
Пакет STATISTICA – универсальный статистический пакет компании StatSoft Inc1. Первая версия пакета (STATISTICA for DOS ) была выпущена в 1991 г. На сегодняшний день разработана 9-я версия пакета (STATISTICA 9). Русифицирована только 6-я версия (STATISTICA 6).
Стандартную комплектацию пакета STATISTICA составляют три модуля, которые могут приобретаться как единым пакетом, так и отдельно.
- Базовый пакет STATISTICA Base предоставляет обширные возможности выбора основных типов статистического анализа. Для эффективной работы базового пакета требуется как минимум 256 MB оперативной памяти. Минимальные требования к скорости процессора – 500 MHz .
- Модуль Линейные и Нелинейные Модели (Advanced Linear/NonLinearModels) содержит большой набор инструментов для моделирования и прогнозирования, включая возможности автоматического выбора модели и расширенные интерактивные средства визуализации.
- Модуль Многомерные разведочные технологии анализа ( Multivariate Exploratory Techniques) служит для применения разведочного анализа различных типов данных в сочетании с интерактивными средствами визуализации.
Помимо общих статистических и графических средств в системе имеются специализированные модули, например, для проведения социологических или биомедицинских исследований, решения технических и промышленных задач, – карты контроля качества, модули анализа процессов и планирования эксперимента.
Анализ данных в STATISTICA
Разработчики STATISTICA утверждают, что пакет может применяться для решения задач в таких областях, как:
- НИОКР , контроль качества, процесс мониторинга в химической, фармацевтической промышленности и в производстве потребительских товаров;
- гарантийный анализ и приложения для удаленного мониторинга в обрабатывающей промышленности;
- анализ рисков, сегментация потребителей и оценка кредитоспособности заемщиков в банковской сфере, в сфере предоставления финансовых услуг и в страховой деятельности.
Возможны различные варианты установки пакета в зависимости от целей и задач пользователя:
- однопользовательская версия ( Single-User );
- сетевая версия (Concurrent Network) для работы в локальных вычислительных сетях;
- Enterprise – версия для применения в вычислительных системах и крупных организациях
- Web-Based – версия для использования в крупных сетях через веббраузер.
Пакет предоставляет пользователям следующие возможности статистического анализа данных:
- исследование корреляций между переменными;
- диаграмма рассеяния, матричная диаграмма рассеяния;
- быстрые основные статистики и блоковые статистики (интерактивные средства, позволяющие одним щелчком мыши вычислять основные статистики и строить графики в любой момент в течение сеанса работы);
- интерактивный калькулятор вероятностных распределений (позволяет интерактивно исследовать структуру распределений, например, зависимость вероятности от параметров);
- анализ многомерных откликов, многомерное шкалирование;
- анализ при помощи временных рядов и прогнозирование временных зависимостей, в том числе анализ сезонных колебаний.
Достоинства STATISTICA:
Ввод данных STATISTICA #01 | СТАТИСТИКА STATISTICA
- реализован обмен данными между STATISTICAи Windows-приложениями;
- результаты анализа в виде графиков, таблиц и текста могут быть сохранены в файле с форматом RTF, который открывается и редактируется в MS Word;
- возможность расширения системы при помощи создания программ на встроенном в STATISTICA языке программирования;
- исходные данные из MS Excel можно легко импортировать в STATISTICA;
- возможность записи макросов для автоматизации выполнения однотипных задач;
- программа способна обрабатывать большие массивы данных – базы данных с числом переменных до 32 000 и практически неограниченным числом наблюдений.
В пакете представлены несколько сотен типов графиков 2D, 3D и 4D, матрицы и пиктограммы; предоставляется возможность разработки собственного дизайна графика . Средства управления графиками позволяют работать одновременно с несколькими графиками, изменять размеры сложных объектов, добавлять художественную перспективу и ряд специальных эффектов, разбивку страниц и быструю перерисовку. Например, 3D -графики можно вращать, накладывать друг на друга, сжимать или увеличивать 9 Дюк В., Самойленко А. Data Mining: учебный курс (+CD). – СПб: Изд. Питер, 2001. .
STATISTICA обладает огромными возможностями для построения графиков непосредственно из таблиц исходных данных и таблиц результатов. Построение графических объектов и анализ данных в пакете тесно интегрированы. После получения результатов статистического анализа их можно с легкостью представить графически посредством команды Быстрые статистические графики. В разных модулях системы имеются свои специальные графики, учитывающие особенности получаемых в них результатов 10 Борисова С.Ф. Компьютер и Интернет для социолога [электронный ресурс] : учеб. пособие-справочник / С.Ф. Борисова. – Н. Новгород, 2002. – URL: http://www.unn.ru/rus/f14/k2/courses/borisova.htm (29.07.10). .
Начинающие пользователи могут начать работу со специальной версии, разработанной для обучения основам статистических методов – Studеnt Еditiоn оf STATISTICA. Эта версия представляет собой урезанный вариант пакета и позволяет анализировать файлы данных, включающих не более 400 наблюдений.
Внешний вид диалогового окна STATISTICA представлен на рис.11.5.
11.6. Пакет STATGRAPHICS
Пакет STATGRAPHICS (STATistical GRAPHICs System) 11 Официальный сайт пакета STATGRAPHICS: http://www.statgraphics.com – универсальный статистический пакет компании Manugistics Inc 12 Официальный сайт компании Manugistics Inc.: www.manugistics.com . Первая версия пакета была выпущена в середине 80-х годов. На сегодняшний день разработана 5-я версия пакета Statgraphics Plus 5.1.
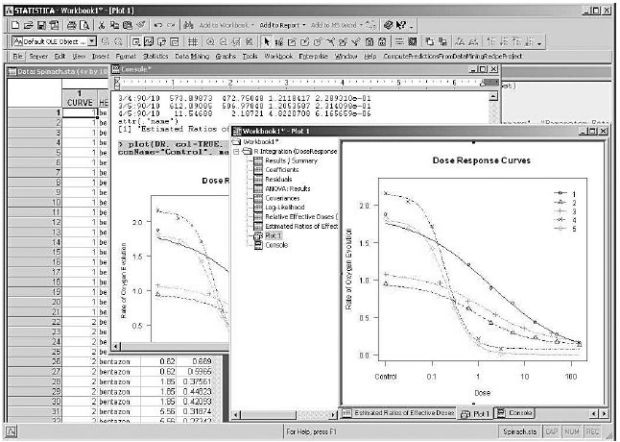
Рис. 11.5. Диалоговое окно STATISTICA
Достоинства STATGRAPHICS:
- сочетание научных методов обработки разнотипных данных с возможностью создания современной высококачественной интерактивной графики;
- широкие возможности взаимодействия с другими программными продуктами (электронными таблицами, базами данных);
- высококачественная двумерная и трехмерная графика,
- интегрированная графика, предполагающая, что все элементы графических представлений результатов анализа могут быть преобразованы. После завершения процедуры статистического анализа данных можно выбрать графические отображения результатов, релевантные используемой процедуре анализа.
В STATGRAPHICS графика из средства презентации результатов анализа превращается в аналитический инструмент: можно идентифицировать точку на графическом отображении и выяснить ее местонахождение в файле данных или вращать и рассматривать с разных сторон трехмерные изображения, осуществлять разгонку точек на диаграммах рассеяния и т. п. 13 Обработка данных на ПК в примерах / В. Дюк . – СПб. : Питер, 1997 . – 240 с. 1
В STATGRAPHICS существует возможность сохранения результатов работы и создания собственных статистических проектов. После завершения анализа пользователь может сохранить последовательность выбранных методов, параметры статистических процедур, виды графических отображений результатов анализа, табличные формы, комментарии и пр. в отдельном файле. Сохраненную схему анализа можно будет автоматически применять к другому множеству данных.
Внешний вид диалогового окна STATGRAPHICS представлен на рис.11.6
Источник: intuit.ru
Создание нового файла в программе Statistica 6.0
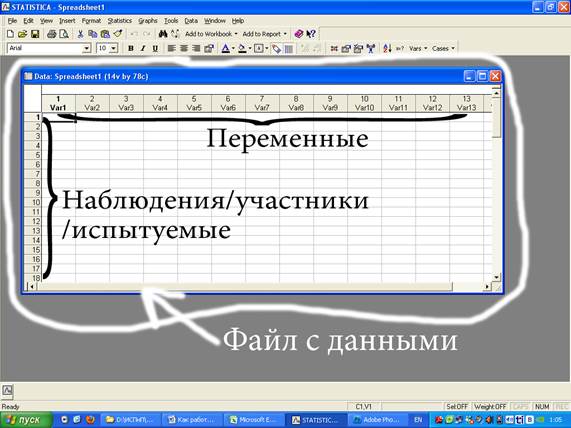
Каждая строка таблицы – один участник исследования. То есть, если всего обследованы, например, 42 человека (и экспериментальная, и контрольная группа вместе), то таблица содержит 42 строки плюс заголовки.
(В примере, о котором пойдет речь дальше, 78 участников исследования)
Каждый столбец таблицы – переменная.
При подготовке данных переменной будем считать любую информацию об участнике исследования. Например, первой переменной – первым столбиком таблицы – может стать порядковый номер или даже какое-то уникальное имя испытуемого. Само по себе имя в исследовании НЕ требуется. Оно может пригодиться только для того, чтобы точно и аккуратно внести всю информацию по этому конкретному человеку.
Следующей переменной может являться тип группы – экспериментальная или контрольная. Можно так и назвать переменную – «группа». Для всех участников исследования надо заполнить эту переменную. Обратите внимание: для всех участников ОДНОЙ группы следует использовать ОДНО И ТО ЖЕ обозначение.
Например, эксп.г. – для всех участников экспериментальной группы, контр.г. – для всех участников контрольной группы. Далее можно указать пол участников исследования.
В файле с примером данных первой переменной является пол (Pol). Следующей переменной является возраст (Age). Здесь просто указан возраст в годах. Далее следует переменная Edu – уровень образования. Эта переменная может принимать только 3 значения – «средне-спец.», «высшее», «неполное высшее».
Далее указан стаж в годах. Следующая переменная – семейное положение, тоже может принимать несколько значений. В этом примере первые шесть переменных содержат общую социально-демографическую информацию; это еще не методики.
Далее идут методики. Переменная номер 7 – Результат методики «Уровень профессионального стресса», может принимать значения от 0 до 60. Переменная 8 – уровни проф.стресса, рассчитанные по данным методики.
Следующие три переменные – №9, 10, 11 – соответствуют трем шкалам методики Маслач (название шкал сейчас нам не важны). Каждая из них может принимать значения от 0 до определенного уровня, сейчас это не важно.
Переменные 12, 13 и 14 – оценки компонентов социально-психологического климата: эмоциональный, когнитивный и поведенческий компоненты. Рассчитываются по методике. Могут принимать только три значения -1, 0, 1.
Итого в нашем примере получаем 14 переменных.
Обращаю Ваше внимание на то, что переменные бывают разные. Нас будет интересовать в первую очередь разделение переменных на метрические и номинативные. Метрические переменные – например, возраст, показатели по шкале интеллекта, и др. – могут принимать разные значение в определенном диапазоне, причем большее или меньшее значение соответствует большему или меньшему уровню измеряемого признака.
Номинативные переменные могут принимать фиксированное число значений. Например, переменная «пол». Может принимать два значение – М или Ж. Переменная «уровень образования»: может принимать три значения – средне-спец., высшее, неполное высшее. Переменная «тип группы» – тоже номинативная, она задает принадлежность участника к экспериментальной или к контрольной группе.
Вопрос: определите, какие переменные из Вашего исследования являются метрическими, какие – номинативными. Это крайне важно для выбора методов исследования.
Результатом данного этапа работы является таблица с данными (составленная на бумаге или – лучше – в программе Excel), плюс понимание, какие переменные являются метрические, какие – номинативными.
Создание нового файла в программе Statistica 6.0
Откройте программу и выберите в верхнем меню File – New. (Рекомендую пользоваться английской версией программы)

Появится окно, в котором можно выбрать необходимое количество переменных (Number of Variables) и количество наблюдений (Number of Cases). В нашем примере будет 14 переменных и 78 наблюдений. Нажмите ОК.
 è
è 
Получим чистый файл, в который можно вносить результаты исследования. Возможно, этот лист будет виден не полностью, поэтому снизу и справа есть полосы прокрутки.
Результатом данного этапа является чистый лист, на который можно вносить результаты исследования.
Пример такого листа ниже.

Аальтернативная стоимость. Кривая производственных возможностей В экономике Буридании есть 100 ед. труда с производительностью 4 м ткани или 2 кг мяса.

Вычисление основной дактилоскопической формулы Вычислением основной дактоформулы обычно занимается следователь. Для этого все десять пальцев разбиваются на пять пар.
Расчетные и графические задания Равновесный объем — это объем, определяемый равенством спроса и предложения.
Кардиналистский и ординалистский подходы Кардиналистский (количественный подход) к анализу полезности основан на представлении о возможности измерения различных благ в условных единицах полезности.
Меры безопасности при обращении с оружием и боеприпасами 64. Получение (сдача) оружия и боеприпасов для проведения стрельб осуществляется в установленном порядке[1]. 65. Безопасность при проведении стрельб обеспечивается.
Весы настольные циферблатные Весы настольные циферблатные РН-10Ц13 (рис.3.1) выпускаются с наибольшими пределами взвешивания 2.
Хронометражно-табличная методика определения суточного расхода энергии студента Цель: познакомиться с хронометражно-табличным методом определения суточного расхода энергии.
Билиодигестивные анастомозы Показания для наложения билиодигестивных анастомозов: 1. нарушения проходимости терминального отдела холедоха при доброкачественной патологии (стенозы и стриктуры холедоха) 2. опухоли большого дуоденального сосочка.
Сосудистый шов (ручной Карреля, механический шов). Операции при ранениях крупных сосудов 1912 г., Каррель – впервые предложил методику сосудистого шва. Сосудистый шов применяется для восстановления магистрального кровотока при лечении.
Трамадол (Маброн, Плазадол, Трамал, Трамалин) Групповая принадлежность · Наркотический анальгетик со смешанным механизмом действия, агонист опиоидных рецепторов.
Источник: studopedia.info
Пакет статистических программ Statistica
Данная система задумывалась как полная статистическая система для пользователей персональных компьютеров, не привыкших к работающим в пакетном режиме ранних версий других статистических пакетов SAS или SPSS. С самого начала эта программа обладала развитым графическим интерфейсом и опиралась на поддержку высококачественной графики для анализа данных.
Система состоит из ряда модулей, работающих независимо. Это означает, что все методы статистической обработки, реализованные в системе, разбиты на несколько групп модулей, в соответствии с разделами статистического анализа. Например, модуль Basic Statistica and Tables (Основные статистики и таблицы) содержит основные описательные статистики, методы статистического анализа различных таблиц, разносторонний инструментарий для проведения разведочного анализа данных. Имеется Multiple Regression (Многомерная регрессия), ANOVA (Дисперсионный анализ), Nonparametrics (Непараметрические статистики), Распределения (Distribution Fitting) и многие другие. Графики в данной системе строятся как из общего меню, так и из подменю процедур, что очень облегчает начинающим выбор адекватного графического представления данных.
Почти все процедуры являются интерактивными, т.е. для запуска обработки необходимо выбрать из меню переменные и ответить на ряд вопросов системы. Это очень удобно для начинающего пользователя, однако резко замедляет деятельность опытного и не позволяет эффективно повторять одну и ту же процедуру несколько раз.
Пакет Statisticaявляется наиболее динамично развивающимся статистическим пакетом и по многочисленным рейтингам является мировым лидером на рынке статистического программного обеспечения.
Знакомство с интерфейсом программы. Меню типа File (Файл), Edit (Правка), Window (Окно), Help (Справка), стандартны для любых приложений Windows и не вызовут сложностей. Основные файлы пакета имеют расширение *.sta.
Создание файла. В меню Файл (File) выберите Новый (New). Выбрать 10×10. ОК. Данные в программе Statistica представлены электронной таблицей. Все столбцы называются Переменные (Variables), сокращённо Var 1, Var 2, Var 3 и т.п. Все строки называются Наблюдения (Cases), обозначены простыми арабскими цифрами. Изменение количества строк или столбцов.
Для увеличения количества строк нажмите кнопку Наблюдения (Cases) и, из предлагаемого меню, выберите функцию Добавить (Add). В возникшем окне измените Число наблюдений (How many) на 1, а Вставить после (Insert after case) на 10. Нажмите OK. Мы получим добавление одной строки после 10-ой. Для увеличения количества столбцов используйте кнопку Переменные (Vars).
Аналогично выбрав функцию Добавить (Add) измените Число переменных (How many) на 1, а Вставить после (After) на 10. Нажав OK, мы получим добавление одного столбца после 10-ого.
Для того чтобы изменить имя столбца или строки подведите курсор к ячейке с именем и произведите на ней двойной щелчок мыши. В появившемся окне, в ячейке Имя (Name) наберите название ячейки и нажмите OK.
Описательные статистики. Создайте таблицу:
| Уровень | Частота |
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 |
Найдите меню Статистических модулей (Statistics). Выберите функцию Основные статистики и таблицы (Basic Statistics/Tables). Нажмите OK. В проявившемся списке найдите Описательные статистики (Descriptive Statistics) и нажмите OK. В окне найдите кнопку Переменные (Variables).
В новом окне выберите переменную Уровень. Нажмите ОК. Вернувшись в предыдущее окно, нажмите кнопку В (W). Должно появиться окно Задание веса (Analysis/Graph Case Weights). Двойным щелчком мыши вызовите в графе Вес из переменной (Weight variable) новое окно.
В нём выберите переменную Частота. Нажмите ОК. Вернувшись в окно Задание веса (Analysis/Graph Case Weights), нажмите ОК.

Во вкладке Advanced выберите следующие показатели: Минимум и максимум (Minimum No. of ties (число совпадающих значений) = 0. Определяющим является значение параметра Z, который приближается к нормальному распределению если нулевая гипотеза верна (Z = 1,2185).
Критерий Краскела-Уоллиса служит для проверки гипотезы о том, что k выборок разных объёмов были получены из одной генеральной совокупности. В модуле непараметрических критериев выберите строчку «comparing multiple independent samples (groups)». Задайте зависимую и независимую переменные (в качестве примера используйте типовой файл Kruskal.sta. Зависимая переменная здесь – PERFRMNC, независимая — CONDITN), задайте коды для групп. Вспомогательными являются диаграммы размаха и категоризированные гистограммы.
Нажимаем кнопку Summary и получаем данные. Потом переключаемся на таблицу критерия Краскела-Уоллиса. Определяющим здесь является H -критерий, который сравнивается с квантилем распределения хи-квадрат и в случае когда гипотеза отклоняется.
Оцените нулевую гипотезу самостоятельно (для данного случая табличное значение хи-квадрат (4-1) равно 7,81).
Q-критерий Кохрена применяется только для бинарных данных (принимающих только два возможных значения). Рассмотрим пример. Для оценки четырёх видов мороженного ряду испытуемых предложили его продегустировать и дать бинарную оценку («нравится» или «не нравится», которую мы обозначим в виде «1» и «0» соответственно). Данные представим данные в виде таблицы.
Проверим нулевую гипотезу о том, что все виды продукта нравятся покупателям в равной степени. Рассчитаем Q-критерий Кохрена (модуль «Cochran Q test»). В таблице результатов даны суммы для каждой переменной, а также процент нулей и единиц. Сравниваем Q-критерий с хи-квадрат (табличное значение то же, что и в предыдущем случае). Если гипотеза отклоняется.
В нашем случае Q = 7,142857, т.е. гипотеза принимается.
| Пломбир | Эскимо | С шоколадом | С фруктами |
| Условия хранения | Содержание влаги |
| 10,1; 7,3; 5,6; 6,2; 8,4; 8,0; 7,6; 5,3; 7,2 | |
| 11,7; 12,2; 11,8; 7,8; 8,9; 8,9; 12,4; 11,0; 10,3; 13,8; 10,5; 9,8; 9,1 | |
| 10,2; 12,0; 8,8; 8,7; 10,5; 11,0; 9,1 |
Преобразуем таблицу, присвоив каждому элементу ряда код соответствующей строки. В модуле Statistics запустить модуль Основные статистики и таблицы (Basic Statistics/Tables). ОК. Здесь выберите модуль Breakdown and one-way ANOVA (Однофакторный дисперсионный анализ). Задаём Variables (Переменные) – зависимыми переменными будут значения, а группирующими коды строк. Задайте коды строк.
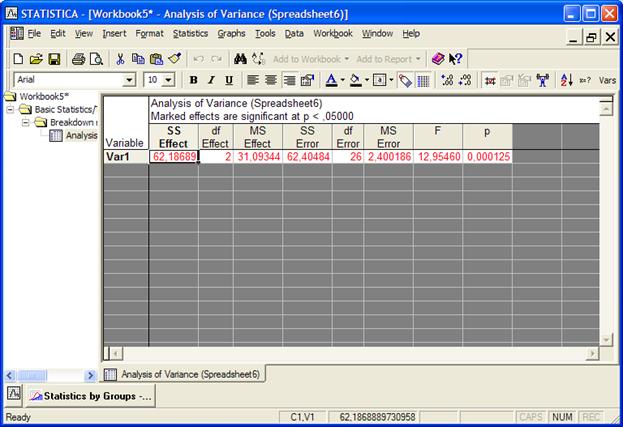
Для получения таблицы дисперсионного анализа нажмите на кнопку Analysis of Variance.
§ SS Effect – мера факториальной изменчивости;
§ df Effect – число степеней свободы факториальной изменчивости;
§ MS Effect – дисперсия факториальной изменчивости;
§ SS Error – мера остаточной изменчивости;
§ df Error – число степеней свободы остаточной изменчивости;
§ MS Error – дисперсия остаточной изменчивости;
§ F – критерий Фишера;
§ p – уровень значимости.
Вычисленный уровень значимости меньше заданного, следовательно, гипотезу о равенстве средних отвергаем. Вывод – условия хранения продукта значимо влияют на влажность.
Для таблицы из лабораторной работы №2 проведите анализ и сравните с ранее полученными вами результатами.
Регрессионный анализ. В пакете Statistica для регрессионного анализа используется модуль Multiple Regression (Множественная регрессия). Рассмотрим пример расчёта модели регрессионного анализа. Дано:
| Примеси | Октановое число |
| 96,3 | |
| 95,7 | |
| 99,9 | |
| 99,4 | |
| 95,1 | |
| 97,8 | |
| 99,3 | |
| 104,9 |
Требуется определить наличие связи между наличием примесей и октановым числом бензина. Выберите модуль Multiple Regression (Множественная Регрессия). Задаём переменные: зависимая переменная – октановое число. Нажимаем кнопку ОК. Получаем результаты:

§ Dependent (Зависимая переменная).В нашем случае «октановое число».
§ No. of Cases (Число наблюдений). Здесь равно 8.
§ Multiple R (Коэффициент множественной корреляции). В случае просто линейной регрессии равен коэффициенту корреляции Пирсона.
§ R 2 (Квадрат коэффициента множественной корреляции). Также известен как коэффициент детерминации. Показывает долю общего разброса (относительно выборочного среднего зависимой переменной), которая объясняется построенной регрессией (изменяется от 0 до 1).
В нашем случае равен 0,7134337, т.е. построенная регрессия объясняет более 71% разброса значений переменной «Октановое число».
§ Adjusted R 2 (Скорректированный коэффициент детерминации).
где n – число наблюдений в модели; p – число параметров модели (число независимых переменных +1, т.к. в модель включён свободный член регрессии).
§ Standard error of estimate (Стандартная ошибка оценки). Определяется как среднее квадратическое отклонение ошибок наблюдений.
§ Intercept (Оценка свободного члена регрессии), т.е. значение коэффициента b0 в уравнении регрессии.
§ Std. Error (Стандартная ошибки свободного члена).
Если p < α (0,05), то нулевая гипотеза отклоняется (наш случай, т.к. p = 0,008315), а если p > α (0,05), то соответственно гипотеза принимается. Следовательно, в нашем случае значение b0 является достоверным. Если выбрать «Summary: Regression results», то можно также увидеть дополнительно другие значимые коэффициенты регрессионной модели.

Для оценки адекватности модели также требуется проанализировать значение F -критерия (критерий Фишера) и рассчитанный для него p -критерий. В нашем случае критерий Фишера равен F(1,6)=14,938 на уровне значимости p 0,0083. Значения весьма значимы и следовательно нулевая гипотеза об отсутствии линейной зависимости (b1 = 0) между переменными отвергается. Модель простой линейной регрессии в этом случае принимает следующий вид:
По этой модели легко спрогнозировать значение октанового числа при добавлении различных примесей.
Самостоятельная работа. На основании данных нижеприведенной таблицы произведите полную процедуру регрессионного анализа. Температура всегда зависимая переменная, независимые переменные меняются (исследуйте все варианты).


Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем.

Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам.

ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между.

Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
Источник: zdamsam.ru