
Парсинг — это распространенный способ получения данных из интернета для разного типа приложений. Практически бесконечное количество информации в сети объясняет факт существования разнообразных инструментов для ее сбора. В процессе скрапинга компьютер отправляет запрос, в ответ на который получает HTML-документ. После этого начинается этап парсинга.
Здесь уже можно сосредоточиться только на тех данных, которые нужны. В этом материале используем такие библиотеки, как Beautiful Soup, Ixml и Requests. Разберем их.
Установка библиотек для парсинга
Чтобы двигаться дальше, сначала выполните эти команды в терминале. Также рекомендуется использовать виртуальную среду, чтобы система «оставалась чистой».
pip install lxml pip install requests pip install beautifulsoup4
Поиск сайта для скрапинга
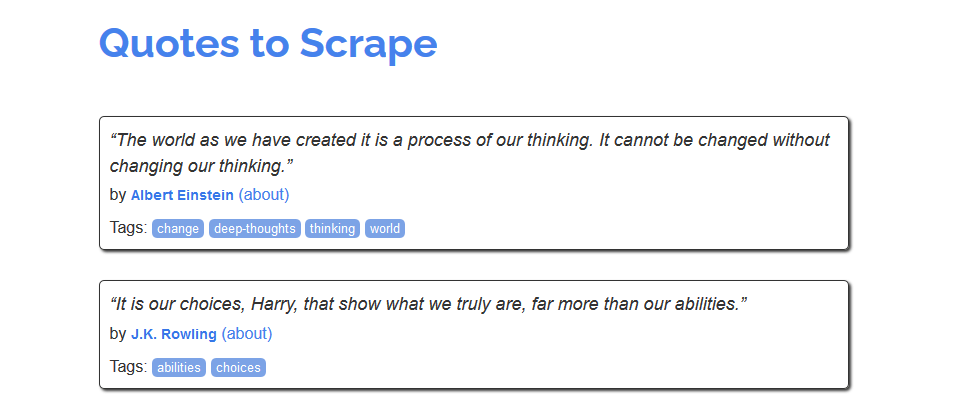
Для знакомства с процессом скрапинга можно воспользоваться сайтом https://quotes.toscrape.com/, который, похоже, был создан для этих целей.
Обучение парсингу на Python #1 | Парсинг сайтов | Разбираем методы библиотеки Beautifulsoup
Из него можно было бы создать, например, хранилище имен авторов, тегов или самих цитат. Но как это сделать? Сперва нужно изучить исходный код страницы. Это те данные, которые возвращаются в ответ на запрос. В современных браузерах этот код можно посмотреть, кликнув правой кнопкой на странице и нажав «Просмотр кода страницы».

На экране будет выведена сырая HTML-разметка страница. Например, такая:
Источник: pythonru.com
Как написать программу для парсинга

Парсинг полученных данных
Извлечь адрес ссылки можно 4 разными способами – с помощью:
- Методов строк.
- Регулярного выражения.
- Запроса XPath.
- Обработки BeautifulSoup.
Рассмотрим все эти способы по порядку.
Методы строк
Это самый трудоемкий способ – для извлечения каждого элемента нужно определить 2 индекса – начало и конец вхождения. При этом к индексу вхождения надо добавить длину стартового фрагмента:
Умение парсить на Python — изменит твою жизнь
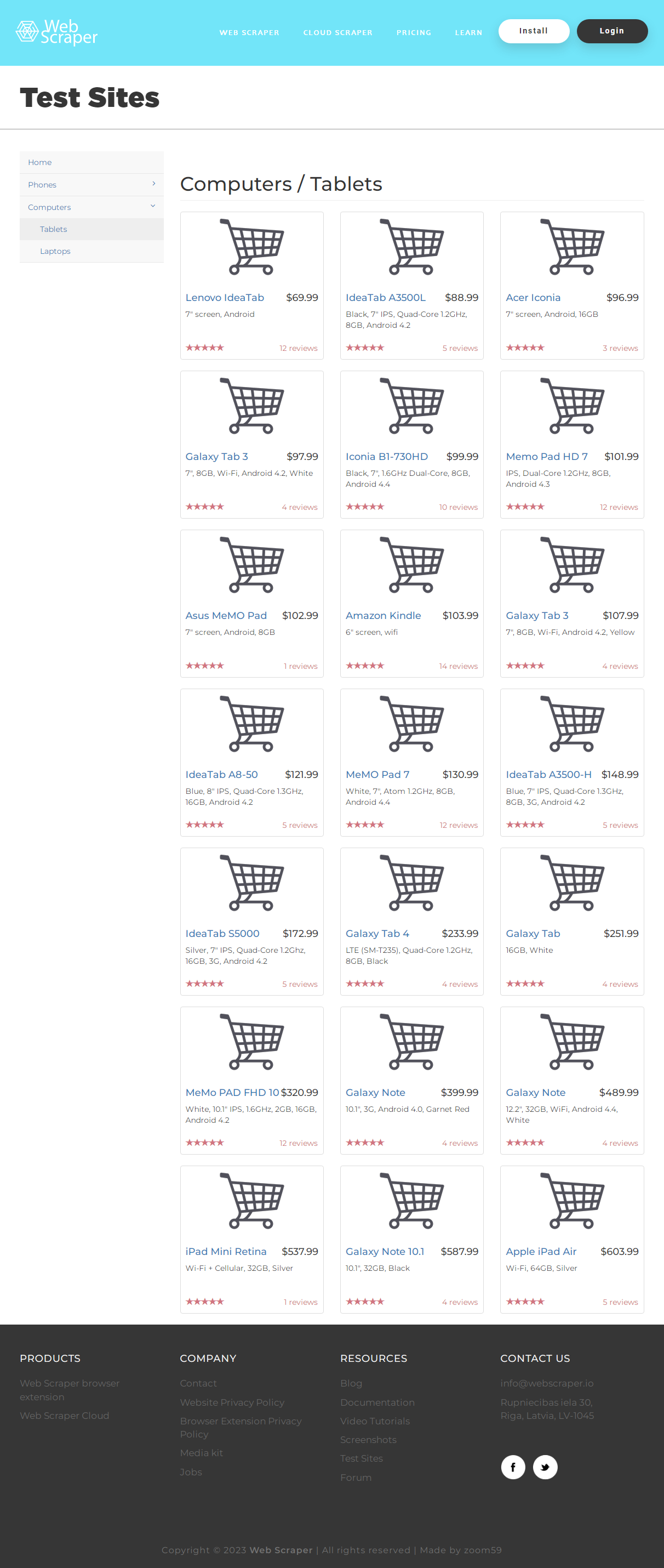
Пока страница не прокручена, полный HTML -код с информацией о планшетах получить невозможно. Для имитации прокрутки мы воспользуемся скриптом ‘window.scrollTo(0, document.body.scrollHeight);’ . Цены планшетов находятся в тегах h 4 класса pull-right price, а названия моделей – в тексте ссылок a класса title. Готовый код выглядит так :
Пример результата:
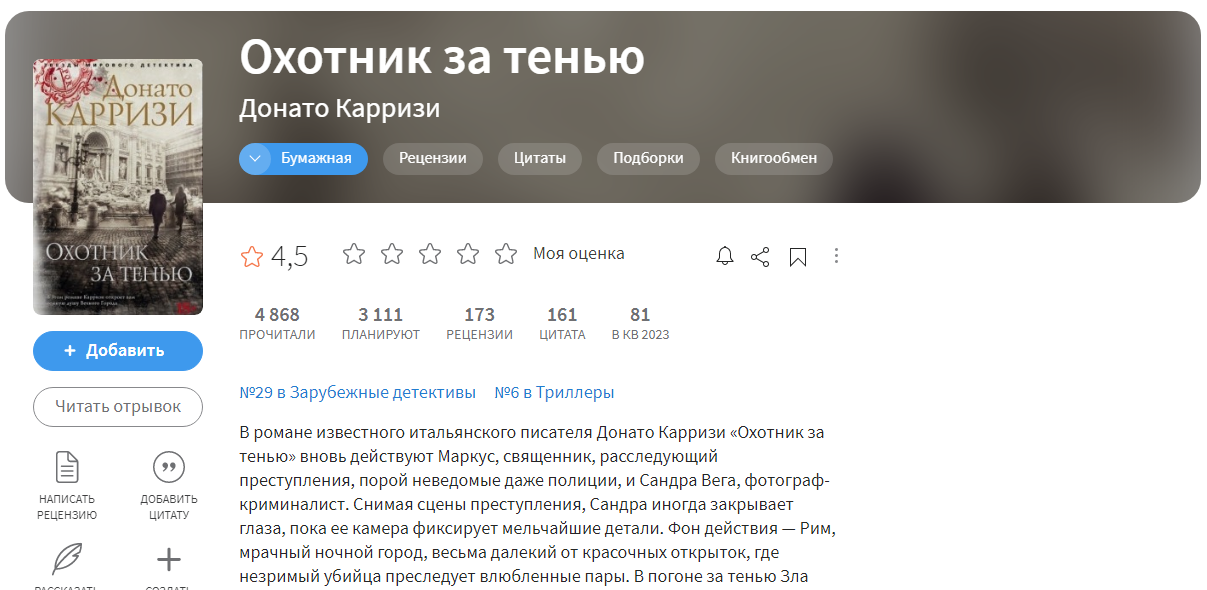
from bs4 import BeautifulSoup import requests import re url = ‘https://www.livelib.ru/book/1002978643-ohotnik-za-tenyu-donato-karrizi’ headers = res = requests.get(url, headers=headers) soup = BeautifulSoup(res.text,’html.parser’) sp = soup.find(‘div’, class_=’bc-menu__image-wrapper’) img_url = re.findall(r'(?:https:)?//.*.(?:jpeg)’, str(sp))[0] response = requests.get(img_url, headers=headers) if response.status_code == 200: file_name = url.split(‘-‘, 1)[1] with open(file_name + ‘.jpeg’, ‘wb’) as file: file.write(response.content)
Задание 6
Напишите программу, которая составляет рейтинг топ-100 лучших триллеров на основе этого списка.
Пример результата:
1. «Побег из Шоушенка», Стивен Кинг — 4.60 2. «Заживо в темноте», Майк Омер — 4.50 3. «Молчание ягнят», Томас Харрис — 4.47 4. «Девушка с татуировкой дракона», Стиг Ларссон — 4.42 5. «Внутри убийцы», Майк Омер — 4.38 . 98. «Абсолютная память», Дэвид Болдаччи — 4.22 99. «Сломанные девочки», Симона Сент-Джеймс — 4.11 100. «Цифровая крепость», Дэн Браун — 3.98
from bs4 import BeautifulSoup import requests url = ‘https://www.livelib.ru/genre/%D0%A2%D1%80%D0%B8%D0%BB%D0%BB%D0%B5%D1%80%D1%8B/top’ headers = res = requests.get(url, headers=headers) soup = BeautifulSoup(res.content,’html.parser’) titles = soup.find_all(‘a’, class_=’brow-book-name with-cycle’) authors = soup.find_all(‘a’, class_=’brow-book-author’) rating = soup.find_all(‘span’, class_=’rating-value stars-color-orange’) i = 1 for t, a, r in zip(titles, authors, rating): print(f’. «», — ‘) i += 1
Задание 7
Напишите программу, которая составляет топ-20 языков программирования на основе рейтинга популярности TIOBE .
Пример результата:
1. Python: 14.83% 2. C: 14.73% 3. Java: 13.56% 4. C++: 13.29% 5. C#: 7.17% 6. Visual Basic: 4.75% 7. JavaScript: 2.17% 8. SQL: 1.95% 9. PHP: 1.61% 10. Go: 1.24% 11. Assembly language: 1.11% 12. MATLAB: 1.08% 13.
Delphi/Object Pascal: 1.06% 14. Scratch: 1.00% 15. Classic Visual Basic: 0.98% 16. R: 0.93% 17. Fortran: 0.79% 18. Ruby: 0.76% 19. Rust: 0.73% 20.
Swift: 0.71%
Задание 8
Напишите программу для получения рейтинга 250 лучших фильмов по версии IMDb. Названия должны быть на русском языке.
Пример результата:
1. Побег из Шоушенка, (1994), 9,2 2. Крестный отец, (1972), 9,2 3. Темный рыцарь, (2008), 9,0 . 248. Аладдин, (1992), 8,0 249. Ганди, (1982), 8,0 250. Танцующий с волками, (1990), 8,0
Задание 9
Напишите программу, которая сохраняет в текстовый файл данные о фэнтези фильмах с 10 первых страниц соответствующего раздела IMDb . Если у фильма/сериала еще нет рейтинга, следует указать N / A .
Ожидаемый результат в файле fantasy . txt – 500 записей:
Мандалорец, (2019– ), 8,7 Всё везде и сразу, (2022), 8,0 Атака титанов, (2013–2023), 9,0 Peter Pan https://proglib.io/p/samouchitel-po-python-dlya-nachinayushchih-chast-17-osnovy-skrapinga-i-parsinga-2023-03-13″ target=»_blank»]proglib.io[/mask_link]