
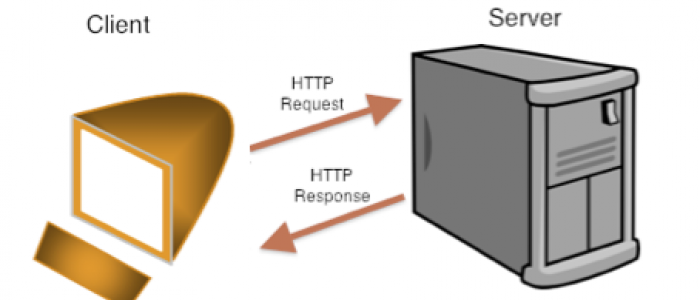
Итак, если у вас уже установлен на компьютере локальный сервер (дистрибьютив Денвер) и вы научились писать простейшие программы на PHP, то самое время узнать, каким образом браузер (клиент) может делать серверу запросы и получать соответствующие ответы. На примере создания простой HTML-формы мы изучим основные принципы такого взаимодействия.
Если вы уже хорошо разбираетесь в каталогах Денвера, то можете создать любой PHP-файл в удобной для вас директории и приступить непосредственно к написанию кода. Для тех, кто еще не уверен в своих силах, советую поступить следующим образом: на виртуальном диске с Денвером (обычно это Z) в папке home создайте папку lessons . Далее, в этой папке создайте еще одну папку – www . Это ваша рабочая папка проекта, которая будет доступна из строки адреса браузера. Перезагрузите Денвер, чтобы созданный хост прописался в системе. Наконец, в папке www создайте файл index.php . Это и будет основной файл с вашим кодом.
Урок Python для новичков, пишем 2 легкие программы
Содержание файла index.php:
Как видите – это обычная HTML-разметка, однако мы назвали файл index.php , а это значит, что теперь в документ мы можем вставлять любые инструкции на языке PHP.
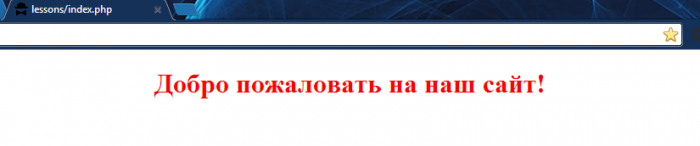
Если вы теперь зайдете в браузере по адресу http://lessons/, то увидите такой результат:
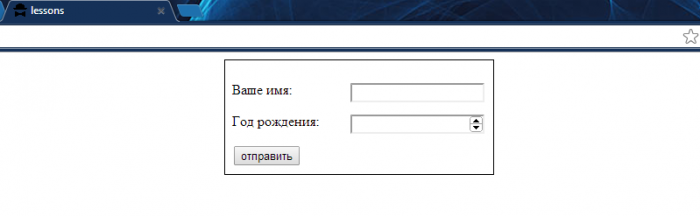
Заполните поля (например: имя – Вася, год рождения – 1990) и нажмите на кнопку «отправить». Что вы видите? А ничего! Опять та же форма, только пустая. Однако не спешите огорчаться – взгляните на адресную строку браузера. Она изменилась и теперь выглядит примерно вот так:
http://lessons/index.php?user_name=Васяsubmit_form=отправить
А это значит, что сервер все-таки получил ваши данные!
Давайте теперь разберемся.
Метод GET
Во-первых, что вообще такое HTML-форма? Это интерфейс, позволяющий отправлять какие-либо данные с браузера клиента на сервер. Взгляните на атрибуты вашей формы:
Атрибут action отвечает за адрес получателя отправляемых данных. В нашем случае форма отправляется на тот же адрес, т.е. на lessons/index.php.
Особое внимание заслуживает атрибут method , который определяет метод отправки запроса на сервер. Таких методов несколько, а наиболее распространенные (и практичные) это методы GET и POST. Сейчас нас будет интересовать метод GET.
GET-запрос означает, что данные будут передаваться на сервер непосредственно через адресную строку. Вы в этом уже убедились, отправив форму – к строке адреса добавились определенные данные. Откуда эти данные берутся? Обратите внимание на теги input в HTML-форме. У всех их присутствует атрибут name , который устанавливает имя данного поля.
При методе GET к основному адресу добавляется символ «?» (знак вопроса), чтобы сервер понимал, что поступили какие-то данные. После символа «?» идут непосредственно сами данные в виде имя=значение . Если таких данных несколько, то они разделяются между собой символом объединения «. Отправьте форму с другими значениями полей и убедитесь в этом.
ChatGPT создаст любое приложение за считанные секунды
Ладно, данные отправились. Что дальше? Куда они ушли и что с ними делать? Вот тут и начинается самое интересное.
Пришло время научиться «ловить» и обрабатывать полученные данные. Ввиду того, что атрибут action указывает на текущий файл index.php, значит данные поступают именно сюда, поэтому в этом же файле мы и пропишем код обработки GET-запроса .
Итак, сразу же после тега добавим такой PHP-код:
Сохраните файл, снова зайдите на http://lessons/, отправьте форму и – о, чудо! – что вы видите?
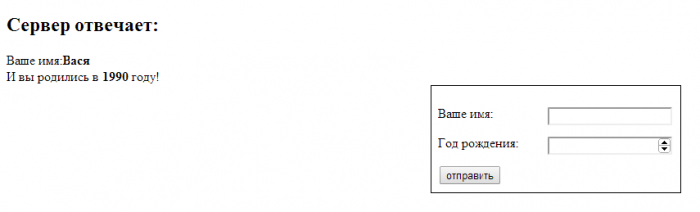
Только что, после отправки формы, сервер получил и обработал полученные данные и прислал в браузер свой ответ!
Рассмотрим PHP-код нашего проекта, который представляет собой условие:
if (isset($_GET[‘submit_form’]))
Сервер проверяет, а получена ли переменная GET-запроса с именем submit_form? То есть, говоря проще, а была ли вообще отправлена форма? Если это так, то серверный php-код отправляет прямо в браузер пользователя новую HTML-разметку со своим ответом, используя для этого оператор echo . Если вы внимательно изучите написанный код-обработчик, то вам сразу все станет понятным!
Интересный же этот метод GET! Измените адресную строку, например, на такую:
http://lessons/index.php?user_name=Мое-имяsubmit_form=отправить
и нажмите кнопку «Ввод». Сервер снова вам ответит, приняв уже другие данные! Думаю, с этим все понятно.
Недостатки GET-метода в том, что, во-первых, есть ограничение на объем передаваемых данных, а во-вторых, этот метод является открытым и любую информацию можно перехватить. Поэтому личные данные пользователя (логин, имя, пароль и др.) никогда нельзя передавать через строку адреса.
Метод POST
Этот метод подразумевает передачу данных отдельным пакетным потоком в теле запроса, что надежно защищает отправляемые данные и позволяет передавать внушительные объемы информации, которые могут быть ограничены лишь настройками сервера. Поэтому такой тип запроса идеально подходит для отправки личных данных и любых типов файлов.
Измените ваш файл, заменив в PHP-коде имена переменных $_GET на $_POST, а в форме пропишите method=»POST» . Обновите страницу и снова отправьте форму. Результат будет таким же, что и при методе GET, однако адресная строка осталась без изменений, а это значит, что данные были благополучно отправлены в защищенном виде в теле самого запроса.
Для закрепления материала создадим маленькое веб-приложение, которое будет запрашивать логин и пароль пользователя для входа на сайт. Код примера будет относительно сложным и от вас требуется внимание и желание разобраться в функционале PHP-программы.
Запустите пример и посмотрите, что происходит. Вначале запрашивается логин и пароль пользователя (в коде мы определили их как «admin» и «secret»), если все верно – мы попадаем на главную страницу сайта, если данные неверные – выводится соответствующее предупреждение.
Рассмотрим реализацию данной технологии.
Обратите внимание – весь код HTML-формы мы не выводим непосредственно, а запоминаем в переменной $form.
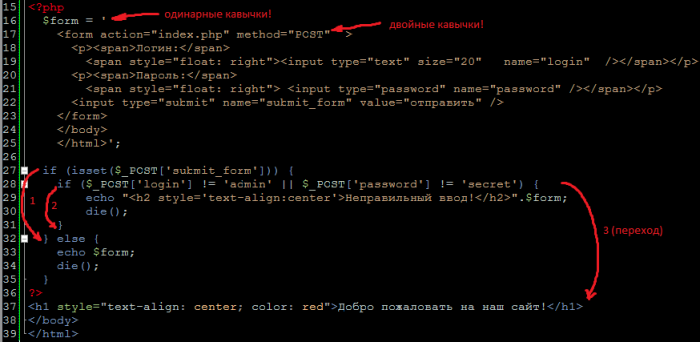
Будьте внимательны с кавычками! Весь HMTL-код находится внутри одинарных кавычек, поэтому его внутренние кавычки должны быть двойными . Если бы вы написали
$form = » …ваш код… «,
то внутренний код будет содержать наоборот – одинарные кавычки.
Далее, в строке 27 проверяется, была ли отправлена форма (условие 1 на рис.), если нет – выводится HTML-форма, и сценарий прекращает свою работу – функция die() . Больше ничего, кроме формы в браузер не выводится.
Если данные были получены, то проверяются POST-переменные на соответствие заданным (условие 2 на рис.). Если они не совпадают, то выводится предупреждающее сообщение, HTML-форма для входа и сценарий снова прекращает работу ( die() ).
Если же второе условие выполняется, то скрипт пропускает все операторы else и переходит на отображение основной страницы. ( переход 3 на рис.).
Это простейший пример. Естественно, в реальных проектах таких прямых проверок не производится – логин и пароль в зашифрованном виде хранятся в файлах или базе данных. Поэтому в статье описана сама технология взаимодействия клиента и сервера на основе GET и POST запросов. Для создания полноценных приложений вам необходимо иметь твердые знания по базам данных и объектно-ориентированному программированию. Об этом – в следующих статьях.
Источник: codeacademy.ru
Как войти на сайт с помощью Python Requests?

Не понял, что значит «войти на сайт»? Что должно быть результатом действия, таким, которое можно чётко определить?

Алан Гибизов, пишу бота который бы считывал ответы на тесты и отправлял их в телеграм. На основне лежит парсинг. Столкнулся с проблемой что нужная ссылка с которой должны браться ответы, не открывается без залогиненного аккаунта. Мне просто нужно войти на сайт используя пайтон, вот и всё.
Kayuro, вы не ответили на мой вопрос:
что должно быть результатом действия, таким, которое можно чётко определить?
Ну, например:
Если я хочу напечатать документ, то результат — видимое изображение документа, которое можно прочесть глазами (на бумаге, на экране).
А что у вас ожидается?
Ещё вопрос: вы как-то пробовали это сделать? Хоть как-нибудь?
Алан Гибизов, Да, пробовал и пробую. В результате ожидаю активную сессию на сайте, для последующей работы с ним. Иначе я не знаю даже как объяснить.
Полазил по другим источникам, попытался переписать.
import requests from bs4 import BeautifulSoup USERNAME = ‘myuser’ PASSWORD = ‘mypass’ URL = ‘https://naurok.com.ua/login’ payload = session = requests.session() r = requests.post(URL, data=payload) account = session.get(‘https://naurok.com.ua/test/monotonnist-i-neperervnist-funkci-parni-ta-neparni-funkci-1059187.html/print’) print (account.content)
import requests from bs4 import BeautifulSoup USERNAME = ‘myuser’ PASSWORD = ‘mypass’ URL = ‘https://naurok.com.ua/login’ payload = session = requests.session() r = requests.post(URL, data=payload) account = session.get(‘https://naurok.com.ua/test/monotonnist-i-neperervnist-funkci-parni-ta-neparni-funkci-1059187.html/print’) print (account.text) url = ‘https://naurok.com.ua/test/monotonnist-i-neperervnist-funkci-parni-ta-neparni-funkci-1059187.html’ response = requests.get(url) soup = BeautifulSoup(response.text, ‘lxml’) quotes = soup.find_all(‘a’, class_=’test-action-button’) for link in soup.find_all(‘a’, class_=’test-action-button’): linkresult = (link.get(‘href’)) if linkresult: urlresult = ‘https://naurok.com.ua’ + linkresult responseresult = requests.get(urlresult) soupresult = BeautifulSoup(response.text, ‘lxml’) quotesresult = soup.find_all(‘div’, class_=’answer-key’) print(quotesresult)
Что выводит после рана:
*html развертку сайта*
[]
Process finished with exit code 0
Я добиваюсь того чтобы он вывел мне эти данные:
1. б (1 балів)
2. б (1 балів)
3. а (1 балів)
4. б (1 балів)
5. а (1 балів)
6. б (1 балів)
7. а (2 балів)
8. а (2 балів)
9. а (1 балів)
10. б (1 балів)
11. в (1 балів)
12. б (2 балів)
13. в (1 балів)
14. в (1 балів)
15. б г (2 балів)
16. б (1 балів)
17. а (1 балів)
18. д (1 балів)
Kayuro, у вас в приведённом коде ошибка в цикле for. Там проверка if не относится к циклу, а должна относиться. Т.е. строчка с if и все следующие должны иметь дополнительный отступ слева, чтобы оказаться в цикле.
Алан Гибизов, Спасибо, это пофиксил. Но меня сейчас волнует решение в выводе правильных значений.
Алан Гибизов, действующий код и нерешенный вопрос:
import requests from bs4 import BeautifulSoup USERNAME = ‘myuser’ PASSWORD = ‘mypass’ URL = ‘https://naurok.com.ua/login’ payload = session = requests.session() r = requests.post(URL, data=payload) account = session.get(‘https://naurok.com.ua/test/monotonnist-i-neperervnist-funkci-parni-ta-neparni-funkci-1059187.html/print’) print (account.text) url = ‘https://naurok.com.ua/test/monotonnist-i-neperervnist-funkci-parni-ta-neparni-funkci-1059187.html’ response = requests.get(url) soup = BeautifulSoup(response.text, ‘lxml’) quotes = soup.find_all(‘a’, class_=’test-action-button’) for link in soup.find_all(‘a’, class_=’test-action-button’): linkresult = (link.get(‘href’)) if linkresult: urlresult = url + ‘/print’ responseresult = requests.get(urlresult) soupresult = BeautifulSoup(response.text, ‘lxml’) quotesresult = soup.find_all(‘div’, class_=’answer-key’) print(urlresult)
Kayuro, вы получаете quotesresult. А что дальше с ним делаете?
Алан Гибизов, quotesresult это уже часть парса, он должен выводить вышеперечисленные значения в виде ответов на тест.
spoiler
1. б (1 балів)
2. б (1 балів)
3. а (1 балів)
4. б (1 балів)
5. а (1 балів)
6. б (1 балів)
7. а (2 балів)
8. а (2 балів)
9. а (1 балів)
10. б (1 балів)
11. в (1 балів)
12. б (2 балів)
13. в (1 балів)
14. в (1 балів)
15. б г (2 балів)
16. б (1 балів)
17. а (1 балів)
18. д (1 балів)
19. б (1 балів)
20. г (1 балів)
21. б (1 балів)
Алан Гибизов, часть для входа на сайт лежит сверху:
import requests from bs4 import BeautifulSoup USERNAME = ’email’ PASSWORD = ‘123strong’ URL = ‘https://naurok.com.ua/login’ payload = responseaccount = requests.get(URL) soupaccount = BeautifulSoup(responseaccount.text, ‘lxml’) quotesaccount = soupaccount.find_all(‘img’, class_=’profile-avatar’) session = requests.session() r = requests.post(URL, data=payload) account = session.get(‘https://naurok.com.ua/test/monotonnist-i-neperervnist-funkci-parni-ta-neparni-funkci-1059187.html/print’) print (quotesaccount)

Kayuro, зачем стартуешь новую session?
У тебя сайт в старой сессии оставил куки, что ты вошел на сайт. А новая сессия про них не знает.
Так что запрос на URL для входа и запрос на URL страницы теста должны выполняться в рамках одной сессии.
А если в питоне не шаришь, значит, откладываешь этот проект и учишь азы питона. Потом вернёшься к нему. Иначе на отступах и прочей мелочи будешь спотыкаться.
Vindicar, что под твоим пониманием новая сессия?
request.session — как я читал, это как раз таки сохранение сессии.
Так-же, что в твоем понимании азы питона?
Vindicar, Мне всего-лишь нужно в этой теме разобраться, а дальше мне будет легче, т.к работа с этим будет завершена. Я жду помощи/решения, а не советов по типу иди учи. Пойми меня.
Kayuro, Я же прямо написал — session.
У тебя первый запрос выполняется как requests.get(), при этом неявно создаётся новая сессия по умолчанию.
Затем ты создаёшь другую сессию вызовом requests.session(), и выполняешь второй запрос уже в отдельной сессии.
Лучше всего создать сессию с самого начала и делать все запросы в её рамках.
Vindicar, сделал как ты сказал, ничего не поменялось. Если есть возможность, напиши код, я его скопирую и вставлю. Возможно я что-то не так абсолютно в коде делаю, а ты даже не знаешь что там в html развертке, если оно решает.
Сайт https://naurok.com.ua
Kayuro, тогда покажи актуальный код, лучше в самом вопросе.
import requests USERNAME = ’email’ PASSWORD = ‘123strong’ LOGIN_URL = ‘https://naurok.com.ua/login’ TEST_URL = ‘https://naurok.com.ua/test/monotonnist-i-neperervnist-funkci-parni-ta-neparni-funkci-1059187.html’ with requests.Session() as session: login_resp = session.get(LOGIN_URL) #куки, реферер login_resp = session.post(LOGIN_URL, data=) info_resp = session.get(TEST_URL) print(info_resp.text)
Vindicar, Не заработало. Могу лишь рассказать что я делаю.
Я ученик 10 класса, и заметил что нет ни одного бота для решения тестов на сайте НаУрок.
Сегодня сказал однокласснице про эту идею. Пришёл домой, зашёл на хабр и спросил возможно ли./
Вспомнил что немного шарю в пайтоне (сам изучал + школа), и неплохо получалось чинить файлы от сына информатички (он тупой был).
Вот, почитал документацию об парсинге/скрапинге, всё хорошо было, ответы уже можно было забирать, но проблема была в том что чтобы чекать данную страницу, нужно войти в аккаунт. Соответственно аккаунт в браузере был, а в коде — нет. Вот и вся история. Код прикреплю ниже весь.
import requests from bs4 import BeautifulSoup url = ‘https://naurok.com.ua/test/monotonnist-i-neperervnist-funkci-parni-ta-neparni-funkci-1059187.html’ response = requests.get(url) soup = BeautifulSoup(response.text, ‘lxml’) quotes = soup.find_all(‘a’, class_=’test-action-button’) for link in soup.find_all(‘a’, class_=’test-action-button’): linkresult = (link.get(‘href’)) if linkresult: urlresult = url + ‘/print’ responseresult = requests.get(urlresult) soupresult = BeautifulSoup(response.text, ‘lxml’) quotesresult = soup.find_all(‘div’, class_=’answer-key’) print(urlresult)
Сам логин (прикреплю твой)
import requests USERNAME = ‘зарегайся, 2 минуты’ PASSWORD = ‘зарегайся, 2 минуты’ LOGIN_URL = ‘https://naurok.com.ua/login’ TEST_URL = ‘https://naurok.com.ua/test/monotonnist-i-neperervnist-funkci-parni-ta-neparni-funkci-1059187.html/print’ with requests.Session() as session: login_resp = session.get(LOGIN_URL) #куки, реферер login_resp = session.post(LOGIN_URL, data=) info_resp = session.get(TEST_URL) print(info_resp.text)
Попробуй зарегаться, если я обречён, то так и скажи.
Vindicar, вот что я ожидал видеть:
1. б (1 балів) 2. б (1 балів) 3. а (1 балів) 4. б (1 балів) 5. а (1 балів) 6. б (1 балів) 7. а (2 балів) 8. а (2 балів) 9. а (1 балів) 10. б (1 балів) 11. в (1 балів) 12. б (2 балів) 13. в (1 балів) 14. в (1 балів) 15. б г (2 балів) 16. б (1 балів) 17. а (1 балів) 18. д (1 балів) 19. б (1 балів) 20. г (1 балів) 21. б (1 балів)
Kayuro, ну в URL страницы у меня была ошибка, исправил код выше.
Теперь страница открывается.
А её парсинг, это уже отдельный вопрос.

Попробуй связаться с разработчиками сайта. Они вряд ли помогут тебе, но попробовать стоит
Vindicar, Парсинг полностью настроен, мне нужно залогиниться. То что ты исправил ссылку в тест_урл — ничего не изменило. Я расстроен.
Shandy, В их же интересах не допускать парсинга, поэтому нечего им писать)
Kayuro, я не спрашиваю, что quotesresult должен делать. Я спрашиваю, что ты с ним делаешь? В твоем коде я этого не увидел.
Кроме того, мне лично не нравится подход «Я жду помощи/решения, а не советов по типу иди учи.» Тут тебе никто не обязан ни помогать, ни тем более давать решения.
Тут ты можешь привести кусок своего кода, который работает не так, как ты ожидал, и спросить, что ты не так делаешь. Тебе могут ответить. Могут и не ответить. Но уж точно тут никто не должен предоставить тебе правильный код — это изволь сам делать.
Советую ознакомиться с правилами.
Источник: qna.habr.com
Парсинг сайта с применением авторизации

Любой, кто когда-либо пытался парсить сайты на python начинал с простого запроса «get» библиотеки «requests». Запрос «get» выгружает html код страницы, который можно обрабатывать под свои нужды.
Но иногда данные доступны только после авторизации на ресурсе. В этом посте я покажу, как можно подключаться, используя логин-пароль и библиотеку «requests».
Использование сессий дает преимущества в скорости парсинга данных и исключает блокировку учетной записи. Если приходится выгружать данные — страницу сайта за страницей, при каждом новом запросе будет создаваться новый запрос с новым подключением к сайту, при использовании сессии она создается один раз и используется на всем протяжении работы.
Возьмем сайт https://ivi.ru/ и попытаемся залогиниться.
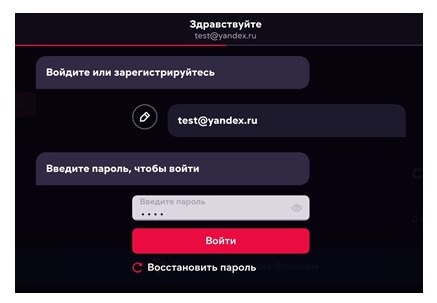
Для авторизации требуется ввести email и пароль. В библиотеке requests есть метод «POST», с помощью которого реализуются отправки данных на сервер. Общий вид использования метода: «requests.post(url, headers, data)». «url» ссылка на ресурс, «headers» заголовки запроса, «data» данные запроса, которые мы будем передавать.
Импорт, авторизация и исходные параметры
pip install requests
Прежде всего, нужно узнать, откуда брать данные «headers» и «data». Для этого запустим инструмент разработчика. Переходим во вкладку СЕТЬ и обновляем страницу. Здесь видим все активности сети.
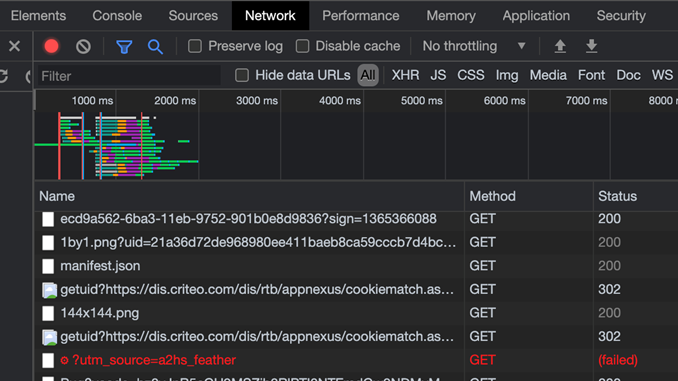
На главной странице сайта входим в профиль. Открывается форма авторизации, вводим логин-пароль и нажимаем кнопку ВОЙТИ. Ищем нашу ссылку.
Чтобы быстрее находить нужную строку в отображении полей нужно добавить поле «Method» и по нему отсортировать столбец. Данные на авторизацию отправляются в «POST» запросах.
Находим строку v5/

Смотрим информацию по этой строке
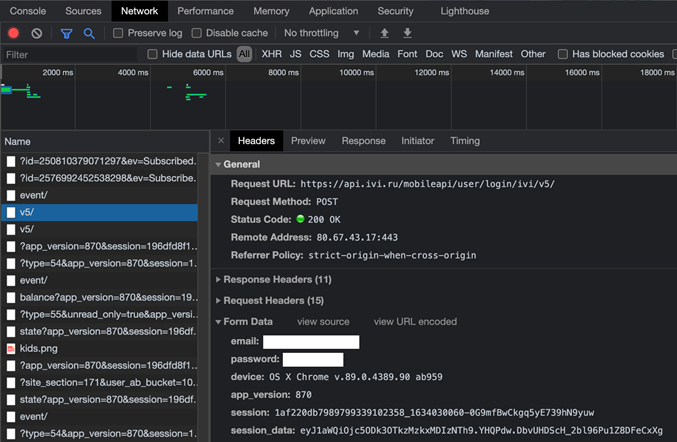
Во вкладке «headers» находим «General» в нем возьмем «url», в «Request Headers» нас интересует только «User-Agent», который пропишем в «headers», в «Form Data» данные для запроса «data».
import requests
url = ‘https://api.ivi.ru/mobileapi/user/login/ivi/v5/’
headers = < ‘User-Agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36’ >
data =
Создаем сессию, она будет держать наше соединение с сайтом, и мы сможем с ним работать.
session = requests.Session() session.headers.update(headers) response = session.post(url, data=data)
Смотрим статус ответа
response
Ответ 200 означает успешный ответ от сервера.
Посмотрим, что возвратил наш запрос
response.json()
Здесь важная строка «session», которая указывает на наш номер сессии. Дальше в примере будет видно, что, если бы мы не создали сессию, изменить данные нам бы не удалось.
Попробуем поменять данные профиля. Нажимаем на кнопку редактировать и меняем имя.

Ищем в инструменте разработчика нашу строку. Чтобы не было много записей, можно сразу же после нажатия кнопки сохранить остановить загрузку страницы, «POST» запрос на изменение будет идти первым, только после этого происходит загрузка страницы с обновленными данными.
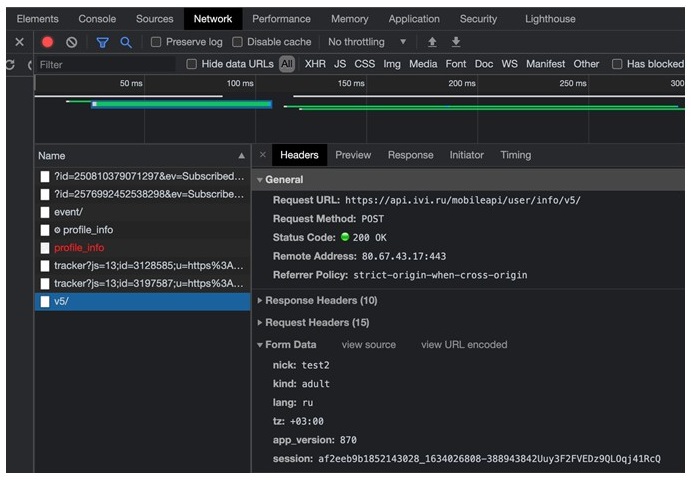
Записываем «url» и копируем «data». Необходимо обратить внимание на строку «session», где нужно передать наш номер сессии. Номер берем из ответа сервера.
url_change_nick = ‘https://api.ivi.ru/mobileapi/user/info/v5/’
session_id = response.json()[‘result’][‘session’] data =
response = session.post(url_change_nick, data=data)
Чтобы удостовериться в работе нашего кода обновляем страницу в браузере.

Наш код успешно сработал.
Использование учетных данных WINDOWS
Также бывают редкие случаи, когда нужно использовать логин-пароль от учетной записи Windows. Для этого можно использовать библиотеку «requests-negotiate-sspi». Она становится особенно полезной, когда часто меняется пароль от учетной записи.
Устанавливаем и импортируем библиотеку, нам нужен метод «HttpNegotiateAuth»
pip install requests_negotiate_sspi from requests_negotiate_sspi import HttpNegotiateAuth
Повторяем все, что делали выше: прописываем «headers», заполняем «data» и поднимаем сессию. Попробуем получить дату и время сервера.
Вначале сделаем запрос без передачи данных авторизации
xml_request = »’ »’ headers = < ‘Host’: host_name, ‘Content-Type’: ‘text/xml; charset=utf-8’, ‘Content-Length’: str(len(xml_request)) >session.headers = headers
response = session.post(‘http://’ + host_name + ‘/ServerService.asmx?WSDL’, data=xml_request) response
Посмотрим текст ответа
response.text
401 — Unauthorized: Access is denied due to invalid credentials.
Как мы видим ошибка авторизации.
Повторяем запрос с использованием «HttpNegotiateAuth»
response = session.post(‘http://’ + host_name + ‘/ServerService.asmx?WSDL’, auth=HttpNegotiateAuth(), data=xml_request) response.text
44298.576980902777
Ответ на запрос даты и времени сервера получен успешно.
Sessions позволяет вам использовать requests более эффективно и решать проблемы с подключением к аккаунту, ускорять работу выполнения запросов и исключать блокировку при ограничении количества соединений.
Источник: newtechaudit.ru