
Он сразу выкатил код и оказалось вполне неплохо. Так как бот работает с данными до 21 года картинку пришлось поискать свежую, ибо то что он выставил не работало.
Выглядит достаточно кликабельно. Пару кило бы купил.
Конечно надо поиграться с текстом и позиционированием, но за 5 минут достаточно хороший результат.
После нажатия на кнопку нас перебрасывает по выданной ссылке.
Итог. Бот отличный но до замены программиста очень далеко, он замечателен в плане сделать грязную работу, написать шапку и подключить библиотеки. Да и собеседник интересный так что юзайте!
Ээээх куда катится мир таким темпом.
Показать ещё
53 комментария
Написать комментарий.
«Бот отличный но до замены программиста очень далеко»
Идёт прохожий по улице, видит — мужик с собакой в шахматы играет. Прохожий подходит и говорит:
— Ого, какая у вас собака умная!
— Да какая она умная, — отвечает мужик — счёт 4-2, я веду.
Вы только что прочитали анекдот про программистов и ChatGPT.
Развернуть ветку
Аккаунт удален
Развернуть ветку
Развернуть ветку
Вообще у людей которые просят ChatGPT написать сайт или программу и потом это как-то интерпретируют совершенно фантастические представления о том как вообще ведется разработка.
ChatGPT не делает и не умеет делать «черновую работу», написать что-то с нуля — это самое простое что можно сделать. Поищите на ютубе туториалы про то как создать свой инстаграмм или твиттер с нуля — три часа и у тебя твой собственный инстаграмм. На хакатонах люди создают новые приложения за два дня.
Сделать с нуля что либо — не сложно, сложно поддерживать это, сложно добавлять новые фичи, сложно создать архитектуру которая предусмотрит меняющиеся требования со стороны бизнеса.
А «черновая работа» это не с нуля сайты делать, черновая работа это без документации разбираться в чужом легаси восьмилетней давности.
Развернуть ветку
Меня больше забавляет истерия вокруг нейросетей, каждый день пост про то, как кто-то уволил айтишника и что всё) А после пример ужасного сайта, продукта, сео текста и др. У людей, в основном, отсутствует понимание, что это инструмент. И как любой инструмент требует навыка работы с ним, доработок и сопровождения. На выходе результат x2, а должен быть x10. Даже тупо ввести правильный запрос и отсеить результаты нужны навыки в соответствующей сфере. А после вот такие «предприниматели» будут искать за 5 рублей специалистов с просьбой доработать этот кусок (кода, дизайна или текста)…
Развернуть ветку
5 комментариев
Тут то я и думаю что он справится, когда ты попал на код который надо разбирать и понимать какую же логику заложил автор, то машина быстрее считает его реверс инжинирингом, я грузил в него код управления шаговым двигателем заранее выставив параметр enable в 0 (на С++) и спросил почему не крутится так он выдал код с исправлениями
Развернуть ветку
2 комментария
Оранжевая кнопка на оранжевом фоне. Сразу видно где человек приложил работу, подбирая картинку.
Развернуть ветку
Можно скинуть ссылку на портфолио работ и попросить чтобы он сварил уху из всего этого, но задача была быстро с минимальными вводными попробовать получить результат и он справился
Развернуть ветку
Картинка бота не грузилась, а там в ТЗ на фоне апельсины, цвет кнопки выбрал бот
Развернуть ветку
Объясните, в чем феномен ChatGPT? Ведь и до него были нейронки. В него влили больше дата сетов? А вообще, видно, как нейронка может ПОМОГАТЬ, а не заменять программиста.
Развернуть ветку
1) Закон шиншилл. Раньше считалось, что есть лимит итераций, после которого обучать нейронку не эффективно. Оказалось, что после плато, эффективность продолжает возрастать — сети можно доучивать практически без ограничений. Название от сети, на которой сделано открытие.
2) Регрессивное предсказание. Чем больше слов ChatGPT уже написал в ответе — тем точнее подбирает следующее. Поэтому работает трюк — если попросить разбить ответ на шаги — точность возрастает. Потому что ответ включает больше контекста на каждой итерации.
3) Большой входной датасет.
ChatGPT предсказывает слова в тексте. Это неплохо работает для кода, потому что код — структурированный текст и множество кейсов уже было написано хотя бы один раз.
Хорошие новости для разработчиков в том, что вариантов рекомбинации бесконечно много и иллюзия разваливается при первой попытке сделать что-то нестандартное, а это примерно сразу.
Раньше была абстракция визуального программирования (конструкторы алгоритмов). Теперь еще есть натурально-языковое — точнее и удобнее, но примерно с теми же ограничениями.
Источник: vc.ru
Python с нуля. Игра «Виселица» за 5 минут.
Наступил очередной день изучения азов языка Python и сегодня напишем классическую игру «Виселица». По правилам, компьютер случайным образом выберет слово, а игрок буква за буквой должен будет его отгадать. В случае неудачи на экране игрока появится псевдографика с повешенным персонажем.
Начинаем программу, как и всегда, с комментариев, а так же импортируем модуль random, который будет отвечать за случайный выбор слова.
# Виселица
# Компьютер случайным образом выбирает слово,
# которое игрок должен отгадать буква за буквой.
# В случае неудачи на экране появится фигурка повешенного.
# Импорт модуля
import random
Начало программы
Далее объявим неизменяемую переменную, так называемую константу, которая будет содержать в себе псевдографику с раскадровкой процесса повешения персонажа. Константу назовем HANGMAN и напишем её заглавными буквами, как принято у питонистов. После неё пишем оператор присваивания, открываем скобку и начинаем процесс рисования восьми стадий гибели человечка. Кортеж «изображений» рисуем в тройных кавычках каждое, чтобы Python понимал, что это нечто многострочное, а так же разделяем запятыми.
Кортеж из 8 псевдографических изображений повешенного
Можете повторить чудовищную красоту как у меня, а можете нарисовать что-то своё. Решать вам. После чего объявляем следующую константу.
Константа с максимально допустимым числом ошибок
Константа MAX_WRONG будет содержать в себе максимальное количество ошибок для игрока, равное числу элементов, содержащихся в кортеже HANGMAN за вычетом единицы. То есть семь.
И последняя константа будет содержать кортеж из слов, которые игроку необходимо будет угадывать. Назовем её WORDS .
Кортеж с загаданными словами
Следующая строка будет отвечать за выбор случайного слова из кортежа WORDS.
word = random.choice(WORDS)
Функция choice модуля random вернет случайный элемент из WORDS, и он будет присвоен переменной word.
Переменная so_far изначально поможет игроку понять, сколько букв содержит искомое слово. С её помощью на экран будет выведено то же количество дефисов, что и длина слова. Но в последующем она будет содержать и отгаданные знаки.
so_far = «-» * len(word)
Переменная wrong, по умолчанию содержащая ноль, будет являться счетчиком ошибок. А переменная used будет являться списком букв, которые введет игрок в процессе игры.
wrong = 0
used = []
Переменные
Основной цикл.
У нас многое готово, но не хватает условий, по которым будет протекать игровой процесс. И в этом нам поможет цикл while, повторяющий блок кода до момента выполнения заданных условий.
Первой строкой выведем приветственную надпись, а следующей определим, что пока количество ошибок (wrong) меньше максимального числа ошибок (MAX_WRONG) и строка so_far неравна выбранному слову word, на экран будет выводиться текущее изображение виселицы, ранее предложенные буквы, и строка so_far.
При этом у игрока будет запрашиваться ввод буквы. Вводимое значение будет присваиваться переменной guess, после чего с помощью метода upper конвертироваться в верхний регистр, а с помощью метода append вноситься в список названых букв used. Если вводимая буква уже содержится в списке (while guess in used) будет запрошен повторный ввод.
Основной цикл
Следующий блок кода в этом же цикле будет проверять наличие вводимой игроком буквы в слове. Если guess содержится в word, на экран будет выводиться соответствующая надпись, а строка so_far изменится на версию с отгаданной буквой.
Проверка наличия буквы в слове
Новая версия строки so_far будет создана с помощью цикла for, и отгаданная буква появится во всех позициях, где она присутствует в слове.
Если же игрок промахнулся с буквой, ему будет выведена соответствующая надпись, а счетчик ошибок добавит к себе единичку.
Завершение игры произойдет при двух условиях:
1. Число совершенных ошибок станет равным максимально допустимому числу ошибок (wrong == MAX_WRONG).
2. Иной вариант, т.е. если игрок угадает слово.
Источник: dzen.ru
Как я написал приложение, которое за 15 минут делало то же самое, что и регулярное выражение за 5 дней

2017-12-04 в 20:42, admin , рубрики: data science, python, Алгоритмы, анализ текста, высокая производительность, Регулярные выражения
От переводчика
Не так давно столкнулся с проблемой поиска набора слов в большом тексте. Разумеется главной проблемой стала производительность. Поиск готовых решений порождал больше вопросов, чем давал ответов. Часто я натыкался на примеры использования каких-то сторонних коробок или онлайн-сервисов. А мне в первую очередь нужно было простое и легкое решение, которое в дальнейшем дало бы мысли для реализации собственной утилиты.
Несколько недель назад вышла замечательная англоязычная статься об open-source python-библиотеки FlashText. Эта библиотека предоставляла быстрое работающее решение задачи поиска и замены ключевых слов в тексте.
Т.к. на русском материалов подобной тематики не так много, то я решил перевести эту статью на русский. Под катом вас ждет описание проблемы, разбор принципа работы библиотеки а так же примеры тестов производительности.
Начало
Основной задачей при работе с текстом является его очистка. Обычно этот процесс очень прост. К примеру нам нужно заменить словосочетание «Javascript» на «JavaScript». Но чаще нам нужно просто найти все упоминания словосочетания «Javascript» в тексте.
Задача очистки данных — это типичная задача для большинства проектов, работающих в области даталогии (науки о данных).
Даталогия начинается с очистки данных
Недавно я решал именно такую задачу. Я работаю исследователем в Belong.co и обработка естественного языка занимает половину моего времени.
Когда я начал использовать Word2Vec для анализа нашего текстового корпуса, то понял, что синонимы анализировались, как одно значение. К примеру термин «Javascripting» использовался вместо «Jacascript» и.т.д.
Чтобы решить эту проблему мне понадобилось очистить текст. Для этого я написал приложение, использующее регулярное выражение, которое заменяло все возможные синонимы словосочетания «Javascript» на его исходную форму. Однако это породило лишь новые проблемы.
Some people, when confronted with a problem, think
“I know, I’ll use regular expressions.” Now they have two problems.
Данную цитату первый раз я встретил тут и именно она характеризовала мой случай. Оказывается регулярное выражение выполняется относительно быстро, только в том случае, если число ключевых слов, которые необходимо найти и заменить в исходном тексте, не превышает лишь нескольких сотен. Но наш текстовый корпус состоял из более чем 3 миллионов документов и 20 тысяч ключевых слов.
Когда я оценил время, которое потребуется на замену всех ключевых слов, при помощи регулярных выражений, то оказалось что нам потребуется 5 дней для одного прогона нашего текстового корпуса.

Первое решение подобной проблему напрашивалось само собой: параллельный запуск нескольких процессов поиска и замены. Однако этот подход перестал быть эффективным, после того как увеличился объем данных. Теперь текстовый корпус состоял из десятков миллионов документов и сотен тысяч ключевых слов. Но я был уверен, что должно быть лучшее решение этой проблемы! И я начал искать его…
Я поспрашивал коллег в моем офисе, задал несколько вопросов на Stack Overflow. В результате у меня была пара неплохих предложений. Vinay Pandey, Suresh Lakshmanan
в обсуждение посоветовали попробовать алгоритм Ахо-Корасик и префиксное дерево.
Мои попытки найти готовое решение не увенчались успехом. Я не нашёл ни одной стоящей библиотеки. В результате я решил реализовать предложенные алгоритмы в контексте моей задачи. Таким образом и появился на свет FlashText.
Прежде чем мы окунемся в детали реализации FlashText, давайте посмотрим как возросла скорость поиска.
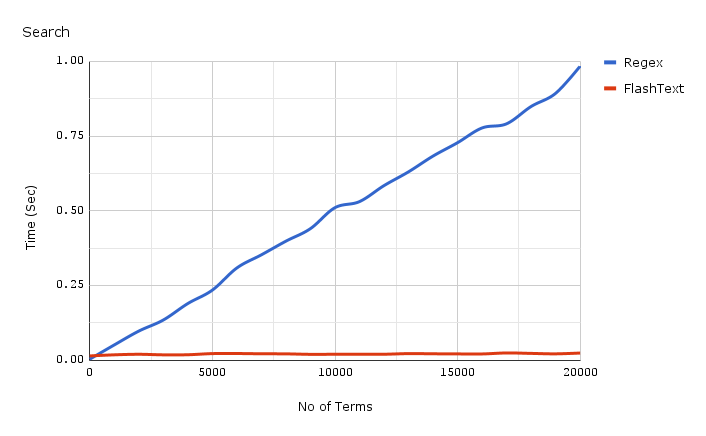
График показывает зависимость времени работы от числа ключевых слов, при выполнение операции поиска ключевых слов в одном документе. Как мы видим, время затраченное приложением использующим регулярное выражение линейно зависит от числа ключевых слов. Для FlashText такой зависимости не наблюдается.
FlashText уменьшил время одного прогона нашего текстового корпуса с 5 дней до 15 минут.

Ниже приведен график зависимости затраченного времени от числа ключевых слов при выполнении операции замены в одном документе.
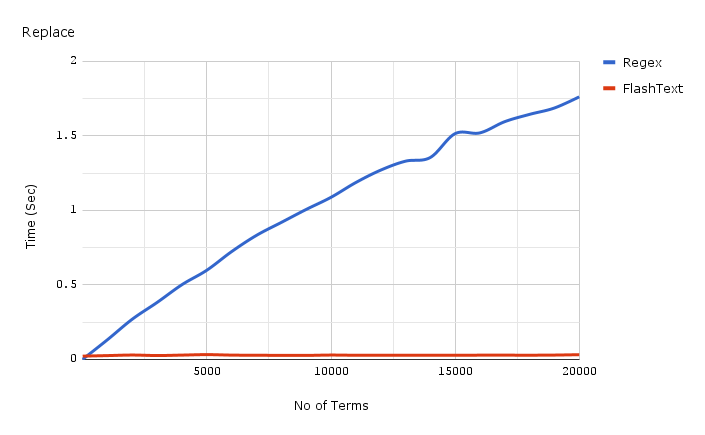
Код для получения бенчмарков, используемых для графиков, представленных выше можно найти здесь, а сами бенчмарки здесь.
Так что же такое FlashText ?
FlashText это небольшая open-source Python-библиотека, которая выложена на GitHub. Она одинаково успешно справляется как с задачей поиска, так и задачей замены ключевых слов в текстовом документе.
Первым шагом при использовании FlashText является составление корпуса ключевых слов, который будет использоваться библиотекой для построения префиксного дерева. После чего на вход библиотеки подается текст для которого будет выполнятся процедура поиска или замены.
При замене FlashText создаст новую строку с замененными ключевыми словами. При поиске библиотека вернёт список ключевых слов, найденных во входной строке. В обоих случаях результат будет получен за один проход входной строки.
В twitter уже появились первые положительные отзывы от счастливых пользователей:
Почему FlashText настолько быстрее ?
Давайте рассмотрим пример работы. Пусть у нас есть текст состоящий из трех слов: I like Python и корпус ключевых слов, состоящий из 4 слов: < Python, Java, J2ee, Ruby >.
Если мы будем проверять наличие каждого ключевого слова из корпуса в исходном тексте, то у нас будет 4 итерации поиска:
is ‘Python’ in sentence? is ‘Java’ in sentence? .
Из псевдокода мы видим, что если список ключевых слов будет состоять из n элементов, то нам понадобиться n итераций.
Но мы можем поступить наоборот: проверять существование каждого слова из исходного текста в корпусе ключевых слов.
is ‘I’ in corpus? is ‘like’ in corpus? is ‘python’ in corpus?
Если предложение состоит из m слов, то у нас будет m итераций. Общее время выполнения операций будет прямо пропорционально зависеть от числа слов в тексте. Стоит отметить, что поиск слова в корпусе ключевых слов будет выполняться быстрее, чем поиск ключевого слова в тексте, т.к. корпус ключевых слов представляет из себя словарь.
В основе FlashText лежит второй подход. В его реализации так же использованы алгоритм Ахо-Корасик и префиксное дерево.
Алгоритм работы следующий:
Вначале создается префиксное дерево для корпуса ключевых слов. Оно будет выглядеть так:
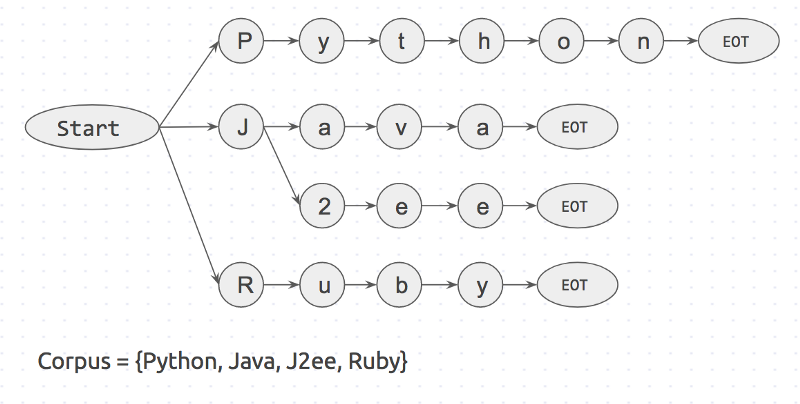
«Start» и «EOT» представляют из себя границы слов: пробел, новая строка и т.д. Ключевое слово будет совпадать с входным значением, только в том случае если слово имеет пограничные символы с обоих сторон. Такой подход исключит ошибочные совпадения, такие как «apple» и «pineapple».
Далее рассмотрим пример. Возьмем строку I like Python и начнем поэлементный поиск в ней ключевых слов.
Step 1: is I in dictionary? No Step 2: is like in dictionary? No Step 3: is Python in dictionary? Yes
Ниже представлено префиксное дерево для шага 3.
is Python in dictionary? Yes
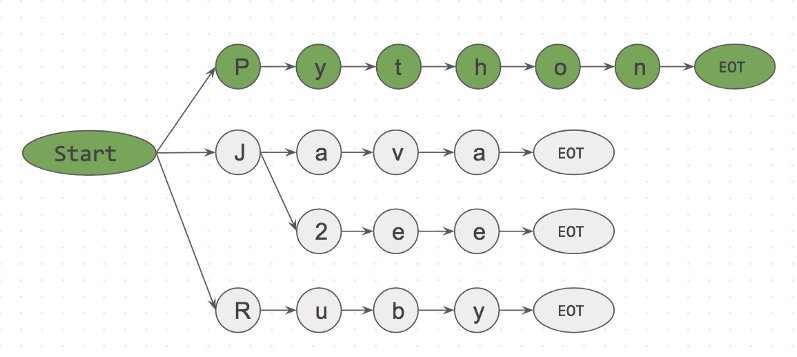
Благодаря такому подходу мы можем уже на первом символе отбросить like, потому что символ i не расположен рядом с start . Таким образом мы практически мгновенно можем откинуть слова, которые не входят в корпус и не тратить на них время.
Алгоритм FlashText будет анализировать символы входной строки I like Python , в то время как корпус ключевых слов может иметь любые размеры. Размер корпуса корпус ключевых слов никак не скажется на быстродействие алгоритма. Это и есть основной секрет алгоритма FlashText.
Когда вам нужно использовать FlashText ?
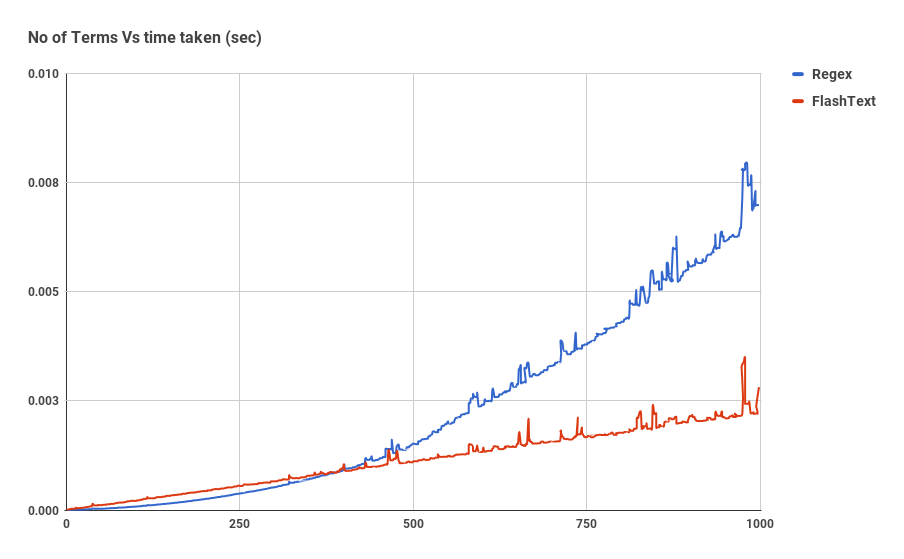
Всё очень просто: как только размер корпуса ключевых слов становится больше 500, то появляется этот график.
Однако стоит отметить, что Regex, в отличие от FlashText, может искать в исходной строке специальные символы такие как ^,$,*,d,, которые не поддерживаются алгоритмом FlashText. То есть включать в корпус ключевых слов элемент worddvec не стоит, а вот с элементом word2vec всё отработает отлично.
Как запустить FlashText для поиска ключевых слов
# pip install flashtext from flashtext.keyword import KeywordProcessor keyword_processor = KeywordProcessor() keyword_processor.add_keyword(‘Big Apple’, ‘New York’) keyword_processor.add_keyword(‘Bay Area’) keywords_found = keyword_processor.extract_keywords(‘I love Big Apple and Bay Area.’) keywords_found # [‘New York’, ‘Bay Area’]
Как запустить FlashText для замены ключевых слов
В общем то это была основная задача ради которой разрабатывался FlashText. У нас это используется для очистки данных перед обработкой.
from flashtext.keyword import KeywordProcessor keyword_processor = KeywordProcessor() keyword_processor.add_keyword(‘Big Apple’, ‘New York’) keyword_processor.add_keyword(‘New Delhi’, ‘NCR region’) new_sentence = keyword_processor.replace_keywords(‘I love Big Apple and new delhi.’) new_sentence # ‘I love New York and NCR region.’
Если у вас есть коллеги которые работают с анализом тестовых данных, распознаванием упоминаний сущностей, обработкой естественного языка или Word2vec, то прошу поделиться этой статьей с ними.
Эта библиотека оказалась очень полезной для нас и я уверен, что она сможет пригодиться кому-нибудь ещё.
Получилось длинно. Спасибо, что дочитали.
Источник: www.pvsm.ru