
Познакомиться с основными поисковыми системами сети Интернет. Овладеть навыками работами в поисковых системах. Научиться выбирать оптимальную поисковую систему с учетом специфики поставленных задач.
Приборы и материалы
Для выполнения лабораторной работы необходим персональный компьютер, функционирующий под управлением операционной системы семейства WINDOWS. Должна быть установлена программа Internet Explorer.
Современные поисковые системы
Интернет — гигантское хранилище информации. Множество страниц, ценных и не очень, существуют безо всякого порядка и связанны между собой только случайными ссылками, зависящими от квалификации и личных пристрастий авторов сайтов. Однако пользователю необходимо ориентироваться в этом многообразии и находить, желательно за минуты, необходимую информацию.
В Интернет существует большое количество поисковых систем. По самым скромным оценкам, их более восьми тысяч, считая классические поисковые машины, общие и специализированные каталоги, а также метапоисковые Web-узлы (которые посылают запросы сразу на несколько поисковых серверов). В дополнение к этому существует ряд альтернативных средств поиска, способных вам пригодиться, включая утилиты, которые, работая совместно с браузером, добывают информацию из Web, и так называемые «экспертные узлы», где с вашими запросами работают живые люди. В настоящее время разрабатываются интеллектуальные поисковые системы. Примером такой системы может служить, например, интеллектуальная поисковая система Nigma (www.nigma.ru).
SEO продвижение сайта в 2023 году (грамотная раскрутка сайта за 7 шагов)
Поисковые машины и каталоги
При всем изобилии методов поиска в Internet наиболее распространенными средствами нахождения информации по-прежнему остаются поисковые машины и каталоги. Каждый из этих инструментов имеет определенные преимущества, а основная разница между ними заключается в участии/неучастии человека.
Поисковые машины – это комплекс специальных программ для поиска в сети.
Основные части программного комплекса:
1. Робот spider (паук). Автономно работающая программа, которая перебирает страницы сайтов, стоящих в очереди на индексацию. Она скачивает на диск поискового сервера содержимое исследуемых страниц.
2. Робот crawler (“путешествующий” паук). Его задача — собирать все ссылки на исследуемой странице, находить среди них новые, неизвестные поисковой системе, и добавлять их в список ожидающих индексации.
3. Индексатор. Обрабатывает страницы из очереди на индексацию. Для этого он составляет “словарь” странички, запоминает “частоту” использования слов. Особо отмечает ключевые слова, используемые в заголовках, выделенные в тексте жирным шрифтом. Помещает все это в особый файл — “индекс”.
4. База данных. Хранит ссылки на страницы, словарь встречаемых на странице слов и много другой информации, которая необходима для формирования результатов поиска.
5. Система обработки запросов и выдачи результатов. Принимает запрос пользователя, формирует запрос к базе данных, получает оттуда результат и передает его пользователю.
Бесплатные программы для ПЛАНИРОВКИ квартиры и создания ДИЗАЙНА ИНТЕРЬЕРА // Для новичков!!!
Поисковые машины запускают в Web программных «пауков», которые путешествуют со страницы на страницу и на каждой индексируют ее полный текст.
Практически у всех поисковых машин одинаковая форма запроса и примерно одинаковый формат выдачи результатов (см. пункт «Внешний вид поисковых страниц»), однако работа поисковых машин существенно различается. Во-первых, релевантностью (степенью соответствия результатов поиска запросу пользователя), во-вторых, величиной и частотой обновления баз данных, в-третьих, скоростью выдачи результатов. Ну и, конечно, поисковые машины различаются удобством работы.
На сегодняшний день поисковые системы — самые популярные страницы сети, на которых пользователи проводят очень много времени. Поэтому, все большее значение при выборе поисковика приобретают сопутствующие сервисы (почта, новостные ленты, торговые площадки и т.п.).
Каталоги — традиционное средство организации информации. Наверное, всем нам приходилось встречаться с библиотечными каталогами, каталогами товаров. Каталоги используются во множестве систем. Практически везде, где необходимо хранить и организовывать информацию.
Одна из основных задач, с которой сталкиваются составители каталогов — создать естественную, интуитивно понятную рядовому пользователю рубрикацию. К сожалению, данную задачу можно решить только с той или иной степенью приближения. Мир непрерывен, строгих границ в нем не существует. Один и тот же сайт можно рассматривать под разными углами зрения и видеть разные его функции. Каталоги формируются людьми-редакторами, которые прочитывают страницы, отсеивают неподходящие и классифицируют узлы по темам.
К недостаткам каталогов можно отнести следующее.
Во-первых, неоднозначность структуры — это явный минус каталожной организации информации (хотя он и несколько сглаживается тем, что в каждом крупном каталоге реализован поиск по каталогу).
Во-вторых, каталоги делают люди. Их полнота и качество зависят от количества и квалификации людей, занятых работой в каталоге, их личных вкусов и пристрастий. Неровность наполнения рубрик — характерная черта всех каталогов.
В- третьих, трудоемкость ручной рубрикации ограничивает объем каталогизируемой информации.
В тоже время безусловными достоинствами каталогов является то, что информация в нем хранится упорядоченно, в соответствии с элементарной человеческой логикой и релевантность найденных страниц при поиске в каталоге обычно на порядок выше, чем при поиске поисковыми системами.
Как было сказано выше, из-за того, что каталоги создаются вручную, они охватывают намного меньше ресурсов, чем поисковые машины. В Web сейчас, по самым скромным оценкам, насчитывается миллиард страниц (причем их число ежедневно увеличивается на миллион). Большинство поисковых машин не подошли сколько-нибудь близко к тому, чтобы проиндексировать всю Сеть. Исключением является Google (для России www.google.ru), который претендует именно на эту цифру — миллиард страниц, частично или полностью охваченных его индексами. Самый большой каталог — Open Directory Project (www.dmoz.org) — на этом фоне кажется крошечным: в него занесено лишь около 2 млн. страниц.
В 1994 г., когда начинался бурный рост «Всемирной паутины», выбор средств поиска в Сети был весьма ограниченным: Yahoo (www.yahoo.com). Этот сервер и по сей день остается краеугольным камнем исследования Web, но как каталог он столкнулся сейчас с жесткой конкуренцией со стороны Open Directory Project.
Многие каталоги весьма полезны, но с учетом всех обстоятельств предпочтение стоит отдать Open Directory Project. Проект Open Directory Project, инициированный компанией Netscape, реализуется усилиями редакторов-добровольцев со всего мира, которых насчитывается более 24 тысяч и которые проиндексировали около 2 млн. узлов b расклассифицировали их по более чем 200 тыс. категорий. Любой поисковый сервер может получить лицензию Open Directory Project и использовать его базу данных при обработке запросов, и на многих это сделано: AltaVista (www.altavista.com), HotBot (www.hotbot.com), Lycos (www.lycos.co.uk) и около сотни других серверов ныряют туда за ссылками.
Можно было бы ожидать, что, коль скоро каталог Open Directory Project создается силами добровольцев, качество результатов будет колебаться. Но в результате мы получаем хорошо организованные списки относящихся к теме страниц с четкими описаниями каждой ссылки. А узел Open Directory Project производит такое же впечатление, как Google: это «чистый поиск» без отвлекающих моментов типа ссылок на магазины.
Какой каталог ни выбрать, у всех есть одно преимущество перед поисковыми машинами: их можно систематически просматривать, пользуясь иерархической системой меню.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник: studopedia.ru
Поиск с помощью каталогов информационных ресурсов
Работать с поисковыми каталогами очень просто. В них поиск информации завершается более или менее плодотворно. Несмотря на простоту работы для пользователя создание и ведение каталога является очень сложным процессом, поскольку каталоги создаются вручную. Высококвалифицированные редакторы лично просматривают информационное пространство WWW, отбирают то, что, по их мнению, представляет общественный интерес и заносят адреса в каталог.
Однако очевидно, что учесть и предусмотреть все возможные варианты просто невозможно. Поэтому, несмотря на всю свою наглядность и открытость, каталоги — это далеко не всегда кратчайший путь к искомому результату. К тому же, нельзя не признать, что именно привычная тематическая каталогизация является причиной недостаточно высоких темпов обработки сайтов, которых к тому же становится все больше.
Предметные каталоги предоставляют и возможность автоматического поиска по ключевым словам. Однако поиск этот происходит не в содержимом самих WWW-серверов, а в их кратких описаниях, хранящихся в каталоге.
Несмотря на столь низкий коэффициент охвата, поисковые каталоги пользуются огромной популярностью. Их принято использовать для первичного, реферативного поиска информации по заданной теме. Если для пользователя тема является совершенно новой и неисследованной, то он вряд ли нуждается в расширенных результатах поиска. Прежде всего ему нужны указатели на классические, наиболее содержательные ресурсы, а именно это и обеспечивают поисковые каталоги. Человеческий фактор, связанный с тем, что над составлением каталога работают люди, а не программы, обеспечивает качественный отбор наиболее важных ресурсов по каждой из тем.
Количество поисковых каталогов в мире невелико, что связано с высокой трудоемкостью их содержания и обслуживания, а также с недостатком квалифицированных кадров-редакторов.
Каталоги могут быть специализированными и универсальными.
Специализированные каталоги включают только ссылки на сайты определенной тематики. Подобные каталоги удобны для поиска информации по конкретной тематике.
Универсальные же каталоги позволяют производить поиск по различным темам. Информация сгруппирована по разделам, а каждый раздел в свою очередь имеет несколько подразделов.
Как известно, в мире нет ничего абсолютно совершенного. Поэтому каталоги имеют как преимущества, так и недостатки.
Преимуществами каталогов являются следующее:
ª структура каталогов древовидная, а это позволяет быстро найти сайты по искомой информации;
ª перечисление Web-узлов происходит в порядке значимости (конечно понятно, что значимость определяется с точки зрения редакторов). Возможно применение сортировки по посещаемости или по дате открытия и тому подобных критериев;
ª в каталоге представлены наиболее популярные Web-узлы, связанные с той или иной темой;
ª существует высокая вероятность быстро найти наиболее «информированный» сайт по заданной теме.
Как уже было отмечено, у каталогов есть и недостатки, которые заключаются в следующем:
ª так как отбор ресурсов, которые упоминаются в каталоге, ведут редакторы, то появляется такой фактор как объективность при «ранжировании» сайтов;
ª в каталогах содержатся далеко не все существующие сайты, поскольку редакторы просто не в состоянии просмотреть миллионы Web-узлов, для того чтобы включить в каталог наиболее интересные ссылки;
ª каталоги обновляются достаточно медленно, а это приводит к тому, что найденные сайты и ссылки могут поменять адрес, а зачастую и вовсе исчезнуть.
Итак, при использовании каталога пользователь имеет преимущество в том, что каждый ресурс в нем был просмотрен и отобран человеком. Кроме того, группировка сайтов по определенным темам позволяет увидеть рядом сайты близкой тематики, причем совершенно не является фактом, что клиент найдет все эти сайты, просто набрав в поисковой службе название их категории в каталоге. Понятно, что хорошие каталоги обеспечивают дополнительный сервис. Это может быть поиск по ключевым словам, автоматическое оповещение по e-mail о свежих поступлениях, списки наиболее интересных поступлений и т.д. Такая организация делает использование коллекций информации очень удобным.
Информация о работе «Поиск информации в Интернете по теме «Учет текущих обязательств и расчетов с покупателями и заказчиками»»
Раздел: Информатика, программирование
Количество знаков с пробелами: 30099
Количество таблиц: 0
Количество изображений: 0
Источник: kazedu.com
Поисковые системы и каталоги
Объем хранящейся в Интернете информации чрезвычайно велик. Пользователи разыскивают в Интернете не только текстовые документы, новости, но и фото-, аудио-, видеоматериалы, товары, вакантные места работы.
Поиск информации в сети можно вести с помощью поисковых систем (ПС) и каталогов. Мощные поисковые системы и каталоги являются сложными техническими комплексами, содержащими десятки быстродействующих компьютеров, обслуживание которых ведут сотни специалистов. Вначале рассмотрим принцип действия ПС, а затем — каталогов.
Поисковые системы иначе называют: поисковыми средствами, поисковыми машинами, автоматическими индексами. Эквивалентными иностранными терминами являются: английский— Search Engines, немецкий — Suchmaschinen, французский — Le systeme de prospection. На жаргоне сети ПС иногда называют искалками, поисковиками.
Работа ПС основывается на формировании запроса, по которому происходит отбор нужных документов из базы данных, хранящейся на сервере. Запрос формируется с помощью ключевых слов (одного или нескольких). Результаты поиска выдаются пользователю в виде списка адресов (гиперссылок) и краткой аннотации к ним.
Запрос — это набор соединенных операторами ключевых слов, с помощью которых поисковая система автоматически ведет поиск и отбор необходимых документов. Другими словами, запрос — это инструкция (команда) для ПС на поиск нужных документов.
Запросы бывают двух типов: простые и сложные (или расширенные, advanced).
Простые запросы состоят из отдельных ключевых слов или словосочетаний. Сложные запросы, кроме ключевых слов, содержат логические и другие операторы.
Поиск — это процедура отбора нужных документов, хранящихся в сети.
Поиск осуществляется либо автоматически с помощью ключевых слов, вводимых в ПС, либо путем последовательного ручного прохода по рубрикам в каталогах.
Поиск с помощью ключевых слов сводится к их вводу (формированию запроса) в специальное поле Поиск и последующему нажатию кнопки Найти. Кнопка Найти в разных ПС может называться Search, Find, Go, Go Get it, Suchen, апорт!, Поиск.
На рисунке приведены фрагменты трех поисковых систем с изображением полей для ввода запросов и командных кнопок.
Для ускорения процедуры поиска ПС производит обработку хранящихся в сети документов — индексацию.
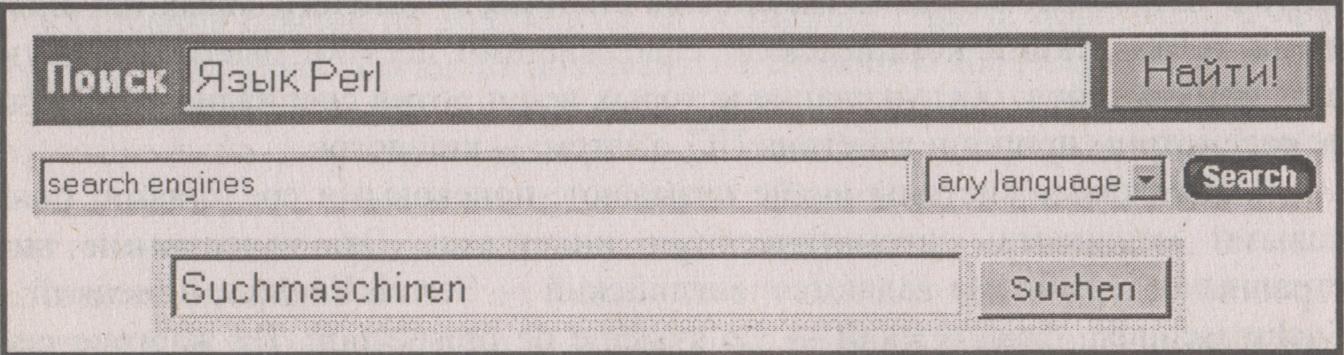
Индексация — это процедура автоматического создания базы данных, в которой хранятся ключевые слова, аннотации документов и доменные адреса, по которым размещены эти документы. В базе данных каждому документу ставится в соответствие свой набор ключевых слов и доменных адресов.
Когда идет обслуживание конкретного запроса на поиск нужной информации, то ПС сравнивает ключевые слова, введенные пользователем, с ключевыми словами, полученными в процессе индексации и хранящимися в базе данных ПС. При совпадении этих слов пользователю выдается доменный адрес данного документа, т. е. указывается место его хранения в сети.
Процедура поиска по ключевым словам очень напоминает работу с обычной книгой, в которой есть алфавитный указатель. Читатель с помощью алфавитного указателя определяет номера страниц книги, на которых присутствует нужное ключевое слово. Этим ускоряется поиск нужной информации. В данном примере номер страницы книги — это как бы доменный адрес Web-страницы.
Индексация документов, размещенных на различных серверах, производится поисковыми системами автоматически с помощью специальных программ — роботов (Robots). Другие названия этих программ — пауки (Spiders) или черви (Worms).
Робот (паук, червь) — программа, которая автоматически периодически «посещает» сайты и индексирует их (т. е. собирает сведения о их содержимом и местоположении).
Назначение роботов очевидно: эти программы постоянно «осматривают», сканируют сеть, запоминают, что где лежит, чтобы в нужный момент времени показать пользователю точное место хранения документа (т. е. его доменный адрес). Этим объясняется потрясающе высокая скорость поиска нужной информации. Фактически роботы начинают поиск задолго до обслуживания конкретного запроса.
Тенденция развития ПС такова, что наиболее быстродействующие ПС стремятся произвести индексацию всего документа, а не только его названия и первых предложений текста. Наиболее совершенные роботы при индексации сканируют не только главную (домашнюю) страницу, но и по гиперссылкам заходят вглубь сайта (узла). Ограничивается такая идеалистическая картина индексации лишь низкой скоростью работы современных ПС и общим быстродействием всей сети.
Предварительная индексация хранящихся в сети документов позволяет впоследствии за несколько секунд обслуживания запроса обработать (отсортировать) гигабайты разнообразной информации.
С помощью механизма предварительной индексации можно получить хороший результат поиска в случаях, когда удается точно сформировать запрос с помощью небольшого числа ключевых слов. В иных случаях пользователь либо получит большое число ссылок (иногда говорят, линков, т. е. связей), которые являются лишь «информационным шумом», либо вовсе не удастся найти необходимый документ.
Значительно повышают избирательность поиска фильтры, которыми снабжаются поисковые системы. Фильтры позволяют:
— ограничить список отбираемых документов с помощью логических операторов (выполнить так называемый сложный поиск);
- ограничить пространство поиска типом протокола, с помощью которого был создан документ (поиск на Web-сайтах или в телеконференциях);
- ограничить отбираемый материал временным отрезком, определенными датами создания разыскиваемого документа (например, между 31 июля|2002 г. и 5 августа 2006 г.);
- отобрать документы, составленные только на определенном языке (русский, английский);
— ограничить отбор документов территорией размещения серверов(например, только Европа); — ограничить поиск определенной частью документа (заголовок, доменный адрес); — отобрать документы, которые содержат фразу с заданным порядком расположения ключевых слов. Поиск русских документов в сети дополнительно осложняется особенностями национальной грамматики. В русском языке (в отличие от английского языка) необходимо учитывать падежные окончания ключевых слов. Наибольшей популярностью в русскоязычной части Интернета пользуются поисковые системы Rambler (произносится Ремблер, а переводится как бродяга, праздношатающийся, его адрес www.rambler.ru), Апорт (www.aport.ru), Google (произносится Гугл, доменный адрес www.google.ru) и Яndех (www.yandex.ru). Русскоязычные ПС позволяют отбрасывать окончания, ключевых слов и заменять их метасимволами «*» и «?». При этом на запрос «самар*» будут найдены документы, содержащие слова: Самара, Самары, самарский, самарская и т. п. Поисковая система Aport использует принципы искусственного интеллекта. Она обрабатывает запрос таким образом, что подбирает синонимы введенным ключевым словам и автоматически решает проблему падежных окончаний. При поиске информации ПС может делать две ошибки: пропускать (не отбирать) нужные пользователю документы и, наоборот, отбирать (присылать) посторонние документы (мусор, информационный шум). Эти ошибки, совершаемые автоматическими ПС, описываются терминами «избирательность» и «чувствительность». Заметим, что в приведенной фразе есть некоторая терминологическая неточность: ПС отбирают не документы, а лишь гиперссылки на них. С помощью полученных ссылок пользователь просматривает или загружает на собственный компьютер понравившийся ему документ. Однако методически удобнее говорить о несоответствии запросу документа, а не гиперссылки. Избирательность — способность ПС отбирать документы, соответствующие запросу, не включая лишних документов. Качество избирательности характеризуется числом ошибок первого рода — число отобранных документов, не соответствующих запросу. Чем выше избирательность, тем меньше посторонних документов попадает к пользователю. Избирательность можно изменять (регулировать) с помощью логических операторов (фильтров). Чувствительность — способность ПС отбирать документы, соответствующие запросу, не пропуская нужных документов. Чувствительность характеризуется числом ошибок второго рода — числом пропусков нужных документов. Чем выше чувствительность, тем меньше вероятность пропуска нужного документа. Релевантность — степень (мера) соответствия (адекватности) найденного в процессе поиска документа сделанному запросу. Уточнить запрос (говорят: отфильтровать информацию) позволяют логические операторы OR, AND, NOT. Использование логического оператора AND (И) приводит к отбору документов, которые обязательно содержат все перечисленные в запросе ключевые слова, соединенные этим оператором. Оператор NOT (НЕТ) позволяет исключить документы, которые содержат ключевое слово, указанное после этого оператора. С помощью оператора NEAR (вблизи, рядом) пользователь может отбирать документы, в которых ключевые слова, соединенные этим оператором, будут находиться поблизости друг от друга, а не в разных концах документа. Оператор FOLLOWED BY позволяет отбирать документы, в которых ключевые слова следуют друг за другом в заданном порядке. Оператор ADJ отбирает документы, в которых ключевые слова являются смежными (следуют одно за другим). К сожалению, каждая ПС имеет собственный синтаксис запросов. Поэтому перед формированием расширенных запросов необходимо уточнить правила использования логических и других операторов. В настоящее время ведутся работы по унификации приемов работы на различных ПС. В 1999 г. началась разработка проекта SESP (Search Engine Standards Project), который призван стандартизировать работу поисковых служб. Современные ПС становятся интеллектуальными. Используя принципы искусственного интеллекта, они ранжируют (располагают) выводимый список документов (ссылок на них) в зависимости от степени их релевантности. При этом ПС анализируют положение найденных ключевых слов в документе (заголовок или текст), число повторений ключевых слов, их взаимное расположение в документе. Наиболее точно отобранные документы располагаются в начале списка найденных в процессе поиска документов. Для ранжирования найденных документов используют следующие показатели. Положение ключевого слова на странице (keyword prominence) — показатель, определяющий, как близко к началу документа находится заданное ключевое слово. Как правило, чем ближе к началу страницы располагается ключевое слово, тем точнее документ соответствует запросу. Частота ключевого слова (keyword frequency) — показатель, учитывающий абсолютную частоту использования ключевых слов (т. е. сколько раз встречается данное ключевое слово на странице). Наибольший «вес» при ранжировании документов имеют слова, расположенные в заголовке Web-страницы (так называемый титул). Именно этот заголовок отображается в строке заголовка браузера при просмотре страницы, и приведенные там слова имеют наибольшую ценность для ПС. Некоторые поисковые системы при ранжировании учитывают индекс цитирования (link popularity) — количество сайтов, которые ссылаются на данный сайт. Не всякий запрос можно четко сформулировать с помощью небольшого числа ключевых слов. Поэтому, кроме индексного механизма, используются и другие механизмы поиска и хранения информации в сети. Как отмечалось ранее, поиск информации в Интернете можно производить с помощью поисковых систем и каталогов. Другое нередко используемое название поисковых средств, построенных с помощью каталогов, — иерархические ПС. Термин «иерархия» означает: расположение частей или элементов целого в порядке от высшего к низшему. В данном случае правильнее говорить: иерархия — это уточнение содержания документа от его общих характеристик к частным характеристикам. Синонимами термина «каталог» являются слова: директория, справочник, категория, рубрикатор. Каталоги представляют собой тематически подобранные сетевые адреса, которые сопровождаются краткими комментариями (аннотациями). Каталоги появились самым естественным путем: пользователи отбирали для себя ссылки на любимые места в Интернете и составляли упорядоченные тематические списки с детализацией каждого раздела (рубрики). Именно так возник всемирно известный каталог Yahoo!, созданный студентами Стэндфордского университета Дэвидом Фило и Джерри Янгом. В каталогах размещение информации ведется с помощью многоуровневой рубрикации, причем на каждом уровне происходит все большая детализация (уточнение) сведений об искомом (хранящемся) документе. При этом каждая последующая рубрика не исключает свойств документа, определенных предыдущей рубрикой, а лишь уточняет их. Иначе говорят: рубрики находятся в отношении соподчинения, иерархии. Еще говорят: используется принцип последовательного уточнения. Важным термином, характеризующим работу каталогов, является рубрикация. Рубрикация— помещение документа в соответствующий раздел (подраздел, рубрику), которое, как правило, производится вручную специалистами (модераторами, аналитиками) или авторами разработанных документов. Разработчиков Web-страниц иногда называют владельцами ресурсов или Web-дизайнерами. Процедура рубрикации достаточно субъективна и осуществляется на основании индивидуальных представлений людей о данной предметной области. Авторы при размещении своих страниц порой руководствуются не соображением точного соответствия документа названию рубрики, а другими соображениями. Например, с целью увеличения посещаемости своих Web-страниц их помещают в рубрики, наиболее популярные в данный мо мент времени. Документ, содержащий разнообразную информацию на Web-странице, порой помещают в несколько рубрик. На следующем рисунке показан фрагмент каталога. Указанные рубрики содержат в себе другие рубрики, в которые еще в большей степени уточняют содержимое хранящегося документа. 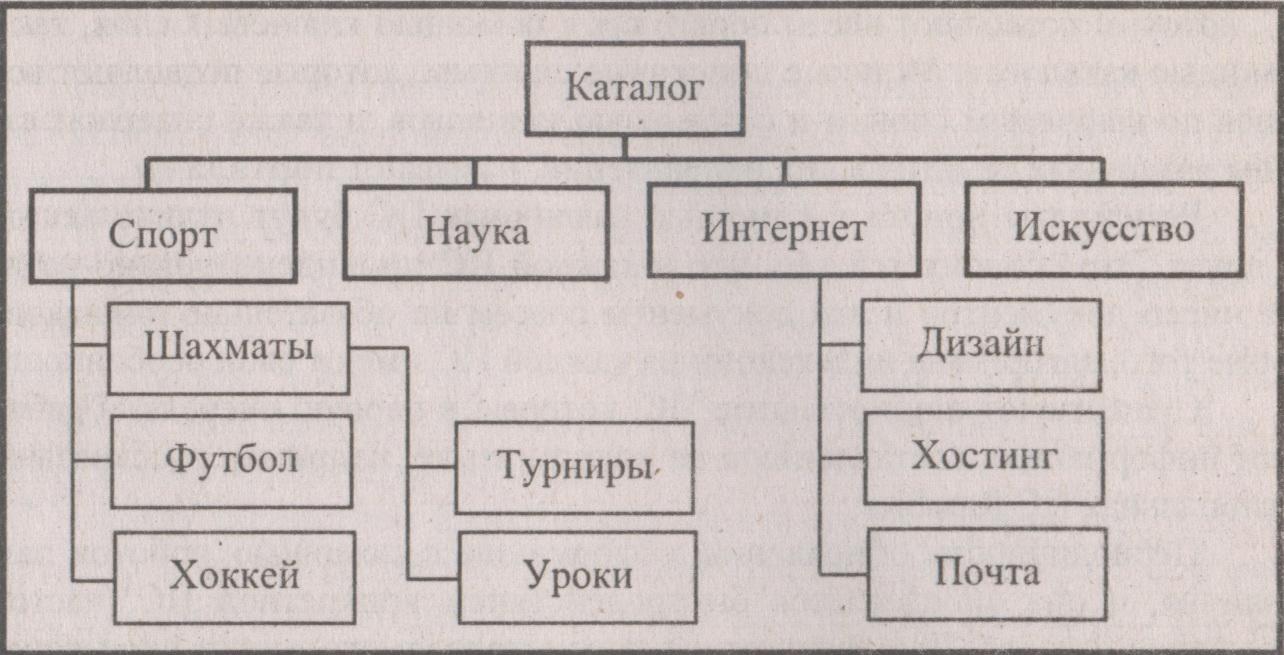 Перечислим доменные адреса некоторых отечественных каталогов: http://www.mail.ru/, http://www.km.ru/url/, http://www.ru/, http://www.ulitka.ru/, http://www.susanin.net/, http://students.informika.ru, h
Перечислим доменные адреса некоторых отечественных каталогов: http://www.mail.ru/, http://www.km.ru/url/, http://www.ru/, http://www.ulitka.ru/, http://www.susanin.net/, http://students.informika.ru, h ttp://www.stars.ru/, http://yp.piter.com/. В Интернете, кроме иерархических каталогов, встречаются и другие типы каталогов — неиерархические, в которых нет соподчинения, например, каталоги, использующие алфавитно-предметную классификацию. В качестве примера можно назвать энциклопедии, музыкальные сайты, телефонные справочники и др. На рисунке слева показан фрагмент неиерархического каталога, в котором хранятся музыкальные произведения в алфавитном порядке. Таким образом, поисковые системы и тематические каталоги имеют свои достоинства и недостатки, взаимно дополняют друг друга. Поисковые системы «осматривают» большое число сайтов, однако автоматический отбор искомых документов сопровождается достаточно большим числом ошибок. База данных каталога хранится на одном сервере и содержит меньший объем информации, чем ПС. Тем не менее, результаты поиска с помощью каталогов имеют большую релевантность по сравнению с поиском с помощью ПС. Естественным путем образовались комбинированные (гибридные) ПС, которые позволяют вести поиск, как с помощью ключевых слов, так и с помощью каталогов. Мощные поисковые системы, которые позволяют вести поиск по ключевым словам и с помощью каталогов, а также содержат страницы различных тематических направлений, называют порталами. Результаты поиска с помощью различных ПС будут отличаться друг от друга. Это объясняется тем, что в каждой ПС проиндексировано различное число документов и эти документы совсем не обязательно одинаковые. Кроме того, алгоритмы индексации на каждой ПС имеют свои особенности. Существуют национальные ПС, которые в первую очередь обрабатывают информацию, составленную на родном языке, например русскоязычная региональная ПС Rambler. Периодичность обновления информации с помощью роботов также различна, и она определяется быстродействием конкретной ПС (частотой посещения сайтов). Для расширения просматриваемого в сети пространства рекомендуют использовать несколько ПС. Метапоисковая система позволяет вести автоматический поиск по сделанному запросу с использованием сразу нескольких поисковых машин. Укажем адреса некоторых метапоисковых систем: www.metacrawler.com, www.metor.com, www.infozoid.com, www.accufnd.com. Кроме ПС общего назначения существуют специализированные ПС. Они предназначены для поиска музыкальных файлов (www.midi.ru), произведений искусств (www.artplanet.com), рисунков (www.graphsearch.com), книг (http://bukinist.agava.ru/), кулинарные рецептов (www.cooking.ru/search.html). В заключение перечислим ПС, предназначенные для поиска файлов: http://www.lycos.com/computers/downloads/ http://www.filesearch.ru/ http://www.files.ru/ http://www.freeware.ru/ При использовании перечисленных систем поиск происходит не с помощью ключевых слов, а по известным именам файлов.
ttp://www.stars.ru/, http://yp.piter.com/. В Интернете, кроме иерархических каталогов, встречаются и другие типы каталогов — неиерархические, в которых нет соподчинения, например, каталоги, использующие алфавитно-предметную классификацию. В качестве примера можно назвать энциклопедии, музыкальные сайты, телефонные справочники и др. На рисунке слева показан фрагмент неиерархического каталога, в котором хранятся музыкальные произведения в алфавитном порядке. Таким образом, поисковые системы и тематические каталоги имеют свои достоинства и недостатки, взаимно дополняют друг друга. Поисковые системы «осматривают» большое число сайтов, однако автоматический отбор искомых документов сопровождается достаточно большим числом ошибок. База данных каталога хранится на одном сервере и содержит меньший объем информации, чем ПС. Тем не менее, результаты поиска с помощью каталогов имеют большую релевантность по сравнению с поиском с помощью ПС. Естественным путем образовались комбинированные (гибридные) ПС, которые позволяют вести поиск, как с помощью ключевых слов, так и с помощью каталогов. Мощные поисковые системы, которые позволяют вести поиск по ключевым словам и с помощью каталогов, а также содержат страницы различных тематических направлений, называют порталами. Результаты поиска с помощью различных ПС будут отличаться друг от друга. Это объясняется тем, что в каждой ПС проиндексировано различное число документов и эти документы совсем не обязательно одинаковые. Кроме того, алгоритмы индексации на каждой ПС имеют свои особенности. Существуют национальные ПС, которые в первую очередь обрабатывают информацию, составленную на родном языке, например русскоязычная региональная ПС Rambler. Периодичность обновления информации с помощью роботов также различна, и она определяется быстродействием конкретной ПС (частотой посещения сайтов). Для расширения просматриваемого в сети пространства рекомендуют использовать несколько ПС. Метапоисковая система позволяет вести автоматический поиск по сделанному запросу с использованием сразу нескольких поисковых машин. Укажем адреса некоторых метапоисковых систем: www.metacrawler.com, www.metor.com, www.infozoid.com, www.accufnd.com. Кроме ПС общего назначения существуют специализированные ПС. Они предназначены для поиска музыкальных файлов (www.midi.ru), произведений искусств (www.artplanet.com), рисунков (www.graphsearch.com), книг (http://bukinist.agava.ru/), кулинарные рецептов (www.cooking.ru/search.html). В заключение перечислим ПС, предназначенные для поиска файлов: http://www.lycos.com/computers/downloads/ http://www.filesearch.ru/ http://www.files.ru/ http://www.freeware.ru/ При использовании перечисленных систем поиск происходит не с помощью ключевых слов, а по известным именам файлов.
Источник: studfile.net