Надежность программы достигается, в первую очередь, благодаря ее правильному проектированию, а не бесконечному тестированию. Это правило означает, что если программа правильно разработана в отношении как структур данных, так и структур управления, то это в определенной степени гарантирует правильность ее функционирования. При применении такого стиля программирования ошибки являются легко локализуемыми и устранимыми.
В большинстве случаев рекомендуется следующий процесс разработки программы на ассемблере:
1.Этап постановки и формулировки задачи:
· изучение предметной области и сбор материала в проблемно-ориентированном контексте;
· определение назначения программы, выработка требований к ней и представление требований, если возможно, в формализованном виде;
· формулирование требований к представлению исходных данных и выходных результатов;
· определение структур входных и выходных данных;
· формирование ограничений и допущений на исходные и выходные данные.
FASM. Установка FASM. Структура программы на ассемблере. Урок 1
· формирование «ассемблерной» модели задачи;
· выбор метода реализации задачи;
· разработка алгоритма реализации задачи;
· разработка структуры программы в соответствии с выбранной моделью памяти.
3. Этап кодирования:
· уточнение структуры входных и выходных данных и определение ассемблерного формата их представления;
· комментирование текста программы и составление предварительного описания программы.
4. Этап отладки и тестирования:
· составление тестов для проверки правильности работы программы;
· обнаружение, локализация и устранение ошибок в программе, выявленных в тестах;
· корректировка кода программы и ее описания.
5. Этап эксплуатации и сопровождения:
· настройка программы на конкретные условия использования;
· обучение пользователей работе с программой;
· организация сбора сведений о сбоях в работе программы, ошибках в выходных данных, пожеланиях по улучшению интерфейса и удобства рабе ты с программой;
· модификация программы с целью устранения выявленных ошибок и, при необходимости, изменения ее функциональных возможностей.
К порядку применения и полноте выполнения перечисленных этапов нужно подходить разумно. Многое определяется особенностями конкретной задачи, ее назначением, объемом кода и обрабатываемых данных, другими характеристиками задачи. Некоторые из этих этапов могут либо выполняться одновременно с другими этапами, либо вовсе отсутствовать.
Традиционно у существующих реализаций ассемблера нет интегрированной среды, подобной интегрированным средам Turbo Pascal, Turbo С или Visual C++. Поэтому для выполнения всех функций по вводу кода программы, ее трансляции, редактированию и отладке необходимо использовать отдельные служебные программы. Большая часть их входит в состав специализированных пакетов ассемблера.
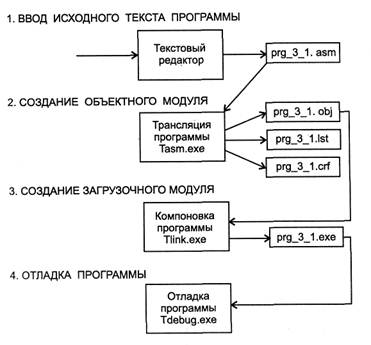
На рисунке один приведена общая схема процесса разработки программы на ассемблере. На схеме выделено четыре шага процесса. На первом шаге, когда вводится код программы, можно использовать любой текстовый редактор. Основным требованием к нему является то, чтобы он не вставлял посторонних символов (спецсимволов редактировании). Файл должен иметь расширение . asm.
Рис. 1. «Процесс разработки программы на ассемблере».
Программы, реализующие остальные шаги схемы, входят в состав программного пакета ассемблера. После написания текста программы на ассемблере наступает следующий этап — трансляция программы. На этом шаге формируется объектный модуль, который включает в себя представление исходной программы в машинных кодах и некоторую другую информацию, необходимую для отладки и компоновки его с другими модулями. Традиционно на рынке ассемблеров для микропроцессоров фирмы Intel имеется два пакета: «Макроассемблер» MASM фирмы Microsoft и Turbo Assembler TASM фирмы Borland.
У этих пакетов много общего. Пакет макроассемблера фирмы Microsoft (MASM) получил свое название потому, что он позволял программисту задавать макроопределения (или макросы), представляющие собой именованные группы команд. Они обладали тем свойством, что их можно было вставлять в программу в любом месте, указав только имя группы в месте вставки.
Пакет Turbo Assembler (TASM) интересен тем, что имеет два режима работы. Один из этих режимов, называемый MASM, поддерживает все основные возможности макроассемблера MASM. Другой режим, называемый IDEAL, предоставляет более удобный синтаксис написания программ, более эффективное использование памяти при трансляции программы и другие новшества, приближающие компилятор ассемблера к компиляторам языков высокого уровня.
В эти пакеты входят трансляторы, компоновщики, отладчики и другие утилиты для повышения эффективности процесса разработки программ на ассемблере.
В данной курсовой работе для получения объектного модуля исходный файл подвергается трансляции при помощи программы tasm.exe из пакета TASM.
После устранения ошибок можно приступать к следующему шагу — созданию исполняемого (загрузочного) модуля, или, как еще называют этот процесс, к компоновке программы. Главная цель этого шага — преобразовать код и данные в объектных файлах в их перемещаемое выполняемое отображение. Процесс создания исполняемого модуля разделяют на 2 шага — трансляцию и компоновку.
Это сделано намеренно для того, чтобы можно было объединять вместе несколько модулей (написанных на одном или нескольких языках). Формат объектного файла позволяет, при определенных условиях, объединить несколько отдельно оттранслированных исходных модулей в один модуль. При этом в функции компоновщика входит разрешение внешних ссылок (ссылок на процедуры и переменные) в этих модулях. Результатом работы компоновщика является создание загрузочного файла с расширением ехе. После этого операционная система может загрузить такой файл и выполнить его.
Устранение синтаксических ошибок еще не гарантирует того, что программа будет хотя бы будет запускаться, не говоря уже о правильности работы. Поэтому обязательным этапом процесса разработки является отладка.
На этапе отладки, используя описание алгоритма, выполняется контроль правильности функционирования как отдельных участков кода, так и всей программы в целом. Но даже успешное окончание отладки еще не является гарантией того, что программа будет работать правильно со всеми возможными исходными данными. Поэтому нужно обязательно провести тестирование программы, то есть проверить ее работу на «пограничных» и заведомо некорректных исходных данных. Для этого составляются тесты.
Специфика программ на ассемблере состоит в том, что они интенсивно работают с аппаратными ресурсами компьютера. Это обстоятельство заставляет программиста постоянно отслеживать содержимое определенных регистров и областей памяти. Естественно, что человеку трудно следить за этой информацией с большой степенью детализации. Поэтому для локализации логических ошибок в программах используют специальный тип программного обеспечения — программные отладчики.
Отладчики бывают двух типов:
· интегрированные — отладчик реализован в виде интегрированной среды типа среды для языков Turbo Pascal, Quick С и т.д.;
· автономные — отладчик представляет собой отдельную программу.
Из-за того, что ассемблер не имеет своей интегрированной среды, для отладки написанных на нем программ используют автономные отладчики. К настоящему времени разработано большое количество таких отладчиков. В общем случае с помощью автономного отладчика можно исследовать работу любой программы, для которой создан исполняемый модуль, независимо от того, на каком языке был написан его исходный текст.
Источник: kazedu.com
ARM аccемблер
Привет всем! По роду деятельности я программист на Java. Последние месяцы работы заставили меня познакомиться с разработкой под Android NDK и соответственно написание нативных приложений на С. Тут я столкнулся с проблемой оптимизации Linux библиотек. Многие оказались абсолютно не оптимизированы под ARM и сильно нагружали процессор.
Ранее я практически не программировал на ассемблере, поэтому сначала было сложно начать изучать этот язык, но все же я решил попробовать. Эта статья написана, так сказать, от новичка для новичков. Я постараюсь описать те основы, которые уже изучил, надеюсь кого-то это заинтересует. Кроме того, буду рад конструктивной критике со стороны профессионалов.
Введение
Итак, для начала разберёмся что же такое ARM. Википедия дает такое определение:
Архитектура ARM (Advanced RISC Machine, Acorn RISC Machine, усовершенствованная RISC-машина) — семейство лицензируемых 32-битных и 64-битных микропроцессорных ядер разработки компании ARM Limited. Компания занимается исключительно разработкой ядер и инструментов для них (компиляторы, средства отладки и т. п.), зарабатывая на лицензировании архитектуры сторонним производителям.
Если кто не знает, сейчас большая часть мобильных устройств, планшетов разработаны именно на этой архитектуре процессоров. Основным преимуществом данного семейства является низкое энергопотребление, благодаря чему он часто используется в различных встроенных системах.
Архитектура развивалась с течением времени, и начиная с ARMv7 были определены 3 профиля: ‘A’(application) — приложения, ‘R’(real time) — в реальном времени,’M’(microcontroller) — микроконтроллер. Историю разработки этой технологии и другие интересный данные вы можете прочитать в Википедии или погуглив в интернете. ARM поддерживает разные режимы работы (Thumb и ARM, кроме того в последние время появился Thumb-2, являющийся смесью ARM и Thumb). В данной статье рассмотрим собственно режим ARM, в котором исполняется 32-битный набор команд.
37 регистров (из которых видимых при разработке только 17)
Арифметико-логи́ческое устройство (АЛУ) — выполняет арифметические и логические задачи
Barrel shifter — устройство, созданное для перемещения блоков данных на определенное количество бит
The CP15 — специальная система, контроллирующая ARM сопроцессоры
Декодер инструкций — занимается преобразованием инструкции в последовательность микроопераций
Конвейерное исполнение (Pipeline execution)
В ARM процессорах используется 3-стадийный конвейер (начиная с ARM8 был реализова 5-стадийный конвейер). Рассмотрим простой конвейер на примере процессора ARM7TDMI. Исполнение каждой инструкции состоит из трёх ступеней:
1. Этап выборки (F) На этом этапе инструкции поступают из ОЗУ в конвейер процессора. 2. Этап декодирования (D) Инструкции декодируются и распознаётся их тип. 3. Этап исполнения (E) Данные поступают в ALU и исполняются и полученное значение записывается в заданный регистр.
Но при разработке надо учитывать, что, есть инструкции, которые используют несколько циклов исполнения, например, load(LDR) или store. В таком случае этап исполнения (E) разделяется на этапы (E1, E2, E3. ).
Условное выполнение
Одна из важнейших функций ARM ассемблера — условное выполнение. Каждая инструкция может исполняться условно и для этого используются суффиксы. Если суффикс добавляется к названию инструкции, то прежде чем выполнить ее, происходит проверка параметров. Если параметры не соответствуют условию, то инструкция не выполняется. Суффиксы: MI — отрицательное число PL — положительное или ноль AL — выполнять инструкцию всегда Суффиксов условного выполнения намного больше. Остальные суффиксы и примеры прочитать в официальной документации: ARM документация А теперь пришло время рассмотреть…
Основы синтаксиса ARM ассемблера
Тем, кто раньше работал с ассемблером этот пункт можно фактически пропустить. Для всех остальных опишу основы работы с этим языком. Итак, каждая программа на ассемблере состоит из инструкций. Инструкция создаётся таким образом: <инструкция|операнды> Метка — необязательный параметр. Инструкция — непосредственно мнемоника инструкции процессору. Основные инструкции и их использование будет разобрано далее. Операнды — константы, адреса регистров, адреса в оперативной памяти. Комментарий — необязательный параметр, который не влияет на исполнение программы.
Имена регистров
Разрешены следующие имена регистров: 1.r0-r15
3.v1-v8 (переменные регистры, с r4 по r11)
4.sb and SB (статический регистр, r9)
10.pc and PC (программный счетчик, r15).
Переменные и костанты
Числовые
Логические
Строковые
Примеры инструкций ARM ассемблера
В данной таблице я собрал основные инструкции, которая потребуется для дальнейшей разработки (на самом базовом этапе:):
Название
Синтаксис
Применение
ADD (добавление)
ADD r0, r1, r2
r0 = r1 + r2
SUB (вычитание)
SUB r0, r1, r2
r0 = r1 — r2
RSB (обратное вычитание)
RSB r0, r1, #10
r0 = 10 — r1
MUL (умножение)
MUL r0, r1, r2
r0 = r1 * r2
MOV
MOV r0, r1
r0 = r1
ORR( логическая операция)
ORR r0, r1, r2
r0 = r1 | r2
TEQ
TEQ r0, r1
r0 == r1
LDR (загрузка)
LDR r4, [r5]
r4 = *r5
STR
STR r4, [r5]
*r5 = r4
ADR
ADR r3, a
a — переменная. r3 = PowerPC, ARM, MIPS, SPARC, SPARC64, m68k — лишь частично.
Работает на Syllable, FreeBSD, FreeDOS, Linux, Windows 9x, Windows 2000, Mac OS X, QNX, Android и др.
Итак, для эмуляции arm понадобится qemu-system-arm. Этот пакет есть в yum, так что тем, у кого Fedora, можно не заморачиваться и просто выполнить комманду: yum install qemu-system-arm
Далее надо запустить эмулятор ARM, так, чтобы он выполнил нашу программу arm.bin. Для этого создадим файл flash.bin, который будет флэш памятью для QEMU. Сделать это очень просто:
Теперь грузим QEMU с полученой flash памятью:
qemu-system-arm -M connex -pflash flash.bin -nographic -serial /dev/null
На выходе вы получите что-то вроде этого:
Наша программа arm.bin должна была изменить значения четырех регистров, следовательно для проверки правильности работы давайте посмотрим на эти самые регистры. Делается это очень простой коммандой: info registers На выходе вы увидите все 15 ARM регистров, при чем у четырех из них будут измененные значения. Проверьте:) Значения регистров совпадают с теми, которые можно ожидать после исполнения программы:
P.S. В этой статье я постарался описать основы программирования на ARM ассемблер. Надеюсь вам понравилось! Этого хватит для того, чтобы далее углубляться в дебри этого языка и писать на нем программы.
Если все получится, буду писать дальше о том, что узнаю сам. Если есть ошибки, прошу не пинать, так как я новичок в ассемблере.
Источник: habr.com
Презентация на тему Программирование на Ассемблере
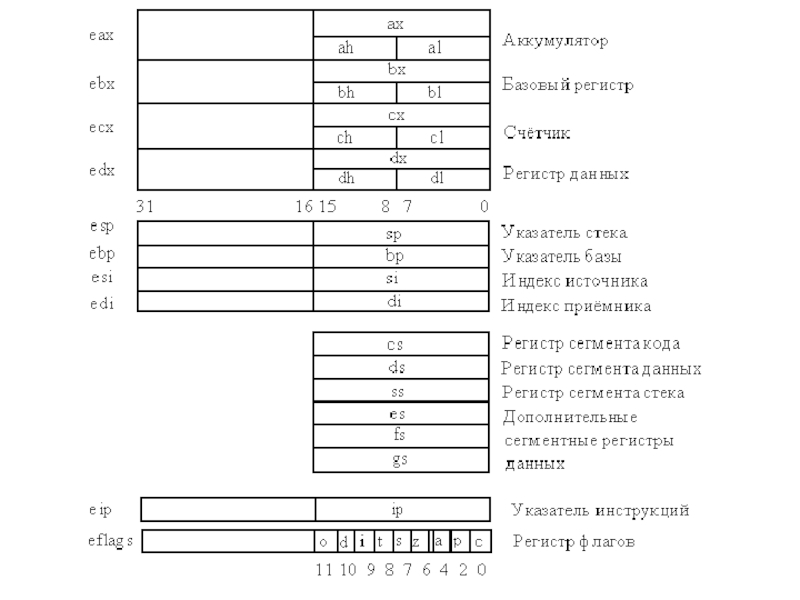
80186, 80286, 80386, 80486, Pentium, Pentium II, Pentium III и т.д. Совместимые с 80х86 микросхемы выпускают также фирны AMD, IBM, Cyrix. Особенностью этих процессоров является преемственность на уровне машинных команд: программы, написанные для младших моделей процессоров, без каких-либо изменений могут быть выполнены на более старших моделях. При этом базой является система команд процессора 8086, знание которой является необходимой предпосылкой для изучения остальных процессоров.
Слайд 7Регистры Для того, чтобы писать программы
на ассемблере, нам необходимо знать, какие регистры
процессора существуют и как их можно использовать. Все процессоры архитектуры x86 (даже многоядерные, большие и сложные) являются дальними потомками древнего Intel 8086 и совместимы с его архитектурой. Это значит, что программы на ассемблере 8086 будут работать и на всех современных процессорах x86.
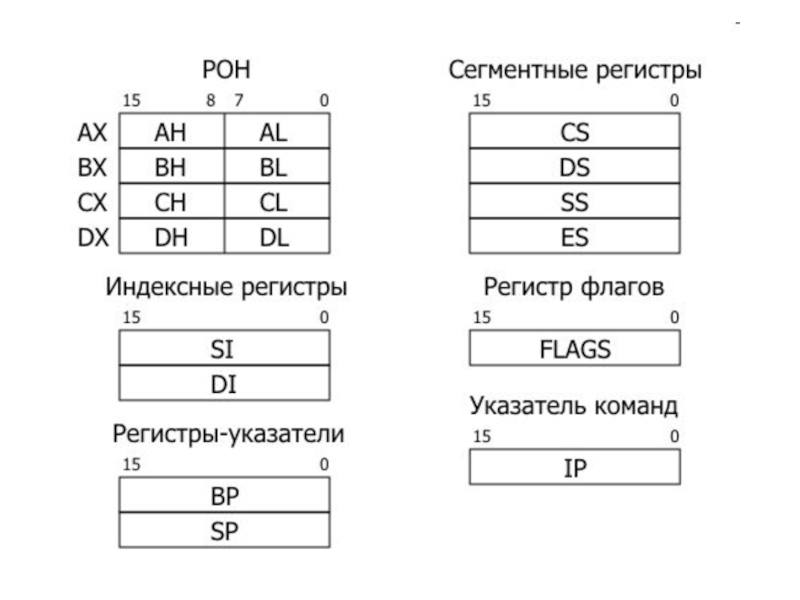
Все внутренние регистры процессора Intel 8086 являются 16-битными:
Слайд 8
Слайд 9Регистры Процессор 8086 имеет 14
шестнадцатиразрядных регистров, которые используются для управления исполнением
команд, адресации и выполнения арифметических операций.
Регистры общего назначения.
К ним относятся 16-разрядные регистры АХ, ВХ, СХ, DX, каждый из которых разделен на 2 части по 8 разрядов: АХ состоит из АН (старшая часть) и AL (младшая часть); ВХ состоит из ВH и BL; СХ состоит из СН и CL; DX состоит из DH и DL; В общем случае функция, выполняемая тем или иным регистром, определяется командами, в которых он используется. При этом с каждым регистром связано некоторое стандартное его значение. Ниже перечисляются наиболее характерные функции каждого регистра:
Слайд 10регистр АХ служит для временного хранения данных
(регистр аккумулятор); часто используется при выполнении операций
сложения, вычитания, сравнения и других арифметических и логических операции; регистр ВХ служит для хранения адреса некоторой области памяти (базовый регистр), а также используется как вычислительный регистр; регистр СХ иногда используется для временного хранения данных, но в основном служит счетчиком; в нем хранится число повторений одной команды или фрагмента программы; регистр DX используется главным образом для временного хранения данных; часто служит средством пересылки данных между разными программными системами, в качестве расширителя аккумулятора для вычислений повышенной точности, а также при умножении и делении. Регистры для адресации. В микропроцессоре существуют четыре 16-битовых (2 байта или 1 слово) регистра, которые могут принимать участие в адресации операндов. Один из них одновременно является и регистром общего назначения — это регистр ВХ, или базовый регистр. Три другие регистра — это указатель базы ВР, индекс источника SI и индекс результата DI. Отдельные байты этих трех регистров недоступны.
Любой из названных выше 4 регистров может использоваться для хранения адреса памяти, а команды, работающие с данными из памяти, могут обращаться за ними к этим регистрам. При адресации памяти базовые и индексные регистры могут быть использованы в различных комбинациях. Разнообразные способы сочетания в командах этих регистров и других величин называются способами или режимами адресации.
Слайд 11 Регистры сегментов. Имеются четыре
регистра сегментов, с помощью которых память можно
организовать в виде совокупности четырех различных сегментов. Этими регистрами являются: CS — регистр программного сегмента (сегмента кода) определяет местоположение части памяти, содержащей программу, т. е. выполняемые процессором команды; DS — регистр информационного сегмента (сегмента данных) идентифицирует часть памяти, предназначенной для хранения данных; SS — регистр стекового сегмента (сегмента стека) определяет часть памяти, используемой как системный стек; ES — регистр расширенного сегмента (дополнительного сегмента) указывает дополнительную область памяти, используемую для хранения данных. Эти 4 различные области памяти могут располагаться практически в любом месте физической машинной памяти. Поскольку местоположение каждого сегмента определяется только содержимым соответствующего регистра сегмента, для реорганизации памяти достаточно всего лишь, изменить это содержимое. Регистр указателя стека. Указатель стека SP – это 16-битовый регистр, который определяет смещение текущей вершины стека. Указатель стека SP вместе с сегментным регистром стека SS используются микропроцессором для формирования физического адреса стека. Стек всегда растет в направлении меньших адресов памяти, т.е. когда слово помещается в стек, содержимое SP уменьшается на 2, когда слово извлекается из стека, микропроцессор увеличивает содержимое регистра SP на 2.
Слайд 12Регистр указателя команд IP. Регистр указателя команд
IP, иначе называемый регистром счетчика команд, имеет
размер 16 бит и хранит адрес некоторой ячейки памяти – начало следующей команды. Микропроцессор использует регистр IP совместно с регистром CS для формирования 20-битового физического адреса очередной выполняемой команды, при этом регистр CS задает сегмент выполняемой программы, а IР – смещение от начала сегмента. По мере того, как микропроцессор загружает команду из памяти и выполняет ее, регистр IP увеличивается на число байт в команде. Для непосредственного изменения содержимого регистра IP служат команды перехода. Регистр флагов. Флаги – это отдельные биты, принимающие значение 0 или 1. Регистр флагов (признаков) содержит девять активных битов (из 16). Каждый бит данного регистра имеет особое значение, некоторые из этих бит содержат код условия, установленный последней выполненной командой. Другие биты показывают текущее состояние микропроцессора.
Слайд 13
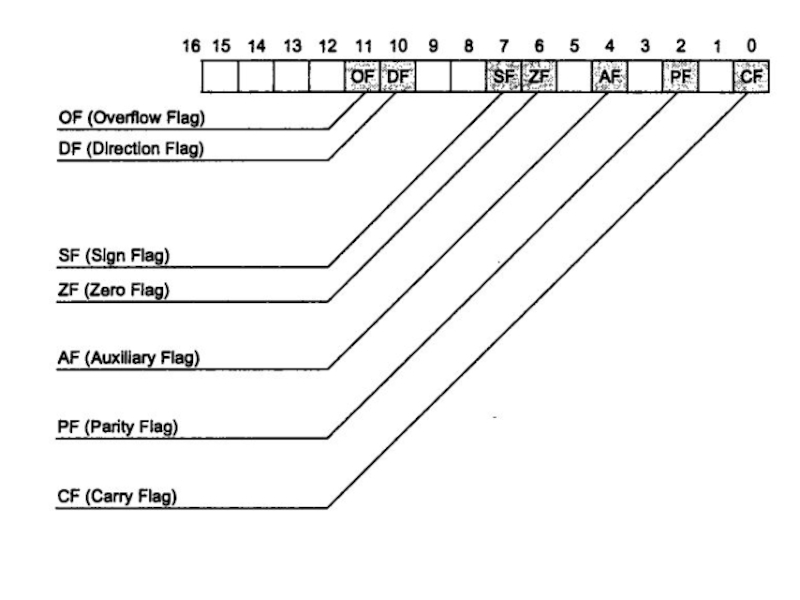
Слайд 14 Указанные на рисунке флаги
наиболее часто используются в прикладных программах и
сигнализируют о следующих событиях: OF (флаг переполнения) фиксирует ситуацию переполнения, то есть выход результата арифметической операции за пределы допустимого диапазона значений; DF (флаг направления) используется командами обработки строк. Если DF = 0, строка обрабатывается в прямом направлении, от меньших адресов к большим. Если DF = 1, обработка строк ведется в обратном направлении; SF (флаг знака) показывает знак результата операции, при отрицательном результате SF = 1; ZF (флаг нуля) устанавливается в 1, если результат операции равен 0; AF (флаг вспомогательного переноса) используется в операциях над упакованными двоично-десятичными числами. Этот флаг служит индикатором переноса или заема из старшей тетрады (бит 3); PF (флаг четности) устанавливается в 1, если результат операции содержит четное число двоичных единиц; CF (флаг переноса) показывает, был ли перенос или заем при выполнении арифметических операций. Легко заметить, что все флаги младшего байта регистра флагов устанавливаются арифметическими или логическими операциями процессора. За исключением флага переполнения, все флаги старшего байта отражают состояние микропроцессора и влияют на характер выполнения программы. Флаги старшего байта устанавливаются и сбрасываются специально предназначенными для этого командами. Флаги младшего байта используются командами условного перехода для изменения порядка выполнения программы.
Слайд 15
Слайд 16
Слайд 17Сегменты, принцип сегментации Числа, устанавливаемые процессором
на адресной шине, являются адресами, то есть
номерами ячеек оперативной памяти (ОП). Размер ячейки ОП составляет 8 разрядов, т.е. 1 байт. Поскольку для адресации памяти процессор использует 16-разрядные адресные регистры, то это обеспечивает ему доступ к 65536 (FFFFh) байт или 64К основной памяти. Такой блок непосредственно адресуемой памяти называется сегментом.
Любой адрес формируется из адреса сегмента (всегда кратен 16, т.е. начинается с границы параграфа) и адреса ячейки внутри сегмента (этот адрес называется смещением). Для адресации большего объема памяти в процессоре 8086 используется специальная процедура пересчета адресов, называемая вычислением абсолютного (эффективного) адреса.
Слайд 18Когда процессор выбирает очередную команду на исполнение,
в качестве ее адреса используется содержимое, регистра
IP. Этот адрес называется исполнительным. Поскольку регистр IP шестнадцатиразрядный, исполнительный адрес тоже содержит 16 двоичных разрядов. Однако адресная шина, соединяющая процессор и память имеет 20 линий связи. Чтобы получить 20-битовый адрес, дополнительные 4 бита адресной информации извлекаются из сегментных регистров. Сами сегментные регистры имеют размер в 16 разрядов, а содержащиеся в этих регистрах (CS, DS, SS или ES) 16-битовые значения называются базовым адресом сегмента. Микропроцессор объединяет 16-битовый исполнительный адрес и 16-битовый базовый адрес следующим образом: он расширяет содержимое сегментного регистра (базовый адрес) 4 нулевыми битами (в младших разрядах), делая его 20-битовым (полный адрес сегмента) и прибавляет смещение (исполнительный адрес). При этом 20-битовый результат является физическим или абсолютным адресом ячейки памяти.
Слайд 19
Слайд 20Существуют три основных типа сегментов: сегмент кода –
содержит машинные команды, Адресуется регистром CS; сегмент данных
– содержит данные, то есть константы и рабочие области, необходимые программе. Адресуется регистром DS; сегмент стека – содержит адреса возврата в точку вызова подпрограмм. Адресуется регистром SS. При записи команд на языке Ассемблера принято указывать адреса с помощью следующей конструкции: : или :
Слайд 21Стек Во многих случаях программе
требуется временно запомнить некоторую информацию. Эта проблема
в персональном компьютере решена посредством реализации стека LIFO («последний пришел — первый ушел»), называемого также стеком включения/извлечения (stack). Стек – это область памяти для временного хранения данных, в которую по специальным командам можно записывать отдельные слова (но не байты); при этом для запоминания данных достаточно выполнить лишь одну команду и не нужно беспокоиться о выборе соответствующего адреса: процессор автоматически выделяет для них свободное место в области временного хранения.
Наиболее важное использование стека связано с подпрограммами, в этом случае стек содержит адрес возврата из подпрограммы, а иногда и передаваемые в/из подпрограмму данные. Стек обычно рассчитан на косвенную адресацию через регистр указатель стека. При включении элементов в стек производится автоматический декремент указателя стека, а при извлечении – инкремент, то есть стек всегда «растет» в сторону меньших адресов памяти. Адрес последнего включенного в стек элемента называется вершиной стека (TOS), а адрес сегмента стека – базой стека.
Слайд 22Адресация данных Для четкого понимания того, как осуществляется
адресация данных, проанализируем способ образования адреса операнда.
Адрес операнда формируется по схеме сегментх:смещение. Селектор сегмента можно указать явным или неявным образом. Обычно селектор сегмента загружается в сегментный регистр, а сам регистр выбирается в зависимости от типа выполняемой операции, как показано ниже. Процессор автоматически выбирает сегмент в соответствии с условиями, описанными в таблице. При сохранении операнда в памяти или загрузке из памяти в качестве сегментного регистра по умолчанию используется DS, но можно и явным образом указать сегментный регистр, применяемый в операции. Пусть, например, требуется сохранить содержимое регистра ЕАХ в памяти, адресуемой сегментным регистром ES и смещением, находящимся в регистре ЕВХ. В этом случае можно использовать команду mov ES:[EBX],EAX Обратите внимание на то, что после имени сегмента указывается символ двоеточия.
Слайд 23
Слайд 24Режимы адресации В зависимости от местоположения
источников образования полного (абсолютного) адреса в языке