
Рассказываем, как за несколько шагов создать простую нейронную сеть и научить её узнавать известных предпринимателей на фотографиях.
Шаг 0. Разбираемся, как устроены нейронные сети
Проще всего разобраться с принципами работы нейронных сетей можно на примере Teachable Machine — образовательного проекта Google.
В качестве входящих данных — то, что нужно обработать нейронной сети — в Teachable Machine используется изображение с камеры ноутбука. В качестве выходных данных — то, что должна сделать нейросеть после обработки входящих данных — можно использовать гифку или звук.
Например, можно научить Teachable Machine при поднятой вверх ладони говорить «Hi». При поднятом вверх большом пальце — «Cool», а при удивленном лице с открытым ртом — «Wow».
Для начала нужно обучить нейросеть. Для этого поднимаем ладонь и нажимаем на кнопку «Train Green» — сервис делает несколько десятков снимков, чтобы найти на изображениях закономерность. Набор таких снимков принято называть «датасетом».
НЕЙРОСЕТЬ своими руками за 10 минут на Python
Теперь остается выбрать действие, которое нужно вызывать при распознании образа — произнести фразу, показать GIF или проиграть звук. Аналогично обучаем нейронную сеть распознавать удивленное лицо и большой палец.
Как только нейросеть обучена, её можно использовать. Teachable Machine показывает коэффициент «уверенности» — насколько система «уверена», что ей показывают один из навыков.
Источник: vc.ru
Как создать свою собственную нейронную сеть с нуля на Python
Мотивация: в рамках моего личного пути к лучшему пониманию глубокого обучения я решил создать нейронную сеть с нуля без библиотеки глубокого обучения, такой как TensorFlow. Я считаю, что понимание внутренней работы нейронной сети важно для любого начинающего специалиста по данным. Эта статья содержит то, что я узнал, и, надеюсь, она будет полезна и вам!
Что такое нейронная сеть?
В большинстве вводных текстов по нейронным сетям при их описании используются аналогии с мозгом. Не углубляясь в аналогии с мозгом, я считаю, что проще описать нейронные сети как математическую функцию, которая отображает заданный вход в желаемый результат.
Нейронные сети состоят из следующих компонентов:
- Входной слой, x
- Произвольное количество скрытых слоев
- Выходной слой, y
- Набор весов и смещений между каждым слоем, W и b
- Выбор функции активации для каждого скрытого слоя, σ. В этом уроке мы будем использовать функцию активации
На приведенной ниже диаграмме показана архитектура двухуровневой нейронной сети (обратите внимание, что входной слой обычно исключается при подсчете количества слоев в нейронной сети).

Создать класс нейронной сети в Python очень просто.
class NeuralNetwork: def __init__(self, x, y): self.input = x self.weights1 = np.random.rand(self.input.shape[1],4) self.weights2 = np.random.rand(4,1) self.y = y self.output = np.zeros(y.shape)
Обучение нейронной сети.
Выход y простой двухслойной нейронной сети:

Вы могли заметить, что в приведенном выше уравнении веса W и смещения b являются единственными переменными, влияющими на выход y.
Естественно, правильные значения весов и смещений определяют силу прогнозов. Процесс точной настройки весов и смещений на основе входных данных известен как обучение нейронной сети.
Каждая итерация процесса обучения состоит из следующих шагов:
- Расчет прогнозируемого выхода y, известный как прямая связь.
- Обновление весов и смещений, известное как обратное распространение.
Последовательный график ниже иллюстрирует процесс.

Прямая связь
Как мы видели на последовательном графике выше, упреждающая связь — это просто простое исчисление, и для базовой двухслойной нейронной сети выходные данные нейронной сети таковы:

Давайте добавим функцию прямой связи в наш код Python, чтобы сделать именно это. Обратите внимание, что для простоты мы приняли смещения равными 0.
class NeuralNetwork: def __init__(self, x, y): self.input = x self.weights1 = np.random.rand(self.input.shape[1],4) self.weights2 = np.random.rand(4,1) self.y = y self.output = np.zeros(self.y.shape) def feedforward(self): self.layer1 = sigmoid(np.dot(self.input, self.weights1)) self.output = sigmoid(np.dot(self.layer1, self.weights2))
Однако нам по-прежнему нужен способ оценить «хорошесть» наших прогнозов (т. е. насколько далеки наши прогнозы)? Функция потерь позволяет нам сделать именно это.
Функция потери
Есть много доступных функций потерь, и природа нашей проблемы должна диктовать наш выбор функции потерь. В этом уроке мы будем использовать простую ошибку суммы квадратов в качестве функции потерь.

То есть ошибка суммы квадратов представляет собой просто сумму разницы между каждым предсказанным значением и фактическим значением. Разница возводится в квадрат, так что мы измеряем абсолютное значение разницы.
Наша цель в обучении — найти наилучший набор весов и смещений, который минимизирует функцию потерь.
Обратное распространение
Теперь, когда мы измерили ошибку нашего прогноза (потери), нам нужно найти способ распространить ошибку обратно и обновить наши веса и смещения.
Чтобы узнать подходящую величину для корректировки весов и смещений, нам нужно знать производную функции потерь по отношению к весам и смещениям.
Вспомним из исчисления, что производная функции — это просто наклон функции.
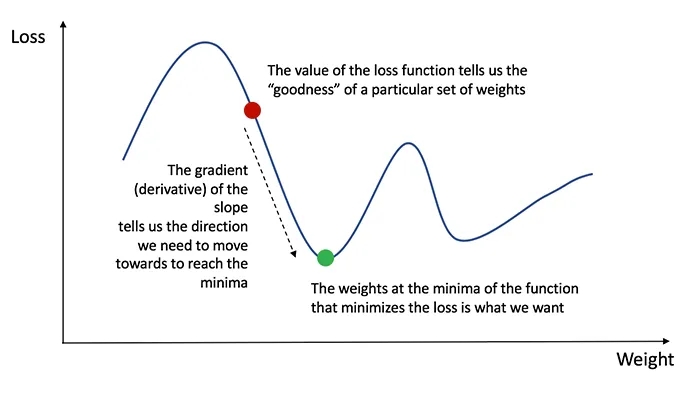
Если у нас есть производная, мы можем просто обновить веса и смещения, увеличивая/уменьшая ее (см. диаграмму выше).
Это известно как градиентный спуск. Однако мы не можем напрямую вычислить производную функции потерь по весам и смещениям, потому что уравнение функции потерь не содержит весов и смещений. Поэтому нам нужно цепное правило, чтобы помочь нам вычислить его.
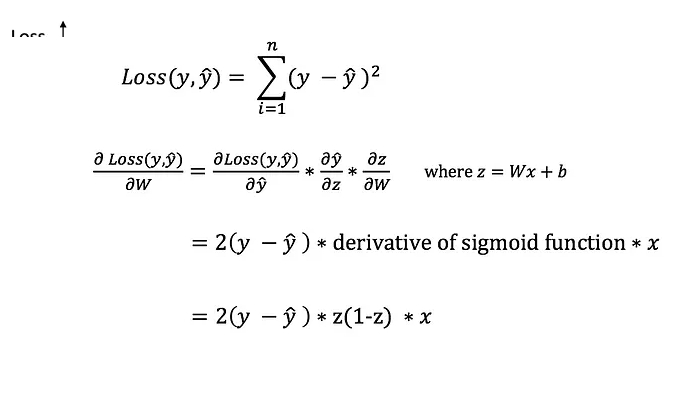
Фу! Это было некрасиво, но позволяет нам получить то, что нам нужно — производную (наклон) функции потерь по весам, чтобы мы могли соответствующим образом скорректировать веса. Теперь, когда у нас это есть, давайте добавим функцию обратного распространения в наш код Python.
class NeuralNetwork: def __init__(self, x, y): self.input = x self.weights1 = np.random.rand(self.input.shape[1],4) self.weights2 = np.random.rand(4,1) self.y = y self.output = np.zeros(self.y.shape) def feedforward(self): self.layer1 = sigmoid(np.dot(self.input, self.weights1)) self.output = sigmoid(np.dot(self.layer1, self.weights2)) def backprop(self): # application of the chain rule to find derivative of the loss function with respect to weights2 and weights1 d_weights2 = np.dot(self.layer1.T, (2*(self.y — self.output) * sigmoid_derivative(self.output))) d_weights1 = np.dot(self.input.T, (np.dot(2*(self.y — self.output) * sigmoid_derivative(self.output), self.weights2.T) * sigmoid_derivative(self.layer1))) # update the weights with the derivative (slope) of the loss function self.weights1 += d_weights1 self.weights2 += d_weights2
Собираем все вместе
Теперь, когда у нас есть полный код Python для прямого и обратного распространения, давайте применим нашу нейронную сеть на примере и посмотрим, насколько хорошо она работает.
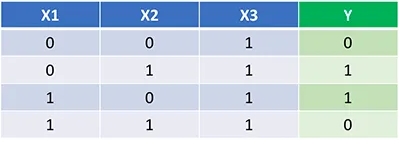
Наша нейронная сеть должна изучить идеальный набор весов для представления этой функции. Обратите внимание, что для нас не совсем тривиально определить веса только путем проверки.
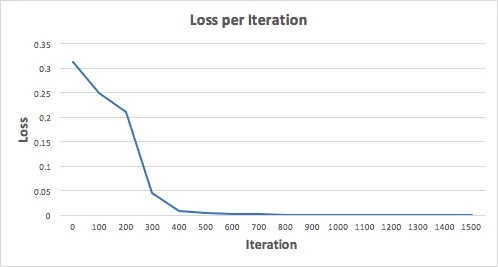
Давайте обучим нейронную сеть на 1500 итераций и посмотрим, что получится. Глядя на приведенный ниже график потерь на итерацию, мы ясно видим, что потери монотонно уменьшаются к минимуму. Это согласуется с алгоритмом градиентного спуска, который мы обсуждали ранее.
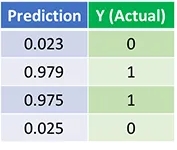
Давайте посмотрим на окончательный прогноз (выход) нейронной сети после 1500 итераций.
НЕЙРОСЕТЬ: просто о сложном! Создание нейронной сети на Python

Нейронные сети, машинное обучение, искусственный интеллект – все эти понятия крепко вошли в нашу жизнь. В статье мы изучим работу с нейросетями, а также создадим свою на Python.
Какие невероятные возможности открываются перед человеком при правильном и разумном применении машинного обучения, нейронных сетей и искусственного интеллекта в целом.
Обычный человек даже не замечает как часто и много он сталкивается с различного рода искусственным интеллектом в повседневной жизни. На самом деле, машинное обучение повсюду: в голосовых помощниках (Siri, Алекса, Кортана), на сайтах, в соц сетях, машинах и даже в том же Google переводчике. Там он используется, чтобы в случае непонимания слова перевести его на любой доступный язык, а далее с того языка переводить на искомый вариант. Это дает им возможность создать переводчик практически для всех языков мира.
При этом всем, до сих пор может показаться, что нейронные сети и машинное обучение где-то далеко, где-то в Калифорнии или в в скрытых штаб-квартирах компаний Google, Tesla, Apple и прочих.
В ходе статьи мы рассмотрим основные положения искусственного интеллекта и постараемся создать свою нейронную сеть на основе языка Python.
Искусственный интеллект
Ни для кого не секрет, что ИИ появился еще в середине прошлого столетия – в 1956 году. Тогда появилась сама концепция этой технологии, были описаны основные парадигмы и принципы. В те времена разработать ИИ не представлялось возможным, ведь тогдашние компьютеры были не мощнее современных калькуляторов, а, собственно, про какой ИИ может идти речь на калькуляторе?
Первый крупный прорыв состоялся в 1996 году. Тогда программа Deep Blue компании IBM обыграла чемпиона по шахматам Гарри Каспарова. Полноценным ИИ это сложно было назвать, ведь шахматы имеют конечное количество возможных ходов и программе необходимо было обладать знаниями обо всех возможных исходах, чтобы предсказать выигрышную стратегию для себя.

Следующий важный прорыв случился уже в 2016 году. Тогда программа AlphaGo компании Google DeepMind обыграла чемпиона мира по Го – Ли Седоля. Это стало важным событием, ведь в Го неограниченное или практически неограниченное количество возможных решений. Здесь в силу вступило машинное обучение, которое не оперировалось на всех возможных комбинациях игры, а оперировалось на основе своих собственных предположений, весов, которые подсказывали как стоит походить в разного рода ситуациях.
Это звучит как действительно настоящие компьютерные мозги, но насколько живи эти мозги? В статье мы еще подберемся к теме обучения нейронной сети, но пока лишь стоит сказать, что подобные программы основываются на достаточно простом для понимания принципе. В программу мы даем различные условия и говорим что при одном условии, будет выигрыш, а при другом — проигрыш. Обучив нейронку тысячами таких примеров она способна сама взвесить входные данные и понять к какому ответу они больше похожи — к выигрышному или наоборот.
Машинное обучение и глубокое обучение
Машинное обучение – это процесс обучения нейронной сети. Обучение, если говорить простыми словами, проходит за счёт указания нескольких вариантов одного решения, а затем нескольких вариантов другого. Далее нейронная система будет иметь некие весы для взвешивания новых задач и будет определять какое значение мы ей предлагаем.
Глубокое обучение – это подмножество машинного обучения. Оно является более дорогим и обучение проходит на гораздо большем массиве данных.
Получается следующая иерархия: есть нейронные сети, которые требуется обучить, выполнить машинное обучение или глубокое обучение. После их обучения мы получаем искусственный интеллект, что способен сам решать поставленные перед ним задачи.
Задача классификации
Теперь рассмотрим нейронную сеть на примере задачи классификации. Нейронные сети способны решать множество задач, мы же рассмотрим наиболее простую из них – задачу классификации. Суть задачи состоит в классификации объекта к определенной группе. Например, мы рисуем число 0, а нейронка должна понять что это за число. Другой пример, мы указываем характеристики автомобиля, а нейронка исходя из описания классифицирует машину и говорит её название.
В любой нейронке есть входные сигналы. Это те характеристики что мы с вами указываем, например, описание автомобиля. На основе этих данных нейронная сеть должна понять какой это автомобиль. Чтобы сделать решение она должна взвесить предоставленные данные и для этого используются, так называемые, весы. Это дополнительные числа, на которые в последствии будут умножены входные сигналы.

После умножения все данные суммируют, добавляется число корреляции и далее результат сравнивают с неким числом. Если итог более числа 0, то можно предположить, что машина, к примеру, Mercedes, а если менее 0, то это будет, например, BMW.