
Грамотное написание MS SQL запросов является важным преимуществом кандидата при приеме на работу, в то время как незнание может стать причиной отказа в новой должности или повышении зарплаты. Этому легко научиться. Достаточно знать синтаксис, который сам по себе простой и понятный. Эта статья раскрывает основные вопросы Structured Query Language.
Она поможет получить первые знания по этой теме или освежить имеющуюся базу знаний. Может быть именно эта статья поможет вам получить желаемую работу.
Важность MS SQL запросов
Аббревиатура SQL расшифровывается – Structured Query Language (язык структурированных запросов). Его конструкции выступают непроцедурным декларативным языком. SQL позволяет сохранять информацию в базах данных (БД) в удобном для использования виде, а также манипулировать данными. Используется для управления данными в системе реляционных баз данных (RDBMS).
БД, в том числе и реляционная модель, основывается на теории множеств. Она подразумевает возможность объединения различных объектов в единое целое, которым в БД выступает таблица. Данное утверждение имеет важное значение, т.к. SQL основывается на работе с множествами, наборами данных, которые по сути и являются таблицами.
Составляем SQL запросы на ПРАКТИКЕ — решаем МНОГО задач
SQL запросы важны для всех веб-проектов в Интернете, обрабатывающих большие объемы информации. Все они вынуждены сохранять ее в различных видах БД. Многие проекты хранят информацию в БД реляционного типа (записи осуществляются в разных табличных подобиях). С помощью различных конструкций MS SQL запросов производится внесение новых и обращение к имеющимся записям.
Говоря простым языком, SQL выступает набором принятых стандартов, которые используются для создания обращений к БД. Стандарты языка SQL не являются статичными. Они постоянно видоизменяются, обновляются, расширяются.
СУБД
Существуют различные версии языка SQL. Эти разновидности специалисты иногда называют диалектами. Они создаются отдельными организациями и сообществами. Создатели выпускают более расширенные варианты устоявшихся языковых стандартов SQL.
Различные вариации спецификаций SQL предназначены для продуктивной работы с самыми разнообразными системами управления базами данных (СУБД). Каждая из них представляет собой систему программ, заточенную на выполнение определенных задач, достижения целей и работу с программными продуктами собственной инфраструктуры.
Чаще всего специалисты применяют СУБД, которые используют собственные стандарты SQL:
- Microsoft SQL Server – система управления БД, собственником которой является Microsoft. Особенно популярна в крупных компаниях корпоративного сектора. По сути является огромным комплексом приложений, который дает возможность сохранять, изменять, анализировать данные, реализовывать их безопасность и т.д. Использует диалект T-SQL (Transact-SQL);
- Oracle Database – СУБД от Oracle. Также очень популярна, в том числе в крупных компаниях корпоративного сектора. Сопоставима с предыдущей СУБД, по отношению к которой является основным конкурентом. Полнофункциональные версии обоих собственников являются достаточно дорогостоящими;
- MySQL – также принадлежит компании Oracle, но предполагает бесплатное использование. Этот продукт достаточно популярен в онлайн-сегменте. Именно на нем работает большинство веб-проектов (все они используют эту СУБД для хранения информации);
- PostgreSQL – свободная система, которая поддерживается и развивается сообществом пользователей. Также распространяется бесплатно, достаточно функциональна и пользуется широкой популярностью.
Возможности расширений в различных диалектах SQL могут иметь как общие свойства (основные конструкции), так и определенные отличия (в используемых типах данных, командах). Это объясняется тем, что диалекты создают и используют различные организации, преследующие разные цели и задачи.
SQL ДЛЯ НАЧИНАЮЩИХ. Все, что нужно знать в SQL для аналитики (основные SQL запросы)
Классификация Structured Query Language
SQL запросы можно разделить на следующие виды:
DDL
Язык определения данных – DDL (аббревиатура Data Definition Language). Основная задача – формирование БД и представление ее структуры. Они диктуют правила (вид) размещения данных в БД.
К DDL относятся SQL Queries:
- ALTER – применяется для добавления, удаления, изменения столбцов в ранее созданной таблице (ALTER TABLE);
- COLLATE – используется, чтобы определить, по каким параметрам будет сортироваться БД, столбцы либо операции приведения условий сортировки, если используется выражение строки символов;
- CREATE – позволяет создать новую БД;
- DROP – позволяет удалять любые данные (в том числе и таблицы) из БД. Добавляется приставкой к нужному элементу (DROP TABLE – удалить таблицу);
- DISABLE TRIGGER – выполняет функции отключения триггеров;
- ENABLE TRIGGER – выполняет включение триггеров DML, DDL или logon;
- RENAME – используется для переименования таблицы, которая создана пользователем;
- UPDATE STATISTICS – выполняет функции обновления статистики оптимизации запросов как для таблиц, так и для индексированных представлений;
- TRUNCATE – удаляет все значения из таблицы, но ее саму оставляет.
DML
Язык манипулирования данными – DML (сокращенное от Data Manipulation Language). К нему относятся команды, при использовании которых осуществляются определенные манипуляции с данными.
Основная часть MS SQL запросов относится именно к DML. В их число входят:
- BULK INSERT – импортирует файл с данными в таблицу либо представляет БД в том формате, который указал пользователь;
- SELECT – выводит нужные данные из определенной таблицы;
- DELETE – выполняет удаление указанной строки (с помощью оператора WHERE) из определенной таблицы в БД,
- UPDATE – позволяет вносить правки или добавлять новую информацию в сделанные ранее записи. Включает: таблицу с полем, в котором необходимо внести изменения, запись нового значения, для обозначения места в выбранной таблице применяется WHERE;
- INSERT – в имеющуюся БД добавляет новые записи;
- UPDATETEXT – выполняет обновление (изменение) существующих полей типа text, ntext или image;
- MERGE – в целевой таблице выполняет операции вставок, обновлений либо удалений, основанные на результатах соединения с данными исходной;
- WRITETEXT – выполняет обновление существующих столбцов, имеющих тип text, ntext или image, в режиме онлайн, с минимальным использованием журнала. Данная инструкция перезаписывает в столбцах, для которых используется, любые данные. Но ее нельзя применять в представлениях для столбцов вышеуказанных типов;
- READTEXT – производит считывание значений text, ntext или image из соответствующих столбцов. Процесс запускается с указанных позиций и длится для обозначенного числа байтов.
Без них не обойтись, когда необходимо:
- внести изменения в ранее занесенные данные;
- получить данные из сформированной ранее БД;
- сохранить, обновить, удалить данные из БД.
DCL
Языком управления данными является DCL (расшифровывается – Data Control Language). В нем объединены запросы вместе с командами, которые касаются прав, разрешений и прочих настроек систем управления БД.
К их числу относятся:
- GRANT – применяется для распределения пользователям привилегий;
- REVOKE – выполняет функции отмены привилегий,
- DENY – применяется для запрещения разрешений участникам. Наделен приоритетом над иными разрешениями, однако не может использоваться к владельцам либо членам с правами sysadmin.
TCL
Языком управления транзакциями является TCL (аббревиатура от Transaction Control Language). TCL-конструкции используются для управления изменениями, происходящими благодаря применению DML-команд. Они дают возможность объединять в наборы транзакций запросы DML.
К ним относятся:
- BEGIN – позволяет выполнять инструкции T-SQL;
- COMMIT – выполняет фиксацию транзакции;
- ROLLBACK – выполняет откат транзакции.
Простые SQL Queries
Для создания таблицы используется CREATE TABLE, новой БД – CREATE DATABASE. Все колонки, которые необходимо добавить вместе с их типами, будут приняты в качестве параметров.
Для формирования БД на сервере используют MS SQL Server Management Studio, а также MS SQL Server. При создании таблиц добавляют команду Primary Key, которая выступает как колонка, в которой все значения уникальны. Это может быть первая колонка с указанием id номера записи (строки) в таблице.
Для выполнения различных операций в SQL предусмотрено множество встроенных функций. Среди них чаще всего используются агрегатные функции:
- MIN()/ MAX() – для возврата минимального либо максимального значения указанного столбца;
- COUNT() – для возврата числа строк;
- AVG() – для возврата среднего значения указанного столбца;
- SUM() – для возврата суммы всех полей столбца, у которых имеются числовые значения.
Ключевое слово AS, добавленное в команду, поможет столбцу присвоить псевдоним. Это сделает его название не только красивым, но и более понятным.
Сложные SQL Queries
Кроме стандартных, часто используются сложные SQL запросы, которые представляют собой комбинацию простых. При выполнении простых запросов промежуточные результаты группируются в соответствующие таблицы данных. Сложный SQL запрос в свою очередь уже манипулирует промежуточными результатами, которые были получены с помощью простых.
Сложные SQL запросы формируются различными способами:
- Один запрос (подзапрос) помещается в иной (внешний), который является основным.
- Реляционные операторы получаются путем использования разных операторов объединения промежуточных результатов, полученных в результате выполнения простых подзапросов.
Структура MS SQL запросов
Остановимся подробнее на структуре самых популярных запросов.
SELECT, FROM
Операторы SELECT и FROM являются обязательными элементами команды. Они определяют, какие столбцы выбраны, их порядок и источник данных.
Общая структура имеет вид:
- SELECT (‘столбцы или * для выбора всех столбцов; обязательно’)
- FROM (‘таблица; обязательно’)
- Чтобы выбрать все (используется обозначение *) из таблицы «Autors»:
SELECT * FROM Autors
- Для выбора столбцов (AutorID, AutorName) из «Autors»:
SELECT AutorID, AutorName FROM Autors
Применение команды SELECT DISTINCT позволяет получить лишь те данные, которые не повторяются в таблице.
WHERE
Элемент WHERE не обязателен. Он используется лишь в тех случаях, когда требуется отобрать данные по определенному условию. Это условие запроса и указывается в операторе WHERE.
WHERE (‘условие/фильтрация, к примеру, city = ‘London’; необязательно’)
Внутри WHERE часто применяются:
- для фильтрования в таблице столбцов сразу по нескольким значениям – IN (включение) / NOT IN (исключение);
- для фильтрования таблицы одновременно по нескольким значениям столбцов – AND (выполнение всех условий) / OR (выполнение хотя бы одного условия);
- математические знаки сравнения (=, , =, <>);
- команды проверки: BETWEEN – на расположение значения в определенном промежутке (в числовом или текстовом выражении), LIKE – по заданному шаблону (в операторе используются два оператора: «%» – ни одного, один либо несколько символов, «_» – один символ).
Позволяет сравнивать не только числовые показатели, но и текстовые.
INSERT
Его использование позволит внести новые записи в БД. К примеру, чтобы добавить еще одного автора (Иван Бунин, 83 года) в БД с именем «tAuthors», необходимо использовать команду:
INSERT INTO tAuthors VALUES (‘Иван’, ‘Бунин’, ’83’)
Элемент GROUP BY не обязателен для запроса. Он используется в тех случаях, когда необходимо задать агрегацию по определенному столбцу (к примеру, когда необходимо узнать, сколько клиентов проживает в каждом районе города).
GROUP BY (‘столбец, по которому необходимо систематизировать данные; необязательно’)
При применении GROUP BY необходимо, чтобы выполнялись условия:
- Список столбцов (по которым производится группировка) внутри запроса SELECT должен соответствовать списку столбцов в GROUP BY.
- Внутри запроса SELECT должны указываться агрегатные функции (SUM, AVG, COUNT, MAX, MIN). Обязательно должны указываться столбцы, к которым они будут применяться.
HAVING
Для запросов не является обязательным. Используется, когда необходимо отфильтровать данные на уровне уже сгруппированных. Наблюдается повторение функций WHERE, но на более высоком уровне. Отличается от WHERE тем, что последний не предназначен для работы с агрегатными функциями.
Структура имеет вид:
HAVING (‘условие/ фильтрация на уровне сгруппированных данных; необязательно’)
Пример использования – проведение выборки по агрегированной таблице с числом клиентов по районам города. К примеру, необходимо оставить выгрузку лишь тех районов, в которых проживает не менее 100 клиентов. Для данного запроса выполнение требуемой фильтрации не составит труда.
ORDER BY
Не является обязательным. Используется, когда в таблице требуется сортировка на возрастание или убывание по одному или нескольким столбцам. В том случае, когда в команде не указаны способы сортировки ASC либо DESK, производится сортировка по возрастанию значений.
ORDER BY (‘столбец, по которому требуется сортировка вывода; необязательно’)
JOIN
Не обязательный для запроса элемент. Применяется в тех случаях, когда необходимо объединить таблицы по определенному ключу (перед которым проставляется оператор ON), присутствующему в каждой из них.
Если необходимо промэппить определенную таблицу данными из другой, используются различные типы присоединений:
- INNER JOIN – пересечение;
- RIGHT/LEFT JOIN – производит мэппинг одной таблицы данными из иной и т.д.
Деревья и иные конструкции часто требуют рекурсивную обработку. Эти проблемы помогают решать рекурсивные запросы. В MS SQL они впервые появились в Server 2005. Их синтаксис сложен и труден к пониманию. Вследствие этого, рекурсивные запросы используются крайне редко.
Хотя рекурсия позволяет экономить время выполнения операций и дисковое пространство.
Кроме вышеуказанных, существует огромное число самых разных запросов: с зацикленными конструкциями, для работы с переменными и т.д. Чтобы их изучить, понадобится серьезно углубиться в изучение этой специфики.
Как видно из статьи, язык SQL легок в понимании и применении. Изучив его основы, вы не только сможете эффективно применять знания при выполнении проектов, но и значительно повысите свое конкурентное преимущество как грамотного работника или кандидата на желаемую должность.
Изучайте материалы, освежайте знания. Если возникли вопросы – обязательно задавайте их. Удачи на полях познания основ SQL!
Источник: otus.ru
Использование sql запросов возможно в следующих программах
Архив > 2018 > Выпуск 2 > Использование SQL-запросов и команд языков программирования для описания алгоритмов выборки данных в функциональных спецификациях на разработку ERP-систем
Использование SQL-запросов и команд языков программирования для описания алгоритмов выборки данных в функциональных спецификациях на разработку ERP-систем

Аннотация: в статье затрагивается вопрос описания алгоритмов выборки данных, содержащихся в функциональных спецификация на разработку ERP-систем. Вводится модель зрелости задания алгоритмов, связанная с опытностью технических консультантов, формирующих спецификации. Рассматриваются способы записывания логики селекции данных на основе краткого текста, SQL-запросов и комбинации структурированного языка запросов и выборочных команд из прикладных языков программирования ERP-системы. Показывается, чем ближе описание к текстовому, тем разработчику сложнее понять логику и наоборот.
Скачать: PDF (статья), PDF (выпуск №2).
Ключевые слова: SQL-запросы в SAP, выборка из базы данных, создание простого запроса на выборку, SQL select, спецификация на разработку, SQL спецификация, выборка данных из таблицы SQL, SQL в SAP, Select ABAP, ABAP programming for SAP, запросы SQL в IT проектах, основные команды SQL, SQL-запрос, основы языка запросов SQL, SQL в программировании.
Введение
Практический каждый проект внедрения корпоративных информационных систем требует их доработки. Для чего готовится документ функциональной спецификации на разработку, содержащий в себе описание исходного требования, верхнеуровневое понимание решения, а также технические детали реализации [1]. Документ готовится вне зависимости от применяемой методологии имплементации, не исключением являются Agile-подходы. В спецификации должен быть соблюден баланс бизнес и технических составляющих: пользователи должны увидеть свои исходные требования к системе и сформировать общую картину решения, в то время как разработчики – найти технические детали, достаточные для старта программирования решения.
Чем опытнее функциональный консультант, тем более детальнее он описывает алгоритмы выборки данных, приближая их к языку программирования ERP-системы. И, наоборот, новичок указывает минимум деталей в форме близкой к краткому тексту. Существует несколько подходов, как можно описать алгоритмы обработки данных. При этом они сильно зависят от зрелости и опытности технических специалистов, участвующих в ERP-проекте [2]. Давайте проанализируем несколько методов и дадим им оценку.
Цель и задачи
Цель статьи состоит в обзоре способов описания алгоритмов выборки данных в спецификациях на разработку ERP-систем. Чем качественнее написана функциональная спецификация, тем меньше алгоритмических ошибок ожидается при ее реализации. Достижение этой цели потребует выполнения следующих задач:
- рассмотрение способов описания алгоритмов;
- анализ SQL-запросов для использования в спецификациях на разработку;
- оценивание методов описания алгоритмов.
1. Алгоритмы в спецификациях на разработку ERP-систем
ERP-система является транзакционной, то есть ориентированной на обработку больших массивов данных. Преимущественно в системах подобного класса используются реляционные базы данных, таблицы в которых взаимосвязаны между собой по принципу «сущность-связь». Следовательно, вся информация, необходимая для пользователей хранится в таблицах баз данных и отображается в экранные формы программ по запросу. Подготовка функциональных спецификаций требует описания алгоритмов выборки данных, иными словами логики выбора информации из таблиц баз данных. Существует несколько способов, как можно описать подобные алгоритмы в спецификациях на разработку:
- ссылка на поле таблицы баз данных без указания деталей;
- применение SQL-запросов;
- использование SQL-запросов и прочих команд языков программирования.
Первый и самый распространенный метод описания алгоритмов заполнения полей в спецификации на разработку представляет собой явную ссылку на поле таблицы баз указания деталей, откуда изымается значение. Форма записи в этом случае принимает вид (1):
Таким способом пользуются новички, так как приведенное описание не содержит технических деталей алгоритмов: входные данные, ограничения и прочие параметры. Более того, если программная разработка является сложной, то достаточно непросто передать всю логику обработки только используя (1), приходится пользоваться кратким текстом для описания алгоритма, что порождает разночтение. Пример использования (1) дан в таблице 1. Как видно из таблицы, описание правил заполнения схоже по принципу с оператором присвоения в языках программирования: слева указывается переменная, а справа – передаваемая ей значения, с той лишь разницей, что переменная характеризует поле на экране программы.
Таблица 1. Пример описания логики заполнения поля на основе ссылки
| № | Название поля | Описание поля | Правило | Алгоритм |
| 1 | BUDAT | Дата проводки /Posting date | = | MKPF-BUDAT |
| 2 | MATNR | Материал /Material | = | MSEG-MATNR |
| 3 | MENGE | Коли-во/ Quantity | = | MSEG-MENGE |
Следующим подходом для указания логики заполнения полей служит применение языка структурированных запросов SQL (Structured Query Language). Структура SQL единообразна и не зависит от языка программирования. Среда программирования может слегка менять синтаксис SQL, добавляя в него специфичный диалект, однако принципиальный разночтений он не дает. Команд обработки данных в языке SQL немного.
Примеры самых частых из них приведены на рис. 1. В спецификациях на разработку в 90% случаев используется оператор SELECT, все остальные применяются гораздо реже. Этот оператор позволяет осуществить выборку данных из таблицы при указании начальных ограничений (2):
где INTO является опциональной специфичный командой языка программирования, позволяющей сохранять найденные значения во временную переменную. Обычно переменная именуется схожим с названием таблицы образом, чтобы не путать разработчика. Рассмотрим пример, данный в табл. 2. Из него легко заметить, что использование SQL-запросов значительно упрощает задание выборки.
Однако в случае, если на экранной форме нужно выдать сразу несколько полей, значения которых хранятся в той же таблице баз данных, описание кажется слишком нагромождённым. Ощущается необходимость разовой записи SQL-запроса, а далее лишь ссылки на результаты выборки. Поэтому переходим к следующему, финальному способу описания.
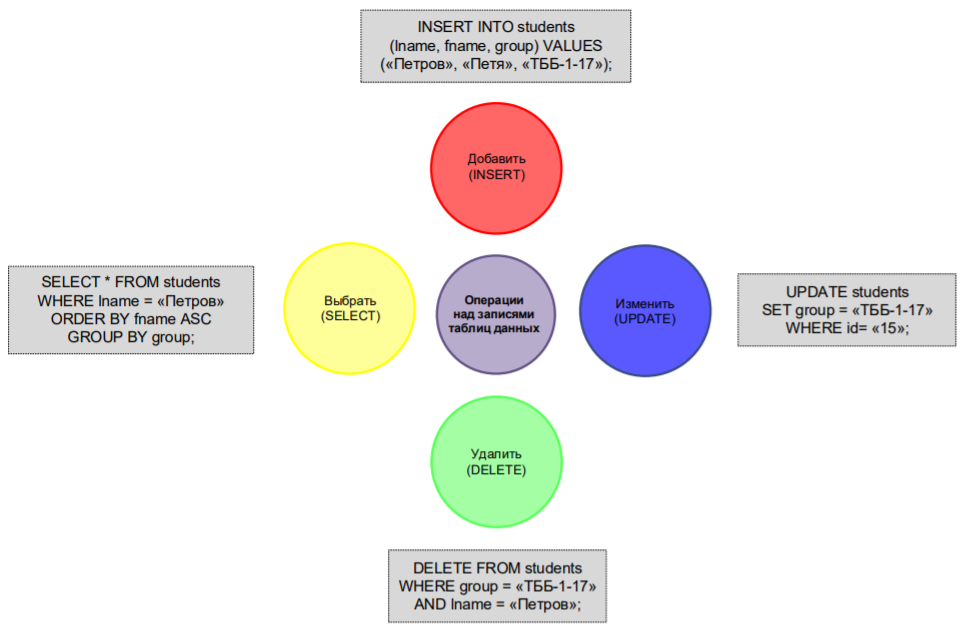
Рис. 1. Типовые SQL-запросы и примеры их использования
Таблица 2. Пример описания алгоритма выборки данных на основе SQL-запросов
| № | Название поля | Описание поля | Правило | Алгоритм |
| 1 | BUDAT | Дата проводки /Posting date | = | Select BUDAT from MKPF where MBLNR = «Номер документа материала» селекционного экрана and MJAHR = «Год документа материала» селекционного экрана |
| 2 | MATNR | Материал /Material | = | Select MATNR from MSEG where MBLNR = «Номер документа материала» селекционного экрана and MJAHR = «Год документа материала» селекционного экрана |
| 3 | MENGE | Коли-во/ Quantity | = | Select MENGE from MSEG where MBLNR = «Номер документа материала» селекционного экрана and MJAHR = «Год документа материала» селекционного экрана |
Наконец, третий способ проектирования алгоритмов выборки данных подразумевает применение как SQL-запросов, так и части команд прикладных языков программирования. В отличие от предыдущего способа, SQL-запросы выносятся в отдельные специи описания, находящиеся много раньше логики заполнения полей. Здесь работает подход: сначала выбираются все данные во временные массивы, которые затем используются для заполнения полей экранных форм. Поля же, в свою очередь, ссылаются на них. Более того, в случае необходимости задания сложной логики расчета, применяются команды языков программирования. Самая применяемая из которых LOOP AT (3):
позволяющая выполнять циклическую обработку данных для всех записей массива. Команда, в частности, сильно помогает, когда данные объекта нормализованы и разнесены по нескольким таблицам, например, заголовка и позиций. Проанализируем пример из табл.
3. Обратите внимание, что алгоритмы выбора данных 1-2 описаны в начале секции, причем оба из них сохраняют найденные значения во временные массивы. Алгоритм 2 использует команду LOOP AT для циклического выбора данных из нормализованной таблицы, относящейся к уровню позиции. Для заполнения поля 1, находящегося на уровне заголовка, применяется значение из временного массива, найденного согласно алгоритму 1, в то время, как поля 2-3 ссылаются на данные, полученные на основе алгоритма 2. Тем самым исключается дублирование описания, как это было отмечено в прошлом методе. Данный способ применяют более продвинутые функциональные специалисты в виду сложности.
Таблица 3. Пример описания логики обработки данных на основе SQL-запросов и прочих команд из языков программирования
Select * from MKPF Into MKPF where
MBLNR = «Номер документа материала» селекционного экрана and
MJAHR = «Год документа материала» селекционного экрана
Loop at MKPF (шага А1)
Select * from MSEG Into MSEG where
MBLNR = MKPF-MBLNR and
MJAHR = MKPF-MJAHR
В виду того, что нет какого-либо общего правила по описанию алгоритмов в спецификациях на разработку для проектов внедрения ERP-систем, каждый функциональный консультант использует свой подход. Если отталкиваться от опытности специалистов, то можно выделить три модели зрелости задания логики обработки данных. Первая модель подразумевает использование краткого текста для описания алгоритмов или проставления ссылки на конкретные поля таблиц данных, где хранится требуемая информация. При этом входные параметры выборок, тонкости алгоритмов и скорость их работы обычно игнорируется. По существу разработчику говорится, что нужно, а вот способ реализации он определяет сам.
Вторая модель зрелости подразумевает применение SQL-запросов с целью записи шагов выборки данных. Этот способ весьма популярен, так как язык структурированных запросов имеет единую форму записи во всех странах и знаком каждому разработчику. Из множества доступных SQL-запросов в спецификациях преимущественно используется команда SELECT.
Проблемы в данном случае остаются лишь в том, как записать логику, требующую сложную формулы расчета. Третья модель зрелости предполагает применение как SQL-запросов, так и команд языков программирования, например, LOOP для задания циклов обработки данных, что дает возможность записать даже самые незаурядные формулы. Однако стоит помнить, вне зависимости от модели зрелости, всегда остается возможность снабжения алгоритмов комментариями.
Литература
- Степанов Д.Ю. Формирование универсальных требований к пользовательским программам при подготовке спецификации на ABAP-разработку // Актуальные проблемы современной науки. – 2014. – т.78, №4. – c.258-268. – URL: https://stepanovd.com/science/26-article-2014-4-design.
- Грофф Д.Р., Вайнберг П.Н., Оппель Э.Д. SQL. Полное руководство. – М.: Вильямс, 2014. – 960 с.
Выходные данные статьи
Петров С.В. Использование SQL-запросов и команд языков программирования для описания алгоритмов выборки данных в функциональных спецификациях на разработку ERP-систем // Корпоративные информационные системы. – 2018. – №2 – С. 30-37. – URL: https://corpinfosys.ru/archive/issue-2/140-2018-2-sqlspecifications.

Об авторе
| Петров Сергей Владимирович – эксперт по разработке программных решений в банковской, торговой и производственной сферах. Специализируется на языках программирования высокого уровня С++, Java и Transact SQL. Имеет более чем 10-летний опыт разработки приложений. Принимал участие в проектах разработки аналитических, экспертных, биотехнических и корпоративных систем. Электронный адрес: Этот адрес электронной почты защищён от спам-ботов. У вас должен быть включен JavaScript для просмотра. |
Статьи выпуска №2
- Стартапы;
- Стратегия реализации в проектах КИС;
- Управление изменениями в проектах ERP-систем;
- Стратегия анализа в проектах внедрения ERP-систем;
- Использование SQL-запросов при подготовке спецификаций.
Источник: corpinfosys.ru
Обзор основных SQL запросов

![]()
05.03.2019
![]()
77262
Рейтинг: 5 . Проголосовало: 10
Вы проголосовали:
Для голосования нужно авторизироваться


Каждый сайт в Интернете, любой проект, обрабатывающий значительный объем информации, вынужден хранить эту информацию в тех или иных базах данных (БД). Подавляющее большинство проектов информацию сохраняют в БД реляционного типа, делая записи в различных подобиях таблиц. Как внесение новых записей, так и обращение к имеющимся, осуществляется с благодаря использованию запросов, составляемых конструкциями SQL (structured query language) – непроцедурного декларативного языка структурированных запросов. В нашем случае это подразумевает, что, используя конструкции SQL, мы будем обращаться к БД, сообщая что нужно сделать с данными, но не указывая способ, как именно это нужно сделать.
Фактически, SQL является набором стандартов, для написания запросов к БД. Последняя действующая редакция стандартов языка SQL — ISO/IEC 9075:2016.
Основываясь на указанных стандартах языка SQL, ряд организаций выпустили свои, расширенные версии стандартов указанного языка. Подобные версии иногда называют диалектами SQL.
Варианты спецификаций SQL разрабатываются компаниями и сообществами и служат, соответственно, для работы с разными СУБД (Системами Управления Базами Данных) – системами программ, заточенных под работу с продуктами из своей инфраструктуры.
Наиболее применяемые на сегодня СУБД, использующие свои стандарты (расширения) SQL:
MySQL – СУБД, принадлежащая компании Oracle.
PostgreSQL – свободная СУБД, поддерживаемая и развиваемая сообществом.
Microsoft SQL Server – СУБД, принадлежащая компании Microsoft. Применяет диалект Transact-SQL (T-SQL).
Благодаря тому, что диалекты SQL что создаются, специфицируются и используются разными организациями, имеют как общие черты, так и ряд отличий в возможностях расширений.
Общими чертами диалектов являются основные конструкции, применимые практически без отличий во многих реляционных БД. Основные отличия диалектов состоят в различиях использованных типов данных, количеством, реализацией и детальными возможностями команд. Разные диалекты применяют как разные наборы зарезервированных слов, так и разные наборы команд.
Здесь мы будем рассматривать запросы, применяя конструкции из спецификаций диалекта T-SQL.
Коснемся классификации SQL запросов.
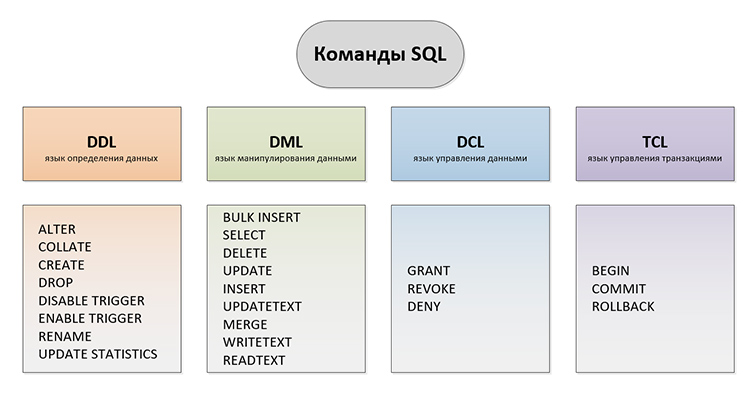
Выделяют такие виды SQL запросов:
DDL (Data Definition Language) — язык определения данных. Задачей DDL запросов является создание БД и описание ее структуры. Запросами такого вида устанавливаются правила того, в каком виде различные данные будут размещаться в БД.
DML (Data Manipulation Language) — язык манипулирования данными. В число запросов этого типа входят различные команды, используя которые непосредственно производятся некоторые манипуляции с данными. DML-запросы нужны для добавления изменений в уже внесенные данные, для получения данных из БД, для их сохранения, для обновления различных записей и для их удаления из БД. В число элементов DML-обращений входит основная часть SQL операторов.
DCL (Data Control Language) — язык управления данными. Включает в себя запросы и команды, касающиеся разрешений, прав и других настроек СУБД.
TCL (Transaction Control Language) — язык управления транзакциями. Конструкции такого типа применяют чтобы управлять изменениями, которые производятся с использованием DML запросов. Конструкции TCL позволяют нам производить объединение DML запросов в наборы транзакций.
Основные типы SQL запросов по их видам:
Ниже мы рассмотрим практические примеры применения SQL запросов для взаимодействия с БД используя запросы двух категорий – DDL и DML.
Тема связана со специальностями:
Создание и настройка базы данных
Нам нужна будет для примеров БД MS SQL Server 2017 и MS SQL Server Management Studio 2017.
Рассмотрим последовательность действий того, как создать SQL запрос. Воспользовавшись Management Studio, для начала создадим новый редактор скриптов. Чтобы это сделать, на стандартной панели инструментов выберем «Создать запрос». Или воспользуемся клавиатурной комбинацией Ctrl+N.
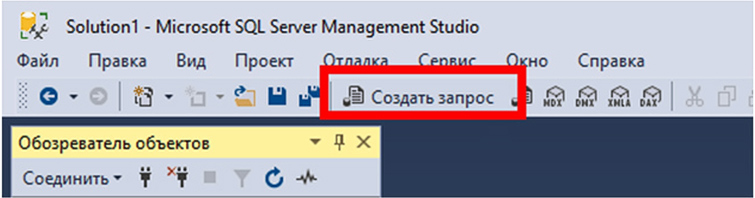
Нажимая кнопку «Создать запрос» в Management Studio, мы открываем тестовый редактор, используя который можно производить написание SQL запросов, сохранять их и запускать.
Используем для начала простые запросы SQL, благодаря которым можно создать и настроить новую БД, чтобы получить возможность в дальнейшем с ней работать.
Создадим новую БД с именем «b_library» для библиотеки книг. Чтобы это делать наберем в редакторе такой SQL запрос:
CREATE DATABASE b_library;
Далее выделим введенный текст и нажмем F5 или кнопку «Выполнить». У нас создастся БД «b_library».
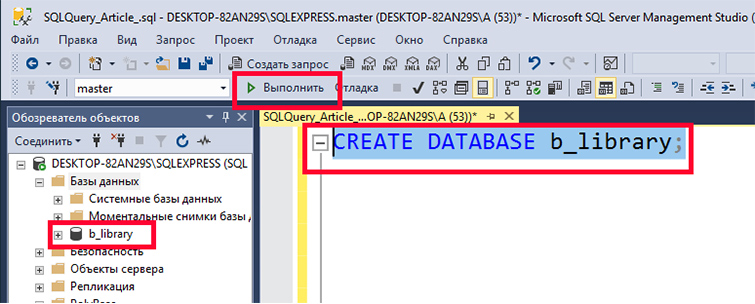
Все дальнейшие манипуляции мы можем провести с этой созданной нами БД. Для этого сначала подключимся к этой базе:
USE b_library;
В БД «b_library» создадим таблицу авторов «tAuthors» с такими столбцами: AuthorId, AuthorFirstName, AuthorLastName, AuthorAge:
CREATE TABLE tAuthors (
AuthorId INT IDENTITY (1, 1) NOT NULL,
AuthorFirstName NVARCHAR (20) NOT NULL,
AuthorLastName NVARCHAR (20) NOT NULL,
AuthorAge INT NOT NULL
);
Заполним нашу таблицу таким авторами: Александр Пушкин, Сергей Есенин, Джек Лондон, Шота Руставели и Рабиндранат Тагор. Для этого используем такой SQL запрос:
INSERT tAuthors VALUES
(‘Александр’, ‘Пушкин’, ’37’),
(‘Сергей’, ‘Есенин’, ’30’),
(‘Джек’, ‘Лондон’, ’40’),
(‘Шота’, ‘Руставели’, ’44’),
(‘Рабиндранат’, ‘Тагор’, ’80’);