
В настоящее время язык программирования Python является ведущим из-за его удобных функций. Python также имеет много интересных модулей и библиотек, с помощью которых пользователи могут многое сделать, используя их. Одна из самых интересных особенностей языка Python – это его аудиомодули.
В этой статье мы обсудим 10 различных типов аудиомодулей и библиотек на Python для воспроизведения и записи звука, их уникальные особенности и преимущества.
- PYO
- PyAudio
- Dejavu
- Mingus
- hYPerSonic
- Pydub
- simpleaudio
- winsound
- python – sounddevice
- playsound
Давайте разберемся с вышеуказанными аудиомодулями по очереди.
1. Аудиомодуль PYO
PYO – это модуль Python, написанный на языке программирования C для создания сценария цифровой обработки сигналов. Этот модуль Python содержит классы для обработки самых разных типов аудиосигналов. Благодаря этому пользователи могут импортировать цепочки обработки сигналов непосредственно в сценарии или проекты Python и могут манипулировать звуковыми сигналами в реальном времени с помощью интерпретатора.
Как Сделать Идеальный Звук В Видео? | Nvidia RTX Voice БЕЗ RTX | Как Убрать Шум Микрофона
Инструмент модулей PYO в Python имеет примитивы, такие как математические операции, базовую обработку сигналов: задержки, генераторы синтеза, фильтры и многое другое. Но он также объединяет алгоритмы для создания звуковой грануляции и многих других художественных звуковых операций.
# to play a sound file: from pyo import * sound = Server( ) .boot( ) sound.start ( ) sound_file = SFPlayer( » path /to /users /sound.aif «, speed = 1, loop = True ).out( ) # for Granulating an audio buffer: sound = Server( ) .boot( ) sound_nd = SndTable( » path /to /users /sound.aif » ) ev = HannTable( ) ps = Phasor( freq = sound_nd.getRate( )*.25, ml = sound_nd.getSize( ) ) dr = Noise( mul = .001, add = .1 ) granulate = Granulator( sound_nd, ev, [ 1, 1.001 ] , ps, dr, 32, ml = .1 ).out( ) # to generate melodies: sound = Server( ) .boot( ) sound.start( ) wv = SquareTable( ) ev = CosTable( [( 0, 0 ) ,( 100 , 1 ) ,( 500 , 0.3 ) ,( 8391 , 0 ) ] ) mt = Metro( 0.135 , 12 ).play( ) ap = TrigEnv( mt , table = ev , dr = 1 , ml = .1 ) pt = TrigXnoiseMidi( mt , dist = ‘ loopseg ‘ , x1 = 20 , scale = 1 , mrange =( 47, 74 ) ) out = Osc( table = wav , freq = pt , ml = ap ).out( )
2. Кроссплатформенный аудиовход – вывод с pyAudio
Pyaudio – это библиотека Python, которая представляет собой кроссплатформенный аудиовход – вывод с открытым исходным кодом. Он имеет широкий спектр функций, связанных со звуком и в основном ориентированных на сегментацию, извлечение функций, классификацию и визуализацию.
Используя библиотеку pyaudio, пользователи могут классифицировать неизвестные звуки, выполнять контролируемую и неконтролируемую сегментацию, извлекать звуковые функции и представления, обнаруживать звуковые события и отфильтровывать периоды тишины из длинных записей, применять уменьшение размерности для визуализации аудиоданных и сходства контента и многое другое.
How to get sound back on a computer if it’s gone
Эта библиотека предоставляет привязки для PortAudio. Пользователи могут использовать эту библиотеку для воспроизведения и записи звука на разных платформах, таких как Windows, Mac и Linux. Для воспроизведения звука с помощью библиотеки pyaudio пользователь должен писать в .stream.
import pyaudio import wave filename = ‘ example.wav ‘ # Set chunk size of 1024 samples per data frame chunksize = 1024 # Now open the sound file, name as wavefile wavefile = wave.open( filename, ‘ rb ‘ ) # Create an interface to PortAudio portaudio = pyaudio.PyAudio( ) # Open a .Stream object to write the WAV file to play the audio using pyaudio # in this code, ‘output = True’ means that the audio will be played rather than recorded streamobject = portaudio.open(format = portaudio.get_format_from_width( wavefile.getsampwidth( ) ), channels = wavefile.getnchannels( ), rate = wavefile.getframerate( ), output = True( ) # Read data in chunksize Data_audio = wavefile.readframes( chunksize ) # Play the audio by writing the audio data to the streamobject while data != »: streamobject.write( data_audio ) data_audio = wavefile.readframes( chunksize ) # Close and terminate the streamobject streamobject.close( ) portaudio.terminate( )
Здесь пользователи могут заметить, что воспроизведение звука с использованием библиотеки pyaudio может быть немного сложнее по сравнению с другими библиотеками воспроизведения звука. Вот почему эта библиотека может быть не лучшим выбором пользователей для воспроизведения звука в своих проектах или приложениях.
Хотя библиотека pyaudio обеспечивает более низкоуровневое управление, что позволяет пользователям устанавливать параметры для своих устройств ввода и вывода. Эта библиотека также позволяет пользователям проверять загрузку своего процессора и активность ввода-вывода.
Библиотека Pyaudio также позволяет пользователям воспроизводить и записывать звук в режиме обратного вызова, где указанная функция обратного вызова вызывается, когда новые данные необходимы для воспроизведения и доступны для записи. Это особенности библиотеки pyaudio, которые отличают ее от других аудиобиблиотек и модулей. Эта библиотека специально используется, если пользователь хочет воспроизвести звук помимо простого воспроизведения.
3. Dejavu
Dejavu – это аудиомодуль на Python с открытым исходным кодом. Он может запоминать записанный звук, прослушивая его один раз, и этот звук сохраняется в базе данных. После этого, когда проигрывается песня, микрофонный вход или дисковый файл, Dejavu пытается сопоставить звук с сохраненными в базе данными, и вернуть песню или запись, которая была воспроизведена ранее.
Модуль Dejavu превосходит распознавание отдельных сигналов с реалистичным количеством шума. Есть две формы, в которых пользователь может использовать Дежавю для распознавания звука:
- Пользователь может распознавать аудио, читая и обрабатывая аудиофайлы на диске.
- Пользователь может использовать микрофон компьютера.
Например:
#User should create a MySQL database where Dejavu can store fingerprints of the audio.
#on user local setup:
$ mysql -u root -p
Enter password: *************
mysql> HERE, USER SHOULD CREATE A DATABASE dejavu;
Готово.
from dejavu import Dejavu config = < » database «: < » host «: » 125.0.1.1 «, » user «: » root «, » password «: < password imported in Local setup >, » database «: < name of the database user has created in local setup >, > > dejv = Dejavu( config )
4. Mingus
Mingus – это пакет на Python. Его используют многие программисты, исследователи музыкантов и композиторы для создания и изучения музыки и песен.
Этот пакет является кроссплатформенным и представляет собой очень продвинутую теорию музыки, представляющую пакет для Python вместе с файлами цифрового интерфейса музыкальных инструментов и поддержкой воспроизведения.
Пакет Mingus можно использовать для образовательных инструментов, для создания редакторов для песен, а также во многих других приложениях и программах, в которые пользователи хотят импортировать функцию обработки и воспроизведения музыки.
Этот пакет представляет собой теорию музыки и включает в себя такие темы, как гаммы, прогрессии, аккорды и интервалы. Mingus тестирует эти компоненты и использует для создания и распознавания музыкальных элементов с помощью удобных сокращений.
import mingus.core.notes as notes_m # for valid notes notes_m.is_valid_note(«C») notes_m.is_valid_note(«D#») notes_m.is_valid_note(«Eb») notes_m.is_valid_note(«Fbb») notes_m.is_valid_note(«G##»)
True True True True True
# для недействительных заметок:
notes_m.is_valid_note(«c») notes_m.is_valid_note(«D #») notes_m.is_valid_note(«E-b»)
False False False
5. hYPerSonic
hYPerSonic – это фреймворк на языках Python и C. Используется для разработки и эксплуатации конвейеров обработки звука, предназначенных для управления в реальном времени.
Эта структура является низкоуровневой, в которой подсчитывается каждый байт, и это также включает объекты для звуковой карты, фильтрует операции с памятью, file – io и осцилляторы. Эта структура работает в операционных системах Linux и OSX.
6. Pydub
Pydub – это библиотека Python, используемая для управления аудио и добавления к нему эффектов. Эта библиотека представляет собой очень простой и легкий, но высокоуровневый интерфейс, основанный на FFmpeg и склонный к jquery. Эта библиотека используется для добавления тегов id3 в аудио, нарезки его и объединения аудиодорожек. Библиотека Pydub поддерживает версии Python 2.6, 2.7, 3.2 и 3.3.
Однако пользователи могут открывать и сохранять файл WAV с помощью библиотеки pydub без каких-либо зависимостей. Но пользователям необходимо установить пакет для воспроизведения звука, если они хотят воспроизводить звук.
Следующий код можно использовать для воспроизведения файла WAV с помощью pydub:
from pydub import AudioSegment from pydub.playback import play sound_audio = AudioSegment.from_wav( ‘ example.wav ‘ ) play( sound_audio )
Если пользователь хочет воспроизводить другие форматы аудиофайлов, такие как файлы MP3, им следует установить libav или FFmpeg.
После установки FFmpeg пользователю необходимо внести небольшое изменение в код для воспроизведения файла MP3.
from pydub import AudioSegment from pydub.playback import play sound_audio = AudioSegment.from_mp3( ‘example.mp3 ‘ ) play( sound_audio )
Используя оператор AudioSegment.from_file(имя_файла, тип_файла), пользователи могут воспроизводить любой формат аудиофайла, поддерживаемый ffmpeg.
# Users can play a WMA file: sound = AudioSegment.from_file( ‘example.wma ‘, ‘ wma ‘ )
Библиотека Pydub также позволяет пользователям сохранять аудио в различных форматах файлов. Пользователи также могут рассчитать длину аудиофайлов, использовать кроссфейды в аудио с помощью этой библиотеки.
7. Simpleaudio
Simpleaudio – это кроссплатформенная библиотека. Также используется для воспроизведения файлов WAV без каких-либо зависимостей. Библиотека simpleaudio ожидает, пока файл закончит воспроизведение звука в формате WAV, перед завершением скрипта.
import simpleaudio as simple_audio filename = ‘ example.wav ‘ wave_object = simple_audio.WaveObject.from_wave_file( filename ) play_object = wave_object.play( ) play_object.wait_done( ) # Wait until audio has finished playing
В файле формата WAV сохраняется категоризация битов, которая представляет необработанные аудиоданные, а также хранятся заголовки вместе с метаданными в формате файла обмена ресурсами.
Окончательная запись состоит в том, чтобы сохранять каждый аудиосэмпл, который представляет собой конкретную точку данных, относящуюся к давлению воздуха, как при 44200 выборок в секунду, 16-битное значение для записей компакт-дисков.
Для уменьшения размера файла этого достаточно для хранения нескольких записей, таких как человеческая речь, с более низкой частотой дискретизации, например 8000 выборок в секунду. Однако более высокие звуковые частоты не могут быть представлены достаточно точно.
Некоторые из библиотек и модулей, обсуждаемых в этой статье, воспроизводят и записывают байтовые объекты, а некоторые из них используют массивы NumPy для записи необработанных аудиоданных. Оба напоминают категоризацию точек данных, которые можно воспроизводить с определенной частотой дискретизации для воспроизведения звука.
В массиве NumPy каждый элемент может содержать 16-битное значение, эквивалентное отдельной выборке, а для объекта bytes каждая выборка сохраняется как набор из двух 8-битных значений. Важное различие между этими двумя типами данных заключается в том, что массивы NumPy изменяемы, а объекты байтов неизменны, что делает последние более подходящими для генерации аудио и обработки более сложных сигналов.
Пользователи могут воспроизводить массивы NumPy и байтовые объекты в библиотеке simpleaudio с помощью оператора simpleaudio.play_buffer(). Но перед этим пользователи должны убедиться, что они уже установили библиотеки NumPy и simpleaudio.
Пример: сгенерировать массив Numpy, соответствующий тону 410 Гц.
import numpy as numpy import simpleaudio as simple_audio frequency = 410 # user’s played note will be 410 Hz fsample = 44200 # 44200 samples per second will be played second = 5 # Note duration of 5 seconds # Generate array with second*sample_rate steps, ranging between 0 and seconds tp = numpy.linspace( 0 , second , second * fsample, False ) # to generate a 410 Hz sine wave note = numpy.sin( frequency * tp * 2 * numpy.pi ) # user should Ensure that highest value is in 16-bit range audio = note *(2**15 — 1) / numpy.max( numpy.abs( note ) ) # now, Convert to 16-bit data ado = audio.astype( numpy.int16 ) # to Start the playback play_object = simple_audio.play_buffer( ado , 1 , 2 , fsample ) # user now Waits for playback to finish before exiting play_object.wait_done( )
8. winsound
winsound – это модуль в Python, который используется для доступа к основному механизму воспроизведения звука операционной системы Windows.
В модуле winsound файл WAV можно воспроизвести с помощью всего нескольких строк кода.
import winsound filename = ‘ example.wav ‘ winsound.PlaySound( filename, winsound.SND_FILENAME )
Модуль winsound не поддерживает никаких форматов файлов, кроме файлов WAV. Это позволяет пользователям подавать звуковой сигнал своим динамикам, используя выражение winsound.Beep(частота, продолжительность).
# User can beep a 1010 Hz tone for 110 milliseconds: import winsound winsound.Beep( 1010, 110 ) # Beep at 1010 Hz for 110 milliseconds
9. python-sounddevice
python – sounddevice – это модуль python для кроссплатформенного воспроизведения звука. Этот модуль предоставляет привязки для библиотеки PortAudio и имеет некоторые подходящие функции для воспроизведения и записи массивов NumPy, содержащих аудиосигналы.
Если пользователь хочет воспроизвести файл WAV, он должен установить NumPy и звуковой файл, чтобы открыть формат аудиофайла в файлах WAV в виде массивов NumPy.
import sounddevice as sound_device import soundfile as sound_file filename = ‘ example.wav ‘ # now, Extract the data and sampling rate from file data_set, fsample = sound_file.read( filename , dtype = ‘ float32 ‘ ) sound_device.play( data_set, fsample ) # Wait until file is done playing status = sound_device.wait( )
Оператор sound_file.read() используется для извлечения необработанных аудиоданных, а также частоты дискретизации файла, которые хранятся в заголовке формата файла обмена ресурсами. Оператор sound_device.wait() используется для того, чтобы убедиться, что сценарий завершается только после завершения воспроизведения звука.
10. playsound
playsound – это модуль Python, с помощью которого пользователи могут воспроизводить звук в одной строке кода. Это кроссплатформенный модуль, который представляет собой единую функцию без каких-либо зависимостей для воспроизведения звуков и аудио.
from playsound import playsound playsound( ‘ example.wav ‘ )
Модуль playsound используется для файлов, отформатированных в файл WAV и файл MP3, а также может работать с другими форматами файлов.
Заключение:
В этой статье мы обсудили различные типы библиотеки Python и модулей, которые используются для воспроизведения и записи различных типов аудиофайлов и звуков. Здесь мы объяснили различные функции и важность каждой библиотеки и модулей для воспроизведения звуков в проекте разработки и модификации приложений и программного обеспечения.
Источник: pythonpip.ru
Управляем звуком ПК от активности пользователя с помощью Python
Без промедления начнём. Нам нужно установить следующее ПО:
- Windows 10
- Anaconda 3 (Python 3.8)
- Visual Studio 2019 (Community) — объясню позже, зачем она понадобится.
Открываем Anaconda Prompt (Anaconda3) и устанавливаем следующие пакеты:
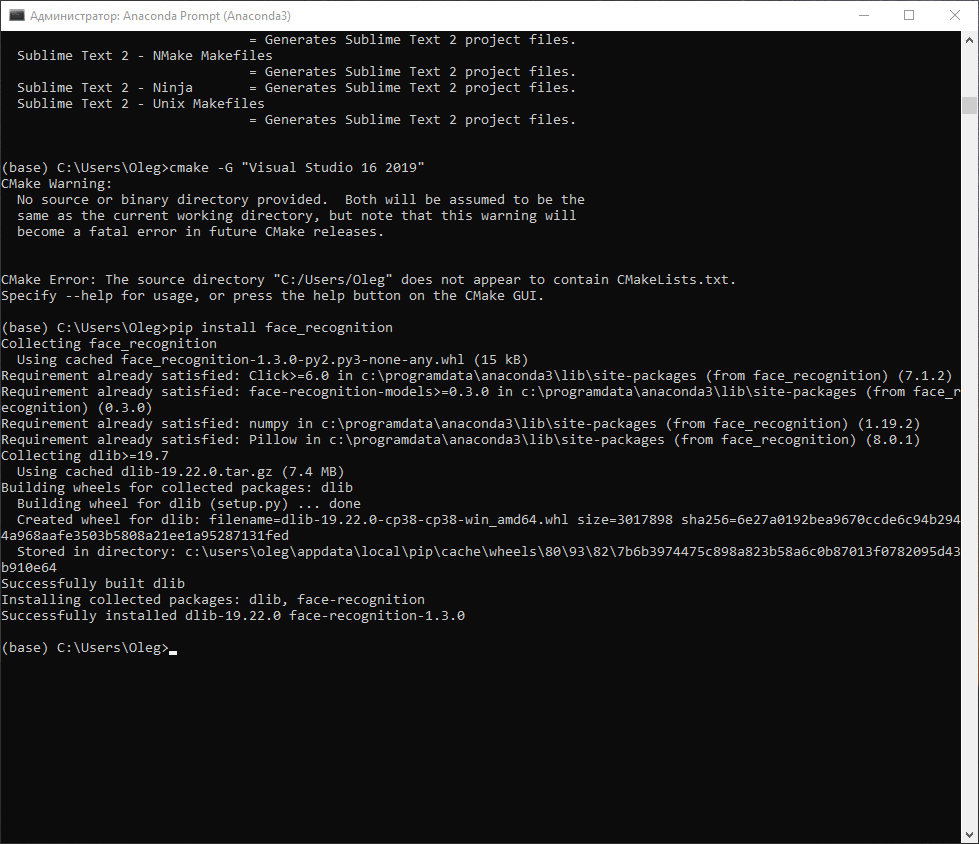
pip install opencv-python pip install dlib pip install face_recognition
И уже на этом моменте начнутся проблемы с dlib.
Решаем проблему с dlib
Я перепробовал все решения, что нашёл в интернете и они оказались неактуальными — раз, два, три, официальное руководство и видео есть. Поэтому будем собирать пакет вручную.
Итак, первая же ошибка говорит о том, что у нас не установлен cmake.
ERROR: CMake must be installed to build dlib

Не закрывая консоль, вводим следующую команду:
pip install cmake
Проблем при установке быть не должно

Пробуем установить пакет той же командой (pip install dlib) , но на этот раз получаем новую ошибку:
Отсутствуют элементы Visual Studio

Ошибка явно указывает, что у меня, скорее всего, стоит студия с элементами только для C# — и она оказывается права. Открываем Visual Studio Installer, выбираем «Изменить», в вкладке «Рабочие нагрузки» в разделе «Классические и мобильные приложения» выбираем пункт «Разработка классических приложений на С++»:

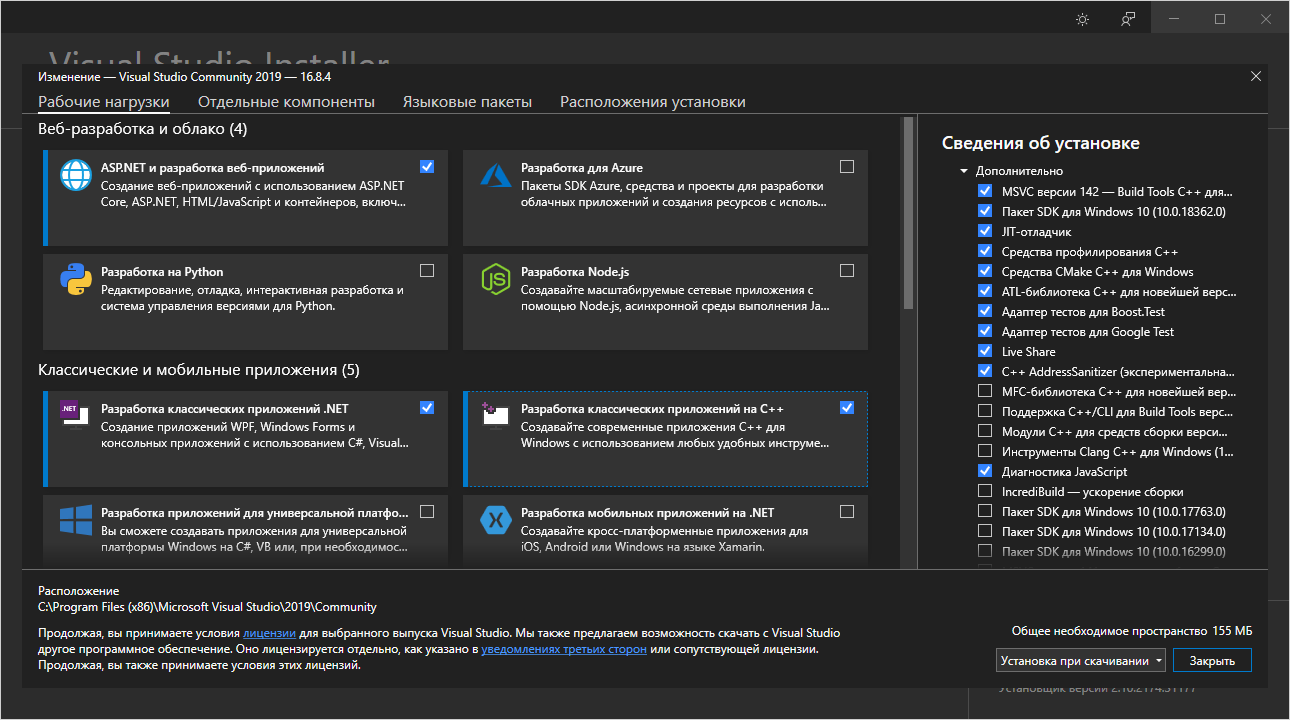

Почему важно оставить все галочки, которые предлагает Visual Studio. У меня с интернетом плоховато, поэтому я решил не скачивать пакет SDK для Windows, на что получил следующую ошибку:
Не нашли компилятор
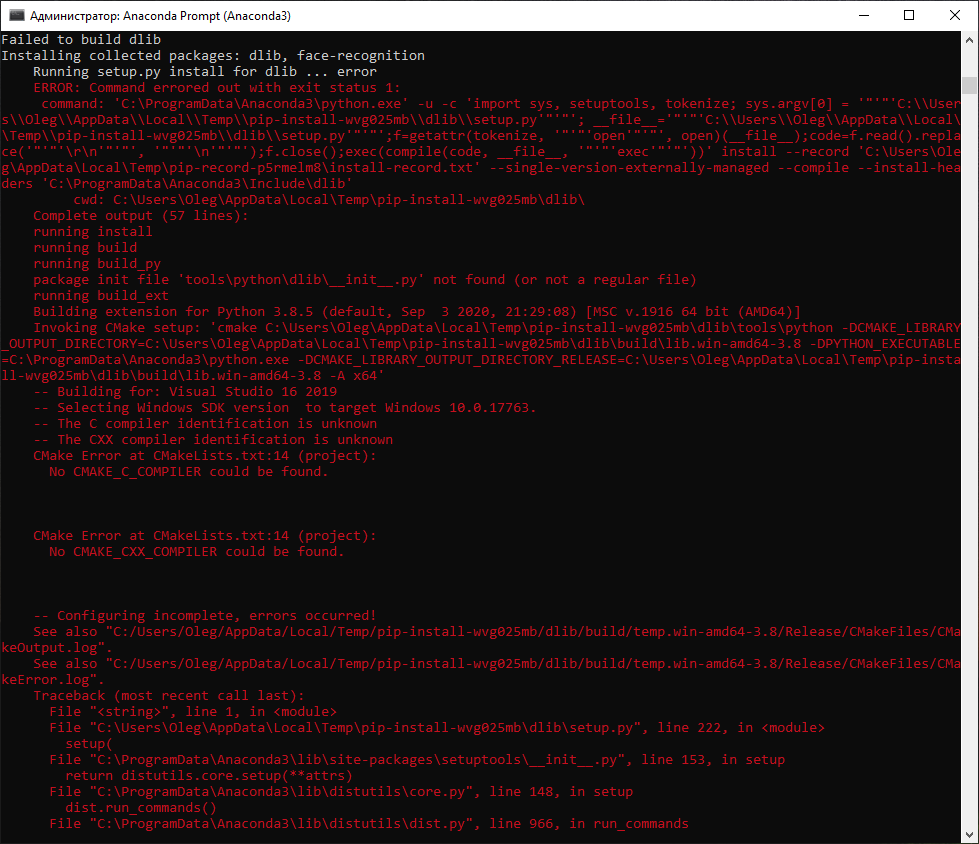
Я начал искать решение этой ошибки, пробовать менять тип компилятора (cmake -G » Visual Studio 16 2019″), но только стоило установить SDK, как все проблемы ушли.
Я пробовал данный метод на двух ПК и отмечу ещё пару подводных камней. Самое главное — Visual Studio должна быть 2019 года. У меня под рукой был офлайн установщик только 2017 — я мигом его поставил, делаю команду на установку пакета и получаю ошибку, что нужна свежая Microsoft Visual C++ версии 14.0. Вторая проблема была связана с тем, что даже установленная студия не могла скомпилировать проект. Помогла дополнительная установка Visual C++ 2015 Build Tools и Microsoft Build Tools 2015.
Открываем вновь Anaconda Prompt, используем ту же самую команду и ждём, когда соберется проект (около 5 минут):
Управляем громкостью
Вариантов оказалось несколько (ссылка), но чем проще — тем лучше. На русском язычном StackOverflow предложили использовать простую библиотеку от Paradoxis — ей и воспользуемся. Чтобы установить её, нам нужно скачать архив, пройти по пути C:ProgramDataAnaconda3Lib и перенести файлы keyboard.py, sound.py из архива. Проблем с использованием не возникало, поэтому идём дальше
Собираем события мыши
Самым популярным модулем для автоматизации управления мышью/клавиатурой оказался pynput. Устанавливаем так же через (pip install pynput) . У модуля в целом неплохое описание — https://pynput.readthedocs.io/en/latest/mouse.html . Но у меня возникли сложности при получении событий. Я написал простую функцию:
from pynput import mouse def func_mouse(): with mouse.Events() as events: for event in events: if event: print(‘Переместил мышку/нажал кнопку/скролл колесиком: <>n’.format(event)) print(‘Делаю половину громкости: ‘, time.ctime()) Sound.volume_set(volum_half) break
В комментариях к статье придём к истине, как лучше сделать.
А что в итоге?
Adam Geitgey, автор библиотеки face recognition, в своём репозитории имеет очень хороший набор примеров, которые многие используют при написании статей: https://github.com/ageitgey/face_recognition/tree/master/examples
Воспользуемся одним из них и получим следующий код, который можно скачать по ссылке: Activity.ipynb, Activity.py
# Подключаем нужные библиотеки import cv2 import face_recognition # Получаем данные с устройства (веб камера у меня всего одна, поэтому в аргументах 0) video_capture = cv2.VideoCapture(0) # Инициализируем переменные face_locations = [] from sound import Sound Sound.volume_up() # увеличим громкость на 2 единицы current = Sound.current_volume() # текущая громкость, если кому-то нужно volum_half=50 # 50% громкость volum_full=100 # 100% громкость Sound.volume_max() # выставляем сразу по максимуму # Работа со временем # Подключаем модуль для работы со временем import time # Подключаем потоки from threading import Thread import threading # Функция для работы с активностью мыши from pynput import mouse def func_mouse(): with mouse.Events() as events: for event in events: if event == mouse.Events.Scroll or mouse.Events.Click: #print(‘Переместил мышку/нажал кнопку/скролл колесиком: <>n’.format(event)) print(‘Делаю половину громкости: ‘, time.ctime()) Sound.volume_set(volum_half) break # Делаем отдельную функцию с напоминанием def not_find(): #print(«Cкрипт на 15 секунд начинается «, time.ctime()) print(‘Делаю 100% громкости: ‘, time.ctime()) #Sound.volume_set(volum_full) Sound.volume_max() # Секунды на выполнение #local_time = 15 # Ждём нужное количество секунд, цикл в это время ничего не делает #time.sleep(local_time) # Вызываю функцию поиска действий по мышке func_mouse() #print(«Cкрипт на 15 сек прошел») # А тут уже основная часть кода while True: ret, frame = video_capture.read() »’ # Resize frame of video to 1/2 size for faster face recognition processing small_frame = cv2.resize(frame, (0, 0), fx=0.50, fy=0.50) rgb_frame = small_frame[:, :, ::-1] »’ rgb_frame = frame[:, :, ::-1] face_locations = face_recognition.face_locations(rgb_frame) number_of_face = len(face_locations) »’ #print(«Я нашел <> лицо(лица) в данном окне».format(number_of_face)) #print(«Я нашел <> лицо(лица) в данном окне».format(len(face_locations))) »’ if number_of_face < 1: print(«Я не нашел лицо/лица в данном окне, начинаю работу:», time.ctime()) »’ th = Thread(target=not_find, args=()) # Создаём новый поток th.start() # И запускаем его # Пока работает поток, выведем на экран через 10 секунд, что основной цикл в работе »’ #time.sleep(5) print(«Поток мыши заработал в основном цикле: «, time.ctime()) #thread = threading.Timer(60, not_find) #thread.start() not_find() »’ thread = threading.Timer(60, func_mouse) thread.start() print(«Поток мыши заработал.n») # Пока работает поток, выведем на экран через 10 секунд, что основной цикл в работе »’ #time.sleep(10) print(«Пока поток работает, основной цикл поиска лица в работе.n») else: #все хорошо, за ПК кто-то есть print(«Я нашел лицо/лица в данном окне в», time.ctime()) Sound.volume_set(volum_half) for top, right, bottom, left in face_locations: cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2) cv2.imshow(‘Video’, frame) if cv2.waitKey(1) с наскоку» тему взять не удалось и результат по видео понятен. Есть неплохая статья на Хабре, описывающая различные методы многопоточности, применяемые в языке. Пока у меня решения нету по этой теме нету — будет повод разобраться лучше и дописать код/статью с учетом этого.
Так же возникает закономерный вопрос — а если вместо живого человека поставить перед монитором картинку? Да, она распознает, что, скорее всего, не совсем верно. Мне попался очень хороший материал по поводу определения живого лица в реальном времени — https://www.machinelearningmastery.ru/real-time-face-liveness-detection-with-python-keras-and-opencv-c35dc70dafd3/ , но это уже немного другой уровень и думаю новичкам это будет посложнее. Но эксперименты с нейронными сетями я чуть позже повторю, чтобы тоже проверить верность и повторяемость данного руководства.
Немаловажным фактором на качество распознавания оказывает получаемое изображение с веб-камеры. Предложение использовать 1/4 изображения (сжатие его) приводит только к ухудшению — моё лицо алгоритм распознать так и не смог. Для повышения качества предлагают использовать MTCNN face detector (пример использования), либо что-нибудь посложнее из абзаца выше.
Другая интересная особенность — таймеры в Питоне. Я, опять же, признаю, что ни разу до этого не было нужды в них, но все статьях сводится к тому, чтобы ставить поток в sleep(кол-во секунд). А если мне нужно сделать так, чтобы основной поток был в работе, а по истечению n-ое количества секунд не было активности, то выполнялась моя функция? Использовать демонов (daemon)?
Так это не совсем то, что нужно. Писать отдельную программу, которая взаимодействует с другой? Возможно, но единство программы пропадает.
Заключение
На своём примере могу точно сказать — не все руководства одинаково полезны и простая задача может перерасти в сложную. Я понимаю, что большинство материалов является переводом/простым копированием документации. Но если ты пишешь руководство, то проверь хотя бы на тестовой системе, что написанные тобой действия точно повторимы. Пробуйте, экспериментируйте — это хороший повод изучить и узнать новое.
P.S. Предлагаю вам, читатели, обсудить в комментариях статью — ваши идеи, замечания, уточнения.
Источник: habr.com
Sound from: перевод, синонимы, произношение, примеры предложений, антонимы, транскрипция
![]()
- Теория
- Грамматика
- Лексика
- Аудио уроки
- Диалоги
- Разговорники
- Статьи
Все права на сервисы и материалы, находящиеся на сайте EnglishLib.org, защищены. Использование материалов возможно только с письменного разрешения владельца и при указании прямой активной ссылки на EnglishLib.org.
Источник: englishlib.org