения СЭД
- Технологии распознавания текста (Необходимость в системах распознавания символов.)
- Российское законодательство по информационной безопасности и безопасности сетей (Ограничение доступа к информации, конфиденциальность и защита информации)
- Технологии распознавания текста
- Способы активизации творческого мышления
- История развития мультимедиа (Гипертекстовые и мультимедийные информационные технологии)
- Этапы изготовления печатной формы для офсетной печати
- Аспекты рассмотрения знаков: синтактика, семантика, прагматика
- Регистрация и индексация документов (Факультет Управления)
- История развития торгового права России ( Коммерческое (торговое) право.)
- История развития торгового права России
- Технологии распознавания текста (по дисциплине Документооборот в управлении)
При копировании любых материалов с сайта evkova.org обязательна активная ссылка на сайт www.evkova.org
Сайт создан коллективом преподавателей на некоммерческой основе для дополнительного образования молодежи
Сайт пишется, поддерживается и управляется коллективом преподавателей
Telegram и логотип telegram являются товарными знаками корпорации Telegram FZ-LLC.
Cайт носит информационный характер и ни при каких условиях не является публичной офертой, которая определяется положениями статьи 437 Гражданского кодекса РФ. Анна Евкова не оказывает никаких услуг.
Источник: www.evkova.org
Что такое оптическое распознавание символов (OCR): обзор и его применение
Оптическое распознавание символов большинству из нас это может показаться сложным и чуждым, но мы чаще используем эту передовую технологию. Мы используем эту технологию достаточно широко, от перевода иностранного текста на предпочитаемый нами язык до оцифровки печатных бумажных документов. Все же, OCR технологии продвинулись дальше и стали неотъемлемой частью нашей технологической экосистемы.
Однако информации об этой инновационной технологии слишком мало, и пришло время пролить на нее свет.
Что такое оптическое распознавание символов (OCR)?
Часть семейства искусственного интеллекта, оптическое распознавание символов — это электронное преобразование текста из рукописных заметок, печатный текст от видео, изображений, и отсканированные документы в машиночитаемый и цифровой формат.
Можно закодировать текст из печатного документа и изменить, сохранить или изменить его в электронном виде для сохранения, восстановления и использования для построения моделей ML с использованием технологии OCR.
Существует два основных типа OCR — традиционный и рукописный. Хотя оба они работают для достижения одного и того же результата, они различаются тем, как они извлекают информацию.
В традиционном OCR текст извлекается на основе доступных стилей шрифта, которые OCR-системы можно тренироваться с. С другой стороны, в рукописном OCR, где каждый стиль письма уникален, читать и кодировать сложно. В отличие от печатного текста, где текст одинаков для всех, рукописный текст уникален для каждого человека. Рукописное распознавание текста требует дополнительной подготовки для точного распознавание образов.
Как работает технология OCR?
В работе технологии OCR задействованы три важных аппаратных и программных элемента.
Шаг 1: Преобразование физического документа в цифровое изображение
На этом этапе необходимо иметь компонент оптического сканера для преобразования документа в цифровое изображение. Если документ находится на бумажном носителе, важно определить интересующую область, чтобы декодированию подлежали только эти области. Области с текстом учитываются для преобразования, а остальные остаются нулевыми. Изображения в документе преобразуются в фоновые цвета, а текст остается темным — это помогает отделить символы от фона.
Шаг 2: Фаза распознавания персонажей
Этот пошаговый удар запускает процесс распознавания определенных символов в тексте. Система не анализирует весь текст — цифры и буквы — за один раз. Он выбирает меньшие сегменты, скорее всего, отдельные слова, если система ИИ может точно распознавать язык.
Распознавание функций: Он используется для идентификации нового персонажа с помощью правил, определяющих специфические характеристики текста. Например, буква «Т» может показаться нам очень простой, но для ИИ это относительно сложная комбинация вертикальных и горизонтальных линий.
Распознавание образов: ИИ обучается с использованием набора текстов и чисел, чтобы автоматически идентифицировать и распознавать совпадения в документах с его изученным хранилищем.
Шаг 3: Обработка и вывод текста
Все идентифицированные символы преобразуются в код ASCII для сохранения на будущее. Очень важно иметь постобработку, чтобы можно было перепроверить первый вывод. Например, буквы «I» и «1» могут выглядеть немного похожими, что затрудняет их распознавание системой, особенно когда речь идет о почерке.
Высококачественный набор данных счетов/квитанций/документов для обучения вашей модели ИИ
Преимущества оптического распознавания символов
Оптическое распознавание символов — технология OCR – дает ряд преимуществ, некоторые из которых:
Увеличьте скорость процесса:
Повышает точность:
Снижает затраты на обработку:
Повышает производительность:
Повышает удовлетворенность клиентов:
Варианты использования и приложения
Сохранение документов / Оцифровка документов
Старые ценные исторические документы можно сохранить, сохранить и сделать неуничтожимыми, преобразовав их в цифровой формат. Технология OCR используется для оцифровки старинных и редких книг, поэтому эти рукописи с неправильным шрифтом можно изменить в цифровом виде и сделать доступными для поиска в будущем.
Банковское дело и финансы
Банковский и финансовый сектор активно использует технологию OCT. Эта технология помогает улучшить предотвращение мошенничества с безопасностью, снизить риск и ускорить обработку. Банки и банковские приложения используют OCR для извлечения важных данных из чеков, таких как номер счета, сумма и подпись от руки. OCR помогает ускорить обработку кредитных и ипотечных заявок, счетов и платежных ведомостей.
До того, как OCR стало более распространенным, все банковские документы, такие как отчеты, квитанции, выписки и чеки, были физическими. Благодаря оцифровке оптического распознавания символов банки и финансовые учреждения могут оптимизировать процессы, устранить ручные ошибки и повысить эффективность процессов за счет быстрого доступа к данным.
Распознавание номерных знаков

Технология OCR широко используется для идентификации цифр и текста на номерных знаках. Эта технология используется для выявления потерянных автомобилей, расчета платы за парковку и предотвращения транспортных преступлений.
Технология OCR помогает внедрять правила безопасности дорожного движения, чтобы избежать мошенничества и преступлений. Поскольку номерные знаки на транспортном средстве связаны с учетными данными водителя, идентификация упрощается.
Более того, номерные знаки состоят из хорошо написанной связки цифр и текста, который несложно прочитать модели ИИ, что делает его более легким и точным.
Преобразование текста в речь
Транскрипция нескольких категорий Отсканированные бумажные документы Datasets

С помощью технологии OCR также эффективно расшифровываются счета-фактуры, квитанции, счета и другие документы различных категорий. Информационные бюллетени, документы с номерами в кружках, формы с флажками и документы с несколькими категориями, такие как налоговые формы и руководства, также могут быть оцифрованы.
Расшифровка медицинских этикеток с помощью OCR
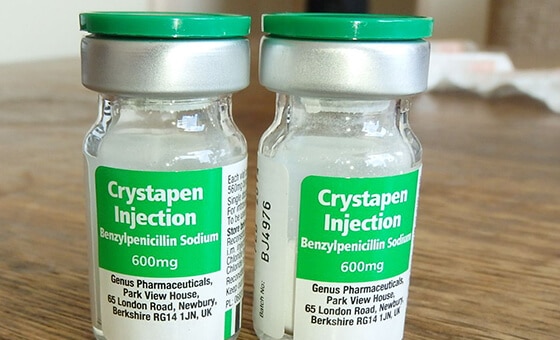
Помогая сканировать рецептурные медицинские этикетки с помощью OCR, теперь можно автоматически собирать медицинские данные. Медицинский данные захвачены из рукописных рецептов, информации о лекарствах и количестве, чтобы избежать ручных ошибок, дублирования и небрежности.
С OCR индустрия здравоохранения может быстро сканировать, хранить и искать историю болезни пациента. OCR позволяет оцифровывать и хранить отчеты о сканировании, историю лечения, больничные записи, страховые записи, рентгеновские снимки и другие документы. Оцифровывая, транскрибируя и сохраняя медицинские этикетки, OCR упрощает процесс и ускоряет оказание медицинской помощи.
Обнаружение улицы/дороги и извлечение данных Street Board с OCR

Автоматическое обнаружение, идентификация и классификация дорожных / уличных знаков выполняются с помощью OCR. Обнаружив дорожные знаки, OCR направляет водителей к более безопасному путешествию. Технология OCR одинаково хорошо работает в условиях низкой освещенности, распознает дорожные знаки на нескольких языках и вывески разной формы и классифицирует их на будущее.
разработать интеллектуальное распознавание символов инструмент, вы должны обучить его набору данных для конкретного проекта.
В Shaip мы предоставляем полностью настраиваемый набор данных документов для разработки высокофункциональных OCR для моделей AI и ML. Наш специализированный процесс оптического распознавания символов помогает в разработке оптимизированных решений для клиентов.