
Команда Frequencies (Частоты) являются одной из самых простых и часто используемых команд SPSS. Действие команды сводится к подсчету количества объектов в каждой категории переменной. Эти и называется распределением частот по категориям переменной.
Для создания частотных распределений в меню Analyze (Анализ) нужно выбрать команду Descriptive Statistic (Описательные статистики), затем Frequencies (Частоты). Появится диалоговое окно.
В левой части окна расположен список всех доступных переменных. В нем необходимо выбрать те переменные, для которых необходимо вычислить распределение частот. Для этого щелчком выделяется нужная переменная и с помощью кнопки с треугольником перемещается в целевой список Variable(s) (Переменные).
Если необходимо удалить переменную из целевого списка, достаточно выделить ее в нем, затем воспользоваться кнопкой с направленной влево стрелкой, переменная вновь переместиться в исходный список. Чтобы полностью очистить целевой список, можно щелкнуть на кнопке Reset (Сброс).
Как посчитать процент выполнения плана в Excel
После создания целевого списка, для получения частотных распределений, нужно щелкнуть на кнопке ОК. Программа SPSS сформирует окно вывода с результатами выполнения команды.
Пример частотного распределения вопроса: «За какую партию Вы голосовали бы в ближайшее воскресенье?» (опрос проводился в 2006 г.)
Интерпретация данных таблицы частотных распределений по вопросу: «За какую партию Вы проголосовали бы в ближайшее воскресенье?» В опросе принял участие 316 респондентов (по строке Total), из них 7 респондентов или 2,2% из общего числа не ответили на поставленный вопрос. Из тех респондентов, кто ответил на вопрос анкеты, большинство – 37,3% опрошенных — проголосовали бы за «Единую Россию», на втором месте – респонденты с протестным голосованием – «против всех» проголосовали бы 12,0%, на третьем – приверженцы партии ЛДПР – 11,7%. Достаточно много респондентов – 14,2% — заявили, что они не стали бы участвовать в выборах, и столько же затруднились с ответом.
Ниже дана трактовка терминов, используемых программой в окне вывода данных.
§ Frequency (Частота) – число объектов, соответствующих каждой категории (градации) переменной (число респондентов, выбравших соответствующий вариант ответа)
§ Percent (Процент) – процент от общей численности (с учетом пропусков). Если в файле есть пропущенные значения, то их процент указан в предпоследней строке Missing System.
§ Valid percent (Валидный процент) – процент значений для каждой категории за вычетом пропущенных значений.
§ Cumulative percent (Кумулятивный процент) – накопленный процент величины Valid percent.
§ Valid (Валидные значения) – список градаций (значений) переменной.
§ Total (Итого) – итоговые значения.
Столбиковые диаграммы. Для того, чтобы создать столбиковую диаграмму для дискретных данных (например, распределение респондентов по полу, предпочтений в выборе партий) необходимо в диалоговом окне Frequencies (Частоты) щелкнуть на кнопке Charts (Диаграммы) и выбрать тип диаграммы с помощью переключателей Bar charts (Столбиковая), Pie charts (Круговая), Histograms (Гистограмма).
Начало работы с SPSS: описательные статистики
В зависимости от величины, которую нужно использовать для отображения частот, в группе Chart Values (Значения в диаграмме) устанавливается переключатель Frequencies (Частоты) Percentages (Проценты). Для закрытия диалогового окна нужно щелкнуть на кнопке Continue (Продолжить). Для завершения операции в диалоговом окне Frequencies щелкнуть на кнопке ОК. После этого программа сгенерирует диаграмму, соответствующую выбранной переменной. Созданные диаграммы можно просмотреть в окне вывода, просмотра данных.
Гистограммы. Используются для отображения распределения частот непрерывных переменных (например, переменная возраста, или переменные отражающие среднюю отметку учащегося и т.д.). Для построения гистограммы в диалоговом окне Frequencies (Частоты) щелкнуть на кнопке Charts (Диаграммы), выбрать тип диаграммы — Histograms (Гистограмма).
Если необходимо установить флажок With normal curve (с нормальной кривой), щелкнуть на кнопке Continue (Продолжить), вернуться в окно Frequencies. Затем сбросить флажок Display frequencies tables (показывать таблицы частот) и щелкнуть на кнопке ОК. Справа от гистограммы помещены вычисленные параметры: среднее значение (Mean), стандартное отклонение распределения (Std.Dev), а также общее число объектов (N).
Задание. 1.По массиву данных opros.sav вычислить частотные (линейные) распределения вопросов: «Играет ли молодежь заметную роль в общественной жизни города?», «Как вы относитесь к политической деятельности?», «Удовлетворены ли вы уровнем своего образования?». Построить диаграммы. Проанализировать полученные данные.
2. Исходя из задач собственного исследования, создать линейные распределения для переменных анкеты. Построить диаграммы. Проанализировать полученные данные.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник: studopedia.ru
ЛБ_7
Таблицы сопряженности или кросстабуляции служат для описания связи двух или более номинальных (категориальных) переменных.
1. Построение таблиц сопряженности
1.1. Реализация в SPSS
Для составления таблиц сопряженности в программе SPSS необходимо выполнить следующую последовательность команд:
Analyze (Анализ) — Descriptive Statistics (Описательные статистики) –
Crosstabs (Кросстабуляции)
В результате откроется диалоговое окно (рис.1), в котором необходимо задать переменные, отражаемые в виде строк и в виде столбцов.

Рис.1. Диалоговое окно Crosstabs
Пример построения таблицы сопряженности для переменных food и diet представлен на рис.2.
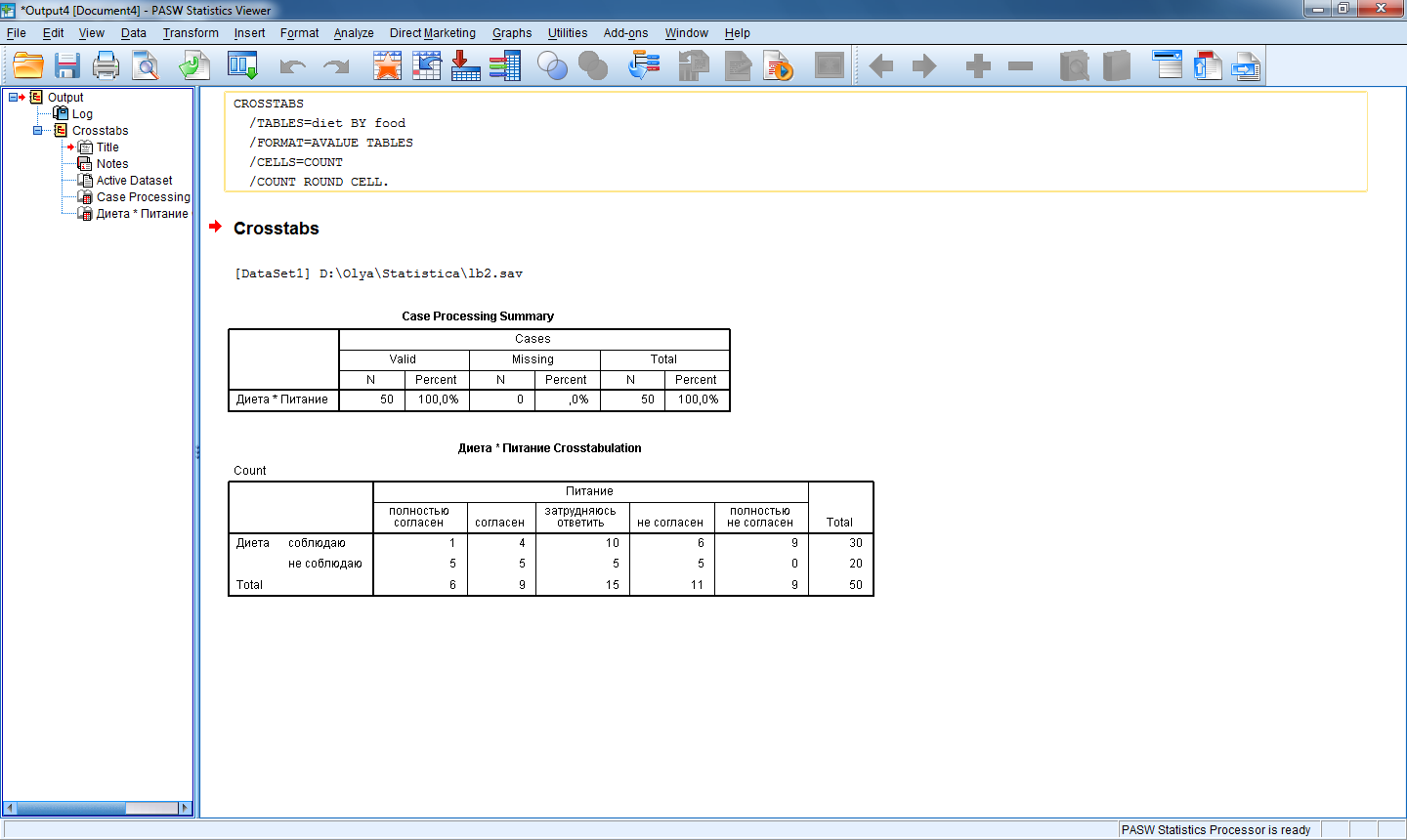
Рис.2. Простая таблица сопряженности для переменных food и diet
Раздел Layer в диалоговом окне Crosstabs (рис.1.) позволяет создавать многоуровневые таблицы сопряженности для трех и более переменных.
Пример построения многоуровневой таблицы сопряженности для переменных food, diet и profit представлен на рис.3.

Рис.3. Многоуровневая таблица сопряженности для переменных food, diet и profit
1.2. Реализация в STATISTICA
Для составления таблиц сопряженности в программе STATISTICA необходимо выполнить следующую последовательность команд:
Statistics (Статистики) – Basic Statistics / Tables (Основные статистики и таблицы) – Tables and banners (Таблицы и заголовки)
В результате откроется диалоговое окно (рис.4.), в котором для построения простой таблицы сопряженности необходимо перейти на вкладку Stub-and-banner и указать переменные для анализа.

Рис.4. Диалоговое окно Crosstabulation tables
После нажатия кнопки ОК открывается окно результатов (рис.5).

Рис.5. Диалоговое окно Для
Затем, нажав на кнопку Stub-and-banner table, на экран будет выведена результирующая таблица.
Пример построения таблицы сопряженности для переменных food и diet представлен на рис.6.

Рис.6. Простая таблица сопряженности для переменных food и diet
Чтобы построить многоуровневую таблицу сопряженности, необходимо в диалоговом окне Crosstabulation tables (рис.4.) перейти на вкладку Crosstabulation и указать переменные для анализа. После нажатия кнопки ОК открывается окно результатов (рис.7.).

Рис.7. Диалоговое окно Crosstabulation tables Results
В диалоговом окне Crosstabulation tables Results, нажатием кнопки Review summary tables (Посмотреть таблицу результатов) или кнопки Summary открывается многоуровневая таблица сопряженности.
Пример построения многоуровневой таблицы сопряженности для переменных food, diet и profit представлен на рис.8.
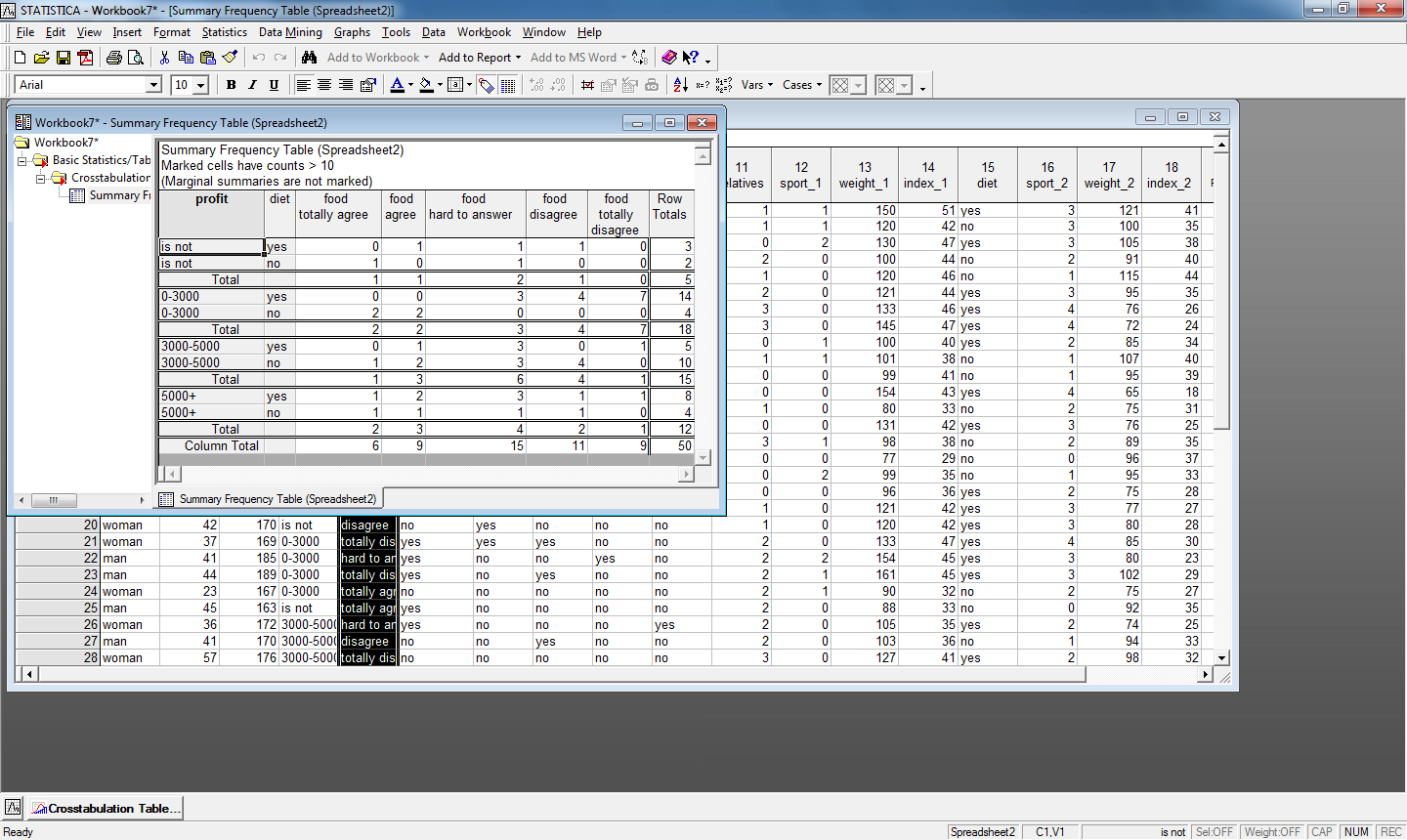
Рис.8. Многоуровневая таблица сопряженности для переменных food, diet и profit
2. Критерий хи-квадрат.
Основной целью построения таблиц сопряженности является выявление взаимосвязи между двумя исследуемыми признаками или выявление соответствия совместного распределения теоретическому. Основным инструментом для проведения подобного рода исследований является тест хи-квадрат.
Для проведения теста хи-квадрат на соответствие реального распределения теоретическому, необходимо составить теоретическое распределение.
2.1. Реализация в SPSS
Для составления теоретического распределения в SPSS необходимо в диалоговом окне Crosstabs (рис.1.) воспользоваться кнопкой и Cells, после чего откроется диалоговое окно (рис.9.)

Рис.9. Диалоговое окно Crosstabs: Cell Display
Для выведения ожидаемых частот флажок из положения Observed нужно переместить в положение Expected – команда выведет на экран ожидаемые частоты для каждой ячейки в предположении, что переменные являются независимыми.
Результат выполнения команды представлен на рис.10.

Рис.10. Расчет ожидаемых частот
Для получения дополнительной информации для вывода на экран остатков (Redisual) в окне Cells выделить вид остатков, который нужен: обычные (Unstandartized), нормированные (Standartized) или уточненные нормированные (Adjusted standartized).
Раздел Percentage позволяет вывести относительные ожидаемые или наблюдаемые частоты, выраженные в процентах частоты, выраженные в процентах (команда Total). Или относительные частоты условного распределения (для распределения, составленного по столбцам (Column) или строкам (Row)).
На рис.11. представлена таблица сопряженности дополненная ожидаемыми частотами и значениями остатков.

Рис.11. Расширенный вид таблицы сопряженности
2.2. Реализация в STATISTICA
Для составления теоретического распределения в STATISTICA необходимо в диалоговом окне Crosstabulation tables Results (рис.5.) перейти на вкладку Options и установить флажок в поле Expected frequencies (Ожидаемы частоты).
Результат выполнения команды представлен на рис.12.

Рис.12. Расчет ожидаемых частот
Для получения дополнительной информации для вывода на экран остатков необходимо в диалоговом окне Crosstabulation tables Results (рис.5.) во вкладке Options установить фложок в поле Redisual frequencies.
Раздел Percentage позволяет вывести относительные ожидаемые или наблюдаемые частоты, выраженные в процентах частоты, выраженные в процентах (команда Total). Или относительные частоты условного распределения (для распределения, составленного по столбцам (Column) или строкам (Row)).
На рис.13. представлена таблица сопряженности дополненная ожидаемыми частотами и значениями остатков. Результат выводится отдельными таблицами.


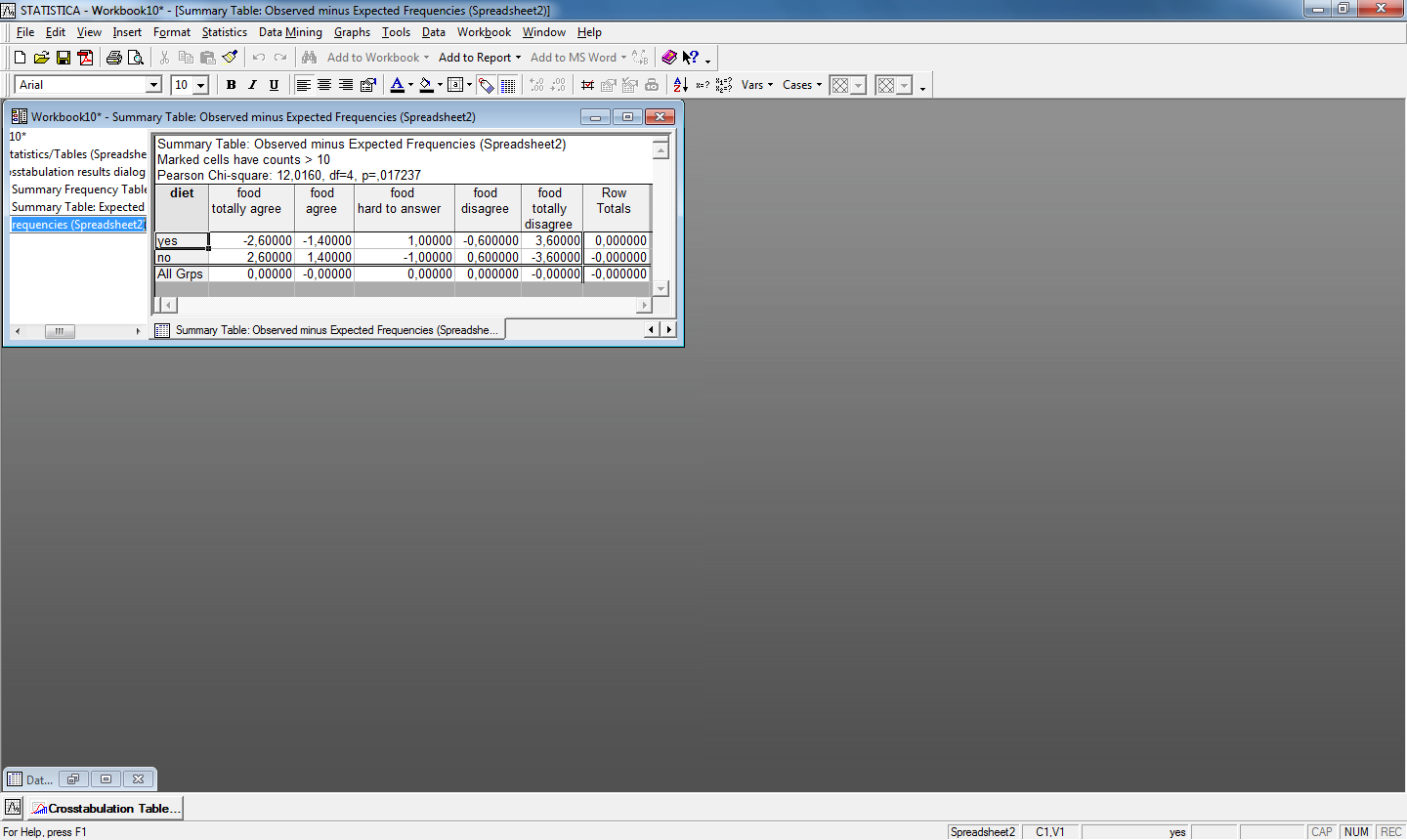
Рис.13. Расширенный вид таблицы сопряженности
3. Расчет критерия хи-квадрат
Ответ на простейший вопрос о взаимосвязи переменных можно получить, вычислив критерий хи-квадрат. Для вычисления критерия хи-квадрат применяется формула Пирсона.
3.1. Реализация в SPSS
Для расчета хи-квадрат по формуле Пирсона в диалоговом окне Crosstabs (рис.1.), необходимо щелкнуть на кнопку Statistics, в результате чего откроется диалоговое окно (рис.14.), в котором необходимо выделить флажком команду Chi-square.

Рис.14. Диалоговое окно Crosstabs: Statistics
Пример расчета критерия хи – квадрат для переменных food и diet представлен на рис.15.

Рис.15. Расчет критерия хи-квадрат Пирсона
В нижней таблице приведены непосредственно результаты расчета критерия:
- Pearson Chi-Square (Хи-квадрат по Пирсону),
- Likelihood Ratio (Отношение правдоподобия),
- Linear-by-Linear Association (Зависимость линейный-линейный),
- N of Valid Cases (Объем выборки).
Визуальный анализ таблицы сопряженности говорит о том, что диету во время программы похудения скорее соблюдают те, кто на вопрос в анкете о правильном питании до программы похудения отвечал «затрудняюсь ответить» или «полностью не согласен». Учитывая, что для числа степеней свободы  и уровня значимости
и уровня значимости  критическое значение критерия хи-квадрат равно
критическое значение критерия хи-квадрат равно  , что меньше расчетного значения, можно говорить о том, что исследуемая зависимость подтверждается. 3.2. Реализация вSTATISTICA Для расчета хи-квадрат по формуле Пирсона в диалоговом окне CrosstabulationtablesResults (рис.5.) во вкладке Options установить фложок в поле Pearsonhttps://studfile.net/preview/1582398/» target=»_blank»]studfile.net[/mask_link]
, что меньше расчетного значения, можно говорить о том, что исследуемая зависимость подтверждается. 3.2. Реализация вSTATISTICA Для расчета хи-квадрат по формуле Пирсона в диалоговом окне CrosstabulationtablesResults (рис.5.) во вкладке Options установить фложок в поле Pearsonhttps://studfile.net/preview/1582398/» target=»_blank»]studfile.net[/mask_link]
Как рассчитать описательную статистику для переменных в SPSS
Лучший способ понять набор данных — вычислить описательную статистику для переменных в наборе данных. Существуют три распространенные формы описательной статистики:
1. Суммарная статистика — числа, суммирующие переменную с использованием одного числа. Примеры включают среднее значение, медиану, стандартное отклонение и диапазон.
2. Таблицы. Таблицы могут помочь нам понять, как распределяются данные. Одним из примеров является таблица частот, которая сообщает нам, сколько значений данных попадает в определенные диапазоны.
3. Графики. Они помогают нам визуализировать данные. Примером может служить гистограмма .
В этом руководстве объясняется, как рассчитать описательную статистику для переменных в SPSS.
Пример: описательная статистика в SPSS
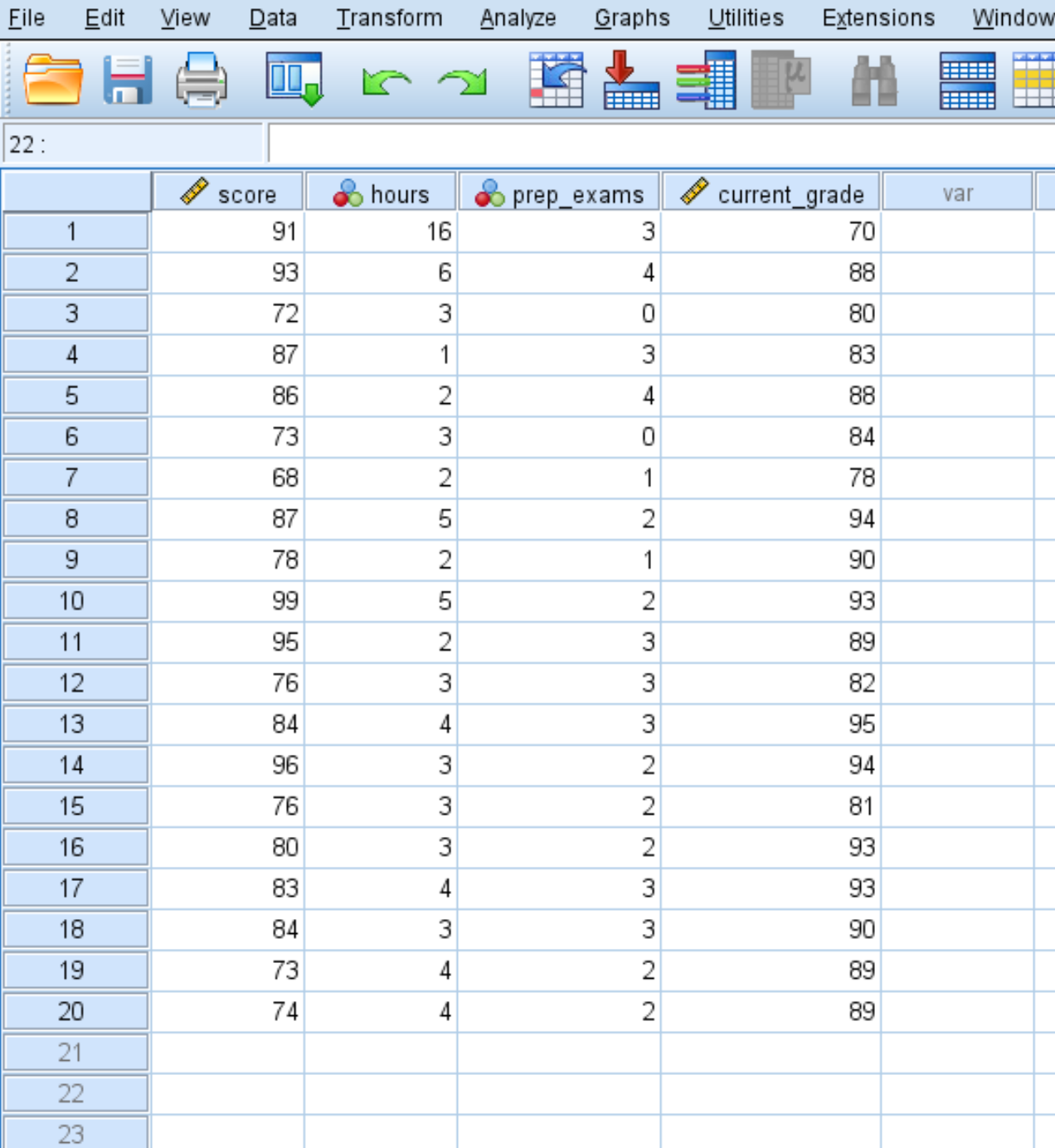
Предположим, у нас есть следующий набор данных, содержащий четыре переменные для 20 учеников определенного класса:
- Оценка экзамена
- Часы, потраченные на учебу
- Сданы подготовительные экзамены
- Текущая оценка в классе
Вот как рассчитать описательную статистику для каждой из этих четырех переменных:
Сводные статистические данные
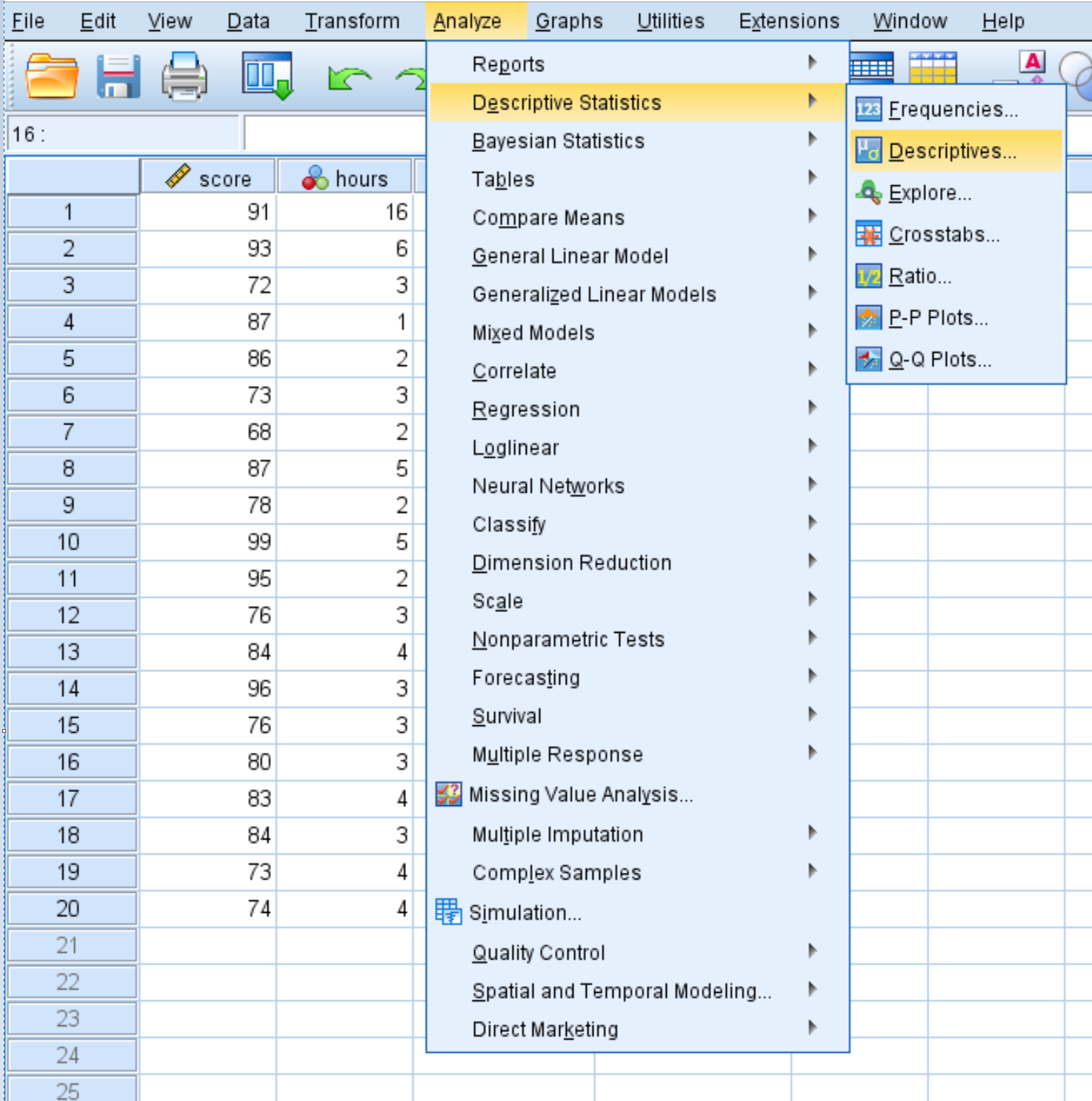
Чтобы рассчитать сводную статистику для каждой переменной, щелкните вкладку « Анализ », затем « Описательная статистика », затем « Описательная статистика»:
В новом появившемся окне перетащите каждую из четырех переменных в поле с надписью Variable(s). При желании вы можете нажать кнопку « Параметры » и выбрать конкретную описательную статистику, которую вы хотите рассчитать с помощью SPSS. Затем нажмите «Продолжить».Затем нажмите ОК .
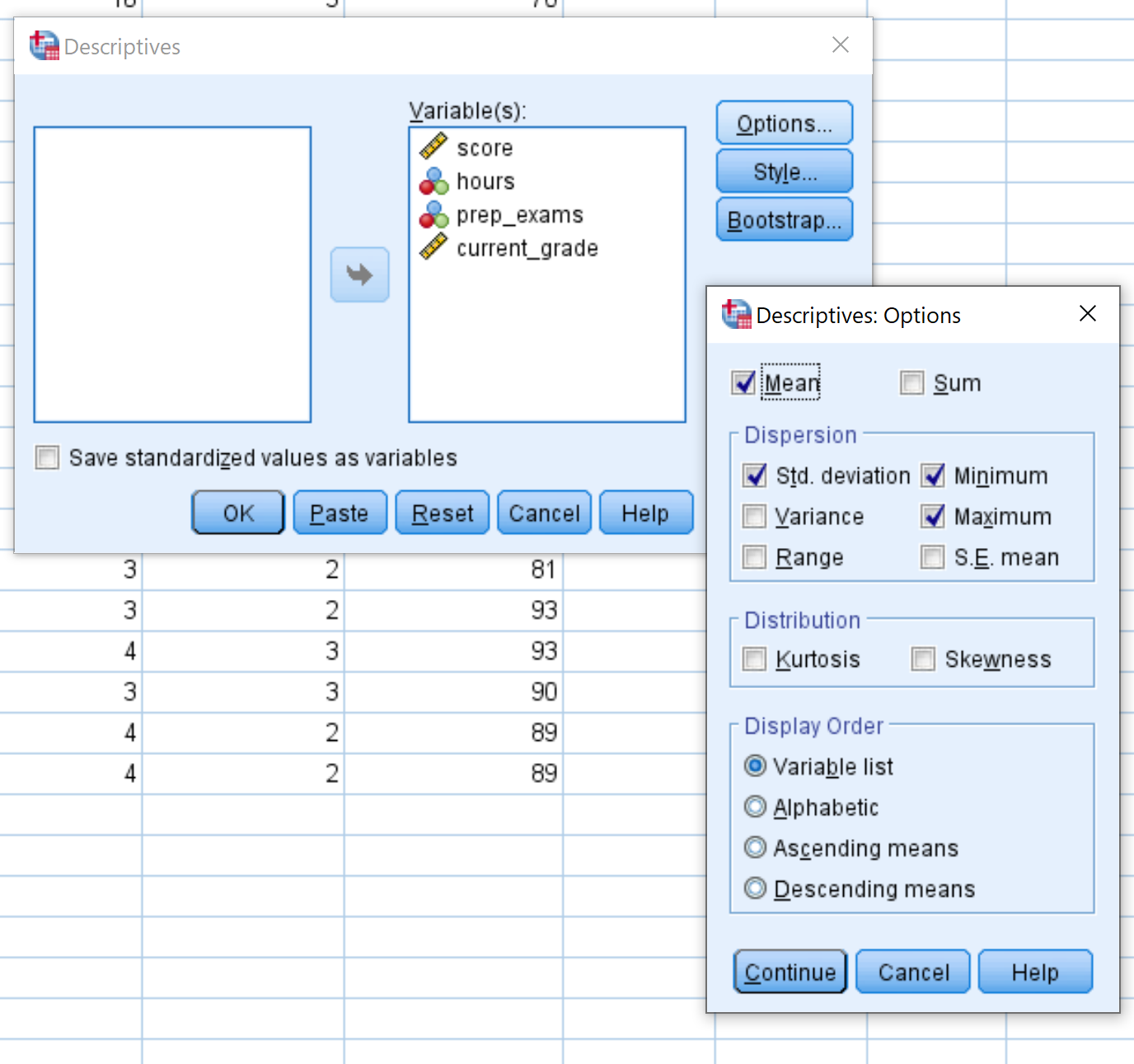
После того, как вы нажмете OK , появится таблица со следующей описательной статистикой для каждой переменной:
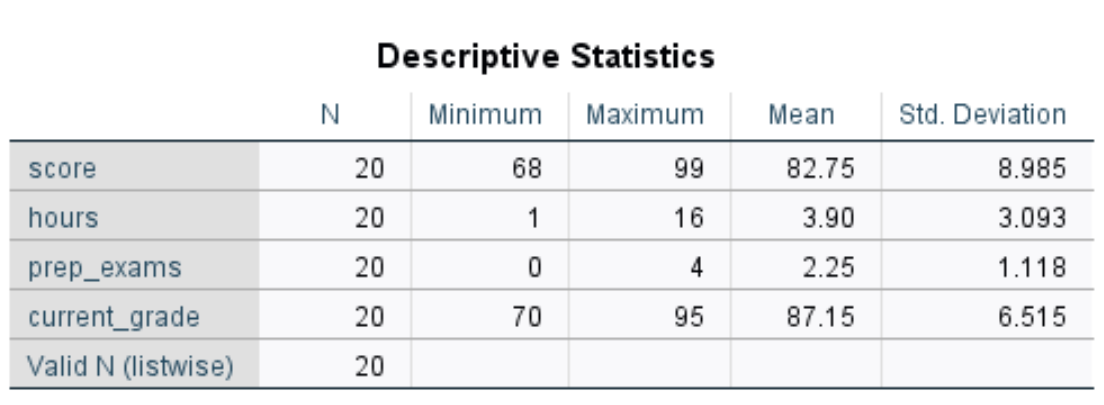
Вот как интерпретировать числа в этой таблице для переменной score :
- N: общее количество наблюдений. В данном случае их 20.
- Минимум: минимальное значение экзаменационного балла. В данном случае это 68.
- Максимум: максимальное значение экзаменационного балла. В данном случае это 99.
- Среднее значение: средний балл за экзамен. В данном случае это 82,75.
- стандарт Отклонение: стандартное отклонение экзаменационных баллов. В данном случае это 8,985.
Эта таблица позволяет нам быстро понять диапазон каждой переменной (используя минимум и максимум), центральное положение каждой переменной (используя среднее значение) и насколько разбросаны значения для каждой переменной (используя стандартное отклонение).
Столы
Чтобы создать таблицу частот для каждой переменной, щелкните вкладку « Анализ », затем « Описательная статистика » и « Частоты ».
В новом появившемся окне перетащите каждую переменную в поле с надписью Variable(s). Затем нажмите ОК .
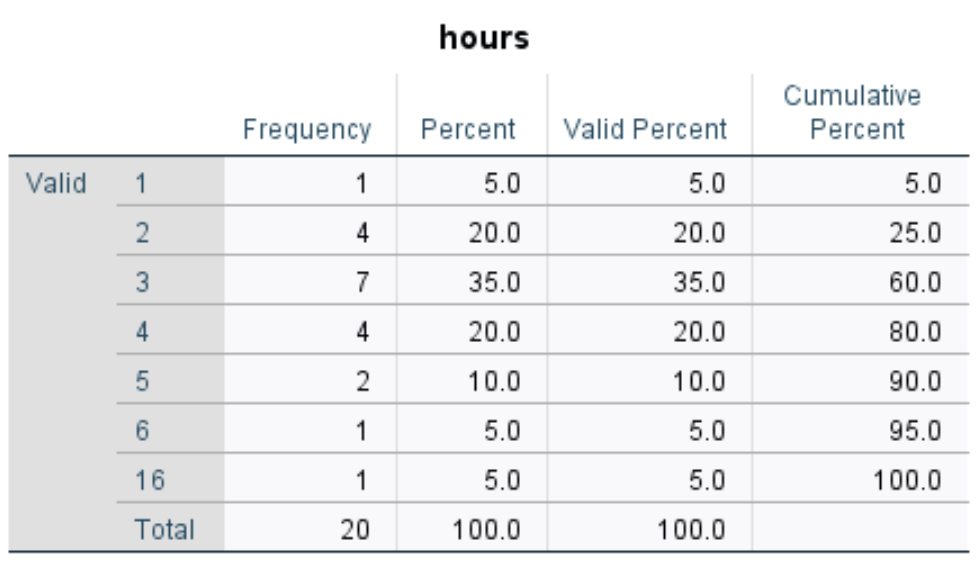
Появится таблица частот для каждой переменной. Например, вот пример для переменной hours :
Способ толкования таблицы следующий:
- В первом столбце отображается каждое уникальное значение переменной hours.В этом случае уникальными значениями являются 1, 2, 3, 4, 5, 6 и 16.
- Во втором столбце отображается частота каждого значения. Например, значение 1 появляется 1 раз, значение 2 — 4 раза и так далее.
- В третьем столбце отображаются проценты для каждого значения. Например, значение 1 составляет 5% всех значений в наборе данных. Значение 2 составляет 20 % всех значений в наборе данных и так далее.
- В последнем столбце отображается совокупный процент. Например, значения 1 и 2 составляют в совокупности 25% от общего набора данных. Значения 1, 2 и 3 составляют в совокупности 60% набора данных и так далее.
Эта таблица дает нам хорошее представление о распределении значений данных для каждой переменной.
Графики
Графики также помогают нам понять распределение значений данных для каждой переменной в наборе данных. Одним из самых популярных графиков для этого является гистограмма.
Чтобы создать гистограмму для заданной переменной в наборе данных, щелкните вкладку « Графики », затем « Построитель диаграмм ».
В появившемся новом окне выберите « Гистограмма » на панели «Выбрать из». Затем перетащите первый вариант гистограммы в главное окно редактирования. Затем перетащите интересующую вас переменную на ось x. Мы будем использовать счет для этого примера. Затем нажмите ОК .
После того, как вы нажмете OK , появится гистограмма, отображающая распределение значений переменной score :
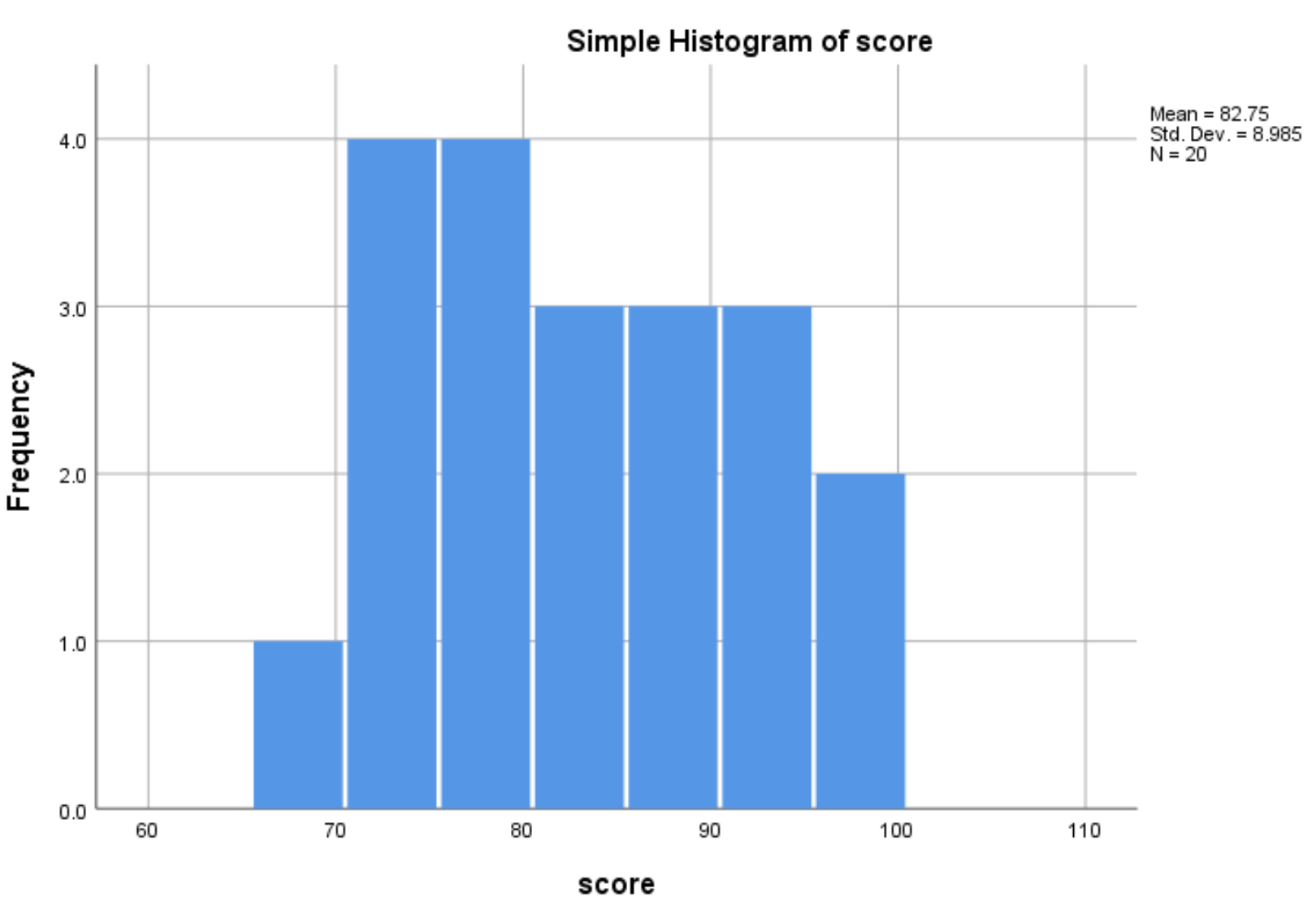
Из гистограммы видно, что диапазон экзаменационных баллов варьируется от 65 до 100, при этом большинство баллов находятся в диапазоне от 70 до 90.