
OCR, история и принцип работы этой технологии распознавания
Технология OCR существует уже давно и является ключом к облегчению работы многих людей, поскольку это способность преобразовывать символы, которые являются неотъемлемой частью изображения, в символы, которыми можно манипулировать, что позволяет избежать утомительной задачи расшифровка текста . Но что за всем этим стоит?
OCR сегодня используется круглосуточно и не только для оцифровки текстов, но и для таких вещей, как перевод в реальном времени текста, написанного на других языках, и мы даже можем преобразовать рукописный текст в печатный.
- OCR и распознавание образов
- Распознавание символов через OCR
- Завивка локонов без распознавания текста
- Искусственный интеллект на помощь в распознавании символов
OCR и распознавание образов
Под паттерном мы понимаем модель, которая служит для получения чего-то подобного; В то время как наши глаза и мозг идентифицируют каждую букву по ее написанию, компьютер не обладает такой способностью к абстракции и должен иметь возможность проводить сравнение, которое всегда является результатом вычитания между двумя элементами: если вычитание дает 0 так что это означает, что сравнение положительное.

В 1960 году Лоуренс (Ларри) Робертс, исследователь Массачусетского технологического института, который, как ни парадоксально, позже стал одним из изобретателей того, что в конечном итоге стало Интернетом, создал систему распознавания символов и связанный с ней шрифт, предназначенный для оцифровки банковских чеков и т. Д. на. конфиденциальная информация, которую нужно было хранить на ранних компьютерах. Этот источник получил название OCR-A.
Если подумать, для компьютера буква, как и любой другой тип данных, представляет собой не что иное, как набор бит, поэтому все, что нам нужно, это сохранить ее в системе, отвечающей за сравнение шрифта в его разных размерах. как сравнительный шрифт.
Распознавание символов через OCR
Первое, что сделает система OCR, — это прочитает документ, чтобы найти текст и исключить для последующего анализа все, что не полезно для оптического распознавания символов.
Как только у вас будут только символы, вам нужно будет просмотреть то, что осталось от изображения, взять его блоки и оцифровать их для последующего сравнения с информацией в памяти. Другими словами, система обнаружения символов просматривает изображение, считывая его блоками с регулярным числом пикселей и непрерывно сравнивая с формами, которые она хранит в своей памяти.

Если он найдет совпадение, он пометит его в файле, который затем покажет и / или сохранит как заключение; указанный файл будет текстовым файлом с самим текстом, извлеченным в процессе распознавания.
Это означает, что наша система распознавания символов должна иметь в памяти шрифт, которым текст был написан на бумаге, или изображение, из которого мы хотим его извлечь, если она может производить сравнение. Но что происходит в особых случаях, таких как рукописный ввод или специальные шрифты?
Завивка локонов без распознавания текста
Возвращаясь к тому, как работает наш мозг, он идентифицирует вещи, потому что он усвоил шаблон, который позволяет ему их идентифицировать. Наш мозг прекрасно знает через выученный образец, что все буквы на следующем изображении — это буква А.

Но компьютер, как правило, не знает этого напрямую и нуждается в системе отсчета, которую мы прокомментировали выше, чтобы знать, является ли сравнение положительным или нет, что привело к тому, что при чтении почерка, который различен для каждого человека, пришлось пройти через долгие усилия в течение нескольких лет.
Как историческое любопытство, когда Apple выпустили то, что можно было бы считать первым в мире «карманным» компьютером, Apple Newton, они пообещали, что у него будет система распознавания рукописного ввода, которая вовремя преобразует вводимые пользователем тексты в печатные. настоящий.

Результат? Катастрофа, так как я не понимал, как пишут большинство людей, и устройство вышло из строя.
Причина этого заключалась не в том, что системы Newton и более поздние были плохими, а в том, что для распознавания образов требовалось много вычислительной мощности, чего не было и не было в течение длительного времени. Даже системы распознавания рукописного ввода поддерживают огромные центры обработки данных и обработки, с которыми они общаются через Интернет.
Искусственный интеллект на помощь в распознавании символов
Системы искусственного интеллекта на самом деле представляют собой системы, обученные распознавать определенные шаблоны, и их можно обучить распознавать символы не на основе сравнительного элемента, а путем применения шаблонов. Например, мы можем идентифицировать букву A с помощью простого шаблона, подобного следующему:
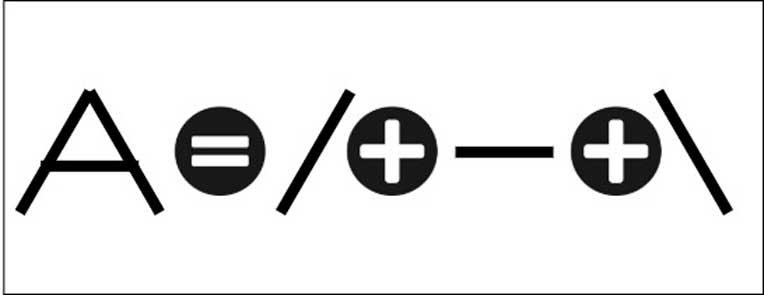
Но идея состоит в том, чтобы обучить машину так, чтобы она знала, как распознавать шаблон без необходимости проводить сравнение, и именно в этот момент появляется искусственный интеллект. Точно так же, как мы можем обучить искусственный интеллект распознавать дорожные знаки. чтобы он мог двигаться в автоматическом режиме, мы также можем научить его распознавать символы. Как? Ну, через нейронную сеть, которая была этому ранее обучена.
Наиболее широко в этих случаях используются так называемые сверточные нейронные сети, которые представляют собой тип искусственных нейронов, которые имеют структуру, аналогичную нейронам первичной зрительной коры биологического мозга, и отлично подходят для классификации и сегментации изображений. и другие приложения компьютерного зрения.
Эти нейронные сети копируют работу биологических систем, отвечающих за обнаружение шаблонов, которые позволяют нам идентифицировать каждую букву.
В то же время каждый раз, когда идентификация оказывается положительной и подтверждается несколько раз, этот пример сохраняется в базе данных для использования в качестве шаблона позже. Фактически, системы в этом случае работают сначала, если есть соответствие в базе данных, которая была создана, и только тогда, когда она не находит, когда активируются механизмы для идентификации шаблонов с помощью искусственного интеллекта.
Источник: itigic.com
What is OCR ?
Optical Character recognition is the process that converts image or PDF into an editable text files
| They use IRIS’ OCR: |
Optical Character Recognition
“OCR” is the abbreviation of “Optical Character Recognition’’, it describes the process whereby an image is captured of a paper document after which the text is ”extracted” from that image.
Hence, paper documents are converted into editable computer files. And that’s precisely what text recognition is all about: entering texts into your computer without retyping them. After all, as efficient as computers are, you have to key in your information first!
40 times faster than manual retyping
Document recognition is easily 40 times faster than manual retyping. To quote just one hard figure: a (very) fast secretary types some 200 characters per minute the fastest OCR software recognizes some 1,600 characters per second on a “decent” PC.
Layout and Table Recognition
You should interpret the word “document” in the broadest sense of the word. The layout of your source document can be recreated so that you don’t have to format your text again. When you have tables of figures to recapture, you can use OCR too. Reading tables is as good an application as capturing texts. Furthermore, you could easily take the point of view that reading tables makes even more sense than OCRing a text: retyping tables is about the most cumbersome typing job you can do.
And when boredom kicks in, typos are right around the corner.
Readiris 16, OCR software
Readiris 16 automatically converts text from paper documents, images or PDF into fully editable files without having to perform all the tedious retyping work!
The optical character recognition (OCR) technology used in Readiris 16 allows very accurate document recognition while preserving the original page layout.
This software will make it very easy to convert PDF to Word, images to text, PDF to Excel, merge PDF and many more!
IRIS OCR, 30 years of development
I.R.I.S. company launched its first OCR engine in 1987 and has always been a world leader in OCR technologies. More than 250 software companies are using I.R.I.S.’ recognition tools in their products and solutions.
Readiris software has always been I.R.I.S.’ flagship OCR product. It’s being used by thusands of poeple across the world and considered as an industry leader by the press.
Since 2013, I.R.I.S. became a proud member of the Canon group.
Источник: www.irislink.com
Оптимизировать разрешение для ocr, Сканировать другую страницы после, Формат – Инструкция по эксплуатации I.R.I.S. Readiris 14 for Windows User Guide

Этот параметр корректирует разрешение изображений,
отсканированных со слишком высоким уровнем детализации
(более 600 точек/дюйм). Когда этот параметр активирован,
Readiris уменьшает разрешение до подходящего уровня.
Обратите внимание, что эта функция не может увеличить
разрешение изображений, отсканированных со слишком
низкой детализацией.
Сканировать другую страницы после
Этот параметр будет полезен при сканировании нескольких
страниц на планшетном сканере. Он позволяет указать время в
секундах, по прошествии которого Readiris сканирует другую
страницу. Таким образом, у вас будет возможность заменить
страницы в сканере, и Readiris будет выполнять
автоматическое сканирование. Вам не придется возвращаться к
приложению Readiris и нажимать кнопку Сканировать при
каждом сканировании новой страницы.
Используйте стрелки вверх и вниз для указания числа секунд,
по прошествии которого ПО Readiris будет сканировать новую
страницу.
Щелкните список Формат, чтобы указать размер сканируемых
документов.
Совет. Самые распространенные форматы в США — Letter и
Legal. В других странах A4 является стандартом.
Источник: www.manualsdir.ru
OCR — определение, преимущества, проблемы и варианты использования [инфографика]

OCR — это технология, позволяющая машинам считывать печатный текст и изображения. Он часто используется в бизнес-приложениях, таких как оцифровка документов для хранения или обработки, и в потребительских приложениях, таких как сканирование квитанции для возмещения расходов.
OCR означает оптическое распознавание символов. Термин «символ» относится как к буквам, так и к цифрам. Программное обеспечение OCR может распознавать, содержит ли данное изображение символы или нет, а затем идентифицировать символы внутри него.

Область распознавания
Ожидается, что в ближайшие годы мировой рынок оптического распознавания символов будет быстро расти. Размер рынка OCR был оценен в 8.93 млрд долларов США в 2021 году. Ожидается, что он будет расти на CAGR 15.4% в период с 2022 по 2030 год. Этот рост обусловлен растущим спросом на OCR в различных отраслях конечного использования, таких как здравоохранение, автомобилестроение и другие.
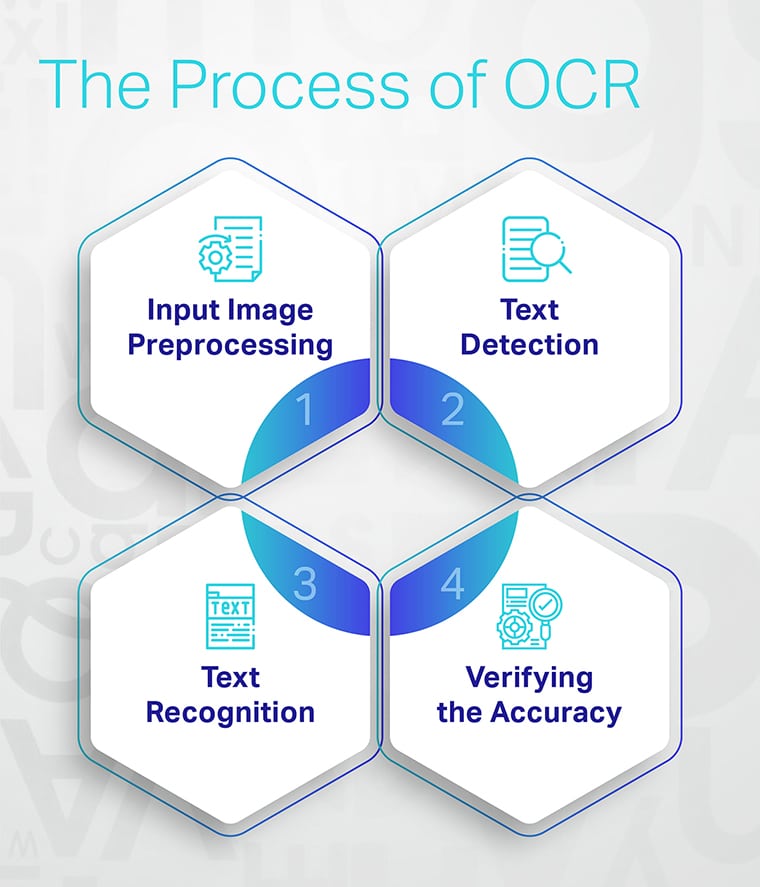
Процесс оптического распознавания символов
OCR — это подробный процесс, который помогает извлекать текст из изображений с помощью NLP.
- Первым шагом в OCR является обработка входного изображения. Это включает в себя очистку изображения и делает его пригодным для дальнейшей обработки.
- Затем механизм OCR ищет области, содержащие текст на изображении. Механизм сегментирует эти области на отдельные символы или слова, чтобы впоследствии их можно было идентифицировать при распознавании текста.
- Используя результаты обнаружения текста, механизм OCR идентифицирует каждый символ по его форме и размеру. Вы часто будете видеть сверточные и рекуррентные нейронные сети, иногда в комбинации, используемые для этой задачи.
- После того, как программное обеспечение OCR закончит распознавание текста в файле изображения, его необходимо проверить на точность, прежде чем его можно будет использовать.
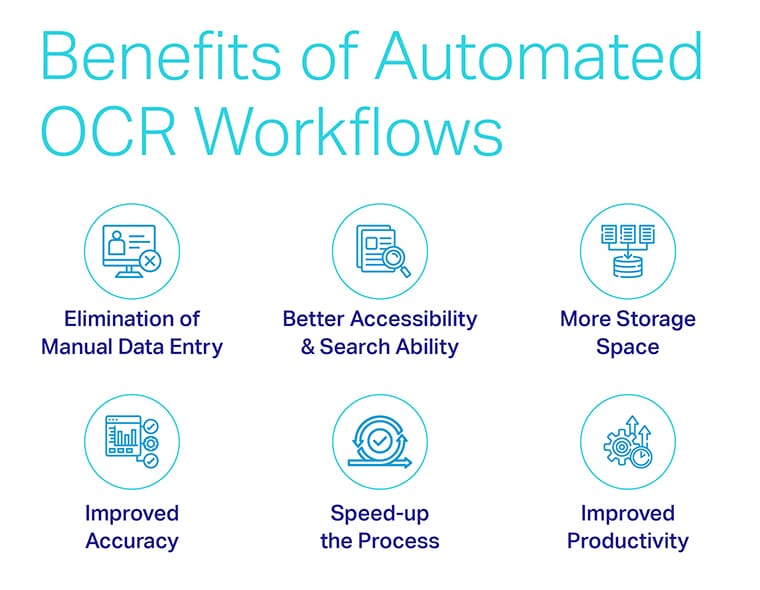
Преимущества автоматизированных рабочих процессов OCR
Ключевые преимущества автоматизированных рабочих процессов OCR включают в себя:
- Более быстрые и точные автоматические результаты при исключении человеческого фактора.
- Более низкая стоимость входа для малого бизнеса благодаря более быстрой обработке данных и эффективному использованию данных.
- Более стабильные результаты для нескольких пользователей и проектов.
- Улучшенное хранение данных и безопасность данных.
- Огромные возможности для масштабирования.

Вызовы
Основная проблема OCR заключается в том, что она не идеальна. Если вы представите, что читаете текст на этой странице с помощью камеры, а затем преобразуете эти изображения в слова, вы поймете, почему OCR может быть проблематичным. Некоторые из проблем OCR включают в себя:
- Размытый текст искажен тенями.
- Цвет фона и текста имеют схожие цвета.
- Части изображения обрезаются или полностью обрезаются (например, нижняя часть «этого»).
- Слабые знаки поверх некоторых букв (например, «i») могут сбить с толку программное обеспечение OCR, думая, что они являются частью буквы, а не знаками сверху.
- Различие типов и размеров шрифтов может быть затруднено при идентификации.
- Условия освещения при фотографировании или сканировании документа.

Случаи использования
- Автоматизация ввода данных: OCR можно использовать для автоматизации процесса ввода данных в базу данных.
- Сканирование штрих-кода: OCR позволяет компьютеру сканировать штрих-коды на продуктах и извлекать информацию о них из баз данных.
- Распознавание номерных знаков: OCR анализирует номерные знаки и извлекает из них такую информацию, как регистрационные номера и названия штатов.
- Проверка паспорта: OCR можно использовать для проверки подлинности паспортов, виз и других проездных документов.
- Распознавание этикеток магазинов: Магазины могут использовать OCR для автоматического считывания этикеток своих продуктов и сравнения их со своими каталогами продуктов, чтобы определить, какие продукты в настоящее время находятся на полках магазинов, какие товары отсутствуют на складе или есть ошибки на складе.
- Обработка страховых случаев: Программное обеспечение OCR может сканировать документы и проверять подписи, даты, адреса и другую информацию в формах, отправленных клиентами, которые подали иски о возмещении ущерба, причиненного стихийными бедствиями, пожарами или кражами.
- Чтение сигналов светофора: Систему OCR можно использовать для считывания цветов светофоров и определения того, являются ли они красными или зелеными.
- Считывание коммунальных счетчиков: Коммунальные предприятия используют OCR для считывания счетчиков электроэнергии, газа и воды, чтобы выставлять клиентам счета за правильные суммы.
- Мониторинг социальных сетей – Компании используют OCR для идентификации и классификации упоминаний компании или бренда в сообщениях социальных сетей, твитах и даже обновлениях Facebook.
- Проверка правоустанавливающих документов: Адвокатское бюро может сканировать такие документы, как контракты, договоры аренды и соглашения, чтобы убедиться, что они разборчивы и точны, прежде чем отправлять их клиентам.
- Многоязычные документы: Компании, которая продает товары в других странах, может потребоваться перевести свои маркетинговые материалы на несколько языков, а затем использовать их в качестве шаблонов для будущих проектов.
- Маркировка медицинских препаратов: OCR широко используется для извлечения значимой информации из этикеток лекарств, чтобы компьютерные системы могли анализировать и обрабатывать ее.

Индустрия
- Розничная: В розничной торговле используется OCR для сканирования штрих-кодов, информации о кредитных картах, квитанций и т. д.
- БФИ: Банки используют OCR для чтения чеков, депозитных ордеров и банковских выписок для проверки подписей и добавления транзакций к счетам. Они также могут анализировать большие объемы данных, чтобы принимать решения о счетах клиентов, инвестициях, кредитах и многом другом с помощью OCR.
- Правительство: OCR можно использовать для сканирования и оцифровки юридических документов, таких как свидетельства о рождении, водительские права и другие официальные записи.
- Образование: Учителя могут использовать OCR для создания цифровых копий книг и других студенческих документов. Учителя также могут сканировать документы на свои компьютеры и использовать технологию OCR для создания электронной копии, к которой учащиеся могут получить доступ в любое время.
- Здравоохранение: Врачам часто необходимо быстро ввести информацию о пациенте в компьютерную систему. Отрасль здравоохранения может использовать OCR для бизнес-процессов, таких как выставление счетов и обработка претензий.
- Производство – Производственным предприятиям часто требуется сканировать такие документы, как счета-фактуры или заказы на поставку. OCR можно использовать для «считывания» серийных номеров на компонентах продукта, когда они проходят по конвейерной ленте или по сборочной линии.
- Наши технологии: Программное обеспечение OCR используется во многих параметрах, связанных с ИТ, включая интеллектуальный анализ данных, анализ изображений, распознавание речи и многое другое. В разработке программного обеспечения OCR используется для преобразования отсканированных документов обратно в цифровые файлы.
- Транспорт и логистика: OCR можно использовать для чтения отгрузочных этикеток или контроля складских запасов. Он также может обнаруживать мошенничество, когда поставщики выставляют счета на оплату.
Вердикт
Процесс OCR относительно прост, требуется всего несколько шагов для преобразования изображения в текст. Есть некоторые ошибки и нестыковки, но технология бесспорно впечатляет, учитывая то, как все это работает.
Источник: ru.shaip.com
Практический пример
Итак, после всех разговоров, пришло время испачкать руки и попробовать себя в моделировании. Мы попробуем решить SVHN задача. Данные SVHN содержат три разных набора данных:поезд,теста такжедополнительный, Различия не ясны на 100%, однакодополнительныйсамый большой набор данных (с ~ 500K выборками) включает в себя изображения, которые как-то легче распознать. Так что ради этого дубля мы будем его использовать.
Чтобы подготовиться к заданию, сделайте следующее:
- Вам понадобится базовый графический процессор с Tensorflow≥1.4 и Keras≥2
- Клонировать проект SSD_Keras из Вот,
- Загрузите предварительно подготовленную модель SSD300 для набора данных кокосов из Вот,
- клонэторепо проекта от Вот..
- Скачать extra.tar.gz файл, содержащий дополнительные изображения набора данных SVHN.
- Обновите все соответствующие пути в json_config.json в этом репозитории проекта.
Чтобы эффективно следовать процессу, вы должны прочитать приведенную ниже инструкцию вместе с запускомssd_OCR.ipynbтетрадь из репо проекта.
И . Вы готовы начать!
Шаг 1: разобрать данные
Как ни крути, но нет «золотого» формата для представления данных в задачах обнаружения. Некоторые хорошо известные форматы: coco, via, pascal, xml. И это еще не все. Например, набор данных SVHN аннотирован неясным.матформат. К счастью для нас, это суть обеспечивает пятноread_process_h5Скрипт для преобразования файла .mat в стандартный json, и вам нужно сделать один шаг вперед и преобразовать его в формат Паскаль, например так:
def json_to_pascal(json, filename): #filename is the .mat file
# convert json to pascal and save as csv
pascal_list = []
for i in json:
for j in range(len(i[‘labels’])):
pascal_list.append( ,’xmin’: int(i[‘left’][j]), ‘xmax’: int(i[‘left’][j]+i[‘width’][j])
,’ymin’: int(i[‘top’][j]), ‘ymax’: int(i[‘top’][j]+i[‘height’][j])
,’class_id’: int(i[‘labels’][j])>)
df_pascal = pd.DataFrame(pascal_list,dtype=’str’)
df_pascal.to_csv(filename,index=False)p = read_process_h5(file_path)json_to_pascal(p, data_folder+’pascal.csv’)
Теперь мы должны иметьpascal.csvфайл, который является гораздо более стандартным и позволит нам прогрессировать. Если преобразование будет медленным, обратите внимание, что нам не нужны все образцы данных. ~ 10К будет достаточно.
Шаг 2: посмотрите на данные
Перед началом процесса моделирования вам следует лучше изучить данные. Я предоставляю только быструю функцию для проверки работоспособности, но я рекомендую вам сделать еще один анализ:
def viz_random_image(df):
file = np.random.choice(df.fname)
im = skimage.io.imread(data_folder+file)
annots = df[df.fname==file].iterrows() plt.figure(figsize=(6,6))
plt.imshow(im) current_axis = plt.gca() for box in annots:
label = box[1][‘class_id’]
current_axis.add_patch(plt.Rectangle(
(box[1][‘xmin’], box[1][‘ymin’]), box[1][‘xmax’]-box[1][‘xmin’],
box[1][‘ymax’]-box[1][‘ymin’], color=’blue’, fill=False, linewidth=2))
current_axis.text(box[1][‘xmin’], box[1][‘ymin’], label, size=’x-large’, color=’white’, bbox=)
plt.show()
viz_random_image(df)

Для следующих шагов я предоставляюutils_ssd.pyв репо, который облегчает тренировку, весовую нагрузку и т. д. Часть кода взята из репозитория SSD_Keras, который также широко используется.
Шаг 3: выбор стратегии
Как обсуждалось ранее, у нас есть много возможных подходов к этой проблеме. В этом уроке я расскажу о стандартном подходе к обнаружению глубокого обучения и использую модель обнаружения SSD. Мы будем использоватьSSD керасреализация от Вот, Это хорошая реализация от PierreLuigi.
Хотя он имеет меньше звезд GitHub, чем rykov8 реализация, кажется, более обновленная, и ее легче интегрировать. Это очень важно заметить, когда вы выбираете, какой проект вы собираетесь использовать. Другими хорошими вариантами выбора станут модель YOLO и маска RCNN.
Шаг 4: Загрузите и обучите модель SSD
Некоторые определения
Чтобы использовать репо, вам необходимо убедиться, что у вас есть репозиторий SSD_keras, и указать пути в файле json_config.json, чтобы позволить записной книжке найти пути
Начать с импорта:
import os
import sys
import skimage.io
import scipy
import jsonwith open(‘json_config.json’) as f: json_conf = json.load(f)ROOT_DIR = os.path.abspath(json_conf[‘ssd_folder’]) # add here mask RCNN path
sys.path.append(ROOT_DIR)
import cv2
from utils_ssd import *
import pandas as pd
from PIL import Image
from matplotlib import pyplot as plt
%matplotlib inline
%load_ext autoreload
% autoreload 2
и еще несколько определений:
task = ‘svhn’labels_path = f’pascal.csv’input_format = [‘class_id’,’image_name’,’xmax’,’xmin’,’ymax’,’ymin’ ]
df = pd.read_csv(labels_path)
Конфигурации модели:
class SVHN_Config(Config):
batch_size = 8
dataset_folder = data_folder
task = task
labels_path = labels_path
input_format = input_format
conf=SVHN_Config()
resize = Resize(height=conf.img_height, width=conf.img_width)
trans = [resize]
Определить модель, вес нагрузки
Как и в большинстве случаев глубокого обучения, мы не начнем обучение с нуля, но мы будем загружать предварительно обученные веса. В этом случае мы загрузим веса модели SSD, обученной на базе данных COCO, которая имеет 80 классов. Ясно, что в нашей задаче всего 10 классов, поэтому мы восстановим верхний слой, чтобы получить правильное количество выходов после загрузки весов. Мы делаем это в функции init_weights. Примечание: правильное количество выходов в этом случае составляет 44: 4 для каждого класса (координаты ограничивающего прямоугольника) и еще 4 для фона / класса нет
learner = SSD_finetune(conf)
learner.get_data(create_subset=True)
weights_destination_path=learner.init_weights()
learner.get_model(mode=’training’, weights_path = weights_destination_path)
model = learner.model
learner.get_input_encoder()
ssd_input_encoder = learner.ssd_input_encoder
# Training schedule definitions
adam = Adam(lr=0.0002, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
ssd_loss = SSDLoss(neg_pos_ratio=3, n_neg_min=0, alpha=1.0)
model.compile(optimizer=adam, loss=ssd_loss.compute_loss)
Определить загрузчики данных
train_annotation_file=f’ train_pascal.csv’
val_annotation_file=f’ val_pascal.csv’
subset_annotation_file=f’ small_pascal.csv’batch_size=4
ret_5_elements=train_generator = learner.get_generator(batch_size, trans=trans, anot_file=train_annotation_file,
encoder=ssd_input_encoder)val_generator = learner.get_generator(batch_size,trans=trans, anot_file=val_annotation_file,
returns=, encoder=ssd_input_encoder,val=True)
5. Обучение модели
В настоящее времячто модель готова, мы установим некоторые последние определения, связанные с обучением, и начнем обучение
learner.init_training()history = learner.train(train_generator, val_generator, steps=100,epochs=80)
В качестве бонуса я включилtraining_plotобратный вызов в учебном скрипте для визуализации случайного изображения после каждой эпохи. Например, вот снимок прогнозов послешестойэпоха:

Репозиторий SSD_Keras обрабатывает сохранение модели практически после каждой эпохи, поэтому вы можете загрузить модели позже, просто изменивweights_destination_pathлиния, равная пути
weights_destination_path =
Если вы следовали моим инструкциям, вы сможете тренировать модель. Ssd_keras предоставляет некоторые дополнительные функции, например, дополнения данных, различные загрузчики и оценщик. Я достиг> 80 мА после короткой тренировки.
Как высоко вы достигли?

Резюме
В этом посте мы обсудили различные проблемы и подходы в области OCR. Как много проблем в глубоком обучении / компьютерном зрении, он имеет гораздо больше, чем кажется на первый взгляд. Мы видели множество его подзадач и несколько разных подходов к их решению, ни один из которых в настоящее время не является серебряной пулей. С другой стороны, мы видели, что не очень сложно достичь предварительных результатов без особых хлопот.
Надеюсь, вам понравилось!
Источник: machinelearningmastery.ru