
237. Автоматический анализ программы [MAP+и проверка]
Программа автоматический анализ
описывать
В процессе реализации автоматического анализа программы часто необходимо определить, могут ли некоторые ограничения быть достигнуты одновременно.
Рассмотрим упрощенную версию ограничений, чтобы удовлетворить проблему: при условии, что x1, x2, x3, . x1, x2, x3, . Представьте переменные, которые появляются в программе, заданные n -образные переменные, такие как xi = xjxi = xj или xjxi ≠ xj. Для эквивалентных/неравных условий, пожалуйста, определите, можете ли вы дать соответствующие значения каждой переменной, чтобы все вышеупомянутые ограничения могли быть выполнены одновременно.
Например, ограничения в задаче: x1 = x2, x2 = x3, x3 = x4, x1 ≠ x4x1 = x2, x2 = x3, x3 = x4, x1 ≠ x4, эти ограничения явно невозможно удовлетворить в В то же время в то же время. Поэтому эта проблема должна рассматриваться как не удовлетворенная.
Теперь дайте некоторые ограничения для решения проблемы, пожалуйста, определите их.
11 секретов ставок! ТОП сайтов для анализа футбольных матчей (xG, средняя статистика, прогрузы )
Входной формат
Первая строка входного файла содержит 1 положительное целое число T, указывая на количество вопросов, которые необходимо определить, и обратите внимание на независимое от этих проблем.
Для каждой проблемы он содержит несколько поведений:
Первая строка содержит 1 положительное целое число N, указывая на то, что количество ограничений, которые необходимо выполнить в этой проблеме.
Следующая n строка, каждая строка включает в себя 3 целого числа I, J, E, описывает 1 равные/разные ограничения и разделен одним пространством между соседними целыми числами. Если e = 1, ограничение равно xi = xjxi = xj; если e = 0, условие ограничения является xi ≠ x x ≠ ≠ xj.
Выходной формат
Выходной файл включает в себя t -строку.
Первая k -строка из выходного файла выводит строку «да» или «нет» (исключая цитаты, все буквы), «да» указывает на то, что k -вопрос на вводе определяется как удовлетворение, «нет» означает что это не может быть затронуто удовлетворить.
диапазон данных
Введите пример:
2 2 1 2 1 1 2 0 2 1 2 1 2 1 1
Выходной образец:
NO YES
отвечать:
Добавьте коллекцию, когда она равна, и сохраните ее, если вы не приравниваете;
Наконец, судите, находится ли неудовлетворительный из них в коллекции;
Код:
#include #include //EOF,NULL #include //memset #include //rand,srand,system,itoa(int),atoi(char[]),atof(),malloc #include //ceil,floor,exp,log(e),log10(10),hypot(sqrt(x^2+y^2)),cbrt(sqrt(x^2+y^2+z^2)) #include //fill,reverse,next_permutation,__gcd, #includestring> #include #include #include #include #include #include //setw(set_min_width),setfill(char),setprecision(n),fixed, #include #include #includeset> #include //INT_MAX #include // bitset n using namespace std; typedef long long LL; typedef long long ll; typedef pairint,int> P; #define all(x) x.begin(),x.end() #define readc(x) scanf(«%c»,%d»,%d%d»,y) #define read3(x,y,z) scanf(«%d%d%d»,y,%dn»,x) #define mst(a,b) memset(a,b,sizeof(a)) #define lowbit(x) x const int mod = 1e9+7; const int MAXN = 1000000+10 ; int tot,cnt,flag; int t,n; int a,b,c; int pre[MAXN * 2]; int wrong1[MAXN],wrong2[MAXN]; mapint,int> H; int mapping(int x) if (H.count(x)) return H[x]; return H[x] = ++ cnt ; > int find(int x) return x == pre[x] ? x : pre[x] = find(pre[x]); > void join(int x,int y) if(find(x) != find(y))< pre[find(y)] = find(x); > > int main()< read(t); while(t—)< cnt = 0; tot = 0; memset(wrong1,0,sizeof wrong1); memset(wrong2,0,sizeof wrong2); read(n); for(int i = 1;i 2; i++) pre[i] = i ; H.clear(); for(int i = 0; i < n; i++)< read3(a,b,c); a = mapping(a) ; b = mapping(b); if(c) else< wrong1[tot] = a, wrong2[tot] = b; tot++; > > flag = 1; for(int i = 0; i < tot; i++) if(find(wrong1[i]) == find(wrong2[i]))< flag = 0; break; > > if(flag) printf(«YESn»); else printf(«NOn»); > >
Источник: russianblogs.com
Ты Должен ЭТО Совмещать! ПРИНЦИПЫ и ОСНОВЫ Технического Анализа! Обучение Трейдингу!
Правила анализа программ
Основными алгоритмическими конструкциями в процедурном программировании являются следование, ветвление и цикл. Для получения функций трудоемкости для лучшего, среднего и худшего случаев при фиксированной размерности входа необходимо учесть различия в оценке основных алгоритмических конструкций.
· Трудоемкость конструкции «Следование» есть сумма трудоемкостей блоков, следующих друг за другом: f=f1+f2+. +fn.
· Трудоемкость конструкции «Ветвление» определяется через вероятность перехода к каждой из инструкций, определяемой условием. При этом проверка условия также имеет определенную трудоемкость. Для вычисления трудоемкости худшего случая может быть выбран тот блок ветвления, который имеет большую трудоемкость, для лучшего случая – блок с меньшей трудоемкостью. fif=f1+fthen*pthen+felse*(1-pthen)
· Трудоемкость конструкции «Цикл» зависит от вида цикла. Для цикла с параметрами будет справедливой формула: ffor=1+3n+nf, где n – количество повторений тела цикла, f – трудоемкость тела цикла.
Реализация цикла с предусловием и с постусловием не меняет методики оценки его трудоемкости. На каждом проходе выполняется оценка трудоемкости условия, изменения параметров (при наличии) и тела цикла. Общие рекомендации для оценки циклов с условиями затруднительны. Так как в значительной степени зависят от исходных данных.
В случае использования вложенных циклов их трудоемкости перемножаются.
Таким образом, для оценки трудоемкости алгоритма может быть сформулирован общий метод получения функции трудоемкости.
1. Декомпозиция алгоритма предполагает выделение в алгоритме базовых конструкций и оценку их трудоемкости. При этом рассматривается следование основных алгоритмических конструкций.
2. Построчный анализ трудоемкости по базовым операциям языка подразумевает либо совокупный анализ (учет всех операций), либо пооперационный анализ (учет трудоемкости каждой операции).
3. Обратная композиция функции трудоемкости на основе методики анализа базовых алгоритмических конструкций для лучшего, среднего и худшего случаев.
Примеры:
Пример 1 Задача суммирования элементов квадратной матрицы
SumM (A, n; Sum)
For i 1 to n
For j 1 to n
Sum Sum + A[i,j]
Алгоритм выполняет одинаковое количество операций при фиксированном значении n, и следовательно является количественно-зависимым. Применение методики анализа конструкции «Цикл» дает:
FA(n)=1+1+ n *(3+1+ n *(3+4))=7 n 2 +4* n +2 = Q(n 2 ), заметим, что под n понимается линейная размерность матрицы, в то время как на вход алгоритма подается n 2 значений.




Пример 2 Задача поиска максимума в массиве
MaxS (S,n; Max)
For i 2 to n
then Max S[i]
Как правильно анализировать матчи для ставок на спорт

Правильный беттинг — это не удача и азарт, а кропотливый анализ, основанный на десятке статистических факторов. Только так можно добиться высокого винрейта (процента побед) и, следовательно, стабильного заработка. Далее расскажем, как правильно анализировать матчи для ставок.
Статистический анализ
Статистика – основа любого анализа, не только для ставок. Изучая результаты команд, можно с высоким винрейтом предугадывать результаты (количество голов, победитель и т.д.). Рассмотрим отдельно наиболее важные критерии.
Анализ домашних матчей
- Поддержка болельщиков.
Фактор психологического настроя даже в профессиональном спорте имеет значение. Неоднократно доказано на практике – поддержка фанатов помогает игрокам демонстрировать более высокий результат.
Пример – ФК «Ротор» (Волгоград). Когда он выступал в ПФЛ (третья по значимости лига в России), на стадион стабильно приходило по 12 тысяч человек. Во многом благодаря этому «Ротор» исправно набирал очки дома и в итоге вышел в ФНЛ. 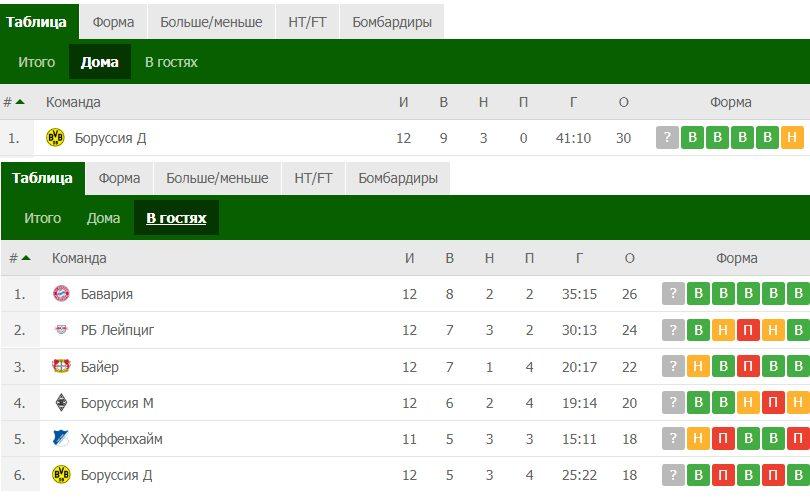
- Географическая отдаленность. Данный аспект актуален только для больших стран. Так, когда в РФПЛ выступали дальневосточные клубы («Луч» и «СКА-Хабаровск») большую часть очков они набирали именно дома. Это связано с тем, что их оппонентам приходилось выдерживать длительные перелеты, разницу часовых поясов и акклиматизацию. Как итог – снижение физических кондиций. В качестве примера приведем результаты «СКА-Хабаровск» в РФПЛ сезона 2017/2018.
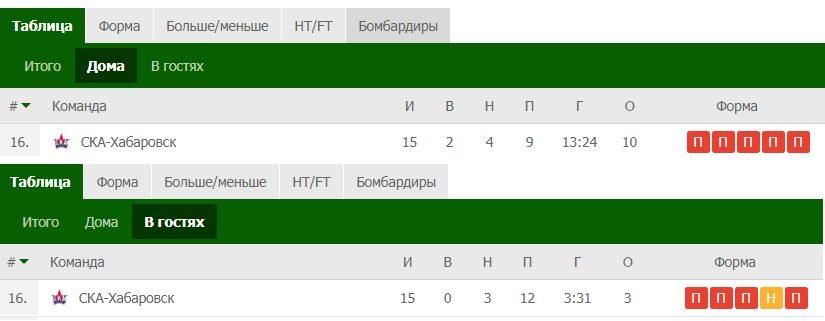
Средняя результативность
Перед тем как ставить на тотал, необходимо учесть два фактора:
- Результативность за последнее время.
- Надежность обороны, среднее количество пропущенных мячей.
То есть открывается статистика последних 10-20 встреч. Высчитывается среднее количество забитых/пропущенных мячей. На основании этих данных определяется ожидаемый тотал (больше или меньше).
Факторный анализ
Под данным понятием подразумеваются субъективные аспекты, не связанные со статистикой. Однако чтобы эффективно анализировать матчи для ставок их тоже необходимо учитывать.