
Поисковый робот (web crawler, или веб-паук) — это специальная программа, которая в автоматическом режиме сканирует веб-страницы и передает собранные данные поисковой системе или компании-владельцу.
Самые известные пользователи краулеров — поисковики. Их пауки переходят по доступным ссылкам, собирают и анализируют содержимое страниц в интернете и отправляют полученные данные на сервер поисковой машины, чтобы пополнить и обновить выдачу.
Зачем нужен поисковый робот
Поисковые роботы — ключевой элемент работы поисковой системы и связующее звено между опубликованным контентом и пользователем. Если веб-страница не просканирована и не добавлена в базу поисковика, она не появится в выдаче. Попасть на нее можно будет только по прямой ссылке.
Роботы также влияют на ранжирование. Например, неизвестные краулеру API и функции JavaScript мешают корректно просканировать сайт. В результате на сервер отправляются страницы с ошибками, а часть контента на них и вовсе может оказаться в слепой зоне робота.
Как работает поисковая система
Поскольку на следующих этапах поисковые системы применяют к полученным данным специальные алгоритмы для выдачи пользователям более релевантной информации, такие некачественные страницы могут оказаться на дне поиска.
Как работает поисковый робот
Прежде чем сайт или файл попадет в базу поисковой системы для дальнейшего ранжирования, робот должен его найти. Чаще всего это происходит автоматически: страницы обнаруживаются при переходе по ссылкам с уже известных боту разделов сайта. Например, при переобходе блога паук фиксирует появление новой записи в нем и вносит ее в расписание следующего обхода.
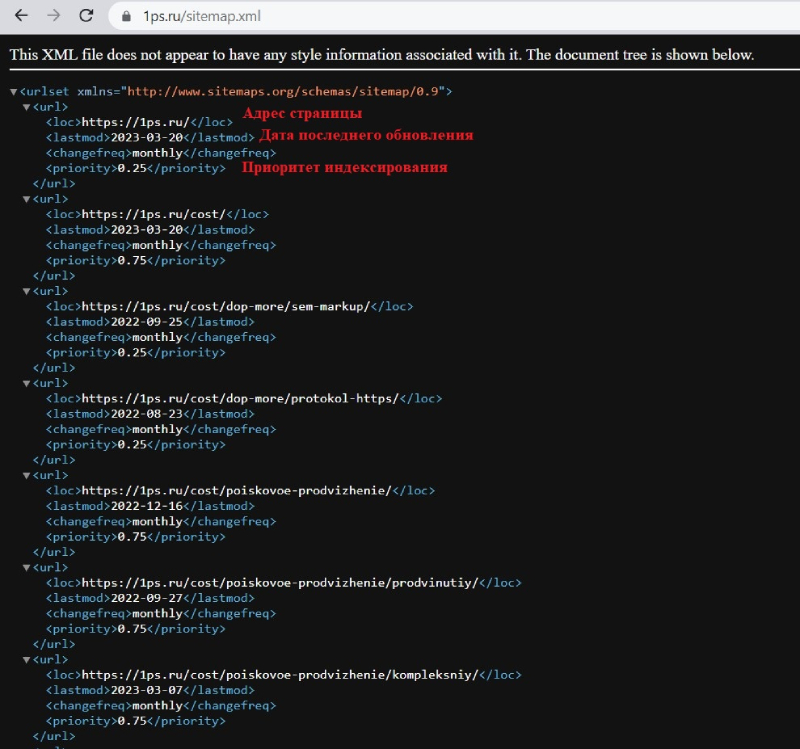
Если на сайте есть файл sitemap.xml ( карта сайта ), то при каждом его обновлении краулер считывает оттуда ссылки для сканирования.
Передать роботу конкретный URL на сканирование можно и вручную. Для этого нужно подключить сайт к «Яндекс.Вебмастеру» (или Google Search Console) и ввести в специальном разделе ссылку на страницу, которая должна быть проиндексирована.
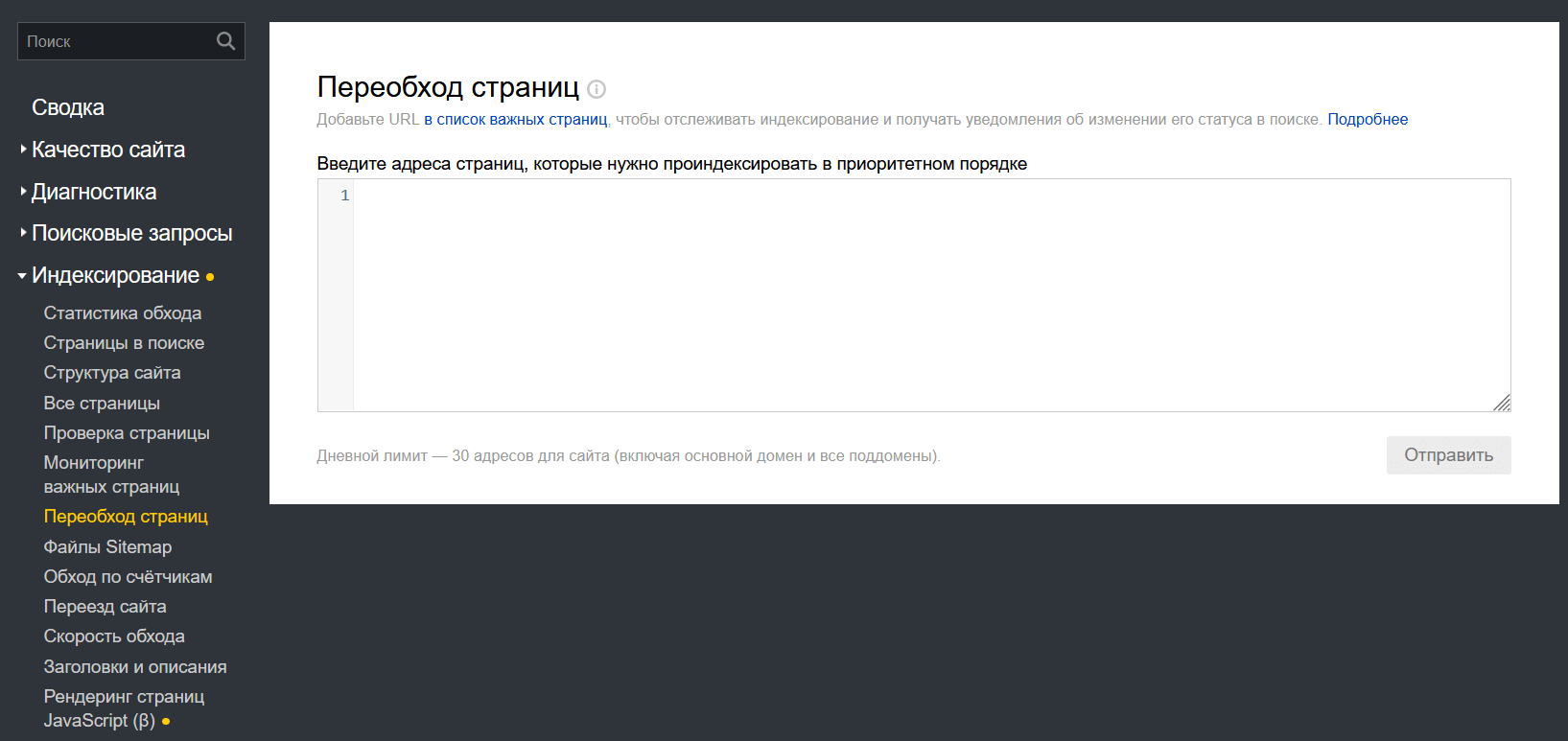
Интерфейс инструмента «Яндекс.Вебмастера» для ручного добавления страниц в очередь на индексацию
Далее, если страница доступна, происходит ее сканирование. Краулер считывает текстовое содержимое, теги и гиперссылки.
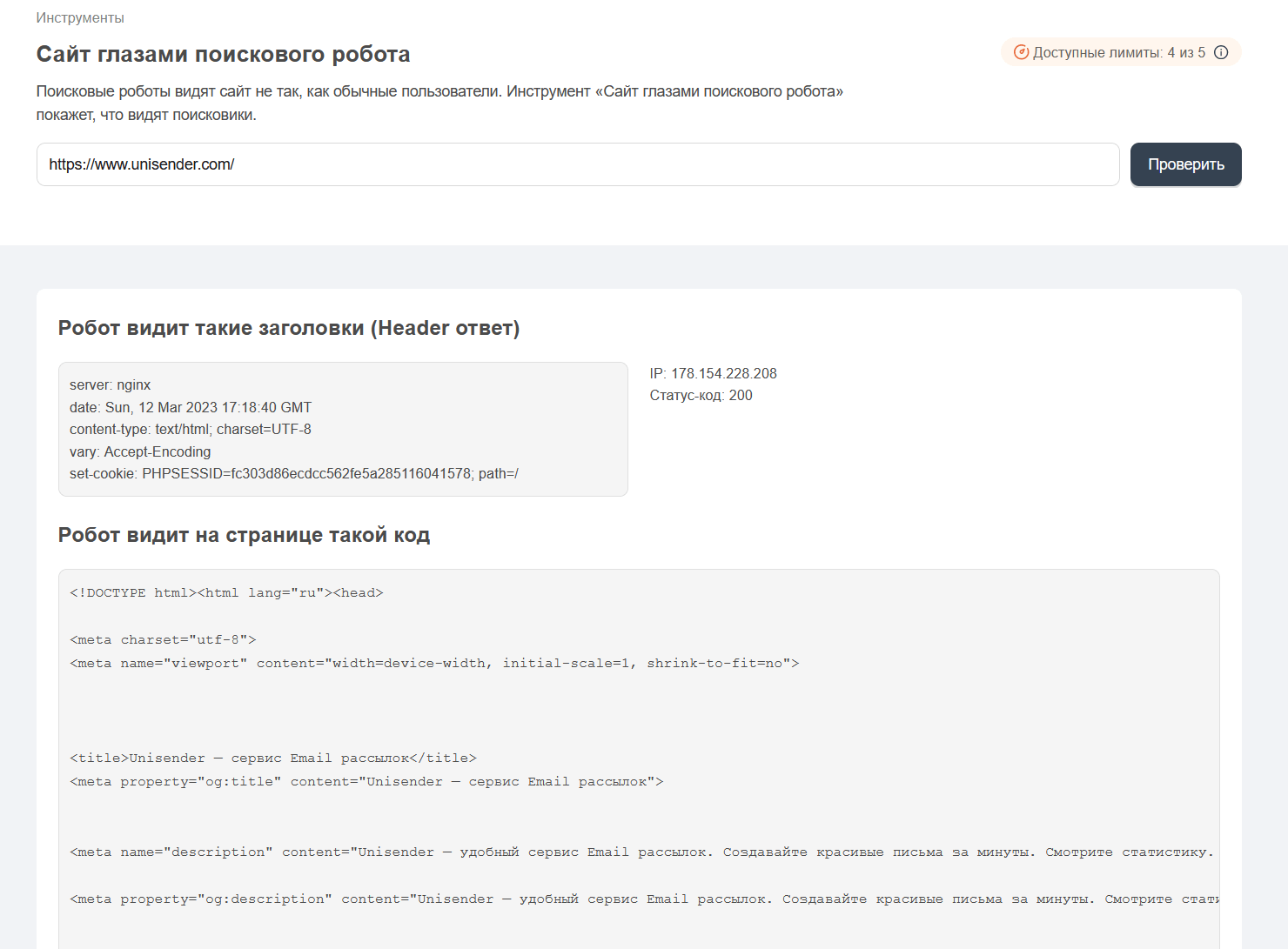
Так робот видит главную страницу сайта Unisender. Источник
Затем веб-паук загружает полученные данные на сервер для дальнейшей их обработки.
Далее содержимое страницы очищается от лишних HTML-тегов, структурируется и помещается в базу поисковой машины (индекс). Фактически индексацией занимается другой робот. Однако зачастую индексного бота считают частью или разновидностью поискового.
Полное руководство по Google Forms — универсальный инструмент для опросов и сбора данных онлайн!
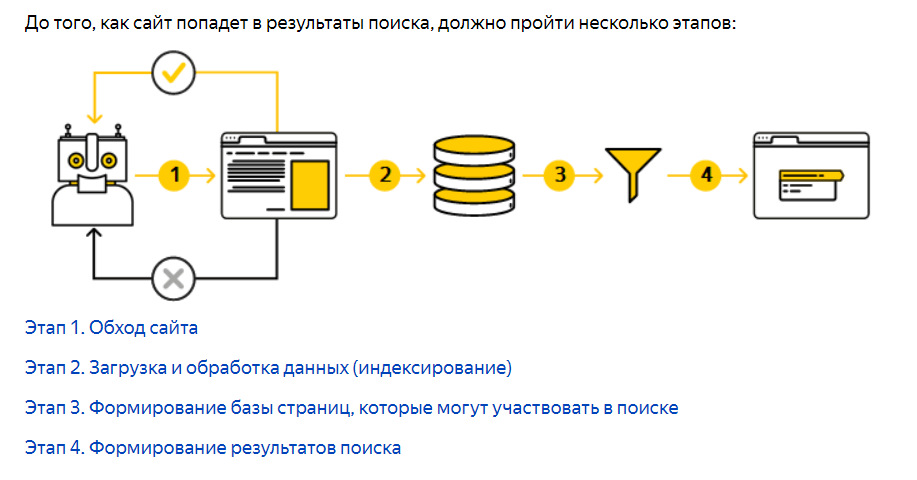
Описание работы поиска «Яндекса». Первые 2 этапа выполняет поисковый робот. Источник
Скорость индексации у разных поисковых систем различается. «Яндекс» добавляет новые страницы в выдачу в течение нескольких дней, в то время как боты Google справляются с задачей за несколько часов.
Если сайт только запускается в работу, и поисковая система еще не знает ни одного его раздела, полное сканирование и индексация может занять несколько месяцев.
Роботы не ограничиваются разовым посещением интернет-ресурса. Они также отслеживают изменения и сообщают поисковой машине об удалении или перемещении уже проиндексированных страниц. Периодичность обхода при этом зависит от объема трафика, размера и глубины сайта, а также частоты обновления контента на нем.
Какие бывают роботы
Самые известные веб-пауки принадлежат поисковым системам. Их функция — добавлять и актуализировать данные в поисковой выдаче. Помимо основных роботов у каждого сервиса есть специализированные, которые скачивают изображения, видео, новости и т.д.
У Googlebot, главного поискового робота Google, есть несколько помощников: Googlebot-Image выполняет поиск изображений, Googlebot-Video отвечает за видео-контент, а Googlebot-News пополняет списки новостного портала.
«Яндекс» также отправляет отдельных пауков сканировать интернет для своих сервисов от «Маркета» до «Аналитики». А над обновлением поиска трудятся два главных робота — основной и быстрый под названием Orange.
Если стандартное индексирование страниц занимает от нескольких дней, то ускоренное позволяет добавить в поиск файлы, созданные минутой назад. В такую быстровыдачу попадают онлайн трансляции, новостные и букмекерские сайты и другие ресурсы, помогающие пользователю получать важную информацию в режиме реального времени.
Отобранные Orange страницы висят в специальной выдаче три дня, после чего заново индексируются основным роботом для размещения в общем каталоге поиска.
Важно понимать, что в ускоренный индекс попадает ограниченное количество ресурсов, отвечающих конкретным требованиям. Простой информационный или продающий ресурс с новостным отделом не попадет в ускоренную новостную индексацию.
Источник: www.unisender.com
Crawler

Crawler (поисковый робот) – это специальная программа, разработанная поисковой системой для индексирования страниц и релевантной выдачи веб-сайтов при запросе пользователя. Поисковый робот оценивает страницы сайтов и заносит данные в специальную базу сайтов поисковой системы.
Иные названия поисковых роботов
- паук;
- краулер;
- бот;
- webscrutter;
- bot;
- webcrawler;
- ant;
- webspider;
- automaticindexer;
- webrobots.
Поисковый робот сканирует глобальную сеть непрерывно. Он посещает уже известные ему сайты, попавшие в список индексированных, и находит ссылки на новые веб-ресурсы. Обнаружив новый сайт, он оценивает по ряду параметров содержимое этого сайта и добавляет его в индекс поисковой системы. Робот обладает «интеллектом» и учитывает регулярность обновления контента. Новостные порталы, информационные агрегаторы он может сканировать ежедневно, а интернет-магазины, сайты компаний – по мере обновления страниц.
Если сайт не оптимизирован, у него нет внешней ссылочной массы, нужно дополнительно привлечь внимание поискового робота. К примеру, Яндекс предлагает заполнить специальную панель вебмастера, а Гугл – данные в Центре вебмастеров.
Боты поисковой системы Яндекс
- Yandex/1.01.001 (compatible, Win16, P), сканирующий и индексирующий картинки и фотоконтент.
- Yandex/1.01.001 (compatible, Win16, I) – основной бот, отвечающий за индексацию сайтов в поисковой системе Яндекс.
- Yandex/1.03.003 (compatible, Win16, D) – бот, проверяющий страницы сайта, добавленные в специальную панель вебмастера (он проверяет соответствие страницы, контент и принимает решение об одобрении или отказе в индексации). В случае положительного решения бот делегирует полномочия по индексации нового сайта основному боту Yandex/1.01.001.
- Yandex/1.01.001 (compatible, Win16, Н) – бот, занимающийся обнаружением зеркал веб-сайтов.
- Yandex/1.02.000 (compatible, Win16, F) – бот, индексирующий фавиконы веб-сайтов.
- Yandex/1.03.000 (compatible, Win16, M) – бот, включающийся в работу после открытия страницы по ссылке «найденные слова».
- YaDirectBot/1.0 (compatible, Win16, I) – бот, сканирующий и индексирующий сайты из рекламной и партнерской сети Яндекса.
Боты поисковой системы Google
- Google Mobile (индексация сайтов, адаптированных под мобильные устройства);
- Googlebot News (индексация новостных сайтов и агрегаторов);
- Googlebot Video (индексация видеоконтента);
- Googlebot Images (индексация картинок и фото);
- Google AdsBot (оценка качества целевой страницы);
- Google AdSense и Mobile AdSense (индексация сайтов, включенных в партнерскую и рекламную сеть);
- Googlebot – основной поисковый робот Google.
Наименования поисковых роботов различных поисковых систем
- Yandex
- Googlebot
- Msnbot
- StackRambler
- Yahoo!Slurp.
Источник: evertop.pro
Как работают поисковые роботы Яндекса и Google
В современном информационном мире, где интернет играет огромную роль, поисковые роботы стали его неотъемлемой частью. Но мало кто задумывается о том, зачем они нужны и как они помогают поисковым системам. Давайте разбираться!
Что такое поисковый робот и зачем он нужен
Поисковый робот (также известный как «паук», «бот» или краулер») представляет собой программу, которая автоматически обходит сайты в интернете, индексирует их содержимое и создает базу данных для использования поисковой системой.
Роботы передают все данные поисковой системе, где они обрабатываются, индексируются и используются для показа в поисковой выдаче по соответствующий запросам.
Если робот не просканировал ваш сайт и не добавил в базу, то он не будет отображаться в поиске. Зайти на ваш сайт можно будет только по прямой ссылке.
Не все поисковые роботы работают одинаково, соответственно и скорость индексации у них будет разная. Например, роботы Google могут просканировать новую страницу за пару часов, а у Яндекс это займет несколько дней. Но об отличиях поисковых систем поговорим позже.
Поисковые роботы не просто заглядывают на веб-сайт однажды и забывают о нем – они являются активными наблюдателями и информируют поисковые системы о любых изменениях, а также об удалении или перемещении уже проиндексированных страниц.
Частота обхода зависит от различных факторов, таких как объем трафика, размер, структура сайта и регулярность обновления контента. Таким образом, роботы постоянно следят за актуальностью информации и стараются поддерживать свежий поисковый индекс.
Как работают поисковые роботы
Поисковый робот базируется на сочетании программного обеспечения и алгоритмов, которые позволяют ему обходить и индексировать веб-сайты.
Вот некоторые основные компоненты, лежащие в основе поискового робота.
- Web-скрейпинг Это процесс автоматического сбора данных с веб-страниц. Роботы используют web-скрейпинг для извлечения текстового содержимого, ссылок, заголовков, метаданных и других элементов со страниц сайта.
- Конвейерная обработка Роботы работают по принципу конвейера, где каждая стадия обработки выполняется последовательно. Например, алгоритм может включать загрузку страницы, извлечение контента, обработку ссылок и индексацию.
- Алгоритмы обхода Роботы используют алгоритмы обхода, чтобы определить, какие страницы посетить и в каком порядке. Также они могут включать следование по ссылкам, проверку sitemap или использование других методов для обнаружения новых страниц.
Работа поискового робота обычно состоит из нескольких этапов – вот основные:
- Планирование. На этом этапе определяется порядок обхода и индексации веб-сайтов. Планировщик устанавливает приоритеты для различных задач робота, определяет периодичность обхода и принимает решения о распределении ресурсов.
- Обход (Crawling). Робот обходит веб-сайты с помощью автоматического процесса, известного как «скрейпинг». Он переходит по ссылкам, начиная с известных точек входа, и собирает информацию с каждой посещенной страницы.
- Обход может осуществляться в ширину (обход всех ссылок на текущей странице перед переходом на следующую) или в глубину (переход на каждую ссылку на странице перед возвратом к исходной странице).
- Индексация. Собранная информация обрабатывается и индексируется. Робот извлекает текстовое содержимое, метаданные, ссылки, изображения и другие данные со страницы. Эта информация сохраняется в поисковой базе данных (индексе), которая позволяет быстро находить страницы в ответ на поисковые запросы.
- Обновление и переиндексация. Роботы периодически повторяют процесс обхода и индексации для обновления информации о веб-сайте.
- Оценка и ранжирование. После индексации роботы могут проводить оценку и ранжирование страниц, используя различные алгоритмы и факторы, такие как релевантность контента, качество ссылок, авторитетность и доверие сайта. Это позволяет поисковой системе отображать наиболее релевантные результаты поиска пользователю.
Каждый из этих этапов важен для эффективной работы поискового робота и обеспечения актуальных результатов поиска.
Больше статей на схожую тематику:
- ПромоСтраницы от Яндекса – что за инструмент и чем он будет полезен бизнесу?
- Как установить удаленные банковские приложения на iPhone: 2 проверенных способа
- SEO-продвижение в 2023 году: 13 трендов, без которых ТОП не светит
Как быстро поисковые роботы индексируют сайты и что на это влияет
Новостные сайты и блоги проверяются роботами поисковиков каждые несколько часов. Но если вы владелец нового сайта, то время значительно увеличивается и придется ждать больше двух недель. К счастью, на скорость индексации сайта можно повлиять.
Для ускорения индексации рекомендуется внедрить системы аналитики, такие как Яндекс Метрика и Google Analytics.
Следующим шагом является подключение сайта к Google Search Console и Яндекс Вебмастеру.
Для повышения эффективности обхода ресурса полезно использование файлов Sitemap и robots.txt.
Файл robots.txt является текстовым файлом на сайте, который указывает инструкции для поисковых роботов относительно того, какие страницы или разделы сайта следует обходить или игнорировать.
Он позволяет вебмастерам контролировать доступ роботов к определенным частям сайта. Sitemap содержит список страниц сайта, которые необходимо проиндексировать.
Метатеги, такие как «noindex» и «nofollow», могут использоваться на страницах сайта для указания роботам об отмене индексации определенных ссылок на странице. Это может быть полезно для скрытия конфиденциальной информации или предотвращения индексации временных или дублирующихся страниц.
На скорость обхода влияет так же техническое состояние сайта. Подробнее о самых распространённых ошибках мы рассказали в статье.
Все эти компоненты позволят ускорить процесс индексации множества веб-страниц и обеспечить актуальность и полноту поисковой базы данных.
Примеры роста кликов, конверсий, заказов и прибыли:
- Рост трафика на 401% у медицинской клиники при регулярном SEO сопровождении
- +8500 посетителей из поисковой выдачи за 4 месяца
- Рост трафика на 310% за 11 месяцев на сайте ионизаторов воды
Сравнение поисковых роботов Google и Яндекс
YandexBot и GoogleBot – самые известные веб-пауки, принадлежащие популярным поисковым системам. Это не единственные роботы, которые существуют, например у Google также есть Googlebot-Image для изображений, Googlebot-News для пополнения списков новостного портала и Googlebot-Video для видеоконтента.
Чтобы разобраться в отличиях роботов Google и Яндекс, рассмотрим таблицу:
Важны больше, ценится количество и качество.
Для Google по-прежнему важно наращивать ссылочный профиль сайта. Это можно наблюдать, проанализировав результаты поисковой выдачи, где часто встречаются ресурсы с большим количеством внешних ссылок.
Важны меньше, ценится качество.
В Яндексе подход к ссылкам имеет свои особенности: большее внимание уделяется их качеству и естественности, когда пользователи сами активно ссылаются на ресурс. Излишняя активность в наращивании ссылочного профиля может привести к санкциям.
Важны для продвижения. Яндекс анализирует поведенческие факторы для определения качества ресурса. Если метрики имеют высокие показатели, это является ясным сигналом того, что сайт полностью отвечает потребностям пользователей, а значит, увеличивает шансы попасть в топ поисковой выдачи. Однако не стоит пытаться искусственно увеличить поведенческие факторы, так как это может привести к санкциям и потере позиций на продолжительный период.
Нет точной информации о том, какие алгоритмы использованы поисковыми системами для ранжирования, но многие эксперты считают, что поведенческие факторы в Яндексе занимают одно из ведущих мест среди самых важных факторов ранжирования.
Ценятся статьи с обширным объемом информации и актуализация контента. Google также обращает внимание на экспертность контента, особенно в тематиках, связанных со здоровьем или благосостоянием пользователей, таких как медицина, финансы и юридические услуги.
Владельцам таких ресурсов крайне важно нанимать профессионалов для написания статей и предоставлять копирайтерам возможность консультироваться с экспертами. Также рекомендуется указывать имя и достижения этих экспертов на странице.
Для достижения успеха в Яндексе требуется создание уникального и незаспамленного контента, свободного от ошибок и опечаток. Объем текста не имеет большого значения для Яндекса: даже страница с тысячей символов может успешно продвигаться в поисковой выдаче.
Это особенно полезно для интернет-магазинов, где товарные карточки не требуют большого количества текста.
То же самое относится и к обновлению контента: если материал является качественным и актуальным, он может оставаться в топе без дополнительных обновлений на протяжении многих лет. Главное, чтобы контент по-прежнему помогал решать проблемы аудитории.
Google предлагает различные фильтры и алгоритмы для обеспечения безопасного и релевантного использования своих продуктов и сервисов.
Фильтр SafeSearch блокирует нежелательный и неуместный контент, включая взрослый контент, насилие и порнографию.
Алгоритм Google Penguin борется с низкокачественными ссылками и спамом, наказывая сайты, использующие нечестные тактики для повышения своего ранжирования.
Алгоритм Google Panda оценивает качество контента на веб-сайтах и придает большую значимость высококачественным и оригинальным материалам, чтобы снизить видимость низкокачественных и дублированных страниц.
Алгоритм Google Hummingbird улучшает понимание запросов пользователей и обеспечивает более точные и релевантные результаты поиска, учитывая контекст запроса и взаимосвязи между словами.
Обновление алгоритма Mobile-Friendly Update оценивает мобильную дружественность веб-сайтов и предпочитает мобильно-оптимизированные сайты в поисковой выдаче на мобильных устройствах.
Алгоритм Google RankBrain использует искусственный интеллект для анализа запросов пользователей и предоставления наиболее релевантных результатов, помогая Google понять семантическую связь и значения слов для более точной интерпретации запросов
У Яндекса так же есть различные фильтры.
Баден-Баден накладывается на большую часть страниц сайта или сразу весь домен. Обычно причиной является избыточное использование ключевых слов на продвигаемых страницах.
С помощью АГС подавляют сайты-сателлиты, которые засоряют выдачу низкокачественным контентом.
Ссылочный взрыв создан для борьбы с новыми сайтами, если для их продвижения приобретают чрезмерное количество внешних ссылок. Очень быстрый рост числа страниц, ссылающихся на такой новый сайт, вызывает подозрения у Яндекса. В результате он сразу обнаруживает такие ресурсы, применяя соответствующие меры.
Минусинск оценивает ссылочный профиль и применяет санкции к сайтам, использующим нечестные методы продвижения.
Переоптимизация применяется, если на странице сайта избыточно используются ключевые слова, и они подобраны неверно. Это может привести к негативным последствиям, таким как снижение позиций в поисковой выдаче на 5-20 пунктов для группы продвигаемых запросов, размещенных на одной странице. Аналитики Яндекса могут вручную ввести эту меру.
Переспам применяется, если используется большое количество повторяющихся ключевых фраз и неестественных речевых оборотов.
«Мобильный» фильтр призван ограничивать сайты, неподходящие для просмотра на мобильных устройствах.
Нравится статья? Тогда смотрите наши курсы!
- Курс «SEO-интенсив»
- Мини-курс «Правильное SEO при алгоритмах Y1 и MUM»
- SEO-марафон «10-часовой интенсив по продвижению сайта»
Заключение
Поисковые роботы играют ключевую роль в организации поисковой выдачи и ранжировании веб-сайтов. Они используют различные фильтры и алгоритмы, чтобы обеспечить безопасность, релевантность и качество результатов поиска. Знание и понимание алгоритмов поисковых роботов поможет оптимизировать веб-сайт и улучшить его видимость в поисковой выдаче.
Современные поисковые роботы уделяют внимание не только ключевым словам, но и другим факторам, таким как поведенческие метрики, экспертность контента, мобильная оптимизация и т.д.
Для веб-мастеров и владельцев сайтов важно следовать рекомендациям поисковых роботов и создавать уникальный, качественный контент. Также стоит учитывать требования к обеспечению безопасности и релевантность информации на сайте.
Если вам нужна помочь в поисковой оптимизации сайта, наши специалисты всегда готовы вам помочь. Сделаем все возможное, чтобы роботы Яндекса и Google правильно проиндексировали ваш сайт и показывали его на высоких позициях поисковой выдачи.

2

1

1


1
Спасибо за реакцию, она бесценна! Обязательно подпишитесь на наш Telegram-канал, публикуем много интересных и актуальных материалов. Не пользуетесь Telegram, тогда познакомьтесь с Катей и подпишитесь на нашу рассылку. ×
Источник: 1ps.ru