
Что такое Apache Hadoop в Azure HDInsight?
Первоначально технология Apache Hadoop была платформой с открытым кодом для распределенной обработки и анализа наборов больших данных в кластерах. Экосистема Hadoop состоит из взаимосвязанного программного обеспечения и служебных программ, таких как Apache Hive, Apache HBase, Spark, Kafka и т. д.
Azure HDInsight — это полностью управляемая комплексная облачная служба аналитики с открытым кодом, предназначенная для предприятий. Тип кластера Apache Hadoop в Azure HDInsight позволяет использовать распределенную файловую систему Apache Hadoop (HDFS) и управление ресурсами Apache Hadoop YARN, а также простую модель программирования MapReduce для параллельной обработки и анализа пакетных данных. Кластеры Hadoop в HDInsight совместимы с Хранилищем BLOB-объектов Azure, Azure Data Lake Storage 1-го поколения или Azure Data Lake Storage 2-го поколения.
Просмотреть доступные компоненты стека технологии Hadoop в HDInsight можно в статье Что представляют собой компоненты и версии Hadoop, доступные в HDInsight? Дополнительные сведения о Hadoop в HDInsight см. на странице возможностей HDInsight в Azure.
Очень кратко про Hadoop и Spark
Что такое MapReduce
Apache Hadoop MapReduce — это программная платформа для создания заданий, обрабатывающих большие объемы данных. Входные данные разбиваются на независимые блоки, которые затем обрабатываются параллельно на узлах кластера. Задание MapReduce состоит из двух функций.
- Mapper(Модуль сопоставления) — принимает входные данные, анализирует их (обычно с помощью фильтрации и сортировки) и передает кортежи (пары «ключ-значение»).
- Reducer(Редуктор) — принимает кортежи, сформированные в модуле сопоставления, и выполняет операцию сводки, которая создает результат меньшего размера, объединяющий данные модуля сопоставления
На следующей диаграмме показан пример задания MapReduce, которое выполняет простую операцию подсчета слов:
Выходные данные этого задания представляют собой частоту использования каждого слова в тексте.
- Процедура map берет каждую строку из входного текста в качестве входных данных и разбивает ее на слова. Она генерирует пару «ключ-значение» каждый раз, когда встречается слово, за которым следует 1. Перед отправкой на обработку редуктором выходные данные сортируются.
- Затем редуктор суммирует эти отдельные счетчики для каждого слова и выдает одну пару «ключ-значение», содержащую слово, за которым следует частота его использования.
Задание MapReduce может быть реализовано на различных языках. Java — это наиболее распространенная реализация, которая используется в данном документе для примера.
Языки разработки
Языки или платформы на основе Java или виртуальной машины Java можно запускать непосредственно как задание MapReduce. В качестве примера в этом документе приведено приложение MapReduce на языке Java. Прочие языки и платформы, например C# или Python, или изолированные исполняемые файлы должны использовать потоковую передачу Hadoop.
01 — Hadoop. Введение
Потоковая передача Hadoop взаимодействует с модулями сопоставления и редукции через потоки STDIN и STDOUT. Модули сопоставления и редукции построчно считывают данные из потока STDIN и записывают выходные данные в поток STDOUT. Каждая строка, которая читается или генерируется модулем сопоставления или редукции, должна быть в формате пар «ключ-значение», разделенных знаком табуляции.
Дополнительные сведения см. в документации по потоковой передаче Hadoop.
Примеры использования потоковой передачи Hadoop с HDInsight см. в следующих документах:
С чего начать
- Краткое руководство. Создание кластера Apache Hadoop в Azure HDInsight с помощью портала Azure
- Учебник. Отправка заданий Apache Hadoop в HDInsight
- Разработка программ MapReduce на Java для Apache Hadoop в HDInsight
- Использование Apache Hive как средства для извлечения, преобразования и загрузки
- Extract, transform, and load (ETL) at scale (Извлечение, преобразование и загрузка (ETL) в масштабе)
- Ввод в эксплуатацию конвейера аналитики данных
Дальнейшие действия
- Создание кластера Apache Hadoop в HDInsight с помощью портала
- Создание кластера Apache Hadoop в HDInsight с помощью шаблона ARM
Источник: learn.microsoft.com
Что такое Hadoop, где и зачем используется

Если вы станете подробно изучать тему Big Data, то рано или поздно столкнетесь с термином Hadoop / «Хадуп». Этим словом обозначается набор программ или процессов с открытым исходным кодом (то есть, бесплатных для пользователя), которые применяются в качестве базы для построения систем Big Data и последующей работы с ними.
Использование больших данных сегодня требуется для средних и крупных компаний, которые пытаются усовершенствовать бизнес-процессы и повысить качество своего сервиса. Имеющаяся информация о покупателях, финансовых показателях, операциях или транзакциях нуждается в постоянном хранении, обработке и анализе. Именно для совершения таких операций применяются специальные сервисы и приложения.
Hadoop является одним из самых популярных решений для совершения операций с Big Data. Его активно используют такие гиганты, как Google, Facebook, eBay и многие другие. Стоит отметить, что «Хадуп» отлично подходит для бизнеса любой отрасли, которые работает с массивами данных объемом более терабайта. Программа имеет множество преимуществ, включая возможность масштабирования и простую оптимизацию на ВМ. Многие облачные провайдеры предлагают ее как облачный сервис.
Разберемся, что же представляет такой инструмент, какие функции он имеет и каким организациям его стоит использовать.
Что такое «Хадуп»
Если говорить простыми словами, то «Хадуп» – это специальный конструктор, который позволяет выстроить хранилища данных под нужды компании. С его помощью можно выполнять хранение и обработку больших массивов информации, выгружать их в другие инструменты, собирать статистику и выстраивать единую систему отображения.
Такой инструмент подходит для использования с неструктурированными сведениями – то есть информацией, которая не была упорядочена, не имеет структуры и ее сложно разбить на группы. Например, примером таких данных могут являться сообщения, файловые документы или фото.
Система поможет найти необходимые сведения в архиве и получить значимую аналитику для организации. Все этом может стать необходимым при определении стратегии бизнес-развития или разработке нового продукта. Например, многие торговые сети используют «Хадуп» для сбора информации о предпочтениях покупателей. Нередко полученные данные объединяются со сведениями о продажах, что позволяет оценить, какие именно действия на сайте приводят к покупке товара.
Если говорить об основных преимуществах технологии, то можно отметить:
- Масштабируемость. Система легко масштабируется, всегда можно добавлять новые узлы при увеличении объема информации.
- Простая работа. Данные не нуждаются в обработке перед сохранением. Платформа Hadoop отлично подходит для переработки неструктурированных данных любого типа, включая тексты, изображения и видео.
- Отказоустойчивость. Копии всех файлов сохраняются автоматически, поэтому в случае сбоя все сведения будут перенаправлены на работающий узел.
- Мощность вычислений. «Хадуп» позволяет обрабатывать информацию с высокой скоростью. Мощность зависит от количества используемых вычислительных узлов: чем больше их используется, тем выше показатели.
- Возможность хранения данных. Инструмент можно настроить для обработки файлов с различных ресурсов, соцсетей компании, финансовых отчетов и т. д. Кроме этого, решение позволяет эффективно хранить данные. Архивы платформы устроены так, что к ним в любой момент можно получить нужный доступ.
«Хадуп» представляет собой набор свободно распространяемых утилит, фреймворков и библиотек. Именно эти компоненты помогают выполнять разработку и распределение программ, которые работают на кластерах из сотен узлов. Такая технология является основополагающей для работы с Big Data.
Источник: www.xelent.ru
Big Data от А до Я. Часть 2: Hadoop
Привет, Хабр! В предыдущей статье мы рассмотрели парадигму параллельных вычислений MapReduce. В этой статье мы перейдём от теории к практике и рассмотрим Hadoop – мощный инструментарий для работы с большими данными от Apache foundation.
В статье описано, какие инструменты и средства включает в себя Hadoop, каким образом установить Hadoop у себя, приведены инструкции и примеры разработки MapReduce-программ под Hadoop.

Общая информация о Hadoop
Как известно парадигму MapReduce предложила компания Google в 2004 году в своей статье MapReduce: Simplified Data Processing on Large Clusters. Поскольку предложенная статья содержала описание парадигмы, но реализация отсутствовала – несколько программистов из Yahoo предложили свою реализацию в рамках работ над web-краулером nutch. Более подробно историю Hadoop можно почитать в статье The history of Hadoop: From 4 nodes to the future of data
Изначально Hadoop был, в первую очередь, инструментом для хранения данных и запуска MapReduce-задач, сейчас же Hadoop представляет собой большой стек технологий, так или иначе связанных с обработкой больших данных (не только при помощи MapReduce).
Основными (core) компонентами Hadoop являются:
-
Hadoop Distributed File System (HDFS) – распределённая файловая система, позволяющая хранить информацию практически неограниченного объёма.
-
Hive – инструмент для SQL-like запросов над большими данными (превращает SQL-запросы в серию MapReduce–задач);
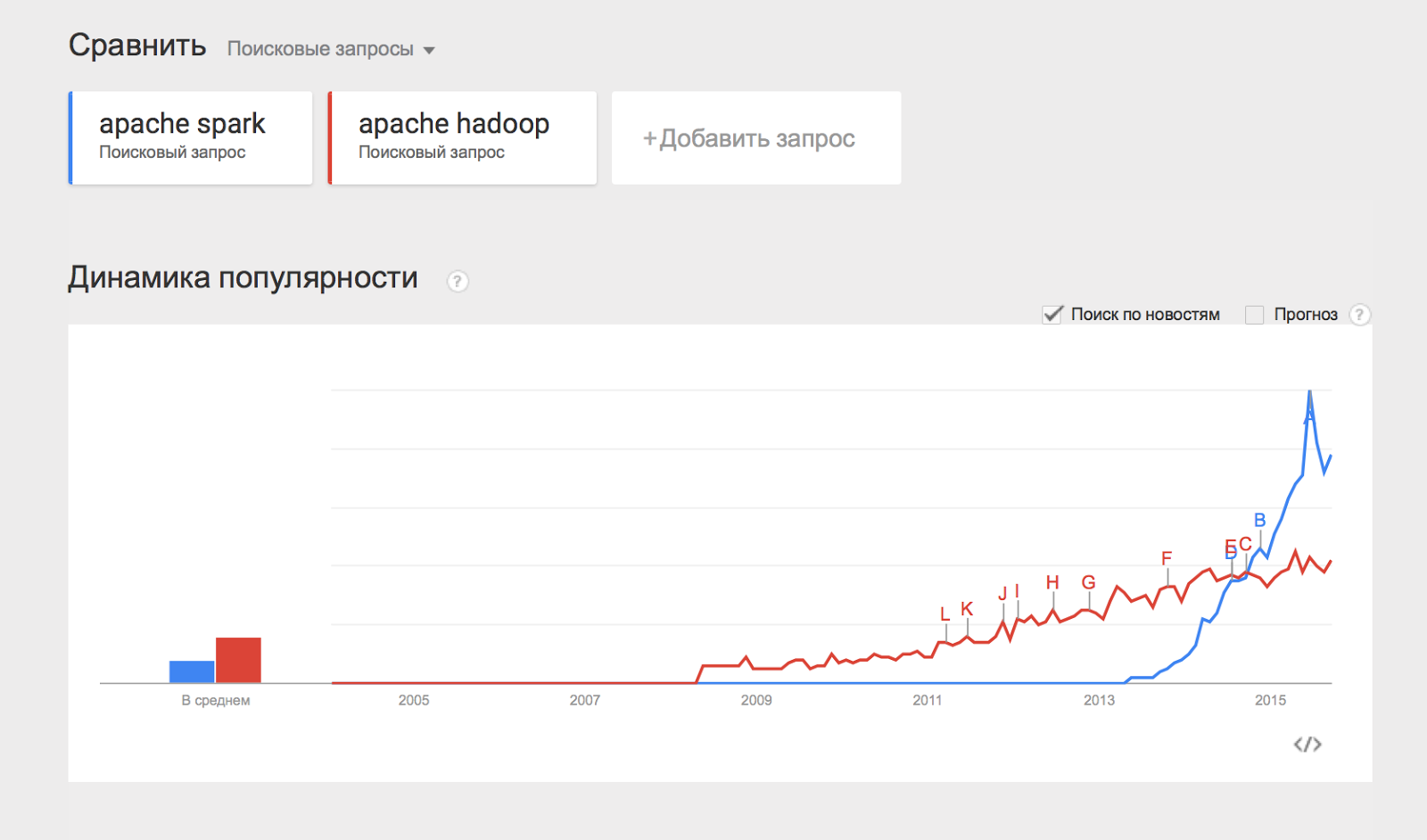
Некоторым из перечисленных компонент будут посвящены отдельные статьи этого цикла материалов, а пока разберём, каким образом можно начать работать с Hadoop и применять его на практике.
Установка Hadoop на кластер при помощи Cloudera Manager
Раньше установка Hadoop представляла собой достаточно тяжёлое занятие – нужно было по отдельности конфигурировать каждую машину в кластере, следить за тем, что ничего не забыто, аккуратно настраивать мониторинги. С ростом популярности Hadoop появились компании (такие как Cloudera, Hortonworks, MapR), которые предоставляют собственные сборки Hadoop и мощные средства для управления Hadoop-кластером. В нашем цикле материалов мы будем пользоваться сборкой Hadoop от компании Cloudera.
Для того чтобы установить Hadoop на свой кластер, нужно проделать несколько простых шагов:
- Скачать Cloudera Manager Express на одну из машин своего кластера отсюда;
- Присвоить права на выполнение и запустить;
- Следовать инструкциям установки.
После установки вы получите консоль управления кластером, где можно смотреть установленные сервисы, добавлять/удалять сервисы, следить за состоянием кластера, редактировать конфигурацию кластера:
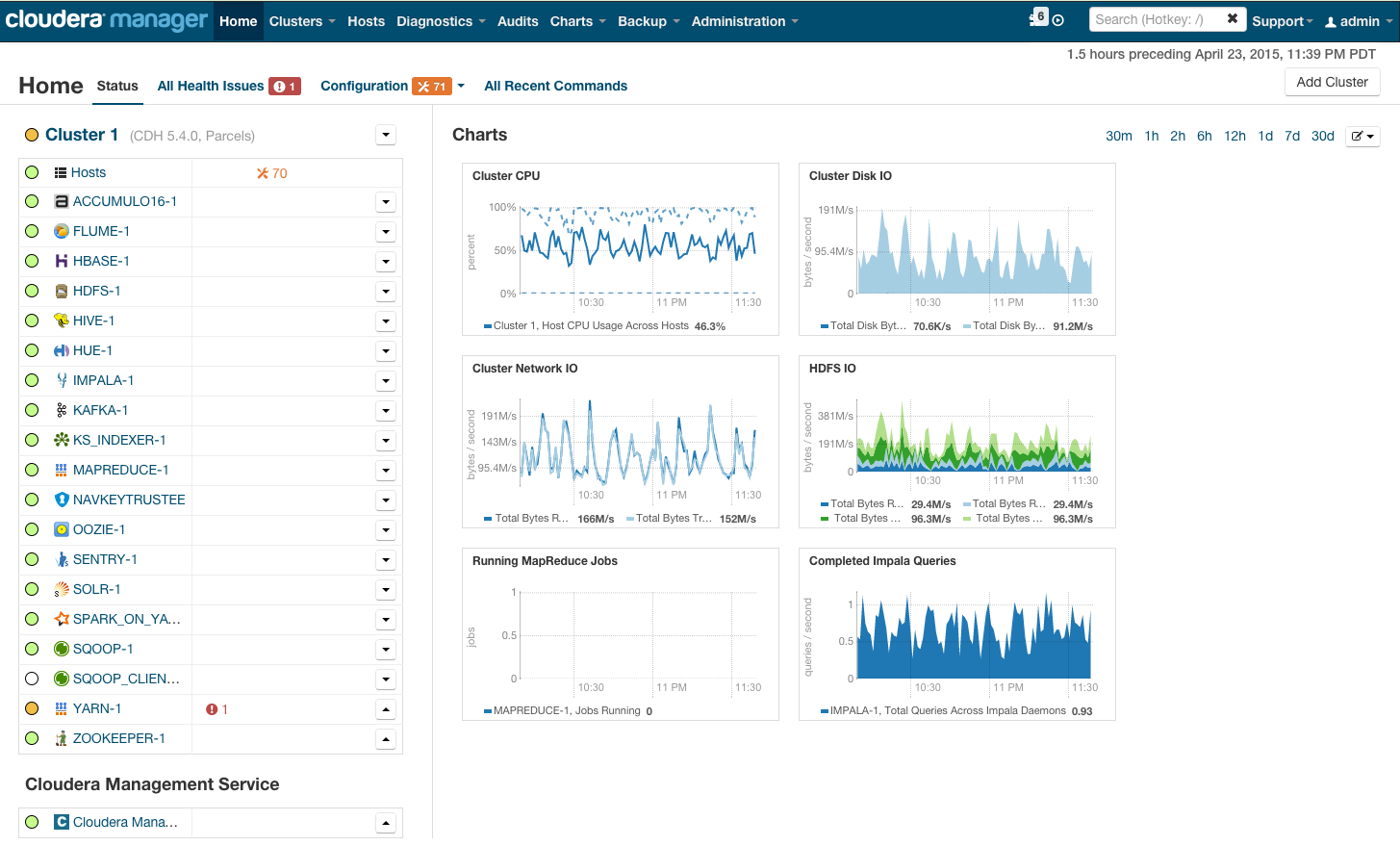
Более подробно с процессом установки Hadoop на кластер при помощи cloudera manager можно ознакомиться по ссылке в разделе Quick Start.
Если же Hadoop планируется использовать для «попробовать» – можно не заморачиваться с приобретением дорогого железа и настройкой Hadoop на нём, а просто скачать преднастроенную виртуальную машину по ссылке и пользоваться настроенным hadoop’ом.
Запуск MapReduce программ на Hadoop
Теперь покажем как запустить MapReduce-задачу на Hadoop. В качестве задачи воспользуемся классическим примером WordCount, который был разобран в предыдущей статье цикла. Для того, чтобы экспериментировать на реальных данных, я подготовил архив из случайных новостей с сайта lenta.ru. Скачать архив можно по ссылке.
Напомню формулировку задачи: имеется набор документов. Необходимо для каждого слова, встречающегося в наборе документов, посчитать, сколько раз встречается слово в наборе.
def map(doc): for word in doc.split(): yield word, 1
def reduce(word, values): yield word, sum(values)
Способ №1. Hadoop Streaming
Самый простой способ запустить MapReduce-программу на Hadoop – воспользоваться streaming-интерфейсом Hadoop.
Streaming-интерфейс предполагает, что map и reduce реализованы в виде программ, которые принимают данные с stdin и выдают результат на stdout.
Программа, которая исполняет функцию map называется mapper. Программа, которая выполняет reduce, называется, соответственно, reducer.
Streaming интерфейс предполагает по умолчанию, что одна входящая строка в mapper или reducer соответствует одной входящей записи для map.
Вывод mapper’a попадает на вход reducer’у в виде пар (ключ, значение), при этом все пары соответствующие одному ключу:
- Гарантированно будут обработаны одним запуском reducer’a;
- Будут поданы на вход подряд (то есть если один reducer обрабатывает несколько разных ключей – вход будет сгруппирован по ключу).
#mapper.py import sys def do_map(doc): for word in doc.split(): yield word.lower(), 1 for line in sys.stdin: for key, value in do_map(line): print(key + «t» + str(value))
#reducer.py import sys def do_reduce(word, values): return word, sum(values) prev_key = None values = [] for line in sys.stdin: key, value = line.split(«t») if key != prev_key and prev_key is not None: result_key, result_value = do_reduce(prev_key, values) print(result_key + «t» + str(result_value)) values = [] prev_key = key values.append(int(value)) if prev_key is not None: result_key, result_value = do_reduce(prev_key, values) print(result_key + «t» + str(result_value))
Данные, которые будет обрабатывать Hadoop должны храниться на HDFS. Загрузим наши статьи и положим на HDFS. Для этого нужно воспользоваться командой hadoop fs:
wget https://www.dropbox.com/s/opp5psid1x3jt41/lenta_articles.tar.gz tar xzvf lenta_articles.tar.gz hadoop fs -put lenta_articles
Утилита hadoop fs поддерживает большое количество методов для манипуляций с файловой системой, многие из которых один в один повторяют стандартные утилиты linux. Подробнее с её возможностями можно ознакомиться по ссылке.
Теперь запустим streaming-задачу:
yarn jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar -input lenta_articles -output lenta_wordcount -file mapper.py -file reducer.py -mapper «python mapper.py» -reducer «python reducer.py»
Утилита yarn служит для запуска и управления различными приложениями (в том числе map-reduce based) на кластере. Hadoop-streaming.jar – это как раз один из примеров такого yarn-приложения.
Дальше идут параметры запуска:
- input – папка с исходными данными на hdfs;
- output – папка на hdfs, куда нужно положить результат;
- file – файлы, которые нужны в процессе работы map-reduce задачи;
- mapper – консольная команда, которая будет использоваться для map-стадии;
- reduce – консольная команда которая будет использоваться для reduce-стадии.
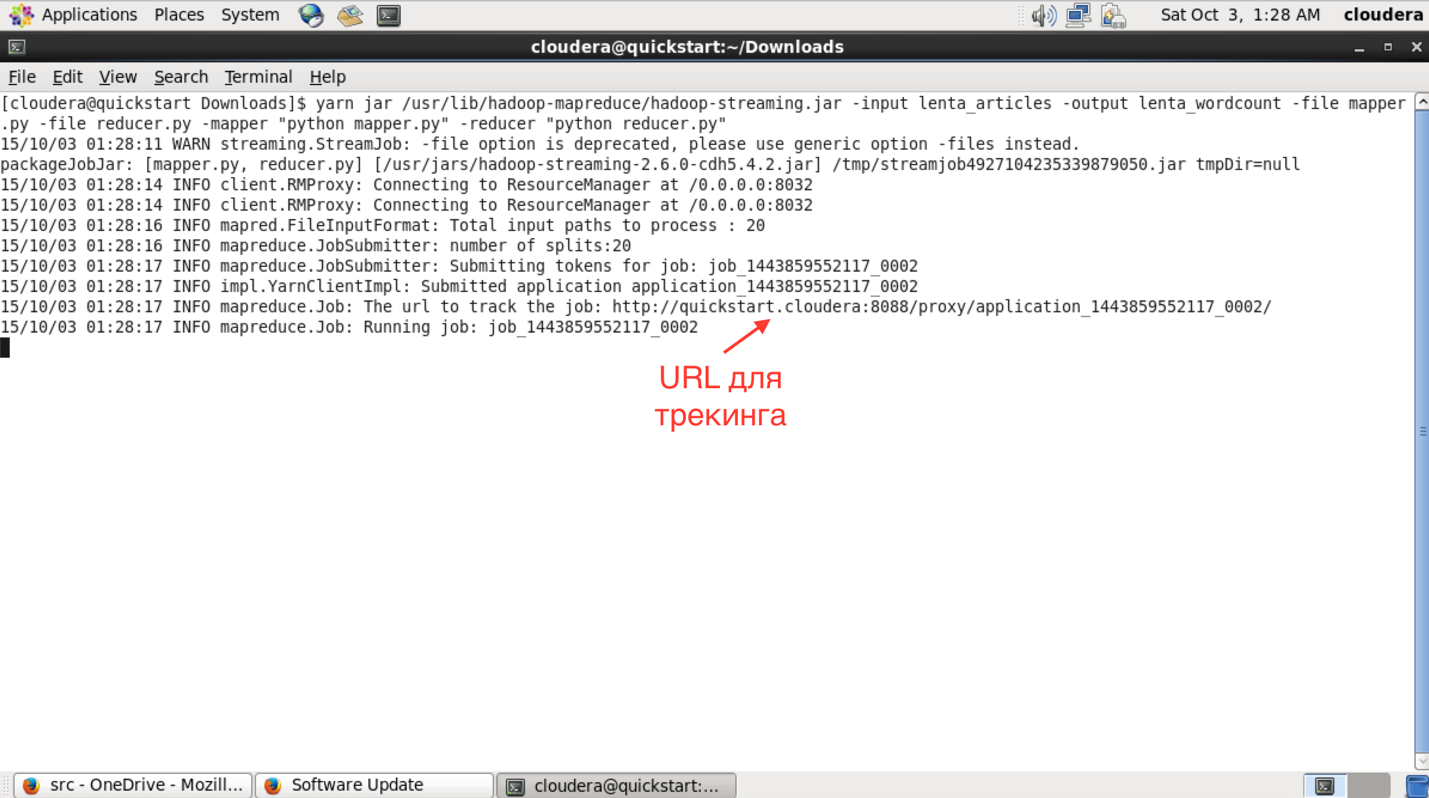
В интерфейсе доступном по этому URL можно узнать более детальный статус выполнения задачи, посмотреть логи каждого маппера и редьюсера (что очень полезно в случае упавших задач).
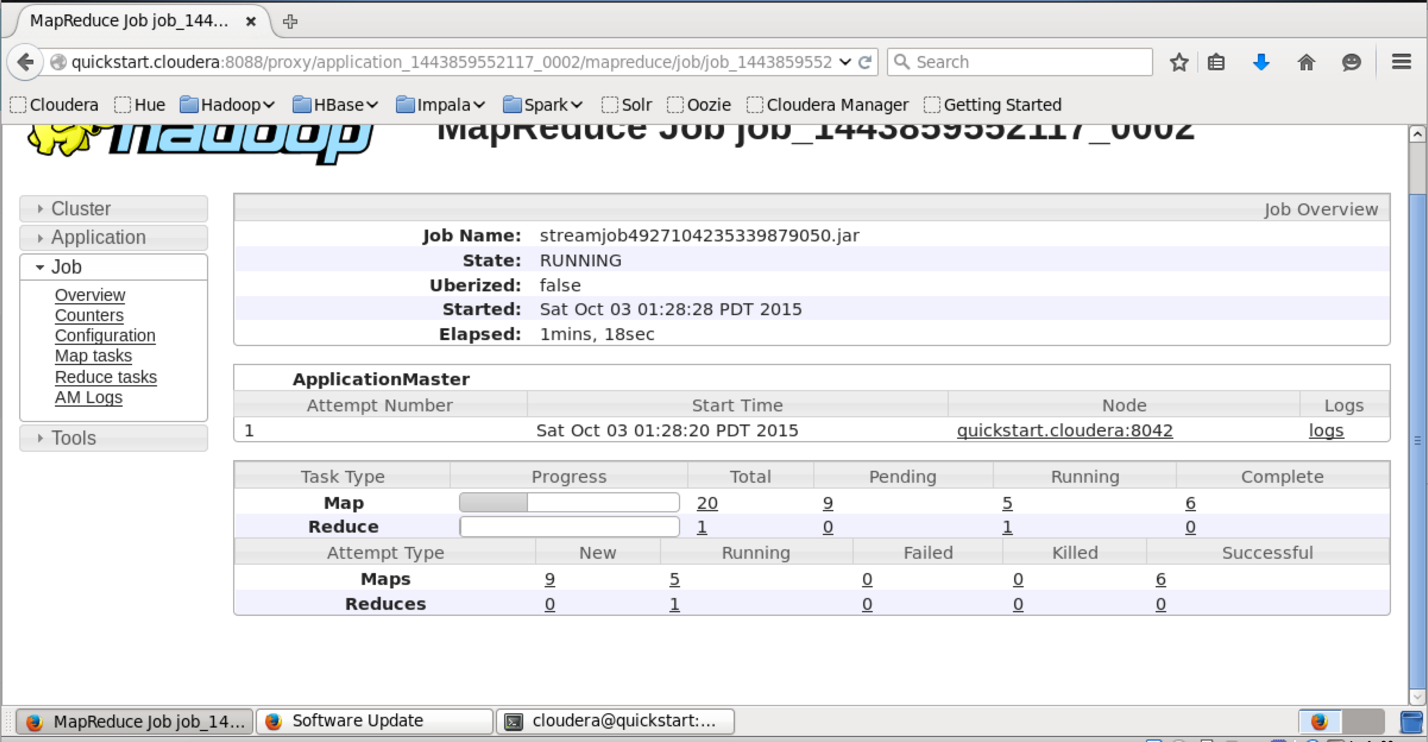
Сам результат можно получить следующим образом:
hadoop fs -text lenta_wordcount/* | sort -n -k2,2 | tail -n5 с 41 что 43 на 82 и 111 в 194
Команда «hadoop fs -text» выдаёт содержимое папки в текстовом виде. Я отсортировал результат по количеству вхождений слов. Как и ожидалось, самые частые слова в языке – предлоги.
Способ №2
Сам по себе hadoop написан на java, и нативный интерфейс у hadoop-a тоже java-based. Покажем, как выглядит нативное java-приложение для wordcount:
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount < public static class TokenizerMapper extends Mapper < private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException < StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) < word.set(itr.nextToken()); context.write(word, one); >> > public static class IntSumReducer extends Reducer < private IntWritable result = new IntWritable(); public void reduce(Text key, Iterablevalues, Context context ) throws IOException, InterruptedException < int sum = 0; for (IntWritable val : values) < sum += val.get(); >result.set(sum); context.write(key, result); > > public static void main(String[] args) throws Exception < Configuration conf = new Configuration(); Job job = Job.getInstance(conf, «word count»); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(«hdfs://localhost/user/cloudera/lenta_articles»)); FileOutputFormat.setOutputPath(job, new Path(«hdfs://localhost/user/cloudera/lenta_wordcount»)); System.exit(job.waitForCompletion(true) ? 0 : 1); >>
Этот класс делает абсолютно то же самое, что наш пример на Python.
Мы создаём классы TokenizerMapper и IntSumReducer, наследуя их от классов Mapper и Reducer соответсвенно. Классы, передаваемые в качестве параметров шаблона, указывают типы входных и выходных значений. Нативный API подразумевает, что функции map на вход подаётся пара ключ-значение. Поскольку в нашем случае ключ пустой – в качестве типа ключа мы определяем просто Object.
В методе Main мы заводим mapreduce-задачу и определяем её параметры – имя, mapper и reducer, путь в HDFS, где находятся входные данные и куда положить результат.
Для компиляции нам потребуются hadoop-овские библиотеки. Я использую для сборки Maven, для которого у cloudera есть репозиторий. Инструкции по его настройке можно найти по ссылке. В итоге файл pom.xmp (который используется maven’ом для описания сборки проекта) у меня получился следующий):
4.0.0 cloudera https://repository.cloudera.com/artifactory/cloudera-repos/ org.apache.hadoop hadoop-common 2.6.0-cdh5.4.2 org.apache.hadoop hadoop-auth 2.6.0-cdh5.4.2 org.apache.hadoop hadoop-hdfs 2.6.0-cdh5.4.2 org.apache.hadoop hadoop-mapreduce-client-app 2.6.0-cdh5.4.2 org.dca.examples wordcount 1.0-SNAPSHOT
Соберём проект в jar-пакет:
mvn clean package
После сборки проекта в jar-файл запуск происходит похожим образом, как и в случае streaming-интерфейса:
yarn jar wordcount-1.0-SNAPSHOT.jar WordCount
Дожидаемся выполнения и проверяем результат:
hadoop fs -text lenta_wordcount/* | sort -n -k2,2 | tail -n5 с 41 что 43 на 82 и 111 в 194
Как нетрудно догадаться, результат выполнения нашего нативного приложения совпадает с результатом streaming-приложения, которое мы запустили предыдущим способом.
Резюме
В статье мы рассмотрели Hadoop – программный стек для работы с большими данными, описали процесс установки Hadoop на примере дистрибутива cloudera, показали, как писать mapreduce-программы, используя streaming-интерфейс и нативный API Hadoop’a.
В следующих статьях цикла мы рассмотрим более детально архитектуру отдельных компонент Hadoop и Hadoop-related ПО, покажем более сложные варианты MapReduce-программ, разберём способы упрощения работы с MapReduce, а также ограничения MapReduce и как эти ограничения обходить.
Спасибо за внимание, готовы ответить на ваши вопросы.
Ссылки на другие статьи цикла:
Источник: habr.com
Hadoop
Hadoop – это свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов. Эта основополагающая технология хранения и обработки больших данных (Big Data) является проектом верхнего уровня фонда Apache Software Foundation.
Из чего состоит Hadoop: концептуальная архитектура
Изначально проект разработан на Java в рамках вычислительной парадигмы MapReduce, когда приложение разделяется на большое количество одинаковых элементарных заданий, которые выполняются на распределенных компьютерах (узлах) кластера и сводятся в единый результат [1].
Проект состоит из основных 4-х модулей:
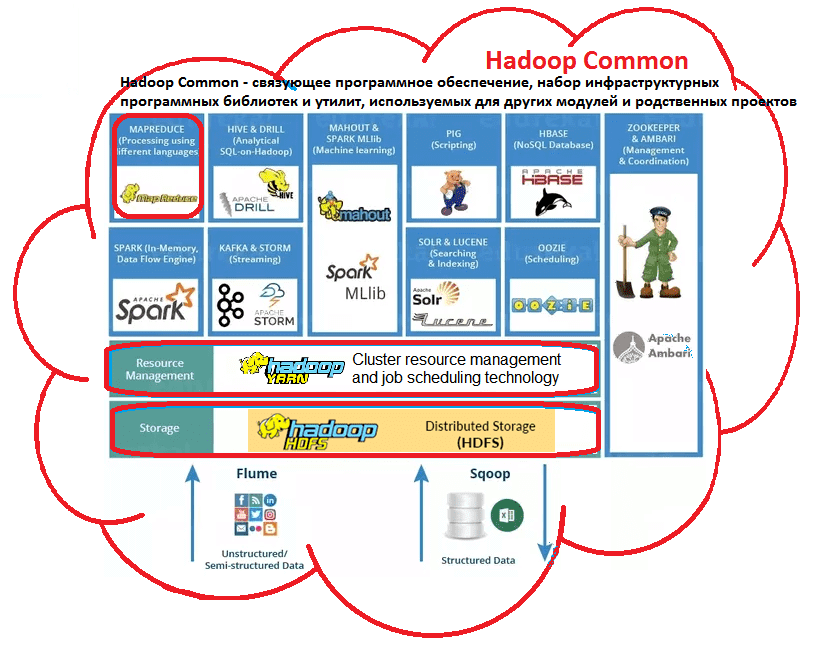
- Hadoop Common – набор инфраструктурных программных библиотек и утилит, которые используются в других решениях и родственных проектах, в частности, для управления распределенными файлами и создания необходимой инфраструктуры [1];
- HDFS– распределённая файловая система, Hadoop Distributed File System – технология хранения файлов на различных серверах данных (узлах, DataNodes), адреса которых находятся на специальном сервере имен (мастере, NameNode) [2]. За счет дублирования (репликации) информационных блоков, HDFS обеспечивает надежное хранение файлов больших размеров, поблочно распределённых между узлами вычислительного кластера [1];
- YARN– система планирования заданий и управления кластером (Yet Another Resource Negotiator), которую также называют MapReduce 2.0 (MRv2) – набор системных программ (демонов), обеспечивающих совместное использование, масштабирование и надежность работы распределенных приложений [3]. Фактически, YARN является интерфейсом между аппаратными ресурсами кластера и приложениями, использующих его мощности для вычислений и обработки данных [1];
- Hadoop MapReduce – платформа программирования и выполнения распределённых MapReduce-вычислений, с использованием большого количества компьютеров (узлов, nodes), образующих кластер.
Сегодня вокруг Hadoop существует целая экосистема связанных проектов и технологий, которые используются для интеллектуального анализа больших данных (Data Mining), в том числе с помощью машинного обучения (Machine Learning) [2].
Как появился хадуп: история разработки и развития
Технология хадуп появилась почти 15 лет назад и постоянно развивается. Далее показаны основные вехи ее истории:
2005 – публикация сотрудников Google Джеффри Дина и Санжая Гемавата о вычислительной концепции MapReduce сподвигла Дуга Каттинга на инициацию проекта. Разработку в режиме частичной занятости вели Дуг Каттинг и Майк Кафарелла, чтобы построить программную инфраструктуру распределённых вычислений для свободной программной поисковой машины на Java. Свое название проект получил в честь игрушечного слонёнка ребёнка основателя [1]. Именно поэтому хадуп неформально называют «железный слон» и изображают его в виде этого животного.
2006 – корпорация Yahoo пригласила Каттинга возглавить специально выделенную команду разработки инфраструктуры распределённых вычислений, благодаря чему Hadoop выделился в отдельный проект [1].
2008 – Yahoo запустила кластерную поисковую машину на 10 тысяч процессорных ядер под управлением Hadoop, который становится проектом верхнего уровня системы проектов Apache Software Foundation. Достигнут мировой рекорд производительности в сортировке данных: за 209 секунд кластер из 910 узлов обработал 1 Тбайт информации. После этого технологию внедряют Last.fm, Facebook, The New York Times, облачные сервисы Amazon EC2 [1].
2010 – корпорация Google предоставила Apache Software Foundation права на использование технологии MapReduce. Hadoop позиционируется как ключевая технология обработки и хранения больших данных (Big Data). Начала формироваться Hadoop-экосистема: возникли продукты Avro, HBase, Hive, Pig, Zookeeper, облегчающие операции управления данными и распределенными приложениями, а также анализ информации [1].
2011 – получение ежегодной инновационной награды медиагруппы Guardian за универсальный подход к хранению и обработке распределенных данных («швейцарский нож XXI века») [1].
2013 – появление модуля YARN в релизе Hadoop 2.0 значительно расширяет парадигму MapReduce, повышая надежность и масштабируемость распределенных систем [3].
Где и зачем используется Hadoop
Выделяют несколько областей применения технологии [4]:

- поисковые и контекстные механизмы высоконагруженных веб-сайтов и интернет-магазинов (Yahoo!, Facebook, Google, Aliexpress, Ebay и т.д.), в т.ч. для аналитики поисковых запросов и пользовательских логов;
- хранение, сортировка огромных объемов данных и разбор содержимого чрезвычайно больших файлов;
- быстрая обработка графических данных, например, газета New York Times с помощью хадуп и Web-сервиса Amazon Elastic Compute Cloud (EC2) всего за 36 часов преобразовала 4 терабайта изображений (TIFF-картинки размером в 405 КБ, SGML-статьи размером в 3.3 МБ и XML-файлы размером в 405 КБ) в PNG-формат размером по 800 КБ.
Все подробности о распределенной обработке данных, администрировании и применении Hadoop для проектов Big Data и Machine Learning на наших компьютерных курсах обучения разных групп пользователей, от «чайников» до профессионалов – хадуп для инженеров, администраторов и аналитиков больших данных в Москве:
- INTR: Основы Hadoop
- HADM: Администрирование кластера Hadoop
- DSEC: Безопасность озера данных Hadoop
- HDDE: Hadoop для инженеров данных
- BAHU: Основы Hadoop для пользователей
Источники
- https://ru.wikipedia.org/wiki/Hadoop
- https://m.habr.com/ru/post/240405/
- https://www.ibm.com/developerworks/ru/library/bd-hadoopyarn/index.html
- https://www.ibm.com/developerworks/ru/library/l-hadoop/index.html
Источник: www.bigdataschool.ru
Из чего состоит Hadoop: концептуальная архитектура
Hadoop – это свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов. Эта основополагающая технология хранения и обработки больших данных (Big Data) является проектом верхнего уровня фонда Apache Software Foundation.
ИЗ ЧЕГО СОСТОИТ HADOOP: КОНЦЕПТУАЛЬНАЯ АРХИТЕКТУРА
Изначально проект разработан на Java в рамках вычислительной парадигмы MapReduce, когда приложение разделяется на большое количество одинаковых элементарных заданий, которые выполняются на распределенных компьютерах (узлах) кластера и сводятся в единый результат.
Проект состоит из основных 4-х модулей:
- Hadoop Common – набор инфраструктурных программных библиотек и утилит, которые используются в других решениях и родственных проектах, в частности, для управления распределенными файлами и создания необходимой инфраструктуры;
- HDFS – распределённая файловая система, Hadoop Distributed File System – технология хранения файлов на различных серверах данных (узлах, DataNodes), адреса которых находятся на специальном сервере имен (мастере, NameNode). За счет дублирования (репликации) информационных блоков, HDFS обеспечивает надежное хранение файлов больших размеров, поблочно распределённых между узлами вычислительного кластера;
- YARN – система планирования заданий и управления кластером (Yet Another Resource Negotiator), которую также называют MapReduce 2.0 (MRv2) – набор системных программ (демонов), обеспечивающих совместное использование, масштабирование и надежность работы распределенных приложений. Фактически, YARN является интерфейсом между аппаратными ресурсами кластера и приложениями, использующих его мощности для вычислений и обработки данных;
- Hadoop MapReduce – платформа программирования и выполнения распределённых MapReduce-вычислений, с использованием большого количества компьютеров (узлов, nodes), образующих кластер.

Архитектурная концепция экосистемы Hadoop
Сегодня вокруг Hadoop существует целая экосистема связанных проектов и технологий, которые используются для интеллектуального анализа больших данных (Data Mining), в том числе с помощью машинного обучения (Machine Learning).
КАК ПОЯВИЛСЯ ХАДУП: ИСТОРИЯ РАЗРАБОТКИ И РАЗВИТИЯ
Технология хадуп появилась почти 15 лет назад и постоянно развивается. Далее показаны основные вехи ее истории:
2005 – публикация сотрудников Google Джеффри Дина и Санжая Гемавата о вычислительной концепции MapReduce сподвигла Дуга Каттинга на инициацию проекта. Разработку в режиме частичной занятости вели Дуг Каттинг и Майк Кафарелла, чтобы построить программную инфраструктуру распределённых вычислений для свободной программной поисковой машины на Java. Свое название проект получил в честь игрушечного слонёнка ребёнка основателя. Именно поэтому хадуп неформально называют “железный слон” и изображают его в виде этого животного.
2006 – корпорация Yahoo пригласила Каттинга возглавить специально выделенную команду разработки инфраструктуры распределённых вычислений, благодаря чему Hadoop выделился в отдельный проект.
2008 – Yahoo запустила кластерную поисковую машину на 10 тысяч процессорных ядер под управлением Hadoop, который становится проектом верхнего уровня системы проектов Apache Software Foundation. Достигнут мировой рекорд производительности в сортировке данных: за 209 секунд кластер из 910 узлов обработал 1 Тбайт информации. После этого технологию внедряют Last.fm, Facebook, The New York Times, облачные сервисы Amazon EC2.
2010 – корпорация Google предоставила Apache Software Foundation права на использование технологии MapReduce. Hadoop позиционируется как ключевая технология обработки и хранения больших данных (Big Data). Начала формироваться Hadoop-экосистема: возникли продукты Avro, HBase, Hive, Pig, Zookeeper, облегчающие операции управления данными и распределенными приложениями, а также анализ информации.
2011 – получение ежегодной инновационной награды медиагруппы Guardian за универсальный подход к хранению и обработке распределенных данных («швейцарский нож XXI века»).
2013 – появление модуля YARN в релизе Hadoop 2.0 значительно расширяет парадигму MapReduce, повышая надежность и масштабируемость распределенных систем.
ГДЕ И ЗАЧЕМ ИСПОЛЬЗУЕТСЯ HADOOP
Выделяют несколько областей применения технологии:
- поисковые и контекстные механизмы высоконагруженных веб-сайтов и интернет-магазинов (Yahoo!, Facebook, Google, Aliexpress, Ebay и т.д.), в т.ч. для аналитики поисковых запросов и пользовательских логов;
- хранение, сортировка огромных объемов данных и разбор содержимого чрезвычайно больших файлов;
- быстрая обработка графических данных, например, газета New York Times с помощью хадуп и Web-сервиса Amazon Elastic Compute Cloud (EC2) всего за 36 часов преобразовала 4 терабайта изображений (TIFF-картинки размером в 405 КБ, SGML-статьи размером в 3.3 МБ и XML-файлы размером в 405 КБ) в PNG-формат размером по 800 КБ.

“Железный слон” и технологии Big Data
Источник: biconsult.ru