
Системы распределенных вычислений появляются, прежде всего, по той причине, что в крупных автоматизированных информационных системах, построенных на основе корпоративных сетей, не всегда удается организовать централизованное размещение всех баз данных и СУБД на одном узле сети. Поэтому системы распределенных вычислений тесно связаны с системами управления распределенными базами данных.
Распределенная база данных — это совокупность логически взаимосвязанных баз данных, распределенных в компьютерной сети.
Система управления распределенной базой данных — это программная система, которая обеспечивает управление распределенной базой данных и прозрачность ее распределенности для пользователей.
Распределенная база данных может объединять базы данных, поддерживающие любые модели (иерархические, сетевые, реляционные и объектно-ориентированные базы данных) в рамках единой глобальной схемы. Подобная конфигурация должна обеспечивать для всех приложений прозрачный доступ к любым данным независимо от их местоположения и формата.
Целостность данных в микросервисной архитектуре / Николай Голов (Avito)
Основные принципы создания и функционирования распределенных баз данных:
§ прозрачность расположения данных для пользователя (иначе говоря, для пользователя распределенная база данных должна представляться и выглядеть точно так же, как и нераспределенная);
§ изолированность пользователей друг от друга (пользователь должен «не чувствовать», «не видеть» работу других пользователей в тот момент, когда он изменяет, обновляет, удаляет данные);
§ синхронизация и согласованность (непротиворечивость) состояния данных в любой момент времени.
Из основных вытекает ряд дополнительных принципов:
§ локальная автономия (ни одна вычислительная установка для своего успешного функционирования не должна зависеть от любой другой установки);
§ отсутствие центральной установки (следствие предыдущею пункта);
§ независимость от местоположения (пользователю все равно, где физически находятся данные, он работает так, как будто они находятся на его локальной установке);
§ непрерывность функционирования (отсутствие плановых отключений системы в целом, например для подключения новой установки или обновления версии СУБД);
§ независимость от фрагментации данных (как от горизонтальной фрагментации, когда различные группы записей одной таблицы размещены на различных установках или в различных локальных базах, так и от вертикальной фрагментации, когда различные поля-столбцы одной таблицы размещены на разных установках);
§ независимость от реплицирования (дублирования) данных (когда какая-либо таблица базы данных (или ее часть) физически может быть представлена несколькими копиями, расположенными на различных установках);
§ распределенная обработка запросов (оптимизация запросов должна носить распределенный характер — сначала глобальная оптимизация, а далее локальная оптимизация на каждой из задействованных установок);
§ распределенное управление транзакциями (в распределенной системе отдельная транзакция может требовать выполнения действий на разных установках, транзакция считается завершенной, если она успешно завершена на всех вовлеченных установках);
1.2 Создать разделённую базу данных в Access
§ независимость от аппаратуры (желательно, чтобы система могла функционировать на установках, включающих компьютеры разных типов);
§ независимость от типа операционной системы (система должна функционировать вне зависимости от возможного различия ОС на различных вычислительных установках);
§ независимость от коммуникационной сети (возможность функционирования в разных коммуникационных средах);
§ независимость от СУБД (на разных установках могут функционировать СУБД различного типа, на практике ограничиваемые кругом СУБД, поддерживающих SQL).
В обиходе СУБД, на основе которых создаются распределенные информационные системы, также характеризуют термином «распределенные СУБД», и, соответственно, используют термин «распределенные базы данных».
Практическая реализация распределенных вычислений осуществляется через отступление от некоторых рассмотренных выше принципов создания и функционирования распределенных систем. В зависимости от того, какой принцип приносится в «жертву» (отсутствие центральной установки, непрерывность функционирования, согласованного состояния данных и др.) выделились несколько самостоятельных направлений в технологиях распределенных систем — технологии «Клиент-сервер», технологии реплицирования, технологии объектного связывания.
Реальные распределенные информационные системы, как правило, построены на основе сочетания всех трех технологий, но в методическом плане их целесообразно рассмотреть отдельно.
5.3 Технологии и модели «Клиент-сервер»
Системы на основе технологий «Клиент-сервер» исторически выросли из первых централизованных многопользовательских автоматизированных информационных систем, интенсивно развивавшихся в 70-х годах (системы mainframe), и получили, вероятно, наиболее широкое распространение в сфере информационного обеспечения крупных предприятий и корпораций.
В технологиях «Клиент-сервер» отступают от одного из главных принципов создания и функционирования распределенных систем — отсутствия центральной установки. Поэтому можно выделить две основные идеи, лежащие в основе клиент-серверных технологий:
§ общие для всех пользователей данные на одном или нескольких серверах;
§ много пользователей (клиентов), на различных вычислительных установках, совместно (параллельно и одновременно) обрабатывающих общие данные.
Иначе говоря, системы, основанные на технологиях «Клиент-сервер», распределены только в отношении пользователей, поэтому часто их не относят к «настоящим» распределенным системам, а считают отдельным классом многопользовательских систем.
Важное значение в технологиях «Клиент-сервер» имеют понятия сервера и клиента.
Под сервером в широком смысле понимается любая система, процесс, компьютер, владеющие каким-либо вычислительным ресурсом (памятью, временем, производительностью процессора и т. д.).
Клиентом называется также любая система, процесс, компьютер, пользователь, запрашивающие у сервера какой-либо ресурс, пользующиеся каким-либо ресурсом или обслуживаемые сервером иным способом.
В своем развитии системы «Клиент-сервер» прошли несколько этапов, в ходе которых сформировались различные модели систем «Клиент-сервер». Их реализация и, следовательно, правильное понимание основаны на разделении структуры СУБД на три компонента:
§ компонент представления, реализующий функции ввода и отображения данных, называемый иногда еще просто как интерфейс пользователя;
§ прикладной компонент, включающий набор запросов, событий, правил, процедур и других вычислительных функций, реализующий предназначение автоматизированной информационной системы в конкретной предметной области;
§ компонент доступа к данным, реализующий функции хранения-извлечения, физического обновления и изменения данных.
Исходя из особенностей реализации и распределения в системе этих трех компонентов различают четыре модели технологий «Клиент-сервер»:
§ модель файлового сервера (File Server — FS);
§ модель удаленного доступа к данным (Remote Data Access — RDA);
§ модель сервера базы данных (DataBase Server — DBS);
§ модель сервера приложений (Application Server — AS).
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник: studopedia.ru
Распределенный SQL: альтернатива шардированию баз данных
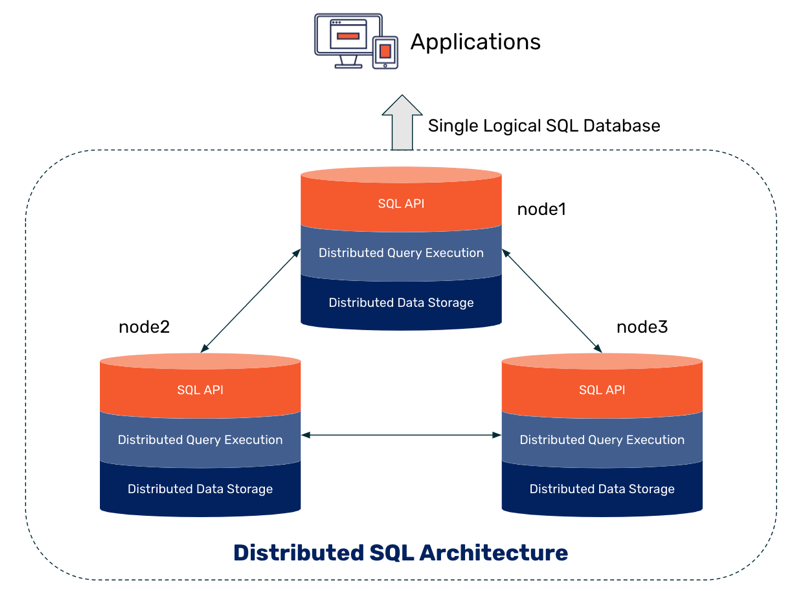
Шардирование баз данных – это процесс разделения данных на меньшие части, называемые «шарды». Эта техника обычно используется, когда возникает потребность в масштабировании записей. В течение жизненного цикла успешного приложения способность сервера его базы обрабатывать операции записи рано или поздно достигает своего предела. Деление данных на несколько шардов – с размещением каждого на собственном сервере БД – уменьшает нагрузку на отдельные узлы, по сути, повышая записывающую способность базы данных в целом. Этот процесс и является шардингом.
Распределённый SQL представляет новый способ масштабирования реляционных баз данных с помощью полностью автоматизированной и прозрачной для приложений стратегии, подобной шардингу. Распределённые БД SQL изначально спроектированы под практически линейное масштабирование. В текущей статье вы познакомитесь с основами распределённого SQL и узнаете, как начать работу с этими базами данных.
▍ Недостатки шардинга баз данных
Шардинг представляет ряд сложностей:
- Разделение данных: иногда бывает сложно сделать правильный выбор относительно разбивки данных по нескольким шардам, поскольку здесь для избежания дисбаланса (hotspot) необходимо найти компромисс между близостью данных и их равным распределением. Под дисбалансом в этом контексте понимаются ситуации, когда один узел вынужден обрабатывать большее число транзакций в сравнении с другими узлами, которые временами могут простаивать.
- Обработка сбоев: если ключевой узел даст сбой, и для обработки нагрузки окажется недостаточно шардов, то как перенести данные на новый узел без даунтайма?
- Сложность запросов: код приложения связан с логикой шардинга данных, и запросы, требующие данные из нескольких узлов, необходимо воссоединять.
- Согласованность данных: обеспечение согласованности данных по нескольким шардам может представлять сложности, поскольку для этого нужно координировать обновление данных в разных шардах. Особенно сложным этот процесс становится, когда обновления производятся параллельно, так как в этом случае иногда приходится разрешать конфликты между разными операциями записи.
- Гибкая масштабируемость: по мере увеличения объёма данных или числа запросов иногда возникает необходимость в расширении БД дополнительными шардами. Это может оказаться сложным процессом с неизбежным даунтаймом, требующим ручного вмешательства для равномерного перераспределения данных по всем шардам.
▍ Что такое распределённый SQL?
Распределённый SQL – это новое поколение реляционных баз данных. Простым языком, распределённая БД SQL – это реляционная БД с прозрачным шардингом, которая для приложений выглядит как одна логическая база данных. Реализуются такие БД в виде SN-архитектуры и движка хранения, который масштабирует и чтение, и записи, сохраняя при этом совместимость ACID и высокую доступность. Распределённые БД SQL обладают возможностями масштабирования, присущими БД NoSQL – которые обрели популярность в 2000-х – но без ущерба для согласованности. Они сохраняют преимущества реляционных баз данных и привносят облачную совместимость с межрегиональной отказоустойчивостью.
Существует несколько иной, но смежный по смыслу термин – NewSQL (введённый Мэтью Аслеттом в 2011 году), описывающий масштабируемые и производительные реляционные БД. Однако БД NewSQL не обязательно поддерживают горизонтальную масштабируемость.
▍ Как работает распределённый SQL?
Чтобы понять принцип работы распределённого SQL, мы разберём случай MariaDB Xpand – распределённую базу данных SQL, совместимую с опенсорсной MariaDB. Xpand работает путём разделения данных и индексов по узлам и автоматического выполнения таких задач, как перебалансировка данных и выполнение распределённых запросов. С целью минимизации задержки запросы выполняются параллельно.
Данные автоматически реплицируются, что гарантирует отсутствие возможных точек сбоя. В случае падения узла Xpand перераспределяет данные среди оставшихся узлов. То же самое происходит при добавлении нового узла.
Компонент под названием rebalancer (перебалансировщик) обеспечивает отсутствие дисбаланса, который представляют проблему при использовании шардинга БД.
Разберём пример. Предположим, что у нас есть экземпляр БД с some_table и набором строк:

Эти данные можно поделить на три части (шарда):

После чего поместить каждый шард в отдельный экземпляр БД:
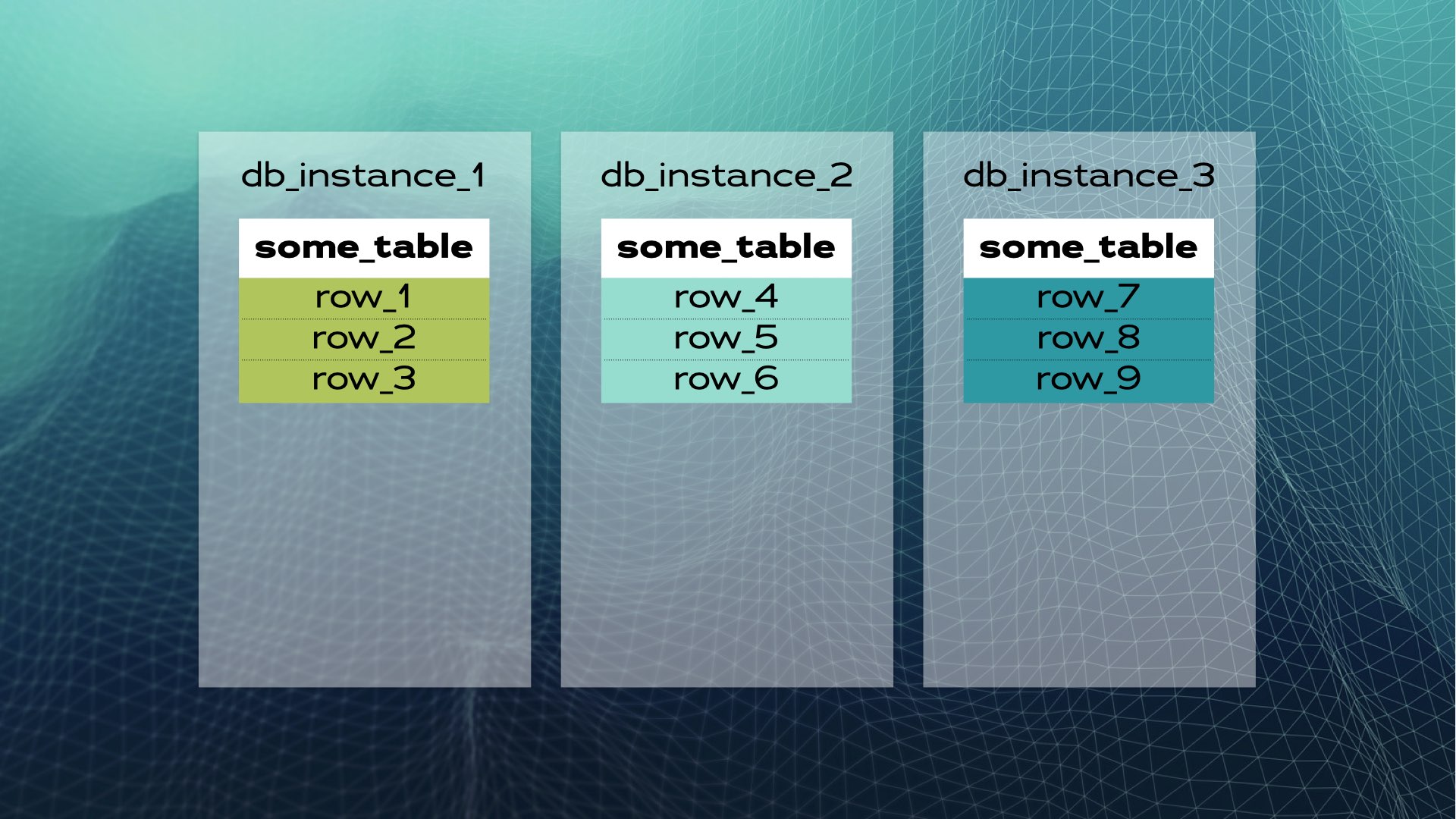
Так выглядит ручной шардинг базы данных. Распределённая же БД SQL будет делать это автоматически. В случае Xpand каждый шард называется срезом. Строки разбиваются при помощи хэша подмножества столбцов таблицы. Причём разбиваются не только данные, но и индексы, которые также распределяются по узлам (экземплярам базы данных).
Более того, для сохранения высокой доступности срезы реплицируются на другие узлы (количество реплик на узел настраивается). Это тоже происходит автоматически:

Когда в кластер добавляется новый узел, или когда один из узлов даёт сбой, Xpand автоматически перераспределяет данные, не требуя ручного вмешательства. Вот что происходит при добавлении узла в предыдущий кластер:

Некоторые строки перемещаются в этот новый узел с целью повышения общей производительности системы. Здесь нужно помнить, что хоть на схеме это и не показано, индексы, также как и реплики, тоже перемещаются и обновляются. А вот чуть более полноценное представление (с немного другой релокацией данных) того же кластера:
Эта архитектура позволяет выполнять практически бесконечное линейное масштабирование. Здесь отсутствует необходимость ручного вмешательства на уровне приложения. Для него этот кластер выглядит как единая логическая база данных. Приложение просто подключается к этой БД через балансировщик нагрузки (MariaDB MaxScale):

Когда приложение отправляет операцию записи (например, INSERT или UPDATE ), вычисляется хэш, который передаётся в соответствующий срез. Несколько записей параллельно отправляются на несколько узлов.
▍ Когда не стоит использовать распределённый SQL
Шардинг БД повышает быстродействие, но также вносит дополнительную нагрузку на уровне взаимодействия между узлами. Это может вести к снижению производительности в случае неудачной настройки базы данных или отсутствия оптимизации маршрутизатора запросов. Распределённый SQL может оказаться не лучшей альтернативой в приложениях, выполняющих менее 10К запросов или 5К транзакций в секунду. Кроме того, если ваша база данных состоит преимущественно из множества небольших таблиц, тогда монолитная БД может оказаться более подходящей.
▍ Начало работы с SQL
Поскольку распределённая БД SQL выглядит для приложения как единая логическая БД, то начать её использовать несложно. Потребуются лишь:
- SQL-клиент вроде DBeaver, DbGate, DataGrip или любое другое аналогичное расширение для вашей IDE;
- Распределённая БД SQL.
Для запуска контейнера Xpand выполните:
docker run —name xpand -d -p 3306:3306 —ulimit memlock=-1 mariadb/xpand-single —user «user» —passwd «password»
Примечание: на момент написания статьи образ mariadb/xpand-single недоступен для архитектур ARM. Для них (например, на машинах Apple с процессорами M1) используйте UTM, чтобы создать виртуальную машину (ВМ) и установить, скажем, Debian. Далее присвойте имя хоста и через SSH подключитесь к созданной ВМ для установки Docker и создания контейнера MariaDB Xpand.
▍ Подключение к базе данных
Подключение к базе данных происходит также, как к корпоративному или комьюнити-серверу MariaDB. Если у вас установлен CLI mariadb, просто выполните:
mariadb -h 127.0.0.1 -u user -p
К базе данных вы можете подключиться с помощью GUI в случае использования БД SQL вроде DBeaver, DataGrip или SQL-расширения для вашей IDE (например, этого для VS Code). Мы же будем использовать бесплатный SQL клиент под названием DbGate. Можете скачать DbGate и запустить его как десктопное приложение или же, раз вы используете Docker, развернуть его в виде веб-приложения, к которому можно будет обратиться из любого места через браузер (по аналогии с популярным phpMyAdmin). Просто выполните следующую команду:
docker run -d —name dbgate -p 3000:3000 dbgate/dbgate
После запуска контейнера перейдите в браузере по адресу http://localhost:3000/ и укажите детали подключения:
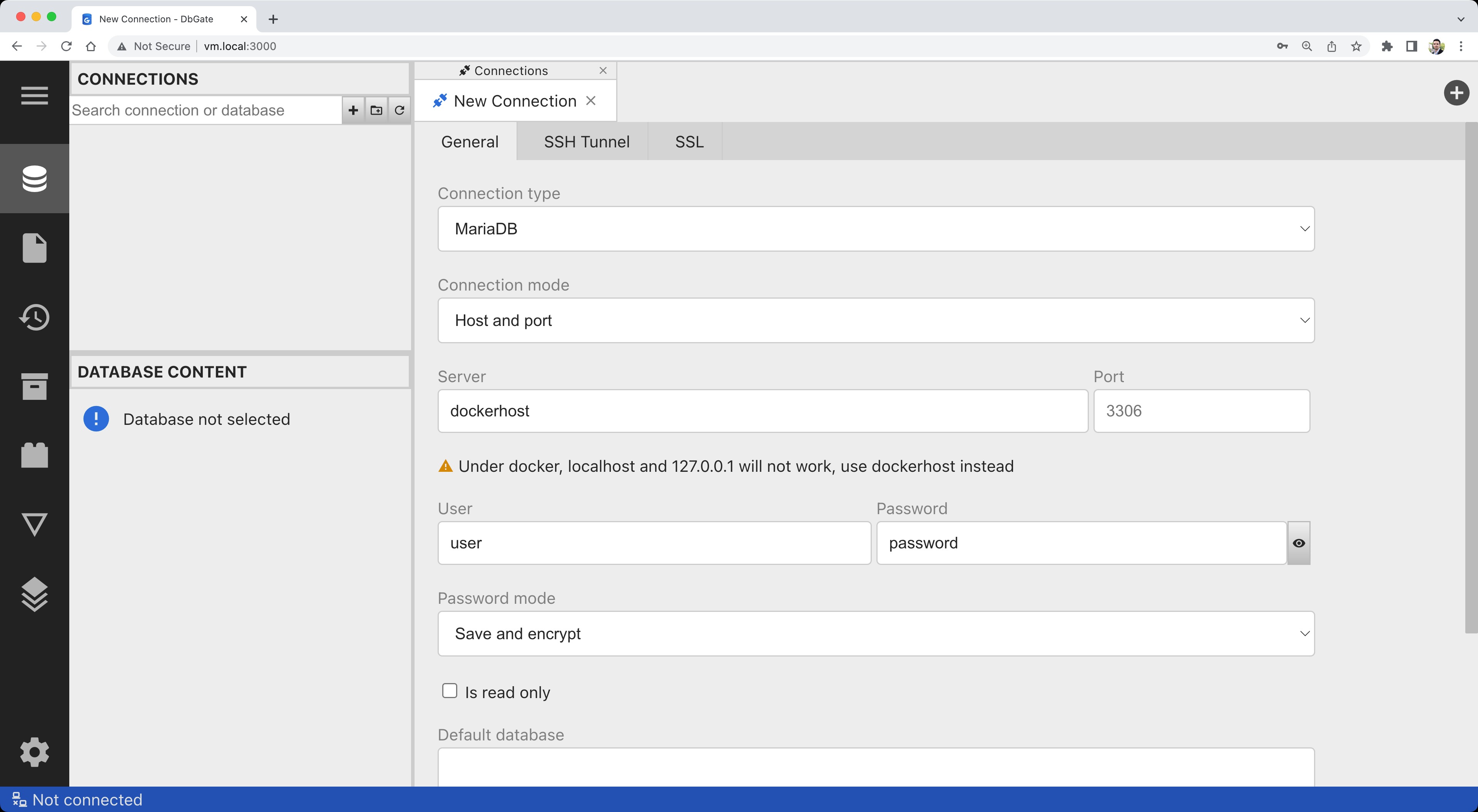
Кликните Test и убедитесь в успешной установке подключения:

Кликните Save и создайте новую базу данных, кликнув правой кнопкой на подключении в левой панели и выбрав Create database. Попробуйте создать таблицы либо импортировать SQL-скрипт. Если вы просто хотите поэкспериментировать, то для этого хорошо подойдут базы дынных Nation или Sakila.
▍ Подключение из Java, JavaScript, Python и C++
Для подключения к Xpand из приложений можно использовать коннекторы MariaDB. Существует множество возможных комбинаций языков программирования и фреймворков обеспечения персистентности. Эта тема уже выходит за рамки нашей статьи, но если вы просто хотите начать и посмотреть, как всё работает, то обратите внимание на эту страницу с примерами кода для Java, JavaScript, Python и C++.
▍ Истинная сила распределённого SQL
В этой статье мы узнали, как запустить БД Xpand с одним узлом для разработки и тестирования в противоположность рабочим процессам продакшен-среды. Однако истинный потенциал распределённых БД SQL заключается в их возможности масштабировать не только операции чтения (как при классическом шардинге БД), но и операции записи путём простого добавления узлов и перераспределения данных. И хотя развернуть Xpand в системе со множеством узлов вполне возможно, для использования его в продакшене проще всего задействовать SkySQL.
Если вы хотите побольше узнать о распределённом SQL и MariaDB Xpand, то вот список интересных ресурсов:
- MariaDB Xpand for distributed SQL (video animation)
- MariaDB Xpand documentation
- Taking Distributed SQL to the Next Level with Columnar Indexing (talk)
- Getting Started With Distributed SQL (refcard)

- ruvds_перевод
- базы данных
- распределенный sql
- nosql
- хранение данных
- шардирование
Источник: habr.com