
Закрыт. Этот вопрос необходимо уточнить или дополнить подробностями. Ответы на него в данный момент не принимаются.
Хотите улучшить этот вопрос? Добавьте больше подробностей и уточните проблему, отредактировав это сообщение.
Закрыт 7 лет назад .
#include «stdafx.h» #include #include #include #include #include int main() < char mass [80][80]; char slovo[80]; int i=0; int a,k=0; setlocale(LC_ALL, «Russian»); FILE *f; f=fopen(«text.txt», «r»); if(f==NULL) printf(«файл text.txt не открытn»); a=i; printf(«Введите слово для поиска: «); // Здесь должен быть линейный поиск >
Отслеживать
задан 17 дек 2014 в 16:34
53 1 1 золотой знак 2 2 серебряных знака 9 9 бронзовых знаков
кому не ясна суть вопроса, посмотрите на ответы, если ответы не ясны, оставьте комментарий под соответствующим ответом
13 дек 2017 в 17:09
3 ответа 3
Сортировка: Сброс на вариант по умолчанию
Вот ответ, разбирайтесь:
#include «iostream» #include #include using namespace std; int main() < ifstream file(«C://1.txt»); // открыли файл с текстом string s, find; char c; while (!file.eof())< // прочитали его и заполнили им строку file.get(c); s.push_back(c); >file.close(); // обязательно закрыли cout > find; int pos = s.find(find); // поиск if (pos == -1) cout
Отслеживать
ответ дан 18 дек 2014 в 12:14
9,951 14 14 золотых знаков 51 51 серебряный знак 114 114 бронзовых знаков
Большое спасибо, теперь разобрался.
19 дек 2014 в 12:25
Как написать свою программу на python? #python #программирование
Как написать программу для поиска
Функция find() возвращает индекс первого вхождения подстроки или отдельного символа в строке в виде значние я типа size_t :
#include #include int main() < std::string text ; std::cout
Если строка или символ не найдены (как в примере выше в последнем случае), то возвращается специальная константа std::string::npos , которая представляет очень большое число (как видно из примера, число 18446744073709551615). И при поиске мы можем проверять результат функции find() на равенство этой константе:
if (text.find(«banana») == std::string::npos)
Функция find имеет ряд дополнительных версий. Так, с помощью второго параметра мы можем указать индекс, с которого надо вести поиск:
#include #include int main() < std::string text ; // поиск с 10-го индекса std::cout
Используя эту версию, мы можем написать программу для поиска количества вхождений строки в тексте, то есть выяснить, сколько раз строка встречается в тексте:
#include #include int main() < std::string text ; std::string word ; unsigned count<>; // количество вхождений for (unsigned i <>; i std::cout
Здесь в цикле пробегаемся по тексту, в котором надо найти строку, пока счетчик i не будет равен text.length() — word.length() . С помощью функции find() получаем индекс первого вхождения слова в тексте, начиная с индекса i. Если таких вхождений не найдено, то выходим из цикла. Если же найден индекс, то счетчик i получает индекс, следующий за индексом найденного вхождения.
Парсинг в Python за 10 минут!
В итоге, поскольку искомое слово «friend» встречается в тексте два раза, то программа выведет
The word is found 2 times.
В качестве альтернативы мы могли бы использовать цикл while :
#include #include int main() < std::string text ; std::string word ; unsigned count<>; // количество вхождений size_t index<>; // начальный индекс while ((index = text.find(word, index)) != std::string::npos) < ++count; index += word.length(); // перемещаем индекс на позицию после завершения слова в тексте >std::cout
Еще одна версия позволяет искать в тексте не всю строку, а только ее часть. Для этого в качестве третьего параметра передается количество символов из искомой строки, которые программа будет искать в тексте:
#include #include int main() < std::string text ; std::string word ; // поиск с 10-го индекса 3 первых символов слова «endless», то есть «end» std::cout
Стоит отметить, что в этом случае искомая строка должна представлять строковый литерал или строку в С-стиле (например, символьный массив с концевым нулевым байтом).
Функция rfind. Поиск в обратном порядке
Функция rfind() работает аналогично функции find() , принимает те же самые параметры, только ищет подстроку в обратном порядке — с конца строки:
#include #include int main() < std::string text ; std::cout
Поиск любого из набора символов
Пара функций — find_first_of() и find_last_of() позволяют найти соответственно первый и последний индекс любого из набора символов:
#include #include int main() < std::string text ; std::string letters; // искомые символы std::cout
В данном случае ищем в строке «Phone number: +23415678901» первую и последнюю позицию любого из символов из строки «0123456789». То есть таким образом мы найдем начальный и конечный индекс номера телефона.
Если нам, наоборот, надо найти позиции символов, которые НЕ представляют любой символ из набора, то мы можем использовать функции find_first_not_of() (первая позиция) и find_last_not_of() (последняя позиция):
#include #include int main() < std::string text ; std::string letters; // искомые символы std::cout
Пишем скрипт для поиска с помощью Python и OpenCV
В этой статье мы рассмотрим, как в кратчайшие сроки написать Python-скрипт, который пригодится для подсчёта числа книг на изображении. Для работы будем использовать библиотеку алгоритмов компьютерного зрения OpenCV.
Какова задача?
Посмотрите на фото ниже:

На изображении мы видим 4 книги и различные отвлекающие предметы: конфету, магниты, кофе, чашку. Наша задача — найти эти 4 книги с помощью машинного зрения и не определить как книгу ни один другой предмет.
Чтобы выполнить эту задачу, мы, кроме вышеупомянутой библиотеки OpenCV, будем использовать также и NumPy, поэтому эти библиотеки понадобится установить.
Приступаем к поиску
Открываем редактор кода, создаём новый файл с именем find_books.py и начинаем:
# -*- coding: utf-8 -*- # импортируем нужные пакеты import numpy as np import cv2 # загружаем изображение, меняем цвет на оттенки серого и уменьшаем резкость image = cv2.imread(«example.jpg») gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) gray = cv2.GaussianBlur(gray, (3, 3), 0) cv2.imwrite(«gray.jpg», gray)
Прежде всего, надо выполнить импорт библиотеки OpenCV. Обратите внимание, что загрузка изображения с диска обрабатывается с помощью функции cv2.imread. Тут мы просто загружаем его с диска, после чего преобразуем цветовую гамму в оттенки серого.
Кроме этого, мы немного размываем изображение, дабы уменьшить ВЧ-шумы и увеличить точность приложения. После исполнения кода изображение будет выглядеть следующим образом:

То есть мы выполнили загрузку изображения с диска, преобразовали фото в оттенки серого, а потом немного размыли изображение.
Что же, давайте определим контуры объектов на изображении:
# распознаём контуры edged = cv2.Canny(gray, 10, 250) cv2.imwrite(«edged.jpg», edged)
Теперь изображение выглядит так:
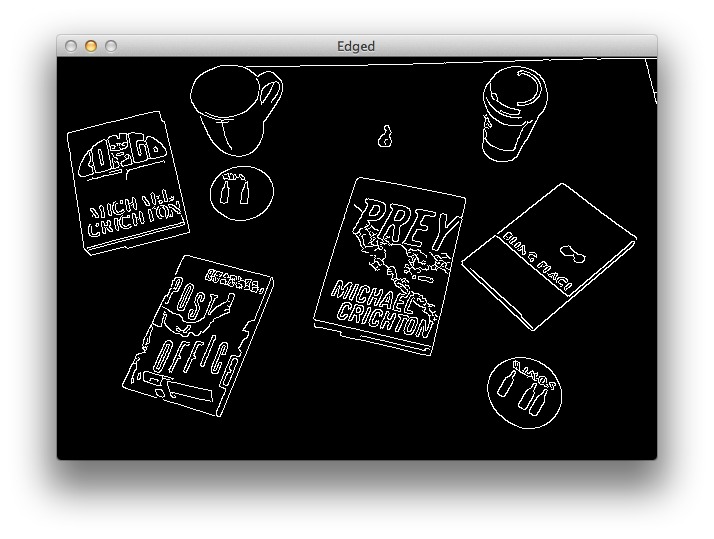
Итак, мы определили на изображении контуры объектов. Но, как видно, часть контуров не закрыта, а между контурами есть промежутки. Дабы убрать промежутки, существующие между белыми пикселями, задействуем операцию «закрытия»:
# создаём и применяем закрытие kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (7, 7)) closed = cv2.morphologyEx(edged, cv2.MORPH_CLOSE, kernel) cv2.imwrite(«closed.jpg», closed)
Вуаля, теперь пробелы в контурах закрыты:
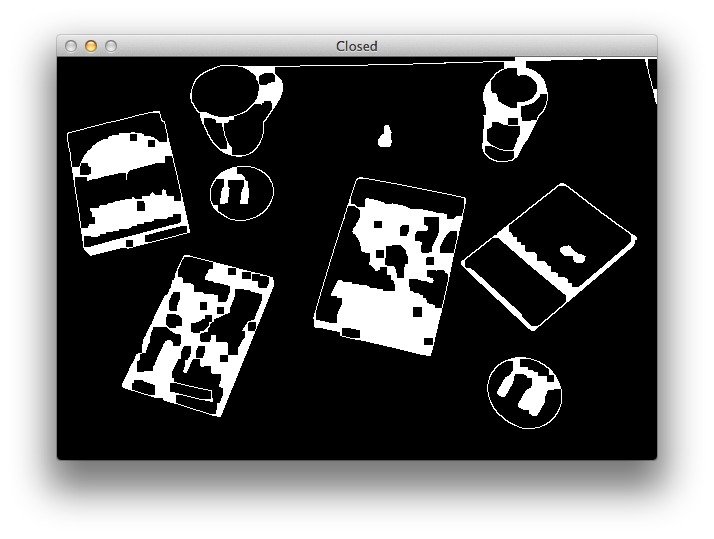
Следующий этап — фактическое обнаружение контуров объектов. Теперь задействуем функцию cv2.findContours:
# находим контуры в изображении и подсчитываем число книг cnts = cv2.findContours(closed.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[1] total = 0
Теперь несколько слов о геометрии книги. Как известно — это прямоугольник, который, соответственно, имеет 4 вершины. Следовательно, если при рассмотрении контура мы обнаружим наличие 4-х вершин, мы сможем предположить, что перед нами именно книга. Чтобы это проверить, надо выполнить цикл по каждому контуру:
# выполняем цикл по контурам for c in cnts: # сглаживаем контур peri = cv2.arcLength(c, True) approx = cv2.approxPolyDP(c, 0.02 * peri, True) # если у контура есть четыре вершины, это, скорее всего, книга if len(approx) == 4: cv2.drawContours(image, [approx], -1, (0, 255, 0), 4) total += 1
При этом для каждого из контуров производится вычисление периметра (с помощью cv2.arcLength), а потом происходит аппроксимация (сглаживание) контура с помощью cv2.approxPolyDP.
Зачем выполняем аппроксимацию? Дело в том, что контур может и не быть идеальным прямоугольником, так как зашумление и тени на изображении всё же оказывают влияние. Когда мы аппроксимируем контур, мы эту проблему решаем.
В конце концов, мы осуществляем проверку, что у аппроксимируемого контура действительно есть 4 вершины. Если это так, мы рисуем вокруг книги контур с одновременным увеличением счётчика общего числа книг.
Давайте завершим этот пример и покажем полученное изображение и число книг, которые удалось найти:
# покажем результирующее изображение print(«Я нашёл книг на этой картинке».format(total) cv2.imwrite(«output.jpg», image))
На этом этапе наше фото будет выглядеть так:

Что касается терминала, то он нам покажет, что мы успешно нашли 4 книги и проигнорировали посторонние предметы:
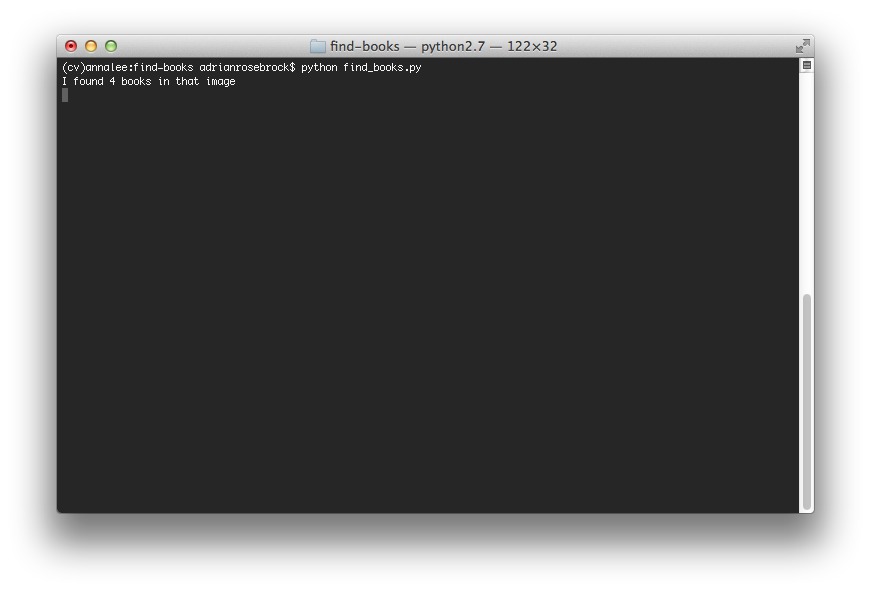
Делаем выводы
Итак, мы показали, как можно найти книги на фотографиях с помощью простых методов обработки изображений, а также компьютерного зрения, Python и OpenCV.
Кратко перескажем суть подхода: 1. Загружаем изображение с диска, преобразуем его в оттенки серого. 2. Немного размываем изображение. 3. Применяем детектор контуров Canny с целью обнаружения объектов на изображении. 4. Закрываем промежутки в контурах. 5. Находим контуры объектов на изображении.
6. Применяем контурную аппроксимацию для определения, был ли контур прямоугольником и, соответственно, книгой.
Источник: otus.ru