
Всё началось с того что, появилась необходимость хотя бы примерно оценить время выполнения участка кода. Оказалось у микроконтроллеров с ядром Cortex-M3 для этого предназначен специальный модуль, который называется Data Watchpoint and Trace Unit, сокращённо DWT.
Чтобы настроить DWT на измерение длительности выполнения кода, необходимо установить 2 бита.
Бит TRCENA в регистре DEMCR, установка единицы в который разрешает использовать DWT.
Бит CYCCNTENA в регистре DWT_CTRL, установка единицы в который запускает счётчик.
Текущее значение счётчика можно считать из 32-битного регистра CYCCNT.
Код, позволяющий оценить время выполнения кода, выглядит следующим образом
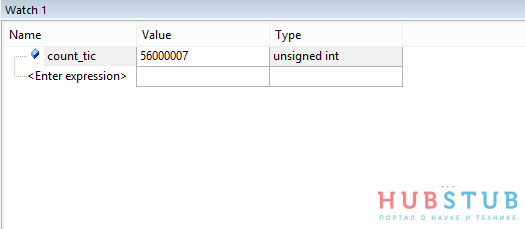
#define DWT_CYCCNT *(volatile unsigned long *)0xE0001004 #define DWT_CONTROL *(volatile unsigned long *)0xE0001000 #define SCB_DEMCR *(volatile unsigned long *)0xE000EDFC SCB_DEMCR |= CoreDebug_DEMCR_TRCENA_Msk;// разрешаем использовать DWT DWT_CYCCNT = 0;// обнуляем значение DWT_CONTROL|= DWT_CTRL_CYCCNTENA_Msk; // включаем счётчик Какой-то код count_tic = DWT_CYCCNT;//смотрим сколько натикало
count_tiс – количество тактов, в течение которых выполнялся код. Если мы хотим получить время надо разделить это значение на тактовую частоту, в моём случае на 56 000 000.
Расчёт времени выполнения программы на python #short
В принципе на этом можно было бы закончить, но есть желание разобраться соответствует ли в действительности то, что мы считываем из DWT_CYCCNT реальному времени.
Для того чтобы проверить это, давайте настроим таймер, который будет генерировать прерывание раз в секунду, внутри прерывания будем считывать значение DWT_CYCCNT, обнулять его и так по кругу.
#include «stm32f10x.h» #define DWT_CYCCNT *(volatile unsigned long *)0xE0001004 #define DWT_CONTROL *(volatile unsigned long *)0xE0001000 #define SCB_DEMCR *(volatile unsigned long *)0xE000EDFC uint32_t count_tic = 0; void TIM3_IRQHandler(void) { count_tic = DWT_CYCCNT; //останавливаем DWT DWT_CONTROL DWT_CYCCNT = 0; //выключаем таймер TIM3->CR1 //обнуляем его значение TIM3->CNT = 0; //сбрасываем флаг прерывания 2 раза, у меня он иначе он не сбрасывался TIM3->SR TIM3->SR > int main(void) { //включаем тактирование таймера RCC->APB1ENR |= RCC_APB1ENR_TIM3EN; //уcтанавливаем предделитель, новая частота таймера 10KHz TIM3->PSC = 5600 — 1; //период 1 секунда TIM3->ARR = 10000 — 1; //счётчик считает вниз TIM3->CR1 //в режиме одного импульса TIM3->CR1 |= TIM_CR1_OPM; //разрешаем прерывания TIM3->DIER |= TIM_DIER_UIE; NVIC->ISER[0] = NVIC_ISER_SETENA_29; //запускаем таймер TIM3->CR1 |= TIM_CR1_CEN; //включаем DWT SCB_DEMCR |= CoreDebug_DEMCR_TRCENA_Msk; DWT_CYCCNT = 0; DWT_CONTROL|= DWT_CTRL_CYCCNTENA_Msk; while(1) { //включаем таймер TIM3->CR1 |= TIM_CR1_CEN; //запускаем DWT DWT_CONTROL|= DWT_CTRL_CYCCNTENA_Msk; > >
КАК ИЗМЕРИТЬ ВРЕМЯ ВЫПОЛНЕНИЯ ПРОГРАММЫ, КОДА, МЕТОДА, ФУНКЦИИ, ЗАПРОСА | C# STOPWATCH | C# ПЛЮШКИ
Установка бита TIM_CR1_OPM включает режим одиночного импульса, в этом режиме после возникновения события счёт прекращается.
Первое значение отличается от остальных, потому как таймер и счётчик надо бы запустить одновременно, следующие отличаются от расчётного значения на несколько тактов, которые необходимы для сохранения значения DWT_CYCCNT в count_tic, то есть данный способ работает. На этом всё, спасибо за внимание.
Источник: hubstub.ru
Как оценить время выполнения программы
1. Влияет ли на цикл системы тип используемых блоков обработки переменных – int, long, real? Насколько существенно это влияние?
2. Что выгоднее использовать с точки зрения сокращения цикла: два блока с двумя входами (or, and, add и т.п.) или тот же блок, но один, и с четырьмя входами? Или одинаково?
3. Что выгоднее использовать с точки зрения сокращения цикла: два блока screen str с одной строчкой или один блок с двумя строчками? Или одинаково?
4. Аналогичный вопрос по блокам EEPROM — что быстрее будет работать, два блока по одной ячейке или один блок на две ячейки?
Вообще, было бы очень кстати иметь хотя бы оценочное представление о потребности ресурсов всех блоков, для оптимального написания программы.
Полезные вопросы. Когда я задался такими вопросами, то выставлял множество однотипных блоков на ‘поляну’ и смотрел, сколько они выполняются времени.
1) Существенно. Если учесть, что мега — восьмиразрядный процессор без встроенной математики, то вполне логично, что (например) сложение двух шеснадцатиразрядных (int) чисел выполняется быстрее, чем сложение двух тридцатидвухразрядных (long). И тем более особняком стоит математика для чисел с плавающей точкой. Не проверял, но ‘на глазок’ сложение двух real в несколько раз (а то и на порядок) медленнее сложения двух int. Если внимательно рассмотреть прикладные макросы и макросы в наших типовых программах (в особенности в программах, генерируемых конструктором), то можно увидеть, что real используются только там, где это действительно необходимо.
2) два блока будут выполняться дольше, т.к. внутри SMH интерпретатор, который выполняет эти блоки по одному. Перейти на другой блок дольше, чем обработать дополнительные входы. В вашем случае всё прозрачно: два блока с двумя входами — это 8 операций (считать блок, считать 2 входа, записать результат, считать блок, считать 2 входа, записать результат), если один блок с 4 входами, то это 6 операций. Плюс к этому ещё и меньше места в памяти занимает.
3) блок screen выводит в один момент одну строку. Общее количество строк влияет только на объём занимаемой памяти. То же относится и с мультиплексорам: блок с 2 входами выполняется ровно такое же время, как и блок с 255 выходами.
4) всё как и в 3 пункте. Тут уже как удобнее использовать — два блока по 1 ячейке не требуют операции чтения, но занимают больше времени в цикле. С другой стороны, организация цикла чтения также займёт дополнительные блоки, следовательно и дополнительное время.
Быстродействие по возрастанию: SMH-2G, Pixel-25, Pixel-12, SMH2010, SMH-2Gi, SMH4, Trim5.
В процентах условно-примерно как 100%, 110%, 120%, 150%, >1000%, >3500%, >3000% и очень зависит от подключенной периферии для расширяемых серий. В масимуме «железа» производительность Pixel-25/SMH-2G падает процентов на 10..15%.
Отступление: SMH2010 — полностью синхронное устройство. Остальные контроллеры асинхронны, т.е. быстродействие программы отличается от быстродействия периферии (программа как правило быстрее).
Время выполнения программы всегда можно посмотреть в системном меню контроллеров Pixel и SMH-2G, или в любых контроллерах с помощью блока Device(kernel)
Также нужно учитывать, что в режиме отладки быстродействие AVR-контроллеров (SMH2010, Pixel, SMH2G) падает примерно на 30%.
Контроллеры на базе linux тоже замедляются в отладке, но на фоне их огромной валовой мощности это практически незаметно.
__________________
Добро всегда побеждает зло. Кто победил — тот и добрый.
Источник: forum.segnetics.com
С++ Оценка времени выполнения кода
Весьма полезно иметь возможность оценить время выполнения какого-то фрагмента кода или потока чтобы выполнить оптимизацию.
Для этого необходима библиотека
#include «chrono»
или #include «thread», которая уже включает библиотеку chrono.
Суть измерения – запоминаем «системное» время в начале кода и по его окончанию и высчитываем разницу.
За работу со временем отвечает библиотека chrono.
int main() < auto Start=chrono::high_resolution_clock::now(); //старт подсчета времени for(int i=0;i<10;++i) < Sleep(100); //задержка 100мс >auto Stop=chrono::high_resolution_clock::now(); //стоп подсчета времени chrono::duration Delta=Stop-Start; //высчитываем разницу cout private: std::chrono::time_point Time_Start, Time_Stop; >;
Примечание: тип переменной std::chrono::time_point
взят для windows и QtCreator – в вашей ос и IDE (или другой версии IDE м.б. иной тип переменной)
Пример использования класса:
int main() < coutTimeCode.EndCnt(); cout
Если оценка времени не нужна — комментируем #define TimeDebug
Источник: iot-embedded.ru