
При тестировании веб-приложений методом BlackBox у нас, как правило, не будет доступа ко всем исходным кодам приложения. Однако нам всегда доступен исходный код веб-страниц. Его необходимо тщательно изучить на предмет утечек информации.
Программисты, в том числе и разработчики веб-приложений, стараются комментировать свой код. Комментарии в коде полезны как во время разработки, так и после, особенно если разработчиков, работающих с данным кодом, много. Но комментарии в коде могут быть полезны и злоумышленникам, если они сожержат конфиденциальную информацию.
Комментарии HTML в коде начинаются с символов :
Комментарии javascript бывают однострочные, и следуют за двойным слэшем //
// однострочный комментарий javascript
И бывают многострочные, которые заключаются между символами /* и */
/* это многострочный комментарий */
Кроме комментариев в коде стоит обратить внимание на теги (они так же могут содержать полезную информацию), скрипты (к примеру, можно обнаружить подозрительный код на сайте или определить технологии, которые используются в приложении), пути к ресурсам приложения. Ниже я приведу несколько примеров.
Подарок на 8 марта на Python. Исходный код в закреплённом комментарии. #shorts #Shorts
Теги с атрибутом name=»author» позволяют тестеру определить автора документа, его email. Такая информация может помочь в дальшейшем при подборе паролей к административным интерфейсам или скорректировать векторы атаки:
Атрибут http-equiv тега позволяет изменять значения некоторых заголовков ответа веб-сервера. Браузер обрабатывает значение этого атрибута так, как будто бы это значение пришло непосредственно от сервера:
В данном случае в коде веб-страницы устанавливаются следующие заголовки ответа:
Refresh — с помощью этого значения определяется время задержки, после которой браузер автоматически перезагрузит страницу. Дополнительно в теге можно указать, какой именно документ нужно загрузить. В данном случае (на скрине выше) без какой-либо задержки должен загружаться документ /server-manager.
Expires — дата устаревания документа, при наступлении которой браузер должен обратиться к серверу за новой версией страницы, а не брать ее из кэша. Значение, равное нулю, интерпретируется как «сейчас».
Cache-Control определяет, должен ли браузер кэшировать данную страницу.
Иногда информация может быть раскрыта в коде скриптов:
в данном скрипте сожержится адрес, по которому, вероятно, находится тестовая версия приложения. При попытке доступа к странице по этому адресу запрашивается логин и пароль:
КАК ЧИТАТЬ ИСХОДНЫЕ КОДЫ | СОВЕТЫ ОТ СОЕРА
Так же по данному url мы можем предположить, что CMS тестируемого приложения — 1c-bitrix.
А в данном скрипте был раскрыт путь от сайта до корня сервера и один из ip-адресов:
Комментарии в js-скриптах или html-коде могут содержать учетные данные:
Непонятно, почему логин и пароль в таком виде и что это за кодировка. Но если посмотреть на длину логина и пароля, то можно предположить, что это admin и pass, и в итоге предположение оказалось верным.
В ходе данного этапа тестирования нужно просмотреть исходный код всех страниц приложения, которые вы найдете. Так же не забывайте про кэш Гугла, в котором можно найти старые версии веб-страниц и соответственно старые исходники.
Определение точек входа приложения.
Когда пентестер исследует приложение, он особенно должен обращать внимение на все HTTP-запросы, на то, где используются GET и POST запросы, на каждый параметр в запросе и на каждое поле ввода в формах. Определение точек входа является ключевой задачей, прежде чем можно будет провести тщательное тестирование, так как это позволяет выявить вероятные слабые места. В ходе этого этапа мы должны выяснить, как формируются запросы в приложении и типичные ответы от сервера.
Для просмотра параметров, отправляемых в POST-заросах вы можете использовать встроенные средства браузера или перехватывающий прокси, такой как OWASP Zap или Burp. В POST-запросах особое внимание обратите на скрытые поля (hidden), в которых может передаваться конфиденциальная информация, или информация, которую по задумке разработчика вы не должны видеть и изменять.
Перед началом этого этапа тестирования составьте таблицу, в левую часть которой записывайте все запросы, а в правую все ответы на эти запросы. Это может быть утомительным и скучным занятием, но именно на этом этапе мы определяем, что и как мы будем тестировать дальше.
В таблице нужно отметить, является ли запрос GET или POST, все заголовки запросов и ответов, является ли доступ аутентифицированным или нет, используется ли SSL, является ли запрос частью многоэтапного процесса и другие замечания, которые покажутся вам важными. Так же обратите внимание, что в приложении могут использоваться и другие HTTP-методы, кроме GET и POST, например PUT или DELETE, которые могут представлять опасность для веб-приложения.
Чек-лист этого этапа выглядит так:
Запросы
— определите, где используются GET-запросы, где POST-запросы, используются ли другие HTTP-методы и в каких точках приложения
— определите все параметры, используемые в каждом POST-запросе
— определите все скрытые параметры POST-запроса. Обычно они не видны в браузере (то есть поля ввода для этих параметров не отображаются в окне браузера), но их можно увидеть в теле запроса, если использовать перехватывающий прокси. В зависимости от значений скрытых параметров может отличаться следующая страница, которая отдается серевером после выполнения запроса, может различаться уровень доступа или данные на странице
— определите все параметры, используемые в каждом GET-запросе. В частности строку запроса (которая обычно следует в URL после знака вопроса), cookie, host
— определите все параметры строки запроса. Они обычно представлены в форме пары параметр=значение, например foo=bar, page=10 и тд. Параметров может быть много и они могут быть разделены символом Server: BIG-IP» указывает на то, что приложение использует балансировщик нагрузки
Примеры.
POST-запрос, просмотр средствами браузера. Можно просмотреть как заголовки запроса и ответа, так и параметры запроса.
Заголовки ответа:
Некоторые параметры в запросе выше являются скрытыми и их нельзя изменить через обычную форму ввода:
GET-запрос. В запросе имеется два параметра — параметр id со значением 69545 и параметр veaction со значением edit:
ЧПУ — человеко-понятные УРЛ, семантические URL
Человеко-понятный УРЛ — URL-путь, состоящий из понятных слов, вместо идентификаторов, и отражающий файловую структуру сайта. Например, вместо
/index.php?cat=10id=41 будет /product/phone/Samsung/ .
Такие URL все чаще можно встретить в современных веб-приложениях. В связи с этим возникает вопрос, как определять параметры GET-запросов, если приложение использует ЧПУ?
Частично на данный вопрос отвечает этот документ —
Ссылка скрыта от гостей
Приведу один пример, в котором оказалось легко выявить параметры строки запроса. Ниже на скриншотах видим семантический URL:
и тот же запрос в привычном виде, с параметром и значением id=5:
Опять же можно попробовать поискать в Гугле. Такие проиндексированные URL могут дать некоторое понимание, как в приложении формируются запросы на самом деле:
Карта приложения.
Теперь, когда мы определили точки входа, для более ясного понимания структуры приложения, понимания его рабочих процессов, можно составить карту приложения. В ходе дальнейшего тестирования мы будем часто обращаться к этой карте, так как на ней будет наглядно представлено, какие части приложения мы уже протестировали, какие области еще не покрыты тестированием, в каких местах найдены уязвимости и недочеты.
Сбор информации для составления карты удобно выполнять с помощью OWASP Zap:
После того, как ZAP пройдется веб-пауком по всему сайту, можно выгрузить все найденные URL в отдельный текстовый файл. Структуру сайта и найденные точки входа можно просматривать в самом ZAP в навигационном окне слева. В окне справа можно просматривать каждый выполненый запрос и ответ.
Теперь на основе полученной информации можно составить карту. Я пробовал использовать для этого LibreOffice Draw и у меня получалось что-то вроде этого:
Реальная карта должна быть более детализирована. Чем выше детализация, тем лучше.
Но мне показалось удобнее составлять карту прямо в exel-таблице, в которой до этого я сохранял точки входа приложения, а так же запросы и ответы. Можно быстро вносить изменения в карту и делать пометки:
Как будете составлять карту вы, решайте сами, но хоть в каком-то виде она обязательно нужна.
Опытных пентестеров прошу поделиться в комментариях своими вариантами, если имеются.
У меня на сегодня все. Всем пока! )
Источник: codeby.net
Программисты, давайте изучать исходники классических программ
Современные программисты — счастливчики: мы живём в мире, в котором исторические и оказавшие существенное влияние программы имеют открытый код, доступный для изучения. Однако, многие программисты только учатся, и изучают те программы, над которыми работают сами. У нас редко находится время для изучения исторических работ, и курсы программирования редко тратят время на такие вещи.
Исходный код программы с комментариями
strcpy(fname,argv[1]);//êàê íàçâàíèå äëÿ ôàéëà îò÷åòà.
strcpy(foname,argv[2]);//Âòîðîé àðãóìåíò — äëÿ ÷òåíèÿ.
f.open(fname);//Ñîçäàíèå è ïîäãîòîâêà ôàéëà ê çàïèñè.
bool=menu();//Áàçîâàÿ ôóíêöèÿ ïðîãðàììû.
f.close();//Çàêðûòèå ôàéëà è çàïèñü íà ÆÄ.
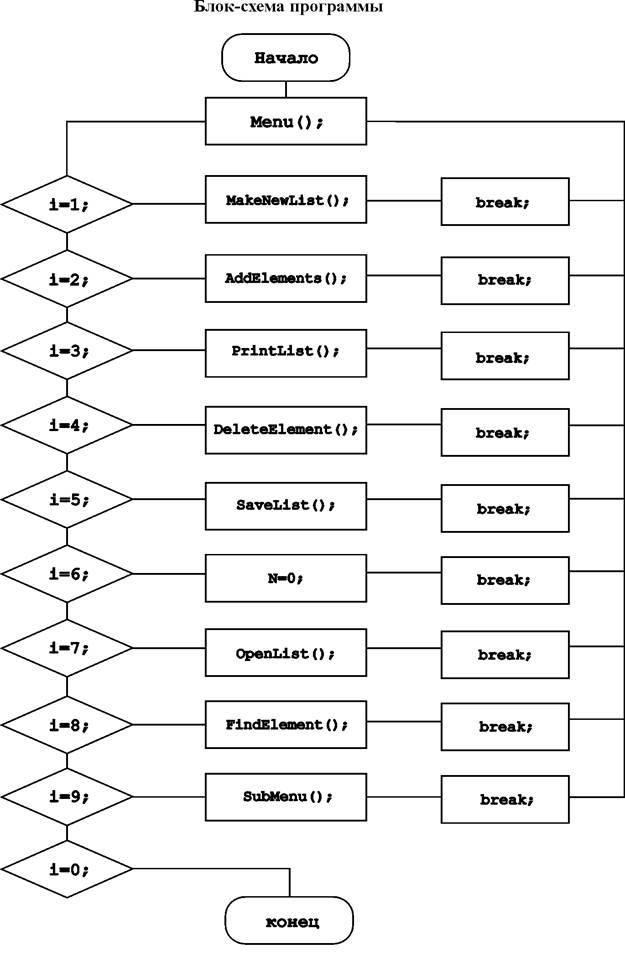
case 2: AddElements(); break; //Add Element
case 3: PrintList(); break; //Print List
case 4: DeleteElement(); break; //Delete Element
case 5: SaveList(); break; //Save List
case 6: n=0; break; //Erase List
case 7: OpenList(); break; //Open File
case 8: FindElement(); break; //Find Element
case 9: SubMenu(); break; //Sort List
case 0: return -1; //Exit
extern int *MasP[100],n,argcGlobal;
extern ofstream f;
case 2: SortByDecrease(); break; //Decrease
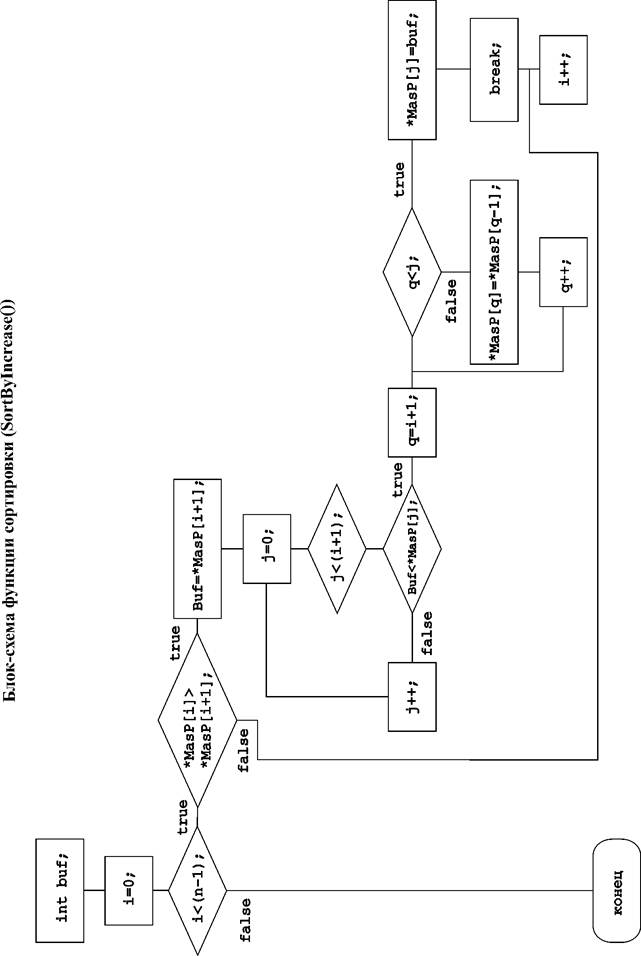
for (int q=i+1; q>j; q—)
>//for Incert place
>//Find unsorted element
>//for Find unsorted element
for (int q=i+1; q>j; q—)
>//for Incert place
>//Find unsorted element
>//for Find unsorted element
void OpenList(char s[20])
char *FileName=new char[20];
//Ïîäêëþ÷àåì ñòðàæè âêëþ÷åíèé.
extern char foname[20];
void OpenList(char s[20]=foname);
Список литературы
1. Лафоре Р. Объектно-ориентированное программирование в С++, 4-е изд. — СПб.: Питер, 2003. – 928 с.: ил.
2. Дейтел Х.М., Дейтел П.Дж. Как программировать на С++.. – М.: Бином, 1999. — 1024 с.
3. Страуструп Б. Язык программирования С++, 3-е изд. — СПб.; М.: Невский Диалект — Бином, 1999. — 991 с.
4. Керниган Б., Ритчи Д. Язык программирования Си. Пер. с англ., 3-е изд., испр. — СПб.: «Невский Диалект», 2001. — 352 с.: ил.
Примечание 1.
Примечание 2.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Самое популярное на сайте:
Источник: studopedia.ru