
Существует три основных канала вывода, управляемых с помощью диалога Диспетчер вывода (доступном в меню Файл), в которые можно направить все результаты:
Эти три канала вывода можно использовать в различных комбинациях (например, Рабочую книгу и Отчет одновременно). Кроме этого, каждый Объект (Таблицы данных или График), помещенный в Рабочую книгу или Отчет, может содержать другие внедренные и связанные Объекты и Документы. Таким образом, вывод STATISTICA можно иерархически организовать различными способами.
Каждый из трех каналов вывода в STATISTICA имеет свои преимущества:
Рабочие книги являются стандартным средством управления выводом. Каждый итоговый Документ (например, Таблица данных или График STATISTICA, а также документ Microsoft Word или Excel) представляется в виде вкладки в Рабочей книге.
Документы можно организовать в виде иерархии папок и элементов (по умолчанию, для каждого Анализа создается отдельный узел) с помощью дерева, в котором каждый отдельный элемент, папка или целая ветвь могут быть легко изменены.
Часть I. Знакомство с SPSS
Например, набор Документов можно перенести (с помощью метода «перетащить и отпустить») в окно Отчета или в рабочую область приложения (например, в рабочую область STATISTICA, где элементы отображаются в виде автономных окон). При настройке иерархии папок, можно перенести ветви целиком в Рабочие книги несколькими различными способами. Рабочие книги совместимы с широким спектром других форматов файлов (например, все документы Microsoft Office), которые можно добавлять в Рабочие книги и редактировать «на месте».
Пользовательские примечания и комментарии в Рабочих книгах. Рабочие книги предоставляют мощные возможности для эффективной работы с чрезвычайно большим количеством итоговых документов и являются наилучшим способом управления выводом. Одним из возможных недостатков является то, что пользовательские комментарии (например, примечания) и дополнительная информация не могут быть прямо вставлены в «поток» вывода Рабочей книги так, как это обычно происходит в традиционных текстовых документах, таких как Отчеты STATISTICA. Отметим, что:
Ко всем Документам STATISTICA можно легко добавить комментарии (a) напрямую, введя текст в Графики, Таблицы и Отчеты; и (b) косвенно, путем создания примечаний в поле Комментарии в диалоге Свойства Документа (доступном в меню Файл — Свойства).
Форматированные документы с комментариями и примечаниями (в виде Отчетов STATISTICA или других текстовых документов) можно легко добавлять в любое место иерархии итоговых Документов в Рабочих книгах.
Отчеты STATISTICA являются более традиционным способом обработки итоговой информации, при котором каждый Объект (например, Таблица данных, График STATISTICA или таблица Microsoft Excel) отображается в виде последовательности текстовых документов.
Однако, технология, скрытая за простым редактором, предоставляет очень богатые функциональные возможности. Например, также как и в Рабочей книге каждый из объектов отчёта можно активизировать, настраивать и редактировать «на месте».
Введение Знакомство Подготовка данных для работы в статистическом пакете Statistica 10!
Очевидное преимущество отчётов заключается в возможности добавлять примечания и комментарии к Объектам традиционными способами. Кроме этого, только Отчеты содержат и сохраняют дополнительную информацию, которая содержит подробное описание последовательности шагов указанных Анализов, исходя из типа заданной дополнительной информации на вкладке Диспетчер вывода в диалоге Параметры (доступном в меню Файл — Диспетчер вывода).
Очевидный недостаток подобных Отчетов заключается в фиксированной внутренней структуре, накладываемой стилем форматирования текстового документа.
Отдельные окна. Кроме всего перечисленного, итоговые Документы STATISTICA могут быть структурированы в виде последовательности автономных окон. Длина очереди задается на вкладке Диспетчер вывода в диалоге Параметры (доступном в меню Файл — Диспетчер вывода).
Явный недостаток такого вида вывода заключается в полном отсутствии организации и в возможном наличии беспорядка в рабочей области приложения (некоторые процедуры создают сотни Таблиц и Графиков), хотя имеется возможность настройки порядка этих объектов в рабочем окне приложения STATISTICA.
Управление выводом в STATISTICA осуществляют с помощью опций на вкладке Диспетчер вывода в диалоге Параметры (доступном при выборе команды Сервис — Параметры или команды Файл — Диспетчер вывода). Изменения, сделанные в этом диалоге, будут использоваться как стандартные параметры при следующем запуске системы STATISTICA.
Диспетчер вывода в меню (доступном во всех Анализов или Графиков) используется для настройки параметров вывода в STATISTICA из текущего Анализа/Графика. Изменения, сделанные в этом диалоге будут действовать только в текущем Анализе или Графике.
Использовать глобальные параметры вывода. Выберите опцию Использовать глобальные параметры вывода, чтобы использовать для вывода текущего Анализа/Графика глобальные параметры вывода (заданные в диалоге Сервис — Параметры на вкладке Диспетчер вывода).
Размещать результаты (Таблицы, Графики) в. Опции в группе Размещать результаты (Таблицы, Графики) в используются для определения места, где будут размещаться Таблицы и Графики после нажатия кнопки OK в диалоге Анализа.
Отдельных окнах. Выберите опцию Отдельных окнах, чтобы все результаты отображались в отдельных окнах. Отметим, что вы можете выбрать опцию Отдельных окнах или Рабочей книге, однако, вы не можете выбрать обе эти опции одновременно. С другой стороны, вы можете выбрать опции Отдельных окнах и Направлять результаты в окно Отчета.
Длина очереди. Введите число в поле Длина очереди (или используйте микропрокрутку), чтобы определить число окон результатов, которые вы хотите отобразить на экране. Если Анализ создает больше окон результатов, чем указано в этой опции, то STATISTICA спросит, хотите ли вы продолжить отображение окон или необходимо прервать процедуру.
Если выбрана опция Отдельных окнах, то Таблицы результатов и Графики автоматически отображаются в порядке «first in-first out» (первым вошел, первым вышел). Вы можете изменить глубину такой очереди в этом параметре. Отметим, что эта опция доступна, только если выбрана опция Отдельных окнах.
Рабочей книге. Выберите опцию Рабочей книге, чтобы каждый итоговый Документ отображался в Рабочей книге. Отметим, что вы можете выбрать опцию Отдельных окнах или Рабочей книге, однако, вы не можете выбрать обе эти опции одновременно. С другой стороны, вы можете выбрать опции Рабочей книге и Направлять результаты в окно Отчета. Отметим, что необходимо выбрать эту опцию, чтобы сделать следующие шесть опций доступными.
Рабочая книга, содержащая файл данных. Выберите команду Рабочая книга, содержащая файл данных, чтобы все результаты были добавлены в ту же Рабочую книгу, что и исходный файл данных. Отметим, что, если вы выберите эту опцию, а файл данных не включен ни в одну Рабочую книгу, то результаты будут отображаться в отдельных окнах.
Если также выбрана опция Автоматически помещать результаты в Рабочую книгу (см. ниже), то результаты автоматически направляются в Рабочую книгу, содержащую файл данных. Если опция Автоматически помещать результаты в Рабочую книгу не выбрана, то результаты отображаются в отдельных окнах. Однако, каждое окно имеет специальную метку, поэтому при нажатии кнопки отмеченные окна автоматически направляются в соответствующее Рабочую книгу, содержащую файл данных. Для получения дополнительной информации см. раздел Добавить в Рабочую книгу.
Отдельная Рабочая книга для каждого Анализа/Графика. Выберите опцию Отдельная Рабочая книга для каждого Анализа/Графика, чтобы создавать отдельные Рабочие книги для результатов каждого Анализа или Графика.
Общая Рабочая книга для всех Анализов/Графиков. Выберите опцию Общая Рабочая книга для всех Анализов/Графиков, чтобы включить результаты всех Анализов и Графиков в одну Рабочую книгу.
Текущая книга. Выберите опцию Текущая книга, чтобы направить все результаты в заданную Рабочую книгу. Если вы не зададите Рабочую книгу, нажав кнопку Обзор, то автоматически появится стандартный диалог Открыть.
Обзор. Нажмите кнопку Обзор, чтобы вызвать стандартный диалог Открыть, в котором необходимо указать существующую Рабочую книгу.
Автоматически помещать результаты в Рабочую книгу. Выберите команду Автоматически помещать результаты в Рабочую книгу, чтобы автоматически направлять все результаты в Рабочую книгу. Отметим, что для использования этой функции вам необходимо выбрать одну из четырех опций выше.
Помещать новые результаты вверху. Выберите опцию Помещать новые результаты вверху, чтобы помещать каждый новый результат в качестве первого наследника в соответствующих папках в Рабочей книге. По умолчанию, эта опция не выбрана, поэтому элементы будут добавляться в Рабочую книгу снизу.
Направлять результаты в Окно отчетов. Выберите опцию Направлять результаты в Окно отчетов, чтобы отображать результаты Анализа и/или Графика в Отчете. Остальные опции в этой группе позволяют определить режим отображения информации в окне Отчета. С их помощью можно определить, какой тип Отчета необходимо использовать и какое количество информации будет отображаться в нем. Отметим, что необходимо выбрать эту опцию, чтобы остальные опции стали доступными.
Отдельный Отчет для каждого Анализа/Графика. Выберите команду Отдельный Отчет для каждого Анализа/Графика, чтобы для каждого Анализа/Графика создавать отдельный Отчет.
Общий Отчет для всех Анализов/Графиков. Выберите опцию Общий Отчет для всех Анализов/Графиков, чтобы направлять результаты всех Анализов/Графиков в общий Отчет.
Текущий Отчет. Выберите опцию Текущий Отчет, чтобы направлять все результаты в существующий Отчет. Если вы не зададите Отчет, нажав кнопку Обзор, то автоматически появится стандартный диалог Открыть.
Обзор. Нажмите кнопку Обзор, чтобы вызвать стандартный диалог Открыть, в котором необходимо указать существующий Отчет.
Отображение информации. Опция «Отображать информацию» позволяет выбрать количество информации, которая будет включена в Отчет:
— «Минимально» — наиболее «экономичный» режим отображения информации в Отчете. В этом режиме в Отчет будут включены только Таблицы данных и Графики.
— «Сжато» — включаются еще и имя файла данных, информация об условиях выбора наблюдений и весах наблюдений, список выбранных переменных и значения пропущенных данных для каждой переменной.
— «Умеренно» — дополнительно включаются в Отчет также длинные имена переменных (или формулы).
— «Полностью» — режим полного отображения информации в Отчете для каждой переменной Анализа.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник: studopedia.ru
Практическое задание 6. Используя возможности сети Интернет изучить современные прикладные статистические программы Statistica

Единственный в мире Музей Смайликов
Самая яркая достопримечательность Крыма

Скачать 25.76 Kb.
Практическое задание 6
Используя возможности сети Интернет изучить современные прикладные статистические программы (Statistica, SPSS, MatLab и др.) , их особенности, плюсы и минусы, результаты оформить в виде следующей таблицы 1 (рассмотреть не менее 7 вариантов программ):
отчет нуждается в
привести его в читабельную
форму. Очень мало книг по
работе в пакете. Сравнительно небольшой набор реализованных методов. Не русифицирован. Реализован набор только
SAS (Statistical Analysis Software)
Отладка кода проходит значительно проще, чем на R;
Интеграция с БД (Oracle/Teradata);
Удобный формат выходных данных (особенно таблиц);
Мощная поддержка со стороны компании SAS;
Многолетний успешный опыт эксплуатации компаниями разной величины, с разными задачами и разным объёмом входных данных. В частности, России SAS используют ОАО “РЖД”, МТС, ЦБ РФ, а также ведущие банки, среди которых Сбербанк, Альфабанк, Тинькофф и многие другие.
Профессиональное использование языка предполагает покупку программного продукта;
Исходники многих исполняемых алгоритмов SAS не являются публичными, следовательно изучение работы языка сильно ограничено;
SAS значительно уступает в производительности R;
С точки зрения объёма кода SAS также зачастую сильно проигрывает (иногда в несколько раз).
MATLAB
Огромные возможности. Но это скорее преимущество всего продукта в целом.
Частые обновления, как правило заметные положительные преобразования происходят не реже пары раз в год.
Программная среда позволяет преобразовывать его в “быстрый” код на С, С++.
Медленный и перегруженный операторами, командами, функциями язык, основной целью которого является улучшение визуального восприятия.
Узконаправленный. Нет никакой больше программной платформы, где бы MATLAB был полезен.
Дороговизна ПО. Если вы не студент — либо готовьтесь опустошить карманы или перейти границу закона. И даже если студент — цена приличная.
Невысокий спрос. Несмотря на большой интерес к MATLAB практически во всех сферах, фактически и легально его используют лишь немногие.
SPSS (IBM)
Позволяет параллельно обрабатывать несколько подвыборок.
Простота в освоении.
Имеются специфические методы, нацеленные исключительно на маркетинговые и социологические исследования (например, Conjoint analysis). Удобен при обработке результатов опроса.
Имеется модуль для автоматизации процесса разработки анкеты и ввода результатов опросов (Data Entry).
Отсутствует возможность реализации собственных алгоритмов;
Существенно уступает в глубине анализа данных.
Wizard Mac
Меньше информации на странице
Wizard позволяет разбить сложный процесс на несколько шагов: страница содержит меньшее количество полей и в целом меньше информации. Простота имеет несколько важных преимуществ. Во-первых, пользователи не так перегружены, как в случае с длинной формой, то есть на завершение процесса тратится меньше когнитивных усилий . Во-вторых, большая часть информации в форме может оказаться неактуальной, но пользователям придется потратить время, чтобы ознакомиться с ней и отфильтровать ее.
Wizards позволяет делать меньше ошибок
Если посетитель сайта видит чрезмерно сложную форму, скорее всего, он проигнорирует определенные части и, возможно, сделает ошибки из-за невнимательности. С Wizard вся необходимая на данном этапе информация может поместиться на одном экране (без утомительной прокрутки), а все объяснения могут быть расположены непосредственно возле полей.
Самый короткий путь для каждого пользователя
Для некоторых посетителей процесс ввода данных может быть быстрым и простым, а для других — сложным и нудным. Если процесс «заточен» под случай конкретного пользователя (и все последующие действия прозрачны и логичны для него), то процесс заполнения не вызывает отрицательных эмоций (ведь каждый шаг буквально привязан к конкретной ситуации).
Например, пользователям, у которых нет кредитной карты, не нужно показывать иконки карты в форме оформления заказа.
Эта технология работает, но все же не существует идеального решения для всех ситуаций, и у Wizard есть свои минусы. Возьмем, например, процесс ввода данных в электронную таблицу с несколькими столбцами. Повторное переключение между мышкой и клавиатурой в случае с Wizard быстро утомит пользователя (по сравнению с обычным переходом через столбцы).
Более того, Wizard может привести к более высокой стоимости взаимодействия (больше кликов), чем другие модели ввода данных. Более того, этот паттерн не позволяет сравнивать информацию из разных шагов. Когда пользователи видят лишь один шаг за раз, может быть не так просто переместить и скопировать одну и ту же информацию или обратиться к данным, введенным ранее.
Процесс заполнения Wizard не так просто сохранить: если пользователь бросил заполнение на полпути, он может лишиться всей проделанной работы. Даже если эта опция предусмотрена, возобновление процесса может стать целой проблемой: пользователю придется вспомнить, что он уже сделал и восстановить контекст.
Wizard может заблокировать доступ к другим частям приложения, которые необходимы для завершения процесса. Использование модального окна, в свою очередь, может помешать восприятию информации в фоновом режиме. И наконец данный паттерн ограничивает контроль пользователей и их творчество. В приложении для обработки фотографий любителям хватит одной простой шкалы, чтобы улучшить цветовой баланс фотографии, в то время как профессионалов этот инструмент ограничит.
EViews может использоваться для общего статистического анализа и эконометрического анализа, такого как анализ поперечных и панельных данных, а также оценка и прогнозирование временных рядов.
EViews сочетает в себе технологию электронных таблиц и реляционных баз данных с традиционными задачами статистического программного обеспечения и использует графический интерфейс Windows. Это сочетается с языком программирования который отображает ограниченную ориентацию объекта.
Абсолютно другие принципы работы с пакетом (если сравнивать с SPSS, STATISTICA, Excel, Minitab);
Мало литературы как по методам, реализованным в пакете, так и по работе в пакете;
Отсутствует русифицированная версия;
Некоторые операции осуществляются исключительно на языке команд как в MS DOS .
Источник: topuch.com
Поисковая геохимия
Итак. Проверить распределние в Statistica можно несколькими способами. Их можно разделить как на табличные, так и на графические. Речь пойдет о вторых. Поскольку только на графике можно заменить особенности распределения: скошенность, бимодальность, итп.

Рис.1. Запускаем Statistica 10 и жмем кнопку Open.

Рис.2. Открываем xls файл с данными геохимической съемки.

Рис.3. Щелкаем «Импортировать выбранный лист в Лист». Кому как, а я предпочитаю держать данные во внутреннем формате Statistica.

Рис.4. Открывается окошко и ставим галочку «Получить названия переменных из первой строки». Статистике также необходимо задать названия проб, что бы она могла ставить подписи на графиках. Но решение по-умолчанию автоматически ставит числовые названия с кучей нулей после запятой. Так что это лучше делать после импорта листа.

Рис.5. Сразу добавляем Лист в Тетрадь. И сохраняем. Тетрадь содержит в себе все добавленные листы и в нее автоматически включаются все графики, таблицы и результаты анализов с данными в листах.

Рис. 6. Открываем вкладку Graphs. Выбираем Гистограммы (Histograms. )
Основные графические инструменты для проверки гипотезы о распределении являются: Гистограммы, Графики нормальной вероятности. А Квантиль-Квантиль и Вероятность-Вероятность графики аналоги второго.

Рис.7. Выбираем интересующие нас хим.элементы (еще они называются признаками). И переходим во вкладку Расширенное (Advanced).
Тут для примера я выбрал два элемента. Медь типичный логнормальный признак, а оксид титана — нормальный. Как правило, в геохимии макрокомпоненты (SiO2, TiO2. Fe, Mg, Ca. )распределены нормально, а микрокомпоненты логнормально. Но нужно проверять все. К тому же не стоит строго подходить «это нормальный, потому что программа сказала!».
У природы свое распределение, мы лишь пытаемся его описать. Так что даже если вы и видите, что критерий нормальности не соблюдается, то все равно можно принять данные за нормальные. В статистике, главное, что бы работало 😀
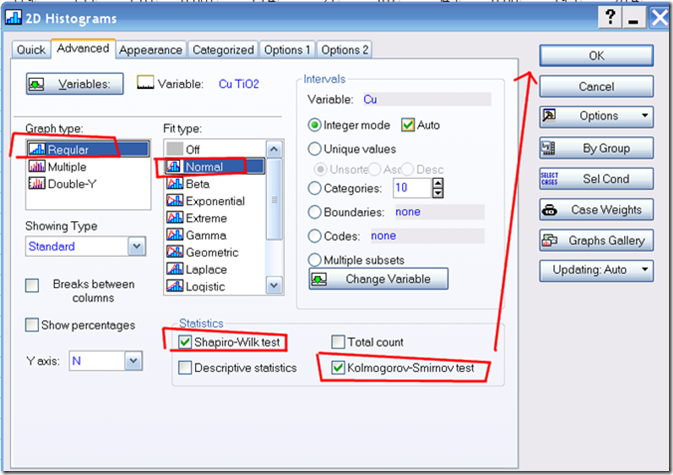
Рис.8. Выбираем подгонку по нормальному распределению (Fit type), внизу щелкаем галочки на тест Шапиро-Уилка, и для желающих тест Колмогорова-Смирнова. Первый лучший. И щелкаем ОК. Программа строит два графика.

Рис. 9. Гистограмма распределения меди с подгонкой к нормальному распределению (красная линия).
Статистик сразу смотри на график. Какой он? Он смещен влево, скошен (правоскошенный), одна мода: основной класс у.е, есть редкие классы у.е. В заголовке написано среднее 85,9 у.е. Из-за смещения и скоса оно явно завышено.
Красная линия так же плохо описывает данные: у нас нет класса —50-0 у.е., а вероятность для него просчитана, класс сильно не доходит до линии. Так же красная линия совсем не описывает классы выше 200 у.е. Все это характерно для логнормального распределения.
Посмотрим на тесты. Тесты оперируют различиями эмпирического распределения с подогнанным. Различие различием, а насколько оно важно? Важность его показывается в подчеркнутых значениях «p». Смотрим, везде p

Рис.10. Гистограмма распределения TiO2 с подгонкой нормального распределения (красная линия)
Посмотрим на тесты. В первом случае вероятность вычислитьн е получилось p0.05. То есть быть незначимыми. Тут они менее значимы, чем в у меди. Но ссылаясь на тест, я должен отклонить гипотезу о нормальном распределении. Поэтому рассмотрим далее и нажмем кнопку анализа в нижней панели программы.
Каждое окно анализа автоматически свертывается туда.
Геохимику на заметку.
Тут используется МАСФ (Метод Анализа Сверхтонкой Фракции) с количественным спектральным анализом с индуктивно связанной плазмой (ICP-AES, ICP-MS). Это дорогие, но стоящие себя методы. Как видите даже самые низкие содержания оксида титана определены, что нереально для полуколичественной спектралки. Геохимику необходимо учитывать исходные данные.
Полуколичественная спектралка (просыпка, как еще имеют в кулуарах) имеет две особенности: завышать низкие содержания и давать дискретные значения.
Представьте, если бы содержания TIO2 были бы определены только с 0,6 у.е., а класс 0,6-0,7 у.е. был бы завышен до 0.7-0,8. Тогда у нас было бы логнормальное распределение. Искусственно.
Дискретные значения: например 10, 20, 30.
100 ppm. Но не 10,1, и не 22,56. Многие исследователи предлагают использовать дискетные распределения для анализа ее. То есть типа черный шаг, белый шаг. Лично мое мнение, это ерунда.
Скажем, так, оценивайте «дискретность» полуколичественного анализа как сильное округление данных.

Рис.11. Посмотрим подгонку для логнормального распределения.
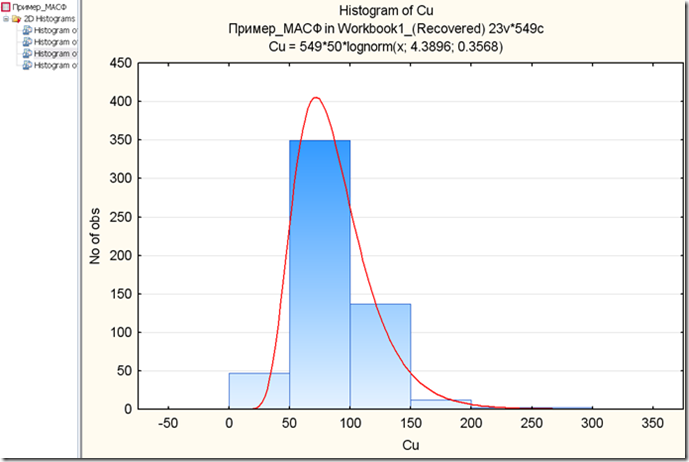
Рис.12. График распределения меди с логнормальной подгонкой (красная линия).
Что-ж, линия отлично описывает график. Прямо типичный логнормальный элемент. В верху представлены среднее и параметр формы. Точнее их натуральные логарифмы. Експонента 4,3896 = 80,6 у.е., то есть среднее арифметическое завышает оценку мат.ожидания (истинного среднего) на 5,3 у.е.
Не критично, в общем то.

Рис. 13. График распределения оксида титана с логнормальной подгонкой (красная линия).
Заметьте, красная линия тоже неплохо описывает данные. Тут еще неопредленность возникает из-за детальности гистограммы. Если сделать столбцов в два раза меньше (шаг 0,2), то столбцы и линия вообще идеально будут соответствовать друг-другу.
В общем, процесс определения типа распределения достаточно эмпирический. Я бы сказал, что тут большую значимость имеет учесть самые логнормальные элементы, а такие ни рыба ни мясо, можно подогнать заодно.
Рассмотрим для примера TIO2 более детально.

Рис. 14. Откроем вкладку Статистики (Statistics) и щелкнем кнопку Подгонка распределения (Distribution Fitting).

Рис. 15. Выбираем Непрерывный тип распределения. Пусть для начала будет Логнормальное.
Про дискретные значения см. рис. 10.

Рис.16. Выбираем элемент и жмем кнопку «Построить график эспериментального и теоретического распределения». Можно построить табличку через конопку Summary.

Рис.17. Гистрограмма распределения оксида титана с логнормальной подгонкой (красная линия)
В данном случае построила несколько другие столбцы. Они не скгруленные. Параметры гистограммы можно изменить во вкладке Parameters (см. картинку выше). Главное отличие, тут программа вычисляет статистику как у теста Шапиро-Уилка. То есть рассчитывает значимость отличия эмпирического распределения от подогнанного по распределению Хи-квадрат.
Как видите p=0.00439, что является значимым отклонением.
Построим график для нормального распределения.

Рис.18. Гистрограмма распределения оксида титана с нормальной подгонкой (красная линия)
Как виидите, отклонение намного меньше, чем для логнормального распределения, а его значимость низка. p=-0,44176, что существенно больше 0,05, а значит гипотеза о нормальном распределении принимается.
Вот так вот исследуя данные можно узнать какое у нас распределение. Как правило у геохимика это занимает несколько минут на элемент. Сразу прикидываете, точность и прецизинность анализа, смотрите какие объекты попали в выборку (по ландшафтам, по геологии), смотрите на гистограммы. Если почти все типичные логнормальные, а один два — ни рыба, ни мясо, так логарифмируйте все и не заморачивайтесь.
Да, собственно, на определении типа распределения все не заканчивается. Надо изменить данные, что бы они стали нормальными. Логнормальные признаки нужно прологарифмировать. Я лично использую десятичный логарифм.

Рис. 19. Создаем копию выборки. Вкладка Данные (Data), кнопка Выборка (Subset).

Рис. 20. Тут можно выбрать какие именно переменные и наблюдения нам нужны. Очень полезно, когда надо создавать маленькие подвыборки по типам геол.образований.

Рис. 21. Добавляем Лист в Тетрадь (см. рис. 5).

Рис. 22. Щелкаем дважды на заголовке переменной. Выбираем количество знаков после запятой 4 (для логафмов), и вписываем внизу формулу =log10(v2)
v2 — соответствует переменной хром. Номер можно увидеть в заголовке окошка.
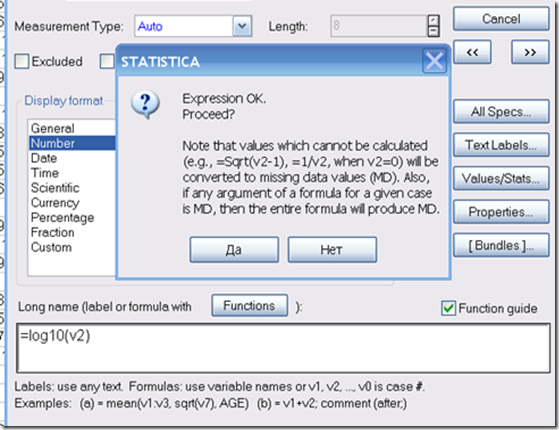
Рис. 23. Соглашаемся. В окошке написано, что не все значения могут логарифмированы.

Рис. 24. Получили логарифмы. Расширим столбец, что бы видеть все значения.
Впишем формулы для остальных элементов. Несколько сложнее, чем в Excel, но привык.

Рис. 25. Выделим все элементы и нажмем кнопку Автоширина (AutoFit). Вообще тут как и в экселе можно пользоваться копированием формата. Да вообще много похожего.
Вот и все. Теперь можно использовать логарифмы в линейных анализах. Они распределены нормально.
На закуску рассмотрю другой графический метод определения типа распределения:

Рис. 26. Опять выбираем вкладку Графики, и кнопку 2D графики — Квантиль-Квантиль графики.

Рис. 26. Построим график распределения оксида титана с нормальной подгонкой.

Рис. 27. График распределения оксида титана с нормальной подгонкой.
Как видите, почти все точки ложатся прямо на линию. Так и должно быть для нормального распределения. А низкие и высокие значения не так уж сильно отклоняются. Ну что-ж, простим лаборатории и природе.

Рис. 28. График распределения оксида меди с нормальной подгонкой.
Тут точки сильно отклоняются от линии. Это типичный график для логнормального элемента.
Вот так в Statistica проверяется и подгоняется распределение данных.
Источник: sosninep.blogspot.com