
Привет, Хабр! Меня зовут Елизавета Петрова я Data Scientist и являюсь участником профессионального сообщества NTA. В современном мире технологии синтеза речи и клонирования голоса стремительно развиваются и уже достигли впечатляющих результатов.
С 2015 года проводится специальное соревнование ASV Spoofing, на котором ежегодно презентуют новые методы проведения спуфинг-атак (атаки, когда один человек или программа маскируется под другую путем фальсификации данных) с помощью видео-дипфейков и синтеза речи. Существующие речевые системы способны синтезировать речь и тембр голоса, на слух неотличимые от настоящих. Технологии клонирования голоса привлекают всё большее внимание и находят широкое применение в таких сферах, как голосовое управление, робототехника, голосовые ассистенты (например, Siri и Алиса) и т.д. Однако вместе с этим открываются новые возможности для мошенничества. Особенно уязвимы системы, использующие голосовую биометрию для идентификации пользователей: используя синтез речи, мошенники могут получить доступ к аккаунтам и данным пользователей.
Нейросети теперь ещё и изменяют голос! Обзор Voice.ai

Для борьбы с неэтичным использованием голосовых технологий необходимо разработать инструменты распознавания искусственной речи. Нужно, чтобы разработанная модель обладала хорошей обобщающей способностью и умела детектировать синтезированную речь независимо от языка, акцента и тембра голоса конкретного человека.
В публикации рассмотрю несколько новейших разработок в этой области, а потом синтезирую запись искусственной речи и на этом примере проверю работу одной из представленных моделей.
Так же, как и задачу синтеза речи, задачу распознавания искусственной речи можно решать с помощью глубокого обучения.
Команда из итальянского университета в своей публикации от 28.09.2022 предлагает[1] воспринимать задачу распознавания клонированного голоса как задачу speaker verification. Speaker verification — это задача распознавания спикера: модель должна проверить, принадлежит ли голос определенному человеку или же это чей-то другой голос. Если модель предсказала, что голос действительно принадлежит одному из спикеров, на записях речи которых училась нейросеть, тогда это настоящая речь, иначе – искусственная. Для сравнения использовались нейросети с различной архитектурой, такие как ResNet, TDNN и LSTM. Недостаток данной модели в том, что она умеет распознавать только тех спикеров, голоса которых «видела» при обучении, но обработать новые голоса модель не сможет.
Исследователи из лаборатории в Китае в августе 2022 года выяснили[2], что, наблюдая за поведением нейронов в слоях нейросети, можно сделать вывод, является речь настоящей или искусственной. С этой целью в нейросети для каждого слоя выбирается числовая граница, определяющая, активирован нейрон или нет. В каждом слое подсчитывается ACN (average count neuron) — среднее количество активированных нейронов.
На графике ниже для сравнения показаны признаки реальной и синтезированной речи, полученные с помощью алгоритма выделения MFCC (мел-кепстральных частотных коэффициентов), неактивированных нейронов и ACN. Видно, что после активации нейроны могут чётко разделить настоящую и синтезированную речь.
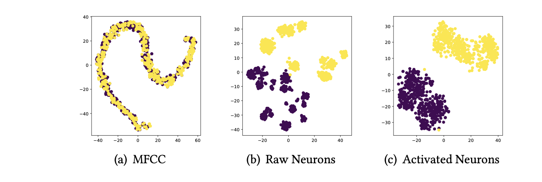
Другая команда китайских ученых 02.08.2022 представила[3] следующий метод: отличить реальную речь от синтезированной можно, проанализировав распределение основного тона сигнала, а также вещественные и мнимые спектрограммы.
На следующем графике распределение основного тона для настоящей речи изображено сверху, для синтезированной — снизу. Видно, что распределение искусственной речи относительно гладкое, в то время как распределение настоящей речи имеет ярко выраженные пики.
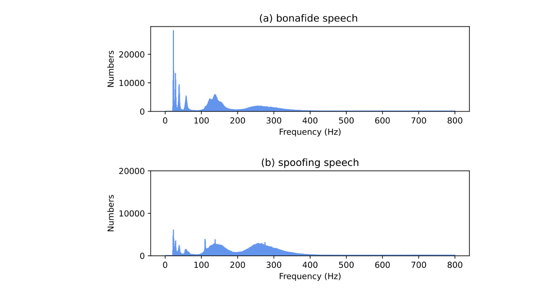
Авторы работы предложили использовать частотную полосу от 0 до 400 Гц для классификации (потому что, как видно из графиков выше, почти весь сигнал распределён на этой полосе), а также вещественную и мнимую спектрограммы сигнала, которые передаются на вход нейросети для классификации.
Однако применять глубокое обучение и сложные архитектуры нейросетей необязательно: есть и другие, более простые подходы распознавания искусственной речи.
Исследователи из лаборатории в США в 2019 году разработали[4] свой подход к задаче, не использующий глубокие нейросети. Генеративные модели оставляют артефакты в синтезированной записи клонированного голоса. Используя методы спектрального анализа и статистические тесты, можно обнаружить эти артефакты.
Ниже на графике представлены спектрограмма настоящей (сверху) и клонированной (снизу) речи. Жёлтым выделены артефакты: вертикальные полосы. Можно заметить, что спектрограмма реальной речи более гладкая вдоль оси Х и не содержит чётко выраженных вертикальных полос.
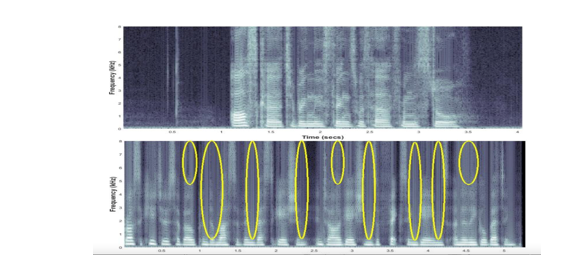
Ещё один интересный подход был представлен в 2022 году[5] исследователями из Италии: они показали, что для определения искусственной речи достаточно проанализировать битрейт сигнала (битрейт – количество бит, используемых для передачи данных в единицу времени).
Ниже на графиках по оси х отложен битрейт, по оси у – количество высказываний. Реальная речь отмечена синим, сгенерированная (для 12 различных техник спуфинга) — красным. Видно, что распределения битрейта отличаются для настоящей и синтезированной речи.
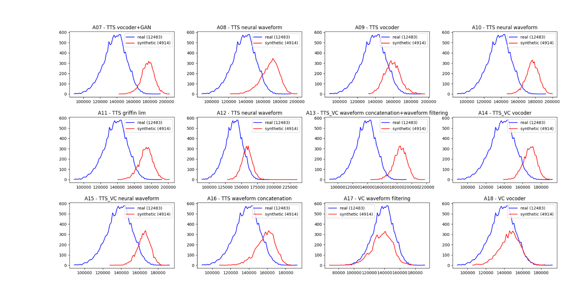
Проиллюстрирую работу моделей детектирования искусственной речи на примере.
Запись с искусственной речью можно сгенерировать самим, либо использовать готовый материал. Для тестирования я взяла отрывок искусственной речи на русском языке из видео, однако можно использовать речь на любом языке, так как это не повлияет на предсказание модели.
Как можно сгенерировать речь самому, покажу ниже на примере нейросети Tortoise TTS:
! git clone https://github.com/jnordberg/tortoise-tts.git % cd tortoise-tts ! pip3 install -r requirements.txt ! python3 setup.py install # Импорт модели import torch import torchaudio import IPython from tortoise.api import TextToSpeech from tortoise.utils.audio import load_audio, load_voice, load_voices # Инициализация модели tts = TextToSpeech() # Текст который будет произносить модель text = «Joining two modalities results in a surprising increase in generalization» # Выберем один из представленных голосов %ls tortoise/voices voice = ‘train_dotrice’ preset = ‘fast’ # Загрузим голос и сгенерируем речь voice_samples, conditioning_latents = load_voice(voice) gen = tts.tts_with_preset(text, voice_samples=voice_samples, conditioning_latents=conditioning_latents, preset=preset) torchaudio.save(‘generated_speech.wav’, gen.squeeze(0).cpu(), 24000)
Получили запись синтезированной речи generated_speech.wav.
На слух обе записи звучат одинаково правдоподобно. Проверю, есть ли в записях неразличимые человеческим ухом артефакты, которые может заметить нейросеть.
Попробую проверить модель [4], как единственное open source решение из рассмотренных.
! git clone https://github.com/UNICT-Fake-Audio/fake-audio-detector.git %cd /content/fake-audio-detector ! pip install -r requirements.txt ! pip install dill ! python3 main.py «/content/generated_speech.wav»
Результат работы для настоящей речи: ‘The sample audio is real’, для искусственной (как сгенерированной с помощью Tortoise, так и взятой из видео) — ‘The sample audio is fake’. Модель работает достаточно быстро, обработка одного файла занимает около 2-3 секунд.
Следовательно, даже достаточно простые модели, анализирующие битрейт сигнала, способны отличить настоящую речь от синтезированной.
Можно с уверенностью сказать, что специалистов Data Scienice и ML инженеров с каждым годом ждут всё новые и новые вызовы по борьбе с неэтичным использованием современных технологий. Однако по мере того, как развиваются технологии клонирования голоса, появляются и новые способы распознать искусственную речь.
Приложение: аудиофайлы и код для демонстрации
По ссылке расположены аудиофайлы, которые использовались для тестирования работы модели и демо-ноутбук с кодом на Google Colab. Можно скачать и протестировать представленные записи речи, либо попробовать сгенерировать свои с помощью ноутбука с Tortoise. Также в колаб-ноутбуке добавлена инструкция, как поменять формат аудиофайла, чтобы модель детекции фейковой речи могла принимать его на вход.
Источник: habr.com
Дипфейки вокруг нас: как ученые нашли способ распознать поддельный голос
При помощи нейросетей подделать можно не только лицо, но и голос. К счастью, ученые смогли разработать метод, при помощи которого эту замену можно распознать.
Никита Шевцев

Gallo images
Распознать аудиофейк сложнее, чем видео. Но ученые нашли способ сделать это
Дипфейки, как аудио, так и видео, стали возможны только с развитием сложных технологий машинного обучения в последние годы. Они принесли с собой новый уровень неопределенности в отношении цифровых медиа. Чтобы обнаружить эти подделки, многие исследователи обратились к анализу визуальных артефактов — мельчайших сбоев и несоответствий, обнаруженных в видео-дипфейках.
0 РЕКЛАМА – ПРОДОЛЖЕНИЕ НИЖЕ
Как распознать поддельный голос
Дипфейки аудио потенциально представляют еще большую угрозу, потому что люди часто общаются устно без видео — например, с помощью телефонных звонков, радио и голосовых записей. Эти голосовые сообщения значительно расширяют возможности злоумышленников использовать подделки.
Для обнаружения дипфейков звука ученые из Университета Флориды разработали метод, который измеряет акустические и динамические различия между голосовыми сэмплами, созданными органически человеком, и теми, которые генерируются синтетически компьютерами. Люди говорят, прогоняя воздух над различными структурами голосового тракта, включая голосовые связки, язык и губы. Перестраивая эти структуры, вы изменяете акустические свойства своего голосового тракта, благодаря чему можете создавать более 200 различных звуков или фонем. Однако анатомия человека существенно ограничивает акустическое поведение этих разных фонем, что приводит к относительно небольшому диапазону звуков для каждой.
РЕКЛАМА – ПРОДОЛЖЕНИЕ НИЖЕ
Дипфейк, напротив, создается путем предварительного прослушивания компьютером аудиозаписей жертвы. В зависимости от используемых методов компьютеру может потребоваться прослушать всего от 10 до 20 секунд аудио. Этот звук используется для извлечения ключевой информации об уникальных аспектах голоса жертвы.
Злоумышленник выбирает фразу, которую будет произносить голос, а затем, используя модифицированный алгоритм преобразования текста в речь, генерирует аудиозапись того, как нужную фразу говорит жертва. Этот процесс создания одного образца подделанного аудио может быть выполнен за считанные секунды, что потенциально позволяет злоумышленникам достаточно гибко использовать поддельный голос в разговоре. Ученые разработали программу, которая может сравнивать возможность воспроизведения звуков человеческой гортанью. Исследователи показали, что дипфейковые аудио нередко включают в себя звуки, которые человеческая гортань в принципе извлечь не может. Программа ученых способна их распознать и сделать вывод о том, является ли аудиозапись фейковой или нет.
Источник: www.techinsider.ru
В Сети появился онлайн-сервис, который может менять голос
Как с помощью нейросети в Интернете можно изменить свой голос
Компания Dwango Media Village , занимающаяся исследованиями и разработками, а также применением сервисных приложений, ориентированных на машинное обучение, анонсировала систему преобразования голоса, которая может изменить звучание любого человека, переформатировав его голос в чужой.
Вот пример работы искусственного преобразования голоса, которое может изменить любой голос в голоса сотни других человек — Dwango Media Village (dmv)
Демонстрация работы системы преобразования голоса, названная Dwango Media Village «Seiren Voice», доступна на следующих сайтах: Seiren Voice (AI Voice Changer) . Стоит отметить, что существуют и отечественные аналогичные проекты, с гораздо более интересным подбором тембров голосов, привычных слуху соотечественников, например технологии на основе методики DeepFake .
Видео взято с YouTube-канала «Vera Voice»
Но что отличает продукт от Dwango Media Village, так это возможность опробовать его собственным голосом. По крайней мере, попытаться это сделать, поскольку сайт японский и может неверно распознавать иностранную речь, да и не со всеми браузерами и платформами он «дружит». Например, с iPhone может не воспринимать речь через любой из браузеров, а с десктопа через браузер Firefox сработает. Как бы то ни было, в компании обещают, что технология будет развиваться и сайт будет также улучшен, а значит, и функционал будет расширен.
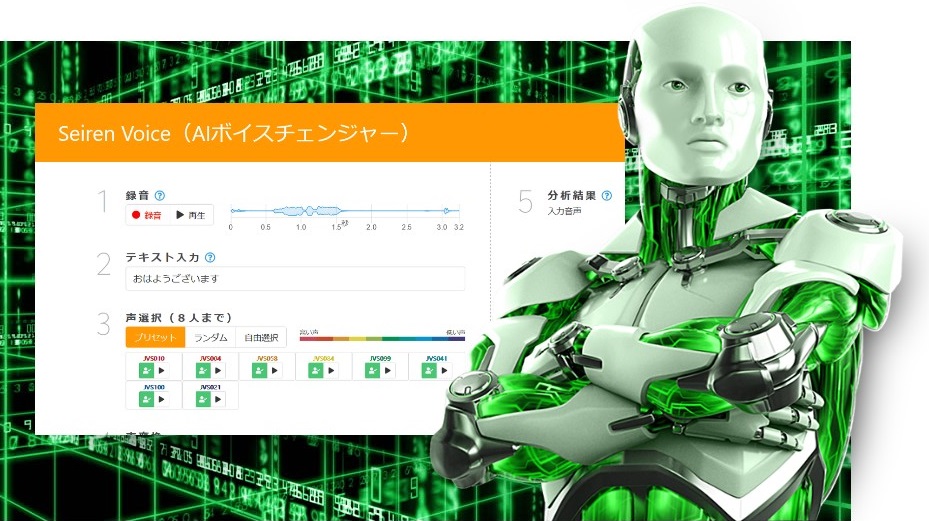
Вы можете записать собственный голос, нажав «Запись» (для удобства элементы управления выделены на скриншотах)
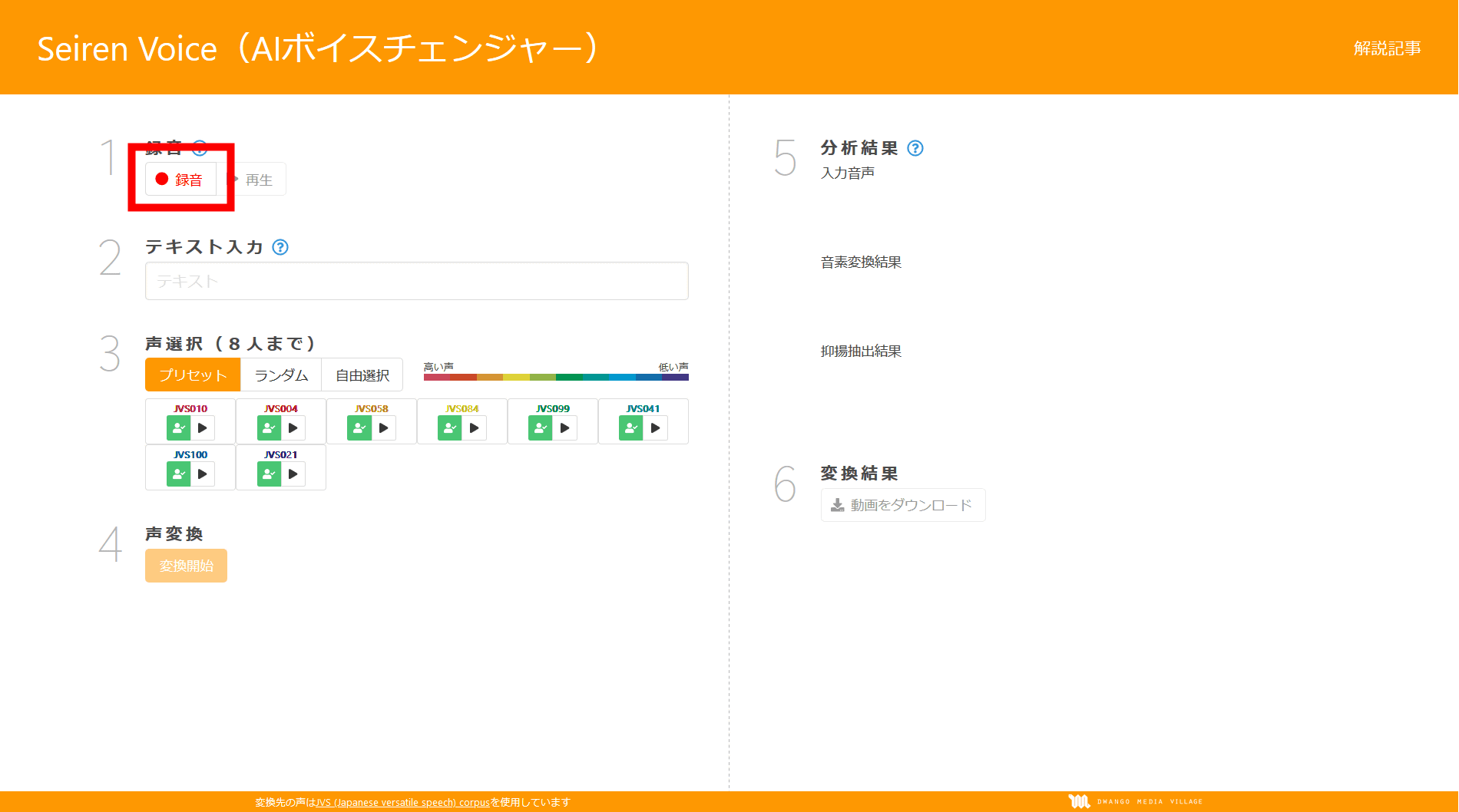
Появится всплывающее окно с запросом разрешения на использование микрофона. Нажмите «Разрешить», чтобы немедленно начать запись (для этого компьютер должен быть оборудован микрофоном).
Пишем любую фразу, но ее лучше не растягивать более чем на 5 секунд.

Когда запись будет завершена, справа от кнопки Записи/ Воспроизведения (на скриншоте она выделена) появится тембр вашего голоса в форме волны.
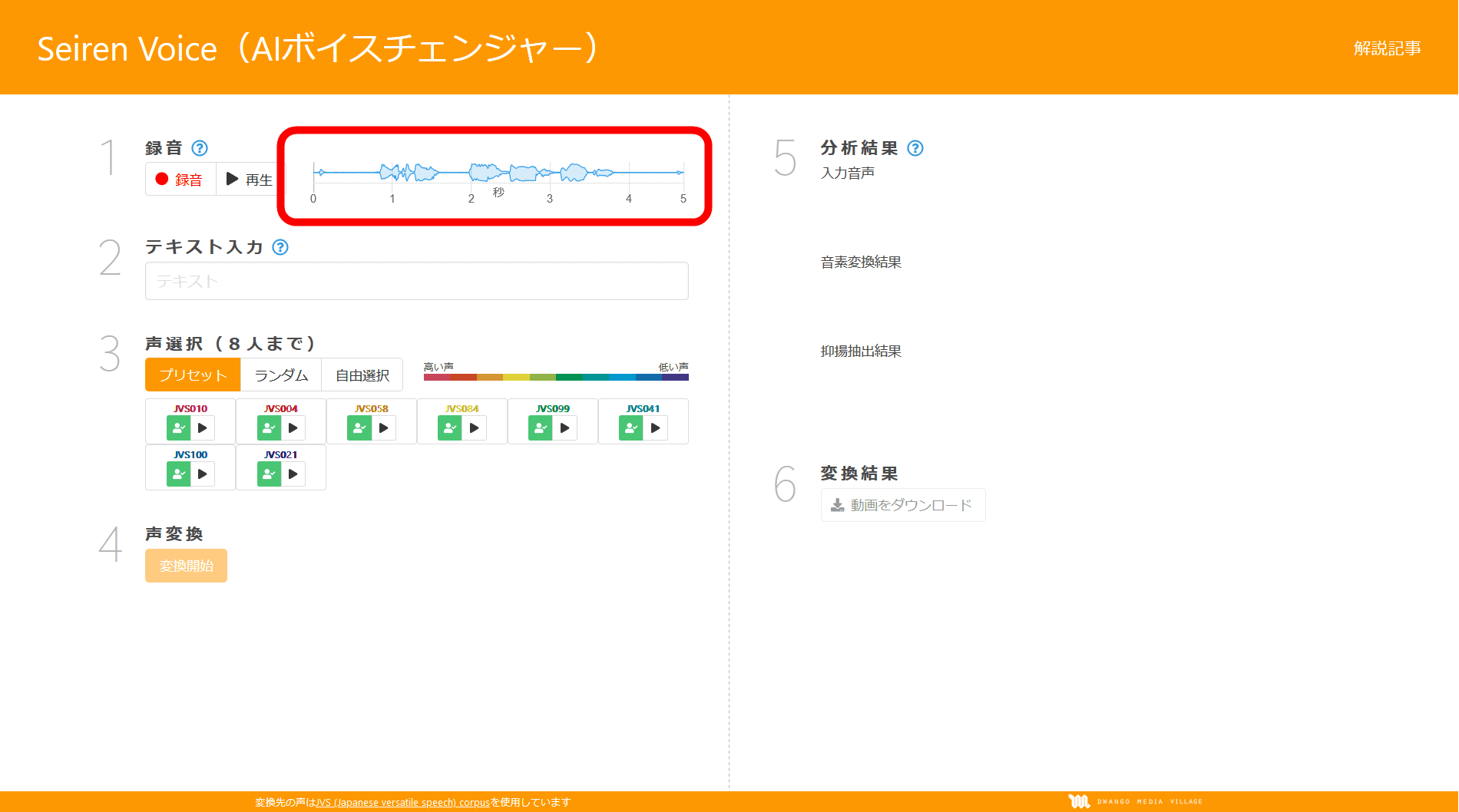
Далее нужно будет ввести текст, который вы прочитали вслух. Говорят, что таким способом точность изменения голоса будет повышена.

В программе существует 100 типов тембров, от высокого до низкого, а преобразование голоса может выполняться для восьми человек одновременно. Нажмите «Начать преобразование» (кнопка выделена).
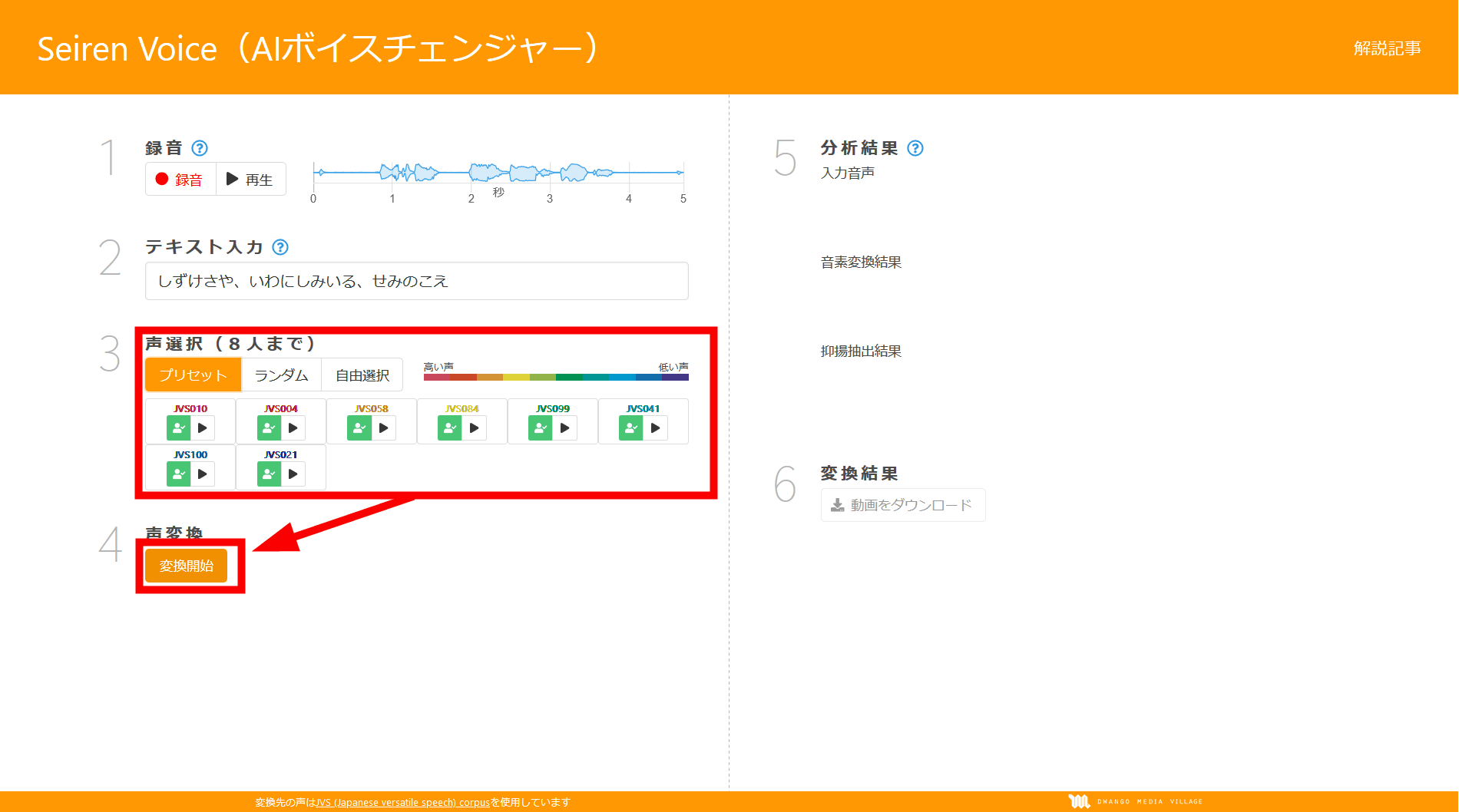
Когда начинается преобразование голоса, сначала отобразится результат анализа. Для входящего голоса результат преобразования фонетического элемента и результат обнаружения интонации показаны на рисунке.
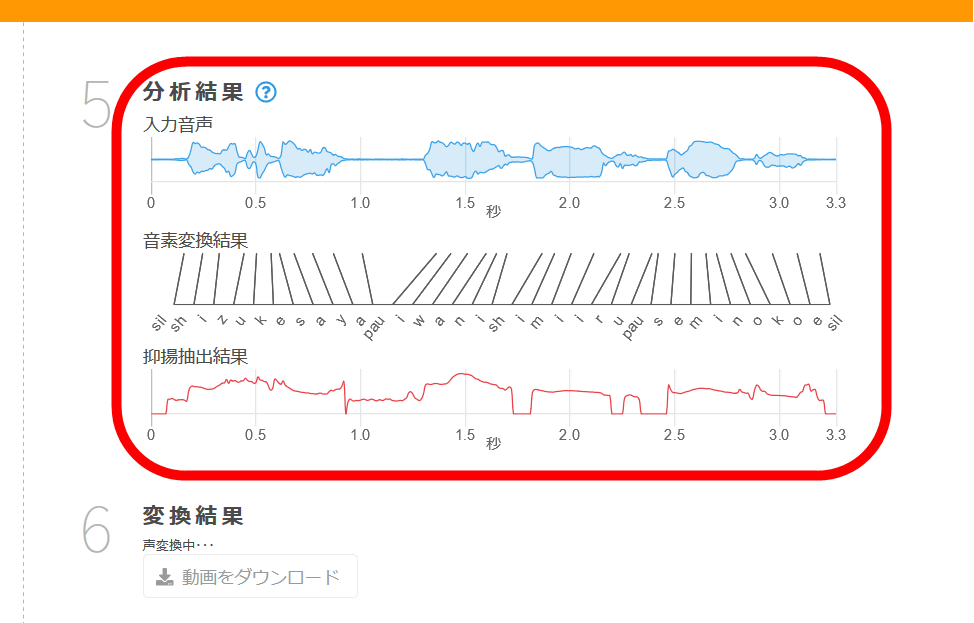
После переформации, которая продлится порядка 40 секунд, в окне результата преобразования появится видео с записанным голосом. Если проиграть его, то можно услышать собственный голос и 8 типов результатов конвертации.
Качество конвертации будет зависеть от качества записи. Если все удалось, то вы услышите следующий результат, только со своей озвучкой:
Видео взято с YouTube-канала «gigazine»
Файл можно скачать в формате MP4.

А у вас получилось поменять свой голос?
Источник: 1gai.ru