
От автора Telegram-канала Аналитика и Growth mind-set (делюсь кейсами с работы, бесплатным обучением, задачами с собеседований).
471 просмотров
Я уверена, что даже полный новичок в Python сможет сделать простой анализ уже через 2 недели. Анализ данных на Python — это не миллионы строк кода, многие манипуляции с данными — это всего лишь одна или несколько строчек.
Вот некоторые мысли из моего опыта.
1) ИЗУЧИТЕ ОСНОВЫ PYTHON (СИНТАКСИС).
Однако тут может возникнуть проблема — вы неделями и месяцами изучаете синтаксис, но при этом до сих пор не понимаете, как делать анализ данных с помощью Python.
На старте я изучала бесплатный курс Python в 2х частях (Часть 1 и Часть 2 на Stepik. Хороший курс? Да. Но изучать его довольно долго. Заявлено 40 + 64 часа, но выходит гораздо больше. Некоторые задачи можно решать по несколько часов, а задач только в Части 1 более 150).
Ну и если уделять даже 2 часа в день 5 дней в неделю, обучение все равно растянется на несколько месяцев, а то и полгода. А за это время вы так и не поймете, как делать анализ данных с помощью Python.
Python на практике / Пишем 3 программы на Питон за 5 минут
Синтаксис знать важно, но также важно не утонуть в нем. На мой взгляд, начать лучше с более короткого курса и быстрее перейти к изучению библиотек для анализа данных и практике. А к синтаксису вы так или иначе будете возвращаться и углубляться в него по мере практики.
Например, есть 2 коротких бесплатных курса от Kaggle по синтаксису: Введение в программирование с Python и Python. Но можно брать и другие.
2) ИЗУЧИТЕ БИБЛИОТЕКИ ДЛЯ АНАЛИЗА ДАННЫХ.
Именно изучая библиотеки вы и поймете, как делать анализ данных с Python. Библиотеки — это наборы шаблонов кода для каждой конкретной ситуации. Знакомиться с библиотеками лучше всего выполняя реальный проект по анализу данных.
Начните с Pandas — это основная библиотека для работы с данными. С помощью нее можно очищать и подготавливать данные, делать анализ, визуализировать и др.
А если вы уже знаете Excel или SQL, то вам будет еще проще освоить эту библиотеку: Pandas имеет схожие функции и может принимать различные типы данных. На официальном сайте Pandas даже есть туториалы, где функции Pandas приводятся в сравнении с Excel или SQL.
Освоив азы Pandas, вам будет легко понять Numpy, Matplotlib, Seaborn и другие библиотеки для анализа данных.
Например, вот краткий бесплатный курс по визуализации данных в Python от Kaggle (а именно используются библиотеки Seaborn и Matplotlib).
3) НАЧНИТЕ ПРАКТИЧЕСКИЙ ПРОЕКТ ПО АНАЛИЗУ ДАННЫХ С ПЕРВЫХ ДНЕЙ
Обучение на практике — лучший способ научиться программировать. Да, это вызов и выход из зоны комфорта, но так вы научитесь гораздо быстрее. После короткого курса синтаксиса уже можно переходить к реальному проекту, в процессе изучая библиотеки.
Поначалу можете подсмотреть, как выглядят проекты по анализу данных у других (например, на Medium много таких проектов). Также примеры проектов анализа данных с помощью Python и где взять данные писала тут.
Если в процессе сталкиваетесь с ошибками, то в помощь Google и Stackoverflow.
4) ЧТОБЫ ПИСАТЬ КОД, НУЖНО НАСТРОИТЬ СРЕДУ РАЗРАБОТКИ.
Первый раз мне эта задача не показалась легкой, тк возникали ошибки, которые я достаточно долго исправляла.
Поэтому с первых дней можно начать с облачных сред разработки, в которых можно писать код сразу без настройки. Например, Google Collab или Kaggle Notebook. А в последствии установите среду разработки, например PyCharm, VScode или другую.
Подписывайтесь на мой канал Аналитика и Growth mind-set, там публикую больше интересного. Вот некоторые посты:
Источник: vc.ru
Введение в анализ данных на Python для начинающих

Наука данных является обширной областью исследования с большим количеством областей, из которых анализ данных является неоспоримо один из наиболее важных из всех этих областей, и независимо от своего уровня мастерства в науке данных, она становится все более важной для понимания.
Если вы новичок в Python, советуем прочитать книги по языку программирования Python
Что такое анализ данных?
Анализ данных — это обработка и преобразование большого количества неструктурированных или неорганизованных данных с целью генерирования ключевой информации об этих данных, которые могли бы помочь в принятии обоснованных решений.
Существуют различные инструменты, используемые для анализа данных, Python, Microsoft Excel, Tableau, SaS и т.Д., Но в этой статье мы сосредоточимся на том, как анализ данных выполняется в python. Более конкретно, как это делается с библиотекой Python под названием Pandas.
Что такое Pandas?
Pandas — это библиотека Python с открытым исходным кодом, используемая для манипулирования данными. Это быстрая и высокоэффективная библиотека с инструментами для загрузки нескольких видов данных в память. Его можно использовать для изменения формы, маркировки среза, индексации или даже группировки нескольких форм данных.
Структуры данных в Pandas
В Pandas есть 3 структуры данных, а именно:
Лучший способ различить три из них — это видеть, что один содержит несколько стеков другого. Итак, DataFrame — это стек Series, а Panel — это стек DataFrame.
Series — это одномерный массив.
Стек из нескольких Series составляет двухмерный DataFrame
Стек из нескольких DataFrames образует трехмерный Panel
Структура данных, с которой мы будем работать больше всего, — это двухмерный DataFrame, который также может быть средством представления по умолчанию для некоторых наборов данных, с которыми мы можем столкнуться.
Анализ данных в Pandas
Для этой статьи какие-либо установки не требуются. Мы будем использовать инструмент под названием colaboratory, созданный Google. Это онлайн среда Python для анализа данных, машинного обучения и искусственного интеллекта. Это просто облачный Jupyter Notebook, который поставляется с предустановленным почти каждым пакетом Python, который вам понадобится как специалист по данным.
Теперь перейдите на сайт https://colab.research.google.com/notebooks/intro.ipynb. Вы должны увидеть картинку ниже.
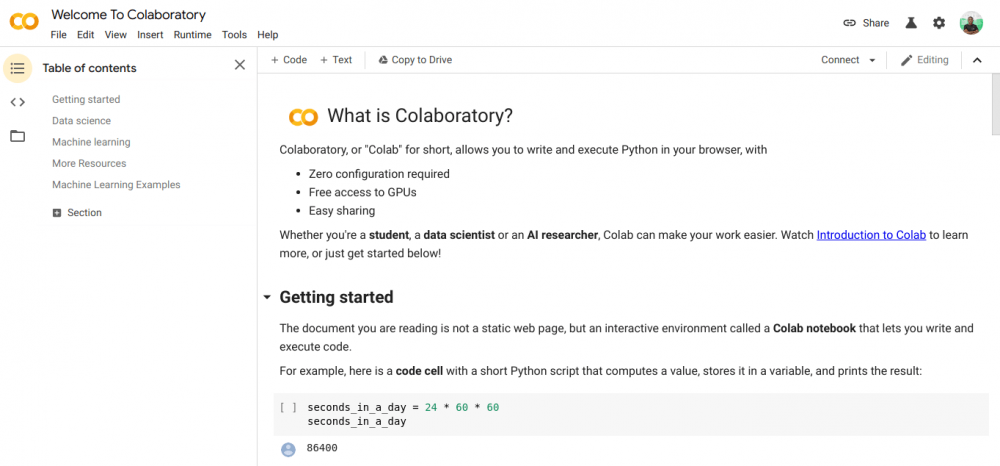
В левом верхнем углу, выберите опцию «File» и нажмите «New notebook». Вы увидите новую страницу записной книжки Jupyter, загруженную в ваш браузер. Первое, что нам нужно сделать, это импортировать Pandas в нашу рабочую среду. Мы можем сделать это, с помощью строки:
import pandas as pd
Для этой статьи мы будем использовать набор данных о ценах на жилье для нашего анализа данных. Набор данных, который мы будем использовать, можно найти здесь. Первое, что мы хотели бы сделать, это загрузить этот набор данных в нашу среду.
Источник: itgap.ru
Как создать веб-приложение для анализа данных на Python
В этой статье я покажу вам, как можно быстро создать простое веб-приложение, управляемое данными, с помощью библиотеки Python streamlit всего в несколько строк кода.
Как специалисту по анализу данных или инженеру по машинному обучению важно иметь возможность развернуть наш проект по науке о данных. Традиционное развертывание моделей машинного обучения с установленной структурой, такой как Django или Flask, может быть сложной и / или трудоемкой задачей.
Эта статья основана на YouTube-видео, которое я сделал по той же теме (Как создать свое первое веб-приложение для анализа данных на Python), и вы можете просмотреть его одновременно с прочтением этой статьи.
Обзор готового веб-приложения
Сегодня мы создадим простое веб-приложение, которое отображает курс и объем акций. Это потребует использования двух библиотек Python, а именно streamlit и yfinance . По сути, приложение будет извлекать исторические рыночные данные из Yahoo! Финансы из библиотеки yfinance . Эти данные сохраняются во фрейме данных, и streamlit будет использовать эти данные в качестве входного аргумента для отображения их в виде линейной диаграммы.
Установите необходимые библиотеки
В этом руководстве мы будем использовать две библиотеки Python, требующие установки. К ним относятся streamlit и yfinance . Вы можете легко сделать это с помощью команды pip install , чтобы установить streamlit :
pip install streamlit
И проделайте то же самое для yfinance следующим образом:
pip install yfinance
Код веб-приложения
Давайте посмотрим на код веб-приложения, которое мы создаем сегодня. Вы увидите, что меньше 20 строк кода (т.е., если не считать комментарии, это сокращает его до 14 строк кода, где 3 из этих строк являются пустыми строками для эстетических целей).
Построчное объяснение кода
Давайте потратим время, чтобы разобраться в приведенном выше коде.
- Строки 1 и 2
: импорт yfinance и присвоение ему псевдонима yf , а также импорт streamlit и присвоение ему псевдонима st . - Строки 4–7
Использует функцию st.write() для печати текста. Этот распечатанный текст написан в формате уценки. - Строки 9–16
Использует yfinance библиотеку для получения исторических данных о рынке из Yahoo! Финансы.
* Строка 11 — определяет символ тикера как GOOGL .
* Строка 13 — создает переменную tickerData с помощью функции yf.Ticker() , которая в качестве name imply позволяет получить доступ к данным тикера. Следует отметить, что tickerData является объектом Ticker, и если мы запустим tickerData как команду, мы получим следующий результат yfinance.Ticker object .
* Строка 15 — Создает tickerDf dataframe и определяет диапазон дат (с 31 мая 2010 г. по 31 мая 2020 г.) и период времени (1 день).

- Строки 18 и 19
Использует функцию st.line_chart() для построения линейного графика (с использованием цены закрытия из Close и Столбцы объема из tickerDf фрейма данных, как определено в строке 15.
Запуск веб-приложения
После сохранения кода в файл с именем myapp.py запустите командную строку (или Power Shell в Microsoft Windows) и выполните следующую команду:
streamlit run myapp.py
Далее мы должны увидеть следующее сообщение:
> streamlit run myapp.py You can now view your Streamlit app in your browser. Local URL: http://localhost:8501 Network URL: http://10.0.0.11:8501
Через некоторое время должно появиться окно интернет-браузера, которое направит вас к созданному веб-приложению, переведя вас на http://localhost:8501 , как показано ниже.

Поздравляю! Вы создали свое первое веб-приложение на Python!
Настройка веб-приложения
Хорошо, вы, вероятно, захотите немного оживить ситуацию и настроить веб-приложение.
Давайте потратим время, чтобы разобраться в приведенном выше коде.
- Строка 6
Обратите внимание, что мы выделили «цену закрытия» жирным шрифтом, используя две звездочки перед и после фразы: **closing price** . Также обратите внимание, что мы сделали слово «объем» как жирным, так и курсивом, используя три звездочки перед и после слова следующим образом: ***volume*** . - Строки 18–20 и 22–25
Здесь мы добавили заголовки заголовков в формате уценки прямо перед ценой закрытия и объем участков.

Вуаля!
И теперь у нас есть обновленное веб-приложение, которое должно автоматически обновляться прямо у вас на глазах.
Подпишитесь на мой список рассылки, чтобы получать мои лучшие обновления (а иногда и бесплатные) в Data Science!
Обо мне
Я работаю полный рабочий день адъюнкт-профессором биоинформатики и руководителем отдела интеллектуального анализа данных и биомедицинской информатики в исследовательском университете в Таиланде. В нерабочее время я ютубер (он же профессор данных), снимаю онлайн-видео о науке о данных. Во всех обучающих видео, которые я делаю, я также размещаю записные книжки Jupyter на GitHub (страница Data Professor GitHub).
Источник: digitrain.ru