
Как правильно установить файл opencl.dll
Подскажите у меня ферма выключалась из-за ошибки, я скачал и установил opencl.dll. скачал и как обычная установка установил. но проблема осталась. может этот файл нужно было как то по особому устанавливать. помещать специально в какую то папку.
immortal85
Друг форума
Сообщения 1.625 Оценка реакций 421
переустанови видео-драйвер
Забой
Бывалый
Сообщения 314 Оценка реакций 195
Было тож такое на Win7 переустановка дров (Win7-Beta-Blockchain-Aug23) не помогает. На Win 10 НОРМ, не стал плясать дальше оставил 10.
jcda
Свой человек
Сообщения 196 Оценка реакций 89
Но ты молодец, все очень подробно и хорошо расписал, ферма выключилась из-за ошибки, это сразу наталкивает на мысль что, что-то не так. Думаю проблема в обычной установки, попробуй установить её не обычно, с изюминкой например утилитой Regsvr32 это очень не обычная утилита, даже больше чем утилита это аж служебная программа для командной строки, что тоже весьма не обычно, для регистрации библеотек в реестре винды.
Обзор новой версии Hashcat 6.0 | OpenCL для CPU
Источник: miningclub.info
Как скачать opencl.dll и исправить ошибки при запуске игр и программ

Opencl.dll — ещё один файл, который часто вызывает ошибки как при входе в Windows 10, 8.1 и Windows 7, так и при запуске игр или программ, такие как «Не удается продолжить выполнение кода, поскольку система не обнаружила opencl.dll», «Запуск программы не возможен, так как на компьютере отсутствует opencl.dll», «Системная ошибка» при запуске amdrsserv.exe и другие.
В этой инструкции подробно о том, как скачать и установить opencl.dll x64 и 32-бит и исправить рассматриваемые ошибки в Windows.
- Исправление ошибок opencl.dll
- Дополнительная информация
- Видео инструкция
Как исправить системные ошибки, вызванные отсутствием opencl.dll

Opencl.dll — одна из библиотек DLL, используемых в программах, использующих технологии OpenCL (Open Computing Language) для просчета графики или других операций с использованием GPU (видеокарты). Технология поддерживается NVIDIA, Intel и AMD.
Скачивать этот файл отдельно со стороннего сайта и пробовать его зарегистрировать в Windows вручную можно, но не является лучшим методом. В случае видеокарт AMD ранее был доступен отдельный OpenCL Driver, но сегодня для систем Windows 10, 8.1 или Windows 7 он не актуален.
Opencl.dll FIX Or Repair For Windows 10
Файл opencl.dll присутствует в комплекте драйверов для всех современных дискретных и интегрированных видеокарт: NVIDIA GeForce, AMD Radeon и Intel HD Graphics. Поэтому лучшее и наиболее часто работающее решение — установка этих драйверов:
- Внимание: «обновление» драйвера кнопкой «Обновить» в диспетчере устройств — это не то, что требуется: так мы получим не все файлы и более того, этот метод иногда и вовсе не производит обновления.
- Если вы, еще до того, как нашли это руководство откуда-то скачали и поместили вручную файлы opencl.dll в папки C:WindowsSystem32 и C:WindowsSysWOW64, лучше их оттуда убрать, они могут помешать следующим шагам.
- Скачайте последний драйвер для вашей видеокарты с официального сайта NVIDIA, AMD или Intel. Внимание: если у вас есть и интегрированная и дискретная видеокарта, например, AMD и Intel, загрузите оба драйвера. Особенно это важно для драйверов AMD, без сопутствующей установки драйвера от Intel (при наличии и этого GPU), ошибки amdrsserv.exe могут продолжать появляться.
- Будет полезным (но обычно не обязательно), если перед запуском установщиков вы удалите текущие драйверы: для некоторых это возможно сделать в Панель управления — Программы и компоненты, для некоторых — с помощью бесплатной утилиты Display Driver Uninstaller (DDU).
- Установите загруженный драйвер или драйверы (при наличии нескольких GPU). В случае если установщик в параметрах предлагает выполнить «чистую установку» (например, NVIDIA), выполните именно её.
- На всякий случай перезагрузите компьютер.
После выполнения указанных действий файлы opencl.dll должны автоматически оказаться в папке C:WindowsSystem32, а в Windows x64 — еще и в C:WindowsSysWOW64, а ошибки «Не удается продолжить выполнение кода, поскольку система не обнаружила opencl.dll», «Системная ошибка amdrsserv.exe» (напрямую связанная с драйверами AMD, которые при появлении этой ошибки следует переустановить вручную) и подобные не должны вас больше побеспокоить.
Дополнительная информация
Если эта статья — не первая, которую вы находите на тему ошибок opencl.dll, вы вероятнее встречали рекомендацию скачать этот файл, скопировать в ранее упоминавшиеся папки и выполнить команду regsvr32.exe opencl.dll (или иные варианты этой команды). Простое копирование файла иногда может исправить ошибку. А проблема с этим методом в том, что зарегистрировать (установить) эту DLL таким методом не получится.
Вы получите сообщение о том, что «Точка входа DllRegisterServer» не найдена, иначе говоря, файл не поддерживает механизм регистрации с помощью regsvr32.dll. Отдельно следует отметить, что в папках System32 и SysWOW64 должны быть разные файлы opencl.dll — для x64 и x86, а обычно предлагается один, что может приводить к ошибкам.
Загрузка и установка opencl.dll — видео инструкция
А вдруг и это будет интересно:
- Лучшие бесплатные программы для Windows
- Как включить скрытые темы оформления Windows 11 22H2
- Как сделать скриншот в Windows 11 — все способы
- Как установить сертификаты Минцифры для Сбербанка и других сайтов в Windows
- Как скрыть файлы внутри других файлов в Windows — использование OpenPuff
- Как исправить ошибку 0x0000011b при подключении принтера в Windows 11 и Windows 10
- Windows 11
- Windows 10
- Android
- Загрузочная флешка
- Лечение вирусов
- Восстановление данных
- Установка с флешки
- Настройка роутера
- Всё про Windows
- В контакте
- Одноклассники
- Живые обои на рабочий стол Windows 11 и Windows 10
- Лучшие бесплатные программы на каждый день
- Как скачать Windows 10 64-бит и 32-бит оригинальный ISO
- Как смотреть ТВ онлайн бесплатно
- Бесплатные программы для восстановления данных
- Лучшие бесплатные антивирусы
- Средства удаления вредоносных программ (которых не видит ваш антивирус)
- Встроенные системные утилиты Windows 10, 8 и 7, о которых многие не знают
- Бесплатные программы удаленного управления компьютером
- Запуск Windows 10 с флешки без установки
- Лучший антивирус для Windows 10
- Бесплатные программы для ремонта флешек
- Что делать, если сильно греется и выключается ноутбук
- Программы для очистки компьютера от ненужных файлов
- Лучший браузер для Windows
- Бесплатный офис для Windows
- Запуск Android игр и программ в Windows (Эмуляторы Android)
- Что делать, если компьютер не видит флешку
- Управление Android с компьютера
- Как включить скрытые темы оформления Windows 11 22H2
- Как сделать скриншот в Windows 11 — все способы
- Как установить сертификаты Минцифры для Сбербанка и других сайтов в Windows
- Как скрыть файлы внутри других файлов в Windows — использование OpenPuff
- Как исправить ошибку 0x0000011b при подключении принтера в Windows 11 и Windows 10
- Как отключить камеру в Windows 11 и Windows 10
- Как включить режим экономии памяти и энергосбережения в Google Chrome
- Как удалить пароли в Яндекс Браузере
- Ваш системный администратор ограничил доступ к некоторым областям этого приложения в окне Безопасность Windows
- Программы для анализа дампов памяти Windows
- Как скрыть уведомления на экране блокировки iPhone
- Как вернуть меню Пуск из Windows 10 или 7 в Windows 11
- Как запускать DOS программы и игры в Windows 11 и 10
- Сжатая память в Windows 10 и Windows 11 — что это?
- Введите A1B2C3 чтобы повторить попытку при входе в Windows 11 и Windows 10 — варианты решения
- Windows
- Android
- iPhone, iPad и Mac
- Программы
- Загрузочная флешка
- Лечение вирусов
- Восстановление данных
- Ноутбуки
- Wi-Fi и настройка роутера
- Интернет и браузеры
- Для начинающих
- Безопасность
- Ремонт компьютеров
- Windows
- Android
- iPhone, iPad и Mac
- Программы
- Загрузочная флешка
- Лечение вирусов
- Восстановление данных
- Ноутбуки
- Wi-Fi и настройка роутера
- Интернет и браузеры
- Для начинающих
- Безопасность
- Ремонт компьютеров
Источник: remontka.pro
Введение в GPU-вычисления
Видеокарты – это не только показатель фпс в новейших играх, это еще и первобытная мощь параллельных вычислений, оставляющая позади самые могучие процессоры. В видеокартах таится множество простых процессоров, умеющих лихо перемалывать большие объемы данных. GPU-программирование – это та отрасль параллельных вычислений где все еще никак не устаканятся единые стандарты – что затрудняет использование простаивающих мощностей.
В этой заметке собрана информация которая поможет понять общие принципы GPU-программирования.
Введение в архитектуру GPU

Разделяют два вида устройств – то которое управляет общей логикой – host, и то которое умеет быстро выполнить некоторый набор инструкций над большим объемом данных – device.
В роли хоста обычно выступает центральный процессор (CPU – например i5/i7).
В роли вычислительного устройства – видеокарта (GPU – GTX690/HD7970). Видеокарта содержит Compute Units – процессорные ядра. Неразбериху вводят и производители NVidia называет свои Streaming Multiprocessor unit или SMX , а
ATI – SIMD Engine или Vector Processor. В современных игровых видеокартах – их 8-32.
Процессорные ядра могут исполнять несколько потоков за счет того, что в каждом содержится несколько (8-16) потоковых процессоров (Stream Cores или Stream Processor). Для карт NVidia – вычисления производятся непосредственно на потоковых процессорах, но ATI ввели еще один уровень абстракции – каждый потоковый процессор, состоит из processing elements – PE (иногда называемых ALU – arithmetic and logic unit) – и вычисления происходят на них.
Необходимо явно подчеркнуть что конкретная архитектура (число всяческих процессоров) и вычислительные возможности варьируются от модели к модели – что несколько влияет на универсальность и простоту кода для видеокарт от обоих производителей.
Для CUDA-устройств от NVidia это sm10, sm20, sm30 и т.д. Для OpenCL видеокарт от ATI/NVidia определяющее значение имеет версия OpenCL реализованная в драйверах от производителя 1.0, 1.1, 1.2 и поддержка особенностей на уровне железа. Да, вы вполне можете столкнуться с ситуацией когда на уровне железа какие-то функции просто не реализованы (как например локальная память на амд-ешных видеокарт линейки HD4800). Да, вы вполне можете столкнуться с ситуацией когда какие-то функции не реализованы в драйверах (на момент написания – выполнение нескольких ядер на видео-картах от NVidia с помощью OpenCL).
Программирование для GPU

Программы пишутся на расширении языка Си от NVidia/OpenCL и компилируются с помощью специальных компиляторов входящих в SDK. У каждого производителя разумеется свой. Есть два варианта сборки – под целевую платформу – когда явно указывается на каком железе будет исполнятся код или в некоторый промежуточный код, который при запуске на целевом железе будет преобразован драйвером в набор конкретных инструкций для используемой архитектуры (с поправкой на вычислительные возможности железа).

Выполняемая на GPU программа называется ядром – kernel – что для CUDA что для OpenCL это и будет тот набор инструкций которые применяются ко всем данным. Функция одна, а данные на которых она выполняется – разные – принцип SIMD.
Важно понимать что память хоста (оперативная) и видеокарты – это две разные вещи и перед выполнением ядра на видеокарте, данные необходимо загрузить из оперативной памяти хоста в память видеокарты. Для того чтобы получить результат – необходимо выполнить обратный процесс. Здесь есть ограничения по скорости PCI-шины – потому чем реже данные будут гулять между видеокартой и хостом – тем лучше.
Драйвер CUDA/OpenCL разбивает входные данные на множество частей (потоки выполнения объединенные в блоки) и назначает для выполнения на каждый потоковый процессор. Программист может и должен указывать драйверу как максимально эффективно задействовать существующие вычислительные ресурсы, задавая размеры блоков и число потоков в них. Разумеется, максимально допустимые значения варьируются от устройства к устройству. Хорошая практика – перед выполнением запросить параметры железа, на котором будет выполняться ядро и на их основании вычислить оптимальные размеры блоков.
Схематично, распределение задач на GPU происходит так:

Выполнение программы на GPU
work-item (OpenCL) или thread (CUDA) – ядро и набор данных, выполняется на Stream Processor (Processing Element в случае ATI устройств).
work group (OpenCL) или thread block (CUDA) выполняется на Multi Processor (SIMD Engine)
Grid (набор блоков такое понятие есть только у НВидиа) = выполняется на целом устройстве – GPU. Для выполнения на GPU все потоки объединяются в варпы (warp – CUDA) или вейффронты (wavefront – OpenCL) – пул потоков, назначенных на выполнение на одном отдельном мультипроцессоре. То есть если число блоков или рабочих групп оказалось больше чем число мултипроцессоров – фактически, в каждый момент времени выполняется группа (или группы) объединенные в варп – все остальные ожидают своей очереди.
Одно ядро может выполняться на нескольких GPU устройствах (как для CUDA так и для OpenCL, как для карточек ATI так и для NVidia).
Одно GPU-устройство может одновременно выполнять несколько ядер (как для CUDA так и для OpenCL, для NVidia – начиная с архитектуры 20 и выше). Ссылки по данным вопросам см. в конце статьи.
Модель памяти OpenCL (в скобках – терминология CUDA)

Здесь главное запомнить про время доступа к каждому виду памяти. Самый медленный это глобальная память – у современных видекарт ее аж до 6 Гб. Далее по скорости идет разделяемая память (shared – CUDA, local – OpenCL) – общая для всех потоков в блоке (thread block – CUDA, work-group – OpenCL) – однако ее всегда мало – 32-48 Кб для мультипроцессора. Самой быстрой является локальная память за счет использования регистров и кеширования, но надо понимать что все что не уместилось в кеширегистры – будет хранится в глобальной памяти со всеми вытекающими.
Паттерны параллельного программирования для GPU
1. Map

Map – GPU parallel pattern
Тут все просто – берем входной массив данных и к каждому элементу применяем некий оператор – ядро – никак не затрагивающий остальные элементы – т.е. читаем и пишем в определенные ячейки памяти.
Отношение – как один к одному (one-to-one).
пример – перемножение матриц, оператор инкремента или декремента примененный к каждому элементу матрицы и т.п.
2. Scatter

Scatter – GPU parallel pattern
Для каждого элемента входного массива мы вычисляем позицию в выходном массиве, на которое он окажет влияние (путем применения соответствующего оператора).
Отношение – как один ко многим (one-to-many).
3. Transpose

Transpose – GPU parallel pattern
Данный паттерн можно рассматривать как частный случай паттерна scatter.
Используется для оптимизации вычислений – перераспределяя элементы в памяти можно достичь значительного повышения производительности.
4. Gather

Gather – GPU parallel pattern
Является обратным к паттерну Scatter – для каждого элемента в выходном массиве мы вычисляем индексы элементов из входного массива, которые окажут на него влияние:
Отношение – несколько к одному (many-to-one).
5. Stencil

Stencil – GPU parallel pattern
Данный паттерн можно рассматривать как частный случай паттерна gather. Здесь для получения значения в каждой ячейке выходного массива используется определенный шаблон для вычисления всех элементов входного массива, которые повлияют на финальное значение. Всевозможные фильтры построены именно по этому принципу.
Отношение несколько к одному (several-to-one)
Пример: фильтр Гауссиана.
6. Reduce

Reduce – GPU parallel pattern
Отношение все к одному (All-to-one)
Пример – вычисление суммы или максимума в массиве.
7. Scan/ Sort
При вычислении значения в каждой ячейке выходного массива необходимо учитывать значения каждого элемента входного. Существует две основные реализации – Hillis and Steele и Blelloch.
out[i] = F[i] = operator(F[i-1],in[i])
Отношение все ко всем (all-to-all).
Примеры – сортировка данных.
Введение в CUDA:
Введение в OpenCL:
Хорошие статьи по основам программирования (отдельный интерес вызывает область применения):
http://www.mql5.com/ru/articles/405
http://www.mql5.com/ru/articles/407
Вебинары по OpenCL:
Курс на Udacity по программированию CUDA:
Выполнение ядра на нескольких GPU:
CUDA – grid, threads, blocks- раскладываем все по полочкам
доступные в сети ресурсы по CUDA
UPDATE 28.06.2013
Враперы для взаимодействия с ОпенСЛ:
JOCL – Java bindings for OpenCL (JOCL)
PyOpenCL – для python
aparapi – полноценная библиотека для жавы
Интересные статью по OpenCL – тут.
доступные материалы курсов по параллельным вычислениям:
UPDATE 23.11.2013
http://clcc.sourceforge.net/ – компилятор для OpenCL, удобен для проверки используемых в проекте OpenCL ядер. Поддерживает Windows, Mac. Хотя под Mac – для этих целей можно воспользоваться и “родным”, более продвинутым средством – openclc:
/System/Library/Frameworks/OpenCL.framework/Libraries/openclc -x cl -cl-std=CL1.1 -cl-auto-vectorize-enable -emit-gcl matrix_multiplication.cl
данная команда не только проверит ваш код на соответствие стандарту OpenCL, но, заодно, создаст и заготовки клиентского кода (в данном случае файлы matrix_multiplication.cl.h/matrix_multiplication.cl.cpp) для вызова ядра из пользовательского приложения.
https://github.com/petRUShka/vim-opencl – плагин для Vim’а с поддержкой проверки синтаксиса OpenCL
1 comment
- рустам on June 25, 2014 at 1:00 pm
- #
- Reply
спасибо большое за статью
Источник: my-it-notes.com
Технология параллельного программирования OpenCL
Эту статью можно считать продолжением статьи [1] о технологии CUDA, здесь мы поговорим о технологии параллельного программирования OpenCL.
1. Введение
OpenCL (Open Computing Language ) это спецификация, описывающая технологию параллельного программирования, которая в первую очередь ориентирована на GPGPU. Изначально она была разработана компанией Apple, в последствии для развития спецификаций OpenCL был образована группа разработчиков Khronos Compute [2], в неё вошли Apple, nVidia, AMD, IBM, Intel, ARM, Motorola и др. Первая версия стандарта была опубликована в конце 2008 года.
В отличии от nVidia CUDA, AMD Stream и т.п., в OpenCL изначально закладывалась мультиплатформенность, т.е. OpenCL программа должна без изменений в коде работать на GPU разных типов (разных производителей). Такая программа без изменений должна работать даже на CPU без GPU, хотя в этом случае она может выполняться существенно медленнее чем на GPU.
2. Схема работы с аппаратурой
Итак — хотим мультиплатформенность и желательно без существенных потерь в производительности. Достигается этот результат следующим образом [3,4].
OpenCL-программа работает с т.н. платформами (platform) . Платформа это программный пакет, который поставляется соответствующим разработчиком аппаратных средств. Например «AMD Accelerated Parallel Processing» или «Intel OpenCL». При этом несколько платформ могут работать одновременно на одной машине.
Каждая платформа включает в себя ICD (Installable Client Driver) — программный интерфейс OpenCL для работы с устройствами, которые эта платформа поддерживает.
В среде Linux список ссылок на ICD, присутствующих в системе, обычно хранится в каталоге /etc/OpenCL/vendors/ , а библиотека libOpenCL.so выполняет роль диспетчера (ICD loader) , т.е. она направляет вызовы OpenCL функций на устройства, через соответствующие ICD.
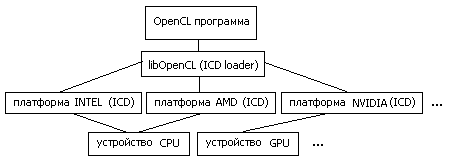
Рис.1: схема работы OpenCL программы с аппаратурой
[ Здесь ] можно увидеть пример конфигурации оборудования. На машине с процессором Intel Core2 CPU 6300 и графическим ускорителем nVidia Quadro FX1700, развернуты три платформы OpenCL: nVidia, AMD, Intel. При этом платформа nVidia поддерживает только GPU Quadro FX1700, а платформы AMD и Intel — только Intel Core2 CPU 6300 в качестве вычислительного устройства. Таким образом каждая платформа содержит одно вычислительное устройство.
Для определения возможностей OpenCL можно воспользоваться утилитой clinfo, также [ здесь ] можно скачать исходник программы, считывающую эту информацию.
Тут надо ещё сказать о версиях OpenCL SDK. При развёртывании платформы на компьютере необходимо уточнить версию пакета. Например, в процессе проведения экспериментов выяснилось, что Intel OpenCL SDK 2014 не поддерживает работу с процессором Intel Core2 CPU 6300, который был установлен на машине. Проблема решилась установкой более старого пакета Intel OpenCL SDK 2012.
3. Структура OpenCL-программы
В OpenCL (аналогично CUDA), программа разделяется на две части: первая часть — управляющая, вторая — вычислительная. В роли управляющего устройства ( host ) выступает центральный процессор (CPU), вычислительное устройство ( device ) выбираем из списка платформ и их устройств. Обычно используется GPU, но не обязательно, это может быть и тот же CPU.
Код, который должен выполняться на device, оформляется специальным способом. Поскольку device могут быть от разных производителей и разных типов, то скомпилировать один бинарник для всех не получится. Решается эта проблема следующим образом.
Текст ядра (kernel) , т.е. части программы выполняемой на device, включается в основную часть программы (выполняемой на host) в «чистом» виде т.е. в виде текстовой строки. Этот исходник компилируется средствами OpenCL непосредственно в процессе работы программы (runtime) для выбранного в данный момент вычислительного устройства, это происходит каждый раз при запуске OpenCL-программы.
Так же есть возможность, скомпилированный таким образом, код ядра сохранить и при инициализации вычислительной программы загружать готовый бинарник. Но в этом случае мы теряем универсальность, этот код будет работать только на одном (данном) типе устройств.
- получить информацию о платформах и устройствах
clGetPlatformIDs(),clGetPlatformInfo(), clGetDeviceIDs(),clGetDeviceInfo() - выбрать устройства и создать для них контекст
clCreateContext() - создать ядро из текста программы
clCreateProgramWithSource(), clBuildProgram(), clCreateKernel() - выделить память для данных на устройствах
clCreateBuffer() - создать очередь комманд для устройтва
clCreateCommandQueue(), clCreateCommandQueueWithProperties( ) - скопировать данные с host на device
clEnqueueWriteBuffer() - назначить параметры выполнения ядра
clSetKernelArg() - запуск ядра
clEnqueueNDRangeKernel() - скопировать результат с device на host
clEnqueueReadBuffer() - обработка результата
- завершение работы, освобождение ресурсов
clReleaseMemObject(), clReleaseKernel(), clReleaseProgram(), clReleaseCommandQueue(), clReleaseContext()
4. Пример OpenCL-программы
В качестве первого примера рассмотрим простую вычислительную задачу: С := d * A + B, где d — константа, А,В и С векторы заданного размера.
__kernel void kernel1(const float alpha, __global float *A, __global float *B, __global float *C) < int idx = get_global_id(0); C[idx] = alpha* A[idx] + B[idx]; >
Листинг 1: код ядра для задачи сложения векторов
Программа запускает много (по количеству элементов векторов) параллельных процессов (тредов) на device, каждый тред получает свой номер (get_global_id), исходя из него считывает свою часть данных из глобальной (__global) памяти device, выполняет вычисления и записывает свою часть результата обратно в память.
Код программы можно скачать [ здесь ]. Для сравнения напишем ещё простую (последовательную) программу и сравним время затраченное на вычисления. Ниже в таблице представлены результаты скорости выполнения программы на разных платформах.
| NVIDIA | Quadro FX 1700 | 3.2 |
| AMD | Intel Core2 CPU 6300 | 19.1 |
| Intel | Intel Core2 CPU 6300 | 11.0 |
| — | Intel Core2 CPU 6300 | 9.3 |
Таблица 1: результаты работы программы saxpy для разных платформ
По результатам, представленным в таб.1, видно, что выполнение примера на GPU почти в три раза быстрее чем на CPU. Для CPU платформа Intel показала лучший результат чем AMD, что очевидно для Intel Core2 CPU 6300. Наилучший результат для CPU показала простая программа, что можно объяснить эффективной работой компилятора и отсутствием необходимости выполнять дополнительные процедуры OpenCL.
5. Группы процессов и их конфигурация
Каждое вычислительное устройство обладает своими ограничениями по количеству одновременно выполняемых тредов, и хотя их общее количество в программе может быть велико, выполняться они будут частями или группами, максимальный размер группы зависит от конкретного устройства.
Иногда треды удобно формировать в виде решетки. Рассмотрим пример задачи умножения матриц.
Листинг 2: код ядра для задачи умножения матриц
Имеем на входе матрицы A[M*K], B[K*N] и соответственно буфер для результата C[M*N]. Программа создаёт M*N тредов в виде решетки MxN, каждый тред [r,c] отрабатывает одну ячейку в матрице результата.
Код программы можно скачать [ здесь ].
Для сравнения напишем ещё простую (последовательную) программу и сравним время затраченное на вычисления. Ниже в таблице представлены результаты скорости выполнения программы на разных платформах.
| NVIDIA | Quadro FX 1700 | 5169.5 |
| AMD | Intel Core2 CPU 6300 | 2279.0 |
| Intel | Intel Core2 CPU 6300 | 920.1 |
| — | Intel Core2 CPU 6300 | 1340.6 |
Таблица 2: результаты работы программы gemm1 для разных платформ
Результаты несколько расстраивают, поскольку из таб.2 видно, что GPU показала наихудший результат. Проблема в крайне неэффективном использовании памяти GPU. Далее мы исправим это затруднение.
6. Модели памяти и синхронизация процессов
В статье [1] была приведена схема организации GPU. Из этой схемы видно, что этот тип устройств обладает сложно организованной памятью, которая может работать с разной скоростью.
- Память global — основная память уcтройства, самая большая по размеру (512MB для FX1700) и самая медленная, она является общей для всех тредов.
- Память local — общая память для одной группы тредов (shared в терминах CUDA), этот тип быстрее global но существенно меньше по размеру (16KB для FX1700)
- Память private — память треда, быстрая но маленькая (8KB для FX1700)
Вернёмся к предыдущему примеру с умножением матриц. В процессе работы ядро выполняет много повторных чтений из памяти global. Попробуем сократить количество чтений с помощью организации быстрого кэша [5].
Листинг 3: код ядра для задачи умножения матриц с кэшированием
Имеем на входе матрицы A[M*K], B[K*N] и соответственно результат C[M*N]. Программа создаёт M*N тредов в виде решетки MxN, группами размера TSxTS, каждый тред отрабатывает одну ячейку в матрице результата, группа тредов кэширует блоки исходных матриц и далее выполняет операции с этим кэшем.
Для того, что бы кэш корректно был заполнен необходима синхронизация группы тредов (barrier) , достигая barrier программа ждет, пока все треды группы соберутся в этой точке и только после этого продолжает выполнение.
Код программы можно скачать [ здесь ].
Ниже в таблице представлены результаты скорости выполнения программы на разных платформах.
| NVIDIA | Quadro FX 1700 | 169.5 |
| AMD | Intel Core2 CPU 6300 | 2301.1 |
| Intel | Intel Core2 CPU 6300 | 1402.7 |
| — | Intel Core2 CPU 6300 | 1340.6 |
Таблица 3: результаты работы программы gemm2 для разных платформ
Из таблицы 3 видно, что модифицированная программа умножения матриц (gemm2) показывает вполне удовлетворительный результат производительности, работая гораздо быстрее первого варианта (gemm1).
7. Заключение
Хотя программы OpenCL могут выполняться с меньшей скоростью в сравнении с CUDA, но они обладает важным свойством — переносимость, этот стандарт имеет хорошие перспективы развития.
В заключении можно ещё привести ссылку на список библиотек, основанных на OpenCL.
https://www.khronos.org/opencl/resources/opencl-libraries-and-frameworks-with-opencl-acceleration
Список литературы
Источник: mechanoid.su