
Так уж случилось, что я оказался ассистентом у профессора в университете. Никогда не думал, что прийдётся сталкиваться с оценкой рисков и визуализацией данных, будучи, по призванию, криптографом. Курс называется «Информационные сети» и включает в себя: анализ случайных процессов, моделирование малых миров; компьютерные алгоритмы для оценки свойств сети; экспериментальные исследования крупных сетей, а также анализ рисков, которые трудно предсказать.
В виду того, что курс читается в основном для ИТ-шников, лектор сделал ставку на то, чтобы дать достаточно теории с минимумом математики и большим количеством практики. Для большинства вышеупомянутых задач подходит программа NetLogo. Она включает собственный язык программирования высокого уровня, который позволяет с лёгкостью моделировать различные случайные процессы. Для визуализации разнообразных данных была выбрана программа Gephi.
На основе опыта использования последней и была написана статья, в которой рассматривается получение входных данных для ПО с последующей их визуализацией.
Семинар ANR-Lab «Визуализация сетевых данных в Gephi»
Собственно постановка задачи была таковой: визуализация каких-либо реальных данных средствами Gephi.
Генерация данных
После некоторых размышлений решил представить взаимодействия авторов с сайта IACR . Кто работает в области защиты информации наверняка знают про него, для всех остальных — это сайт, где в открытом доступе представлены статьи по информационной безопасности.
Форматы файлов Gephi
Gephi понимает достаточно большое количество форматов файлов.

Как видно из рисунка, самый лучший вариант — использовать gexf. Как оказалось, это открытый формат и библиотеку с лёгкостью можно скачать с отсюда. На сайте пишется, что Libgexf в настоящее время работает только на Linux (проверено в Ubuntu 8.10 и 9.04). Не долго думая, решил скачать исходники и скомпилировать под Ubuntu 11.10 с интерфейсами для Python (так как остальную часть решил реализовывать на нём).
Сгенерировал тестовый файл и решил запустить в Gephi, но с ее помощью не открылись ни мой файл, ни скачанные из интернета, ни даже тот, который сама сохранила. Не знаю что за баг, но, поковыряв немного и попробовав на двух машинах, решил от этой затеи отказаться и искать альтернативу. После того, как поигрался с CSV и понял, что его функционала мало, наткнулся на импорт из БД.
- обязательно:
- id — номер вершины
- необязательно:
- label — пометка или обозначение вершины
- x — координата x на плоскости, где будет расположена вершина графа
- y — координата y на плоскости, где будет расположена вершина графа
- size — размер вершины
- обязательные:
- source — id начальной вершины
- target — id конечной вершины
- необязательные:
- label — пометка или обозначение ребра
- weight — вес ребра
Gephi создание графа
Скрипт заполнения БД на Python
- Загружать данные об авторах статьи
- Разделить данные об авторах на отдельные ФИО
- Заполнять БД в соответствии с предыдущим пунктом
Приведу лишь некоторые комментарии. В качестве БД использовалась sqlite3, интерфейс поддержка которой присутствует в python. Таблицы и колонки созданы в соответствии с описанием в разделе «Форматы файлов». «httр://eprint.iacr.org/cgi-bin/cite.pl?entry=year/number» использовалась в качестве исходной ссылки, где year — год публикации, number — номер статьи.
Изначально предполагалось, что нужно перебирать с 001 до последнего, который определяется по отсутствию слова «author». Однако, потом выяснилось, что не все номера статей присутствуют (например, нет 001 в 2004 году). Поэтому пришлось нагородить велосипед на проверку 3-х подряд не найденных авторов. Ещё одних подвох ждал при получении ФИО. Строки авторов могут иметь вид:
«»
«»
«ша Попович>»
«»
«»
Кто подскажет как быстро из строк получить ФИО, буду благодарен. На выходе должно быть [‘Елена Прекрасная’,’Тугарин Змей’,’Алёша Попович’] (без пробелов и запятых, т.е. просто имя и фамилия через пробел).
Ну и напоследок, чтобы не мучить интернет, я решил сначала создать локальный дамп авторов, а потом его использовать в качестве входных данных. Для этого я использовал pickle, который позволяет делать дамп переменных в файл, а после, в случае необходимости, извлекать. Для этого я создал словарь (dictionary). В качестве ключей выступали года, а значения — массив строк с авторами. Таким образом, я могу создавать БД по интересующим меня годам, используя лишь локальный файл.
Визуализация данных при помощи Gephi
В качестве примера возьмем маленький граф: года с 1996 по 2003. Он состоит из 759 вершин и 437 рёбер. Эту информацию можно увидеть при импортировании графа:
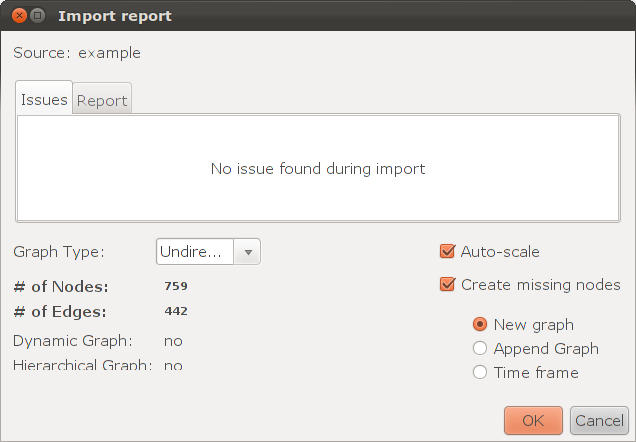
или в окне «Context».
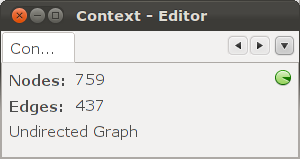
Дополнительно, при импортировании можно выбрать ориентацию графа: ориентированный, неориентированный или смешанный.
Далее выберем окно «Ranking» для начального редактирования графа. В зависимости от степени, раскрасим все вершины в оттенки синего цвета и зададим размер самой вершины. Рекомендую задавать максимальный размер вершины, равный максимальной степени вершины или в 2 раза больше.
В конечном итоге получилось вот это:
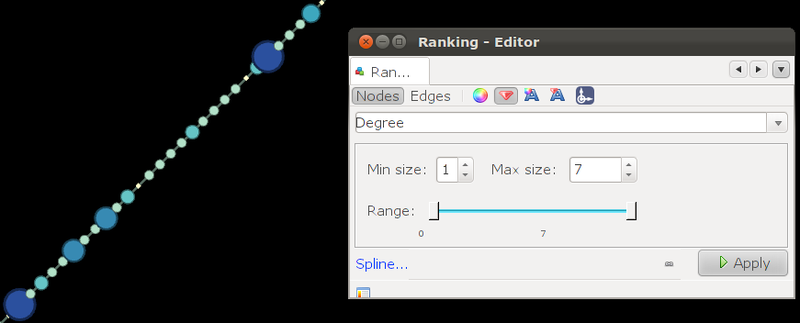
Теперь, чтобы красиво всё представить, выберем окно «Layout». В этом окне представлены алгоритмы, которые можно использовать для упорядочивания графа.
Далее приводятся скриншоты некоторых из них.


Parallel Force Atlas

Ещё вершины можно прикрепить к одной из осей, однако это выбирается в окне «Ranking» -> «Coordinates»
На графе можно выбрать вывод поля «label». Например:

Выводы
Gephi является хоть и молодым, но очень мощным средством визуализации различных данных, который подойдет как новичку, так и опытному пользователю. Использование баз данных позволяет быстро и легко получить необходимые входные данные для визуализации.
Источник: habr.com
Визуализация на Gephi

Knowledge Graph или Граф знаний — база знаний, которая построена на основе семантических связей. Один из инструментов визуализации KG является Gephi. Что такое Gephi и для чего он нужен, подробно рассказано в статье «Графовые методы анализа в gephi».

- Как изменить размер и цвет вершин и ребер?
- Как установить название вершин и ребер?
- Как отфильтровать данные?
Начнем с описания данных для построения и анализа графа. Для загрузки в gephi нам необходимо два файла – nodes и edges. Файлы, которые я использую для построения в этой статье:
Файл «nodes_st» содержит уникальные значения вершин и их «айдишники». Дополнительно значения из label я разбила на группы (проект, сотрудник, отдел, тема проекта) и записала в столбец «group» (это позволит в дальнейшем настроить цветовые схемы вершин).

Файл «edges_st» содержит все возможные переходы из одной вершины в другую. В моем файле есть три поля source, target и name_edges. Обязательными являются только source и target, поле name_edges сформировано самостоятельно, чтобы можно было добавить подписи на ребрах.

При загрузке данных не забываем выбирать тип графа (ориентированный, неориентированный и смешанный) и ставить отметку «Append to existing workspace», чтобы загрузка происходила в одну рабочую область.

1 Размер и цветовая схема ребер и вершин. Размер и цветовая схема ребер и вершин
Данные загружены, можно перейти к блоку «Укладка» (Layout). Выбираем укладку в соответствии с топологией, которую вы хотите выделить.
К примеру, ForceAtlas, ForceAtlas2, Yifan Hu отлично подойдут, чтобы показать разбиение на классы/группы, можно настраивать силы отталкивания и притяжения вершин. С другими алгоритмами можно ознакомиться в Интернете.
После «заливки» данных мы получили граф, разбитый на кластеры. В нашем случае вершины — сотрудники сгруппировались вокруг вершин-отделов. Укладка выбрана ForceAtlas, сила отталкивания- 1000.

Скорректируем размеры вершин. Для этого в блоке Appearance (вкладка nodes) выбираем размер – Ranking. Из выпадающего списка – Degree, устанавливаем размеры вершин от наименее часто встречающей (min size) до самой популярной вершины (max size). В моем случае размер установлен от 10 до 50.

Фрагмент полученного графа представлен ниже.

Блок Appearance позволяет настроить цвет узлов и ребер. Рассмотрим на примере узлов (nodes). Развернув палитру, выбираем тип окрашивания:
Unique – монохромное окрашивание.
Partition – может быть более двух цветов, все зависит от количества групп/классов, на которые вы разбили вершины. Ranking – создает плавный цветовой переход от наименее часто встречающихся до популярных вершин.

На рисунке ниже представлено окрашивание Partition по полю group (данное поле сформировано вручную)

Теперь нам осталось подписать и отфильтровать данные. Переходим к пункту 2.
2 Название вершин и ребер на графе
Раскрываем панель, расположенную под графом

Устанавливаем галки «Узел» и «Ребро», настраиваем шрифт и размер. Размер текста относительно вершин настраивается ползунком.

Также эта панель позволяет менять цвет фона (вкладка global), убирать ребра и изменять их размер (вкладка Ребра).

3 Фильтрация данных
Рассмотри фильтрацию на примерах.
Кейс 1. Нас интересуют все проекты с темой 48. Перетаскиваем Ego Network (из папки Топология) в окно ниже «Наборы фильтров. Устанавливаем значение «ID узла» равное «тема 48» и фильтруем. Если нам интересно посмотреть какие сотрудники участвовали в этих проектах, то увеличиваем глубину до 2.

Кейс 2. Показать темы проектов, которыми занимались сотрудники отдела3 Для начала отфильтруем данные по отделу 3 и расширим глубину до 3, чтобы захватить названия тем (глубина 1 –сотрудники, глубина 2 – проекты, глубина 3 – тема проекта).

Так как нас интересуют только темы проектов, оставим только нужные нам вершины. Добавляем в набор фильтров оператор AND и Атрибут group (сформирован из поля label) по значению. Указываем в параметрах атрибута «тема_проекта». Наш новый граф готов.


Основные возможности инструмента Gephi рассмотрены, из серой «скучной» массы, мы получили читаемый граф для анализа с возможностью фильтрации и визуализации.
Источник: newtechaudit.ru