
Kafka что это за программа
флаг —strip 1 просит архиватор не создавать родительскую папку типа ~/kafka/kafka_2.13-2.6.0, а распаковывать содержимое сразю в ~/kafka.
4 Настройка сервера Kafka
Поведение Kafka по умолчанию не позволяет нам удалить тему, категорию, группу или название канала, в котором можно публиковать сообщения. Чтобы исправить это, давайте отредактируем файл конфигурации:
nano ~/kafka/config/server.properties
и добавим это в конец:
delete.topic.enable = true
5 Создание Systemd Unit — файлов и запуск сервера Kafka
Создаем файл для зукипера (необходим для работы Kafka)
sudo nano /etc/systemd/system/zookeeper.service
[Unit]
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
ExecStart=/home/kafka/kafka/bin/zookeeper-server-start.sh /home/kafka/kafka/config/zookeeper.properties
Про Kafka (основы)
ExecStop=/home/kafka/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
секция Unit требует чтобы перед запуском zookeeper сеть и файловая система уже были готовы
секция Service назначает используемые при старте и остановке zookeeper скрипты
Теперь создаем то же самое для Kafka:
sudo nano /etc/systemd/system/kafka.service
[Unit]
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User=kafka
ExecStart=/bin/sh -c ‘/home/kafka/kafka/bin/kafka-server-start.sh /home/kafka/kafka/config/server.properties > /home/kafka/kafka/kafka.log 2>TutorialTopic».
7.2 Создайте продюссера и пошлите сообщение:
echo «Hello, World» | ~/kafka/bin/kafka-console-producer.sh —broker-list localhost:9092 —topic TutorialTopic > /dev/null
7.3 Создайте консьюмера и запустите приём сообщений:
~/kafka/bin/kafka-console-consumer.sh —bootstrap-server localhost:9092 —topic TutorialTopic —from-beginning
флаг —from-beginning даст возможность получить сообщения отправленные до запуска консьюмера. Вывод должен быть Hello, World.
Этот скрипт будет выполняться и принимать сообщения в реальном времени. Можете подключиться через другой терминал и попробовать отправить ещё что-нибудь в этот топик.
Также рекомендую скачать и установить клёвый десктопный клиент https://www.conduktor.io/ и законнектиться к серверу Kafka снаружи.

II. Создание Java SpringBoot проекта
Источником инфотмации послужила статья https://habr.com/ru/post/496182/, поэтому если что непонятно — вэлком туда.
Для начала создадим новый SpringBoot проект с зависимостями: Spring Web и Spring for Apache Kafka.
Мы не будем юзать Spring Web, он тут нужен только для того чтобы подтянулся Jackson. Либо можно не включать его в зависимости, а в файле pom.xml, прописать ручками
Что такое Apache Kafka и зачем это нужно
com.fasterxml.jackson.core jackson-databind
Создадим класс который будет слать сообщения каждые 3 секунды:
SuppressWarnings здесь потому что идея упорно говорит что такого бина не существует. Но он есть.
Теперь создадим класс консьюмера:
метод messageListener будет вызываться как поступит новое сообщение.
Група консьюмеров — это группа в рамках которой доставляется один экземпляр сообщения. Например, у Вас есть три консьюмера в одной группе, и все они слушают одну тему. Как только на сервере появляется новое сообщение с данной темой, оно доставляется кому-то одному из группы. Остальные два консьюмера сообщение не получают.
Ну и напоследок отредактируем файл application.properties:
#адрес сервера Kafka spring.kafka.bootstrap-servers=192.168.0.239:9092
Запускаем и тестируем! Можно юзать, например, Postman, либо встроенный в идею инструмент Tools > HTTP Client > Test RESTful Web Service.
Эксперименты
Продюссер при отправке сообщения может вернуть ответ об успешности или ошибке. Настрою коллбэк и буду выводить в консоль результат отправки сообщения. Дополним вызов kafkaTemplate.send:
ListenableFuture> future = kafkaTemplate.send(«msg», «currentTime», (new Date()).toString()); future.addCallback(System.out::println, System.err::println);
Теперь попробую перезагружать сервер Kafka. Что из этого вышло:
Если приложение запускается при недоступном сервере Kafka, То возникает исключение org.springframework.kafka.KafkaException: Send failed; nested exception is org.apache.kafka.common.errors.TimeoutException: Topic msg not present in metadata after 60000 ms.
Если сервер Kafka становится недоступным в процессе работы, то ошибки обрабатываются в возвращаемом future объекте метода kafkaTemplate.send.
Пока Kafka недоступен, Spring копит отправленные но недоставленные сообщения внутни себя
- Если сервер недоступен менее 2-х минут, то как только Kafka станет доступен, спринг выплюнет все сообщения туда прикрепив к ним правильное время отправки.
- Если сервер недоступен более 2-х минут, то вызовется коллбэк с ошибкой доставки. Типа такого org.springframework.kafka.core.KafkaProducerException: Failed to send; nested exception is org.apache.kafka.common.errors.TimeoutException: Expiring 40 record(s) for msg-0:120000 ms has passed since batch creation и такого org.apache.kafka.common.errors.TimeoutException: Expiring 40 record(s) for msg-0:120000 ms has passed since batch creation. Причем пачкой для нескольких сообщений. В итоге получится такой цикл: накопление сообщений — пачка ошибок — накопление сообщений — следующая пачка ошибок. Не разбирался по какому принципу, но как-то так. При появлении сервера Kafka, накопленные будут отправлены, а те, что с ошибками, — потерялись навсегда.
Отправка и получение кастомных объектов
Сначала реализуем продюссер. Для отправки объектов будем использовать сериализацию в Json. Для каждого кастомного класса нам нужен свой KafkaTemplate. Прежде чем приступить к их созданию, сделаем пару кастомных классов: UserDTO и UserDTO.Address:
package ru.knastnt.kafkatest; public class UserDTO < private String name; private int age; private Address address; public static UserDTO getTestInstance()< UserDTO u = new UserDTO(); UserDTO.Address a = new UserDTO.Address(); a.setStreet(«Ленина»); a.setHouse(16); u.setName(«Иван»); u.setAge(25); u.setAddress(a); return u; >public String getName() < return name; >public void setName(String name) < this.name = name; >public int getAge() < return age; >public void setAge(int age) < this.age = age; >public Address getAddress() < return address; >public void setAddress(Address address) < this.address = address; >public static class Address < private String street; private int house; public String getStreet() < return street; >public void setStreet(String street) < this.street = street; >public int getHouse() < return house; >public void setHouse(int house) < this.house = house; >> >
Теперь настроим кастомные шаблоны. Всё поместим в отдельный класс KafkaProducerConfig:
Основное что мы тут делаем — назначаем сериализаторы для ключа и значения сообщений.
А внутрь цикла в методе run, допишем действия по отправке наших кастомных объектов:
//Шлём объекты через кастомные шаблоны sleep(2000); ListenableFuture> userFuture = kafkaUserTemplate.send(«msg2», «user», UserDTO.getTestInstance()); userFuture.addCallback(System.out::println, System.err::println); sleep(2000); ListenableFuture> userFuture2 = kafkaAddressTemplate.send(«msg3», «addr», UserDTO.getTestInstance().getAddress()); userFuture2.addCallback(System.out::println, System.err::println);
Предлагаю запуститься и посмотреть как объекты улетают в кафку (это будет видно в консоли). К тому же можете воспользоваться https://www.conduktor.io/ и убедиться что топики пополняются новыми сообщениями.
Сделаем теперь несколько консьюмеров чтобы получать эти сообщения из кафки. Это несколько сложнее, но принцип тот же.
Создаем класс KafkaConsumerConfig:
Собственно для каждого кастомного класса нужно сделать по параметризованному ConcurrentKafkaListenerContainerFactory — это спринговая потокобезопасная обёртка.
В каждую из них нужно заинджектить конфигурацию консьюмера. Я реализовал её в виде параметризованного метода, в котором ключ — строка, а значение — объект передаваемого класса в json формате.
Теперь добавим пару слушающих методов в наш класс Listener:
Источник: knasys.ru
Запуск Kafka Server
И если вы видите следующий текст на консоли, значит, он работает.
2018-06-10 06:38:44,477] INFO Kafka commitId : fdcf75ea326b8e07 (org.apache.kafka.common.utils.AppInfoParser)
[2018-06-10 06:38:44,478] INFO [KafkaServer started (kafka.server.KafkaServer)
Создать темы
Сообщения публикуются в темах. Используйте эту команду для создания новой темы.
➜ kafka_2.11-1.1.0 bin/kafka-topics.sh —create —zookeeper localhost:2181 —replication-factor 1 —partitions 1 —topic test
Created topic «test».
Вы также можете получить список всех доступных тем, выполнив следующую команду.
➜ kafka_2.11-1.1.0 bin/kafka-topics.sh —list —zookeeper localhost:2181
test
Как видите, он печатает, test ,
Отправка сообщений
Далее мы должны отправлять сообщения,производителииспользуются для этой цели. Давайте инициировать продюсера.
➜ kafka_2.11-1.1.0 bin/kafka-console-producer.sh —broker-list localhost:9092 —topic test
>Hello
>World
Вы запускаете консольный интерфейс производителя, который работает на порту 9092 по умолчанию. —topic позволяет установить тему, в которой будут публиковаться сообщения. В нашем случае тема test
Это показывает вам > подскажите, и вы можете ввести все, что вы хотите.
Сообщения хранятся локально на вашем диске. Вы можете узнать о его пути, проверив значение log.dirs в config/server.properties файл. По умолчанию они установлены на /tmp/kafka-logs/
Если вы перечислите эту папку, вы найдете папку с именем test-0 , После перечисления вы найдете 3 файла: 00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex
Если вы откроете 00000000000000000000.log в редакторе он показывает что-то вроде:
Похоже, что закодированные данные или разделитель разделены, я не уверен. Если кто-то знает этот формат, то дайте мне знать.
В любом случае, Кафка предоставляет утилиту, которая позволяет вам проверять каждое входящее сообщение.
➜ kafka_2.11-1.1.0 bin/kafka-run-class.sh kafka.tools.DumpLogSegments —deep-iteration —print-data-log —files /tmp/kafka-logs/test-0/00000000000000000000.log
Dumping /tmp/kafka-logs/test-0/00000000000000000000.log
Starting offset: 0
offset: 0 position: 0 CreateTime: 1528595323503 isvalid: true keysize: -1 valuesize: 5 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: Hello
offset: 1 position: 73 CreateTime: 1528595324799 isvalid: true keysize: -1 valuesize: 5 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: World
Вы можете увидеть сообщение с другими деталями, такими как offset , position а также CreateTime и т.п.
Использование сообщений
Сохраненные сообщения также должны быть использованы. Начнем с консольного потребителя.
➜ kafka_2.11-1.1.0 bin/kafka-console-consumer.sh —bootstrap-server localhost:9092 —topic test —from-beginning
Если вы запустите, он будет сбрасывать все сообщения с начала до настоящего времени. Если вам просто интересно использовать сообщения после запуска потребителя, вы можете просто пропустить —from-beginning переключи его и беги. Причина в том, что старые сообщения не отображаются, потому что смещение обновляется, как только потребитель отправляет ACK брокеру Kafka для обработки сообщений. Вы можете увидеть рабочий процесс ниже.

Доступ к Кафке в Python
Для использования доступно несколько библиотек Python:
- Кафка-Python — Библиотека сообщества с открытым исходным кодом.
- PyKafka — Эта библиотека поддерживается Parsly и считается, что она является Pythonic API. В отличие от Kafka-Python, вы не можете создавать динамические темы.
- Сливной питон кафка: — предлагается Confluent в качестве тонкой обертки вокруг librdkafka следовательно, это производительность лучше, чем два.
Для этого поста мы будем использовать открытый исходный кодКафка-Python,
Система оповещения рецептов в Кафке
Напоследок после о Elasticsearch, я очистил данные Allrecipes. В этом посте я собираюсь использовать тот же скребок, что и источник данных. Система, которую мы собираемся создать, представляет собой систему оповещения, которая будет отправлять уведомления о рецептах, если она соответствует определенному порогу калорий. Там будет две темы:
- raw_recipes: — Он будет хранить сырой HTML каждого рецепта. Идея состоит в том, чтобы использовать эту тему в качестве основного источника наших данных, которые впоследствии могут быть обработаны и преобразованы в соответствии с потребностями.
- parsed_recipes: -Как следует из названия, это будет проанализированный данные каждого рецепта в формате JSON.
Длина названия темы Кафки не должна превышать 249,
Типичный рабочий процесс будет выглядеть ниже:

устанавливать kafka-python с помощью pip
pip install kafka-python
Сырой рецепт производителя
Первая программа, которую мы собираемся написать, — продюсер. Он получит доступ к Allrecpies.com и получит сырой HTML и сохранит вraw_recipesтема.

Парсер рецептов
Следующий скрипт, который мы собираемся написать, будет служить как потребителем, так и производителем. Сначала он будет использовать данные из raw_recipes разделить и преобразовать данные в формат JSON, а затем опубликовать их в parsed_recipes тема. Ниже приведен код, который будет извлекать данные HTML из raw_recipes тема, разобрать, а затем кормить в parsed_recipes тема.

Все идет нормально. Мы сохранили рецепты как в формате raw, так и в формате JSON для дальнейшего использования. Далее мы должны написать потребителя, который будет связываться с parsed_recipes тема и генерировать оповещение, если определенно calories critera встречается.
JSON декодируется, а затем проверяется количество калорий, после того, как критерии соответствуют, выдается уведомление.
Вывод
Kafka — это масштабируемая, отказоустойчивая система обмена сообщениями с публикацией и подпиской, которая позволяет создавать распределенные приложения. Из-за его высокая производительность и эффективность она становится популярной среди компаний, которые производят большое количество данных из различных внешних источников и хотят получать данные в режиме реального времени. Я только что раскрыл суть этого. Изучите документы и существующую реализацию, и это поможет вам понять, как она лучше всего подходит для вашей следующей системы.
Эта статья первоначально опубликована Вот ,
щелчок Вот подписаться на мою рассылку для будущих сообщений.
Источник: machinelearningmastery.ru
Использовать Apache Kafka для гарантированного упорядочивания сообщений
Apache Kafka — это программное обеспечение для обмена сообщениями, используемое для передачи данных и информации между системами.
Учитывая возможности Kafka, он может поддерживать широкий спектр сценариев использования. В LinkedIn он был создан для сбора метрик об использовании приложений.
Основы Kafka
Очередь сообщений позволяет многим разрозненным приложениям взаимодействовать, посылая друг другу сообщения. Очередь — это очередь объектов, ожидающих обработки — в последовательном порядке, начиная с начала очереди. Приложения, которые читают данные из очереди сообщений, называются «потребителями». Приложения, которые отправляют сообщения в Kafka, называются «производителями».
В платформе данных сообщения могут быть данными, а потребители — программами обработки данных. Эти программы обработки могут быть ориентированы на пакетную обработку, а могут быть программами потоковой обработки в режиме реального времени.

Почему именно Kafka?
- Kafka обладает высокой масштабируемостью. Очень легко добавить большое количество потребителей без ущерба для производительности и надежности. Это потому, что Kafka не отслеживает, какие сообщения в теме были потреблены потребителями. Она просто хранит все сообщения в теме в течение настраиваемого периода времени.
- Kafka также поддерживает различные модели потребления. Вы можете иметь одного потребителя, обрабатывающего сообщения в режиме реального времени, и другого потребителя, обрабатывающего сообщения в пакетном режиме в полностью разделенном режиме.
- Kafka поддерживает возможность получения сообщений от широкого круга производителей.
- Долговечность сообщений в Kafka высокая. Он сохраняет сообщения/события в течение заданного периода времени.
- Kafka линейно масштабируется при больших объемах данных. Добавление дополнительных брокеров/кластеров увеличит пропускную способность или уменьшит задержку.
- Kafka поддерживает отличную интеграцию с другими системами обработки данных. К ним относятся Apache Storm, Spark, NiFi, Flume и т.д. для завершения работы.
Примеры использования Kafka
Обмен сообщениями
Kafka хорошо работает в качестве замены более традиционного брокера сообщений. Брокеры сообщений используются по разным причинам (для разделения обработки и производителей данных, для буферизации необработанных сообщений и т.д.).
Отслеживание активности веб-сайта
Kafka можно использовать для построения конвейера отслеживания активности пользователей в виде набора каналов публикации-подписки в реальном времени. Активность на сайте (просмотры страниц, поиск или другие действия пользователей) может быть опубликована в центральных темах с одной темой для каждого типа активности.
Агрегация журналов
Kafka является заменой решения для агрегации журналов. Агрегация журналов обычно собирает физические файлы журналов с серверов и помещает их в центральное хранилище (файловый сервер или HDFS) для обработки. По сравнению с системами, ориентированными на журналы, такими как Scribe или Flume, Kafka предлагает такую же высокую производительность, более надежные гарантии долговечности благодаря репликации и гораздо меньшую сквозную задержку.
Архитектура Kafka и ее компоненты
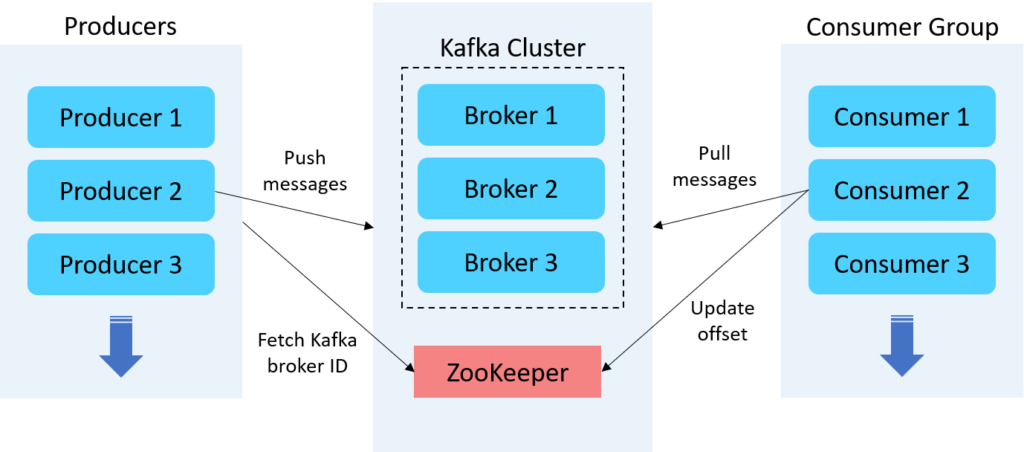
Брокеры Kafka
Брокер Kafka — это сервер, работающий в кластере Kafka (или, говоря иначе, кластер Kafka состоит из нескольких брокеров). Как правило, несколько брокеров работают согласованно, образуя кластер Kafka и обеспечивая балансировку нагрузки, надежное резервирование.
Apache ZooKeeper
Брокеры Kafka используют ZooKeeper для управления и координации работы кластера Kafka. ZooKeeper уведомляет все узлы, когда топология кластера Kafka меняется, в том числе когда брокеры и темы (топики) добавляются или удаляются.
Продюсеры Kafka
Продюсер Kafka служит источником данных, который оптимизирует, записывает и публикует сообщения в одной или нескольких темах (топиках) Kafka. Производители Kafka также сериализуют, сжимают и распределяют данные между брокерами с помощью разделения.
Потребители Kafka
Потребители читают данные, читая сообщения из тем, на которые они подписаны. Потребители принадлежат к группе потребителей. Каждый потребитель в определенной группе потребителей отвечает за чтение подмножества разделов каждой темы, на которую он подписан.
Топики Kafka
Топик Kafka определяет канал, по которому передаются данные. Производители публикуют сообщения в топики, а потребители читают сообщения из топика, на который они подписаны.
Партиции Kafka
В кластере Kafka темы делятся на партиции, а партиции реплицируются между брокерами. Из каждого раздела несколько потребителей могут читать из топика параллельно.
Группа потребителей
Группа потребителей Kafka включает связанных потребителей с общей задачей. Kafka отправляет сообщения из разделов темы потребителям в группе потребителей. В момент чтения каждый раздел читается только одним потребителем в группе.
Фактор репликации тем
Репликация тем необходима для создания отказоустойчивых и высокодоступных развертываний Kafka. Когда брокер выходит из строя, реплики тем на других брокерах остаются доступными, чтобы гарантировать, что данные остаются доступными и что развертывание Kafka избегает сбоев и простоев.
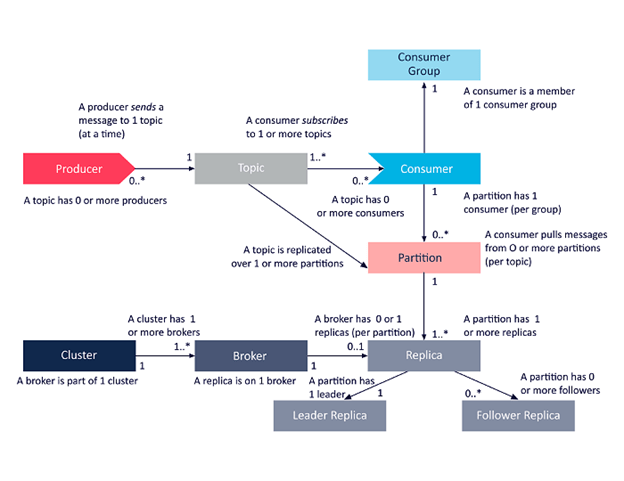
Как обеспечить порядок сообщений
В Kafka порядок может быть гарантирован только в пределах раздела (партиции). Это означает, что если сообщения были отправлены от производителя в определенном порядке, брокер запишет их в партицию, и все потребители будут читать из нее в том же порядке. Поэтому, естественно, в теме с одной партицией легче обеспечить упорядочивание по сравнению с несколькими партициями.
Однако с одной партицией трудно добиться параллелизма и балансировки нагрузки.
Существует несколько способов, с помощью которых мы можем добиться упорядочивания сообщений, параллелизма и балансировки нагрузки одним способом. Давайте посмотрим, как Kafka обрабатывает порядок сообщений с одним брокером/одним партицией и несколькими брокерами/многими партициями.
Порядок сообщений при использовании одного брокера
Порядок сообщений в Kafka хорошо работает для одной партиции. Но с одним разделом трудно добиться параллелизма и балансировки нагрузки.
Давайте создадим топиком (с одной репликой и одной партицией) с именем топика «test»:
./kafka-topics.sh —create —zookeeper localhost:2181 —topic test —replication-factor 1 —partitions 1
Рассмотрим пример набора данных со схемами row_no, name, transaction_type и amount, как показано ниже:
0001,Test1,credit,10000 0002,Test2,debit,20000 0003,Test3,credit,30000 0004,Test4,debit,40000 0005,Test5,debit,50000
Kafka поставляется с клиентом командной строки, который будет принимать данные из файла или стандартного ввода и отправлять их в виде сообщений в кластер Kafka. По умолчанию каждая строка будет отправлена как отдельное сообщение.
Давайте опубликуем приведенный выше пример набора данных в нашей новой топика test:
./kafka-console-producer.sh —topic test —bootstrap-server localhost:9092 >0001,Test1,credit,10000 >0002,Test2,debit,20000 >0003,Test3,credit,30000 >0004,Test4,debit,40000 >0005,Test5,debit,50000
Порядок будет получен такой же, как и выше для одного топика.
./kafka-console-consumer.sh —bootstrap-server localhost:9092 —topic test —from-beginning >0001,Test1,credit,10000 >0002,Test2,debit,20000 >0003,Test3,credit,30000 >0004,Test4,debit,40000 >0005,Test5,debit,50000
Порядок сообщений при использовании нескольких брокеров
Существует три метода, с помощью которых мы можем сохранить порядок сообщений внутри разделов в Kafka. У каждого метода есть свои плюсы и минусы.
Метод 1: Round Robin или Spraying
Метод 2: Хеширование ключевых разделов
Метод 3: Пользовательский разделитель
Метод 1: Round Robin или Spraying (по умолчанию)
В этом методе разделитель будет посылать сообщения всем партициям по кругу, обеспечивая сбалансированную нагрузку на сервер.
Для примера создадим топик (с тремя репликами и тремя партициями) с именем топика «test2»:
./kafka-topics.sh —create —zookeeper localhost:2181 —topic test —replication-factor 3 —partitions 3
Опубликуем тот же набор данных в новой топике test2:
/.kafka-console-producer.sh —topic test2 —bootstrap-server localhost:9092 >0001,Test1,credit,10000 >0002,Test2,debit,20000 >0003,Test3,credit,30000 >0004,Test4,debit,40000 >0005,Test5,debit,50000
Давайте создадим потребителя, который будет получать сообщения из Kafka:
./kafka-console-consumer.sh —bootstrap-server localhost:9092 —topic test2 —from-beginning >0004,Test4,debit,40000 >0001,Test1,credit,10000 >0003,Test3,credit,30000 >0002,Test2,debit,20000 >0005,Test5,debit,50000
Давайте разберемся, что происходит под капотом. Есть три раздела (A, B и C). Раздел B работает быстро благодаря низкой сетевой и системной задержке, и сообщения, отправленные на него, были получены первыми. Затем идет раздел C, за которым следует A.
Этим методом достигается параллелизм и балансировка нагрузки, но не удается сохранить общий порядок, однако порядок внутри раздела сохраняется. Это метод по умолчанию, и он не подходит для некоторых бизнес-сценариев. Если дебетовая транзакция произойдет раньше кредитной, то это будет неясно для бизнес-пользователей, которые потребляют сообщения.
Для того чтобы преодолеть описанные выше сценарии и сохранить порядок сообщений, давайте попробуем другой подход.
Метод 2: Хеширование ключевых разделов
В этом методе мы можем создать ProducerRecord, указать ключ сообщения, вызвав new ProducerRecord (имя топика, ключ сообщения, сообщение).
Разделитель по умолчанию будет использовать хэш ключа, чтобы гарантировать, что все сообщения для одного и того же ключа попадут к одному и тому же производителю. Это самый простой и наиболее распространенный подход. Это тот же метод, который использовался. Для хеширования используется операция модуляции.
Hash(Key) % Количество партиций -> Номер партиции
Однако простая отправка строк текста приведет к сообщениям с нулевыми ключами. Чтобы отправлять сообщения с ключами и значениями, мы должны установить свойства parse.key и key.separator в командной строке при запуске производителя.
Ниже приведен фрагмент кода для метода хэширования, который устанавливает свойство parse.key в true, а для key.separator задает «:».
В приведенном ниже примере сообщений ключами являются key1, key2, а значениями — value1, value2.
— broker-list localhost:9092 — topic topic-name — property «parse.key=true» — property «key.separator=:» key1:value1 key2:value2
Давайте создадим топик (с тремя репликами и тремя партициями) с именем темы test1:
./kafka-topics.sh —create —zookeeper localhost:2181 —topic test1 —replication-factor 3 —partitions 3
И опубликуем несколько сообщений в топике test1 с ключевым значением для всех записей:
./kafka-console-producer.sh —topic test1 —bootstrap-server localhost:9092 —property «parse.key=true» —property «key.separator=:» >0001:0001,Test1,credit,10000 >0002:0002,Test2,debit,20000 >0001:0001,Test3,credit,30000 >0002:0002,Test4,debit,40000 >0001:0001,Test5,debit,50000
Как видно ниже, порядок сообщений внутри ключей сохраняется.
./kafka-console-consumer.sh —bootstrap-server localhost:9092 —topic test1 —from-beginning
./kafka-console-consumer.sh —bootstrap-server localhost:9092 —topic test1 —from-beginning >0002:0002,Test2,debit,20000 >0002:0002,Test4,debit,40000 >0001:0001,Test1,credit,10000 >0001:0001,Test3,credit,30000 >0001:0001,Test5,debit,50000
Брокер назначает ключ 0001 для раздела A (раздел с высокой задержкой) и ключ 0002 для раздела B (раздел с низкой задержкой), используя метод хэширования ключей. Потребитель потребляет сообщение, основываясь на значении ключа в заказе.
С помощью этого метода мы можем поддерживать порядок сообщений в пределах ключа.
Но недостатком этого метода является то, что он использует случайное значение хэширования для передачи данных в назначенный раздел, и это приводит к перегрузке данных в один раздел.
Метод 3: Пользовательский разделитель
Мы можем написать собственную бизнес-логику, чтобы решить, какое сообщение должно быть отправлено в тот или иной раздел. При таком подходе мы можем упорядочить сообщения в соответствии с нашей бизнес-логикой и одновременно добиться параллелизма.

Основные выводы
- Одной из важнейших функций Kafka является балансировка нагрузки на сообщения и гарантированное упорядочивание в распределенном кластере для достижения параллелизма.
- Использование большего количества разделов приводит к увеличению пропускной способности и задержки. Однако это может привести к накладным расходам на обслуживание.
- Используя раздел с хэширующим ключом, мы можем доставлять сообщения с одинаковым ключом по порядку, отправляя их в один и тот же раздел. Данные внутри раздела будут храниться в том порядке, в котором они были записаны. Поэтому данные, прочитанные из раздела, будут прочитаны по порядку для этого раздела с ключом производителя.
- Используя Пользовательский разделитель, мы можем маршрутизировать сообщения, используя произвольные бизнес-правила.
Похожие записи:
- Какова производительность Kafka, если он записывает данные на диск?
- Как, где и когда Apache Kafka записывает данные
- Kafka: Удалить топик из консоли
- Kafka: увеличить количество партиций топика
- Установка Apache Kafka в CentOS Stream
- Что делает Apache Kafka таким быстрым
- Kraken v2.7.0 build 247
Источник: g-soft.info
Установка и работа с Kafka на Linux

Опубликовано: 03.10.2022
- Установки и настройке Kafka.
- Конфигурирование, а также запуск сервисов zookeeper и kafka.
- Выполнение тестовых запросов к брокеру сообщений.
Так как установка Kafka выполняется путем распаковки бинарника, инструкция написана для использования на различных дистрибутивах Linux, например, Ubuntu, Rocky, Astra, РЕД ОС.
Наше ознакомление с программным продуктом разобьем на разделы:
Подготовка системы
Перед тем, как приступить к установке Kafka, выполним предварительную настройку системы. Рассмотрим варианты для дистрибутивов на основе deb и rpm.
Установка служебных пакетов
Для работы нам понадобятся некоторые утилиты:
- curl — отправка http-запросов, в том числе, для загрузки файлов.
- tar — распаковка и создание архивов.
- wget — загрузка файлов по сети.
Установим их заранее.
а) Для систем на основе DEB:
apt install curl tar wget
б) Для систем на основе RPM:
yum install curl tar wget
Настройка брандмауэра
Для работы с кафкой по сети необходимо открыть порт 9092. В зависимости от утилиты управления брандмауэром наши команды будут отличаться.
а) Для Iptables (как правило, для deb):
iptables -I INPUT -p tcp —dport 9092 -j ACCEPT
Для сохранения правил используем утилиту iptables-persistent:
apt install iptables-persistent
б) Для Firewalld (как правило, для rpm):
firewall-cmd —permanent —add-port=9092/tcp
firewall-cmd —permanent —reload
Установка Kafka
Как упоминалось выше, установка программного продукта выполняется путем распаковки бинарника, а также настройки и установки необходимых компонентов. Итого, мы должны:
- Установить JDK.
- Распаковать бинарник Kafka.
- Внести правки в конфигурационный файл.
- Создать юнит-файлы для запуска сервисов zookeeper и kafka.
Установка OpenJDK
В зависимости от типа Linux наши команды будут немного отличаться.
а) Для систем на основе DEB:
apt install default-jdk
б) Для систем на основе RPM:
yum install java-11-openjdk-devel
Смотрим версию java:
Мы должны увидеть что-то на подобие:
openjdk version «11.0.10» 2021-01-19
OpenJDK Runtime Environment .
Установка и настройка Kafka
Переходим на страницу загрузки Kafka и копируем ссылку на скачиваем приложения:

Используя скопированную ссылку, скачиваем бинарник:
Создадим каталог, куда установим кафку:
Распакуем скачанный архив в созданный каталог:
tar zxf kafka_*.tgz -C /opt/kafka —strip 1
Интернет сообщество сразу рекомендует внести небольшую правку в конфигурационный файл. Откроем его:
* данная директива разрешает ручное удаление темы из кафки.
Настройка запуска kafka
Осталось настроить запуск кафки в качестве сервиса. Мы создадим отдельного пользователя и создадим два юнита systemd — один для zookeeper, второй для kafka.
Для создания пользователя вводим:
useradd -r -c ‘Kafka broker user service’ kafka
Назначим владельцем созданного пользователя для каталога кафки:
chown -R kafka:kafka /opt/kafka
Создаем первый юнит-файл:
[Unit]
Description=Zookeeper Service
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
ExecStart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties
ExecStop=/opt/kafka/bin/zookeeper-server-stop.sh
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
Создаем второй файл для кафки:
[Unit]
Description=Kafka Service
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User=kafka
ExecStart=/bin/sh -c ‘/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties > /opt/kafka/kafka.log 2>Hello, World from Kafka» | /opt/kafka/bin/kafka-console-producer.sh —broker-list localhost:9092 —topic Test
* в данном примере мы отправляем в наш сервер сообщение Hello, World from Kafka.
Попробуем достать сообщение. Выполняем команду:
/opt/kafka/bin/kafka-console-consumer.sh —bootstrap-server localhost:9092 —topic Test —from-beginning
* опция from-beginning позволяет увидеть все сообщения, которые были отправлены в брокер до создания подписчика (отправки запроса на чтения данных из кафки).
Мы должны увидеть:
Hello, World from Kafka
При этом мы подключимся к серверу в интерактивном режиме. Не спешим выходить. Откроем вторую сессию SSH и еще раз введем:
echo «Hello, World from Kafka again» | /opt/kafka/bin/kafka-console-producer.sh —broker-list localhost:9092 —topic Test
Вернемся к предыдущей сессии SSH и мы должны увидеть:
Hello, World from Kafka
Hello, World from Kafka again
Можно считать, что программа минимум выполнена — Kafka установлена и работает.
Источник: www.dmosk.ru