
Меня зовут Котов Илья, я Data Scientist и участник профессионального сообщества NTA.
В предложенной работе, на примере задачи поиска логических ошибок робота, я продемонстрирую, как методы тематического моделирования помогут исследователя при работе с большим объемом текстовых данных.
Задача тематического моделирования возникает очень часто, когда существует необходимость в обработке большого количества текстовой информации. Тематическое моделирование – это разбиение коллекции текстовых документов на группы, в которых элементы имеют общую тематику. Стоит понимать, что один документ может иметь разные темы, в таком случае документ определяется распределением тематик, однако для нашей задачи крайне необходимо, чтобы документ однозначно принадлежал определенной группе. Использование метода предполагает то, что никаких дополнительных данных, кроме самого текста не используется.
Способов применения тематического моделирования в реальных задачах множество. Например, вы можете автоматически определять тематику письма в электронной почте, а после ранжировать его. В задаче информационного поиска тематическое моделирование позволяет более качественно отбирать информацию по текстовому запросу. Исследователям, которые работают с текстовой информацией просто необходим инструмент, который может структурировать объемные текстовые массивы. Интересно и то, что предметом исследования может быть не только человеческий язык, но и любые текстоподобные данные: программный код, банковские транзакции, музыкальные произведения.
Синтаксические и логические ошибки в коде 1С: как находить и исправлять
Для начала четко обозначу задачу – это улучшение процесса дистанционного взыскания.
Необходимо найти все диалоги, в которых робот совершает логическую ошибку следующего вида:
Бот задает вопрос о том, закроет ли клиент долг => клиент отвечает отрицательно или неопределенно => бот считает, что ответ положительный и фиксирует это.
Что я подразумеваю под диалогом скажу чуть позже.
Рассмотрим примерный шаблон, по которому бот ведет беседу с клиентом.
- Приветствие и информирование о том, что разговор будет записан.
- Идентификация клиента.
- Информирование о задолженности.
- Прощание.
Соответственно, в процессе возможны различные варианты развития диалога, например, клиент не прошел идентификацию, занят, лежит в больнице, не может найти работу и так далее. Проблема в том, что возможных исходов и вариаций ответа неимоверное множество и довольно сложно их структурировать.
Фрагмент диалога, в котором клиент не прошел идентификацию.

Фрагмент диалога, в котором клиент не готов к диалогу.

Как уже было сказано, эту задачу я буду решать с помощью методов тематического моделирования.
Обзорный план моего решения:
3 Синтаксические и логические ошибки в коде
- Собрать и обработать все ответы клиентов на вопрос о задолженности.
- Разбить ответы клиентов на группы. Этот пункт является скорее подзадачей, которая облегчит разметку. Обзорный осмотр 200 кластеров быстрее, чем просмотр всей коллекции диалогов, которых около 1 000 000.
- Разметить эти кластеры вручную, там, где клиент без сомнений говорит о том, что он заплатит или уже заплатил = 1, во всех остальных случаях = 0 (включая неопределенности: *не знаю*, *когда придет зарплата*, *наверное завтра* и так далее).
- Если у ответа стоит отметка 0 и при этом бот ведет себя также, как и при 1(то есть думает, что клиент ответил утвердительно), то этот случай я буду считать логической ошибкой и направлять аналитику для дальнейшего осмотра.
Сбор и обработка ответов клиентов
Диалог в рамках данной работы – это отсортированная по времени таблица, у которой есть 2 поля и свой собственный id.
speaker – кто произнес цитату (робот или клиент).
sent – цитата.

Всего таких диалогов около 1 000 000.
Для начала рассмотрю только те диалоги, в которых бот дошел до вопроса об оплате и отберу ответы клиентов. В моем понимании ответом клиента будет цитата, которая идет после вопроса робота. Соберу все ответы в одну коллекцию.
#список вопросов об оплате robot_questions = [ ‘ВНЕСЕТЕ ПЛАТЕЖ?’ ‘ОПЛАТА ПОСТУПИТ ЗАВТРА?’, ‘ВЫ ГОТОВЫ ПРОИЗВЕСТИ ОПЛАТУ ЗАВТРА?’, ‘ВЫ ГОТОВЫ ОПЛАТИТЬ ЕЁ ЗАВТРА?’, ‘ВЫ ГОТОВЫ ОПЛАТИТЬ ЭТУ СУММУ?’, ‘ВО ИЗБЕЖАНИЕ НЕГАТИВНЫХ ПОСЛЕДСТВИЙ, ВЫ ГОТОВЫ ПРОИЗВЕСТИ ОПЛАТУ ЗАВТРА?’ ] #ответы клиентов client_answers = [] #номера таблиц в которых отсутствует вопрос или их по какой-то причине более 1, #пока для простоты не будем рассматривать эти случаи. black_indexes = [] #идем по каждому диалогу и отбираем только те, в которых бот 1 раз задает вопрос из списка, #далее забираем ответы клиента. for table_index, table in enumerate(data): search_robot_questions = table.loc[((table[‘sent’].isin(robot_questions)) str: return ‘ ‘.join([MORPH_ANALYZER.normal_forms(word)[0] for word in tokenize(sent.lower())]) simple_preprocessing(‘МОЖНО ПАРУ ДНЕЙ ДАЙТЕ МНЕ ЕЩЁ ПОЖАЛУЙСТА Я ПРОСТО С РЕБЁНКОМ ВЫЕХАТЬ НЕ МОГУ’) >>> ‘можно пара день дать я ещё пожалуйста я просто с ребёнок выехать не мочь’
Теперь необходимо векторизовать ответы клиентов, с дальнейшей обработки с помощью методов машинного обучения.
Для векторизации я буду использовать меру TF-IDF. Мера TF-IDF эффективна для выделения ключевых слов в тексте, это мне и нужно. Цитаты клиентов достаточно короткие, поэтому можно найти слово или несколько слов, которые могут полностью характеризовать всю цитату.
У TF-IDF есть свои преимущества, если сравнивать ее с другими способами векторизации текста:
- Легкая интерпретация.
- Простота.
- Регулирование параметров.
Подробнее о TF-IDF можно прочитать тут.
#предобработка текста preproc_data = [simple_preprocessing(item) for item in client_answers] #векторизация vectorizer = CountVectorizer() vectorizer_corpus = vectorizer.fit_transform(preproc_data) tfidf = tfidf_t() vectors = tfidf.fit_transform(vectorizer_corpus)
Теперь можно использовать алгоритм кластеризации. Я буду использовать DBSCAN. Главное преимущество DBSCAN – это устойчивость к шуму и возможность работы с данными, которые имеют нетипичную форму, однако алгоритм имеет квадратичную сложность, что может привести к долгой работе при больших объемах.
Конфигурация модели
Чтобы подобрать оптимальный параметр eps, вы можете использовать информацию из этого источника, тем самым вы можете улучшить качество ваших кластеров.
Пока для простоты возьму значение eps = (0.1, 0.3, 0.5, 0.7, 1). Чем меньше eps – тем больше объекты в кластере похожи друг на друга.
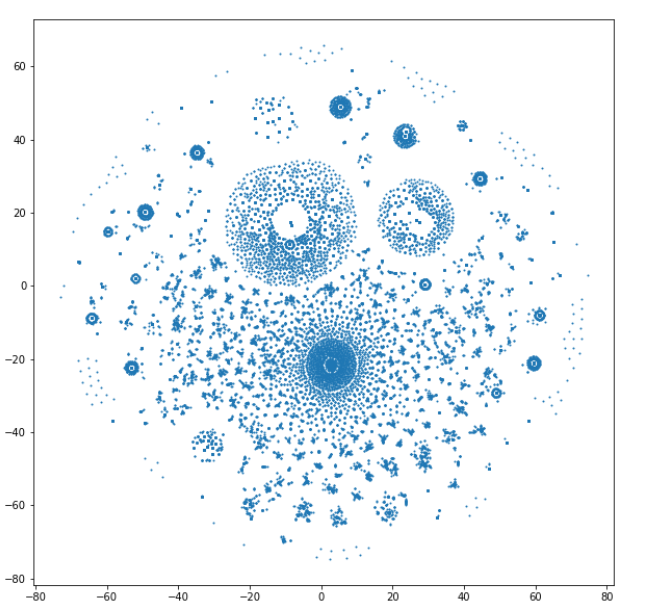
Для большей интерпретации и понимания, я пожертвую информацией и снижу размерность до двух компонент. Однако, жертвуя информативностью, мы получаем возможность визуализировать полученные двумерные вектора на плоскости. Чтобы понизить размерность и не потерять значительную часть информации, которая находится в ваших векторах, вы можете использовать, например, сингулярные значения и правило локтя, подробнее можно посмотреть тут.
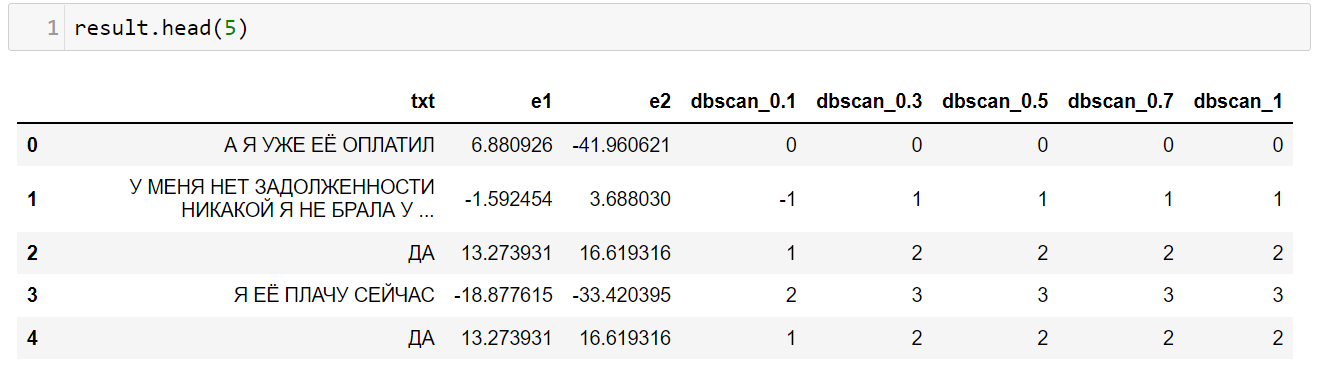
В коде, который представлен ниже, я создаю таблицу с метками кластеров, которые соответствуют определенному параметру eps (0.1, 0.3, 0.5, 0.7, 1).
import seaborn as sns from sklearn.manifold import TSNE from sklearn.cluster import DBSCAN low_vectors_tsne = TSNE(n_components=2).fit_transform(vectors.toarray()) result = pd.DataFrame() result[‘txt’] = client_answers result[‘e1’] = low_vectors_tsne[:, 0] result[‘e2′] = low_vectors_tsne[:, 1] for eps in [0.1, 0.3, 0.5, 0.7, 1]: result[f’dbscan_’] = DBSCAN(eps=eps, min_samples=2).fit(low_vectors_tsne).labels_
Результат работы кода:
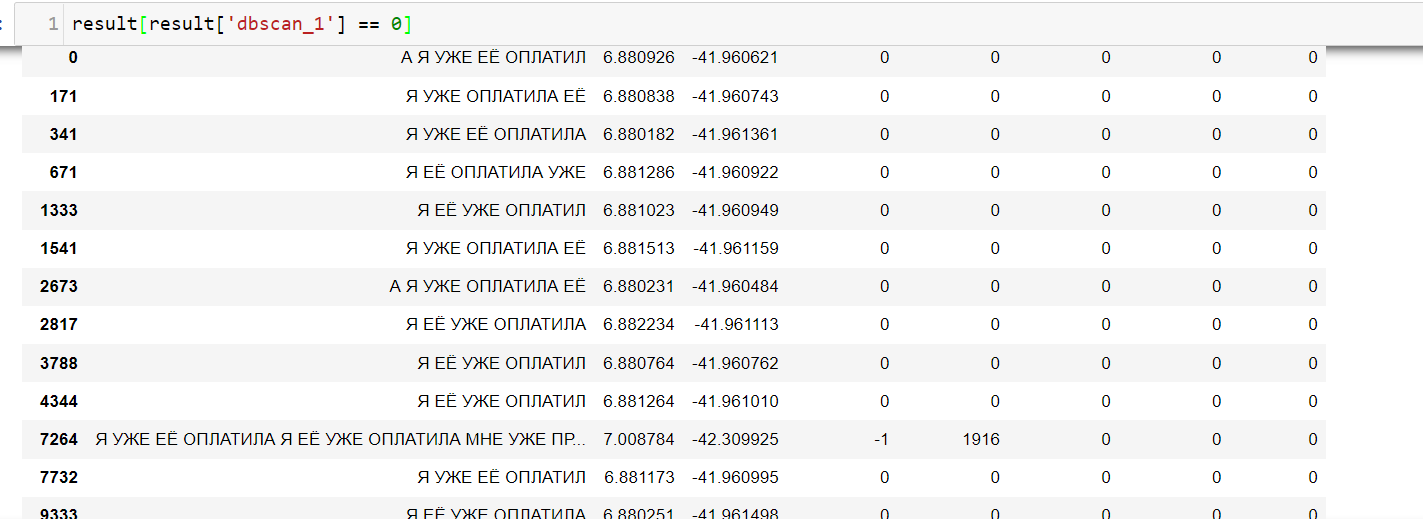
Посмотрю на результаты и сделаю выборку значений, у которых поле ‘dbscan_1’ = 0 (то есть это все цитаты нулевого класса, при eps = 1).
Теперь посмотрю, например, 5 класс.
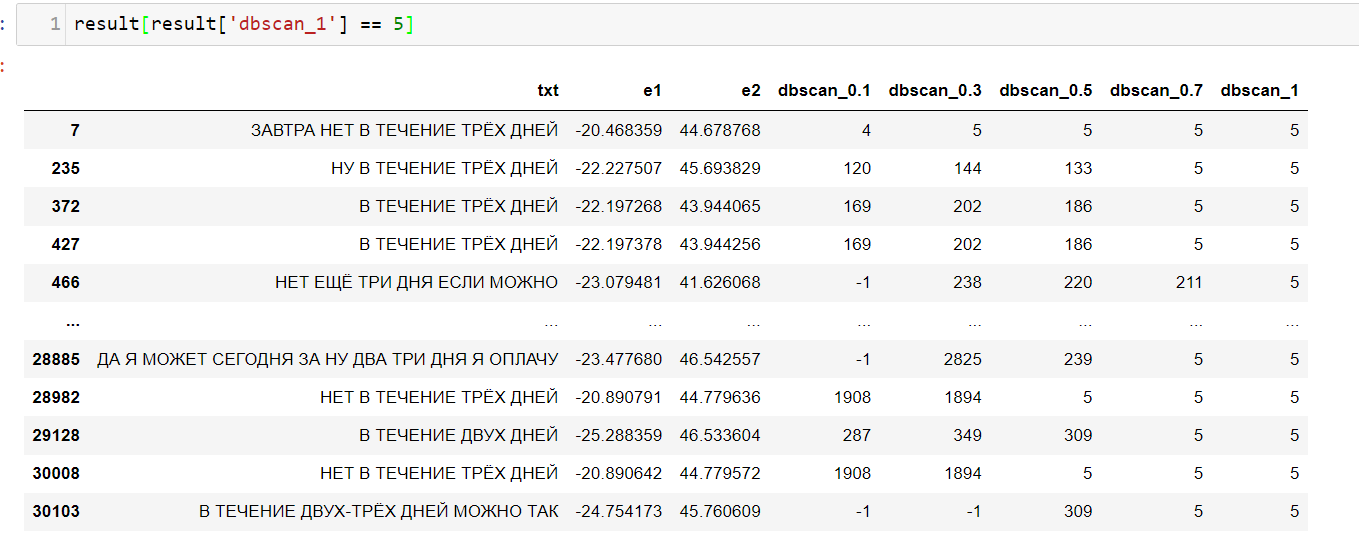
Можно заметить, что цитаты схожи между собой и вполне интерпретируемы, этого я и добивался.
Визуализирую данные (eps=1).
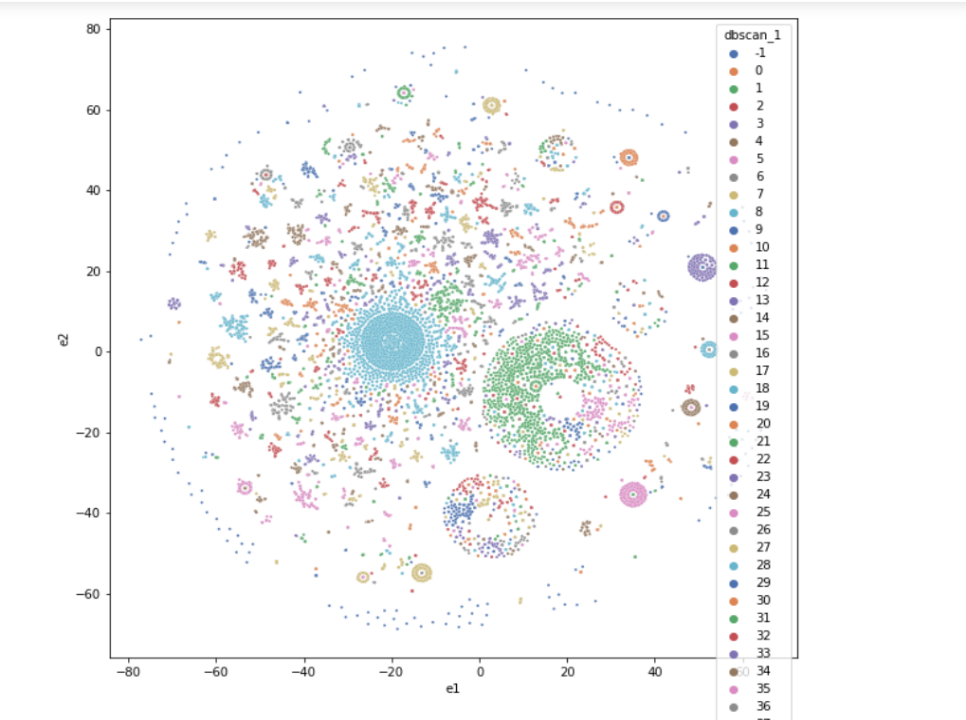
Разметка кластеров и отбор кандидатов на ошибку
Получилось более 200 кластеров, которые уже не так трудно разметить вручную, в отличии от 1 000 000 диалогов. Это и была главная цель структурирования. Размечу полученные классы метками 0 или 1.
После разметки остается лишь задать правило, по которому я буду выявлять ошибки робота. Если стоит метка 0 и при этом робот произносит фразы, характерные метке 1, то этот диалог является кандидатом на ошибку.
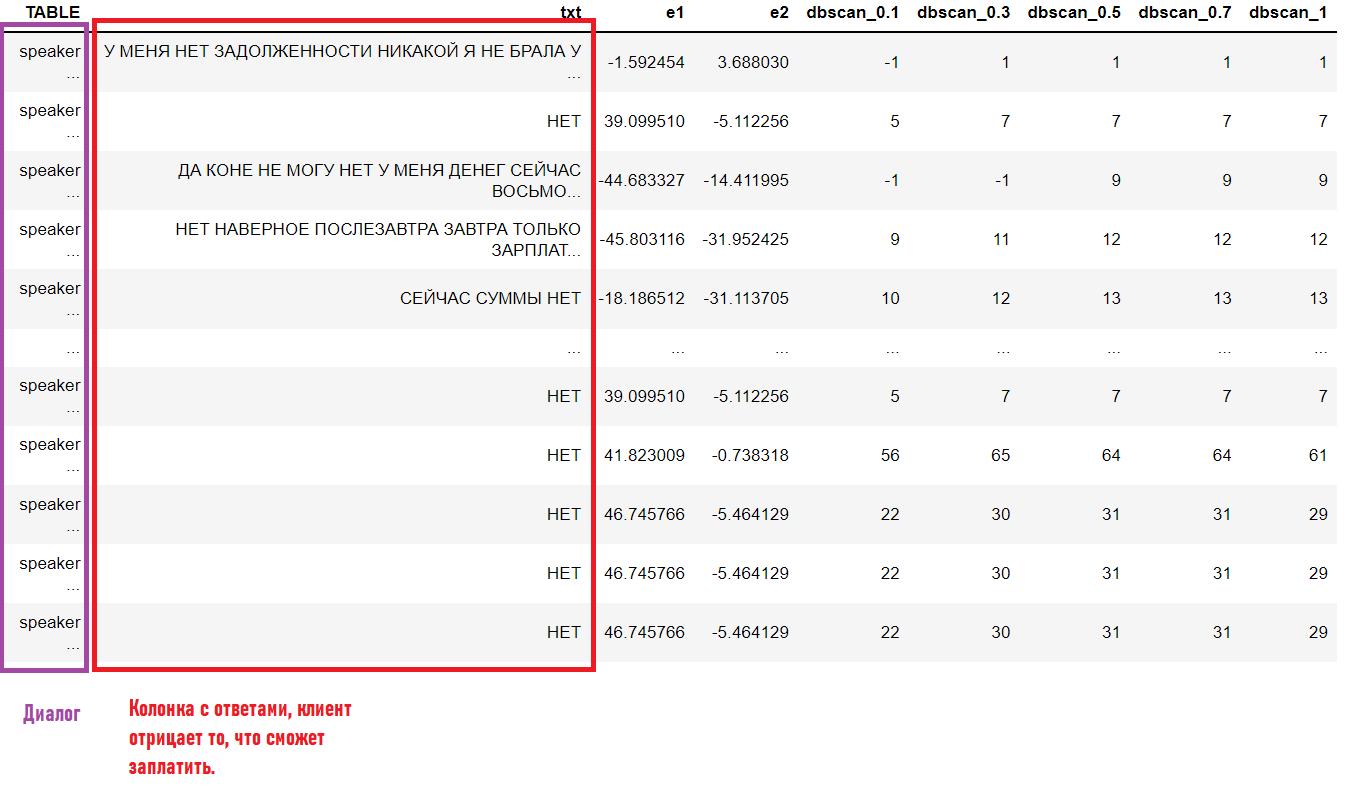
Отберу те строки, у которых в колонке с диалогами робот говорит:
‘ Я ФИКСИРУЮ ВАШЕ ОБЕЩАНИЕ ОБ ОПЛАТЕ’ хотя бы 1 раз.
То есть данная строка содержится в данном диалоге один или более раз.
candidate = [] for dialog in negative_answer[‘TABLE’].to_list(): if dialog[dialog[‘sent’] == ‘Я ФИКСИРУЮ ВАШЕ ОБЕЩАНИЕ ОБ ОПЛАТЕ’].shape[0] > 0: candidate.append(dialog)
На выборку из 1 000 000 диалогов получилось 419 диалогов – кандидатов на ошибку. Полученных кандидатов я передаю аналитику для более глубокого анализа.
Подведу итоги
В этом материале я разобрал практический пример того, как можно использовать методы тематического моделирования для решения задач обработки больших массивов текстовых данных.
Предложенный метод является далеко не единственным способом решения задачи, вы всегда можете изменять его части, использовать предобученые трансформеры для получения векторов или поменять алгоритм кластеризации, использовать LDA, LSI, иерархическую кластеризацию и так далее.
У этого метода есть и свои недостатки, в векторах отсутствуют семантические знания, то есть модель не видит семантических зависимостей между словами и не сможет ничего сказать о слове, которого нет в датасете. Однако главное его преимущество – это легкое восприятие, относительно не сложная математика и универсальность.
С полным кодом можно ознакомиться по ссылке.
- тематическое моделирование
- tf-idf
- dbscan
- чат-бот
- сезон machine learning
- Python
- Программирование
- Машинное обучение
- Natural Language Processing
Источник: habr.com
Отладка в visual studio. Поиск логических ошибок в программе
Как было показано в предыдущем разделе на примере программы, преобразующей массив целых чисел, приложение может собираться и работать, но не выполнять полностью того, что ему полагается делать. Это означает, что текст программы не соответствует спецификации поставленной задачи и содержит логическую ошибку, а возможно, сразу и несколько логических ошибок.
Из всех категорий ошибок логические ошибки найти наиболее трудно, так как они берут свое начало в ошибочном рассуждении при поиске решения задачи. Такие ошибки обнаруживаются на этапе выполнения программы и приводят к неверным результатам, к остановке или «зависанию» приложения. Это делает необходимым тестирование приложения с различными наборами данных. Только тщательное тестирование на самых разнообразных значениях данных может дать на практике гарантию того, что приложение не содержит логических ошибок.
Самым простым способом локализации логической ошибки является пошаговое прослеживание результатов выполнения всех операторов программы. При отладке приложения в VS можно отображать значения указанных переменных или выражений в любой точке программы.
Вычисленные значения можно, сравнивать с теми, что должны быть, и если обнаруживается несоответствие, то, логическая ошибка локализована.
Начало сеанса отладки
Первый шаг отладки приложения – это выбор команды Start Debugging (F5) на стандартной панели инструментов или в меню Debug, после чего приложение запускается в режиме отладки.
Перед началом отладки целесообразно определить то место в программе, где возможна ошибка. Это, как правило, позволяет существенно сократить время, затрачиваемое на поиски ошибки. В примере 2 ошибка может содержаться в том фрагменте программы, который изменяет значения элементов массива после их ввода с клавиатуры.
Установка точек останова
Для того чтобы отладчик прерывал выполнение программы на определенной строке, необходимо установить на этой строке точку останова. Точка останова – это просто место (например, строка с оператором программы), которое помечено для отладчика и отображается красным кружком в поле индикаторов (узкое поле серого цвета с левого края окна редактора кода). Когда отладчик встречает точку останова, то выполняющаяся программа моментально останавливается (до выполнения данной строки кода).
Установить точку останова на какой-либо строке кода можно при помощи щелчка по полю индикаторов данной строки (рис. 16). Либо можно установить курсор на нужной строке и нажать клавишу F9.

Рисунок 16. Установка точки останова
Просмотр данных в отладчике
Когда выполнение программы в сеансе отладки приостановлено (например, при помощи точки останова), можно изучить состояние и содержимое ее переменных и объектов. Для этого в VS можно использовать три вида окон: Local (Локальные), Autos (Видимые) и Watch (Контрольные).
Доступ к окнам можно получить нажав Debug->Windows->выбрать нужное окно(Рис. 17)
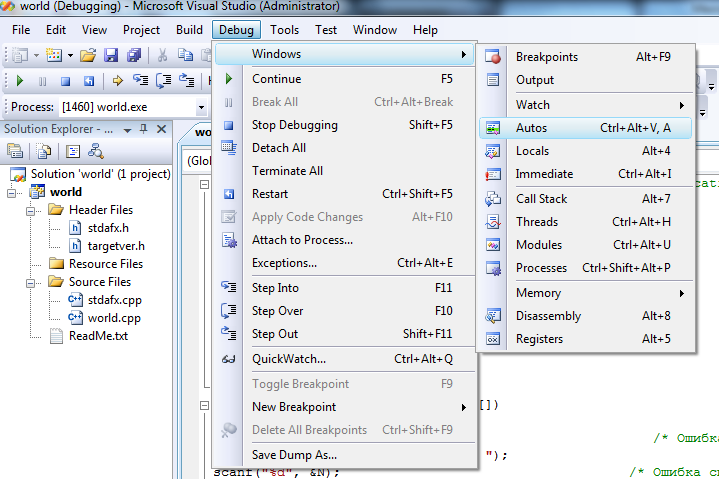
Рисунок 17. Доступ к окнам
Окно Local показывает все переменные и их значения для текущей области видимости отладчика. Это дает вам представление обо всем, что имеется в текущей выполняющейся функции. Переменные в этом окне организованы в список и автоматически настраиваются отладчиком. На рис. 18 показан пример окна Local.
С его помощью можно увидеть приложение нашего примера, которое приостановлено до обнуления соответствующих элементов массива. Обратите внимание, что объект (массив) a развернут для того, чтобы показать значения его элементов в момент остановки выполнения программы. По мере установки значений результаты будут отображаться в столбце Value.
Однако очень часто просмотр всех локальных переменных дает слишком много информации, чтобы в ней можно было разобраться. Так может происходить тогда, когда в области видимости данного процесса или функции находится слишком много операторов. Для того
чтобы увидеть значения, связанные с той строкой кода, на которую вы смотрите, можно использовать окно Autos. Это окно показывает значения всех переменных и выражений, имеющихся в текущей выполняющейся строке кода или в предыдущей строке кода. На рис. 19
показано окно Autos для той же самой строки кода, которая показана на рис. 18. Обратите внимание на разницу.
Окна Watch в VS позволяют настраивать собственный список переменных и выражений, за которыми нужно наблюдать (рис. 20). Окна Watch выглядят и ведут себя точно так же, как и окна Local и Autos. Кроме того, те элементы, которые вы размещаете в окнах Watch, сохраняются между сеансами отладки.
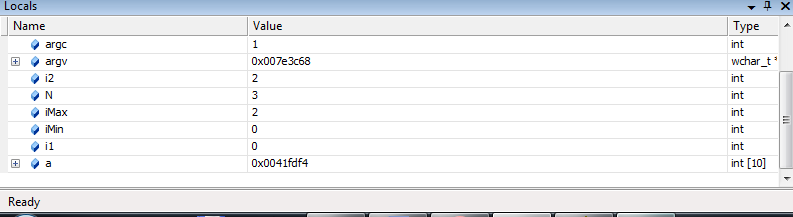
Рисунок 18. Окно Local
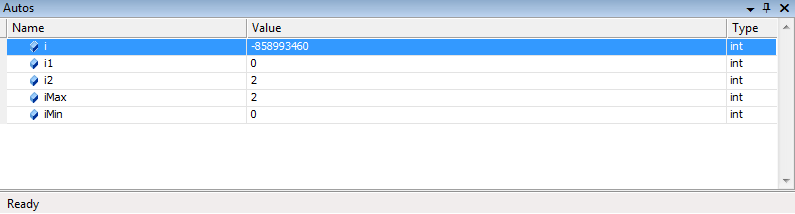
Рисунок 19. Окно Autos
Вы получаете доступ к окнам Watch из меню или панели инструментов Debug (рис. 17). Четыре окна Watch (которые называются Watch 1, Watch 2, Watch 3 и Watch 4) позволяют настроить четыре списка элементов, за которыми необходимо наблюдать. Эта возможность может быть особенно полезна в том случае, когда каждый список относится к отдельной области видимости вашего приложения.
Переменную или выражение в окно Watch 1 можно добавить из редактора кода. Для этого в редакторе кода выделите переменную (или выражение), щелкните по ней правой кнопкой мыши и выберите пункт Add Watch. При этом выделенная переменная (или выражение) будет помещена в окно Watch 1. Вы можете также перетащить выделенный элемент в это окно.
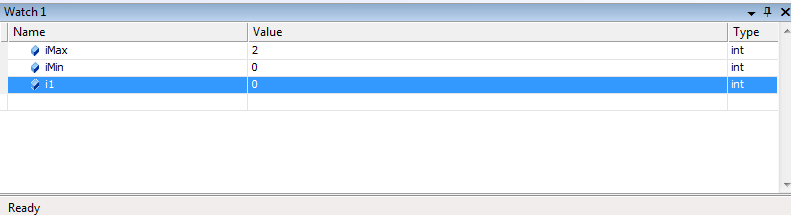
Рисунок 20. Окно Watch 1
Пошаговое прохождение для поиска ошибки
После того как в нашем примере отладчик, встретив точку останова, прервал выполнение программы, далее можно выполнять код по шагам (режим трассировки). Для этого можно выбрать команду Step into на панели инструментов Debug или нажать функциональную клавишу F11(Рис. 21).
Это приведет к последовательному выполнению кода по одной строке, что позволит вам видеть одновременно и ход выполнения приложения, и состояние объектов программы по мере выполнения кода. Команда Step into (F11) позволяет продвигаться по коду по одной строке. Вызов этой команды выполнит текущую строку кода и поместит курсор на следующую выполняемую строку. Важное различие между Step into и другими похожими командами состоит в
том, как Step into обрабатывает строки кода, в которых содержатся вызовы функций. Если вы находитесь на строке кода, которая вызывает другую функцию программы, то выполнение команды Step into перенесет вас на первую строку этой функции.
Если сделать так в нашем примере, то вы увидите ошибку: обнуление элементов массива должно начинаться не с элемента с индексом i1, а со следующего элемента i1+1.
Команда Step out (F10) позволяет вам сохранять фокус в текущей функции (не заходя в вызываемые ею подпрограммы), т. е. вызов Run out приведет к выполнению строки за строкой, но не заведет вас в вызовы функций и при этом следующей выполняемой
строкой для пошагового прохождения станет следующая за вызовом функции строка.
Рис 21. Команда Step Into
Одной из более удобных (и часто упускаемых) функциональных возможностей набора инструментов отладки является функция Run to cursor ( Выполнить до текущей позиции). Она работает в полном соответствии со своим названием. Вы устанавливаете курсор на некий код и вызываете эту команду.
Приложение компилируется и выполняется до тех пор, пока не доходит до той строки, где находится курсор. В этой точке отладчик прерывает приложение и выдает вам эту строку кода для пошагового прохождения. Рис. 22.
Рисунок 22. Вызов команды Run To Cursor
Продолжить отладку после точки останова можно повторным нажатием на кнопку F5 (Start Debugging).
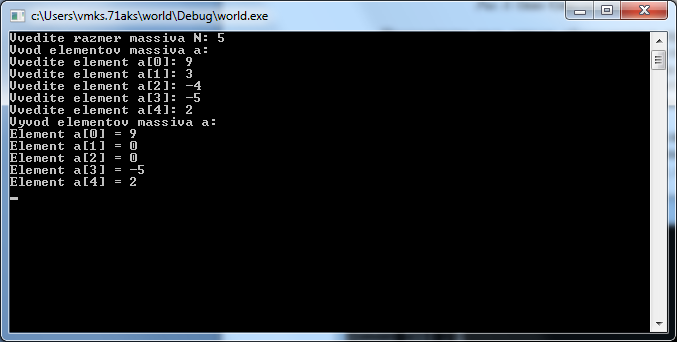
Рисунок 23. Результат работы программы после исправления ошибки
Рассмотрим пошаговое выполнение программы с использованием окна Watch на простейшем примере.
Пример.
int _tmain(int argc, _TCHAR* argv[])
Источник: studfile.net
Поиск и исправление логических ошибок в программе или коде HTML

Поиск и исправление ошибок в программе — это интересная и необычная задача. Некоторые ошибки найти и исправить несложно. А для других до сих пор конкретных алгоритмов не придумали, поэтому приходится ограничиться лишь обобщенными решениями, следовани е которым облегчит ваш поиск и сделает вашу программу функциональной и эффективной.
Поиск и исправление ошибок в программе
- Синтаксические — ошибки, которые допускаются в результате невнимательности программистов: неправильно выбран оператор, пропущена буква или символ, лишние буква, символ, оператор и т. п.
- Логические — ошибки, которые возникают от неправильного выполнения скрипта или части кода. Такие ошибки могут привести к критическим ситуациям, когда становится невозможн ой дальнейшая работа или модернизация программы. Как правило, эта категория ошибок очень трудно обнаруживается.
Синтаксические ошибки
- н аходите нужный валидатор,
- находите при помощи него синтаксические ошибки,
- исправляете ошибки.
Логические ошибки
- Всегда записывайте ошибку в блокнот или трекер. Как только заметили логическую ошибку в программе, нужно записать ее в трекер. Потому что вы не знаете , сколько уйдет времени и сил на поиск такой ошибки. А в процессе поиска может произойти все что угодно и вы просто можете забыть какие-то важные детали о самой ошибке.
- «Ок, Google!». Если вы нашли ошибку, то есть шанс, что она не уникальна и кто-то с ней уже сталкивался. А это значит, что вполне вероятно, что у кого-то уже есть решение этой проблемы. Поэтому попробуйте найти ее решение в сети.
- Ищите строку! Если поиск в сети не дал результатов, то запустите программу в отладчике и попробуйте найти строку кода, где возникает ошибка. Это , скорее всего , не решит проблему, но даст вам хоть какое-то представление о ней и позволит продолжить дальнейшие поиски.
- Найдите точную строку! Отладчик вам выдаст строку с багом, но , скорее всего , причина будет не в этой строке. Чаще всего причина возникает в данных, которые получила эта строка с багом. Поэтому нужно провести более тщательный анализ и найти причину и природу возникновения ошибки. Ошибки могут происходить по-разным причинам, поэтому это т процесс будет не самым простым и легким.
- Исключайте. Может так случиться, что сразу найти нужную строку кода не получится. В таком случае нужно выявить «проблемный» блок кода. Для этого нужно постепенно отключать компоненты программы, пока не будет выявлен «проблемный» компонент.
- Нужно исключить проблему в аппаратном обеспечении. Редкий случай, но бывает так, что проблема с «железом» вызывает ошибки с исследуемой программой. Можно обновить операционную систему, среду разработк и , заменить оперативную память и т. д.
- Ищите совпадения. Когда возникают ошибки в программе? В одно и то же время? В одном и том же месте? Что обще го у пользователей, у которых возника ю т ошибки? Задавайте подобные вопросы и ищите взаимосвязь. Это м ожет натолкнуть вас на поиск самой проблемы.
- Обратитесь за помощью. Не стесняйтесь спрашивать у более опытных коллег, что может быть не так с вашей программой? Как найти ошибки в ко д е и как их исправить? Ведь проблема может быть в чем угодно, а поиски решения могут занять долгое время. А с вами рядом всегда могут оказаться те, к то сможет помочь.
Заключение
Поиск и исправление логических ошибок в программе иногда становится очень стрессовой задачей. Поэтому в первую очередь никогда не нужно паниковать, если ваша программа работает не так , как надо. Не нужно сразу обвинять всех подряд или себя в том , что такая ошибка возникла.
Иногда логические ошибки действительно возникают по стечению обстоятельств и чисто случайно, поэтому только ваш и спокойствие и размеренность помо гут их обнаружить.