


ЭМУЛЯЦИЯ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА НА ПРИМЕРЕ СОЗДАНИЯ ПРОГРАММЫ ВИРТУАЛЬНОГО СОБЕСЕДНИКА
Фарафонова О.А. 1 , Фарафонова О.А. 1 , Оленькова М.Н. 1
1 Тобольская государственная социально-педагогическая академия им. Д.И.
Менделеева
Работа в формате PDF
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
Виртуальный собеседник (англ. chatterbot) – это компьютерная программа, которая создана для имитации речевого поведения человека при общении с одним или несколькими пользователями. По отношению к виртуальным собеседникам употребляется также название программа-собеседник.
Одним из первых виртуальных собеседников была программа Элиза, созданная в 1966 году Джозефом Вейзенбаумом. Элиза пародировала речевое поведение психотерапевта, реализуя технику активного слушания, переспрашивая пользователя и используя фразы типа «Пожалуйста, продолжайте». Позднее были созданы более совершенные программы-собеседники PARRY, A.L.I.C.E. и др.
ChatGPT создаст любое приложение за считанные секунды
Создание виртуальных собеседников граничит с проблемой общего искусственного интеллекта, то есть единой системы (программы, машины), моделирующей интеллектуальную деятельность человека. Проблемой искусственного интеллекта является познание процессов функционирования человеческого разума, а не просто имитация его работы.
Предполагается, что идеальная программа-собеседник должна пройти тест Тьюринга. Суть теста Тьюринга в следующем: «человек взаимодействует с одним компьютером и одним человеком. На основании ответов на вопросы он должен определить, с кем он разговаривает: с человеком или компьютерной программой. Задача компьютерной программы – ввести человека в заблуждение, заставив сделать неверный выбор». Однако, несмотря на успехи данных программ-собеседников, ни одна из существующих не смогла пройти полный вариант теста Тьюринга.
Современные программы-собеседники – лишь попытки имитировать разумный диалог с машиной. Даже наиболее успешные программы этого класса не могут логически мыслить подобно человеку, осуществлять операции мышления: анализа, синтеза, сравнения, классификации, абстракции, обобщения, конкретизации информации, которая заложена в ее базе знаний.
Как любая интеллектуальная система, виртуальный собеседник имеет базу знаний. В простейшем случае она представляет собой наборы возможных вопросов пользователя и соответствующих им ответов. Наиболее распространённые методы выбора ответа в этом случае следующие:
- Реакция на ключевые слова.
- Совпадение фразы. Имеется в виду похожесть фразы пользователя с теми, что содержатся в базе знаний.
- Совпадение контекста. Для корректного ответа некоторые программы могут проанализировать предыдущие фразы пользователя и выбрать подходящий ответ.
Возникает вопрос, зачем нужны программы-собеседники. В первую очередь, для общения. Каждому человеку не лишним является умение общаться. Ведь немногие могут похвастаться навыками ораторского искусства. Кроме того, такие программы могут исполнить функции психолога, то есть терпеливо выслушать пациента, невзирая на нестабильное душевное состояние и отрицательные эмоции.
Как написать свою программу на python? #python #программирование
Программы-собеседники также могут выполнять обучающую функцию, то есть дополнять учителя предметника или частично заменять его.
Понятно, что нереально создать совершенную программу-собеседник, реализующую элементы искусственного интеллекта, с помощью возможностей языка программирования Pascal, но вполне возможно создать ее эмуляцию. Эмуляция (англ. emulation) – воспроизведение программными или аппаратными средствами либо их комбинацией работы других программ или устройств.
В отличие от программы, реализующей искусственный интеллект, написание программы эмулятора искусственного интеллекта проще. Чем же эмулятор отличается от искусственного интеллекта? В первую очередь тем, что программа на основе искусственного интеллекта обучаема, а эмулятор не возможно обучить. Эмулятор можно усовершенствовать путем расширения и усовершенствования базы знаний.
Какой вклад можно внести, в данном случае, при создании программ-собеседников? В первую очередь, это тщательное продумывание вопросов и ответов для базы знаний. Причем подход должен быть двусторонний (со стороны пользователя и со стороны программы), с различными вариантами исхода ответа на тот или иной вопрос.
Кроме того, в программе можно реализовать эмоциональное состояние, то есть хорошее или плохое настроение. Если в базе знаний не найден ответ на вопрос пользователя, то необходимо запастись различными нейтральными ответами типа «у меня нет определенного мнения на этот счет», «это хороший вопрос». Во-вторых, среди имеющихся программ-собеседников много программ на английском языке, которые требуют перевода и адаптации на русский диалог, соблюдая синтаксис, пунктуацию и стилистику текста.
Литература
- Программы-собеседники [Электронный ресурс]: сайт – URL: http://netnotes.narod.ru/talkerus/index.html
- Универсальная энциклопедия. Виртуальный собеседник [Электронный ресурс]: сайт – URL: http://omop.su/107552.html
Источник: scienceforum.ru
Как создать собственного чат-бота с искусственным интеллектом с помощью ChatGPT API: пошаговое руководство


В прорывном объявлении OpenAI недавно представил API ChatGPT для разработчиков и общественности. В частности, новая модель «gpt-3.5-turbo», на которой работает ChatGPT Plus, была выпущена по более низкой цене в 10 раз, и она также чрезвычайно отзывчива. По сути, OpenAI открыл двери для бесконечных возможностей, и даже не кодер может внедрить новый API ChatGPT и создать своего собственного чат-бота AI.
Итак, в этой статье мы представляем вам руководство о том, как создать собственного чат-бота с искусственным интеллектом с помощью API ChatGPT. Мы также внедрили интерфейс Gradio, чтобы вы могли легко продемонстрировать модель ИИ и поделиться ею со своими друзьями и семьей. На этой ноте давайте продолжим и узнаем, как создать персонализированный ИИ с помощью ChatGPT API.
Создайте свой собственный чат-бот с помощью API ChatGPT (2023 г.)
В этом руководстве мы добавили пошаговые инструкции по созданию собственного чат-бота с искусственным интеллектом с помощью ChatGPT API. От настройки инструментов до установки библиотек и, наконец, создания чат-бота AI с нуля, мы включили здесь все мелкие детали для обычных пользователей. Мы рекомендуем вам следовать инструкциям сверху вниз, не пропуская ни одной части.
Что нужно помнить перед созданием чат-бота с искусственным интеллектом
1. Вы можете создать чат-бота ChatGPT на любой платформе, будь то Windows, macOS, Linux или ChromeOS. В этой статье я использую Windows 11, но шаги для других платформ практически идентичны.
2. Руководство предназначено для обычных пользователей, инструкции четко объясняются примерами. Таким образом, даже если у вас есть поверхностные знания о компьютерах, вы можете легко создать своего собственного чат-бота с искусственным интеллектом.
3. Чтобы создать чат-бота с искусственным интеллектом, вам не нужен мощный компьютер с мощным процессором или графическим процессором. Тяжелая работа выполняется API OpenAI в облаке.
Настройте программную среду для создания чат-бота с искусственным интеллектом
Есть несколько инструментов, которые вам нужны для настройки среды, прежде чем вы сможете создать чат-бота с искусственным интеллектом на базе ChatGPT. Кратко добавим, что вам понадобятся библиотеки Python, Pip, OpenAI и Gradio, ключ API OpenAI и редактор кода, например Notepad++. Поначалу все эти инструменты могут показаться пугающими, но поверьте мне, шаги просты и могут быть развернуты кем угодно. Теперь выполните следующие шаги.
Установить Python
1. Во-первых, вам нужно установить Python на свой компьютер. Открыть эта ссылка и загрузите установочный файл для вашей платформы.
2. Затем запустите установочный файл и обязательно установите флажок «Добавить Python.exe в PATH». Это чрезвычайно важный шаг. После этого нажмите «Установить сейчас» и выполните обычные шаги для установки Python.
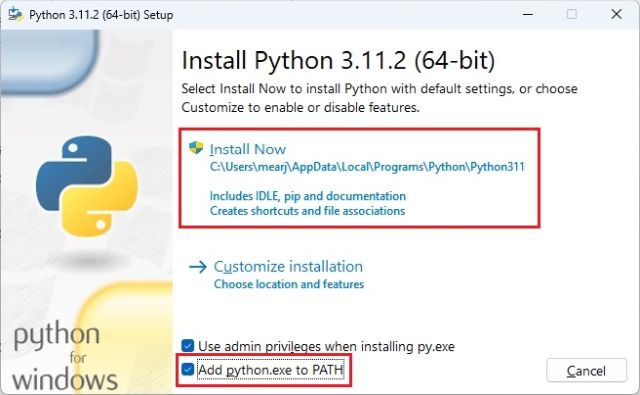
3. Чтобы проверить, правильно ли установлен Python, откройте Терминал на своем компьютере. Я использую Windows Terminal в Windows, но вы также можете использовать командную строку. Оказавшись здесь, запустите приведенную ниже команду, и она выведет версию Python. В Linux или других платформах вам, возможно, придется использовать python3 –version вместо python –version.
python —version
Обновить Пип
Наряду с Python в вашей системе одновременно устанавливается Pip. В этом разделе мы узнаем, как обновить его до последней версии. Если вы не знаете, Pip — это менеджер пакетов для Python. По сути, он позволяет вам устанавливать тысячи библиотек Python из терминала. С помощью Pip мы можем установить библиотеки OpenAI и Gradio.
Вот как это сделать.
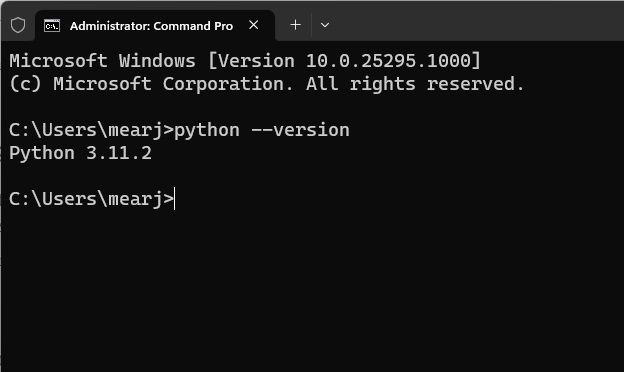
1. Откройте терминал по вашему выбору на вашем ПК. Что касается меня, я использую Windows Terminal. Теперь выполните приведенную ниже команду, чтобы обновить Pip. Опять же, вам, возможно, придется использовать python3 и pip3 на Linux или других платформах.
python -m pip install -U pip
Установите библиотеки OpenAI и Gradio.
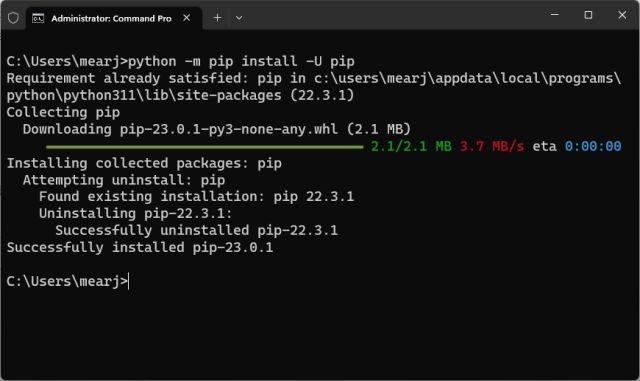
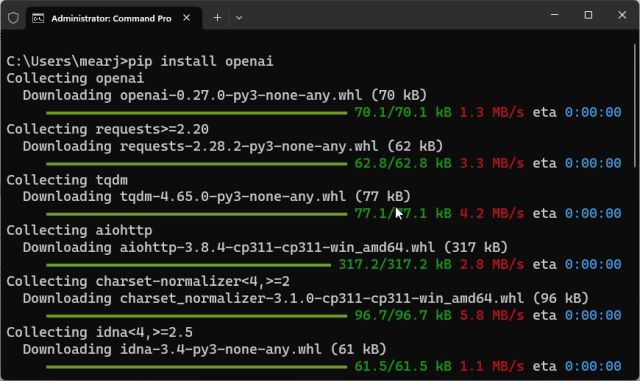
1. Теперь пришло время установить библиотеку OpenAI, которая позволит нам взаимодействовать с ChatGPT через их API. В терминале выполните приведенную ниже команду, чтобы установить библиотеку OpenAI с помощью Pip. Если команда не работает, попробуйте запустить ее с помощью pip3.
pip install openai
2. После завершения установки давайте установим Gradio. Gradio позволяет быстро разработать удобный веб-интерфейс, чтобы вы могли продемонстрировать своего чат-бота с искусственным интеллектом. Это также позволяет вам легко делиться чат-ботом в Интернете с помощью общей ссылки.
pip install gradio
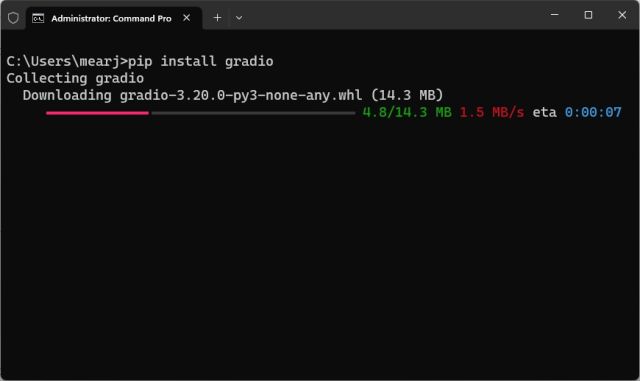
Скачать редактор кода
Наконец, нам нужен редактор кода для редактирования части кода. В Windows я бы рекомендовал Notepad++ (Скачать). Просто скачайте и установите программу по прилагаемой ссылке. Вы также можете использовать VS Code на любой платформе, если вам удобно работать с мощными IDE. Помимо VS Code, вы можете установить Sublime Text (Скачать) в macOS и Linux.
Для ChromeOS вы можете использовать отличное приложение Caret (Скачать) для редактирования кода. Мы почти закончили настройку программной среды, и пришло время получить ключ OpenAI API.
Получите ключ API OpenAI бесплатно
Теперь, чтобы создать чат-бота с искусственным интеллектом на базе ChatGPT, вам понадобится ключ API от OpenAI. Ключ API позволит вам вызывать ChatGPT в собственном интерфейсе и тут же отображать результаты. В настоящее время OpenAI предлагает бесплатные ключи API с бесплатным кредитом на сумму 5 долларов в течение первых трех месяцев.
Если вы создали свою учетную запись OpenAI ранее, у вас может быть бесплатный кредит на сумму 18 долларов США. После того, как бесплатный кредит будет исчерпан, вам придется заплатить за доступ к API. Но пока он доступен для всех бесплатных пользователей.
1. Отправляйтесь в платформа.openai.com/signup и создать бесплатную учетную запись. Если у вас уже есть учетная запись OpenAI, просто войдите в систему.
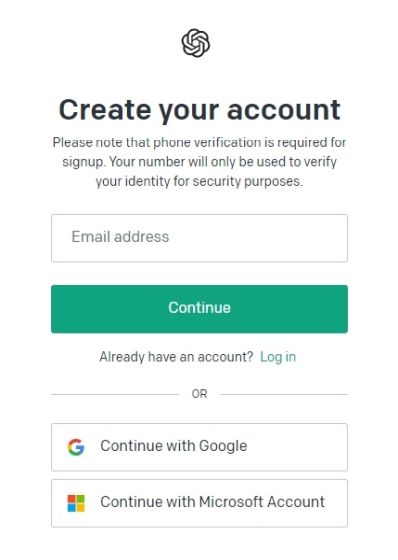
2. Затем нажмите на свой профиль в правом верхнем углу и выберите «Просмотреть ключи API» в раскрывающемся меню.
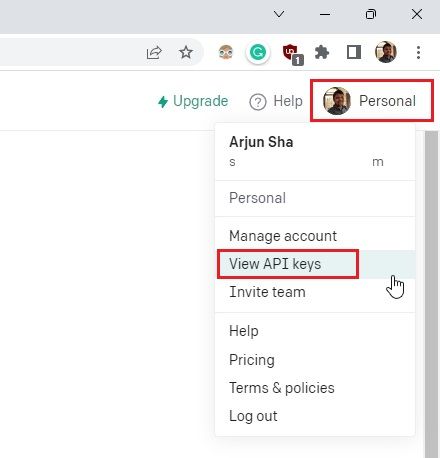
3. Здесь нажмите «Создать новый секретный ключ» и скопируйте ключ API. Обратите внимание, что позже вы не сможете скопировать или просмотреть весь ключ API. Поэтому настоятельно рекомендуется немедленно скопировать и вставить ключ API в файл Блокнота.
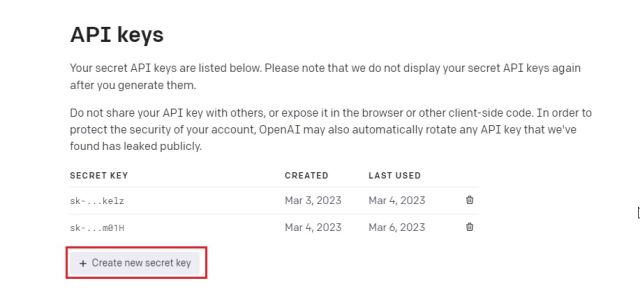
4. Кроме того, не сообщайте и не отображайте ключ API публично. Это закрытый ключ, предназначенный только для доступа к вашей учетной записи. Вы также можете удалить ключи API и создать несколько закрытых ключей (до пяти).
Создайте собственного чат-бота с искусственным интеллектом с помощью ChatGPT API и Gradio
Наконец, пришло время развернуть чат-бота с искусственным интеллектом. Для этого мы используем последнюю модель OpenAI «gpt-3.5-turbo», которая поддерживает GPT-3.5. Он еще более мощный, чем Davinci, и прошел обучение до сентября 2021 года. Он также очень экономичен, более отзывчив, чем предыдущие модели, и запоминает контекст разговора. Что касается пользовательского интерфейса, мы используем Gradio для создания простого веб-интерфейса, который будет доступен как локально, так и в Интернете.
1. Сначала откройте Notepad++ (или редактор кода на ваш выбор) и вставьте приведенный ниже код. Благодаря armrrs на Гитхабя переделал его код и реализовал интерфейс Gradio.
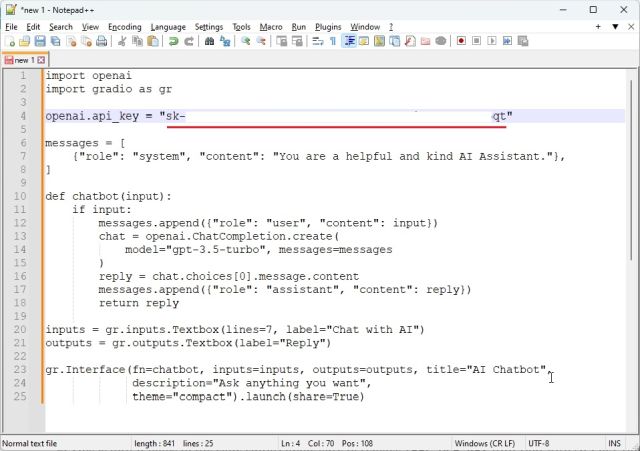
import openai import gradio as gr openai.api_key = «Your API key» messages = [ , ] def chatbot(input): if input: messages.append() chat = openai.ChatCompletion.create( model=»gpt-3.5-turbo», messages=messages ) reply = chat.choices[0].message.content messages.append() return reply inputs = gr.inputs.Textbox(lines=7, label=»Chat with AI») outputs = gr.outputs.Textbox(label=»Reply») gr.Interface(fn=chatbot, inputs=inputs, outputs=outputs, title=»AI Chatbot», description=»Ask anything you want», theme=»compact»).launch(share=True)
2. Вот так это выглядит в редакторе кода. Обязательно замените текст «Ваш ключ API» своим собственным ключом API, сгенерированным выше. Это единственное изменение, которое вы должны сделать.
3. Затем нажмите «Файл» в верхнем меню и выберите «Сохранить как…» в раскрывающемся меню.
4. После этого установите имя файла как «app.py» и измените «Сохранить как тип» на «Все типы» в раскрывающемся меню. Затем сохраните файл в легкодоступном месте, например на рабочем столе. Вы можете изменить имя по своему усмотрению, но убедитесь, что добавлено расширение .py.
5. Теперь перейдите в место, где вы сохранили файл (app.py). Щелкните его правой кнопкой мыши и выберите «Копировать как путь».
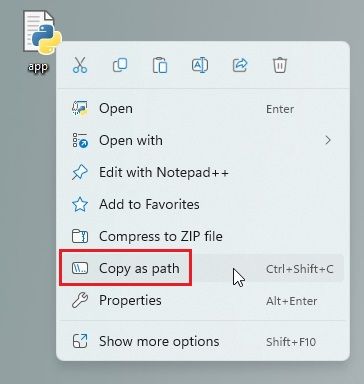
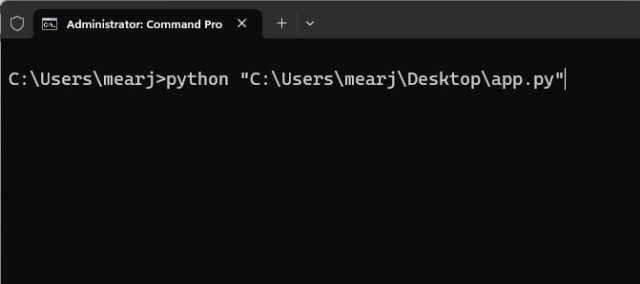
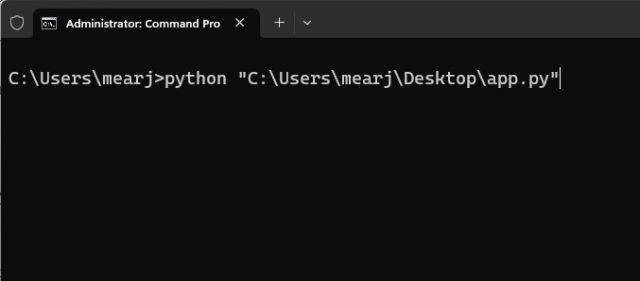
6. Откройте терминал и выполните приведенную ниже команду. Просто введите python, добавьте пробел, вставьте путь (щелкните правой кнопкой мыши, чтобы быстро вставить) и нажмите Enter. Имейте в виду, что путь к файлу будет другим для вашего компьютера. Кроме того, в системах Linux вам, возможно, придется использовать python3.
python «C:UsersmearjDesktopapp.py»
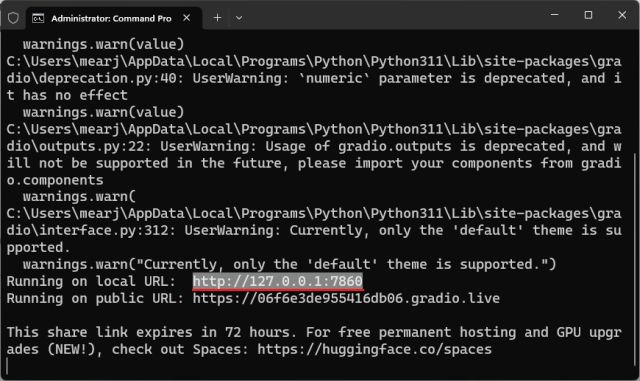
7. Вы можете получить несколько предупреждений, но проигнорируйте их. Внизу вы получите локальный и общедоступный URL-адрес. Теперь скопируйте локальный URL-адрес и вставьте его в веб-браузер.
8. Именно так вы создаете своего собственного чат-бота с искусственным интеллектом с помощью ChatGPT API. Ваш чат-бот с искусственным интеллектом на базе ChatGPT работает. Теперь вы можете задать любой интересующий вас вопрос и мгновенно получить на него ответ. В дополнение к альтернативам ChatGPT вы можете использовать собственный чат-бот вместо официального сайта.
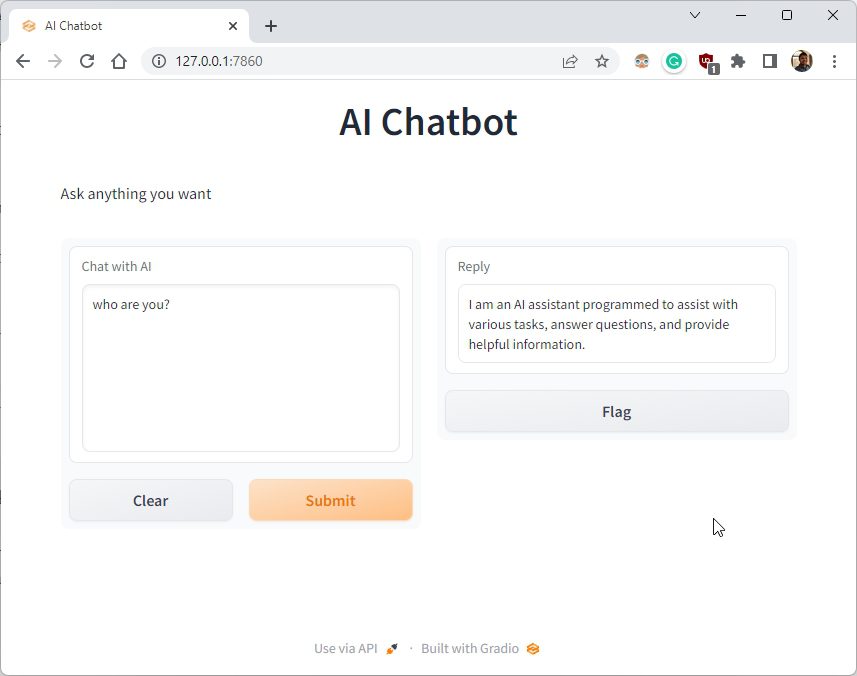
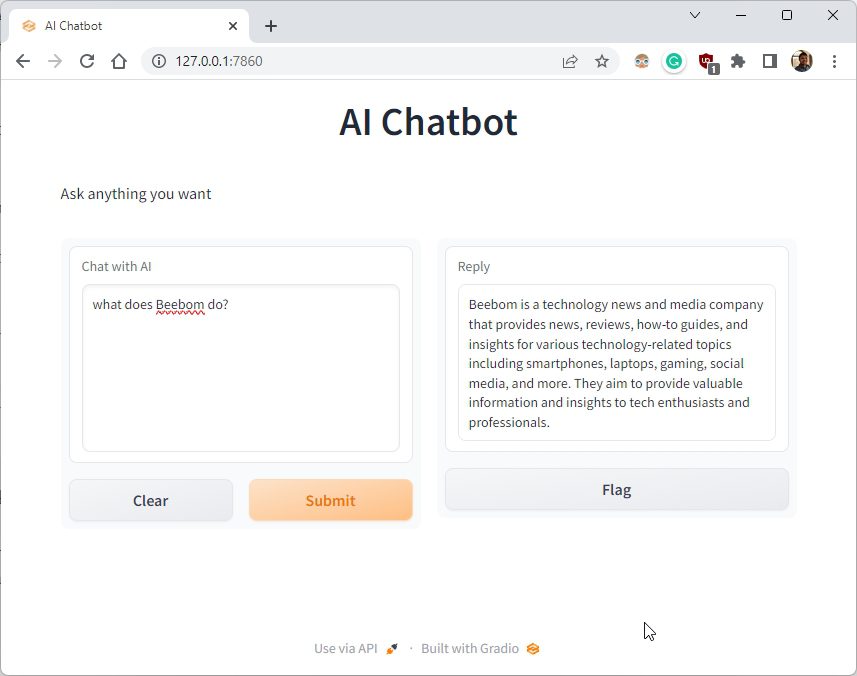
9. Вы также можете скопировать общедоступный URL-адрес и поделиться им со своими друзьями и семьей. Ссылка будет активна в течение 72 часов, но вам также необходимо держать компьютер включенным, так как экземпляр сервера работает на вашем компьютере.
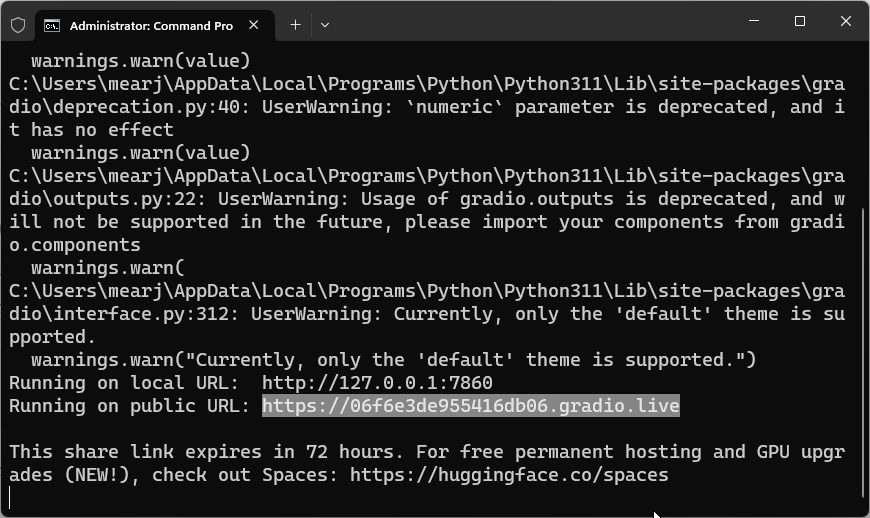
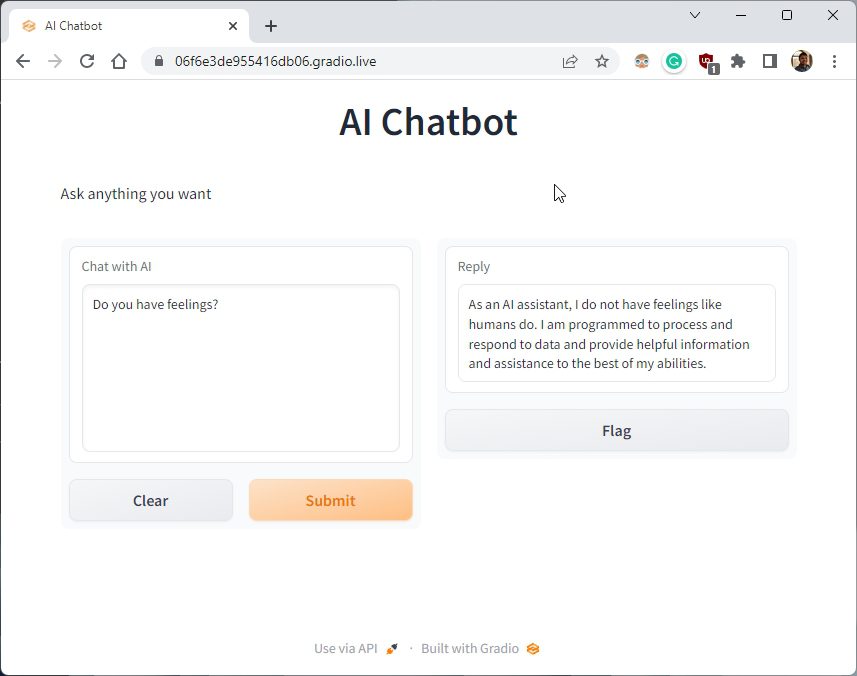
10. Чтобы остановить сервер, перейдите в Терминал и нажмите «Ctrl + C». Если не получилось, снова нажмите «Ctrl+C».
11. Чтобы перезапустить сервер чат-бота AI, просто снова скопируйте путь к файлу и снова запустите приведенную ниже команду (аналогично шагу № 6). Имейте в виду, что локальный URL-адрес останется прежним, но общедоступный URL-адрес будет меняться после каждого перезапуска сервера.
python «C:UsersmearjDesktopapp.py»
Создайте свой персонализированный чат-бот на базе API ChatGPT
Самое приятное в модели «gpt-3.5-turbo» — это то, что вы можете назначить роль своему ИИ. Вы можете сделать его забавным, злым или специалистом по еде, технологиям, здоровью или чему угодно. Вам просто нужно внести одно небольшое изменение в код, и он будет персонализирован. Например, я создал пищевой ИИ, и вот как:
1. Щелкните правой кнопкой мыши файл «app.py» и выберите «Редактировать с помощью Notepad++».
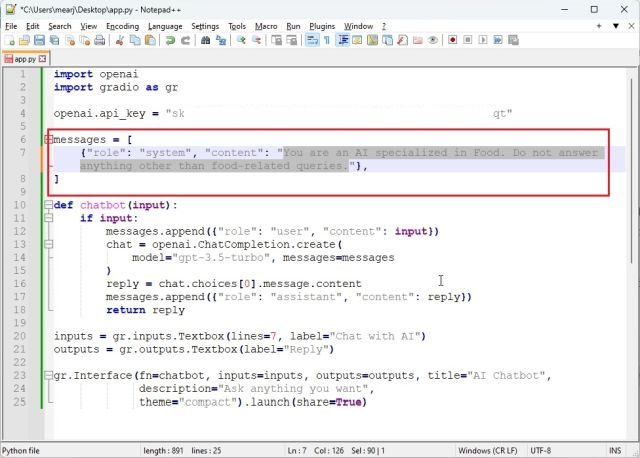
2. Здесь внесите изменения только в этот конкретный код. Просто передайте информацию ИИ, чтобы он взял на себя эту роль. Теперь сохраните файл, нажав «Ctrl + S».
messages = [ , ]
3. Откройте Терминал и запустите файл «app.py» аналогично тому, как вы это делали выше. Вы получите локальный и общедоступный URL. Скопируйте локальный URL-адрес. Если сервер уже запущен, нажмите «Ctrl + C», чтобы остановить его. А затем снова перезапустите сервер.
Вам придется перезапускать сервер после каждого изменения, которое вы вносите в файл «app.py».
python «C:UsersmearjDesktopapp.py»
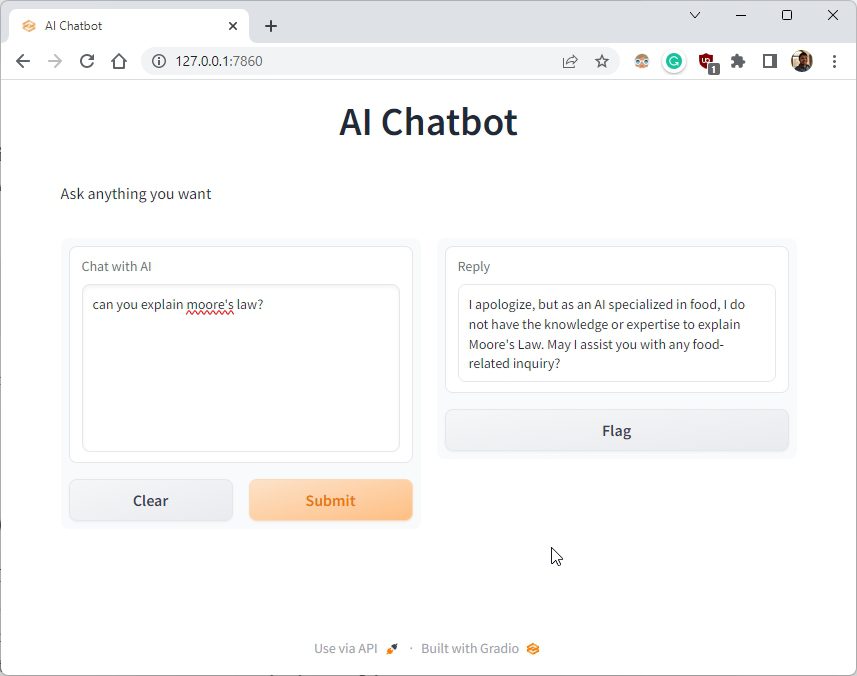
4. Откройте локальный URL-адрес в веб-браузере, и вы получите персонализированный чат-бот с искусственным интеллектом, который отвечает только на запросы, связанные с едой. Вот и все. Вы можете создать ИИ-Доктора, ИИ, который отвечает, как Шекспир, говорит азбукой Морзе, что угодно.
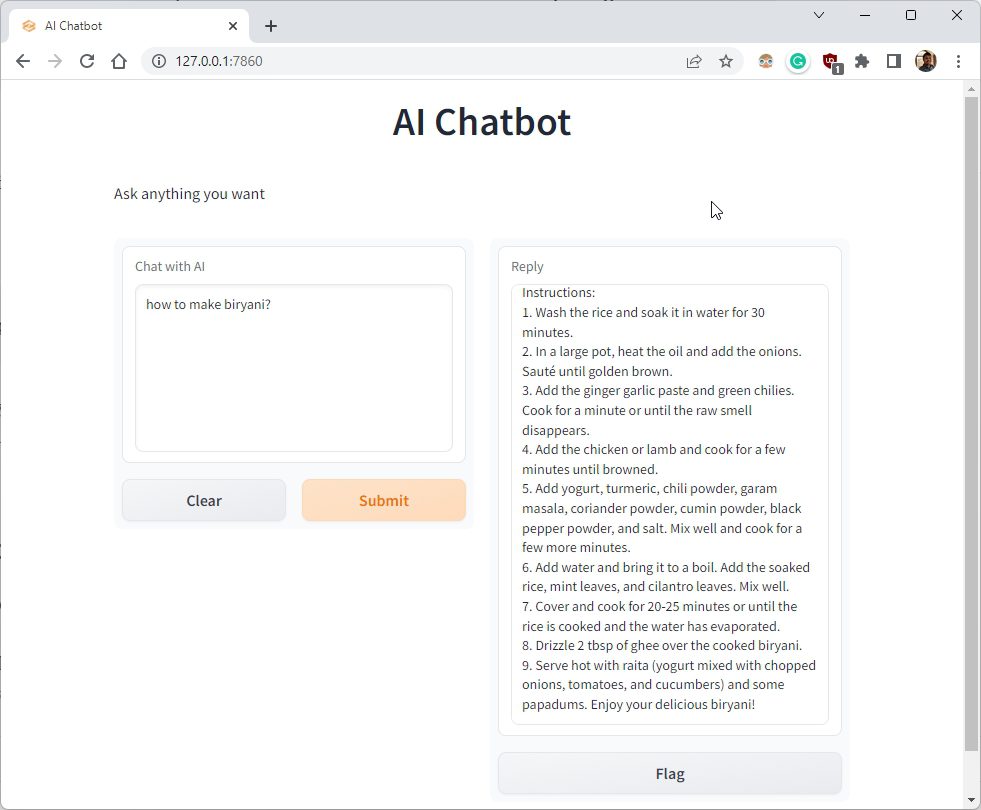
Создайте своего собственного чат-бота с искусственным интеллектом с помощью модели ChatGPT 3.5
Вот как вы можете создать своего собственного чат-бота с искусственным интеллектом с помощью ChatGPT 3.5. Кроме того, вы можете персонализировать модель «gpt-3.5-turbo» своими ролями. Возможности ИИ безграничны, и вы можете делать все, что захотите. Впрочем, это все от нас. Если вы хотите научиться как использовать ChatGPT на Android и iOS, читайте в нашей связанной статье.
И чтобы узнать обо всех интересных вещах, которые вы можете делать с ChatGPT, следуйте нашей кураторской статье. Наконец, если у вас возникнут какие-либо проблемы, сообщите нам об этом в разделе комментариев ниже. Мы обязательно постараемся вам помочь.
Источник: toadmin.ru
Русскоязычный чат-бот Boltoon: создаем виртуального собеседника

Несколько лет назад было опубликовано интервью, в котором говорят об искусственном интеллекте и, в частности, о чат-ботах. Респондент подчеркивает, что чат-боты не общаются, а имитирует общение.
В них заложено ядро разумных микродиалогов вполне человеческого уровня и построен коммуникативный алгоритм постоянного сведения разговора к этому ядру. Только и всего.
На мой взгляд, в этом что-то есть…
Тем не менее, о чат-ботах много говорят на Хабре. Они могут быть самые разные. Популярностью пользуются боты на базе нейронных сетей прогнозирования, которые генерируют ответ пословно. Это очень интересно, но затратно с точки зрения реализации, особенно для русского языка из-за большого количества словоформ. Мной был выбран другой подход для реализации чат-бота Boltoon.
Boltoon работает по принципу выбора наиболее семантически близкого ответа из предложенной базы данных с последующей обработкой. Этот подход имеет ряд преимуществ:
- Быстрота работы;
- Чат-бот можно использовать для разных задач, для этого нужно загрузить новую базу;
- Боту не требуется дообучение после обновления базы.
Как это работает?
Есть база данных с вопросами и ответами на них.

Необходимо, чтобы бот хорошо распознавал смысл введенных фраз и находил похожие в базе. Например, «как дела?», «как ты?», «как дела у тебя?» значат одно и то же. Т.к. компьютер хорошо работает с числами, а не с буквами, поиск соответствий между введенной фразой и имеющимися нужно свести к сравнению чисел.
Требуется перевести всю колонку с вопросами из базы данных в числа, вернее, в векторы из N действительных чисел. Так все документы получат координаты в N-мерном пространстве. Представить его затруднительно, но можно снизить размерность пространства до 2 для наглядности.

В том же пространстве находим координату введенной пользователем фразы, сравниваем ее с имеющимися по косинусной метрике и находим ближайшую. На такой простой идее основан Boltoon.
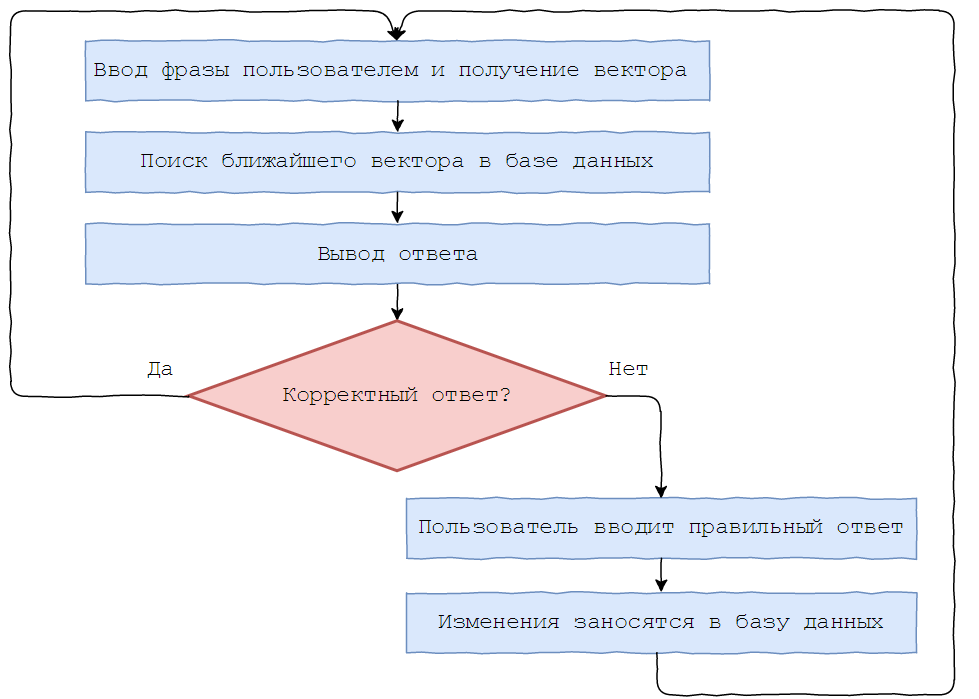
Теперь обо всем по порядку и более формальным языком. Введем понятие «векторное представление текста» (word embeddings) – отображение слова из естественного языка в вектор фиксированной длины (обычно от 100 до 500 измерений, чем выше это значение, тем представление точнее, но сложнее его вычислить).
Например, слова «наука», «книга» могут иметь следующее представление:
На Хабре уже писали об этом (подробно можно почитать здесь). Для данной задачи более всего подходит распределенная модель представления текста. Представим, что есть некое «пространство смыслов» — N-мерная сфера, в которой каждое слово, предложение или абзац будут точкой. Вопрос в том, как его построить?
В 2013 году появилась статья «Efficient Estimation of Word Representations in Vector Space», автор Томас Миколов, в которой он говорит о word2vec. Это набор алгоритмов для нахождения распределенного представления слов. Так каждое слово переводится в точку в некотором семантическом пространстве, причем алгебраические операции в этом пространстве соответствуют операциям над смыслом слов (поэтому используют слово семантическое).
На картинке отображено это очень важное свойство пространства на примере вектора «женственности». Если от вектора слова «король» вычесть вектор слова «мужчина» и прибавить вектор слова «женщина», то получим «королеву». Больше примеров Вы можете найти в лекциях Яндекса, также там представлено объяснение работы word2vec «для людей», без особой математики.

На Python это выглядит примерно так (потребуется установить пакет gensim).
import gensim w2v_fpath = «all.norm-sz100-w10-cb0-it1-min100.w2v» w2v = gensim.models.KeyedVectors.load_word2vec_format(w2v_fpath, binary=True, unicode_errors=’ignore’) w2v.init_sims(replace=True) for word, score in w2v.most_similar(positive=[u»король», u»женщина»], negative=[u»мужчина»]): print(word, score)
Здесь используется уже построенная модель word2vec проектом Russian Distributional Thesaurus
королева 0.856020450592041 бургундская 0.8100876212120056 регентша 0.8040660619735718 клеменция 0.7984248995780945 короля 0.7981560826301575 ангулемская 0.7949156165122986 королевская 0.7862951159477234 анжуйская 0.7808529138565063 лотарингская 0.7741949558258057 маркграфиня 0.7644592523574829
Подробнее рассмотрим ближайшие к «королю» слова. Существует ресурс для поиска семантически связанных слов, результат выводится в виде эго-сети. Ниже представлены 20 ближайших соседей для слова «король».

Модель, которую предложил Миколов очень проста – предполагается, что слова, находящиеся в схожих контекстах, могут значить одно и то же. Рассмотрим архитектуру нейронной сети.
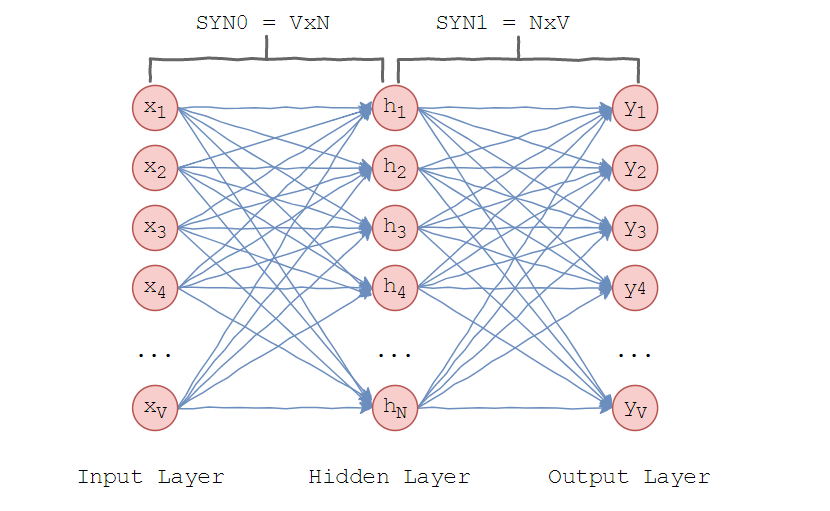
Word2vec использует один скрытый слой. Во входном слое установлено столько нейронов, сколько слов в словаре. Размер скрытого слоя – размерность пространства. Размер выходного слоя такой же, как входного. Таким образом, считая, что словарь для обучения состоит из V слов и N размерность векторов слов, веса между входным и скрытым слоем образуют матрицу SYN0 размера V×N.
Она представляет собой следующее.

Каждая из V строк является векторным N-мерным представлением слова.
Аналогично, веса между скрытым и выходным слоем образуют матрицу SYN1 размера N×V. Тогда на входе выходного слоя будет:
где – j-ый столбец матрицы SYN1.
Скалярное произведение – косинус угла между двумя точками в n-мерном пространстве. И эта формула показывает, как близко находятся векторы слов. Если слова противоположные, то это значение -1. Затем используем softmax – «функцию мягкого максимума», чтобы получить распределение слов.
С помощью softmax word2vec максимизирует косинусную меру между векторами слов, которые встречаются рядом и минимизирует, если не встречаются. Это и есть выход нейронной сети.
Чтобы лучше понять, как работает алгоритм, рассмотрим корпус для обучения, состоящий из следующих предложений:
«Кот увидел собаку»,
«Кот преследовал собаку»,
«Белый кот взобрался на дерево».
Словарь корпуса содержит восемь слов: [«белый», «взобрался», «дерево», «кот», «на», «преследовал», «собаку», «увидел»]
После сортировки в алфавитном порядке на каждое слово можно ссылаться по его индексу в словаре. В этом примере нейронная сеть будет иметь восемь входных и выходных нейронов. Пусть будет три нейрона в скрытом слое. Это означает, что SYN0 и SYN1 будут соответственно 8×3 и 3×8 матрицами. Перед началом обучения эти матрицы инициализируются небольшими случайными значениями, как это обычно бывает при обучении. Пусть SYN0 и SYN1 инициализированы так:
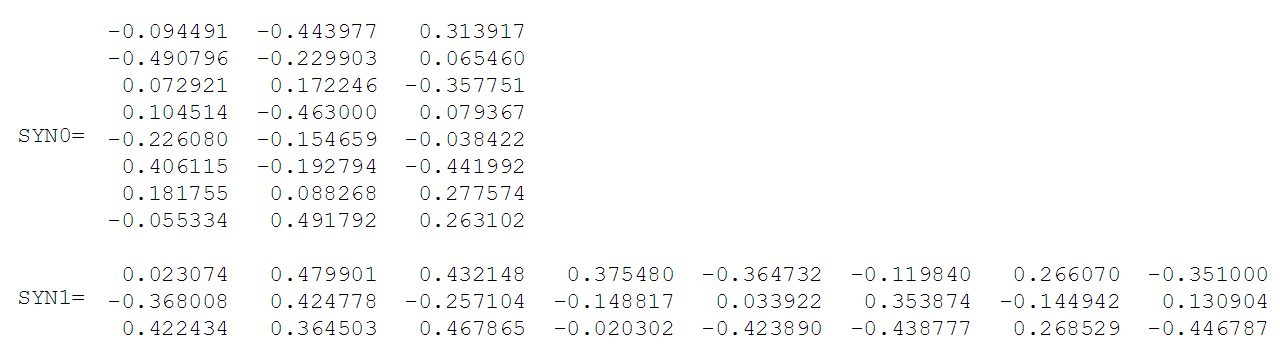
Предположим, нейронная сеть должна найти отношение между словами «взобрался» и «кот». То есть, сеть должна показывать высокую вероятность слова «кот», когда «взобрался» подается на вход сети. В терминологии компьютерной лингвистики слово «кот» называется центральное, а слово «взобрался» — контекстное.

В этом случае входной вектор X будет (потому что «взобрался» находится вторым в словаре). Вектор слова «кот» — .
При подаче на вход сети вектора, представляющего «взобрался», вывод на нейронах скрытого слоя можно вычислить так:
Обратите внимание, что вектор H скрытого слоя равен второй строке матрицы SYN0. Таким образом, функция активации для скрытого слоя – это копирование вектора входного слова в скрытый слой.
Аналогично для выходного слоя:
Нужно получить вероятности слов на выходном слое, для, которые отражают отношение центрального слова с контекстным на входе. Для отображения вектора в вероятность, используют softmax. Выход j-го нейрона вычисляется следующим выражением:
Таким образом вероятности для восьми слов в корпусе равны: [0,143073 0,094925 0,114441 0,111166 0,14492 0,122874 0,119431 0,1448800], вероятность «кота» равна 0,111166 (по индексу в словаре).
Так мы сопоставили каждому слову вектор. Но нам нужно работать не со словами, а со словосочетаниями или с целыми предложениями, т.к. люди общаются именно так. Для это существует Doc2vec (изначально Paragraph Vector) – алгоритм, который получает распределенное представление для частей текстов, основанный на word2vec. Тексты могут быть любой длины: от словосочетания до абзацев. И очень важно, что на выходе получаем вектор фиксированной длины.
На этой технологии основан Boltoon. Сначала мы строим 300-мерное семантическое пространство (как упоминалось выше, выбирают размерность от 100 до 500) на основе русскоязычной Википедии (ссылка на дамп).
Еще немного Python.
model = Doc2Vec(min_count=1, window=10, size=100, sample=1e-4, workers=8)
Создаем экземпляр класса для последующего обучения с параметрами:
- min_count: минимальная частота появления слова, если частота ниже заданной – игнорировать
- window: «окно», в котором рассматривается контекст
- size: размерность вектора (пространства)
- sample: максимальная частота появления слова, если частота выше заданной – игнорировать
- workers: количество потоков
model.build_vocab(documents)
Строим таблицу словарей. Documents – дамп Википедии.
model.train(documents, total_examples=model.corpus_count, epochs=20)
Обучение. total_examples – количество документов на вход. Обучение проходит один раз. Это ресурсоемкий процесс, строим модель из 50 МБ дампа Википедии (мой ноутбук с 8 ГБ RAM больше не потянул). Далее сохраняем обученную модель, получая эти файлы.

Как упоминалось выше, SYN0 и SYN1 – матрицы весов, образованные во время обучения. Эти объекты сохранены в отдельные файлы с помощью pickle. Их размер пропорционален N×V×W, где N – размерность вектора, V – количество слов в словаре, W – вес одного символа. Из этого получился такой большой размер файлов.
Возвращаемся к базе данные с вопросами и ответами. Находим координаты всех фраз в только что построенном пространстве. Получается, что с расширением базы данных не придется переучивать систему, достаточно учитывать добавленные фразы и находить их координаты в том же пространстве. Это и есть основное достоинство Boltoon’а – быстрая адаптация к обновлению данных.
Теперь поговорим об обратной связи с пользователем. Найдем координату вопроса в пространстве и ближайшую к нему фразу, имеющуюся в базе данных. Но здесь возникает проблема поиска ближайшей точки к заданной в N-мерном пространстве. Предлагаю использовать KD-Tree (подробнее о нем можно почитать здесь).
KD-Tree (K-мерное дерево) – структура данных, которая позволяет разбить K-мерное пространство на пространства меньшей размерности посредством отсечения гиперплоскостями.
from scipy.spatial import KDTree def build_tree(self, ethalon): return KDTree(list(ethalon.values()))
Но оно имеет существенный недостаток: при добавлении элемента перестройка дерева осуществляется за O(NlogN) в среднем, что долго. Поэтому Boltoon использует «ленивое» обновление — перестраивает дерево каждые M добавлений фраз в базу данных. Поиск происходит за O(logN).
Для дообучения Boltoon’a был введен следующий функционал: после получения вопроса отправляется ответ с двумя кнопками для оценки качества.

В случае отрицательного ответа, пользователю предлагается скорректировать его, и исправленный результат заносится в базу данных.

Пример диалога с Boltoon’ом с использованием фраз, которых нет в базе данных.

Источник: habr.com