
Общие сведения об Apache Kafka в Azure HDInsight
Apache Kafka — это распределенная платформа потоковой передачи с открытым исходным кодом, которую можно использовать для создания конвейеров и приложений потоковой передачи данных в режиме реального времени. Kafka также предоставляет функцию брокера сообщений, подобную очереди сообщений, с помощью которой можно выполнять публикацию и подписываться на именованные потоки данных.
Ниже приведены характеристики Kafka в HDInsight.
- Это управляемая служба, которая упрощает процесс настройки. Она создает конфигурацию, проверенную и поддерживаемую корпорацией Майкрософт.
- Корпорация Майкрософт предоставляет соглашение об уровне обслуживания (SLA), гарантирующее 99,9 % время непрерывной работы Kafka. Дополнительные сведения см. в документе Соглашение об уровне обслуживания для HDInsight.
- В качестве резервного хранилища для Kafka используются управляемые диски Azure. Управляемые диски могут обеспечить до 16 ТБ хранилища для каждого брокера Kafka. См. сведения о настройке числа управляемых дисков и повышении степени масштабируемости для Apache Kafka в HDInsight. См. дополнительные сведения об управляемых дисках Azure.
- Служба Kafka была разработана для одномерной стойки. Azure разделяет стойку на два измерения — домены обновления (UD) и домены сбоя (FD). Корпорация Майкрософт предоставляет инструменты, которые могут выполнять перераспределение секций и реплик Kafka в доменах обновления и доменах сбоя. Дополнительные сведения см. в статье Обеспечение высокого уровня доступности данных с помощью Apache Kafka в HDInsight.
- HDInsight позволяет изменить количество рабочих узлов (в которых размещается брокер Kafka) после создания кластера. Вертикальное увеличение масштаба можно выполнить на портале Azure, в Azure PowerShell и других интерфейсах управления Azure. Для Kafka выполните повторную балансировку реплик секций после масштабирования. Балансировка секций позволяет Kafka пользоваться преимуществами нового количества рабочих узлов. HDInsight Kafka не поддерживает вертикальное уменьшение масштаба или уменьшение числа брокеров в кластере. При попытке уменьшить число узлов будет возвращена ошибка InvalidKafkaScaleDownRequestErrorCode . Дополнительные сведения см. в статье Обеспечение высокого уровня доступности данных с помощью Apache Kafka в HDInsight.
- Журналы Azure Monitor можно использовать для мониторинга Kafka в HDInsight. В журналах Azure Monitor представлена информация об уровне виртуальной машины (например, метрики диска и сетевой карты, а также метрики JMX от Kafka). Дополнительные сведения см. в статье Анализ журналов для Apache Kafka в HDInsight.
Архитектура Apache Kafka в HDInsight
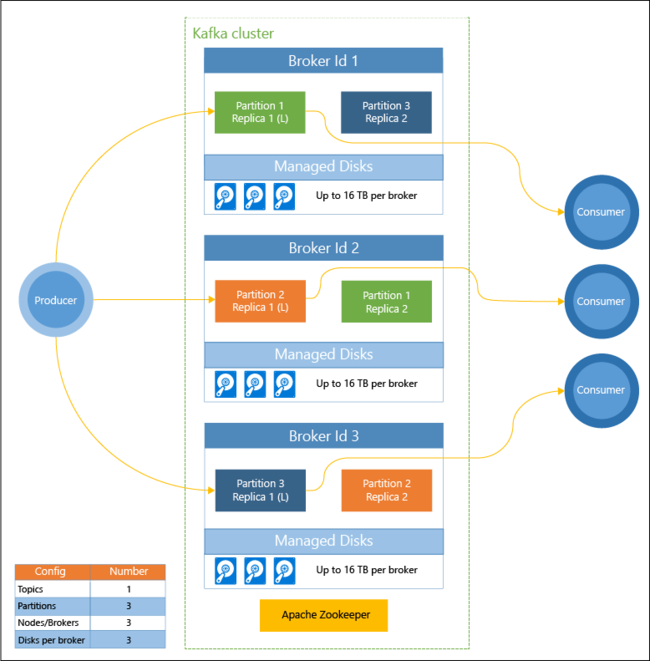
На приведенной ниже схеме показана стандартная конфигурация Kafka, в которой предусмотрены группы потребителей, секционирование и репликация, чтобы обеспечить параллельное считывание событий и отказоустойчивость.
Что такое Apache Kafka за 5 минут
Что такое Apache Kafka и зачем это нужно
Apache ZooKeeper управляет состоянием кластера Kafka. Служба Zookeeper предназначена для параллельных надежных транзакций с низкой задержкой.
В Kafka записи (данные) хранятся в разделах. Записи создаются производителями, а используются потребителями. Производители отправляют записи в брокеры Kafka. Каждый рабочий узел в кластере HDInsight — это брокер Kafka.
Разделы позволяют распределить записи между брокерами. При считывании записей можно использовать один потребитель на секцию, чтобы обеспечить параллельную обработку данных.
Репликация используется для дублирования секций между узлами, чтобы обеспечить защиту от сбоев узлов (брокеров). Секция, обозначенная на схеме буквой (L), является ведущей (leader) в определенном разделе. Трафик производителя направляется в ведущую секцию каждого узла в зависимости от состояния, которым управляет ZooKeeper.
Для чего использовать Apache Kafka в HDInsight?
Ниже приведены распространенные задачи и шаблоны, которые могут быть выполнены с помощью Kafka в HDInsight.
| Репликация данных Apache Kafka | Kafka предоставляет программу MirrorMaker, которая производит репликацию данных между кластерами Kafka. Сведения об использовании MirrorMaker см. в статье Репликация разделов Apache Kafka с помощью Kafka в HDInsight и MirrorMaker. |
| Модель обмена сообщениями по схеме «публикация — подписка» | Kafka предоставляет API производителя для публикации записей в разделе Kafka. При подписке на раздел используется API пользователя. Дополнительные сведения см. в статье Краткое руководство по созданию Apache Kafka в кластере HDInsight. |
| Потоковая обработка | Kafka часто используется со Spark для потоковой обработки в режиме реального времени. В Kafka 0.10.0.0 (HDInsight версий 3.5 и 3.6) появился API потоковой передачи, который позволяет создавать решения потоковой передачи без использования Spark. Дополнительные сведения см. в статье Краткое руководство по созданию Apache Kafka в кластере HDInsight. |
| Горизонтальное масштабирование | В Kafka потоки разделяются между узлами в кластере HDInsight. Процессы пользователя можно связать с отдельными секциями для обеспечения балансировки нагрузки при использовании записей. Дополнительные сведения см. в статье Краткое руководство по созданию Apache Kafka в кластере HDInsight. |
| Упорядоченная доставка | В каждой секции записи сохраняются в потоке в том порядке, в котором они были получены. Достаточно связать один процесс пользователя с секцией — и записи будут обрабатываться в определенном порядке. Дополнительные сведения см. в статье Краткое руководство по созданию Apache Kafka в кластере HDInsight. |
| Обмен сообщениями | Благодаря поддержке модели обмена сообщениями по схеме «публикация — подписка» Kafka часто используется как брокер сообщений. |
| Отслеживание действий | Kafka предоставляет возможность ведения журнала записей в определенном порядке, поэтому Kafka можно использовать для отслеживания и повторного создания действий. Например, действий пользователя на веб-сайте или в приложении. |
| Агрегирование | С помощью потоковой обработки можно объединить информацию из разных потоков для ее централизации в качестве оперативных данных. |
| Преобразование | С помощью потоковой обработки можно объединять и дополнять данные из нескольких входных разделов в один или несколько выходных разделов. |
Дальнейшие действия
Ниже приведены ссылки на статьи об использовании Apache Kafka в HDInsight.
- Краткое руководство по созданию Apache Kafka в кластере HDInsight
- Использование Kafka c прокси-сервером REST
- Пример потоковой передачи Apache Spark (DStream) с использованием Apache Kafka в HDInsight
Источник: learn.microsoft.com
Что такое Apache Kafka: как устроен и работает брокер сообщений
Apache Kafka — распределенный брокер сообщений, работающий в стриминговом режиме. В статье мы расскажем про его устройство и преимущества, а также о том, где применяют «Кафку».
Что такое брокер сообщений
Главная задача брокера — обеспечение связи и обмена информацией между приложениями или отдельными модулями в режиме реального времени.
Брокер — система, преобразующая сообщение от источника данных (продюсера) в сообщение принимающей стороны (консьюмера). Брокер выступает проводником и состоит из серверов, объединенных в кластеры.
Apache Kafka — диспетчер сообщений, разработанный LinkedIn. В 2011 году был опубликован программный код. В 2012 году Kafka попал в инкубатор Apache, дальнейшая разработка ведется в рамках Apache Software Foundation. Открытое программное обеспечение с разрешительной лицензией написано на Java и Scala.
Изначально «Кафку» создавали как систему, оптимизированную под запись, и создатель Джей Крепс выбрал такое название в честь одного из своих любимых писателей.
Шаги передачи данных
Чтобы понять, как функционирует распределенная система Apache Kafka, необходимо проследить путь данных.
Событие или сообщение — данные, которые поступают из одного сервиса, хранятся на узлах Kafka и читаются другими сервисами. Сообщение состоит из:
- Key — опциональный ключ, нужен для распределения сообщений по кластеру.
- Value — массив байт, бизнес-данные.
- Timestamp — текущее системное время, устанавливается отправителем или кластером во время обработки.
- Headers — пользовательские атрибуты key-value, которые прикрепляют к сообщению.
Продюсер — поставщик данных, который генерирует сообщения — например, служебные события, логи, метрики, события мониторинга.
Консьюмер — потребитель данных, который читает и использует события, пример — сервис сбора статистики.
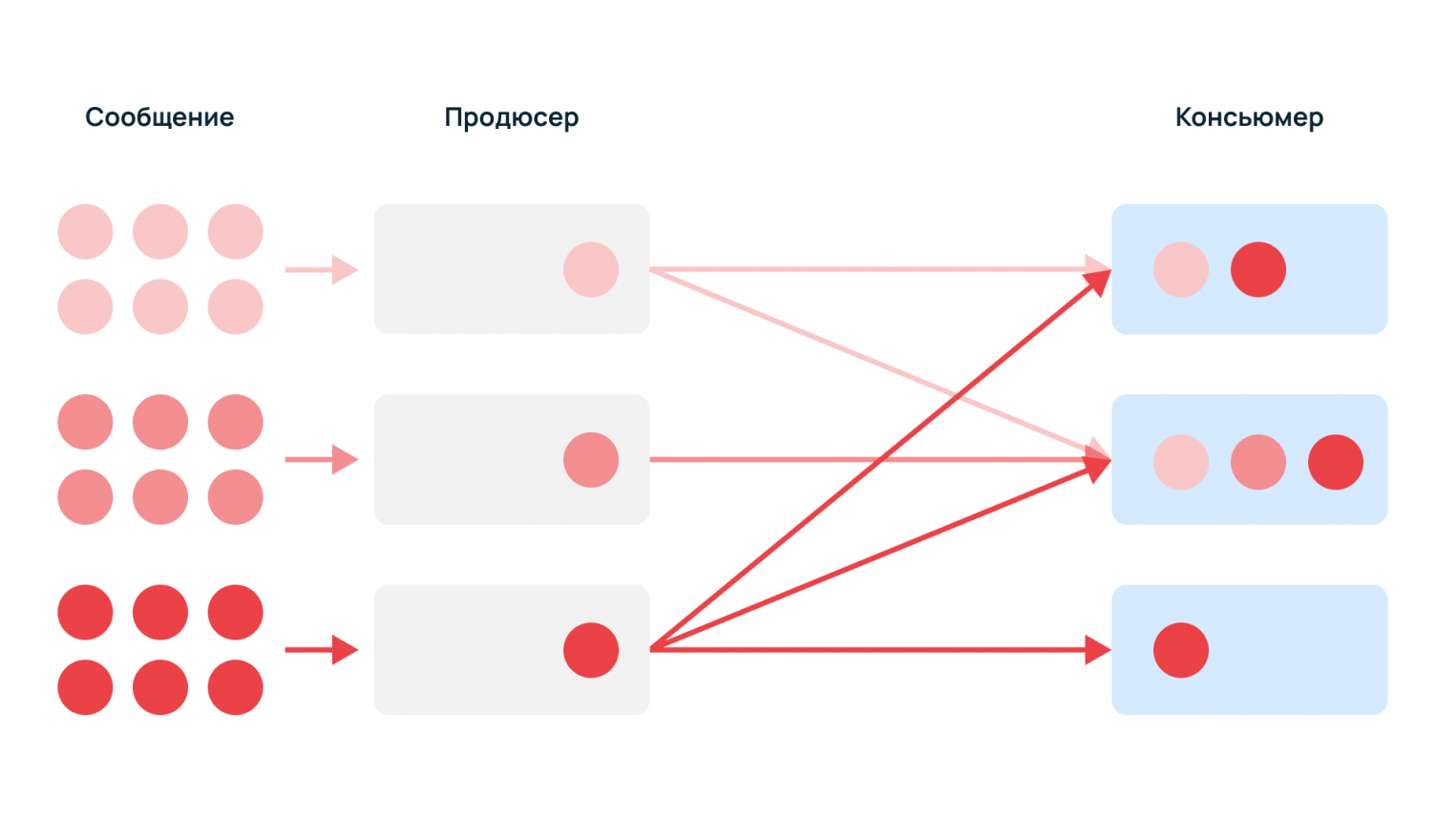
Какие сложности решает распределенная система
Сообщения могут быть однотипными или разнородными, поскольку разным потребителям нужны разные данные. Один тип событий может быть нужен всем консьюмерам, а другие — только одному.
Без брокера продюсеры должны знать получателя и резервного консьюмера, если основной недоступен. К тому же, поставщикам данных придется самостоятельно регистрировать новых консьюмеров. С помощью брокера продюсеры просто отправляют информацию в единый узел.
Managed service для Apache Kafka
Сообщения хранятся на узлах-брокерах. Kafka — масштабируемый кластер со множеством взаимозаменяемых серверов, в которые добавляются новые брокеры, распределяющие задачи между собой.
ZooKeeper — инструмент-координатор, действует как общая служба конфигурации в системе. Работает как база для хранения метаданных о состоянии узлов кластера и расположении сообщений. ZooKeeper обеспечивает гибкую и надежную синхронизацию в распределенной системе, позволяя нескольким клиентам выполнять одновременно чтение и запись.
Kafka Controller — среди брокеров Zookeeper выбирает одного, который будет обеспечивать консистентность данных.
Topic — принцип деления потока данных, базовая и основная сущность Apache Kafka. В топик складывается стрим данных, единая очередь из входящих сообщений.
Partition — для ускорения чтения и записи топики делятся на партиции. Происходит параллелизация данных. Это конфигурируемый параметр, сообщения могут отправлять несколько продюсеров и принимать несколько консьюмеров.
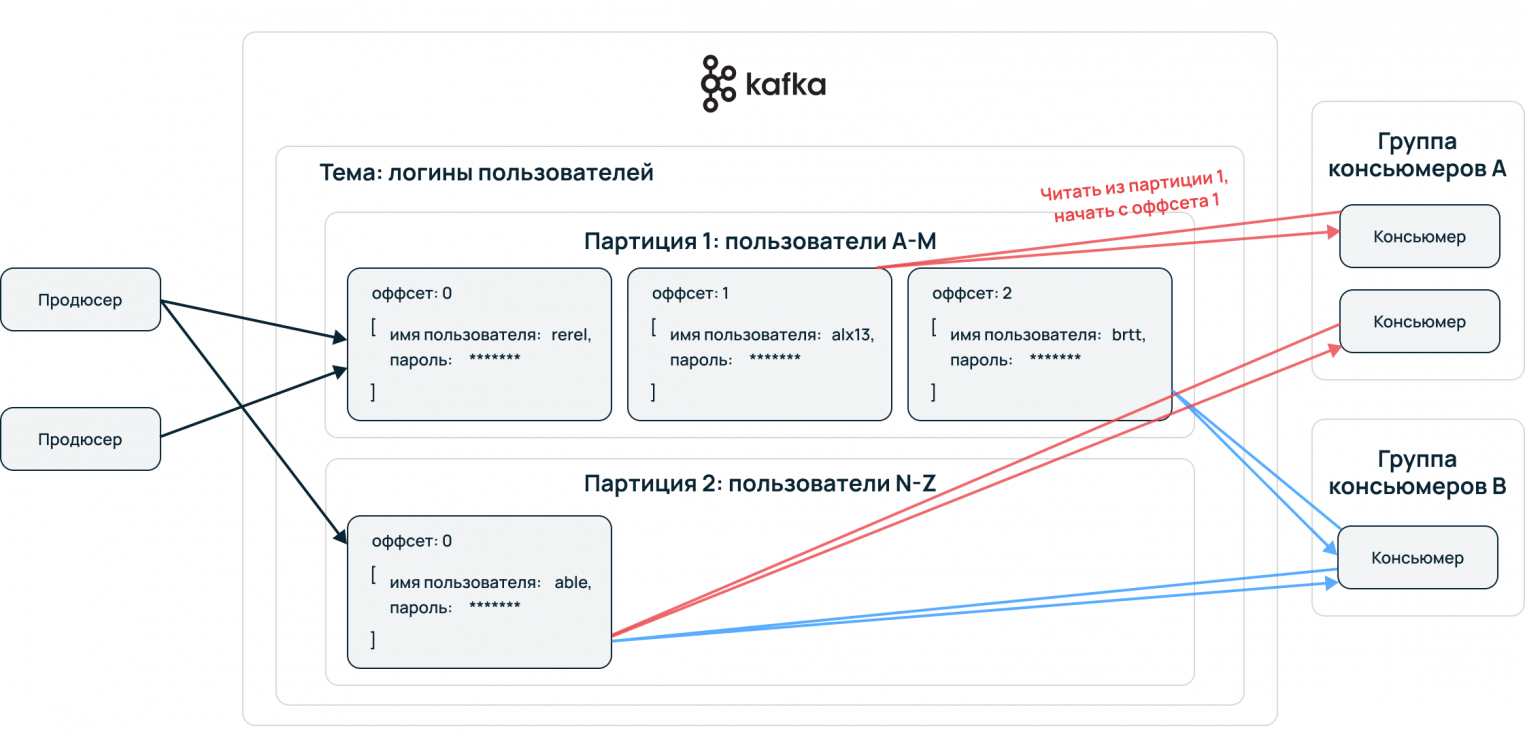
Упорядочение событий происходит на уровне партиций. Принимающая сторона потребляет данные в порядке расположения в партиции. Пример: все события одного пользователя сервисы принимают упорядоченно, обработка сохраняет последовательность пути пользователя. Выстраивается конвейер данных, алгоритмы машинного обучения могут извлекать из сырой информации необходимую для бизнеса информацию.
Преимущества Apache Kafka
Брокер распределяет информацию в широковещательном режиме. Применяющийся в Apache Kafka подход нужен для масштабирования и репликации данных.
Горизонтальное масштабирование
Множество объединенных серверов гарантируют высокую доступность данных — выход из строя одного из узлов не нарушает целостность. Кластер состоит из обычных машин, а не суперкомпьютеров, их можно менять и дополнять. Система автоматически перебалансируется.
Чтобы события не потерялись, существуют механизмы репликации. Данные записываются на несколько машин, если что-то случается с сервером, он переключается на резервный. Кластер в режиме реального времени определяет, где находятся данные, и продолжает их использовать.
Офсеты
Если консьюмер падает в процессе получения данных, то, когда он запустится вновь и ему нужно будет вернутся к чтению этого сообщения, он воспользуется офсетом и продолжит с нужного места.
Взаимодействие через API
Брокеры решают проблему интеграции разных технических стеков и протоколов. Интеграция происходит просто: продюсерам и консьюмерам необходимо знать только API брокера. Они не контактируют между собой, с помощью чего достигается высокая интегрируемость с другими системами.
Принцип first in — first out
Принцип FIFO действует на консьюмеров. Чтение происходит в том же порядке, в котором пришла информация.
Где применяется Apache Kafka
Отказоустойчивая система используется в бизнесе, где необходимо собирать, хранить и обрабатывать большие неструктурированные данные. Примеры — платформы, где требуется интеграция данных из большого количества источников, сервисы стриминговой аналитики, mission-critical applications.
Big Data
Первоначально LinkedIn разработали «Кафку» для своих целей: обмена данными между службами, репликации баз данных, потоковой передачи информации о деятельности и операционных показателях приложений.
Для IBM Apache Kafka работает как средство обмена сообщениями между микросервисами. В аналитических системах американской корпорации Apache Kafka обрабатывает потоковые и событийные данные.
Uber, Twitter, Netflix и AirBnb с помощью хорошо развитых пайплайнов обработки данных передают миллиарды сообщений в день. «Кафка» решает проблемы перемещения Big data из одного источника в другой.
Издание The New York Times использует Apache Kafka для хранения и распространения опубликованного контента среди различных приложений и систем, которые делают его доступным для читателей в режиме реального времени.
Internet of Things
IoT-платформы используют архитектуру с большим количеством конечных устройств: контроллеров, датчиков, сенсоров и smart-гаджетов. ПО интернета вещей с помощью алгоритмов ML составляет графики профилактического ремонта оборудования, анализируя данные, поступающие с устройств.
ML-системы работают с онлайн-потоками, когда приборы, приложения и пользователи постоянно посылают данные, а сервисы обрабатывают их в реальном времени. Apache Kafka выступает центральным звеном в этом процессе.
Отрасли
Kafka используют организации практически в любой отрасли: разработка ПО, финансовые услуги, здравоохранение, государственное управление, транспорт, телеком, геймдев.
Сегодня Kafka пользуются тысячи компаний, более 60% входят в список Fortune 100. На официальном сайте представлен полный список корпораций и учреждений, которые используют брокера Apache.
Конкуренты
Чаще всего Kafka сравнивают с RabbitMQ. Обе системы — брокеры сообщений. Главное отличие в модели доставки: Kafka добавляет сообщение в журнал, и консьюмер сам забирает информацию из топика; брокер RabbitMQ самостоятельно отправляет сообщения получателям — помещает событие в очередь и отслеживает его статус.
«Кролик» удаляет событие после доставки, «Кафка» хранит до запланированной очистки журнала. Таким образом, брокер Apache используется как источник истории изменений.
Разработчики RabbitMQ создали системы управления потоком сообщений: мониторинг получения, маршрутизация и шаблоны доставки. Подобное гибкое управление подойдет для высокоскоростного обмена сообщениями между несколькими сервисами. Минус такого подхода в снижении производительности при высокой нагрузке.
Главный вывод — для сбора и агрегации событий из большого количества источников, логов и метрик больше подойдет Apache Kafka.
Заключение
Благодаря высокой пропускной способности и согласованности данных Apache Kafka обрабатывает огромные массивы данных в реальном времени. Системы горизонтального масштабирования и офсеты гарантируют надежность. Kafka — удачное решение для проекта с очень большими нагрузками на обработку данных. Установить это ПО можно на серверы Ubuntu, Windows, CentOS и других популярных операционных систем.
Источник: selectel.ru
Роль Apache Kafka в Big Data и DevOps: краткий ликбез и практические кейсы

Мы уже упоминали Apache Kafka в статье про промышленный интернет вещей (Industrial Internet Of Things, IIoT). Сегодня поговорим о том, где и для чего еще в Big Data проектах используется эта распределённая, горизонтально масштабируемая система обработки сообщений.
Как работает Apache Kafka
Apache Kafka позволяет в режиме онлайн обеспечить сбор и обработку следующих данных:
- поведение пользователя на сайте;
- потоки информации с множества конечных устройств IoT и IIoT («сырые данные»);
- агрегация журналов работы приложений;
- агрегация статистики из распределенных приложений для корпоративных витрин данных (ETL-хранилищ);
- журналирование событий.
Яркий пример использования Apache Kafka – непрерывная передача информации со smart-периферии (конечных устройств) в IoT-платформу, когда данные не только передаются, но и обрабатываются множеством клиентов, которые называются подписчиками (consumers). В роли подписчиков выступают приложения и программные сервисы.
Здесь имеют место отложенные вычисления, когда подписчиков меньше, чем сообщений от издателей – источников данных (producer). Сообщения (messages) записываются по разделам (partition) темы (topic) и хранятся в течении заданного периода. Подписчики сами опрашивают Kafka на предмет наличия новых сообщений, и указывают, какие записи им нужно прочесть, увеличивая или уменьшая смещение к нужной записи. Записанные события могут переигрываться или обрабатываться повторно [1].

Зачем нужна Кафка в Big Data
Поскольку сообщения скапливаются в топике до их обработки подписчиками, Apache Kafka также называют брокером сообщений и средством для управления очередями в Big Data системах с высокой пропускной способностью сети (сотни тысяч сообщений в секунду). Однако, в отличие от RabbitMQ, другой популярной системы управления очередью сообщений, Apache Kafka является, прежде всего, распределенным реплицированным журналом фиксации изменений [2]. Чем еще отличаются эти брокеры сообщений, читайте в нашей новой статье. Именно с журналированием связаны ключевые сценарии использования Kafka (use-cases) и особенности программной реализации этой системы.
В частности, если необходимо сформировать общий журнал поведения всех пользователей приложения, Кафка поможет собрать и агрегировать логи каждого сеанса от каждого клиента в потоковом режиме (онлайн) [3]. Эта информация, в свою очередь, может использоваться в ETL-процессах (Extract, Transform, Load) для использования в дэшбордах систем интеллектуальной бизнес-аналитики (BI, Business Intelligence) [4].
Источник: www.bigdataschool.ru
Разбираемся в Apache Kafka: подборка полезных статей и кейсов
Мы много пишем и рассказываем про Apache Kafka, поэтому решили создать подборку наших статей. Они помогут освоить инструмент, познакомят с рабочими кейсами с использованием Kaфки.
Немного (много) об инструменте и том, как его освоить
Apache Kafka: основы технологии
Apache Kafka — это, если очень коротко, отказоустойчивая распределенная платформа с открытым исходным кодом. Где требуется Кафка, какие особенности у неё есть и чем она отличается от других популярных систем обмена сообщениями и информацией — в нашем материале.
И маленькому стартапу, и большому энтерпрайзу — Кафка, которую нужно знать
Можно ли использовать Apache Kafka в качестве базы данных и какое у Кафки будущее? Провели небольшое интервью с нашим экспертом, спикером Слёрма, Георгом Гаалом. Он ответил на эти вопросы, а ещё рассказал о сильных и слабых сторонах платформы, возможностях её масштабирования. Читайте материал здесь.
Apache Kafka и RabbitMQ: в чем разница и что лучше изучать?
Для решения задачи распределения поступающих данных разработчик может обратиться к Кафке и Rabbit. Это разные инструменты, подходящие под определенные запросы. Где что лучше использовать, о различиях и особенностях рассказываем тут.
Лучшие книги по Apache Kafka
С чего начинается Кафка? Со страниц книг практикующих специалистов и авторов инструмента! Подобрали для вас мануалы, с которыми у вас получится освоить Kafka и начать активно применять. Список книг лежит здесь.
Apache Kafka на практике
Кафка помогает организовать работу микросервисов и спасает разработчиков там, где другие инструменты рухнули под наплывом данных. Делимся производственными кейсами.
Рецепт готовки Apache Kafka: как создавался Data Lake на 80 Тb
Перед Михаилом Кобиком и его командой встала интересная задача — клиент попросил организовать хранилище данных на 80 ТР. О танцах с бубном и продуктивных решениях в нашем материале.
Обкафкился по полной: 3 фейла с Apache Kafka
Учиться лучше всего на чужих ошибках: свои встанут в копеечку и прибавят седых волос. Всеволод Севостьянов, Engineering Manager в HelloFresh, поделился тремя историями из практики и рассказал, как не надо использовать Kafka. Об опыте Всеволода читайте здесь.
Реальные примеры применения Kafka в автопроме
Kafka требуется во многих профессиональных областях, в том числе и в автопроме. Рассказываем о трех вариантах использования Кафки — при подключенных транспортных средствах, в умном производстве и в инновационных услугах перевозок читайте в статье.
Опыт работы с Apache Kafka: интервью с inDriver
Порой компании приходят к решению сменить архитектуру приложения и сделать вместо монолитного приложения микросервисную архитектуру. DevOps-инженеры компании inDriver Радик Сейфуллин и Александр Плотников модернизировали старое приложение, и в работе им пригодилась Кафка — она помогла решить проблемы старого приложения . Об интересных моментах и сложностях они рассказали в этом материале.
Kafka, Lamoda и непреодолимое желание учиться
На наших курсах учатся разработчики из крупнейших компаний России: занятия ещё не закончились, а они уже применяют знания на практике. Никита Галушко, разработчик подразделения Online Shop Lamoda, рассказал о своих впечатлениях от курса и о том, как Kafka помогает решить проблемы в отделе Research and Development. Читайте статью тут.
Хотите перейти от теории к делу и освоить Kafka на практике? Книги и статьи —это хорошо, но ничто не заменит полноценный курс с полным разбором теории, обратной связью от опытных спикеров и практики на стендах. С курсом от Слёрма у вас получиться сэкономить 3 месяца самостоятельного копания в документации — всю информацию дадим мы.
Источник: vc.ru
Роль Apache Kafka в системах обработки данных
На сегодняшний момент почти в каждой компании, которая серьезно подходит к вопросам сбора и обработки данных, есть какой-либо брокер сообщений. Это может быть AWS Kinesis, Google PubSub или какой-то еще сервис. Но если мы говорим о компаниях, размещающих сервисы не в облаке, а на своей инфраструктуре, то в качестве брокера чаще всего выступает Apache Kafka. В подтверждение того, насколько она распространена, на главной странице проекта приведен факт — “Более 80 % компаний из Fortune 100 используют Kafka”. Давайте обсудим, что это и какую роль этот сервис играет в системах обработки данных.
Что такое Kafka?
Kafka — это сервис, позволяющий в реальном времени и с высокой пропускной способностью передавать сообщения между различными системами. Его используют для различных целей — передача данных в хранилище, потоковая аналитика, взаимодействие между сервисами и т. д.
Кафка представляет из себя кластер из нескольких брокеров, каждый из которых обслуживает свою часть общей нагрузки. Каждый поток сообщений в Кафке называется “топик” (англ. topic). Например, в отдельный топик могут литься данные от веб-аналитики, фиксирующей заходы пользователей сайта, в отдельный — данные о заказах, в отдельный — факты подписок на рассылку.
Каждый такой топик делится на партиции. Эти партиции равномерно распределяются по всем брокерам кластера для повышения пропускной способности. Клиент, пишущий в топик, называется “producer”, а читающий из топика — “consumer”.
Среди плюсов Кафки можно выделить следующие: ● Отказоустойчивость. ● Простота использования. ● Высокая пропускная способность. ● Горизонтальное масштабирование. ● Возможность долгосрочного хранения истории сообщений. ● Большое число интеграций для сервисов и библиотек для разных языков.
Роль Kafka в системах обработки данных
Главный вопрос, который может возникнуть, — зачем нам этот “посредник” между различными системами? Не проще ли будет отправлять данные напрямую? Это ведь дополнительная точка для потенциального отказа системы.
Приведем пару аргументов: 1. Кафка позволяет унифицировать протокол обмена данными между разными системами. Допустим, у вас есть 3 сервиса, поставляющие данные, и 2 сервиса, потребляющие данные. Часто потреблять данные нужно не из одного сервиса, а из нескольких. Между каждой парой сервисов придется писать отдельную интеграцию из-за разницы в реализациях (язык, тип базы и т. д.).
В пределе количество таких “перемычек” между разными сервисами достигает 32 = 6. То есть нужно будет написать 6 разных коннекторов. Это выглядит просто. Но что, если систем будет 20 и 5? Это уже 255 = 100 коннекторов. И так далее. Кафка же дает универсальный интерфейс.
Для каждого сервиса будет достаточно написать только интеграцию с кафкой. А это уже 20 + 5 = 25 перемычек, что намного проще. Не говоря о том, что для многих сервисов и языков интеграция с Кафкой уже реализована. 2. Кафка выступает временным хранилищем между источником и приемником.
Если у вас произошла авария или вам нужно банально обновить приемник, вы можете не беспокоиться о потере данных при наличии Кафки. Данные из источника останутся в хранилище Кафки и их можно будет дочитать после запуска системы-приемника. 3. Кафка выступает “буфером” для нагрузки. Если источник внезапно выдал большой объем данных, система-приемник может упасть под нагрузкой.
Если же между ними стоит Кафка, она примет на себя нагрузку и благодаря высокой отказоустойчивости и пропускной способности сможет принять и сохранить данные, пока система-приемник будет не спеша вычитывать их в своем темпе. 4. Кафка жизненно важна для реалтайм-аналитики, так как позволяет доставлять данные с очень низкими задержками. При попытке использовать обычную СУБД в качестве промежуточного хранилища для потоков данных вы очень быстро столкнетесь с высокой нагрузкой на базу и долгими задержками доставки данных. Кафка же была изначально создана именно для поставки потоков данных в режиме реального времени и позволяет добиться задержек в несколько миллисекунд. Кроме того, большинство фреймворков для потоковой обработки данных (Spark Streaming, Apache Flink) отлично интегрированы с Кафкой “из коробки”.
Заключение
На текущий момент Кафка стала обязательным элементом для реализации множества архитектур обработки данных. Крайне желательно внедрить Кафку, если: ● у вас сложная топология обмена данными, включающая большое число источников и приемников, основанных на различных технологиях; ● вам необходимо предоставлять аналитику в режиме реального времени; ● вы хотите повысить надежность вашей системы доставки данных.
Учитывая, что с каждым годом роль потоковой обработки данных и реалтайм-аналитики только увеличивается, необходимость внедрения Кафки или аналогичного брокера в систему обработки данных будет становиться всё более актуальной.
Источник: otus.ru