
Написание интерпретатора скриптов на С++. Часть 1: Обзор.
Тянулся нудный осенний вечер; делать как всегда было нечего. И вдруг, ни с того ни с сего, пришла мне в голову идея написать статью по созданию интерпретатора. «Делать тебе нечего. – иди лучше к коллоквиуму по вышке готовься», — раздался внутренний голос. И я уже было потянулся к розетке, чтобы вырубить мой компьютер, но внезапно вспомнил.
Вспомнил, как я сам писал систему обработки сценариев. Вспомнил, сколько времени, усилий и нервов было впустую затрачено на поиск исчерпывающей информации по этой теме. Вспомнил бессонные ночи, проведенные за отладкой. И еще много чего вспомнил, а потом. послал свой внутренний голос и принялся за работу.
Этот цикл статей предназначен, прежде всего, для читателя, не имеющего опыта работы в области написания интерпретаторов. Я постараюсь рассмотреть этот процесс настолько подробно, на сколько позволяют мои знания и опыт. Итак:
Тема работы: написание системы обработки сценариев на С++.
Что такое компилятор и интерпретатор ? Их основные отличия.
Цель работы:
1) ознакомление читателя с темой;
2) создание работоспособного интерпретатора с нуля;
3) его «внедрение» в какое-либо приложение.
Приборы и оборудование: базовые навыки владения С++, ООП и STL.
Постановка задачи:
Возможности языка
По существу, наша система обработки сценариев состоит из следующих основных компонентов:
— Lexer – преобразует входные данные (обычно, файл) в поток лексем (таких как ключевые слова, операторы и т.д.);
— Generator – генерирует байт код для последующего выполнения виртуальной машиной;
— Executor – выполняет байт код.
А вот наглядное изображение взаимодействия этих компонентов:
Термины и понятия:
Ниже я привожу словарь терминов и понятий, которые будут периодически использоваться в последующих статьях цикла. Все нижеперечисленные определения рассматриваются в контексте скриптов ESL.
аргумент (или параметр) – это значение, передаваемое в функцию. Например в случае вызова функции IntToStr(123) аргументов является число 123.
выражение – это то, что приводит к некоторому значению. Например, как простая переменная, так и формула (x*n-1)/y2k являются выражениями. Любое выражение можно превратить в инструкцию, добавив после него «;». Операции присваивания также являются выражениями. Примеры выражений: x, y = x, func1(), y = func1().
идентификатор – это имя, определенное в скрипте. Любое слово в программе (за исключением комментариев и ключевых слов) является идентификатором. Все имена стандартных и игровых функций также являются идентификаторами.
Как работает язык программирования(Компилятор)? Основы программирования.
инструкция – базовый элемент скрипта. Пример: for(. ), if(. ), a = b;.
ключевое слово – это имя, определенное в самом ESL. Сюда не включаются имена стандартных и программных функций, которые являются идентификаторами. Примеры: if, for, end.
комментарии – строки (или части строк), содержащие игнорируемый лексером текст. Комментарии введены для пояснения скриптов. Комментарием считается текст, заключенный между «%» и концом строки. Например:
%это комментарий, находящийся справа от кода
%это комментарий, находящийся в новой строке
операнд – это подвыражение, которое при помощи операторов комбинируется в более сложное выражение. Например, в выражении x + y оператор «+» имеет два операнда x и y.
оператор – символ, определенный в ESL, при помощи которого подвыражения (операнды) комбинируются в более сложные выражения. Например +,-,*.
определение – создание новой переменной.
переменная – именованный фрагмент памяти для хранения данных. Названия переменных не должны совпадать с ключевыми словами и функциями и могут состоять из латинских или русских букв, цифр и символа подчеркивания. Пример: a, _string1_.
составная инструкция – группа инструкций, заключенных в фигурные скобки. Пример:
строка (string) – тип переменной в ESL, представляющий собой совокупность символов.
управляющая структура – это инструкция, имеющая возможность изменять ход выполнения программы на основе каких-либо условий. Управляющими структурами в ESL являются if-else, while и for.
функция – группа инструкций, исполняемая как единое целое и предназначенная для выполнения некоторых действий или получения значения. В ESL имеются стандартные (встроенные в исходный код программы ESL) и внешние (встроенные в исходный код вызывающей программы) функции. Возможность создания новых функций в скриптах (пока) отсутствует.
Уфф. кажется все. Первая, думаю самая сложная для написания, статья готова. Теперь читатель ознакомлен с общими принципами языка ESL, поэтому, следующие части будут посвящены более интересным вопросам — непосредственно реализации системы сценариев.
Готов выслушать все вопросы, предложения и критику.
Источник: gamedev.ru
Глава 29. Интерпретатор языка C
Завершающая глава книги посвящена теме, представляющей интерес для всех программистов, работающих с языком С, и кроме того, она иллюстрирует основные средства языка путем создания интерпретатора языка Little С.
Не отрицая всей значимости и актуальности компиляторов, приходится признать, что их создание — очень трудный и длительный процесс. Фактически, одно только создание библиотеки рабочих программ компилятора уже представляет собой чрезвычайно сложную задачу. В то же время создание интерпретатора языка — сравнительно более легкая задача, «выполнимая» в рамках одной главы.
Нужно отметить, что легче понять принципы работы хорошо сконструированного интерпретатора, чем аналогичного компилятора. Помимо простоты разработки, интерпретатор языка содержит нечто такое, чего нет в компиляторе, — движущий механизм, фактически выполняющий программу. Необходимо помнить, что компилятор только транслирует исходный текст программы, то есть придает программе тот вид, в котором она выполняется компьютером, а интерпретатор выполняет программу. Именно это различие делает интерпретаторы более интересной темой для рассмотрения.
Большинство программистов, пишущих программы на С, оценили не только мощность и гибкость этого языка, но и его необычную формальную красоту, сделавшую его особенно привлекательным для специалистов. Благодаря его логичности и чистоте о языке С часто говорят как об элегантном языке.
К настоящему времени об использовании языка С и принципах программирования на нем написано довольно много, однако исследования работы языка «изнутри» встречаются не часто. Поэтому лучшим способом завершения этой книги будет создание программы на С, интерпретирующей подмножество этого же языка.
В данной главе рассматривается разработка интерпретатора, способного выполнять программы, написанные на подмножестве языка С. Этот интерпретатор не только вполне работоспособен, он также написан таким образом, что его легко расширять, добавляя новые средства, отсутствующие даже в стандарте С. Читатель, который не знает, как выполняется программа на языке С, будет приятно удивлен прямолинейностью ее выполнения. Язык С — один из самых теоретически последовательных языков программирования. Ознакомившись с этой главой, читатель не только получит интерпретатор С, пригодный для использования и расширения, но и существенно улучшит свое понимание структуры языка. К тому же, сама работа с этим интерпретатором — весьма интересное и увлекательное занятие.
- Практическое значение интерпретатора
- Определение языка Little C
- Интерпретация структурированного языка
- Неформальная теория языка С
- Синтаксический анализатор выражений
- Интерпретатор Little C
- Библиотечные функции Little C
- Компиляция и компановка интерпретатора Little C
- Демонстрация Little C
- Усовершенствование интерпретатора Little C
- Расширение Little C
Источник: t-r-o-n.ru
0.2 – Введение в языки программирования
Современные компьютеры невероятно быстры и постоянно становятся еще быстрее. Однако они также имеют некоторые существенные ограничения: они изначально понимают только ограниченный набор команд, и им нужно точно сказать, что делать.
Компьютерная программа (также обычно называемая приложением) – это набор инструкций, которые компьютер может выполнить для выполнения некоторой задачи. Процесс создания программы называется программированием. Программисты обычно создают программы, создавая исходный код (обычно сокращено говорят просто код), который представляет собой список команд, введенных в один или несколько текстовых файлов.
Набор физических компонентов компьютера, из которых состоит компьютер, и которые выполняют программы, называется аппаратным обеспечением. Когда компьютерная программа загружается в память и аппаратное обеспечение последовательно выполняет каждую инструкцию, это называется запуском или выполнением программы.
Машинный язык
Центральный процессор (CPU) компьютера не понимает язык C++. Ограниченный набор инструкций, которые CPU может понимать напрямую, называется машинным кодом (или машинным языком, или набором инструкций).
Вот пример инструкции машинного языка: 10110000 01100001 .
Когда были изобретены первые компьютеры, программистам приходилось писать программы непосредственно на машинном коде, что было очень трудно и отнимало много времени.
Как организованы эти инструкции, выходит за рамки данного введения, но интересно отметить две вещи.
- Во-первых, каждая инструкция состоит из последовательности нулей и единиц. Каждый отдельный 0 или 1 называется битом (от «binary digit», или «двоичная цифра»). Количество битов, составляющих одну команду, может различаться – например, некоторые процессоры обрабатывают инструкции, которые всегда имеют длину 32 бита, тогда как некоторые другие процессоры (например, семейство x86, которое вы, вероятно, используете) имеют инструкции, которые могут быть переменной длины.
- Во-вторых, каждый набор битов интерпретируется центральным процессором в команду для выполнения очень конкретной работы, например, сравнения этих двух чисел или помещения этого числа в эту ячейку памяти. Однако из-за того, что разные CPU имеют разные наборы инструкций, инструкции, написанные для одного типа процессоров, не могут использоваться процессором, который не использует такой же набор команд. Это означало, что программы, как правило, нельзя было портировать (переносить, использовать без серьезной доработки) между различными типами систем, и их приходилось переписывать заново.
Язык ассемблера
Поскольку людям трудно читать и понимать машинный код, был изобретен ассемблер. В языке ассемблера каждая инструкция идентифицируется коротким сокращением (а не набором битов), и могут использоваться имена и другие числа.
Вот та же инструкция, что и выше, но на языке ассемблера: mov al, 061h .
Это сделало разработку намного проще для чтения и записи, чем машинный код. Однако CPU не понимает ассемблер напрямую. Вместо этого программа на ассемблере, прежде чем она сможет быть выполнена компьютером, должна быть переведена на машинный код. Это делается с помощью программы, называемой ассемблером. Программы, написанные на языках ассемблера, обычно бывают очень быстрыми, и ассемблер всё еще используется сегодня, когда очень важна скорость выполнения программы.
Однако у ассемблера всё же есть недостатки. Во-первых, языки ассемблера по-прежнему требуют использования множества инструкций даже для простых задач. Хотя отдельные инструкции в некоторой степени удобочитаемы, понимание того, что делает вся программа, может быть сложной задачей (это немного похоже на попытку понять предложение, рассматривая каждую букву по отдельности). Во-вторых, язык ассемблера по-прежнему не очень портируем – программа, написанная на ассемблере для одного процессора, скорее всего, не будет работать на аппаратном обеспечении, использующем другой набор инструкций, и ее придется переписывать или сильно модифицировать.
Высокоуровневые языки
Чтобы решить проблемы удобочитаемости и переносимости, были разработаны новые языки программирования, такие как C, C++, Pascal (и более поздние языки, такие как Java, Javascript и Perl). Эти языки называются языками высокого уровня, поскольку они разработаны, чтобы позволить программисту писать программы, не беспокоясь о том, на каком компьютере будет выполняться программа.
Вот всё та же инструкция, что и выше, на C/C++: a = 97;
Как и программы на ассемблере, программы, написанные на языках высокого уровня, прежде чем их можно будет запустить, должны быть переведены в формат, понятный компьютеру. Это можно сделать двумя основными способами: компиляция и интерпретация.
Компилятор – это программа, которая читает исходный код и создает автономную исполняемую программу, которую затем можно запустить. После того, как ваш код был преобразован в исполняемый файл, вам не нужен компилятор для запуска программы. Вначале компиляторы были примитивными и создавали медленный, неоптимизированный код. Однако с годами компиляторы стали очень хороши в создании быстрого, оптимизированного кода и в некоторых случаях могут делать его лучше, чем люди, пишущие на ассемблере!
Ниже показано упрощенное представление процесса компиляции:
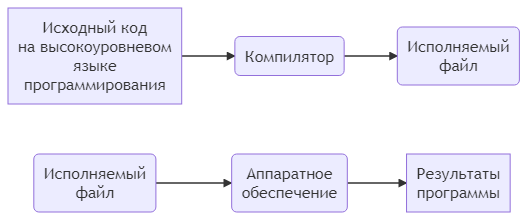
Поскольку программы на C++ обычно компилируются, мы вскоре рассмотрим компиляторы более подробно.
Интерпретатор – это программа, которая непосредственно выполняет инструкции в исходном коде, не требуя их предварительной компиляции в исполняемый файл. Интерпретаторы, как правило, более гибки, чем компиляторы, но менее эффективны при запуске программ, потому что при запуске программы каждый раз должен выполняться процесс интерпретации. Это означает, что при каждом запуске программы требуется интерпретатор.
Ниже показано упрощенное представление процесса интерпретации:

Дополнительная информация
Ни один из подходов не имеет перед другим явного преимущества – если бы один подход всегда был лучше, велика вероятность, что мы стали бы использовать его повсюду!
В целом, компиляторы имеют следующие преимущества:
- Поскольку они могут видеть весь исходный код заранее, при генерации кода они могут выполнять ряд анализов и оптимизаций, благодаря чему окончательная версия кода выполняется быстрее, чем простая интерпретация каждой строки по отдельности.
- Компиляторы часто могут генерировать низкоуровневый код, который выполняет эквивалент высокоуровневых идей, таких как «динамическое связывание» или «наследование» с точки зрения поиска в памяти внутри таблиц. Это означает, что итоговые программы должны помнить меньше информации об исходном коде, что снижает использование памяти сгенерированной программой.
- Скомпилированный код обычно быстрее, чем интерпретируемый код, потому, что выполняемые инструкции обычно предназначены только для самой программы, а не для самой программы плюс накладные расходы интерпретатора.
В целом, у компиляторов есть следующие недостатки:
- Некоторые языковые функции, такие как динамическая типизация, сложно эффективно скомпилировать, потому, что компилятор не может предсказать, что произойдет, пока программа не будет запущена. Это означает, что компилятор может генерировать не очень хороший код.
- Компиляторы обычно имеют длительное время «запуска» из-за затрат на выполнение всего анализа, который они делают. Это означает, что в таких окружениях, как веб-браузеры, где важно быстро загружать код, компиляторы могут работать медленнее, потому что они оптимизируют короткий код, который не будет запускаться много раз.
В целом, у интерпретаторов есть следующие преимущества:
- Поскольку они могут читать код в том виде, в каком он написан, и им не нужно выполнять дорогостоящие операции для генерации или оптимизации кода, они, как правило, запускаются быстрее, чем компиляторы.
- Поскольку интерпретаторы могут видеть, что делает программа во время ее выполнения, интерпретаторы могут использовать ряд динамических оптимизаций, которые компиляторы могут не видеть.
В целом, у интерпретаторов есть следующие недостатки:
- Интерпретаторы обычно используют больше памяти, чем компиляторы, потому, что интерпретатору необходимо хранить больше информации о программе, доступной во время выполнения.
- Интерпретаторы обычно тратят некоторое время процессора внутри кода для интерпретатора, что может замедлить выполнение программы.
Поскольку у интерпретаторов и компиляторов есть взаимодополняющие сильные и слабые стороны, в средах выполнения языка становится всё более обычным явлением сочетание элементов обоих методов. Хорошим примером этого является JVM – сам код Java компилируется и изначально интерпретируется. Затем JVM может найти код, который выполняется много-много раз, и скомпилировать его непосредственно в машинный код, что означает, что «горячий» код получает преимущества компиляции, а «холодный» – нет. JVM также может выполнять ряд динамических оптимизаций, таких как встроенное кэширование, для повышения производительности способами, которые обычно не выполняются компиляторами.
Многие современные реализации JavaScript используют аналогичные приемы. Большая часть кода JavaScript короткая и не так уж много чего делает, поэтому обычно начинают с интерпретатора. Однако если станет ясно, что код запускается неоднократно, многие JS-движки скомпилируют код (или, по крайней мере, скомпилируют его отдельные части) и оптимизируют его, используя стандартные методы. В конечном итоге код работает быстро при запуске (полезно для быстрой загрузки веб-страниц), а также быстрее работает и при дальнейшем выполнении.
И последняя деталь: языки не компилируются и не интерпретируются. Обычно код C компилируется, но доступны и интерпретаторы C, которые упрощают отладку или визуализацию выполняемого кода (они часто используются при вводном изучении программирования – или, по крайней мере, они использовались раньше).
JavaScript считался интерпретируемым языком, пока некоторые JS-движки не начали его компилировать. Некоторые реализации Python являются чисто интерпретаторами, но вы можете найти компиляторы Python, которые генерируют нативный код. Некоторые языки легче компилировать или интерпретировать, чем другие, но ничто не мешает вам создать компилятор или интерпретатор для любого конкретного языка программирования. Теоретический результат, называемый проекциями Футамуры, показывает, что всё, что можно интерпретировать, можно и скомпилировать.
Большинство языков можно компилировать или интерпретировать, однако традиционно языки, такие как C, C++ и Pascal, компилируются, тогда как «скриптовые» языки, такие как Perl и Javascript, обычно интерпретируются. В некоторых языках, например в Java, используется сочетание этих двух методов.
Высокоуровневые языки обладают многими необходимыми свойствами.
Во-первых, на языках высокого уровня намного легче читать и писать, потому что команды ближе к естественному языку, который мы используем каждый день.
Во-вторых, высокоуровневые языки требуют меньшего количества инструкций, чем низкоуровневые языки, для выполнения одной и той же задачи, что делает программы более краткими и легкими для понимания. В C++ вы можете сделать что-то вроде a = b * 2 + 5; в одну строку. На ассемблере для этого потребуется 5 или 6 разных инструкций.
В-третьих, программы можно компилировать (или интерпретировать) для многих различных систем, и вам не нужно изменять программу для работы на разных процессорах (вы просто перекомпилируете ее для конкретного процессора). В качестве примера:
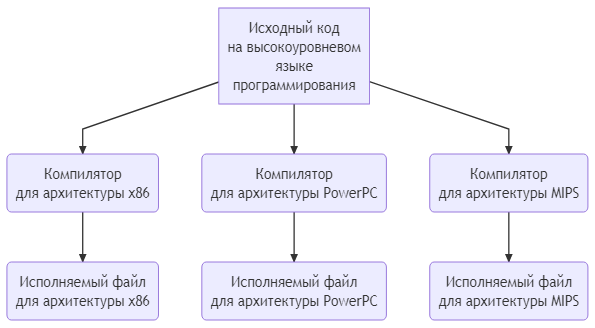
В портируемости есть два общих исключения. Во-первых, многие операционные системы, такие как Microsoft Windows, содержат специфичные для платформы возможности, которые вы можете использовать в своем коде. Это может значительно упростить написание программы для конкретной операционной системы, но за счет усложнения портируемости. В данной серии статей мы избегаем кода, специфичного для какой-либо платформы.
Некоторые компиляторы также поддерживают специфичные для компилятора расширения – если вы их используете, ваши программы без изменений не смогут компилироваться другими компиляторами, которые не поддерживают те же расширения. Мы поговорим об этом позже, когда вы установите компилятор.
Правила, рекомендации и предупреждения
По мере изучения этих руководств мы будем выделять важные моменты в следующих трех категориях:
Правило
Правила – это инструкции, которые вы должны выполнять в соответствии с требованиями языка. Несоблюдение правил обычно приводит к тому, что ваша программа не работает.
Лучшая практика
Лучшие практики – это то, что вам следует делать, потому что такой способ обычно считается стандартным или настоятельно рекомендуется. То есть либо так поступают все (а если вы поступите иначе, то вы будете делать не то, что ожидают), либо это лучше других альтернатив.
Предупреждение
Предупреждения – это то, чего делать не следует, поскольку они обычно приводят к неожиданным результатам.
Источник: radioprog.ru
Интерпретатор
Интерпрета́тор ( промежуточный код», и только после этого приступают к выполнению. И поэтому все синтаксические ошибки обнаруживаются до выполнения. Такие интерпретаторы быстрее выполняют большие и циклические программы, так как не занимаются анализом исходного кода (в т.ч. избыточным, например, в циклах) в реальном времени, но могут быть сложны для начинающих.
Некоторые интерпретаторы для начинающих (преимущественно, для языка См. также
Внимание! Это незаконченная статья. Вы можете помочь доработать статью и наполнить ее материалом.
Для улучшения статьи необходимо: отнести в категорию и дописать
Источник: osdev.fandom.com