
С помощью функции распознавания речи можно вводить данные, указывать действия или команды и выполнять задачи.
Для распознавания речи используется специальная среда выполнения, API распознавания для программирования среды выполнения, готовые грамматики для диктовки и веб-поиска, а также системный пользовательский интерфейс по умолчанию, который помогает пользователям обнаруживать и использовать функции распознавания речи.
Настройка распознавания речи
Для поддержки распознавания речи в приложении пользователь должен подключиться и включить микрофон на своем устройстве и принять политику конфиденциальности Майкрософт, предоставив приложению разрешение на его использование.
Чтобы автоматически запрашивать у пользователя системное диалоговое окно, запрашивающее разрешение на доступ и использование звукового канала микрофона (пример из примера распознавания речи и синтеза речи , показанного ниже), просто задайте возможность «Микрофонdevice » в манифесте пакета приложения. Дополнительные сведения см. в объявлениях возможностей приложений.
САМОЕ БЫСТРОЕ РАСПОЗНАВАНИЕ РЕЧИ БЕЗ ИНТЕРНЕТА НА PYTHON

Если пользователь нажимает кнопку «Да», чтобы предоставить доступ к микрофону, ваше приложение добавляется в список утвержденных приложений на странице Параметры —> конфиденциальность —> микрофон. Тем не менее, так как пользователь может отключить этот параметр в любое время, необходимо убедиться, что ваше приложение имеет доступ к микрофону, прежде чем пытаться использовать его.
Если вы также хотите поддерживать диктовку, Кортана или другие службы распознавания речи (например, предопределенную грамматику, определенную в ограничении раздела), необходимо также убедиться, что включена функция распознавания речи в Интернете (Параметры —> конфиденциальность —> речь).
В этом фрагменте кода показано, как приложение может проверить, присутствует ли микрофон и есть ли у него разрешение на его использование.
public class AudioCapturePermissions < // If no microphone is present, an exception is thrown with the following HResult value. private static int NoCaptureDevicesHResult = -1072845856; /// /// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle /// the Cortana/Dictation privacy check. /// /// You should perform this check every time the app gets focus, in case the user has changed /// the setting while the app was suspended or not in focus. /// /// True, if the microphone is available. public async static Task RequestMicrophonePermission() < try < // Request access to the audio capture device.
MediaCaptureInitializationSettings settings = new MediaCaptureInitializationSettings(); settings.StreamingCaptureMode = StreamingCaptureMode.Audio; settings.MediaCategory = MediaCategory.Speech; MediaCapture capture = new MediaCapture(); await capture.InitializeAsync(settings); >catch (TypeLoadException) < // Thrown when a media player is not available. var messageDialog = new Windows.UI.Popups.MessageDialog(«Media player components are unavailable.»); await messageDialog.ShowAsync(); return false; >catch (UnauthorizedAccessException) < // Thrown when permission to use the audio capture device is denied. // If this occurs, show an error or disable recognition functionality. return false; >catch (Exception exception) < // Thrown when an audio capture device is not present. if (exception.HResult == NoCaptureDevicesHResult) < var messageDialog = new Windows.UI.Popups.MessageDialog(«No Audio Capture devices are present on this system.»); await messageDialog.ShowAsync(); return false; >else < throw; >> return true; > >
/// /// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle /// the Cortana/Dictation privacy check. /// /// You should perform this check every time the app gets focus, in case the user has changed /// the setting while the app was suspended or not in focus. /// /// True, if the microphone is available.
Бесплатное преобразование голоса из видео и аудио файлов в печатный текст
IAsyncOperation^ AudioCapturePermissions::RequestMicrophonePermissionAsync() < return create_async([]() < try < // Request access to the audio capture device. MediaCaptureInitializationSettings^ settings = ref new MediaCaptureInitializationSettings(); settings->StreamingCaptureMode = StreamingCaptureMode::Audio; settings->MediaCategory = MediaCategory::Speech; MediaCapture^ capture = ref new MediaCapture(); return create_task(capture->InitializeAsync(settings)) .then([](task previousTask) -> bool < try < previousTask.get(); >catch (AccessDeniedException^) < // Thrown when permission to use the audio capture device is denied. // If this occurs, show an error or disable recognition functionality. return false; >catch (Exception^ exception) < // Thrown when an audio capture device is not present. if (exception->HResult == AudioCapturePermissions::NoCaptureDevicesHResult) < auto messageDialog = ref new Windows::UI::Popups::MessageDialog(«No Audio Capture devices are present on this system.»); create_task(messageDialog->ShowAsync()); return false; > throw; > return true; >); > catch (Platform::ClassNotRegisteredException^ ex) < // Thrown when a media player is not available. auto messageDialog = ref new Windows::UI::Popups::MessageDialog(«Media Player Components unavailable.»); create_task(messageDialog->ShowAsync()); return create_task([] ); > >); >
var AudioCapturePermissions = WinJS.Class.define( function () < >, <>, < requestMicrophonePermission: function () < /// /// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle /// the Cortana/Dictation privacy check. /// /// You should perform this check every time the app gets focus, in case the user has changed /// the setting while the app was suspended or not in focus. /// /// True, if the microphone is available. return new WinJS.Promise(function (completed, error) < try < // Request access to the audio capture device. var captureSettings = new Windows.Media.Capture.MediaCaptureInitializationSettings(); captureSettings.streamingCaptureMode = Windows.Media.Capture.StreamingCaptureMode.audio; captureSettings.mediaCategory = Windows.Media.Capture.MediaCategory.speech; var capture = new Windows.Media.Capture.MediaCapture(); capture.initializeAsync(captureSettings).then(function () < completed(true); >, function (error) < // Audio Capture can fail to initialize if there’s no audio devices on the system, or if // the user has disabled permission to access the microphone in the Privacy settings. if (error.number == -2147024891) < // Access denied (microphone disabled in settings) completed(false); >else if (error.number == -1072845856) < // No recording device present. var messageDialog = new Windows.UI.Popups.MessageDialog(«No Audio Capture devices are present on this system.»); messageDialog.showAsync(); completed(false); >else < error(error); >>); > catch (exception) < if (exception.number == -2147221164) < // REGDB_E_CLASSNOTREG var messageDialog = new Windows.UI.Popups.MessageDialog(«Media Player components not available on this system.»); messageDialog.showAsync(); return false; >> >); > >)
Распознавание речевого ввода
В ограничении определяются слова и фразы (словарь), которые приложение распознает в речевом вводе. Ограничения находятся в основе распознавания речи и дают вашему приложению больший контроль над точностью распознавания речи.
Для распознавания речевых входных данных можно использовать следующие типы ограничений.
Предопределенные грамматики
Предопределенные грамматики диктовки и веб-поиска обеспечивают распознавание речи в приложении без необходимости создавать грамматику. Когда используются эти грамматики, распознавание речи выполняется удаленной веб-службой, а результаты возвращаются на устройство.
Стандартная грамматика для диктовки в свободной форме может распознавать большинство слов и фраз, произносимых пользователем на данном языке, и оптимизирована для распознавания коротких фраз. Предопределенная грамматика для диктовки используется, если для объекта SpeechRecognizer не заданы никакие ограничения. Диктовка в свободной форме удобна, если не нужно ограничивать область высказываний пользователя. Обычно она используется для создания текстов заметок и диктовки сообщений.
Грамматика веб-поиска, например грамматика диктовки, содержит большое количество слов и фраз, которые пользователь может произнести. Однако она оптимизирована для распознавания терминов, которыми люди обычно используются, выполняя поиск в Интернете.
Поскольку предопределенные грамматики для диктовки и веб-поиска могут иметь большой размер и размещаются в сети (а не на устройстве), они могут уступать в производительности настраиваемым грамматикам, установленным на устройстве.
Эти предопределенные грамматики можно использовать для распознавания до ввода речи продолжительностью до 10 секунд, и для этого не потребуется никаких доработок с вашей стороны. Однако потребуется подключение к сети.
Чтобы использовать ограничения веб-службы, поддержка ввода речи и диктовки должна быть включена в Параметры, включив параметр «Узнать меня» в Параметры — конфиденциальность —>> речь, рукописный ввод и ввод.
Здесь показано, как проверить, включен ли голосовой ввод, и если нет, как открыть страницу Параметры -> Конфиденциальность -> Голосовые функции, рукописный ввод и ввод с клавиатуры.
Сначала мы инициализируем глобальную переменную (HResultPrivacyStatementDeclined) до значения HResult 0x80045509. См. сведения об обработке исключений в C# или Visual Basic.
private static uint HResultPrivacyStatementDeclined = 0x80045509;
Затем мы отберем все стандартные исключения во время распознавания и проверим, равно ли значение HResult значению переменной HResultPrivacyStatementDeclined. При положительном результате мы отобразим предупреждение и вызовем await Windows.System.Launcher.LaunchUriAsync(new Uri(«ms-settings:privacy-accounts»)); , чтобы открыть страницу «Параметры».
catch (Exception exception) < // Handle the speech privacy policy error. if ((uint)exception.HResult == HResultPrivacyStatementDeclined) < resultTextBlock.Visibility = Visibility.Visible; resultTextBlock.Text = «The privacy statement was declined.» + «Go to Settings ->Privacy -> Speech, inking and typing, and ensure you» + «have viewed the privacy policy, and ‘Get To Know You’ is enabled.»; // Open the privacy/speech, inking, and typing settings page. await Windows.System.Launcher.LaunchUriAsync(new Uri(«ms-settings:privacy-accounts»)); > else < var messageDialog = new Windows.UI.Popups.MessageDialog(exception.Message, «Exception»); await messageDialog.ShowAsync(); >>
Программные ограничения списка
Программные ограничения-списки представляют упрощенный подход к созданию простой грамматики с использованием списка слов или фраз. Для распознавания коротких четких фраз удобно использовать ограничения-списки. Явно указание всех слов в грамматике также повышается точность распознавания, так как подсистема распознавания речи должна обрабатывать голосовые данные только в рамках подтверждения соответствия. Список можно также обновлять программными средствами.
Ограничение-список состоит из массива строк, представляющих ввод речи, принимаемый приложением для операции распознавания. Чтобы создать ограничение-список в приложении, создайте объект ограничения-списка для распознавания речи и передайте ему массив строк. Затем добавьте этот объект в коллекцию ограничений распознавателя. Когда распознаватель речи распознает любую из строк в массиве, распознавание завершается успешно.
Грамматики SRGS
Грамматика SRGS – это статический документ, который, в отличие от программного ограничения-списка, использует формат XML, определенный в спецификации SRGS Version 1.0. Грамматика SRGS предоставляет больший контроль над распознаванием речи и позволяет создавать несколько семантических значений в одном распознавании.
Ограничения голосовых команд
С помощью XML-файлов определения голосовых команд можно задать команды, которые пользователь может произносить, чтобы выполнять определенные действия при активации вашего приложения. Дополнительные сведения см. в статье «Активация приложения переднего плана» с помощью голосовых команд с помощью Кортана.
Примечание Тип используемого типа ограничения зависит от сложности создаваемого интерфейса распознавания. Каждый может оказаться наилучшим для конкретной задачи распознавания, и в приложении может найтись место всем типам ограничений. Сведения об ограничениях см. в статье Определение настраиваемых ограничений распознавания.
Предопределенная грамматика универсального приложения для Windows для диктовки распознает большинство слов и коротких фраз в заданном языке. По умолчанию она активируется, когда создается экземпляр объекта распознавателя речи без настраиваемых ограничений.
В этом разделе мы покажем, как:
- Создать распознаватель речи.
- Скомпилировать ограничения универсального приложения для Windows по умолчанию (в набор грамматик распознавателя речи не добавлены грамматики).
- Начать прослушивание речи с помощью простого интерфейса распознавания и результатов преобразования текста в речь, передаваемых методом RecognizeWithUIAsync. Если пользовательский интерфейс по умолчанию не требуется, используйте метод RecognizeAsync.
private async void StartRecognizing_Click(object sender, RoutedEventArgs e) < // Create an instance of SpeechRecognizer. var speechRecognizer = new Windows.Media.SpeechRecognition.SpeechRecognizer(); // Compile the dictation grammar by default. await speechRecognizer.CompileConstraintsAsync(); // Start recognition. Windows.Media.SpeechRecognition.SpeechRecognitionResult speechRecognitionResult = await speechRecognizer.RecognizeWithUIAsync(); // Do something with the recognition result. var messageDialog = new Windows.UI.Popups.MessageDialog(speechRecognitionResult.Text, «Text spoken»); await messageDialog.ShowAsync(); >
Настройка пользовательского интерфейса распознавания
Когда ваше приложение пытается распознать речь при помощи вызова SpeechRecognizer.RecognizeWithUIAsync, отображаются несколько экранов в следующем порядке.
Если вы используете ограничение на базе предварительно заданной грамматики (диктовки или веб-поиска):
Если вы используете ограничение на базе списка слов или фраз или ограничение на базе грамматического файла SRGS:
- Экран Слушаю.
- Экран Вы сказали, если сказанное пользователем можно интерпретировать по-разному.
- Экран Я услышал или экран ошибки.
На следующем изображении представлен пример потока между экранами распознавателя речи, использующего ограничение на базе грамматического файла SRGS. В этом примере распознавание речи прошло успешно.
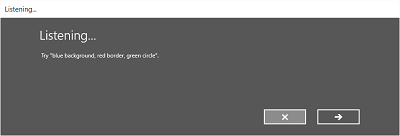
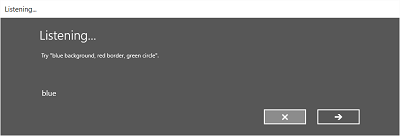
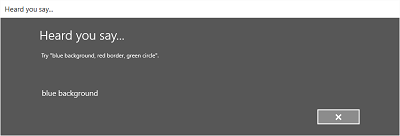
Экран Слушаю может предоставлять примеры слов или фраз, которые приложение может распознать. Здесь мы покажем, как использовать свойства класса SpeechRecognizerUIOptions (его можно получить, вызвав свойство SpeechRecognizer.UIOptions) для настройки содержимого на экране Слушаю.
Похожие статьи
Примеры
Источник: learn.microsoft.com
Как это работает? Распознавание речи
Сегодня много кто решает повседневные задачи на ходу — с телефона. С его помощью можно проверить почту, отправить документы и фотографии, найти ближайший банкомат или построить автомобильный маршрут. Не для всех подобных задач удобно пользоваться клавиатурой, поэтому сейчас одно из самых актуальных направлений мобильной разработки — это управление голосом.
В основе голосового управления лежит технология распознавания речи. В ней задействованы достижения различных областей: от компьютерной лингвистики до цифровой обработки сигналов. На конференции YaC 2013 в начале октября Яндекс представил свою технологию распознавания речи, и сегодня мы хотели бы рассказать о том, как она работает.
Акустическая модель
Если сказать голосовому поиску «Лев Толстой», смартфон услышит не имя и фамилию, не два слова, а звуковой сигнал, в котором звуки плавно перетекают друг в друга, не имея чётких границ. Задача системы распознавания речи — восстановить по этому сигналу, что было сказано. Ситуацию осложняет то, что одна и та же фраза, произнесённая разными людьми в разной обстановке, будет давать совершенно непохожие друг на друга сигналы. Правильно интерпретировать их помогает система акустического моделирования.
Когда вы произносите голосовой запрос, например, в Яндекс.Навигаторе, смартфон записывает его и отправляет на сервер Яндекса. На сервере запись разделяется на много маленьких фрагментов (фреймов) длиной 25 миллисекунд, внахлёст, с шагом 10 миллисекунд. То есть из одной секунды вашей речи получается сто фреймов.
Дальше каждый из них пропускают через акустическую модель — функцию, которая определяет, какие звуки вы произнесли. На основе этих данных система, натренированная методами машинного обучения, определяет варианты слов, которые вы видите в результатах поиска. Мобильный Браузер в ответ на запрос «Лев Толстой» найдёт сайты о великом писателе, а Навигатор и Карты предложат улицу Льва Толстого.
Точность результатов напрямую зависит от того, насколько хорошо система определяет произнесённые звуки. Для этого достаточно точным и полным должен быть фонетический алфавит, с которым она работает.
Фонетический алфавит Яндекса
В русском языке, по разным теориям, около 40 фонем (звуковых единиц). Наша система распознавания речи сопоставляет входящий речевой сигнал с фонемами, а потом уже из них собирает слова. Например, слово «Яндекс» состоит из семи фонем — [й][а][н][д][э][к][с].
Фонемы могут обладать различной длительностью, и в разбивке по фреймам слово «Яндекс» может выглядеть, например, так — [й][й][а][а][а][а][а][а][ а][а][а][а][н][н][д][д][э ][к][с]. Произношение любой фонемы зависит от её соседей и позиции в слове. То есть звук [а] в начале, в середине и в конце слова — это три разных [а], а звук [а] между двумя гласными в сочетании «на аудиозаписи» отличается от [а] между согласными в слове «бак». Поэтому для хорошего распознавания фонема — слишком грубая единица.
Чтобы точнее смоделировать произношение фонемы, мы, во-первых, делим каждую фонему на три части: условные начало, середину и конец. Во-вторых, мы разработали свой фонетический алфавит, который учитывает позицию и контекст фонем. Брать в работу все возможные варианты контекстно-зависимых фонем было бы неблагоразумно, так как многие из них не встречаются в реальной жизни.
Поэтому мы научили нашу программу рассматривать похожие звуки вместе. В результате мы получили набор из 4000 элементарных единиц — сенонов. Это и есть фонетический алфавит Яндекса, с которым работает наша технология распознавания речи.
Вероятности
В идеальном мире программа безошибочно определяет, какая фонема соответствует каждому фрагменту голосового запроса. Но даже человек иногда может не понять или не расслышать все звуки и достраивает слово исходя из контекста. И если человек опирается на собственный речевой опыт, то наша система оперирует вероятностями.
Во-первых, каждый фрагмент голосового запроса (фрейм) сопоставляется не с одной фонемой, а с несколькими, подходящими с разной степенью вероятности. Во-вторых, есть таблица вероятностей переходов, которая указывает, что после «а» с одной вероятностью будет тоже «а», с другой — «б» и так далее. Это позволяет определить варианты последовательности фонем, а потом, по имеющимся у программы данным о произношении, морфологии и семантике — варианты слов, которые вы могли сказать.
Программа также умеет восстанавливать слова по смыслу. Если вы находитесь в шумном месте, говорите не очень чётко или используете неоднозначные слова, она достроит ваш запрос исходя из контекста и статистики. Например, фразу «мама мыла…» программа с большей вероятностью продолжит как «мама мыла раму», а не как «мама мыла рану». Благодаря машинному обучению на множестве данных наша программа устойчива к шуму, хорошо распознаёт речь с акцентом, качество распознавания практически не зависит от пола и возраста говорящего.
Сейчас наша технология распознавания речи правильно определяет 94% слов в Навигаторе и мобильных Картах и 84% слов в мобильном Браузере. При этом на распознавание уходит около секунды. Это уже весьма достойный результат, и мы активно работаем над его улучшением. Мы верим, что через несколько лет голосовой интерфейс ввода не будет уступать классическим способам.
P.S. Кроме собственно технологии, мы представили на YaC 2013 публичное API для распознавания речи — SpeechKit. С его помощью разработчики могут добавить голосовой поиск Яндекса в свои приложения для Android и iOS. Скачать SpeechKit, а также ознакомиться с документацией, можно здесь.
Источник: yandex.ru
Как работает распознавание речи и где его можно использовать

Голосовой поиск в Google или голосовое управление в машине уже никого не удивляют — мы привыкли к этим технологиям. Они экономят время и делают жизнь комфортнее. Но технология распознавания речи включает гораздо больше возможностей: оптимизацию бизнес-процессов, анализ маркетинговых кампаний, повышение продаж. Как работает распознавание речи и как применить его в бизнесе — читайте в статье.
Что такое распознавание речи
Система распознавания речи — это технология, с помощью которой речь человека возможно трансформировать в текст. Она может работать автономно, а может обучаться особенностям произношения конкретного пользователя.
Распознавание голоса — часть технологии распознавания речи. Идентификацию говорящего используют при биометрической проверке, для ограничения доступа к личным файлам. Система запоминает голос человека и отличает его от других голосов.
Технология распознавания речи, или Speech-to-Text (голос в текст), появилась еще в конце прошлого столетия, но качественно преобразовывать человеческую речь в текст программы научились только в 2000-х — по мере развития IT-технологий и машинного обучения. Сегодня системы распознавания речи массово используют в повседневной жизни и в бизнесе, ведь это заметно экономит ресурсы.
Как работает технология
Это сложный многоступенчатый алгоритм, поэтому постараемся описать общий принцип действия. Если сказать голосовому поиску «Александр Пушкин», телефон услышит не имя известного писателя, а звуковой сигнал без четких границ. Система восстанавливает по этому непрерывному сигналу воспроизведенную человеком фразу следующим образом:
- Сначала устройство записывает голосовой запрос, а нейросеть анализирует поток речи. Волна звука делится на фрагменты — фонемы.
- Затем нейросеть обращается к своим шаблонам и сопоставляет фонемы с буквой, слогом или словом. Далее образуется порядок из известных программе слов, а неизвестные слова она вставляет по контексту. В результате объединения информации с этих двух этапов получается перевод речи в текст.
На заре развития процесс работы Speech-to-Text заключался в элементарной акустической модели — речь человека сопоставлялась с шаблонами. Но количества словарей в системе было недостаточно для точного распознавания, программа часто ошибалась.
Благодаря обучаемости нейронных сетей качество распознавания речи значительно выросло. Алгоритм знает типичную последовательность слов в живой речи и может воспринимать структуру языка — так работает языковая модель. А каждая новая обработанная голосовая информация влияет на качество обработки следующей, уменьшая количество погрешностей.
Где применяют алгоритм
Технология распознавания речи позволяет нам искать нужную информацию, составлять маршрут по навигатору. Вот еще несколько сфер, где использование Speech-to-Text сделало жизнь проще:
- Телефония. Технология экономит не только время звонящего, но и ресурсы компании. С помощью голосового набора и робота клиенты могут без участия менеджеров заказывать товары, отвечать на опросы и получать консультации.
- Бытовая техника и персональный компьютер. Сегодня можно управлять голосом различными устройствами: выключателями, системами освещения и гаджетами. Вы можете обучить свой компьютер распознавать ваш голос (с системами Windows и Mac)
- Медицина. В 2020 году российские разработчики создали Voice2Med — систему на основе искусственного интеллекта, которая заполняет медицинские документы, пока врач диктует информацию во время осмотра.
Как распознавание речи используется в бизнесе
Распознавание речи позволяет автоматизировать многие процессы в бизнесе, от продаж и контроля клиентского сервиса до защиты от мошенников.
С использованием этой технологии аналитика телефонных разговоров с клиентами стала проще и дешевле: система автоматически записывает звонки и собирает данные для повышения конверсии.
Например, система речевой аналитики MANGO OFFICE помогает узнать, с какими конкурентами клиенты чаще всего сравнивают ваш продукт. Вы создаете теги для упоминаний о конкурентах, анализируете отчеты разговоров и понимаете, как нужно улучшить маркетинговую стратегию. Также можно анализировать работу сотрудников — отмечайте стоп-слова, следите за соблюдением скриптов продаж. В случае, когда необходимо транскрибировать речь из видео, можно скачать из него аудиофайл и загрузить его в сервис речевой аналитики. Важно чтобы речь на видео была четкой, поэтому используйте микрофон когда говорите на видео.
Еще одно направление, где речевая аналитика помогает развитию бизнеса — интерактивные голосовые системы (IVR). Это незаменимый инструмент в управлении колл-центром. Speech-to-Text распознает речь клиента, а голосовой робот автоматически подбирает нужную информацию для ответа или переводит звонок на оператора. Технология уменьшает количество потерянных звонков, так как многие люди не успевают или не могут нажимать на кнопки в голосовом меню.
Службам контроля сервиса не обязательно проводить дополнительные опросы: это можно сделать автоматически, а потом проанализировать отчеты. Службы безопасности в банках используют речевую аналитику, чтобы защитить личные данные клиентов.
Заключение
Технология преобразования голоса в текст упрощает повседневные задачи и помогает развивать многие профессиональные сферы. В бизнесе Speech-to-Text используют для эффективного взаимодействия с клиентами и быстрой обработки большого объема данных. Аналитика и голосовые роботы уменьшают затраты, повышают средний чек и изучают реальные потребности клиентов. Речевая аналитика автоматизирует контроль звонков и экономит время. Вы повышаете конверсию в продажу, улучшаете качество обслуживания и получаете фидбек от рынка на понятном языке.
Попробуйте речевую аналитику в деле — получите бесплатный демодоступ на 7 дней!
Источник: www.mango-office.ru