
Исторически сложилось так, что наиболее часто применяемый способ — это Threads в их различных реинкарнациях. Способ хорош тем что не требует дополнительных библиотек. Чтобы использовать этот вариант, достаточно имеющихся возможностей OC.
Обычно используется для скрытия от пользователя различных продолжительных операций, чтобы не терять возможность отрисовки GUI в момент ожидания операции. Основное достоинство — потоки разделяют адресное пространства и принадлежат одному процессу. Поэтому все передачи данных между потоками выполняются максимально быстро. Чаще всего достаточно передать указатель.
Синхронизация потоков не затратна и не требует системных вызовов (Syscall) — долгих операций с переключением контекста. Сюда же можно отнести и многопроцессные программы в самом простейшем виде — использующие fork() или что-то подобное из системных функций для порождения нового процесса, но применяющее для синхронизации и обмена данными системное API.
Для более простого распараллеливания уже существующего кода был придуман OpenMP. Больщинство работы по распараллеливанию и синхронизации здесь переложена на компилятор и его библиотеки. Для распараллеливания достаточно разместить определенные прагмы (#pragma …) в коде программы. Набор этих прагм описан в стандарте. Плюс такого подхода — легкость обретения параллелизма программой.
Уроки Ардуино. Как написать скетч: многозадачность на millis() и переключение режимов
Недостатки — требуется специальный компилятор, низкий уровень параллельности, необходимость следования навязываемой парадигме.
MPI (Message Passing Interface). Эта библиотека, как следует из названия не предназначена для какого либо распараллеливания, однако ее чаще всего применяют для написания параллельных программ на больших кластерах. Именно для написания, так как для применения MPI плохо подходит вариант «напишем последовательный код, а потом распараллелим».
В варианте с MPI программа сразу представляет собой N процессов. Это N фиксировано и задается параметром при запуске приложения. Т.е. это полный параллелизм, а библиотека предоставляет примитивы для синхронизации и обмена данными. К плюсам применения MPI относят высокую масштабируемость решения, высокий уровень параллельности и отличная портабельность кода. Основные минусы — сложности при программировании, относительно высокие затраты на синхронизацию и обмен данными.
Кроме основных трех способов существуют еще и другие малоизвестные, малоприменимые и/или устаревшие. Такие как GlobalArrays — распределенные структуры данных со скрытым доступом к элементам, PVM — прародитель MPI… Может еще чего есть — напишите мне, если знаете
Как это выглядит
Здесь я минимально приведу код, чтобы его можно было охватить глазами. Объяснять как это работает здесь смысла нет, для этого будут отдельные темы.
1. Создание двух процессов вызовом fork():
int main() < . pid = fork(); if (pid == 0) < // код потомка else< // код родителя>. >
2. Использование прагм openmp()
int main()< . #pragma parallel for for (int i=0; i
Источник: openmp.ru
Как создать программу в блокноте (Часть I)
Используем параллельные алгоритмы C++17 для улучшения производительности
1. Введение в параллельное программирование
Приступая к изучению основ параллельного программирования, необходимо прежде всего четко понять, в чем же заключается принципиальное отличие программы параллельной от программы последовательной. С этой целью рассмотрим один простейший пример.
Пусть перед нами стоит задача вычисления следующей суммы:

. (1)
Очевидно, что решение этой задачи на обычном однопроцессорном персональном компьютере не представляет никакой сложности и соответствующая программа на языке С имеет следующий вид:
int main(int argc, char **argv)
int S=0; /* искомая сумма */
int k; /* переменная цикла */
/* вычисление суммы */
/* печать результата на экран */
printf(“Sum is equal to %d”,S);
/* нормальное завершение работы программы */
Теперь предположим, что в нашем распоряжении имеется многопроцессорная вычислительная система (МВС), содержащая 32 процессора. Зададимся вопросом: каким образом можно осуществить вычисление суммы (1) на этой системе так, чтобы были задействованы все 32 процессора?
При этом естественно ожидать, что время вычисления на МВС должно быть существенно меньше, чем на обычном персональном компьютере * ) . Очевидно, что выигрыш во времени вычислений будет получен лишь в том случае, когда процессоры МВС будут работать одновременно, или параллельно. Но для этого каждый процессор должен выполнять свой набор операций, не зависящих от операций, выполняющихся на других процессорах системы. Отсюда естественным образом возникает задача, получившая в практике параллельного программирования название задачи декомпозиции и заключающаяся в разделении исходной задачи на ряд автономных, т.е. независимых друг от друга, подзадач. Решение каждой подзадачи осуществляется на отдельном процессоре МВС.
Для рассматриваемой нами задачи (1) можно легко выделить 32 независимые подзадачи: очевидно, что это возведение в куб первых 32 натуральных чисел:
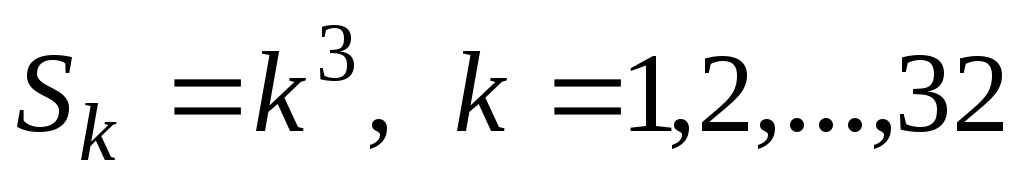
. (2)
Таким образом, мы можем поручить каждому из имеющихся в нашем распоряжении процессоров решение одной из задач (2). Для получения окончательного ответа нам необходимо просуммировать результаты, полученные на отдельных процессорах. Эту операцию будем выполнять на одном процессоре.
Какие же дополнительные функции нам потребуются, чтобы адаптировать рассмотренную выше программу для МВС? Прежде всего, это функции, позволяющие передавать данные от одного процессора к другому. Введем две такие гипотетические функции: Send и Recv. Применительно к рассматриваемой нами задаче эти функции могут иметь следующие прототипы:
void Send(int sbuf, int dest);
void Recv(int rbuf, int source);
Первая функция (Send) осуществляет передачу данных типа int, связанных с идентификатором sbuf на текущем процессоре, процессору с номером dest. Вторая функция (Recv) принимает данные типа int от процессора с номером source и связывает их с идентификатором rbuf на текущем процессоре. При этом под текущим понимается процессор, вызвавший ту или другую функцию.
При выполнении параллельной программы на МВС необходимо также знать порядковый номер каждого процессора и общее количество процессоров, которые задействованы в решении задачи. Именно через порядковый номер обычно происходит распределение подзадач по процессорам. Нумерация процессоров традиционно начинается с 0. Поэтому помимо уже введенных функций нам потребуются еще две функции:
void Rank(int MyID);
void Size(int NumProc);
Функция Rank(MyID) записывает в MyID номер текущего процессора, а функция Size(NumProc) возвращает в NumProc общее количество активных процессоров.
Теперь с помощью введенных функций мы можем написать параллельную программу для решения задачи (1):
int main(int argc, char **argv)
int S=0; /* искомая сумма */
int k; /* переменная цикла */
int SAdd; /* вспомогательная переменная */
int NumProc; /* количество процессоров */
int MyID; /* номер процессора */
/* определение количества
активных процессоров */
/* определение номера текущего процессора */
/* вычисление куба числа
на каждом процессоре */
/* передача результатов со всех процессоров
на процессор с номером 0 и вычисление на
этом процессоре окончательной суммы */
if (MyID!=0) Send(S,0);
/*печать результата на экран */
printf(“Sum is equal to %d”,S);
/* нормальное завершение работы программы */
Каким же образом будет выполняться данная параллельная программа на МВС? Сразу необходимо понять следующее: в принятой нами модели параллельного программирования (забегая чуть вперед отметим, что именно такая модель лежит в основе MPI) весь программный код выполняется каждым процессором, но со своим набором данных.
Другим словами, каждый процессор имеет свою копию программы, которую он и выполняет. Такая технология параллельного программирования носит название технологии разделения по данным. Так, в нашем случае после операции возведения в куб в переменной S на разных процессорах будут храниться разные числа: скажем, на втором процессоре это будет 27, а на девятом – 1000 (напомним, что процессоры нумеруются с 0!). Номер процессора хранится в переменной MyID.
Обратим также внимание на следующий весьма важный момент: если в параллельной программе необходимо выделить участок кода, который должен выполняться не всеми процессорами, а их частью или вообще одним процессором, то для этого используются условные операторы (структуры выбора языка С), в логические условия которых обязательно входит идентификатор номера процессора (в нашем случае MyID). Так, в приведенном примере функция Send будет вызвана всеми процессорами, кроме нулевого, а функция Recv, наоборот, будет вызвана только нулевым процессором, но 31 раз.
Далее отметим, что реализованный в нашей параллельной программе вычислительный алгоритм несколько отличается от алгоритма, по которому написана последовательная программа. А именно: в параллельной программе появилась дополнительная операция сложения – увеличение на единицу номера процессора. Поэтому количество вычислительных операций в последовательной и параллельной программе несколько различаются. Такая ситуация является достаточно типичной: при распараллеливании практически никогда не удается сохранить количество операций исходного последовательного алгоритма – в параллельном алгоритме оно всегда оказывается несколько больше.
В приведенном примере вывод результатов на экран осуществляет только нулевой процессор. Следует отметить, что стандарт MPI не оговаривает правила ввода-вывода и ряд его реализаций (в том числе и MPICH) допускают ввод и вывод данных через любой процессоор. Однако существуют реализации MPI не поддерживающие этот режим. Поэтому в данном пособии мы будем придерживаться следующего правила: ввод-вывод данных и весь диалог с пользователем в параллельной программе осуществляется только через нулевой процессор.
Подводя общий итог отметим, что для написания простейшей параллельной программы нам потребовалось ввести всего четыре гипотетические функции межпроцессорного обмена данными. Теоретически этих функций достаточно для написания любой параллельной программы. Тем не менее библиотека MPI содержит более 120 функций. Нетрудно догадаться, что такое многообразие обусловлено необходимостью создавать не просто параллельные программы, а эффективные параллельные программы. Поэтому прежде чем перейти к изучению самой библиотеки MPI остановимся кратко на вопросах оценки эффективности параллельных программ и факторах, влияющих на эту эффективность.
Источник: studfile.net