
**1-ый учебный вопрос: Основные определения курса.** *Проектирование баз данных* — процесс создания схемы базы данных и определения необходимых ограничений целостности. На самом деле, в нашем курсе мы пойдем несколько дальше и расширим данное выше определение до следующего вида: *Проектирование баз данных* — процесс создания схемы базы данных и определения необходимых ограничений целостности для реляционной модели данных, процесс создание схемы базы данных для хранилища данных и создание nosql моделей данных.
Также, в процессе прохождения курса мы рассмотрим некоторые особенности релиза проекта баз данных в разных СУБД и некоторые особенности оптимизации базы данных на этапе ее релиза. *Концептуальное (инфологическое) проектирование* — построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных.
Будем принимать термины «семантическая модель», «концептуальная модель» и «инфологическая модель», которые могут встретиться в литературе, как синонимы. *Логическое (даталогическое) проектирование* — создание схемы базы данных на основе конкретной модели данных, например, чаще всего — реляционной модели данных. Для реляционной модели данных даталогическая модель будет включать в себя набор схем отношений, обычно с указанием первичных ключей, а также связей между отношениями, представляющих собой внешние ключи.
DEV1-12. 07. Схема данных приложения «Книжный магазин»
На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД. *Физическое проектирование* — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т.д.
Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и другие средства оптимизации. **2-ой учебный вопрос: Концептуальное проектирование БД.** Сразу необходимо отметить, что при осуществлении концептуального проектирования не учитывается ни модель данных, с которой инженер имеет дело, но формальные правила нотаций, которые будут использоваться при описании конкретной модели. Для осуществления моделирования такого рода обычно применяются стандарты, рекомендации или руководства, разработанные на предприятии, или же иные, распространенные абстрактные модели.
В качестве одной из таких моделей может выступать модель “сущность-связь” (ER-модель). Ниже, дадим основные определения элементов концептуальной модели данных: *Сущность БД* – элемент базы данных, представляющий собой объект, который существует независимо от других, за которым хотел бы осуществлять наблюдение владелец базы данных.
Каждая сущность обладает собственным именем и кратким описанием. *Экземпляр сущности* – отдельно взятый элемент сущности БД, конкретный представитель сущности. *Документирование сущностей* – ведение словаря данных концептуальной модели с записью сущностей. *Связь* – ассоциация, объединяющая несколько сущностей. Может существовать между несколькими сущностями (наиболее распространенная – между двумя сущностями, бинарная) или же между сущностью и ей самой (рекурсивная). *Класс принадлежности сущности* — это характер участия сущности в связи.
PHP Как хранить картинки в базе данных How to save images as a BLOB in MySQL
Различают обязательные и необязательные классы принадлежности сущности к связи. Обязательным является такой класс принадлежности, когда экземпляры сущности участвуют в установлении связи в обязательном порядке.
В противном случае сущность принадлежит к необязательному классу принадлежности. *Имя связи* – любое осмысленное название связи, выраженное в глагольном наклонении. Словарь данных концептуальной модели, связи — центральное хранилище информации, содержащее в себе “тройки”: “описание связи – тип связи – класс принадлежности сущностей, участвующий в связи”. *ER — модель* – наиболее часто применимая в логическом моделировании модель.
ER — модель представляет собой формальную конструкцию, которая сама по себе не предписывает никаких графических средств её визуализации. В настоящий момент времени можно выделить две ключевых нотации для изображения графических диаграмм ER – модели: нотация Питера Чена и нотация Crow’s Foot. *Нотация Питера Чена* — множества сущностей изображаются в виде прямоугольников, множества отношений изображаются в виде ромбов.
Если сущность участвует в отношении, они связаны линией. Если отношение не является обязательным, то линия пунктирная, рис. 1.  *Нотация Crow’s Foot.* Согласно данной нотации, сущность изображается в виде прямоугольника, содержащего её имя, выражаемое существительным.
Связь изображается линией, которая связывает две сущности. Тип связи указывается графически, множественность связи изображается в виде “вилки” на конце связи. Класс принадлежности сущности так же изображается графически — необязательность сущности помечается кружком на конце связи.
Именование обычно выражается одним глаголом в изъявительном наклонении настоящего времени: “имеет”, “принадлежит” и т. д.; или глаголом с поясняющими словами: “включает в себя”, и т.п. Наименование может быть одно для всей связи или два для каждого из концов связи. Во втором случае, название левого конца связи указывается над линией связи, а правого – под линией.
Каждое из названий располагаются рядом с сущностью, к которой оно относится, рис. 2.  *Атрибут* – свойство сущности.
Для каждого атрибута, при концептуальном проектировании определяются следующие значения: — имя атрибута, его краткое описание; — тип атрибута, размерность его значений (если это возможно); — значение атрибута “по умолчанию” (если необходимо); *Первичный ключ сущности* – атрибут сущности, позволяющий уникальным образом идентифицировать ее экземпляры. Далее, поэтапно, перечислим все процедуры концептуального проектирования.
1. Определение сущностей и их документирование. Каждой сущности присваивается имя, которое будет понятно другим пользователям. При этом имя будет точно характеризовать смысл сущности. Имена и описание сущностей заносятся в словарь данных. Для каждой сущности примерно устанавливается ожидаемое количество экземпляров.
2. Определение связей между сущностями и их документирование. Связям присваиваются логичные и понятные имена в глагольном наклонении. Описания связей с их типом, классом принадлежности сущностей и именами заносится в словарь данных. 3. Создание ER – модели предметной области. Создается несколько альтернативных макетов модели, называемых эскизами.
Из этих вариантов выбирается оптимальный вариант модели хранения данных и оптимальный набор его элементов. 4. Определение атрибутов и их документирование. Каждому атрибуту присваивается осмысленное имя, понятное пользователю и точно раскрывающее его суть. Информация об атрибутах помещается в словарь данных.
5. Определение значений атрибутов и их документирование (если они дискретны). Дискретные атрибуты (построенные на дискретном, то есть – ограниченном множестве значений, которые они могут принимать) должны быть зафиксированы в словаре данных в виде конечного дискретного множества. Например, <холодный, теплый, горячий>.
6. Определение первичных ключей сущности и их документирование. Сведения об определенных ключах помещаются в словарь данных. 7. Корректировка эскизов моделей с конечными пользователями БД. Результат представляется ER-моделью с сопровождающей документацией (в первую очередь это – словарь данных).
Модель корректируется до тех пор, пока не будет удовлетворять условиям технического задания и/или требованиям конечного пользователя. Возможно проведение аудита соответствия модели техническому заданию. **3-ий учебный вопрос: Логическое проектирование БД.** *Реляционная модель данных* — это набор отношений, имена которых совпадают с именами схем отношений в схеме БД.
Основными понятиями реляционных моделей данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение. Покажем смысл этих понятий на примере отношения “Сотрудники”, содержащего информацию о сотрудниках некоторого предприятия (рис.
3).  *Тип данных.* Понятие типа данных в реляционной модели данных полностью адекватно по¬нятию типа данных в языках программирования. Напомним, что традиционно (нестрогое) определение типа данных состоит из трех основных компонентов: — определение множества значений данного типа; — определение набора операций, применимых к значениям типа; — определение способа внешнего представления значе¬ний типа (литералов).
Обычно в современных реляционных базах данных допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как «деньги»), специальных «темпоральных» данных (дата, время, временной интервал), изображений, звуков. В примере на рис. 3 мы имеем дело с данными трех типов: строки символов, целые числа и “деньги”. Домен.
В общем виде домен определяется путем задания некоторого базового типа данных, к которому относятся элементы домена, и про¬извольного логического выражения, применяемого к элементу этого типа данных (ограничения домена). Элемент данных является элементом домена в том и толь¬ко в том случае, если вычисление этого логического выражения дает результат ис¬тиной.
С каждым доменом связывается имя, уникальное среди имен всех доменов соответствующей базы данных. Наиболее правильной интуитивной трактовкой понятия домена является его восприятие как допустимого потенциального множества значений данного типа. *Схема отношения* — это именованное множество упорядоченных пар , если понятие домена не поддерживается.
По определению степенью или «арностью» схемы отношения является мощность этого множества. Например, степень отношения Сотрудники (рис. 3 равна четырем, то есть оно является 4-арным (кватернарным).
Если все атрибуты одного отношения определены на разных доменах, то, что¬бы не плодить лишних имен, разумно использовать для именования атрибутов имена соответствующих доменов. *Схема БД* — это множество именованных схем отношений. *Кортеж.* Множество упорядоченных пар , которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. Значение должно быть допустимым значением домена, на котором определен данный атрибут. *Отношение* — это множество кортежей, соответствующих одной схеме отношения.
Определение первичного ключа аналогично определению его в концептуальной модели данных. Далее, поэтапно, перечислим все процедуры логического проектирования. 1. Выбор модели данных. Чаще всего выбирается реляционная модель данных. 2. Определение набора отношений.
В соответствии с реляционной моделью данных, на основании утвержденной концептуальной модели данных создаются схемы отношений, отношения и атрибуты логической модели данных. Устанавливаются связи между отношениями. Связи, отношения, доменные ограничения документируются. 3. Нормализация отношений. Как правило, отношения приводятся к третьей нормальной форме.
Следует обратить внимания на случаи, когда нормализация не требуется. 4. Проверка логической модели данных на предмет возможности выполнения всех транзакций, заявленных пользователем в техническом задании или оговоренных при начале проектирования. 5. Определение требований поддержки целостности данных.
Проверяются следующие типы ограничений: обязательные данные (без null), доменные ограничения, целостность сущностей (правильные первичные ключи), ссылочная целостность (правильные внешние ключи), ограничения по бизнес-правилам. 6. Корректировка логической модели данных с конечными пользователями.
Результатом будет окончательный вариант словаря данных и er-модели, готовой к конвертации для реализации в одной из СУБД. **4-ий учебный вопрос: Физическое проектирование БД.** Соотнесем определения, которые мы дали применительно к сущности с терминами, которые используются при построении физической модели (табл. 1).
Таблица 1.  Дадим ряд определений для некоторых элементов физической модели. *Физический тип данных* – тип данных, характеризующий столбец с данными. Эти типы данных могут значительно отличаться друг от друга в зависимости от СУБД (MS SQL Server, IBM DB2, Oracle 12c и т.д.), в которой реализована физическая модель. *Уникальный индекс первичного ключа* – индекс, передающий столбцу в таблице все свойства первичного ключа.
Именно по этому индексу СУБД определит первичный ключ в таблице и установит условие ссылочной целостности. *Хранимая процедура* — объект базы данных, представляющий собой набор SQL-инструкций, который компилируется один раз и хранится на сервере. Хранимые процедуры очень похожи на обыкновенные процедуры языков высокого уровня, у них могут быть входные и выходные параметры и локальные переменные, в них могут производиться числовые вычисления и операции над символьными данными, результаты которых могут присваиваться переменным и параметрам.
Обычная хранимая процедура запускается на исполнение пользователем БД. *Триггер* – хранимая процедура, запускаемая СУБД автоматически, при наступлении определенного в коде хранимой процедуры события. *Внешний ключ* — подмножество столбцов некоторой переменной таблицы R2, значения которых должны совпадать со значениями некоторого первичного ключа некоторой переменной таблицы R1. Таблица R2 в этом случае называется потомком, а таблица R1 – родителем.
Выделим этапы физического проектирования баз данных. 1. Проектирование таблиц базы данных с учетом специфики выбранной СУБД. Помимо таблиц реализуются связи, представления, проводится индексирование. 2. Реализация бизнес-правил в выбранной СУБД. Бизнес-правила реализуются при помощи создания хранимых процедур и триггеров на языке SQL.
3. Дальнейшая оптимизация физической модели базы данных. Определяется нагрузка на отдельные элементы базы данных, оценивается пропускная способность и время отклика на запросы в обоих направлениях (на выдачу/на запись), создаются дополнительные индексы, если это требуется. 4. Разработка стратегии обеспечения безопасности информации.
Определение пользовательских групп, наделение правами разных ролей, выдача пар “логин-пароль” пользователям БД. 5. Осуществление постоянного мониторинга базы данных и СУБД. Постоянная модернизация физической модели. Отслеживание угроз для БД и СУБД. 
Источник: msuniversity.ru
ИНФОРАЦИЯ: ХРАНЕНИЕ СИМВОЛЬНЫХ ВЕЛИЧИН В ПАМЯТИ ЭВМ
Текстовая информация хранится в текстовом двоичном коде. Для этого каждому символу ставят соответствующее некоторое неотрицательное число – код символа. А это число записывается в память в двоичном виде.
Система кодировки (таблицы кодировки) — конкретное соответствие между символами и кодами.
В ПК используют 8-разрядная система. Использование 8-разрядных кодов позволяет закодировать 2 8 =256 различных символов (каждый код занимает 1 байт памяти).
Обычно используют кодировку, которая обозначается – ASCII (American Standard Information Interchange – Американский стандартный код для информационного обмена). В ней содержатся две таблицы кодировки: базовая(0 — 127) и расширенная (128 — 255).
0 – 31: первые 32 кода отданы производителям аппаратных средств ПК. Здесь размещаются управляющие коды, которым соответствуют никакие символы языков, они не выводятся на экран (невидимые символы) и принтер, но они позволяют управлять выводом прочих данных.
32 – 127: содержат коды символов английского алфавита (у больших и маленьких букв разные коды), знаки препинания, арифметические знаки.
128 – 255: содержат расширенную таблицу, в которой хранятся коды национальных алфавитов (русский).
Русский алфавит закодирован 5-ю различными алфавитами:
1. Windows – 1251: используются в ЭВМ, работающих на платформе Windows.
2. КОИ-8: код обмена информации (8 знаков (разрядов) = 1 байт). Используется в компьютерных сетях на территории России и в российском секторе Интернет.
3. ISO (международный институт стандартизации): международный стандарт в котором закодированы русские символы.
4. Устаревшие кодировки, а также те которые используются крайне редко (ГОСТ).
Если кодировать символы 16-ю разрядами (хотя бы 2 байта отводить на один символ), то у нас получается 64536 различных кодов (2 16 =65536).
Таблица кодировки, основанная на 16-ти разрядной кодировке называется Юникод (UNICODE). Она поддерживается некоторыми языками и операционными системами (язык – Java, и ОС Windows NT). Но есть недостаток — текстовые документы занимают больший объем памяти.
26. ПОНЯТИЕ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА. НАПРАВЛЕНИЯ ИССЛЕДОВАНИЙ.[59]
ИИ — одно из направлений информатики, целью кот. явл. разработка аппаратно-программных средств, позволяющих пользователю ставить и решать задачи, традиционно считающиеся интеллектуальными, общаясь с ЭВМ, на ограниченном подмножестве естественного языка.
ИИ — машинное моделирование человеческих интеллектуальных функций.
Направление исследований:
1. Распознавание образов – разработка технических систем, воспринимающих визуальную и звуковую информацию, кодирующих и размещающих её в памяти ЭВМ, решение проблем понимания и логических рассуждений в процессе обработки визуальной и речевой информации (каждому объекту ставится в соответствии матрица признаков, по которой происходит его распознавание).
2. Математика и автоматическое доказательство теорем.
3. Игры и творчество – Традиционно искусственный интеллект включает в себя игровые интеллектуальные задания – шахматы, шашки и т.д. Игры, характеризующиеся конечным числом ситуаций и четко определенными правилами, с самого начала исследований по Искусственному Интеллекту привлекли к себе внимание как предпочтительные объекты исследования. Интеллектуальными системами был быстро достигнут и превзойден уровень человека средних способностей. Сейчас это скорее коммерческое направление, так как в научном плане идеи считаются тупиковыми.
4. Распозначание естественноязыковых интерфейсов и машинный перевод (Понимание естественного языка). В 50-х гг. одной из популярных тем исследований искусственного интеллекта являлась область машинного перевода. Первая программа в этой области – переводчик с английского на русский. Первая идея — — пословный перевод, оказалась неплодотворной. В настоящее время используется более сложная модель, включающая анализ и синтез естественно-языковых сообщений, которая состоит из нескольких блоков. Для анализа это (синтез включает аналогичные этапы, но несколько в другом порядке):
· Морфологический анализ – анализ слов в тексте.
· Синтаксический анализ – анализ предложений, грамматики и связей между словами.
· Семантический анализ – анализ смысла каждого предложения на основе некоторой предметно-ориентированной базы знаний.
· Прагматический анализ – анализ смысла предложений в окружающем контексте на основе собственной базы знаний.
5. Новые архитектуры ПК – Это направление занимается разработкой новых аппаратных решений и архитектур, направленных на обработку символьных и логических данных. Создаются Пролог- и Лисп- машины, компьютеры V и VI поколений. Последние разработки посвящены компьютерам баз данных и параллельным компьютерам.
6. Интеллектуальные роботы – Роботы – это электромеханические устройства, предназначенные для автоматизации человеческого труда. Идея создания роботов исключительно древняя. Само слово появилось в 20-х годах. Его автор – чешский писатель Карел Чапек. Со времени создания сменилось несколько поколений роботов.
В настоящее время в мире изготавливается более 60 тыс. роботов в год.
I. Роботы с жесткой схемой управления. Практически все современные промышленные роботы принадлежат к первому поколению. Фактически это программируемые манипуляторы.
II. Адаптивные роботы с сенсорными устройствами. Есть образцы таких роботов, но в промышленности их пока не используются.
III. Самоорганизующиеся или интеллектуальные роботы. Это конечная цель развития робототехники. Основная проблема при создании интеллектуальных роботов – проблема машинного зрения.
7. Выявление и представление знаний специалистов в экспертных системах. ЭС-интеллектуальные системы, вобравшие в себя знания специалистов в конкретных видах деятельности – имеют большое практическое значение, с успехом применяются во многих областях, таких как автоматизированное проектирование, медицинская диагностика, химический анализ.
8. Специальное и программное обеспечение – В рамках этого направления разрабатываются специальные языки для решения задач невычислительного плана. Эти языки ориентированы на символьную обработку информации – LISP, PROLOG, SMALLTALK, РЕФАЛ и др. Помимо этого создаются пакеты прикладных программ, ориентированные на промышленную разработку интеллектуальных систем, или программные инструментарии искусственного интеллекта, например KEE, ARTS[10]. Достаточно популярно создание так называемых пустых экспертных систем, или оболочек, — EXSYS, M1 и др., в которых можно наполнять базы знаний, создавая различные системы.
9. Обучение и самообучение – Активно развивающаяся область искусственного интеллекта. Включает модели, методы и алгоритмы, ориентированные на автоматическое накопление знаний на основе анализа и обобщения данных. Включает обучение по примерам (или индуктивное), а также традиционные подходы распознавания образов.
Данные – это отдельные факты, характеризующие объекты, процессы и явления в предметной области, а также их свойства. Данные хранятся в базе данных.
Знаний – это выявленные закономерности предметной области (принципы, связи, законы), позволяющие решать задачи в этой области (или хорошо структурированные данные, или данные о данных, или метаданные). Знания хранятся в базе знаний. База знаний – основа любой интеллектуальной системы.
27. МОДЕЛЬ ДАННЫХ (МД). ПОНЯТИЕ МД. ВИДЫ МД. СВЯЗЬ МД С БД. ВИДЫ БД.
ПРИМЕРЫ БД. РЕЛЯЦИОННАЯ БД (РБД): ПОНЯТИЕ, ОСНОВНЫЕ ЭЛЕМЕНТЫ БД И КРАТКАЯ ХАРАКТЕРИСТИКА РАБОТЫ С РБД.[33]
В основе любой БД лежит модель данных (информационная структура) – она является ядром БД.
Модель данных (МД) — совокупность правил организации структуры данных в БД, операций над ними, а также ограничений целостности, определяющих допустимые связи и значения данных, последовательность их изменения.
К числу классических относятся следующие модели данных: сетевая, иерархическая и реляционная. Однако в последние годы появляются новые МД, основанные на комбинации классических моделей или на некотором их подмножестве, например, постреляционная, многомерная и объектно-ориентированная. Разрабатываются также системы, основанные на таких МД, как объектно-реляционная, семантическая или ориентированная.
Виды МД:
1. Иерархическая модель – подчиненность объектов нижнего уровня объектам верхнего уровня (каталог файлов).
2. Сетевая модель – возможность устанавливать к вертикальным горизонтальные связи; произвольный граф, между верхними и нижними объектами задано соотношение «многие ко многим».
3. Реляционная МД – (relation-связь, отношение) организация данных таблиц. Каждая реляционная таблица – двумерный массив со следующими свойствами:
· Каждый элемент таблицы один.
· Все столбцы однородны, то есть имеют одинаковый тип и длину.
· Каждый столбец имеет уникальное имя.
· Одинаковые строки отсутствуют;
· Порядок следования строк и столбцов может быть произвольным.
4 .Многомерная БД предназначена для интерактивной аналитической обработки информации. Многомерность модели характеризует в 1-ю очередь лог структуру представления информации (не x, y, z, а строка, столбец, глубина). Эта модель удобна и эффективна при анализе данных (глубина). Но слишком громоздка для простейших задач.
5. Объектно-ориентиров МД — объединяет 2 модели: реляционную и сетевую. Логическая структура внешне похожа на иерархическую, отличается от неё методами нумерования данных.
6. Постреляционная представляет собой расширенную реляционную, сжимающую ограничения целостности данных, хранящихся в записи таблиц. Достоинство: возможность представления совокупности таблиц одной постреляционной таблицей. Недостаток: сложность решения проблем обеспечения целостности данных.
7. Объектно-реляционнная МД – гибрид объектной технологии и реляционной МД (работает с Visual Basic).
Классификация БД и примеры:
По характеру хранения:
1. Фактографическая – факты регистрируются как конкретные значения об объектах реального мира (картотеки, хранящиеся в хронологическом порядке).
2. Документальная – совокупность неструктурированных текстов, документов и графических объектов (архив).
По технологии обработки данных:
1. Централизованные – представлены на одном из множества компьютеров.
2. Распределенные – разделены на части и из частей представлена на конкретном ПК. Работа с такой БД осуществляется с помощью системы управления распределенной базой данных (СУРБД).
По способу доступа к данным:
1. С удаленным доступом (сетевая) – обращение к БД с другого компьютера.
2. С локальным доступом – обращение к БД текущего ПК без выхода в сеть.
Существует особый тип БД, кот называется БЗ (база Знаний) – лежит в основе экспертных систем, кот имитируют функции человека эксперта. В ней происходит анализ и накопление данных.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник: studopedia.ru
Обработка и хранение информации
Предметная область какой-либо деятельности — часть реального мира, подлежащая изучению с целью организации управления процессами и объектами для получения бизнес-результата. Предметная область может быть разделена (декомпозирована) на фрагменты: например, предприятие — это дирекция, плановые отделы, бухгалтерия, цеха, отделы маркетинга, логистики и продаж, клиенты, поставщики и т. д. Каждый фрагмент предметной области характеризуется множеством объектов и процессов, использующих объекты, а также множеством пользователей, характеризуемых различными взглядами на предметную область и данными, которые описывают указанные составляющие предметной области . Эти данные отражают динамичную внешнюю и внутреннюю среды предприятия, поэтому в специальных разделах информационной системы необходимо создавать динамически обновляемые модели отражения внешнего мира с использованием единого хранилища — базы данных .
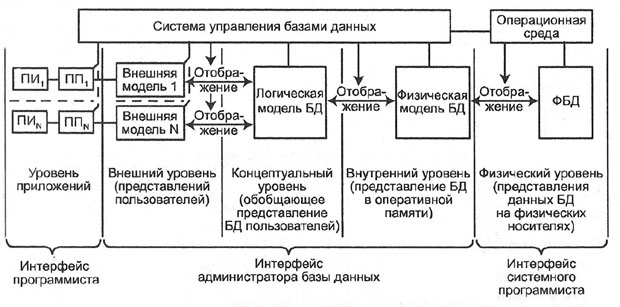
Рис. 2.2. Общая схема базы данных
База данных, БД (Data Base) — структурированный организованный набор данных, объединенных в соответствии с некоторой выбранной моделью и описывающих характеристики какой-либо физической или виртуальной системы ( рис. 2.2).
Понятие «динамически обновляемая БД » означает, что соответствие базы данных текущему состоянию предметной области обеспечивается не периодически, а в режиме реального времени. При этом одни и те же данные могут быть по -разному представлены в соответствии с потребностями различных групп пользователей.
Система управления базами данных, СУБД (Data Base Management System) — специализированная программа или комплекс программ, предназначенные для манипулирования базой данных. Для создания информационной системы и управления ею СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор .
СУБД часто упрощенно или ошибочно называют «базой данных». Нужно различать набор данных (собственно БД ) и программное обеспечение , предназначенное для организации и ведения баз данных ( СУБД ).
Отличительной чертой баз данных следует считать то, что данные хранятся совместно с их описанием, а в прикладных программах описание данных не содержится. Независимые от программ пользователя данные обычно называются метаданными или данными о данных. В ряде современных систем метаданные , содержащие также информацию о пользователях, форматы отображения, статистику обращения к данным и др. сведения, хранятся в специальном словаре базы данных .
Организация структуры БД формируется исходя из следующих соображений:
- адекватность описываемому объекту/системе — на уровне концептуальной и логической моделей ;
- удобство использования для ведения учета и анализа данных — на уровне так называемой физической модели .
Виды концептуальных и логических моделей БД :
- картотеки;
- сетевые;
- иерархические;
- реляционные;
- дедуктивные;
- объектно-ориентированные;
- многомерные.
На уровне физической модели электронная БД представляет собой файл или набор данных в dbf-форматах приложений Excel , Access либо в специализированном формате конкретной СУБД . Также в СУБД в понятие физической модели включают специализированные виртуальные понятия, существующие в ее рамках, — » таблица «, «табличное пространство «, «сегмент», «куб», » кластер » и т. д.
В настоящее время наибольшее распространение получили реляционные базы данных . Картотеками пользовались до появления электронных баз данных. Сетевые и иерархические базы данных считаются устаревшими, объектно-ориентированные пока никак не стандартизированы и не получили широкого распространения.
Реляционная база данных — база данных , основанная на реляционной модели. Слово «реляционный» происходит от английского » relation » ( отношение ).
Теория реляционных баз данных была разработана доктором Эдгаром Коддом из компании IBM в 1970 году. В реляционных базах данных все данные представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении которых расположены данные. Запросы к таким таблицам возвращают таблицы, которые сами могут становиться предметом дальнейших запросов. Каждая база данных может включать несколько таблиц. Кратко особенности реляционной базы данных можно сформулировать следующим образом:
- данные хранятся в таблицах, состоящих из столбцов («атрибутов») и строк («записей»);
- на пересечении каждого столбца и строчки стоит в точности одно значение;
- у каждого столбца есть свое имя, которое служит его названием, и все значения в одном столбце имеют один тип;
- запросы к базе данных возвращают результат в виде таблиц, которые тоже могут выступать как объект запросов;
- строки в реляционной базе данных неупорядочены, упорядочивание производится в момент формирования ответа на запрос.
Общепринятым стандартом языка работы с реляционными базами данных в настоящее время является язык структурированных запросов ( Structured Query Language — SQL ). Это универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных . Вопреки существующим заблуждениям, SQL является информационно-логическим языком, а не языком программирования.
SQL основывается на реляционной алгебре . Язык SQL делится на три части:
- операторы определения данных;
- операторы манипуляции данными (Insert, Select, Update, Delete);
- операторы определения доступа к данным.
Основные функции системы управления базами данных :
- управление данными во внешней памяти (на различных носителях);
- управление данными в оперативной памяти;
- журналирование изменений и восстановление базы данных после сбоев;
- поддержка языков БД (язык определения данных, язык манипулирования данными, язык определения доступа к данным).
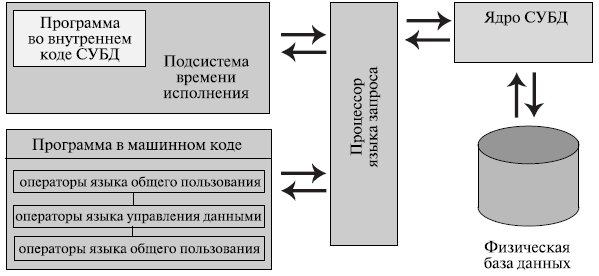
Рис. 2.3. Основные компоненты СУБД
Обычно современная СУБД содержит следующие компоненты ( рис. 2.3):
- ядро, которое отвечает за управление данными во внешней и оперативной памяти и журналирование ;
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода;
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД;
- сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
По типу управляемой базы данных СУБД разделяются на иерархические, реляционные, объектно-реляционные, объектно-ориентированные, сетевые.
По архитектуре организации хранения данных:
- локальные СУБД (все части локальной СУБД размещаются на одном компьютере);
- распределенные СУБД (части СУБД могут размещаться на двух и более компьютерах).
Классификация СУБД по способу доступа к БД :
- файл-серверные ;
- клиент-серверные;
- трехзвенные;
- встраиваемые.
Файл-серверные СУБД. Архитектура » файл-сервер » не имеет сетевого разделения компонентов диалога и использует компьютер для функции отображения, что облегчает построение графического интерфейса. » Файл-сервер » только извлекает данные из файлов, так что дополнительные пользователи добавляют лишь незначительную нагрузку на центральный процессор , и каждый новый клиент добавляет вычислительную мощность сети. Минус — высокая загрузка сети. На данный момент файл-серверные СУБД считаются устаревшими. Примеры: Microsoft Access, MySQL (до версии 5.0).
Клиент-серверные СУБД. Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера. Клиент-серверные СУБД , в отличие от файл -серверных, обеспечивают разграничение доступа между пользователями и меньше загружают сеть и клиентские машины.
Сервер является внешней по отношению к клиенту программой, и по мере надобности его можно заменить другим. Недостаток клиент-серверных СУБД — в самом факте существования сервера (что плохо для локальных программ — в них удобнее встраиваемые СУБД ) и больших вычислительных ресурсах, потребляемых сервером. Примеры: Firebird , Interbase , MS SQL Server , Oracle , DB2 , PostgreSQL, MySQL (старше версии 5.0).
Существенным недостатком клиент-серверной архитектуры является необходимость установления прямого соединения между клиентским компьютером и базой данных. При трехзвенной архитектуре пользовательское приложение (клиент) соединяется со специально выделенным сервером приложений, и только он уже соединяется с базой данных. Кроме повышения уровня безопасности трехзвенная архитектура позволяет более гибко модернизировать приложения. Как правило, в массовой клиентской части оставляют только минимальный набор функций по доступу и отображению информации, а основную бизнес-логику реализуют в программах, запускаемых на серверах приложений . При этом модернизация обычно затрагивает только сервер приложений , а на массовых клиентских местах переустанавливать ПО не приходится.
Встраиваемая СУБД — это, как правило, «библиотека», которая позволяет унифицированным образом хранить большие объемы данных на локальной машине. Доступ к данным может происходить через SQL либо через особые функции СУБД . Встраиваемые СУБД быстрее обычных клиент-серверных и не требуют установки сервера, поэтому востребованы в локальном ПО , которое имеет дело с большими объемами данных — например, геоинформационные системы (Geographic Informational System — GIS ). Примеры: SQLite, BerkeleyDB, один из вариантов Firebird , один из вариантов MySQL .
В общем случае СУБД могут быть классифицированы в системе координат «Неоднородность — Автономность -Распределенность» ( рис. 2.4).
Таким образом, распределенная обработка данных в обязательном порядке предполагает наличие банков и баз данных. Но база данных — это не просто место , куда складывают данные, ими нужно пользоваться, актуализировать, изменять форматы и связи, совершать множество других действий. Если бессистемно наполнять базу данных информацией, то через некоторое время ее невозможно будет использовать — времени на поиск нужных данных будет уходить все больше и больше, физическое пространство базы переполнится. Чтобы этого избежать, данные необходимо «очищать» и структурировать, а для эффективной работы с ними необходимы системы управления работой баз данных.
Индустрия создания баз данных и СУБД берет свое начало в 60-х годах прошлого века и к настоящему времени достаточно развита, однако понятие » хранилище данных » в современном понимании его появилось относительно недавно.
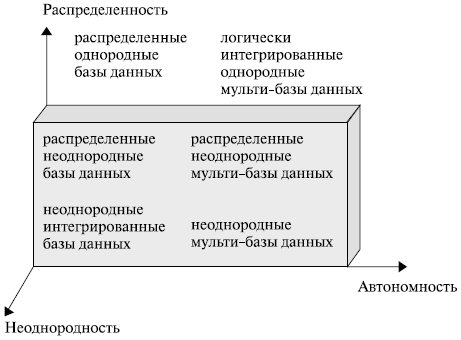
Рис. 2.4. Классификационная система координат
Идея хранилищ данных оказалась востребованной, так как во многих видах государственной, деловой, научной, социальной деятельности необходимы тематически объединенные и исторически очищенные совокупности данных, при этом постоянно возрастала потребность:
- в более дешевых данных;
- в точных и структурированных данных;
- в большей оперативности получения и обработки данных;
- в интегрированных данных.
К концу 1980-х годов, когда была в полной мере осознана необходимость интеграции корпоративной информации и надлежащего управления этой информацией, появились технические возможности для создания соответствующих систем, которые первоначально были названы «хранилищами информации» ( Information Warehouse — IW). И лишь в 1990-е годы, с выходом книги Уильяма (Билла) Инмона, хранилища получили свое нынешнее наименование «хранилища данных» ( Data Warehouse — DW) [Inmon W.H. Building the Data Warehouse , QED/Wiley, 1991, 312 р.].
Билл Инмон определил хранилища данных как «предметно-ориентированные, интегрированные, неизменные, поддерживающие хронологию наборы данных, организованные для целей поддержки управления, призванные выступать в роли единого и единственного источника истины, обеспечивающего менеджеров и аналитиков достоверной информацией, необходимой для оперативного анализа и принятия решений».
В основе концепции хранилищ данных лежат следующие основополагающие идеи:
- интеграция ранее разъединенных детализированных данных (исторические архивы, данные из традиционных систем обработки документов, разрозненных баз данных, данные из внешних источников) в едином хранилище данных;
- тематическое и временное структурирование, согласование и агрегирование ;
- разделение наборов данных, используемых для операционной (производственной) обработки, и наборов данных, используемых для решения задач анализа.
Данные, помещаемые в хранилище, должны отвечать определенным требованиям — предметной ориентированности, интегрированности, поддержки хронологии и неизменяемости (таблица 2.3).
| Предметная ориентированность | Все данные о некоторой сущности (бизнес-объекте, бизнес-процессе и т. д.) из некоторой предметной области собираются из множества различных источников, очищаются, согласовываются, дополняются, агрегируются и представляются в единой, удобной для их использования в бизнес-анализе форме |
| Интегрированность | Все данные о различных бизнес-объектах взаимно согласованы и хранятся в едином общекорпоративном хранилище |
| Поддержка хронологии | Данные хронологически структурированы и отражают историю за период времени, достаточный для выполнения задач бизнес-анализа, прогнозирования и подготовки принятия решения |
| Неизменяемость | Исходные (исторические) данные, после того как они были согласованы, верифицированы и внесены в общекорпоративное хранилище, остаются неизменными и используются исключительно в режиме чтения |
Хранилище данных выполняет множество функций, но его основное предназначение — предоставление точных данных и информации в кратчайшие сроки и с минимумом затрат.
Понятие хранилище данных в первоначальном понимании было основано на понятии распределенной витрины данных ( Distributed Data Mart — DDM ). Поэтому в классическом исполнении хранилище данных было прежде всего репозиторием (сквозной базой данных) данных и информации предприятия.
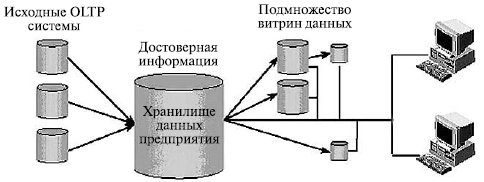
Рис. 2.5. Схема организации данных в хранилище
Среда хранилища была предназначена только для чтения и состояла из детальных и агрегированных данных, которые полностью очищены и интегрированы; кроме того, в репозитории хранилась обширная и детальная история данных на уровне транзакций. С точки зрения архитектурного решения такое хранилище данных реализует свои функции через подмножество зависимых витрин данных ( рис. 2.5).
Достоинствами архитектуры классического хранилища данных являются:
- общая семантика;
- централизованная, управляемая среда;
- согласованный набор процессов извлечения и бизнес-логики использования;
- непротиворечивость содержащейся информации;
- легко создаваемые по шаблонам и наполняемые витрины данных;
- единый репозиторий метаданных ;
- многообразие механизмов обработки и представления данных.
К недостаткам можно отнести большие затраты по реализации, высокую ресурсоемкость в масштабе всего предприятия, потребность в сложных сервисных системах, рискованный сценарий развития, когда все данные и метаданные находятся в одном репозитории и в неблагоприятном случае могут быть потеряны. Кроме того, при фильтрации, агрегировании и рафинировании «сырых» данных для такого хранилища обычно теряется очень много информации, которая может быть чрезвычайно полезной при бизнес-анализе. В связи с этим возникло понимание того, что хранилище, помимо механизмов размещения и извлечения данных (On Line Transactional Processing — OLTP ), репозитория и витрин, должно иметь соответствующее пространство для организации «сырых» данных и их многомерного анализа в режиме реального времени (On Line Analytical Processing — OLAP ).
Источник: intuit.ru