Поисковые каталоги Взгляните на эту книгу. Она начинается с Содержания и заканчивается Алфавитным указателем. Несмотря на то, что они расположены в разных местах книги и выглядят совершенно по-разному, задача у них одна: помочь найти в книге именно тот раздел, который в данный момент нужен.
Подобные программы называют червяками, пауками, гусеницами, краулерами, спайдерами и другими подобными именами. Каждый поисковый указатель эксплуатирует для этой цели свою уникальную программу, которую нередко сам и разрабатывает.
Многие современные поисковые системы родились из экспериментальных проектов, связанных с разработкой и внедрением автоматических программ, занимающихся мониторингом Сети. Теоретически, при удачном входе спайдер способен прочесать все Webпространство за одно погружение, но на это надо очень много времени, а ему еще необходимо периодически возвращаться к ранее посещенным ресурсам, чтобы контролировать происходящие там изменения и выявлять «мертвые», т. е. потерявшие актуальность ссылки.
Фишки Chrome и Windows: сохранение страниц в браузере, плагины, управление чужим компьютером
Неактуальными называют ресурсы, которые по каким-то причинам перестали существовать (или изменили местоположение), хотя гиперссылки, имеющиеся в других ресурсах, продолжают на них указывать. При использовании «мертвых» гиперссылок мы получаем сообщение от броузера о том, что ресурс не найден.
После копирования разысканных Web-ресурсов на сервер поисковой системы начинается второй этап работы — индексация. В ходе индексации создаются специальные базы данных, с помощью которых можно установить, где и когда в Интернете встречалось то или иное слово. Считайте, что индексированная база данных — это своего рода словарь.
Она необходима для того, чтобы поисковая система могла очень быстро отвечать на запросы пользователей. Современные системы способны выдавать ответы за доли секунды, но если не подготовить индексы заранее, то обработка одного запроса будет продолжаться часами. На третьем этапе происходит обработка запроса клиента и выдача ему результатов поиска в виде списка гиперссылок.
Допустим, клиент хочет узнать, где в Интернете имеются Web-страницы, на которых упоминается известный голландский механик, оптик и математик Христиан Гюйгенс. Он вводит слово Гюйгенс в поле набора ключевых слов и нажимает кнопку Найти (Search).
По своим базам указателей поисковая система в доли секунды разыскивает подходящие Web-ресурсы и формирует страницу результатов поиска, на которой рекомендации представлены в виде гиперссылок, Далее клиент может пользоваться этими ссылками для перехода к интересующим его ресурсам. Все это выглядит достаточно просто, но на самом деле здесь есть проблемы.
Основная проблема Современного Интернета связана с изобилием Web-страниц. Достаточно ввести в поле поиска такое простое слово, как, например, «футбол», и российская поисковая система выдаст несколько тысяч ссылок, сгруппировав их по 1020 штук на отображаемой странице.
Несколько тысяч — это еще не так много, потому что зарубежная поисковая система в аналогичной ситуации выдала бы сотни тысяч ссылок. Попробуйте найти среди них нужную! Впрочем, для рядового потребителя совершенно все равно, выдадут ему тысячу результатов поиска или миллион. Как правило, клиенты просматривают не более 50 ссылок, стоящих первыми, и что там делается дальше, мало кого беспокоит. Однако клиентов очень и очень беспокоит качество самых первых ссылок. Клиенты не любят, когда в первом десятке встречаются ссылки, утратившие актуальность, их раздражает, когда подряд идут
Как работают веб приложения. Что происходит, когда вы вводите адрес в браузере
ссылки на соседние файлы одного и того же сервера. Самый же плохой вариант — когда подряд идут несколько ссылок, ведущих к одному и тому же ресурсу, но находящемуся на разных серверах. Клиент вправе ожидать, что самыми первыми будут стоять наиболее полезные ссылки. Вот здесь и возникает проблема.
Человек легко отличает полезный ресурс от бесполезного, но как объяснить это программе?! Поэтому лучшие поисковые системы проявляют чудеса искусственного интеллекта в попытке отсортировать найденные ссылки по качественности их ресурсов. И делать это они должны быстро — клиент не любит ждать.
Строго говоря, все поисковые системы черпают исходную информацию из одного и того же Web-пространства, поэтому исходные базы данных у них могут быть относительно похожи. И лишь на третьем этапе, при выдаче результатов поиска, каждая поисковая система начинает проявлять свои лучшие (или худшие) индивидуальные черты.
Операция сортировки полученных результатов называется ранжированием. Каждой найденной Web-странице система присваивает какой-то рейтинг, который должен отражать качество материала. Но качество — понятие субъективное, а программе нужны объективные критерии, которые можно выразить числами, пригодными для сравнения.
Высокие рейтинги получают Web-страницы, у которых ключевое слово, использованное в запросе, входит в заголовок. Уровень рейтинга повышается, если это слово встречается на Web-странице несколько раз, но не слишком часто. Благоприятно влияет на рейтинг вхождение нужного слова в первые 5-6 абзацев текста — они считаются самыми важными при индексации.
По этой причине опытные Web-мастера избегают давать в начале своих страниц таблицы. Для поисковой системы каждая ячейка таблицы выглядит как абзац, и потому основной содержательный текст как бы далеко отодвигается назад (хотя на экране это и не заметно) и перестает играть решающую роль для поисковой системы.
Очень хорошо, если ключевые слова, использованные в запросе, входят в альтернативный текст, сопровождающий иллюстрации. Для поисковой системы это верный признак того, что данная страница точно соответствует запросу. Еще одним признаком качества Web-страницы является тот факт, что на нее есть ссылки с каких-то других Web-страниц. Чем их больше, тем лучше.
Значит, эта Web-страница популярна и обладает высоким показателем цитирования. Самые совершенные поисковые системы следят за уровнем цитирования зарегистрированных ими Web-страниц и учитывают его при ранжировании. Создатели Web-страниц всегда заинтересованы в том, чтобы их просматривало больше людей, поэтому они специально готовят страницы так, чтобы поисковые системы давали им высокий рейтинг. Хорошая, грамотная работа Web-мастера способна значительно поднять посещаемость Web-страницы, однако есть и такие «мастера», которые пытаются обмануть поисковые системы и придать своим Web-страницам значимость, которой в них на самом деле нет. Они многократно повторяют на Webстранице какие-то слова или группы слов, а для того чтобы те не попадались на глаза читателю, либо делают их исключительно мелким шрифтом, либо применяют цвет текста, совпадающий с цветом фона.
За такие «хитрости» поисковая система может и наказать Web-страницу, присвоив ей штрафной отрицательный рейтинг. В последние годы сложилась и практика коммерческого рейтингования. В этом случае поисковая система дает более высокий рейтинг тем Wеb-страницам. за которые их владелец заплатил.
Невзирая на очевидную субъективность такого подхода. в нем есть определенный смысл для тех, кто ищет информацию в Интернете по распространенным словам. Например, если клиент ввел в поле поиска слово «автомобиль» или «сантехника», то можно предположить, что он хочет приобрести либо машину, либо смеситель для мойки.
В этом случае ему не нужны романы из жизни сантехников, как не нужны и рассуждения об управлении автомобилем. Почему бы не дать ему на первом месте среди результатов поиска адреса известных торговых фирм? Необходимость в ранжировании результатов поиска очевидна.
Без этого клиенты захлебнулись бы в потоке предлагаемых ссылок и. может быть, так никогда и не добрались бы до самых полезных для себя ресурсов. Однако у ранжирования есть и негативная сторона. У каждой поисковой системы своя политика ранжирования, и не исключено, что взгляды создателей поисковой системы не вполне совпадают со взглядами клиента.
Очень может быть и так, что до каких-то ценных для себя ресурсов он никогда и не доберется, потому что по результатам ранжирования они всегда будут отодвигаться глубоко вниз. Из этого можно сделать несколько выводов: • Во-первых, старайтесь избегать прямолинейного поиска по одному слову.
Дайте поисковой системе группу ключевых слов, а еще лучше — фразу. • Для поиска по группе слов или по ключевой фразе используйте не какую попало поисковую систему, а ту, к которой наиболее привыкли. В разных системах используются разные правила для записи группы слов, и эти правила надо знать (об этом мы поговорим ниже). • Если пользуетесь поиском по одному слову, то, наоборот, применяйте как можно больше разных поисковых систем.
То, что они используют разные алгоритмы рейтингования, нам на пользу — это дает шанс не пропустить какой-то значимый ресурс. Краткий обзор поисковых указателей России За рубежом возникновение первых поисковых указателей относится к 19941995гг., а в России — к 1996-1997 гг.
Поскольку в России объем Web-ресурсов составляет лишь несколько процентов от мирового, отечественным поисковым системам работать много проще, чем западным. Технически они оснащены самыми современными средствами, соответствующими уровню 2000 года, а общий размер Рунета (российского сектора Интернета) сегодня примерно таков, каким был западный сектор в 1994 1995 гг.
Поэтому сегодня в России особых проблем с поиском информации нет и в ближайшее время они не предвидятся. А в западном секторе проблемы с поиском очень большие, и разные поисковые системы пытаются по-разному их преодолеть. О том, как это происходит, мы и расскажем. Из поисковых указателей в России сегодня действуют три главных (есть и более мелкие системы, но мы останавливаться на них не будем). Это «Рамблер» (www.rambler.ru), «Яндекс» (www.yandex.ru) и «Апорт2000» (www.aport.ru).
категориям. Кроме того, в системе есть специальный раздел каталожного типа, который называется Special Editions. Он ведется вручную, и в нем можно найти готовые подборки материалов по актуальным проблемам. Имеется в системе и небольшой коммерческий раздел Special Collections. Его материалы поставляются за деньги. Впрочем, коммерческий раздел невелик и совершенно не портит систему.
По-видимому, он рассчитан на журналистов, которым могут срочно потребоваться справки по «горячим» темам. Проверка и выбор поискового указателя Конкретные рекомендации по выбору поискового указателя очень быстро стареют. Ситуация в Интернете меняется буквально на глазах. Не проходит и полугода, чтобы что-нибудь не изменилось и в поисковых системах.
Та система, которая была наилучшей вчера, может быть не самой лучшей сегодня и очень плохой завтра. В то же время популярность — вещь хитрая. Она трудно зарабатывается, но потом и долго живет. В итоге мы очень часто встречаемся с ситуацией, когда самой популярной является далеко не лучшая система.
Мы поможем читателю научиться самостоятельно проверять разные поисковые системы и выбирать для работы те, которые дают лучшие результаты. При проверке размер поискового указателя не имеет решающего значения . Нам ведь нужны не миллионы ссылок, а всего две-три, но желательно самые лучшие.
Поэтому важно не только то, как много Web-страниц проиндексировала поисковая система, но и то, когда она это делала в последний раз, как часто потом проверяла актуальность ссылок и насколько корректно представляет результаты поиска. Чтобы проверить качество работы поисковой системы, надо дать ей задание на розыск сведений, о которых устаревшая система знать не может.
Вот тут-то и проявится гниль тех систем, которые когда-то нагребли горы материала, а теперь не обновляют его и представляют клиентам старье, густо сдобрив рекламой. Давайте проведем такой опыт. Допустим, мы узнали, что в течение последних месяцев 2000 года мир интересовался ходом выборов президента США.
Попробуем заказать в разных системах поиск документов, в которых одновременно содержатся три слова: Буш, Гор и выборы. Вот что он дает: «Рамблер» — 45 документов; «Апорт» — 3338 документов; «Яндекс» — 17 036 документов. В том, что «Апорт» отстает от «Яндекса», нет ничего удивительного, ведь «Апорт» никогда не стремился к механическому увеличению размеров указателя.
Его сильная сторона — качественный отбор. Но нельзя не обратить внимание на результат «Рамблера», имеющего внушительный указатель, который всего лишь в два раза меньше указателя «Яндекса». Этот нехитрый эксперимент говорит о том, что как поисковая система «Рамблер» прекратил свое развитие и, по-видимому, сосредоточивается на чем-то другом.
Такой же опыт можно поставить и за рубежом. Мы, например, разыскиваем Webстраницы, на которых упоминается операционная система с проектным названием Microsoft Whistler. К моменту написания этой книги она еще не существовала в природе.
Те поисковые системы, которые плохо обновляют указатели, неминуемо проявят себя на этом задании.
| Ключевые слова | Поисковая система | Результат поиска |
| +Mkrosoft +Whistler | Alta Vista (230 млн) | 2800 |
| Microsoft Whistler | Northern Light (250 млн) | 14 000 |
| Microsoft Whistter | Fast Search (580 млн) | 26 900 |
Как видите, две самые современные системы, Northern Light и Fast Search, различаются по результатам примерно так же, как различаются размеры их указателей. Результат, выдаваемый системой Alta Vista, заметно хуже. А теперь сами назовите слово, характеризующее указатель Alta Vista, если свежей информации в нем в пять раз меньше, чем в Northern Light.
Заметим также, что выдача результатов в системе Alta Vista происходит очень медленно. Классификационно-рейтинговые системы Строго говоря, эти системы не являются поисковыми, но, если надо найти «то, не знаю что», ими удобно пользоваться. Самый крупный классификатор в России — «Рамблер Тор 100» размещается на портале «Рамблер» (www.rambler.ru).
Классификатор похож на каталог, но, в отличие от каталога, перед ним не ставится задача собрать как можно больше информации о ресурсах Сети. По каждой из категории, входящих в классификатор, представляются лучшие сайты, а дальше работает счетчик. Чем больше посетителей обращаются к конкретному сайту, тем выше показания счетчика.
Те, кто вышел в Сеть без серьезных намерений, но с общим желанием отдохнуть и познакомиться, например, с музыкальными новинками, могут увидеть, какие сайты в этой области посещаются чаще других и. соответственно, начать свое путешествие именно с них. Приемы поиска информации Рассказывать о том, как пользоваться поисковыми каталогами, нет никакой необходимости.
Надо просто зайти на сайт (адреса мы уже дали), выбрать категорию, которая интересует, в ней выбрать раздел, и так далее, пока не откроется список конкретных ссылок. Точно так же работают и с классификаторами, только там против каждой ссылки на сайт имеется число, показывающее, сколько людей воспользовались этим адресом в последние сутки (в последний час, в последнюю неделю).
Значительно интереснее рассмотреть приемы использования поисковых указателей, тем более что для разных указателей эти приемы разные. Но прежде чем приступать к изучению конкретных систем, давайте рассмотрим общие концепции, равно относящиеся ко всем поисковым указателям. Четыре вида поиска Все поисковые указатели реализуют несколько алгоритмов поиска. К ним относятся: простой поиск, расширенный поиск, контекстный поиск и специальный поиск.
Источник: studfile.net
Как работают поисковые системы. Разбираемся, что такое сканирование, индексирование и ранжирование
Хола, котаны! Поисковые системы обнаруживают, обрабатывают и систематизируют все, что есть в Интернете. Благодаря этому, в Google или Яндексе пользователи получают ответы на запросы. Однако не все так быстро: чтобы контент отображался в результатах поиска, сначала его должна увидеть поисковая система.
В статье мы расскажем, как поисковики сканируют, индексируют и ранжируют контент, и объясним, почему этот момент важен для рекламодателей. Присаживайтесь поудобнее и читайте статью!
Поделиться
Сегодня слово “поисковик” ассоциируется с Google. И не зря: это самая популярная поисковая система в мире. 9 из 10 людей используют Google, когда хотят найти информацию в Интернете.
Список популярных поисковых систем
- Bing
- Baidu
- Yahoo!
- Яндекс
Зарубежные поисковики
- About
- Find-It!
- Dogpile
- Arianna
- InfoSpace
- Internet Sleuth
- Jayde
- Lycos
- Meta Eureka
- Meta Crawler
- Qwant
Поисковики без запретов
- DuckDuckGo
- not Evil
- YaCy
- Pipl
- Dogpile
- BoardReader
Как работают поисковые системы интернета? Разбираем, как работает поисковая система Google
- сканируют: находят в Интернете контент на каждом URL;
- индексируют: хранят и систематизируют контент. Как только страница попадает в индекс, она отображается в результате выполнения соответствующих запросов;
- ранжируют: предоставляют фрагменты контента, которые соответствуют запросу пользователя. Результаты упорядочены в порядке от наиболее релевантного к наименее релевантному.
Как работают алгоритмы гугл. Выясняем, что такое сканирование поисковыми системами
Сканирование — это процесс, с помощью которого поисковые системы обнаруживают обновленный контент в Интернете, например, новые сайты или страницы, изменения на сайтах и мертвые ссылки. Для этого поисковик использует программу, которую называют сканером, ботом или пауком (у каждой поисковой системы свой тип).


Он работает по алгоритму, чтобы определить, какие сайты сканировать и как часто. Контент бывает разным — это веб-страница, изображение, видео, PDF-файл и т.д. Независимо от формата контент обнаруживается по ссылкам.
Googlebot начинает с загрузки нескольких веб-страниц, а затем переходит по ссылкам на этих веб-страницах, чтобы найти новые URL-адреса. Перепрыгивая по пути ссылок, сканер находит релевантный материал и добавляет его в индекс Caffeine — базу обнаруженных URL-адресов. Так и открывается новый контент.
Что такое индекс поисковой системы
Поисковые системы обрабатывают и хранят информацию, которую находят, в индексе — базе данных контента. Как только поисковик обрабатывает каждую из просматриваемых страниц, он составляет индекс видимых слов и их расположение на каждой странице. По сути, это база данных из миллиардов веб-страниц.
Затем извлеченный контент сохраняется, а информация систематизируется и интерпретируется алгоритмом поисковой системы для измерения важности по сравнению с аналогичными страницами.
Благодаря этим серверам, пользователи получают доступ к интернет-страницам в доли секунды. Для хранения и сортировки информации требуется много места, поэтому у Microsoft и Google более миллиона серверов.
Рейтинг в поисковых системах. Как происходит Индексация сайта в Google?
После ввода ключевика в окно поиска системы проверяют страницы в индексе, чтобы те соответствовали запросу. Оценка этим страницам выставят на основе алгоритма, который состоит из сотен сигналов ранжирования.
Эти страницы (или изображения и видео) будут отображаться пользователю в зависимости от поставленной оценки.
Чтобы сайт занимал высокое место на страницах результатов поиска, важно убедиться, что поисковые системы правильно его сканируют и индексируют. В противном случае они не смогут ранжировать контент сайта в результатах поиска.
Советуем почитать — Что нужно знать о новых ограничениях на ежемесячные расходы в Google Ads?
- типология сайтов: рейтинг, который сделан поисковой системой, чтобы отличить один запрос от другого;
- контекст;
- время;
- макет: поисковая выдача покажет разные результаты в зависимости от цели поиска.
Типология сайтов
Как только пользователь набирает запрос, первое, что делает поисковая система, — это классифицирует его, чтобы получить типологию для запроса.
- сайты местных компаний;
- сайты для взрослых;
- новостные сайты и прочее.
Контекст
- социальные факторы;
- исторические факторы;
- экологические факторы;
- позицию;
- время;
- тип запроса.
Время
В работе стоит учитывать это соотношение времени выполнения и индексации контента.
По этой причине на результаты, например, «Первая мировая война» больше влияет источник, в то время как для «фильмы, которые уже вышли» поисковая система отдает приоритет свежести контента.
Макет результатов
Если ищет человек видео, то такой контент Google и будет показывать в поисковой выдаче.
Если цель поиска — тема, в которой много релевантных запросов, появляется поле «Люди также ищут».
И это также относится к другим элементам поисковой выдачи — темам и связанным поисковым запросам.
Google, Яндекс, Baidu и Microsoft и другие поисковики позволяют пользователям всего мира находить невообразимое количество информации. Так, сегодня поисковые системы — едва ли не самое совершенное техническое решение, которое видел мир.
В перспективе поисковики будут развиваться в сторону естественных интерфейсов, таких как голос и изображения. Сегодня работа систем, в основном, основана на ключевиках и тексте.
Продвижение в поисковиках — один из лучших способов привлечь и монетизировать аудиторию. Но чтобы конкурировать с другими платформами, важно понимать, как поисковая система обрабатывает контент и по каким принципам отображает его аудитории. Используйте советы из статьи, чтобы ваш сайт как можно лучше ранжировался и получил больше возможностей попасть на первые страницы поисковой выдачи.
Источник: gdetraffic.com
Средства поиска информацииWWW

На этом уроке учащиеся рассмотрят различные поисковые службы интернета. Узнают, чем отличаются друг от друга поисковые каталоги и поисковые указатели. Рассмотрят механизмы работы поисковых служб и увидят пример работы с поисковым каталогом.

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет.
Получите невероятные возможности

1. Откройте доступ ко всем видеоурокам комплекта.

2. Раздавайте видеоуроки в личные кабинеты ученикам.

3. Смотрите статистику просмотра видеоуроков учениками.
Получить доступ
Конспект урока «Средства поиска информацииWWW»
На прошлых уроках мы узнали что интернет – это не только система компьютерных сетей, а так же и глобальная информационная система, которая предоставляет пользователям возможности доступа к информации, а так же общения между собой.
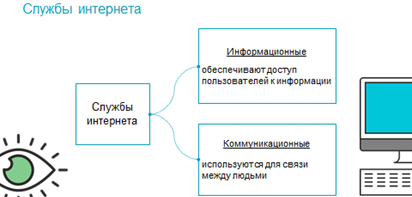
Возможности, которые предоставляет интернет, представлены его службами, которые можно разделить на информационные и коммуникационные. Информационные службы – предоставляют пользователям доступ к различной информации, а коммуникационные – дают возможность общения между собой.
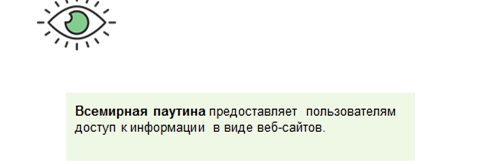
Самой массовой службой интернета, является всемирная паутина. Она предоставляет пользователям доступ к информации в виде сайтов.
Вспомним, что любой компьютер, подключённый к интернету получает уникальный тридцатидвухбитный идентификатор, или IP-адрес.
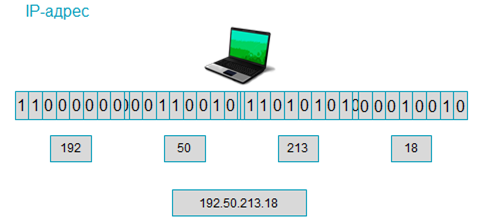
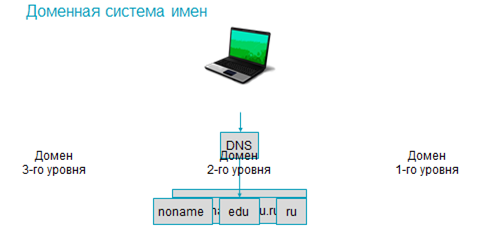
Который для удобства восприятия пользователями делится на четыре октета, а затем значение каждого из них переводится в десятичную систему счисления. Полученные числа записываются по порядку и разделяются точками. Благодаря доменной системе имён или DNS некоторые узловые компьютеры так же получают уникальные символьные имена, которые называются доменными. Доменные имена имеют иерархическую структуру, доменное имя содержит название самого домена, а также всех доменов, в которые он входит. Они записываются от последнего уровня к первому, разделяясь точками.
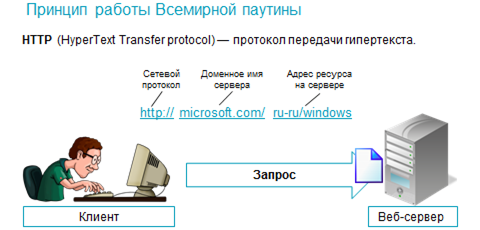
Всемирная паутина так же является структурой данных. Она состоит из документов, которые связаны между собой гиперссылками. Текст, который содержит гиперссылки, называется гипертекстом.

Всемирная паутина работает по системе «клиент-сервер» согласно протоколу передачи гипертекста HTTP. Так компьютер-клиент, отправляет запрос на веб-сервер, который содержит веб-страницы, а веб-сервер отправляет клиенту указанную в запросе страницу или, если она недоступна – сообщение об ошибке. Для запроса нужной веб-страницы используется её универсальный указатель ресурса или URL», состоящий из названия сетевого протокола, доменного имени веб-сервера, а также расположения ресурса, на сервере.