
FreeOCR — это программа для оптического распознавания символов для Windows.
Если вам когда-либо приходилось копировать текст изображения или отсканированного документа, вы знаете, что у вас есть два основных способа сделать это.
Вы можете скопировать текст вручную, что может занять некоторое время, в зависимости от его длины и качества документа, или вместо этого использовать программу распознавания текста.
Программное обеспечение для оптического распознавания символов может ускорить процесс, и, хотя оно не является безошибочным и требует, чтобы вы просмотрели этот текст, чтобы исправить любые ошибки, сделанные в процессе распознавания, оно может сэкономить вам много времени.
Мы рассмотрели Project Naptha для Google Chrome только недавно, который добавил функциональность в браузер. Хотя он хорошо работает в Интернете, он вообще не поможет вам с локальными документами.
FreeOCR для Windows предоставляет вам два режима работы. Вы можете использовать его для открытия существующих файлов изображений или PDF-документов или использовать встроенную функцию сканирования для сканирования и обработки документов, которые еще не доступны в электронной форме.
Программа для считывание текста с картинки.
Предупреждение : Установщик содержит сторонние предложения. Убедитесь, что вы отклоняете их, если не хотите устанавливать их в своей системе. Он предлагал Conduit Search Protect, панель инструментов V-Bates и удаленный доступ к вашему домашнему или офисному компьютеру во время установки.
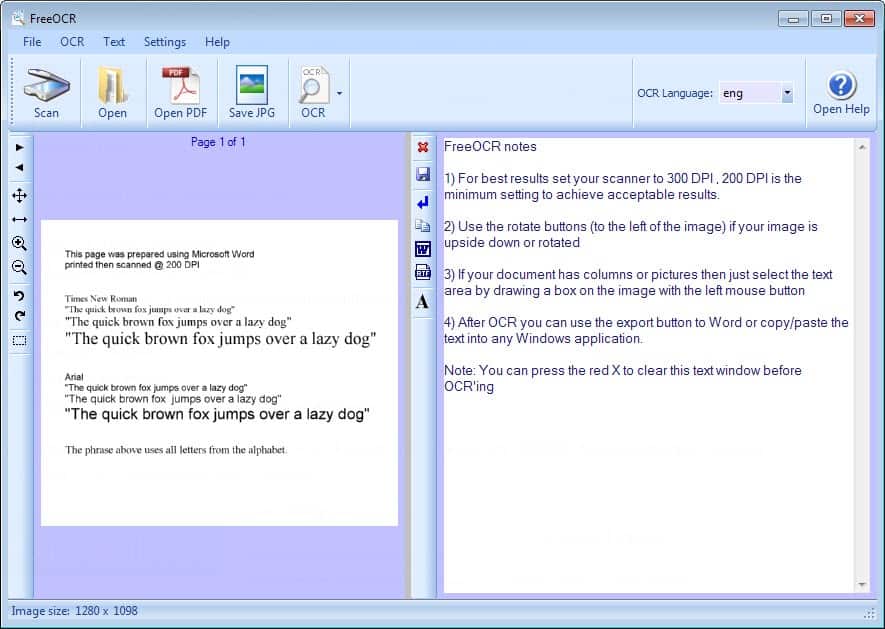
Интерфейс программы очень простой. Вы найдете главную панель инструментов вверху, которую вы используете для загрузки документа. Вы можете выбрать «Открыть» для загрузки изображения, «Открыть PDF» для загрузки PDF-документа или «отсканировать», чтобы использовать подключенный сканер для сканирования бумажного документа.
Если вы выбрали опцию сканирования, убедитесь, что для достижения наилучших результатов для сканера установлено разрешение не менее 300 точек на дюйм во время сканирования.
Документ отображается в левой части основной области. Здесь вы можете переворачивать страницы, если это многостраничный документ, и использовать другие функции, такие как масштабирование, поворот или подгонка под экран.
Щелчок по кнопке OCR вверху позволяет запустить оптическое распознавание символов на текущей странице или на всех страницах. Вы можете использовать инструмент выделения на левой странице, чтобы распознавать текст только в выбранной области.
Процесс быстрый и не займет много времени. Результаты автоматически отображаются справа. Эта сторона работает как текстовый редактор, а это означает, что вы можете вносить здесь исправления непосредственно перед сохранением или копированием информации.
Программа использует Движок Tesseract OCR и регулярно обновляется.
Вердикт
Программа действительно хорошо работает, если вы загружаете в нее черный текст на белом фоне документов. В этих условиях оптическое распознавание текста всегда было почти идеальным.
Программы распознавания текста
Качество вывода снижается, если качество исходного документа или изображения не самое высокое. Хотя он все еще может определять некоторые или даже большинство символов, вам придется впоследствии отредактировать полученный текст, поскольку он будет содержать ошибки.
Смотрите так же:
- Opera Software ASA переименовывается в Otello Corporation
- Посещенные помогает отслеживать посещенные ссылки в Firefox.
- Image Autosizer для Chrome позволяет лучше контролировать просмотр изображений
- Аудиокнига Сон
Источник: bauinvest.su
Аналоги FreeOCR
FreeOCR — это программа для сканирования и распознавания, включающая в себя движок Tesseract free ocr, также известный как графический интерфейс Tesseract.
Он включает в себя установщик Windows и очень прост в использовании. FreeOCR поддерживает многостраничные TIFF, факсимильные документы, а также большинство типов изображений, включая сжатые TIFF, которые механизм Tesseract сам по себе не может прочитать.
Может работать с форматами PDF, а также совместим со сканерами TWAIN.
Бесплатный механизм распознавания текста Tesseract — это находящийся в открытом доступе продукт, выпущенный Google. Он был разработан в Hewlett Packard Laboratories в период с 1985 по 1995 год. В 1995 году вошел в тройку лучших на конкурсе OCR, организованном Университетом Невады.
Источник: ruprogi.ru
FreeOCR 5.4.1

FreeOCR – небольшая бесплатная программа для распознавания текста с изображений и документов PDF. Поддерживает многие распространенные форматы – JPEG, TIFF, PNG и другие. Также может получать изображение со сканера и сразу распознать с него текст. Изначально русский язык не поддерживается, но его можно скачать с сайта разработчика.
Главное окно FreeOCR поделено на 2 области – слева находится исходное изображение или документ, справа – распознанный текст. Чтобы добавить файл с диска, нажмите Open или Open PDF. Если вам нужно получить изображение со сканера, нажмите Scan. Далее выбранный вами файл появится в левой части окна. Если он повернут, то вы можете развернуть его в нужное положение.
Также вы можете вручную мышью указать, какую область нужно сканировать. Чтобы запустить распознавание, нажмите кнопку OCR – вы можете выбрать, нужно ли распознавать весь документ или только открытую страницу (применимо для PDF-файла).
Результаты распознавания появятся в левой части окна FreeOCR. Текст можно скопировать в буфер обмена или сохранить в форматах TXT, DOCX или RTF. Если вы получили изображение со сканера, то его тоже можно сохранить в JPEG.
Особенности программы
• Распознавание текста с изображения или файла PDF.
• Возможность распознавания текста с изображения, полученного со сканера.
• Сохранение текста в TXT, DOCX или RTF.
• Поддержка русского языка для распознавания (скачивается дополнительно с сайта разработчика).
• Поддерживает Windows 7 и выше.
Программу FreeOCR можно скачать совершенно бесплатно.
Скачать бесплатно FreeOCR 5.4.1
Распознавание текста FreeOCR модуль распознавания русского языка — Скачать
| Версия: | 5.4.1 |
| Русский язык: | Нет |
| Разработчик: | FreeOCR |
| Операционка: | Windows All |
| Размер: | 10,8 Mb |
Сохранить:
Источник: kmsauto2020.ru
4 программы для распознавания текста


Знакомство с интерфейсом компьютерных игр и прикладного программного обеспечения может обернуться настоящей головной болью, если вы не знаете языка, который в этом самом интерфейсе используется. Нельзя вот так просто взять и скопировать текст меню в буфер обмена и вставить его в поле переводчика как это обычно мы делаем с текстом документов или веб-сайтов.
К счастью существуют утилиты позволяющие захватывать текст непосредственно с рабочего стола, то есть с изображений и элементов интерфейса. Как и ABBYY FineReader, являющейся одной из самых известных программ для распознания текста, эти утилиты используют технологию OCR. А вот и примеры.
Screenshot Reader

Замечательный коммерческий продукт от компании ABBYY. Утилита позволяет захватывать текст с изображений и преобразовывать его в редактируемый текст. Приложением поддерживается захват выделенной области, экрана, окна.
Извлекать можно не только текст, но и таблицы с последующим экспортом в файл, буфер обмена или Excel. Аналогичные операции можно проделывать и с текстом.
А еще Screenshot Reader умеет сохранять скриншоты и пересылать их по электронной почте. В общей сложности приложением поддерживается 179 языков. Утилита отличная, но использовать ее лучше вместе с родной ABBYY FineReader.
Capture2Text

Бесплатная портативная программка для распознавания текста. Работает программа с выделенной областью. Поддерживается более 30 языков, однако по умолчанию присутствуют только шесть языков, а именно английский, французский, немецкий, испанский, китайский и японский.
Файлы для русского и прочих языков нужно загружать отдельно с сайта разработчика.
Capture2Text также поддерживает распознание речи, правда особо высоким качеством распознания она похвастать не может. Из недостатков также можно отметить не очень удобный интерфейс.
SimpleOCR

Предназначается эта программа для работы с отсканированными документами, а вот с десктопа похоже захватывать текст она не умеет, по крайней мере, соответствующей опции мне так и не удалось найти. Выделение работает только для загруженных в программу файлов.
Русского языка я тоже не нашел, попытка распознать кириллический текст также не увенчалась успехом. В общем SimpleOCR можно представить как некое подобие ABBYY FineReader или лучше сказать пародию на FineReader.
Из достоинств отметить можно разве что низкие требования к системе, малый вес и умение сохранять форматирование исходного файла.
FreeOCR

Еще один аналог FineReader (заметьте именно аналог, а не подобие), который мне так и не удалось установить. По какой-то причине мой Avast заблокировал загрузку файлов программы (устанавливается FreeOCR через веб-инсталлятор) и, в общем, на этом все и завершилось.
Судя по описаниям, работает FreeOCR с уже существующими файлами, то есть захватывать скриншоты как это умеет делать Screenshot Reader программа не может.
Русский язык по умолчанию отсутствуют, загружать и устанавливать языковой пакет нужно отдельно. Несомненным плюсом FreeOCR является бесплатность и простота использования.
Итог
Так что если вам нужна хорошая распознавалка, выбирайте Screenshot Reader, не пожалеете, а еще лучше установить полный пакет ABBYY FineReader.
Стоит этот продукт немало, с другой стороны найти «обработанную» рабочую версию не составит особого труда.
Источник: www.softrew.ru