
Если интернет – огромная библиотека, в которой собраны книги со всего мира, а пользователь – читатель, который пришел за книгой, то поисковая система – библиотекарь, способный в кратчайшие сроки найти искомую книгу. Как поисковик быстро находит нужный сайт? С помощью индексации, которую совершают поисковые роботы .
Поисковый индекс
Когда пользователь вводит запрос в строке поиска, система формирует выдачу, которую она берет из собственной базы данных. Эта база данных находится на серверах поисковых систем и представляет собой хранилище информации о сайтах – поисковый индекс.
В выдаче мы видим результаты в порядке убывания их значимости. Если сайт отсутствует в индексе поисковика, то он не показывается по поисковым запросам. Пользователи смогут найти страницу только тогда, когда ее проиндексирует робот.
Что такое индексация сайтов
Индексация сайта – это процесс сбора информации о сайте, ее последующей обработки и добавления в базу данных поисковых систем.
75. Поисковый робот. Алгоритм работы поискового робота | Topodin.com
Она может осуществляться двумя способами:
Владелец ресурса добавляет адрес в базу с помощью специальной формы, которая есть в любом поисковике.
2) Автоматический
Робот самостоятельно находит сайт и сканирует его в соответствии со своим алгоритмом работы.
Индексация интернет-ресурсов начала производиться еще в 90-х годах прошлого столетия. Тогда основным признаком было текстовое наполнение – наличие ключевых слов. Сегодня же учитываются сотни характеристик, а сам принцип ранжирования сложен и основан на искусственном интеллекте.
Что такое поисковый робот
Роботы – это специальные программы, предназначенные для получения данных о сайтах в автоматическом режиме. Они обращаются по протоколу HTTP к серверам, на которых расположены страницы сайта, а в ответе получают тело каждой страницы. После многоступенчатой обработки в базу вносятся только те данные, которые необходимы для поиска и ранжирования. Так сайт попадает в индекс поисковиков.
Робот – это важнейший элемент поисковой системы. Под роботом подразумевается не одна конкретная программа для индексации сайта , а комплекс программ. У каждой системы они свои.
Например, роботы Яндекса:
- основой (главный робот);
- индексатор картинок (специализируется на графических файлах);
- робот-зеркальщик (предназначен для работы с зеркалами);
- быстробот (обрабатывает сайты с часто меняющимся контентом).
Роботы создают базу данных, которая используется для формирования релевантной поисковой выдачи.
Как проверить индексацию
1. Поисковый оператор site;
В строке поиска вводим адрес сайта после конструкции «site:». Так мы узнаем приблизительное число проиндексированных страниц в соответствующей системе. Этот способ работает и в Яндексе, и в Google. Если результаты сильно отличаются, то это может говорить о наличии санкций в одном из поисковиков.
2. Панели вебмастера Яндекс и Гугл;
Купил ПРОБИВ ДАННЫХ за 1000 и 10 000 РУБЛЕЙ!
Яндекс.Вебмастер: Индексирование сайта – Страницы в поиске;
Google Search Console: Индекс Google – Статус индексирования.
3. Сервисы для проверки индексации.
Бесплатные сервисы: XSEO.in, SEOGadget.
У сайта RDS целая линейка сервисов, в том числе и плагин для браузера RDS Bar. Он предоставляет комплексную информацию, полезную для СЕО-продвижения сайта .
Как управлять индексацией
Робот воспринимает сайт не в том виде, в котором привык видеть веб-страницы рядовой пользователь. Программа анализирует все страницы ресурса, в том числе и созданные ошибочно или находящиеся в разработке.
Так как робот индексирует за раз ограниченное количество страниц, он может просканировать только «пустые» страницы, а полезные оставить на потом. Так уменьшается скорость индексации, а вместе с ней и позиция ресурса.
Чтобы этого не случилось, необходимо управлять индексацией. Рассмотрим несколько простых и эффективных инструментов:
1. Robots.txt ;
Это текстовый файл, указаниям которого подчиняется робот. Инструкция для робота пишется при помощи директив:
- User-agent – указывает, для какого поисковика написаны правила (User-agent: Yandex). Если правила для всех систем, то используется *;
- Allow – разрешает индексирование отдельных объектов. Например, когда нужно закрыть от робота весь каталог за исключением нескольких файлов;
- Disallow – запрещает сканировать объекты. Это самая распространенная директива в Robots.txt. Она прячет от робота служебные файлы и страницы, дубли и другие объекты, не нуждающиеся в продвижении. О том, как вредит неправильная работа с дублями СЕО-продвижению мы уже рассказывали в нашем блоге;
- Host – указывает главное зеркало. Из страниц с идентичным контентом помечает ту, которую нужно индексировать;
- Sitemap – содержит адрес с картой сайта, если она есть;
- Clean-param – запрещает индексацию страниц с определенными параметрами;
- Crawl-delay – устанавливает временные ограничения на скачивание страниц для поискового робота .
2. Атрибут nofollow;
Закрывает от робота определенные ссылки на странице. Универсален для всех поисковиков.
3. Тег noindex;
Выделяет части текста, которые робот не будет сканировать. Это фирменный тег Яндекса, остальные системы его воспринимают только после небольшой работы с синтаксисом.
4. Атрибут rel=”canonical”;
Выделяет главную страницу, которая будет показываться в выдаче. Нужен для разделения основного зеркала от второстепенного.
Карта сайта содержит перечень страниц и взаимосвязей между ними, а также данные для индексации сайта – приоритет сканирования и частоту обновления. Карту можно создать самостоятельно или с помощью сторонних сервисов, например, gensitemap.
Почему важна скорость индексации сайта
Поисковый робот сканирует сайты не регулярно, а через определенные промежутки времени. Их длительность напрямую зависит от частоты обновления контента. При этом он обрабатывает данные порционно, а не все сразу, чтобы не нагружать сервер. В среднем индексация в Яндексе занимает несколько недель, в Google – несколько дней.
Новостные ресурсы, где часто происходит добавление материала, посещаются роботом практически непрерывно. Поэтому свежие новости почти сразу появляются в поисковой выдаче.
Веб-страницы, которые обновляются редко, проверяются роботом один-два раза в неделю. Сайты, на которых новый контент не появляется, тоже посещаются роботом, но редко – пару раз в месяц.
Так как результаты поиска формируются из индекса поисковой системы, то чем раньше ресурс попадет в него – тем лучше. Чем больше скорость индексации сайта – тем выше его позиция в поисковой выдаче. Это один из подтвержденных факторов ранжирования.
Есть еще несколько причин для повышения скорости индексации:
- Содержимое сайта потеряет актуальность еще до того, как его увидят пользователи. Например, если опубликована срочная новость или условия акции, которая скоро закончится;
- Конкуренты скопируют и опубликуют контент раньше, если их сайт сканируется быстрее. Так они займут более высокие позиции;
- Пользователи не успеют увидеть важные изменения и уйдут к конкурентам. Например, расширился ассортимент, появились скидки, но посетитель не дождался, пока они окажутся в выдаче.
Как ускорить индексацию сайта
- Настроить файл robots.txt;
- Создать карту сайта;
- Использовать Яндекс.Вебмастер и Google Search Console;
- Сделать простую и удобную навигацию для посетителей;
- Публиковаться на более крупных ресурсах;
- Добавлять контент, если не регулярно, то хотя бы часто;
- Убрать из индексации дубли и ненужные страницы;
- Исправить технические ошибки;
- Использовать быстрый и надежный хостинг.
Индексация сайта – сложный процесс, непосредственно влияющий на позицию ресурса в выдаче. Управление индексаций является неотъемлемым элементом СЕО-продвижения.
Если Вам понравилась статья — ставим лайк и делимся ей в социальных сетях. Хотите получать больше полезных статей? Подпишитесь на рассылку. Раз в неделю пишем коротко про интернет-маркетинг.
Источник: dzen.ru
Какую работу выполняют роботы-пауки поисковиков
Краулер (поисковый робот, бот, паук) — это программные модули поисковых систем, которые отвечают за поиск веб-сайтов их сканирование и добавление материалов в базу данных. Поисковый паук без участия оператора посещает миллионы сайтов с гигабайтами текстов. Их принцип действия напоминает работу браузеров: на первом этапе оценивается содержимое документа, затем материал сохраняется в базе поисковика, после чего он переходит по линкам в другие разделы.
Какую работу выполняют роботы пауки поисковых машин
Малознакомые с принципом работы поисковых ботов вебмастера представляют их какими-то могущественными существами. Но, все гораздо проще. Каждый робот отвечает за выполнение своих функций. Они не могут проникать как «шпионы» в запароленные разделы сайта, понимать работу фреймов, JavaScript или флеш-анимаций. Все зависит от того, какие функции в них были заложены разработчиками.
Скорость индексации и частота обходов сайта роботами во многом зависит от регулярности обновления контента и внешней ссылочной массы. Чтобы помочь боту проиндексировать все страницы, позаботьтесь о создании карт сайта в двух форматах .html и .xml.
Поисковая выдача формируется в 3 этапа:
- Сканирование — поисковые боты собирают содержимое сайтов (тексты, фото и видео).
- Индексация — робот вносит в базу данных собранную информацию и присваивает каждому документу определенный индекс. Материалы могут несколько дней находиться в быстровыдаче и получать трафик.
- Выдача результатов — каждая страница занимает определенную позицию по результатам ранжирования, заложенным в алгоритмах поисковых систем.
Специалисты Google и «Яндекс» часто вносят коррективы в работу поисковых роботов, например, ограничивают объем сканируемого текста или глубину проникновение паука внутрь сайта. Вебмастерам приходится адаптироваться под изменения при SEO-продвижении: выбирать оптимальные размеры текстов, ориентируясь на конкурентов в ТОП-10 выдаче, учитывать вложенность материалов, производить перелинковку материалов и так далее.
У каждой поисковой системы, будь то Google или «Яндекс», есть свои «пауки», отвечающие за разные функции. Их количество отличается, но задачи практически идентичные.
Как управлять поисковыми ботами?
Часто владельцы сайтов закрывают доступ некоторым поисковым роботам к определенному содержимому сайта, которое не должно принимать участие в поиске. Все команды паукам прописываются в специальном файле robots.txt.
Документ предоставляет краулерам список документов, которые нельзя индексировать (это может быть технические разделы сайта или личные данные пользователей). Ознакомившись с правилами, робот уходит с сайта или переходит на разрешенные для сканирования страницы.
Что указывать в robots.txt:
- Закрывать/открывать для индексации фрагменты контента или разделы сайта.
- Интервалы между запросами поисковых ботов.
Команды могут быть общими для всех роботов или отдельные для Yandex, Googlebot, Mail.Ru. Подробнее о работе с robots.txt читайте здесь.
Как узнать, что поисковый робот посещает сайт?
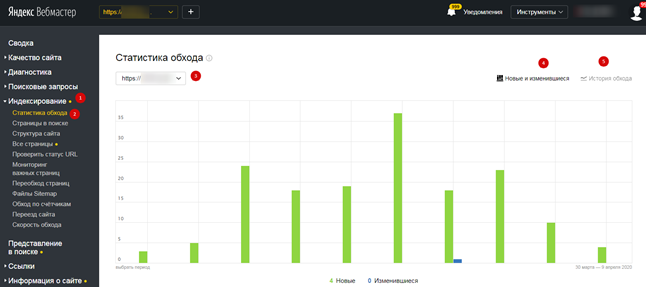
Существует несколько способов, позволяющих определить, как часто на ваш сайт заходят краулеры. Проще всего это отследить робота от «Яндекса». Для этого авторизуйтесь в сервисе «Яндекс.Вебмастер», откройте страницу «Индексирование» и «Статистика обхода»:
В этом разделе вы узнаете, какие страницы обошел робот, как часто обращался к вашему сайту («История обхода») и ошибки, случившиеся по причине перебоев со стороны сервера или неправильного содержимого документов.
Чтобы получить подробную информацию по конкретному разделу, найдите его в списке, где указан URL-сайта.
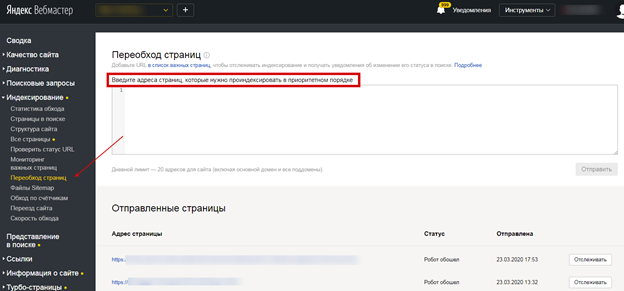
Рассказать поисковому роботу и направить на конкретную страницу можно с помощью инструмента «Переобход страниц». Добавьте урл-адреса в соответствующее поле:
Точно также успешно можно отследить и посещение поискового робота Google. Для этого авторизуйтесь в Google Analytics.
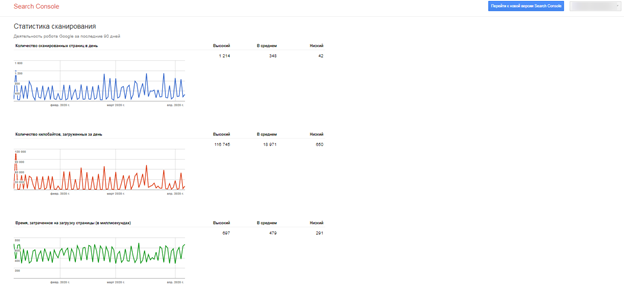
Появятся данные про обход страниц роботом:
Выводы
Краулеры нужны не только поисковым системам для индексирования сайтов и добавления документов в базу данных, но и для SEO-специалистов, чтобы анализировать ресурсы, исправлять недочеты и успешно продвигать их в поиске.
Вебмастера будут всегда пытаться разгадать алгоритмы работы поисковых роботов, которые постоянно совершенствуются. Работа над качеством сайта — долгий и тернистый путь, направленный на долгосрочный результат.
А у вас не было проблем с индексацией сайта? Отслеживаете ли вы посещение сайта поисковыми роботами? Поделитесь свои опытом в комментариях.
Источник: puzat.ru
как называется поисковая система в которой программа робот автоматически вносит информацию в базу данных
Запомните, главное правило – чтобы ваш сайт получал дополнительный качественный трафик, необходимо чтобы о вашем проекте узнали мировые поисковые системы. Мало кто знает про эту “фишку” – но она работает и является бесплатно для любого пользователя. Прочтите, что пишут ниже про данную систему.
После добавления сайта в открытую базу, советуем воспользоваться другими сервисами проекта:
Статистика сервиса
