
Файлы позволяют пользователю считывать большие объемы данных непосредственно с диска, не вводя их с клавиатуры. Существуют два основных типа файлов: текстовые и двоичные.
Текстовыми называются файлы, состоящие из любых символов. Они организуются по строкам, каждая из которых заканчивается символом «конца строки». Конец самого файла обозначается символом «конца файла». При записи информации в текстовый файл, просмотреть который можно с помощью любого текстового редактора, все данные преобразуются к символьному типу и хранятся в символьном виде.
В двоичных файлах информация считывается и записывается в виде блоков определенного размера, в которых могут храниться данные любого вида и структуры.
Для работы с файлами используются специальные типы данных, называемые потоками. Поток ifstream служит для работы с файлами в режиме чтения, а ofstream в режиме записи. Для работы с файлами в режиме как записи, так и чтения служит поток fstream.
В программах на C++ при работе с текстовыми файлами необходимо подключать библиотеки iostream и fstream.
FolderMenu — доступ к файлам и папкам
Для того чтобы записывать данные в текстовый файл, необходимо:
- описать переменную типа ofstream.
- открыть файл с помощью функции open.
- вывести информацию в файл.
- обязательно закрыть файл.
Для считывания данных из текстового файла, необходимо:
- описать переменную типа ifstream.
- открыть файл с помощью функции open.
- считать информацию из файла, при считывании каждой порции данных необходимо проверять, достигнут ли конец файла.
- закрыть файл.
Запись информации в текстовый файл
Как было сказано ранее, для того чтобы начать работать с текстовым файлом, необходимо описать переменную типа ofstream. Например, так:
ofstream F;
Будет создана переменная F для записи информации в файл. На следующим этапе файл необходимо открыть для записи. В общем случае оператор открытия потока будет иметь вид:
F.open(«file», mode);
Здесь F — переменная, описанная как ofstream, file — полное имя файла на диске, mode — режим работы с открываемым файлом. Обратите внимание на то, что при указании полного имени файла нужно ставить двойной слеш. Для обращения, например к файлу accounts.txt, находящемуся в папке sites на диске D, в программе необходимо указать: D:\sites\accounts.txt.
Файл может быть открыт в одном из следующих режимов:
- ios::in — открыть файл в режиме чтения данных; режим является режимом по умолчанию для потоков ifstream;
- ios::out — открыть файл в режиме записи данных (при этом информация о существующем файле уничтожается); режим является режимом по умолчанию для потоков ofstream;
- ios::app — открыть файл в режиме записи данных в конец файла;
- ios::ate — передвинуться в конец уже открытого файла;
- ios::trunc — очистить файл, это же происходит в режиме ios::out;
- ios::nocreate — не выполнять операцию открытия файла, если он не существует;
- ios::noreplace — не открывать существующий файл.
Параметр mode может отсутствовать, в этом случае файл открывается в режиме по умолчанию для данного потока.
Этому файлу не сопоставлена программа — решение
После удачного открытия файла (в любом режиме) в переменной F будет храниться true, в противном случае false. Это позволит проверить корректность операции открытия файла.
Открыть файл (в качестве примера возьмем файл D:\sites\accounts.txt) в режиме записи можно одним из следующих способов:
1
2
3
4
5
6
7
8
9
10
//первый способ
ofstream F ;
F. open ( «D: \ sites\accounts.txt» , ios :: out ) ;
//второй способ, режим ios::out является режимом по умолчанию
//для потока ofstream
ofstream F ;
F. open ( «D: \ game \ noobs.txt» ) ;
//третий способ объединяет описание переменной и типа поток
//и открытие файла в одном операторе
ofstream F ( «D: \ game \ noobs.txt» , ios :: out ) ;
После открытия файла в режиме записи будет создан пустой файл, в который можно будет записывать информацию.
Если вы хотите открыть существующий файл в режиме дозаписи, то в качестве режима следует использовать значение ios::app.
После открытия файла в режиме записи, в него можно писать точно так же, как и на экран, только вместо стандартного устройства вывода cout необходимо указать имя открытого файла.
Например, для записи в поток F переменной a, оператор вывода будет иметь вид:
Для последовательного вывода в поток G переменных b, c, d оператор вывода станет таким:
Закрытие потока осуществляется с помощью оператора:
F.close();
В качестве примера рассмотрим следующую задачу.
Задача 1
Создать текстовый файл D:\sites\accounts.txt и записать в него n вещественных чисел.
Решение
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#include «stdafx.h»
#include
#include
#include
using namespace std ;
int main ( )
<
setlocale ( LC_ALL, «RUS» ) ;
int i, n ;
double a ;
//описывает поток для записи данных в файл
ofstream f ;
//открываем файл в режиме записи,
//режим ios::out устанавливается по умолчанию
f. open ( «D: \ sites \ accounts.txt» , ios :: out ) ;
//вводим количество вещественных чисел
cout > n ;
//цикл для ввода вещественных чисел
//и записи их в файл
for ( i = 0 ; i < n ; i ++ )
<
cout //ввод числа
cin >> a ;
f >
//закрытие потока
f. close ( ) ;
system ( «pause» ) ;
return 0 ;
>
Чтение информации из текстового файла
Для того чтобы прочитать информацию из текстового файла, необходимо описать переменную типа ifstream. После этого нужно открыть файл для чтения с помощью оператора open. Если переменную назвать F, то первые два оператора будут такими:
ifstream F ;
F. open ( «D: \ sites \ accounts.txt» , ios :: in ) ;
После открытия файла в режиме чтения из него можно считывать информацию точно так же, как и с клавиатуры, только вместо cin нужно указать имя потока, из которого будет происходить чтение данных.
Например, для чтения данных из потока F в переменную a, оператор ввода будет выглядеть так:
F>>a;
Два числа в текстовом редакторе считаются разделенными, если между ними есть хотя бы один из символов: пробел, табуляция, символ конца строки. Хорошо, когда программисту заранее известно, сколько и какие значения хранятся в текстовом файле. Однако часто известен лишь тип значений, хранящихся в файле, при этом их количество может быть различным.
Для решения данной проблемы необходимо считывать значения из файла поочередно, а перед каждым считыванием проверять, достигнут ли конец файла. А поможет сделать это функция F.eof(). Здесь F — имя потока функция возвращает логическое значение: true или false, в зависимости от того достигнут ли конец файла.
Следовательно, цикл для чтения содержимого всего файла можно записать так:
1
2
3
4
5
6
7
8
9
//организуем для чтения значений из файла, выполнение
//цикла прервется, когда достигнем конец файла,
//в этом случае F.eof() вернет истину
while ( ! F. eof ( ) )
<
//чтение очередного значения из потока F в переменную a
F >> a ;
//далее идет обработка значения переменной a
>
Для лучшего усвоения материала рассмотрим задачу.
Задача 2
В текстовом файле D:\game\accounts.txt хранятся вещественные числа, вывести их на экран и вычислить их количество.
Решение
#include «stdafx.h»
#include
#include
#include
#include
using namespace std ;
int main ( )
<
setlocale ( LC_ALL, «RUS» ) ;
int n = 0 ;
float a ;
fstream F ;
//открываем файл в режиме чтения
F. open ( «D: \ sites \ accounts.txt» ) ;
//если открытие файла прошло корректно, то
if ( F )
<
//цикл для чтения значений из файла; выполнение цикла прервется,
//когда достигнем конца файла, в этом случае F.eof() вернет истину.
while ( ! F. eof ( ) )
<
//чтение очередного значения из потока F в переменную a
F >> a ;
//вывод значения переменной a на экран
cout //увеличение количества считанных чисел
n ++ ;
>
//закрытие потока
F. close ( ) ;
//вовод на экран количества считанных чисел
cout >
//если открытие файла прошло некорректно, то вывод
//сообщения об отсутствии такого файла
else cout system ( «pause» ) ;
return 0 ;
>
На этом относительно объемный урок по текстовым файлам закончен. В следующей статье будут рассмотрены методы манипуляции, при помощи которых в C++ обрабатываются двоичные файлы.
Источник: kvodo.ru
unixforum.org
Как при наборе адреса http://yandex.ru просмотреть к каким файлам обращается процесс google-chrome? Желательно список файлов, только отвечающих за вызов конкретного урла, а не все файлы, включае даже которые используется сам браузер, помимо гугл хром.
Спасибо сказали:
serzh-z Бывший модератор Сообщения: 8256 Статус: Маньяк ОС: Arch, Fedora, Ubuntu Контактная информация:
Re: К каким файлам обращается процесс?
Сообщение serzh-z » 22.04.2014 15:53
strace, ltrace и «grep open» в помощь.
Либо F12 и вкладка Network.
Спасибо сказали:
aleksnsk Сообщения: 180
Re: К каким файлам обращается процесс?
Сообщение aleksnsk » 22.04.2014 16:06
Google Chrome F12 вкладка network.
Спасибо!
Спасибо сказали:
drBatty Сообщения: 8735 Статус: GPG ID: 4DFBD1D6 дом горит, козёл не видит. ОС: Slackware-current Контактная информация:
Re: К каким файлам обращается процесс?
Сообщение drBatty » 23.04.2014 08:22
22.04.2014 15:40
Как при наборе адреса http://yandex.ru просмотреть к каким файлам обращается процесс google-chrome? Желательно список файлов, только отвечающих за вызов конкретного урла, а не все файлы, включае даже которые используется сам браузер, помимо гугл хром.
сначала узнайте PID, потом
lsof -p $PID
«файлы конкретного урла» === /0.
Скоро придёт
Осень
Спасибо сказали:
eddy Сообщения: 3321 Статус: Красный глаз тролля ОС: ArchLinux Контактная информация:
Re: К каким файлам обращается процесс?
Сообщение eddy » 23.04.2014 08:58
23.04.2014 08:22
«файлы конкретного урла»
Видимо, сокеты и фифо имелись в виду. Хотя, первые файлами назвать как-то язык не поворачивается.
А еще есть fuser. Похоже, то же самое делает, что lsof -p.
Ну и всегда можно просто взять, да просканировать дерево нужного процесса в /proc вручную (чем собственно эти lsof/fuser и занимаются).
RTFM
——-
KOI8-R — патриотичная кодировка
Спасибо сказали:
drBatty Сообщения: 8735 Статус: GPG ID: 4DFBD1D6 дом горит, козёл не видит. ОС: Slackware-current Контактная информация:
Re: К каким файлам обращается процесс?
Сообщение drBatty » 23.04.2014 10:33
23.04.2014 08:58
Видимо, сокеты и фифо имелись в виду. Хотя, первые файлами назвать как-то язык не поворачивается.
почему «не поворачивается»?
23.04.2014 08:58
да просканировать дерево нужного процесса в /proc вручную (чем собственно эти lsof/fuser и занимаются).
можно и вручную конечно.
Скоро придёт
Осень
Спасибо сказали:
eddy Сообщения: 3321 Статус: Красный глаз тролля ОС: ArchLinux Контактная информация:
Re: К каким файлам обращается процесс?
Сообщение eddy » 23.04.2014 13:56
23.04.2014 10:33
почему «не поворачивается»?
Потому что у сокета нет инода на ФС. А у фифо обычно есть (правда, он тоже ему не нужен — имя файла для фифо задают лишь для упрощения работы ведру, буферы-то все равно на диск не сбрасываются!).
Хотя, с другой стороны, в /dev/, /proc/ и /sys/ вообще псевдофайлы валяются, которые к реальным файлам никакого отношения не имеют.
RTFM
——-
KOI8-R — патриотичная кодировка
Спасибо сказали:
drBatty Сообщения: 8735 Статус: GPG ID: 4DFBD1D6 дом горит, козёл не видит. ОС: Slackware-current Контактная информация:
Re: К каким файлам обращается процесс?
Сообщение drBatty » 23.04.2014 14:04
23.04.2014 13:56
Потому что у сокета нет инода на ФС.
дык он и не на ФС.
Скоро придёт
Осень
Спасибо сказали:
serzh-z Бывший модератор Сообщения: 8256 Статус: Маньяк ОС: Arch, Fedora, Ubuntu Контактная информация:
Re: К каким файлам обращается процесс?
Сообщение serzh-z » 23.04.2014 14:36
Господа пейсатели, поднимите глаза на первые посты и немного почитайте.
Спасибо сказали:
drBatty Сообщения: 8735 Статус: GPG ID: 4DFBD1D6 дом горит, козёл не видит. ОС: Slackware-current Контактная информация:
Re: К каким файлам обращается процесс?
Сообщение drBatty » 23.04.2014 15:27
Скоро придёт
Осень
Спасибо сказали:
MrClon Сообщения: 838 ОС: Ubuntu 10.04, Debian 7 и 6
Re: К каким файлам обращается процесс?
Сообщение MrClon » 23.04.2014 15:34
23.04.2014 15:27
За тем что человеку похоже нужны были сетевые обращения и он уже всецело удовлетворён хромовскими «инструментами разработчика»
Спасибо сказали:
aleksnsk Сообщения: 180
Re: К каким файлам обращается процесс?
Сообщение aleksnsk » 26.04.2014 17:12
23.04.2014 15:34
23.04.2014 15:27
За тем что человеку похоже нужны были сетевые обращения и он уже всецело удовлетворён хромовскими «инструментами разработчика»
нет нужны именно обращения к каким файлам на конкретно, указанный урл.
Спасибо сказали:
MrClon Сообщения: 838 ОС: Ubuntu 10.04, Debian 7 и 6
Re: К каким файлам обращается процесс?
Сообщение MrClon » 27.04.2014 00:59
26.04.2014 17:12
нет нужны именно обращения к каким файлам на конкретно, указанный урл.
В контексте http нет никаких файлов, есть URLы к которым клиент отправляет GET и POST запросы получая в ответ какие-то данные (html страницы, картинки, архивы, что угодно).
Спасибо сказали:
drBatty Сообщения: 8735 Статус: GPG ID: 4DFBD1D6 дом горит, козёл не видит. ОС: Slackware-current Контактная информация:
Re: К каким файлам обращается процесс?
Сообщение drBatty » 28.04.2014 12:26
26.04.2014 17:12
нет нужны именно обращения к каким файлам на конкретно, указанный урл.
ещё раз повторю
23.04.2014 08:22
«файлы конкретного урла» === /0.
27.04.2014 00:59
В контексте http нет никаких файлов, есть URLы к которым клиент отправляет GET и POST запросы получая в ответ какие-то данные (html страницы, картинки, архивы, что угодно).
Дополню, что есть типа «файлов», называется «сетевые сокеты». Такие точки входа «в сеть». Но я уверен, что для вас ТС, они бесполезны. Ну я уже сказал: lsof -p PID их показывает.
если под рукой есть Linux prog. man, читайте man 2 socket, там ещё есть see also
accept(2), bind(2), connect(2), fcntl(2), getpeername(2), getsockname(2), getsockopt(2),
ioctl(2), listen(2), read(2), recv(2), select(2), send(2), shutdown(2), socketpair(2),
write(2), getprotoent(3), ip(7), socket(7), tcp(7), udp(7), unix(7)
Скоро придёт
Осень
Источник: unixforum.org
Команда strace в Linux
В операционной системе и используемых в ней программах иногда возникают ошибки, причину которых очень сложно понять, анализируя файлы журналов и сообщения об ошибках. Но и для таких ситуаций в Linux есть средства. За процессом работы любой из программ можно проследить, наблюдая системные вызовы, которые использует программа.
С помощью системных вызовов можно понять, к каким файлам обращается программа, какие сетевые порты она использует, какие ресурсы ей нужны, а также какие ошибки возвращает ей система. Это помогает разобраться в особенностях работы программы и лучше понять причину ошибки. За всё это отвечает команда strace Linux. В сегодняшней статье мы разберёмся, что она из себя представляет и как ею пользоваться.
Команда strace Linux
Как я уже сказал, команда strace показывает все системные вызовы программы, которые та отправляет к системе во время выполнения, а также их параметры и результат выполнения. Но при необходимости можно подключиться и к уже запущенному процессу. Перед тем, как перейти к практике, разберём опции утилиты и её синтаксис:
$ strace опции команда аргументы
В самом простом варианте strace запускает переданную команду с её аргументами и выводит в стандартный поток ошибок все системные вызовы команды. Давайте разберём опции утилиты, с помощью которых можно управлять её поведением:
- -i — выводить указатель на инструкцию во время выполнения системного вызова;
- -k — выводить стек вызовов для отслеживаемого процесса после каждого системного вызова;
- -o — выводить всю информацию о системных вызовах не в стандартный поток ошибок, а в файл;
- -q — не выводить сообщения о подключении о отключении от процесса;
- -qq — не выводить сообщения о завершении работы процесса;
- -r — выводить временную метку для каждого системного вызова;
- -s — указать максимальный размер выводимой строки, по умолчанию 32;
- -t — выводить время суток для каждого вызова;
- -tt — добавить микросекунды;
- -ttt — добавить микросекунды и количество секунд после начала эпохи Unix;
- -T — выводить длительность выполнения системного вызова;
- -x — выводить все не ASCI-строки в шестнадцатеричном виде;
- -xx — выводить все строки в шестнадцатеричном виде;
- -y — выводить пути для файловых дескрипторов;
- -yy — выводить информацию о протоколе для файловых дескрипторов;
- -c — подсчитывать количество ошибок, вызовов и время выполнения для каждого системного вызова;
- -O — добавить определённое количество микросекунд к счетчику времени для каждого вызова;
- -S — сортировать информацию выводимую при опции -c. Доступны поля time, calls, name и nothing. По умолчанию используется time;
- -w — суммировать время между началом и завершением системного вызова;
- -e — позволяет отфильтровать только нужные системные вызовы или события;
- -P — отслеживать только системные вызовы, которые касаются указанного пути;
- -v — позволяет выводить дополнительную информацию, такую как версии окружения, статистику и так далее;
- -b — если указанный системный вызов обнаружен, трассировка прекращается;
- -f — отслеживать также дочерние процессы, если они будут созданы;
- -ff — если задана опция -o, то для каждого дочернего процесса будет создан отдельный файл с именем имя_файла.pid.
- -I — позволяет блокировать реакцию на нажатия Ctrl+C и Ctrl+Z;
- -E — добавляет переменную окружения для запускаемой программы;
- -p — указывает pid процесса, к которому следует подключиться;
- -u — запустить программу, от имени указанного пользователя.
Вы знаете основные опции strace, но чтобы полноценно ею пользоваться, нужно ещё разобраться с системными вызовами, которые используются чаще всего. Мы не будем рассматривать все, а только основные. Многие из них вы уже и так знаете, потому что они называются так же, как и команды в терминале:
- fork — создание нового дочернего процесса;
- read — попытка читать из файлового дескриптора;
- write — попытка записи в файловый дескриптор;
- open — открыть файл для чтения или записи;
- close — закрыть файл после чтения или записи;
- chdir — изменить текущую директорию;
- execve — выполнить исполняемый файл;
- stat — получить информацию о файле;
- mknod — создать специальный файл, например, файл устройства или сокет;
А теперь разберём примеры strace Linux.
Примеры использования Strace
1. Запуск программы
Самый простой способ запуска утилиты — просто передать ей в параметрах имя команды или исполняемый файл программы, которую мы хотим исследовать. Например, uname:
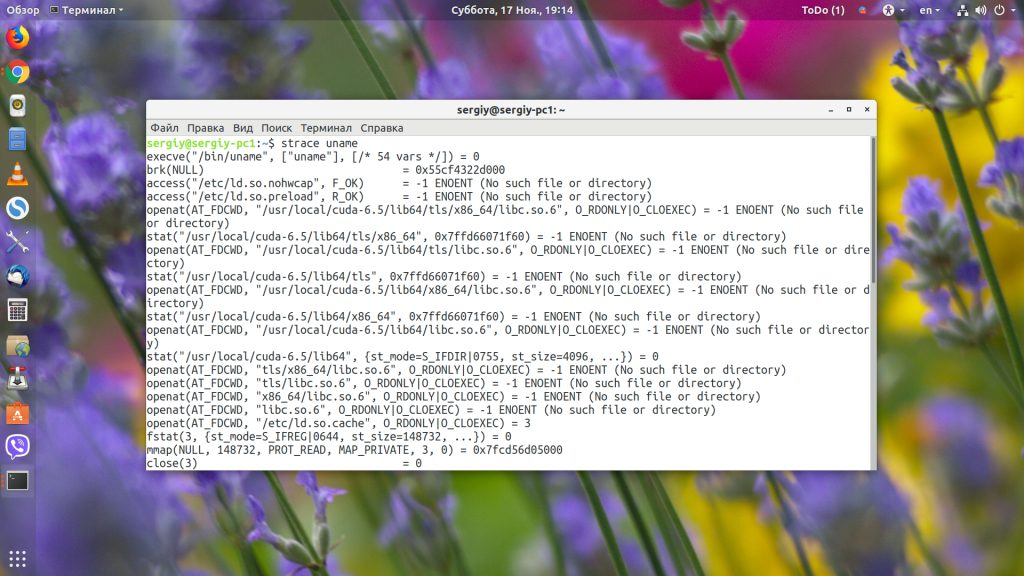
Как и ожидалось, мы видим список системных вызовов, которые делает утилита, чтобы узнать версию ядра. Синтаксис вывода такой:
имя_системного_вызова ( параметр1 , параметр2 ) = результат сообщение
Имя системного вызова указывает, какой именно вызов использовала программа. Для большинства вызовов характерно то, что им нужно передавать параметры, имена файлов, данные и так далее. Эти параметры передаются в скобках. Далее идет знак равенства и результат выполнения. Если всё прошло успешно, то здесь будет ноль или положительное число.
Если же возвращается отрицательное значение, делаем вывод, что произошла ошибка. В таком случае выводится сообщение.
Например, в нашем выводе есть сообщения об ошибке:
openat(AT_FDCWD, «/usr/local/cuda-6.5/lib64/tls/x86_64/libc.so.6», O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
Здесь результат выполнения -1 и сообщение говорит, что файл не найден. Но на работу программы это не влияет. Это проблема подключения сторонних библиотек и к этой утилите она не имеет отношения. А основная работа программы выполняется строчкой:
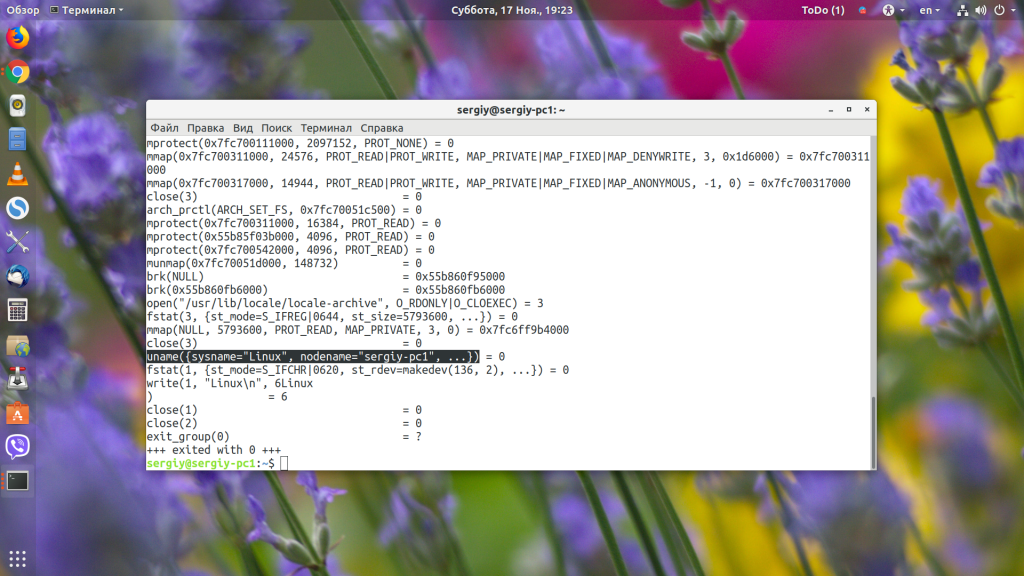
И здесь ядро вернуло положительный результат.
2. Подключение к запущенной программе
Если программа, которую нам надо отследить, уже запущена, то не обязательно её перезапускать с нашей утилитой. Можно подключиться к ней по ее идентификатору PID. Для тестирования этой возможности запустим утилиту dd, которая будет записывать нули из /dev/zero в файл file1:
dd if=/dev/zero of=~/file1
Теперь узнаем PID нашего процесса, поскольку он такой один, можно воспользоваться pidof, вы же можете использовать ps:
И осталось подключиться к нашему процессу:
sudo strace -p 31796
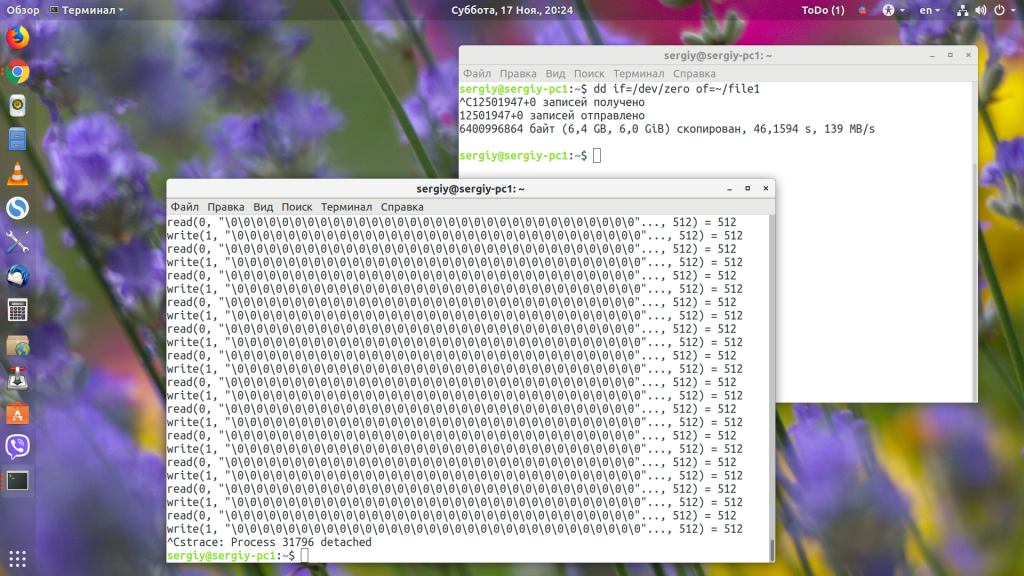
В выводе утилиты мы видим, что она читает данные из одного места с помощью вызова read и записывает в другое через write. Чтобы отсоединится от процесса, достаточно нажать Ctrl+C. Дальше рассмотрим примеры strace Linux для фильтрации данных.
3. Фильтрация системных вызовов
Утилита выводит слишком много данных, и, зачастую, большинство из них нас не интересуют. С помощью опции -e можно применять различные фильтры для более удобного поиска проблемы. Мы можем отобразить только вызовы stat, передав в опцию -e такой параметр trace=stat:
sudo strace -e trace=stat nautilus
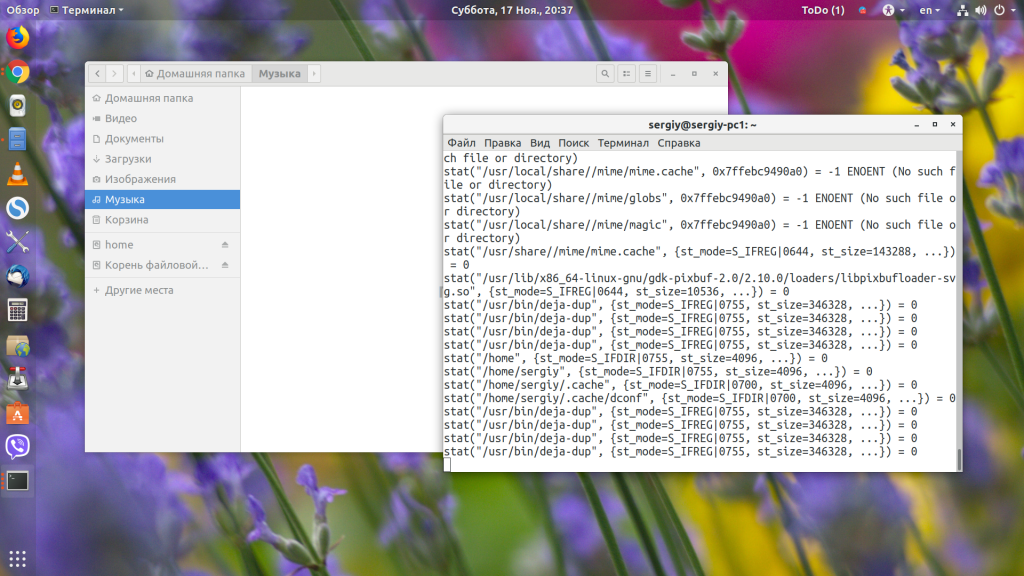
Кроме непосредственно системных вызовов, в качестве параметра для trace можно передавать и такие значения:
- file — все системные вызовы, которые касаются файлов;
- process — управление процессами;
- network — сетевые системные вызовы;
- signal — системные вызовы, что касаются сигналов;
- ipc — системные вызовы IPC;
- desc — управление дескрипторами файлов;
- memory — работа с памятью программы.
4. Возвращение ошибки
Можно попросить strace вернуть программе ошибку по нужному системному вызову -e, но с параметром fault. Синтаксис конструкции такой:
fault = имя_вызова : error = тип_ошибки : when = количество
С именем вызова всё понятно, тип ошибки, номер ошибки, которую надо вернуть. А с количеством всё немного сложнее. Есть три варианта:
- цифра — вернуть ошибку только после указанного количества запросов;
- цифра+ — вернуть ошибку после указанного количества запросов и для всех последующих;
- цифра+шаг — вернуть ошибку для указанного количества и для последующих с указанным шагом.
Например, сообщим uname, что системного вызова uname не существует:
sudo strace -e fault=uname uname
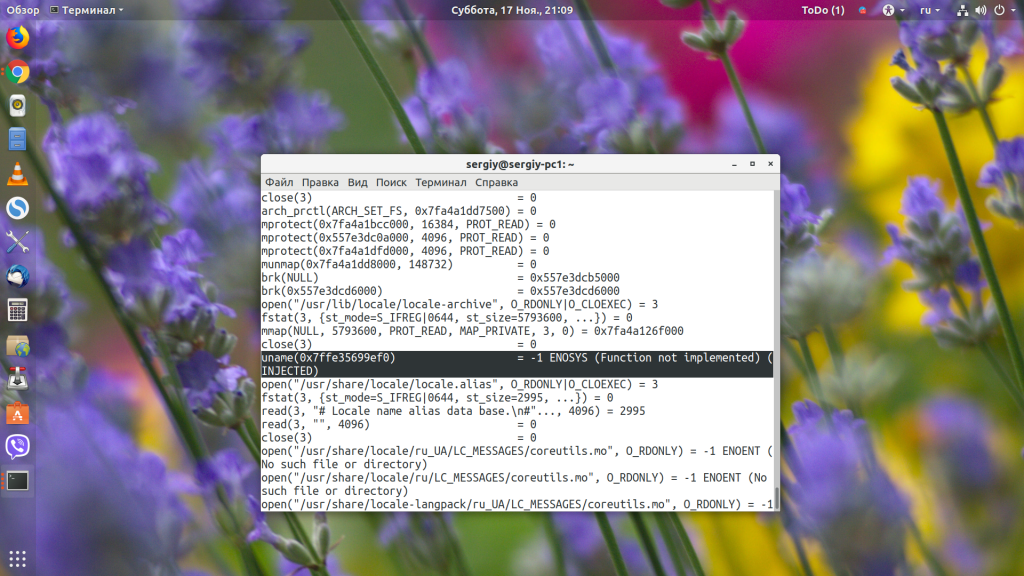
В выводе видим, что система вернула программе нашу ошибку, а потом та с помощью вызова write говорит пользователю, что узнать версию и называние системы невозможно.
5. Фильтрация по пути
Если вас интересует не определённый вызов, а все операции с нужным файлом, то можно выполнить фильтрацию по нему с помощью опции -P. Например, меня интересует, действительно ли утилита lscpu обращается к файлу /proc/cpuinfo, чтобы узнать информацию о процессоре:
strace -P /proc/cpuinfo lscpu
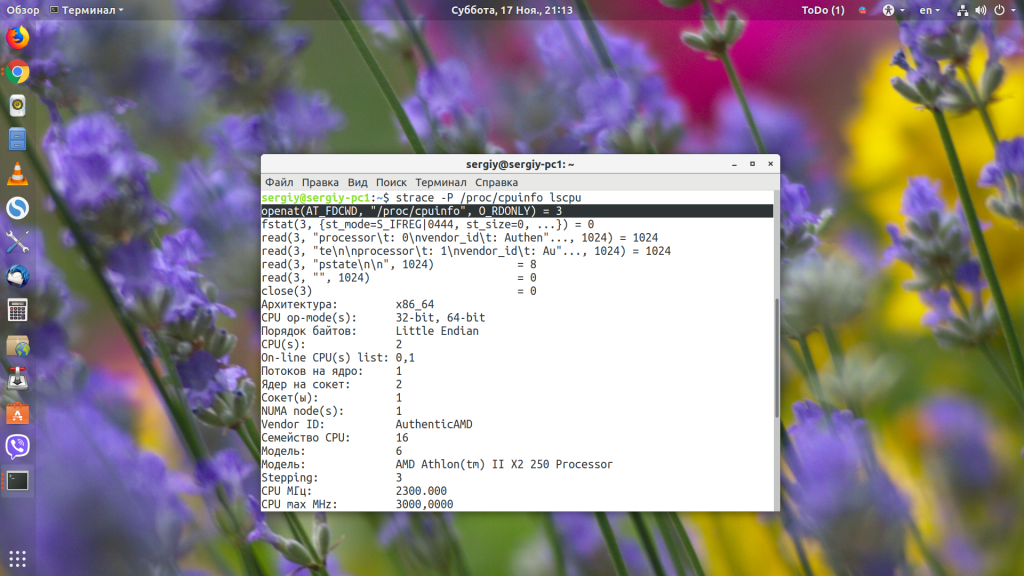
И в результате мы видим, что действительно обращается. Она открывает его для чтения с помощью вызова openat.
6. Статистика системных вызовов
С помощью опции -с вы можете собрать статистику для системных вызовов, которые использует программа. Например, сделаем это для nautilus:
sudo strace -c nautilus
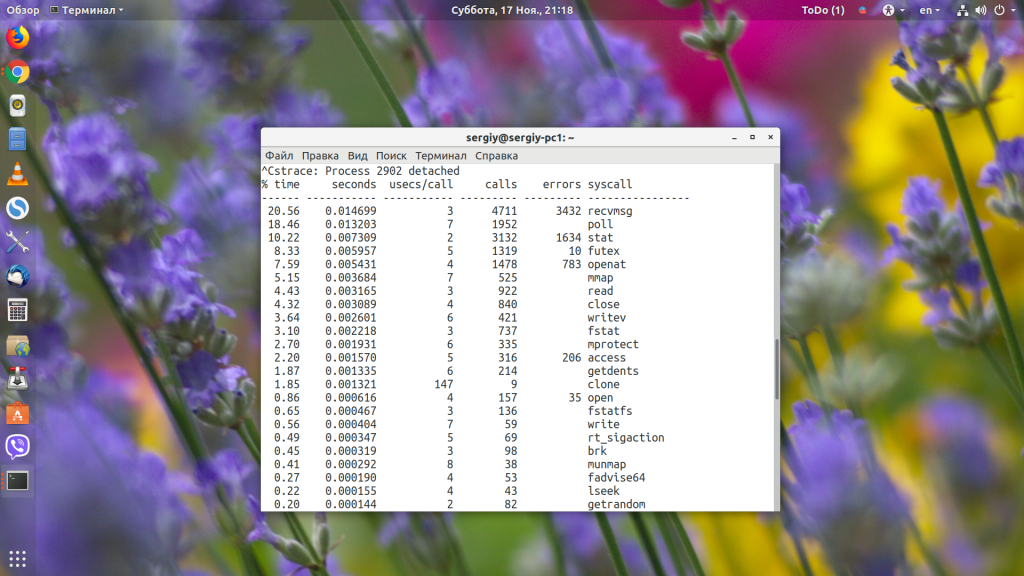
Во время работы утилита ничего выводить не будет. Результат будет рассчитан и выведен, когда вы завершите отладку. В выводе будут такие колонки:
- time — процент времени от общего времени выполнения системных вызовов;
- seconds — общее количество секунд, затраченное на выполнение системных вызовов этого типа;
- calls — количество обращений к вызову;
- errors — количество ошибок;
- syscall — имя системного вызова.
Если вы хотите получать эту информацию в режиме реального времени, используйте опцию -C.
7. Отслеживание времени выполнения
Чтобы отображать время выполнения каждого системного вызова, используйте опцию -t:
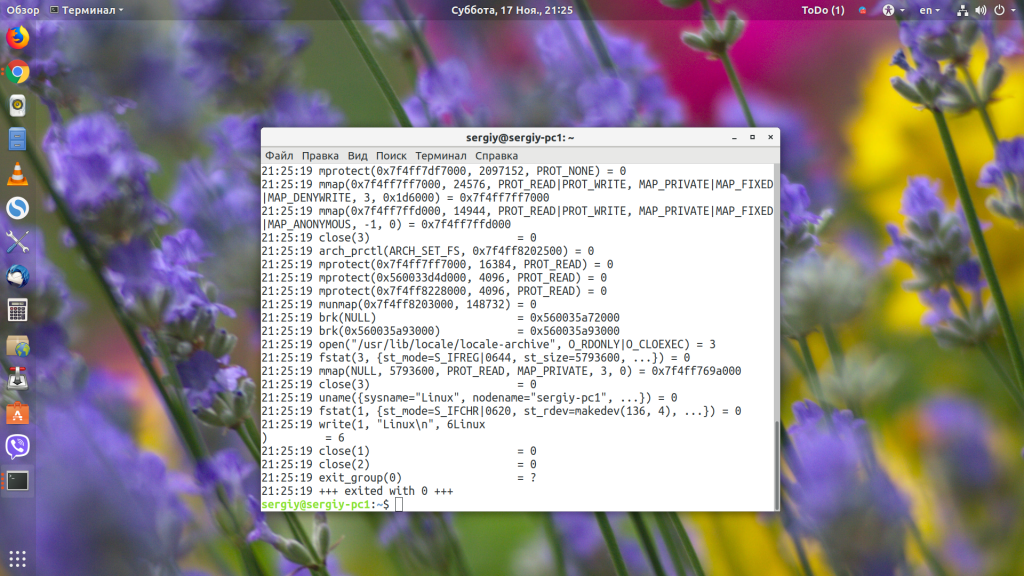
Можно также отображать микросекунды:
strace -tt uname
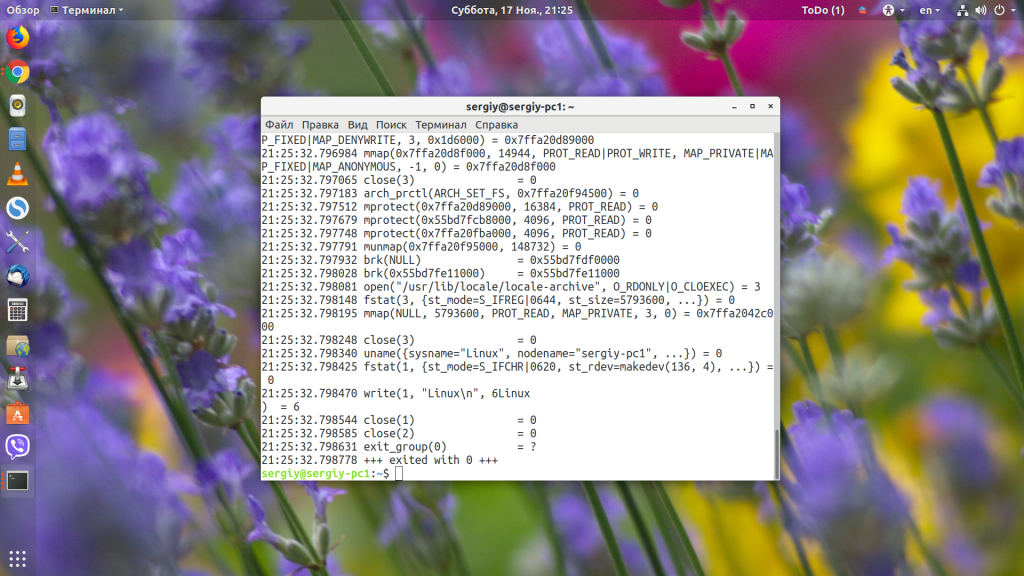
Или отображать время в формате UNIX:
strace -ttt uname
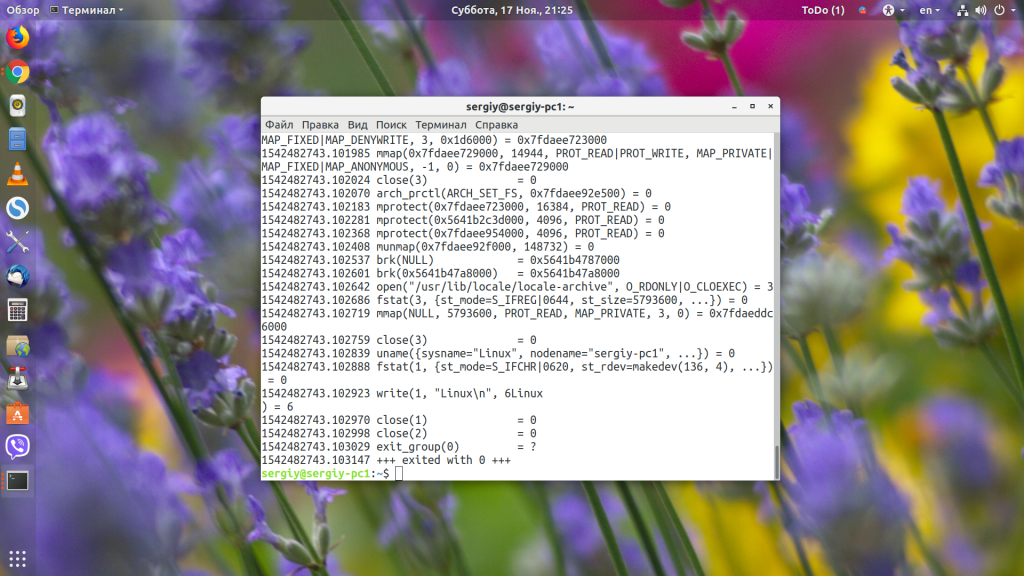
Чтобы добавить время выполнения вызова, добавьте -T:
strace -ttt -T uname
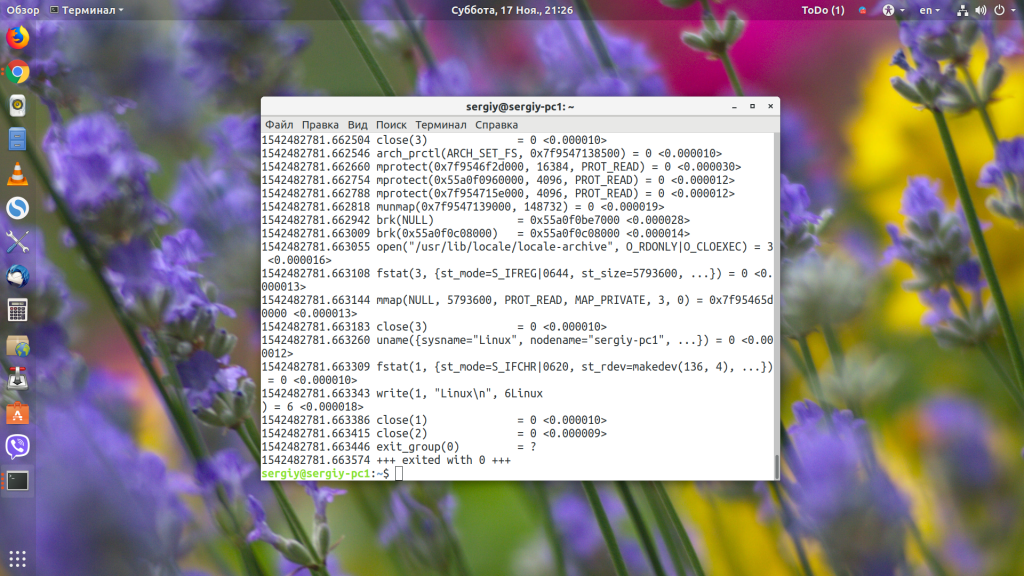
Выводы
В этой статье была рассмотрена команда strace Linux. Как видите, это очень удобный инструмент, который поможет решить множество проблем в вашей системе или на сервере. Мы рассмотрели только основные возможности утилиты, но этого будет вполне достаточно, чтобы начать работать с ней, а более подробную информацию можно найти в официальном руководстве.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
Похожие записи
Оцените статью
(8 оценок, среднее: 4,75 из 5)
Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Об авторе
Основатель и администратор сайта losst.ru, увлекаюсь открытым программным обеспечением и операционной системой Linux. В качестве основной ОС сейчас использую Ubuntu. Кроме Linux, интересуюсь всем, что связано с информационными технологиями и современной наукой.
5 комментариев к “Команда strace в Linux”
Какие есть еще системные утилиты для диагностики неисправности, и анализа работы программ? И если можете сделайте статейки на них. Еще интересуют программы для анализа трафика — НЕ Wireshark. Есть GUI версии программ ?
Спасибо. Ответить
D, Самое банальное — запуск программы из консоли. Возможно, она в терминал вывалит диагностическую информацию, среди которой будут и ошибки. Это же (и еще кое-что) можно и в journalctl посмотреть. Саму программу имеет смысл запускать в режиме дебага.
Имею в виду, что бывают «специальные» ключи (наподобие -v у ssh), которые дают более подробный вывод, они в man’е, и/ или в конфиге выставить, чтобы она писала лог с максимальной подробностью, в какой-либо файл (у вебсерверов это есть). Ну и смотреть этот файл, как вариант, через tail -F в режиме реального времени.
Если же сам что-то менял и где-то неочевидно накосячил при установке/ настройке, то можно и пакет банально переставить, если сервис не успел развернуть Иногда имеет смысл посмотреть через ldd (и выставление LD_DEBUG=all), что за библиотеки нужны софтине, и нашла ли она их. Помимо strace есть еще куча подобного софта (для диагностики и профилирования), типа ftrace и ltrace.
Несколько отдельно можно выделить gdb — это отладчик, но тут все даже несколько менее тривиально, чем с strace, это скорее инструмент для тех, кто сам пишет софт, а не пытается «заткнуть дырки» (баги) в неработающей системе. Так что да, strace и gdb это несколько тяжелая артиллерия зачастую, порой все гораздо проще и решается чтением логов. Увидев сообщения об ошибках, имеет смысл их обдумать, а если мыслей нет — хотя бы загуглить. Если интересует более широко — анализ работы всей системы, что в общем-то включает и работу отдельных программ, то никто не отменял top и кипу других утилит.
А вообще, вопросы производительности просто ОЧЕНЬ круто рассматривает Брендан Грегг.
http://www.brendangregg.com/USEmethod/use-linux.html Для анализа трафика в реальном времени — tcpdump. Неясно чем Wireshark не угодил, работает почти так же, тот же захват трафика, навешивание фильтров, только еще куча всяких фенечек и собственно GUI, который вы хотите. Если интересует статистика, то можно логировать через тот же iptables.
Если статистика, но более серьезно. то это уже скорее область сетевого железа, с их netflow и пр. Ответить
Это конечно здорово примитивы выкладывать. А на не самое очевидное, например echo или cd не решились замахнуться? Ответить
Источник: losst.pro