
Аннотация: Для создания, хранения, обработки и коллективного использования информации применяются специальные программные системы, называемые системами управления базами данных (СУБД).
8.1. Общая характеристика баз данных
База данных – это совокупность структурированных и взаимосвязанных данных, относящихся к определенной предметной области .
Для создания, хранения, обработки и коллективного использования информации применяются специальные программные системы, называемые системами управления базами данных ( СУБД ).
К основным функциям СУБД относятся следующие:
- физическое размещение в памяти данных и их описаний;
- поддержка баз данных в актуальном состоянии;
- механизмы поиска запрашиваемых данных;
- доступ к данным при одновременном запросе одних и тех же данных многими пользователями (прикладными программами);
- способы обеспечения защиты данных от некорректных обновлений и/или несанкционированного доступа.
Основная особенность СУБД – это наличие процедур для ввода и хранения не только самих данных, но и описаний их структуры.
Основы реляционных СУБД. Что необходимо знать программисту
Тщательное проектирование базы данных – первый и очень важный шаг создания базы. Он позволяет избежать затрат, связанных с внесением исправлений в структуру хранящихся данных.
Проектирование базы данных начинается с анализа предметной области и выявления требований к ней отдельных пользователей (сотрудников организации, для которых создается база данных ). На этапе проектирования выявляются объекты информации и их характеристики, определяются виды данных, требующие регулярного обновления, и способы представления информации на экране и в отчетах, формулируются вопросы, на которые необходимо регулярно отвечать при поиске данных. Это помогает конкретизировать требования к хранимой информации. В любой момент можно изменить структуру хранящейся в базе информации, подкорректировав структуру таблиц и, соответственно, форм и отчетов. За проектирование и поддержку базы данных отвечает администратор базы данных (АБД).
СУБД использует следующие модели и описания:
- инфологическую;
- даталогическую;
- физическую.
Трехуровневая архитектура (инфологический, даталогический и физический уровни) позволяет обеспечить независимость хранимых данных от использующих их программ.
Первоначально создается обобщенное неформальное описание создаваемой базы данных . Это описание называют инфологической моделью данных, и оно выполняется с использованием естественного языка, блок-схем, математических формул, таблиц, графиков и других средств. Инфологическая модель отражает предметную область, для которой проектируется база данных , и полностью независима от физических параметров среды хранения данных. Основными конструктивными элементами инфологических моделей являются сущности, связи между ними и их свойства (атрибуты). Инфологическая модель не должна изменяться до тех пор, пока изменения в реальном мире не повлекут за собой изменения предметной области и, следовательно, изменения в модели.
Описание, создаваемое разработчиками базы данных по инфологической модели данных, называют даталогической моделью данных. Конечным результатом даталогического проектирования является описание логической структуры базы данных на ЯОД – языке описания данных конкретной СУБД . При создании даталогической модели данных обеспечивается однозначное соответствие между конструкциями языка описания данных и графическими обозначениями информационных единиц и связей между ними.
В основе каждой СУБД лежит концепция модели данных, то есть некоторой абстракции представления данных. Изначально были успешными две конкурирующие модели – иерархическая и сетевая. Иерархическая БД состоит из упорядоченного набора деревьев. Корпорация IBM разработала и внедрила язык описания данных DL/I ( Data Language One ), который моделировал данные в иерархической форме ( представление данных в форме деревьев). Эта модель была разработана совместно с промышленными предприятиями и предназначалась для хранения и поддержки данных, которые иерархически связаны между собой, например, сметы материалов и списки деталей. Типичным представителем иерархической СУБД является СУБД IMS ( Information Management System ) компании IBM , первая версия которой появилась в 1968 г.
На рис.8.1 показан пример схемы иерархической БД . Тип записи ФАКУЛЬТЕТ является предком (родительской или исходной записью) для типов записей КАФЕДРЫ и ДЕКАНАТ, а записи КАФЕДРЫ и ДЕКАНАТ – потомки (дочерние или порожденные записи) для записи ФАКУЛЬТЕТ.
Все экземпляры определенного типа порожденной записи, относящиеся к одному экземпляру исходной записи, называются близнецами. Иерархическая модель реализует отношение между исходной и дочерними записями по схеме один-ко-многим ., то есть одной родительской записи может соответствовать любое число дочерних. В иерархической базе данных существует единственный иерархический путь доступа к любой записи, начиная с корня дерева, т.е. порядок обхода дерева – сверху-вниз, слева-направо. По сути иерархическая модель – ориентированный граф .
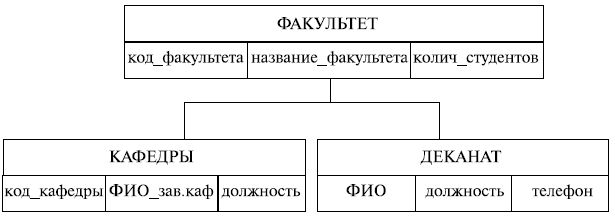
Рис. 8.1. Схема иерархической модели базы данных
В терминологии IMS вместо термина » запись » использовался термин «сегмент», а под термином » запись базы данных » понималось все дерево сегментов. В 1970 году группа CODASYL, которая разрабатывала стандарты для языка COBOL , создала модель под названием DBTG ( Data Base Task Group , группа задач базы данных ). Модель DBTG была готова к представлению как иерархических, так и сетевых данных. Однако эта модель была очень сложной, поэтому не имела большого успеха.
Типичным представителем систем, основанных на сетевой модели данных , является СУБД IDMS (Integrated Database Management System ), разработанная компанией Cullinet Software , Inc. Сетевой подход к организации данных является расширением иерархического подхода. Как и в иерархической модели, связи ведут от родительской записи к дочерней, но на этот раз поддерживается множественное наследование . В сетевой модели допускается несколько исходных записей для одной порожденной записи наряду с возможностью наличия записей без исходной записи (рис.8.2). Другими словами, в сетевой модели любая запись может участвовать в нескольких отношениях предок- потомок . Сетевая модель – неориентированный граф .
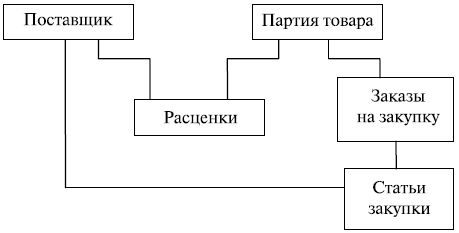
Рис. 8.2. Схема сетевой модели базы данных
Большинство применяемых сегодня баз данных основаны на реляционной модели. Основная идея реляционной модели – представить произвольную структуру данных в виде двумерных таблиц. Наиболее распространенной в настоящее время настольной реляционной базой данных является MS Access, пример которой рассматривается в разделе 6.3.3.
Реляционная модель впервые была предложена Э.Ф. Коддом (E.F. Codd) в 1970 году. Понятие модели данных, введенное Коддом, впоследствии развил Кристофер Дейт. Согласно Дейту, реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части. Данные хранятся в таблицах.
Столбцы таблиц называются полями, а строки – записями. В каждом поле может храниться информация только одного типа. Запросы предназначены для манипулирования данными, содержащимися в базе данных.
Кодд определил правила реляционной модели, которые получили название «12 правил Кодда». Позже Кодд добавил «нулевое» правило.
- Реляционная СУБД должна быть способна полностью управлять базой данных, используя связи между данными.
- Информационное правило: вся информация в реляционной БД, включая имена таблиц и столбцов, должна определяться строго как значения таблиц.
- Гарантированный доступ: любое значение БД должно быть гарантированно доступным через комбинацию имени таблицы, первичный ключ и имя столбца.
- Поддержка нулевого значения: СУБД должна уметь работать с нулевыми (пустыми) значениями. Нулевое значение – это неизвестное, независимое, неприменимое значение, в отличие от значений по умолчанию и обычных значений.
- Активный, оперативный реляционный каталог – описание БД и ее содержимое – должны быть определены на логическом уровне через таблицы, к которым можно применять запросы, используя DML ( Data Manipulation Language – язык манипулирования данными).
- Исчерпывающее подмножество языка данных: по крайней мере, один из поддерживаемых языков должен иметь четко определенный синтаксис и быть самодостаточным. Он должен поддерживать определение данных и манипулирование ими, правила целостности, авторизацию и транзакции.
- Правило обновления представлений: все представления, теоретически обновляемые, могут быть обновлены через систему.
- Вставка, обновление и удаление: СУБД поддерживает не только запрос данных, но и вставку, обновление и удаление.
- Физическая независимость данных: логика программ-приложений остается прежней при изменении физических методов доступа к данным и структур хранения.
- Логическая независимость данных: логика программ-приложений остается прежней, в пределах разумного, при изменении структур таблиц.
- Независимость целостности: язык БД должен быть способен определять ограничения целостности. Они должны быть доступны из оперативного каталога, и не должно быть способа их обойти.
- Независимость распределения: перенос базы данных с одного компьютера на другой компьютер не должен оказывать влияния на запросы программ-приложений. Реляционная СУБД не должна зависеть от потребностей конкретного клиента.
- Согласованность языков всех уровней: низкоуровневый язык доступа к данным не должен игнорировать правила безопасности и целостности, поддерживаемые языком более высокого уровня.
Предложив реляционную модель данных , Э.Ф. Кодд создал и инструмент для удобной работы с отношениями – реляционную алгебру – формальную систему манипулирования отношениями, основными операциями которой являются проекция , соединение, пересечение и объединение .
Реляционное исчисление – это еще одна формальная система , которая манипулирует отношениями. Реляционное исчисление основано на логике первого порядка. Так же как и выражения реляционной алгебры, формулы реляционного исчисления определяются над отношениями реляционных баз данных, и результатом вычисления также является отношение .
Реляционная алгебра и реляционное исчисление имеют одинаковую выражающую мощность ; т. е. все запросы, которые можно сформулировать с помощью реляционной алгебры, могут быть также сформулированы с помощью реляционного исчисления и наоборот. Первым это доказал Э. Ф. Кодд в 1972 году. Это доказательство основано на алгоритме, по которому произвольное выражение реляционного исчисления может быть сокращено до семантически эквивалентного выражения реляционной алгебры. Алгоритм носит название » алгоритм редукции Кодда».
Реляционные базы данных имеют следующие специфические особенности.
- Для каждого поля таблицы базы данных определен тип данных, таким образом нельзя в одно поле разных записей вводить данные разных типов.
- СУБД позволяют не только вводить данные в таблицы, но и контролировать правильность вводимых данных. Имеются в виду не только ограничения по типу данных, но и контроль допустимых значений, количество вводимых знаков и т.п. СУБД не позволит сохранить в записи те данные, которые не удовлетворяют заданным правилам.
- Таблицы баз данных могут включать в себя количество записей, исчисляемое сотнями тысяч, и при этом СУБД обеспечивает удобные способы извлечения нужной информации из этого множества записей.
- Все данные хранятся, независимо от их структуры и содержания, в одном файле, и доступ к этим данным осуществляется постранично, не превышая ограничений на ресурсы компьютера.
- Можно устанавливать связи между таблицами и затем при помощи запросов совместно использовать данные разных таблиц. Данные, полученные в результате запроса, представляются также в виде таблицы.
- Запрос на выборку может быть обращен к одной или нескольким таблицам одновременно. Данные в выборке являются динамическими, т. е. при повторном запуске запроса по измененным данным, выборка изменяется.
- Благодаря установке взаимосвязей между отдельными таблицами удается избежать ненужного дублирования данных, сэкономить память компьютера, а также увеличить скорость обработки информации.
- Большинство баз данных может поддерживать одновременную работу с базой данных нескольких пользователей, при этом все пользователи гарантированно будут работать с актуальными данными.
- По сравнению с другими прикладными пакетами в базах данных имеется развитая система защиты от несанкционированного доступа, которая предоставляет, помимо парольной защиты файла, возможность каждому пользователю или группе пользователей видеть и изменять только те объекты, к которым пользователи имеют право доступа.
При проектировании реляционной базы данных большое внимание уделяется процессу нормализации таблиц. Целью нормализации является создание такого проекта базы данных , где будет исключена избыточность информации, т. е. каждый квант информации будет сохраняться лишь в одном месте. Основное назначение нормализации – исключение возможной противоречивости хранимых данных и экономия памяти. Пренебрежение нормализацией делает структуру базы данных запутанной, а саму базу – ненадежной в работе.
Теория нормализации основывается на наличии той или иной зависимости между полями таблицы. Определены два вида таких зависимостей: функциональные и многозначные.
Поле В таблицы функционально зависит от поля А той же таблицы в том и только в том случае, когда в любой заданный момент времени для каждого из различных значений поля А обязательно существует только одно из различных значений поля В. Отметим, что здесь допускается, что поля А и В могут быть составными.
Поле В находится в полной функциональной зависимости от составного поля А, если оно функционально зависит от А и не зависит функционально от любого подмножества поля А.
Поле А многозначно определяет поле В той же таблицы, если для каждого значения поля А существует определенное множество соответствующих значений В.
Процесс нормализации представляет собой последовательное преобразование исходной БД к нормализованной базе данных путем поэтапного приведения таблиц к нормальным формам (НФ). При этом каждая следующая НФ обязательно включает в себя предыдущую, что позволяет разбить процесс на этапы и производить его однократно, не возвращаясь к предыдущим этапам. Всего в реляционной теории насчитывается 6 нормальных форм: первая нормальная форма ( 1НФ ), вторая нормальная форма (2НФ), третья нормальная форма (3НФ), нормальная форма Бойса-Кодда (НФБК), четвертая нормальная форма (4НФ) и пятая нормальная форма (5НФ).
По существу, таблица находится в 2НФ, если она находится в 1НФ и удовлетворяет, кроме того, некоторым дополнительным условиям. Таблица находится в 3НФ, если она находится в 2НФ и, помимо этого, удовлетворяет другим дополнительным условиям и т.д.
Таблица находится в первой нормальной форме ( 1НФ ) тогда и только тогда, когда ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто.
Таблица находится во второй нормальной форме (2НФ), если она удовлетворяет определению 1НФ и все ее поля, не входящие в первичный ключ , связаны полной функциональной зависимостью с первичным ключом.
Таблица находится в третьей нормальной форме (3НФ), если она удовлетворяет определению 2НФ и ни одно из ее неключевых полей не зависит функционально от любого другого неключевого поля.
Кодд и Бойс обосновали и предложили более строгое определение для 3НФ, которое учитывает, что в таблице может быть несколько ключей. Таблица находится в нормальной форме Бойса-Кодда (НФБК), если и только если любая функциональная зависимость между ее полями сводится к полной функциональной зависимости от возможного ключа.
В следующих нормальных формах (4НФ и 5НФ) учитываются не только функциональные, но и многозначные зависимости между полями таблицы.
В настоящее время практически каждый производитель СУБД предлагает собственный программный продукт автоматизированного проектирования. Это Oracle Designer ( Oracle ), Power Desinger ( Sybase ) и другие. Демонстрационные версии данных программных продуктов можно загрузить с соответствующих сайтов (www.oracle.com, www.sybase.com). Кроме того, для автоматизированного проектирования представлены решения фирм, не производящих СУБД . Наиболее распространенными являются программные продукты фирмы AllFusion – AllFusion ERwin Data Modeler и AllFusion Process Modeler (ранее – BPwin) (см. www.interface.ru).
Выделяют следующие разновидности языков реляционной алгебры:
- dBASe-подобные языки приближены к языкам структурного программирования. Эти языки обеспечивают создание интерфейса пользователя и типовые операции обработки данных;
- графические реляционные языки, ориентированные на конечных пользователей;
- SQL-подобные языки запросов, реализованные в большинстве многопользовательских и распределенных систем управления базами данных.
dBASe-подобные языки используют базы данных dBASe, Paradox, FoxPro, Clipper , Rbase и др.
Типичным представителем графического реляционного языка является язык QBE (Query By Example ), реализованный в среде электронных таблиц, в различных базах данных, например, в MS Access, в пакете Microsoft Query. Этот язык относится к языкам манипулирования данными и имеет простейшие синтаксические конструкции, легко осваиваемые пользователями-непрограммистами.
SQL (Structured Query Language ) применяется при работе с реляционными базами данных в современных СУБД ( ORACLE , dBASE IY, dBASE Y, Paradox, Access и др.). Для отдельных СУБД синтаксис версий языка SQL может различаться.
Язык SQL стал стандартом языков запросов для работы с реляционными базами данных архитектуры «файл- сервер » и «клиент- сервер » и для управления распределенными базами данных. Это реляционно полный язык, предназначенный для работы с базами данных, создания запросов на выборку данных, для выполнения вычислений, для обеспечения целостности баз данных.
Источник: intuit.ru
Путеводитель по базам данных в 2021 г
Данные — это один из наиболее важных компонентов геопространственных технологий и, пожалуй, любой другой отрасли. К управлению данными сейчас относятся серьезно во всех отраслях, поэтому знания по этой дисциплине имеют важное значение для карьеры ИТ-специалистов. Этот цикл статей задуман как универсальное руководство, в котором мы рассмотрим тему от и до, начиная с вопроса «Что такое данные?» и заканчивая изучением и применением геопространственных запросов.

Основные понятия баз данных
Что такое данные?
Данные могут представлять собой любую информацию, которая сохраняется с целью обращения к ней в будущем. Эта информация может включать числа, текст, аудио- и видеоматериалы, местонахождение, даты и т. д. Она может быть записана на бумаге либо сохранена на жестком диске компьютера или даже в облаке.
Что такое база данных?
Множество записей данных, собранных вместе, образуют базу данных. Базы данных обычно создаются для того, чтобы пользователи могли обращаться к большому количеству данных и массово выполнять с ними определенные операции.База данных может хранить что угодно: представьте себе, например, блокнот вашей бабушки со всеми ее вкусными рецептами, учетную книгу ваших родителей, куда они записывают все доходы и расходы, или свою страницу в Facebook со списком всех ваших друзей. Из этих примеров видно, что все данные в базе данных относятся более-менее к одному типу.
Зачем нужна база данных?
Создание базы данных упрощает разным пользователям доступ к наборам информации. Приведенные выше примеры показывают, что в базе данных мы можем хранить записи с информацией похожего типа, но это правда лишь отчасти, поскольку с появлением баз данных NoSQL это определение меняется (подробнее читайте далее в статье).Так как размер веб-сайтов становится все больше и степень их интерактивности все выше, данные о пользователях, клиентах, заказах и т. д. становятся важными активами компаний, которые испытывают потребность в надежной и масштабируемой базе данных и инженерах, способных в ней разобраться.
Система управления базами данных (СУБД)
Итак, мы уже знаем, что данные и базы данных важны, но как осуществляется работа с базами данных в компьютерных системах? Вот тут на сцену и выходит СУБД. СУБД — это программное обеспечение, предоставляющее нам способ взаимодействия с базами данных на компьютере для выполнения различных операций, таких как создание, редактирование, вставка данных и т. д. Для этого СУБД предоставляет нам соответствующие API. Редко какие программы не используют СУБД для работы с данными, хранящимися на диске.Помимо операций с данными СУБД также берет на себя резервное копирование, проверку допуска, проверку состояния базы данных и т. д. Поэтому рекомендуется всегда использовать СУБД при работе с базами данных.
Пространственные данные и база данных
Особое внимание мы уделим обработке пространственных данных, поэтому я хотел бы обсудить здесь этот тип данных. Пространственные данные несколько отличаются от остальных. Координаты необходимо сохранять в особом формате, который обычно указан в документации на веб-сайте о базе данных. Этот формат позволяет базе считывать и правильно воспринимать координаты.
Если обычно для поиска данных мы используем запросы типа Получить все результаты, где возраст > 15, то пространственный запрос выглядит как-то так: Получить все результаты в радиусе 10 км от определенной точки. Поэтому пространственные данные необходимо хранить в надлежащем формате.
Типы баз данных
Базы данных обычно делятся на два типа: реляционные и нереляционные. Оба типа имеют свои плюсы и минусы. Было бы глупо утверждать, что один лучше другого, поскольку это будет зависеть от варианта использования. Конкретно для пространственных данных я в 99 % случаев использую реляционные базы данных, и вы скоро поймете почему.
Реляционные базы данных и РСУБД
Допустим, ваш начальник просит вас создать электронную таблицу с важной информацией, включающей имена, местонахождения, адреса электронной почты, номера телефонов и должности всех сотрудников. Вы сразу же откроете таблицу Excel или Google Spreadsheets, напишете все эти названия столбцов и начнете собирать информацию.
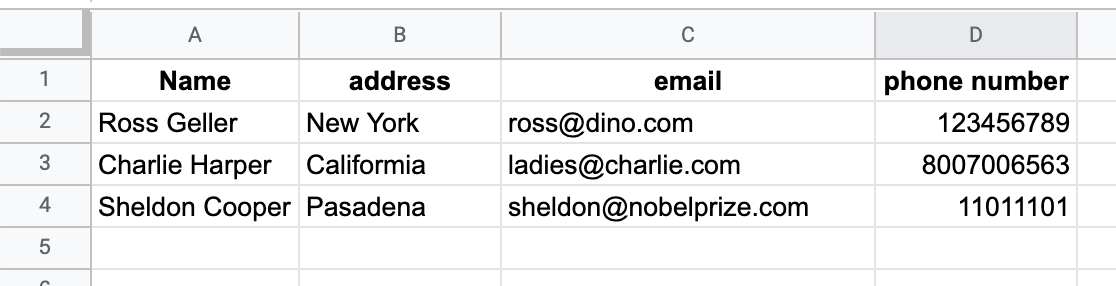
Закономерность здесь заключается в том, что каждая запись содержит ограниченный и фиксированный набор полей, которые нам нужно заполнить. Таким образом мы создали таблицу со всей информацией, где у каждой записи имеется уникальный первичный ключ, который определяет ее однозначным образом и делает ее доступной для всех операций. В реляционных базах данных любая таблица содержит фиксированное количество столбцов, и можно устанавливать связи между разными столбцами.
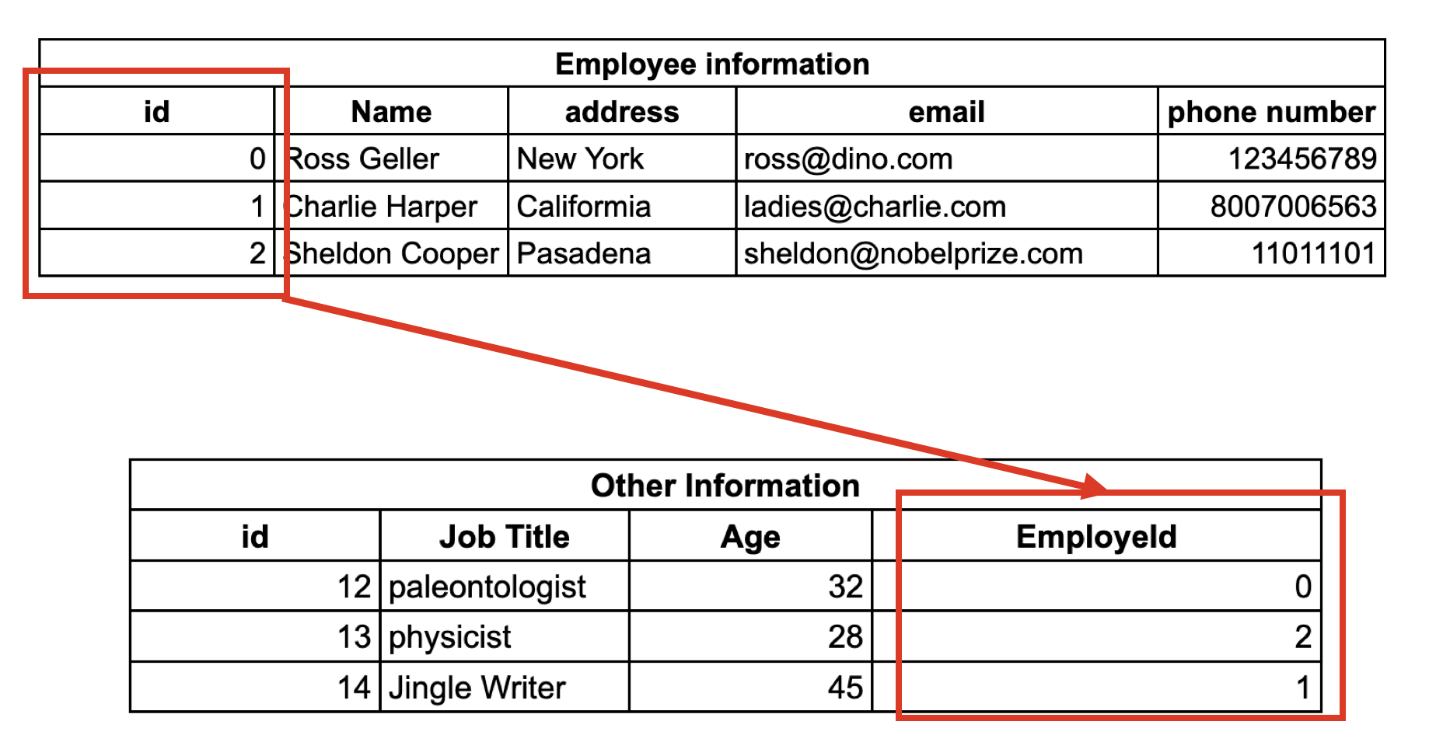
Взаимосвязи в реляционных базах данных мы подробно рассмотрим позже.
По сравнению с базами данных NoSQL, недостатком реляционных баз данных является относительно медленное получение результатов, когда количество данных стремительно увеличивается (по мнению автора статьи — прим. пер.). Еще один недостаток заключается в том, что при добавлении каждой записи нужно следовать определенным правилам (типы столбцов, количество столбцов и т. д.), — мы не можем просто добавить отдельный столбец только для одной записи.В реляционных базах данных используется SQL (Structured Query Language — язык структурированных запросов), с помощью которого пользователи могут взаимодействовать с данными, хранящимися в таблицах. SQL стал одним из наиболее широко используемых языков для этой цели. Мы подробнее поговорим об SQL чуть позже.Вот примеры некоторых известных и часто используемых реляционных баз данных: PostgreSQL, MySQL, MS SQL и т. д. У каждой крупной компании, занимающейся реляционными базами данных, есть собственная версия SQL. В большинстве аспектов они выглядят одинаково, но иногда требуется немного изменить какой-нибудь запрос, чтобы получить те же результаты в другой базе данных (например, при переходе из PostgreSQL в MySQL).
Нереляционные базы данных (NoSQL)
Все базы данных, не являющиеся реляционными, относятся к категории нереляционных баз данных. Обычно данные хранятся в нетабличном формате, например:
- Пара «ключ-значение»
- Формат JSON, XML
- Графовый формат
Основное преимущество баз данных NoSQL состоит в том, что все строки независимы и могут иметь разные столбцы. Как показано на изображении ниже, оба пользователя относятся к одной и той же таблице Core_user, но их записи содержат разную информацию.
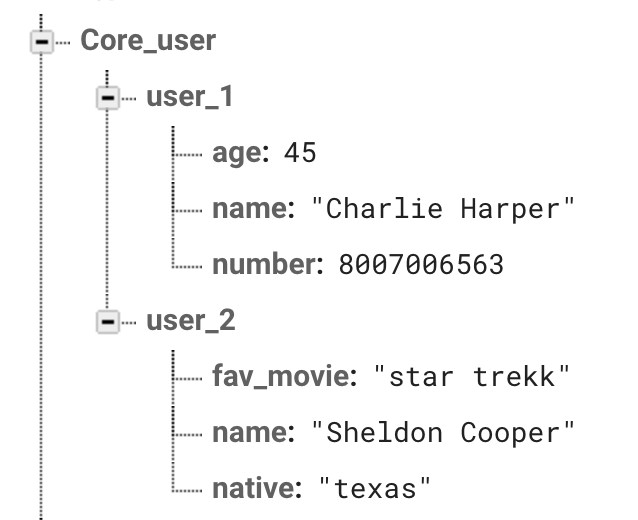
База данных NoSQL реального времени в Google Firebase
При использовании баз данных NoSQL пользователям иногда приходится прописывать собственную логику, чтобы добавить уникальный ключ к каждой записи и тем самым обеспечить доступ к записям. В большинстве стандартных баз данных NoSQL, таких как Firebase и MongoDB, для хранения данных используется формат JSON. Благодаря этому очень легко и удобно выполнять операции с данными из веб-приложений, используя JavaScript, Python, Ruby и т. д.
Рекомендации по выбору типа базы для хранения пространственных данных
Очевидно, что нам хотелось бы сохранить точку, линию, многоугольник, растры и т. д. так, чтобы это имело смысл, вместо того чтобы сохранять просто координаты. Нам нужна СУБД, которая позволяет не только сохранять данные, но и запрашивать их пространственными методами (буфер, пересечение, вычисление расстояния и т. д.).
На сегодняшний день для этого лучше всего подходят реляционные базы данных, поскольку в SQL есть функции, помогающие выполнять подобные операции. Использование таких дополнительных средств, как PostGIS для PostgreSQL, открывает разработчикам возможности для написания сложных пространственных запросов. С другой стороны, NoSQL тоже работает в области геопространственных технологий: например, MongoDB предоставляет кое-какие функции для выполнения геопространственных операций. Однако реляционные базы данных все же лидируют на рынке с большим отрывом.
Работа с РСУБД
Основное внимание мы уделим РСУБД, так как именно эти системы в большинстве случаев мы будем использовать для хранения пространственных данных и работы с ними. В качестве примера мы будем использовать PostgreSQL, поскольку это самая перспективная реляционная база данных с открытым исходным кодом, а ее расширение PostGIS позволяет работать и с пространственными данными.
Вы можете установить PostgreSQL, следуя инструкциям из документации. Помимо PostgreSQL рекомендуется также загрузить и установить pgAdmin. Платформа pgAdmin предоставляет веб-интерфейс для взаимодействия с базой данных. Также для этого можно загрузить и установить какое-либо другое совместимое ПО или использовать командную строку.

Пользователи могут изменять множество настроек для баз данных, включая порт, имя пользователя, пароль, доступность извне, выделение памяти и т. д., но это уже другая тема. В этой статье мы сосредоточимся на работе с данными, находящимися в базе.
Создание базы данных. Нам нужно создать базу данных (в идеале должно быть по одной базе данных для каждого проекта).
В инструменте запросов (Query Tool) база данных создается следующим образом:
CREATE DATABASE
Создание таблиц. Создание таблицы требует некоторых дополнительных соображений, поскольку именно здесь нам нужно определить все столбцы и типы данных в них. Все типы данных, которые можно использовать в PostgreSQL, вы найдете здесь.
pgAdmin позволяет нам выбрать в таблице различные ключи и ограничения, например Not Null (запрет на отсутствующие значения), Primary Key (первичный ключ) и т. д. Обсудим это подробнее чуть позже.
Заметьте, что мы не добавляли столбец первичного идентификатора в список столбцов, поскольку PostgreSQL делает это автоматически. Мы можем создать сколько угодно таблиц в одной базе данных. После того как таблицы созданы, мы можем установить связи между разными таблицами, используя определенные столбцы (обычно столбцы с идентификаторами).В инструменте запросов таблица создается следующим образом:
CREATE TABLE ( , , .. . .. PRIMARY KEY () );
CRUD-операции с данными в таблицах
CRUD-операции (создание, чтение, обновление и удаление — Create, Retrieve, Update, Delete) — это своего рода hello world в мире СУБД. Поскольку эти операции используются наиболее часто, команды для их выполнения одинаковы во всех РСУБД. Мы будем писать и выполнять запросы в инструменте запросов в pgAdmin, который вызывается следующим образом:
1. Создание новой записи
Для добавления новой записи в таблицу используйте следующую команду:
INSERT INTO (column1, column2, column3. ) VALUES (value1, value2, value3. );
INSERT, INTO, VALUE являются ключевыми словами в SQL, поэтому их нельзя использовать в качестве переменных, значений и т. д. Чтобы добавить новую запись в нашу таблицу пользователей, мы напишем в инструменте запросов следующий запрос:
INSERT INTO users(name, employed, address) VALUES (‘Sheldon Cooper’, true, ‘Pasadena’);
Обратите внимание: строки всегда следует заключать в ‘ ‘ (одинарные кавычки), а не в » » (двойные кавычки).
2. Получение записей (всех или нескольких)
Данные, хранящиеся в базе данных, можно извлечь и отобразить на экране. При этом мы можем получить все данные или ограниченное количество записей. Код для получения данных:
select from
Этот код извлекает весь набор данных. Если вы хотите получить только 20 записей, напишите:
select from limit 20
Если вы хотите получить данные из всех столбцов, то вместо перечисления названий всех столбцов можно написать:
select * from
Если вы хотите получить результат с определенным условием, используйте ключевое слово WHERE, как показано ниже:
select * from where =
Вы можете создавать даже сложные запросы, о которых мы поговорим позже.В нашем примере мы можем получить нужные нам данные:
—Retrieving Specific columns for all users select name,employed from users —Retrieving all columns for all users select * from users —Retrieving all columns for first 3 users select * from users limit 3 —Retrieving all columns for all users where employed = true select * from users where employed = true
3. Обновление записей (всех или нескольких)РСУБД позволяет нам обновить все или только некоторые записи данных, указав новые значения для столбцов.
UPDATE SET = , =
Если вы хотите обновить определенные строки, добавьте условия с использованием ключевого слова WHERE:
UPDATE SET = , = WHERE =
В нашем случае мы обновим таблицы с помощью следующих запросов:
— Make all rows as employed = true update users set employed = true — change employed = false for entries with address = ‘nebraska’ update users set employed = false where address = ‘nebraska’
4. Удаление записей (всех или нескольких)Удалять записи в SQL легко. Пользователь может удалить либо все строки, либо только определенные строки, добавив условие WHERE.
— Deleting all entries Delete from — Deleting entries based on conditions Delete from where =
— Deleting all entries Delete from users — Deleting entries based on conditions Delete from users where employed = false
CRUD-операции используются очень часто, поскольку выполняют основные функции в базе данных.
Перевод подготовлен в рамках курса «Базы данных». Все желающих приглашаем на бесплатный двухдневный онлайн-интенсив «Бэкапы и репликация PostgreSQL. Практика применения». Цели занятия: настроить бэкапы; восстановить информацию после сбоя. Регистрация здесь.
- Блог компании OTUS
- Администрирование баз данных
- Big Data
Источник: habr.com
СУБД (система управления базами данных) — виды, классификация и назначение систем в экономике

Эффективность управления зависит от модели информационной обработки. Современные системы управления базами данных (СУБД) часто являются дополнениями Windows, т. к. в этой области комфортно используются ресурсы вычислительной техники, по сравнению со средой DOS. Разработчики не связываются субъективными рамками определенного пакета и применяют дополнительные приложения.
Общее понятие
Основному курсу расширения системы управления и развитию современных средств создания дополнительных инструментов уделяется особое внимание. Эффективная система на предприятии представляет собой унифицированную структуру сведений, которая используется одновременно для решения нескольких задач различными объектами. Функции СУБД заключаются в следующих направлениях:
- получение детализированных или общих отчетов по результатам работы;
- определение курса изменения рабочих показателей;
- получение срочных сведений без задержки;
- полный и точный анализ полученной информации.
Предметной областью называется реальная сфера производства, которая изучается для создания организационного управления с последующей автоматизацией. Объект представляет собой системный элемент, информация о котором присутствует в базе. В некоторых случаях объекты объединяются в классы, если они обладают набором одинаковых компонентов — информационных отражений элементарных характеристик.
Поступление и хранение сведений подчиняется определенным принципам:
- правдивость и целостность информации с обеспечением физической сохранности для исключения несанкционированного доступа и структурных искажений;
- единственность и минимальная избыточность сведений с целью недопущения дублирования операций.
Запись информации представляет собой комплексное сочетание значений, которые характеризуют связанные между собой элементы.
Первичным ключом называется одна или несколько характеристик, которые идентифицируют определенный промышленный элемент. Вторичный ключ предназначен для использования при поиске записей в программе и содержит в основе повторяющиеся значения для похожих объектов.
Системы управления
Комплекс программных и лингвистических инструментов управляет сведениями внешней памяти с помощью дисков. Структура координирует информацию в оперативной памяти с применением дискового кэша. Система проводит изменения в таблицах и производит восстановление и резервное копирование сведений после сбоев.
Современный комплекс управления содержит компоненты:
- ядро, отвечающее за координацию сведений в оперативной и наружной памяти и процесс журнализации;
- процессор языковой информативной базы, который централизует запросы на получение или изменение данных и создает независимый внутренний код для машины;
- внешние утилиты на сервере для обеспечения других рабочих возможностей по обслуживанию управляющей структуры.
По степени охвата числа объектов системы бывают локальные и распределенные. Первый тип СУБД помещается на одном компьютере и может относиться к развернутой системе в качестве отдельного элемента. Распределенные системы содержат несколько серверов и координируют множество подразделений.
Классификация СУБД по доступу к базе
В файл-серверных комплексах хранение данных имеет централизованный характер. Информация находится на каждом компьютере клиента (рабочей точке). Путь к сведениям проходит посредством локальной сети. Синхронизация доступа осуществляется файловыми блокировками, при такой структуре на процессор оказывается слабая нагрузка. В качестве примера можно привести Paradox, Microsoft Access, Fox Pro Visual.
К недостаткам относится:

- высокая локальная мощность;
- ограниченная возможность центрального управления с местных серверов;
- невысокая надежность;
- общедоступность и слабая безопасность.
Клиент-серверные системы в информатике имеют назначение для непосредственного доступа к базе в монопольном режиме. Структура централизованно обрабатывает запросы на обработку. В этом управляющем комплексе снижается локальная мощность, повышается возможность координации и снижается опасность взлома или выхода из строя. К недостаткам относится повышенное требование к серверным параметрам. Примером служат модели: Interbase, Infjrmix, SQL Postgre, Oracle.
Отличие встраиваемых структур состоит в том, что они являются частью программы и не предполагают самостоятельной установки. Эта система находит применение в качестве хранилища собственных приложений и не используется для массового доступа. Такие комплексы реализуются как виды СУБД в форме бесплатных библиотек. Доступ организовывается посредством создания программных интерфейсов. Примером служат системы SQLite, Firebird Embedded, Compact Server, Open Edge.
По модели информационной основы
Иерархическая база разрабатывается в форме древовидной структуры, в которую включаются объекты различных уровней и подсистем. Между элементами присутствуют связи, компоненты отличаются числом потомков (объектов дальнего расположения от корня). Звенья с общим первоначальным объектом носят название близнецов. Примером служит иерархический базис с корневым каталогом, в котором есть список файлов и подкаталогов.
Сетевые системы по структуре недалеко уходят от иерархических моделей. Сущность отличий состоит в том, что в каталоге применяются указатели поиска в обоих направлениях. Такие индикаторы соединяют сведения, которые относятся к родственным категориям.
Реляционные приложения связываются с базовой системой посредством зависимых связей. Целью разработки модели является уход от недостатков структурной основы. Управляющий комплекс реляционного типа не допускает избыточности информации, ведущей к аномальному искажению результатов деятельности и нарушению целостности сведений.

Классификатор выделяет тип модели в виде объектно-ориентированной системы. Сведения группируются в виде элементов и их характеристик, методов взаимодействия. Этот тип системы работает с базовыми объектами аналогично области программирования, расширяет языки утилиты. Модель позволяет просматривать информацию длительного хранения, проводить параллели между элементами, восстанавливать потерянные сведения.
Объектно-реляционные системы позволяют выделить в результате запроса классы элементов, отдельные объекты, иерархическое расположение. Часто такие модели почти не отличаются от реляционных комплексов.
Использование внешней памяти
Системы с непосредственным проведением информации предполагают немедленную фиксацию записей во внешнем пространстве в случае поступления подтвердительного сигнала различной транзакции. Стратегия применяется только при высоких рабочих параметрах наружного хранилища.
СУБД с функцией отложенной фиксации сохраняет поступающие сведения в кулуарах внешней памяти до установления следующих условий:

- Появления контрольного знака.
- Окончания объема внешнего устройства, которое отводится под регистрацию. В этом случае система систематизирует информацию и пишет журнал сначала.
- Выявления недостатка оперативки при работе буферных отделов внешней памяти.
В результате обмен между центром и наружным хранилищем становится реже, что ведет к увеличению эффективности. Программные продукты подразделяются на промышленные системы и персональные модели.
Профессиональные комплексы
Промышленные модели управления являются основой для автоматизации координирующей системы крупных объектов экономики. На базе профессиональных структур разрабатываются комплексы обработки сведений крупной банковской системы, предприятий или отраслей.
Крупные автоматизированные модели управления должны отвечать условиям:
- иметь возможность пропорционального расширения в случае развития подконтрольного объекта;
- быть универсальными, т. е. переноситься на различные программные серверы;
- сопротивляться сбоям и перегрузкам;
- иметь многоуровневую разветвленность сохраняемых сведений;
- обеспечивать безопасность информации и контролировать уровень доступа пользователя.
Промышленные системы имеют богатую историю создания. В 70−80 годах популярностью пользовалась модель СУБД Adabas. Сейчас используются управляющие комплексы DB 2, Oracle, Sybase, Progress. Перечисленные системы отличаются универсальностью и определяют курс развития иных продуктов информатики.
Персональные программы
Такое обеспечение применяется для решения локальных задач одним пользователем или небольшой группой. Работа ведется с персонального устройства (компьютера).
Настольные ЭВМ отличаются характеристиками:

- простота в работе, позволяющая разрабатывать действенные приложения для опытных пользователей и новичков;
- ограниченные требования к настольным ресурсам и программному обеспечению.
В последнее время отмечается тенденция к удалению граней между профессиональными и настольными моделями. Это объясняется конкуренцией производителей, которые расширяют комплекс функциональных характеристик продукта в угоду увеличения возможностей пользователя.
Современные технологии
При разработке программ используется прием, когда приложение программы делится на клиентскую часть и управляющий сервер. Первый компонент представляет собой пользовательский интерфейс, который видит работник. Сущность второго понятия заключается в сборе, хранении и применении информации, координировании безопасности.
Взаимодействие двух частей начинается после формирования запроса пользователя к базе. Клиентская секция направляет интерпелляцию к серверу, который выполняет команду. Результат обработки отправляется на персональное устройство клиента. Если управление исключает вариант клиент-сервер, то снижается производительность получения информации. Это происходит из-за необходимости копирования файла на личную ЭВМ с последующей обработкой.

Технология обеспечивает пользователю просмотр удобного интерфейса и получение результата запроса в удобной форме. При этом есть возможность применения нескольких взаимосвязанных приложений. Например, в области Access могут использоваться возможности построения таблиц или диаграмм в программе Excel, а отчет клиент получает в виде текста из Word.
Используется технология SQL — язык для создания запросов в структурированной форме. Модель применяется для обработки основных информативных сведений, которые содержатся в базах других приложений. Данные обрабатываются как на персональном устройстве, так и в базах основного сервера.
Применение в экономике
Программное обеспечение для координации деятельности помогает решать разнообразные и масштабные задачи. На основе базовой модели создаются автоматизированные комплексы управления предприятий разной величины. СУБД лежит в основе программного обеспечения для бухгалтеров, например, «Парус», «1С Бухгалтерия» и других. Управляющие структуры используются для анализа и прогнозирования отраслевого расширения и развития государственной экономики.

Автоматизированные системы информации (АИС) стали применяться с шестидесятых годов в военно-промышленной отрасли, где накопилось множество полезных сведений. Вначале данные хранились и обрабатывались в форме чисел, но затем появилась возможность учета с применением естественного языка.
Документальные системы используются для обработки бумаг, популярными являются поисковые системы для подборки по запросам пользователя. В документальных базах есть сведения графического, текстового, звукового типа. Примером служит информативная база в области уголовного делопроизводства.
Фактографические структуры используют фактические данные, сохраненные в формализованной категории. Такие комплексы работают при складском учете товаров, начислении оплаты труда, производственной деятельности. Простые запросы обрабатываются моментально, а аналитические процессы выдаются через определенный промежуток времени.
Источник: nauka.club