

Free Online OCR — бесплатный онлайн сервис для распознавания текста. К достоинствам аналога ABBYY FineReader относятся хорошее качество распознавания текста; неограниченное количество загрузок; работа с 70 языками, в том числе русским; распознавание текста, содержащего сразу несколько языков; отсутствие регистрации.
Free Online OCR предоставляет возможность выделять, а также разворачивать часть документа, предназначенную для дальнейшей обработки. Распознает следующие форматы: JPEG, JFIF, PNG, GIF, BMP, PBM, PGM, PPM и PCX. Работает с такими форматами сжатия как Unix compress, bzip2, bzip и gzip; со следующими мультистраничными документами: TIFF, PDF и DjVu. Распознает файлы DOCX и ODT с изображениями. Работает с ZIP архивами.
Результат может быть получен в виде простого текста (TXT), документа Microsoft Word (DOC) и PDF-файла Adobe Acrobat.
Лучшие программы для распознавания текста. Рейтинг OCR.
Для настройки распознавания вы можете повернуть страницу, выбрать область распознавания и выставить опцию обработки текста с колонками.
Отсканированный текст сервис распознаёт хорошо, если в нём не присутствуют изображения.


Но если текст содержит картинки или сфотографирован не в самом хорошем качестве, то результат далёк от корректного.


Free Online OCR — хороший сервис для распознавания хорошо отсканированных страниц, которые содержат только текст.
Источник: freeanalogs.ru
Распознаем текст в PDF-файле онлайн

Извлечь текст из PDF-файла методом обычного копирования можно далеко не всегда. Часто страницы подобных документов представляют собой отсканированное содержимое их бумажных вариантов. Для преобразования таких файлов в полностью редактируемые текстовые данные используются специальные программы с функцией Optical Character Recognition (OCR).
Такие решения являются весьма сложными в реализации и, следовательно, стоят немалых денег. Если потребность в распознавании текста с PDF у вас возникает регулярно, вполне целесообразно будет приобрести соответствующую программу. Для редких же случаев более логичным будет воспользоваться одним из доступных онлайн-сервисов с подобными функциями.
Как распознать текст с PDF онлайн
Конечно, набор возможностей онлайн-сервисов OCR, в сравнении с полноценными десктопными решениями, более ограничен. Но и работать с такими ресурсами можно либо же совсем бесплатно, либо за символическую плату. Главное, что с основной своей задачей, а именно с распознаванием текста, соответствующие веб-приложения справляются так же хорошо.
Способ 1: ABBYY FineReader Online
Компания-разработчик сервиса — одна из лидеров в области оптического распознавания документов. ABBYY FineReader для Windows и Mac является мощным решением для преобразования PDF в текст и дальнейшей работы с ним.
Веб-аналог программы, конечно же, уступает ей по функционалу. Тем не менее сервис умеет распознавать текст со сканов и фотографий на более чем 190 языках. Поддерживается преобразование PDF-файлов в документы Word, Excel и т.п.
- Прежде чем приступить к работе с инструментом, создайте аккаунт на сайте или войдите при помощи учетной записи Facebook, Google или Microsoft.
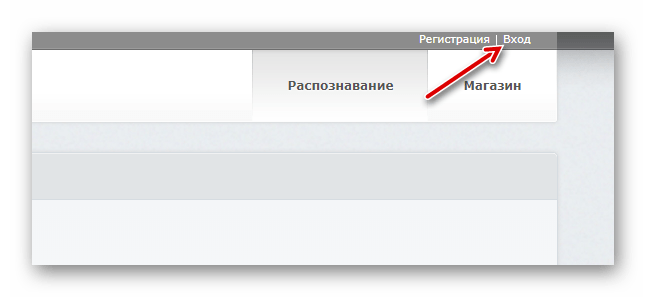
Чтобы перейти к окну авторизации, щелкните по кнопке «Вход» в верхней панели меню. - Осуществив вход, импортируйте нужный PDF-документ в FineReader, воспользовавшись кнопкой «Загрузить файлы».
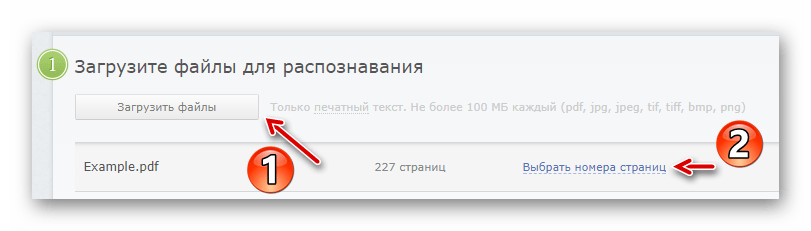
Затем нажмите «Выбрать номера страниц» и укажите желаемый промежуток для распознавания текста. - Далее выберите языки, присутствующие в документе, формат итогового файла и нажмите на кнопку «Распознать».
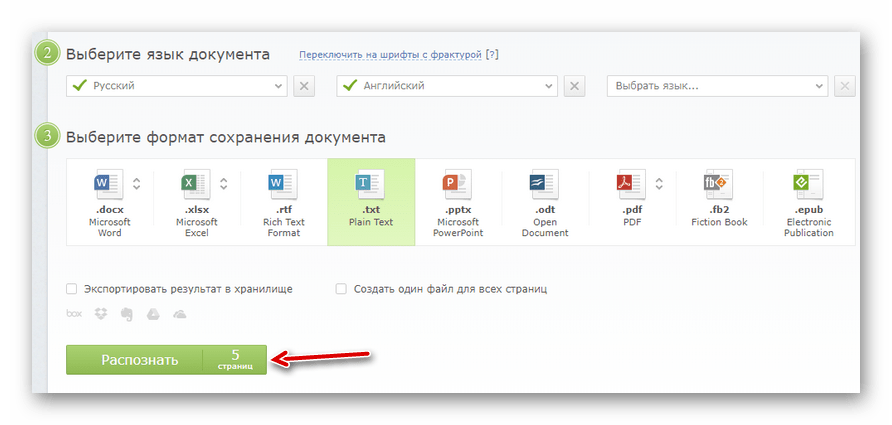
- После обработки, длительность которой полностью зависит от объема документа, вы можете скачать готовый файл с текстовыми данными просто щелкнув по его названию.
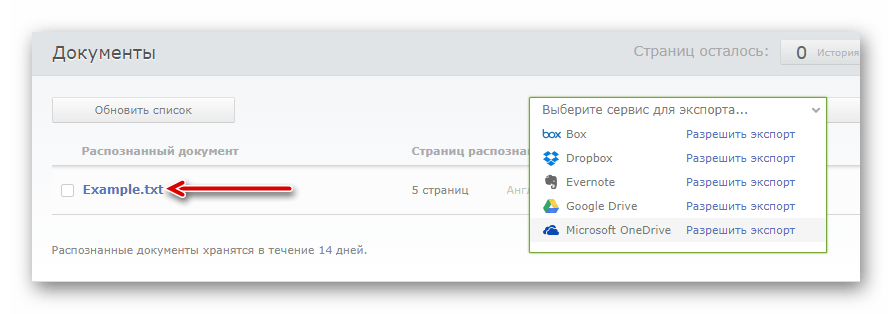
Либо же экспортируйте его в один из доступных облачных сервисов.
Сервис отличается, вероятно, наиболее точными алгоритмами распознавания текста на изображениях и PDF-файлах. Но, к сожалению, его бесплатное использование ограничено пятью обрабатываемыми страницами в месяц. Чтобы работать с более объемными документами, придется купить годовую подписку.
Тем не менее, если функция OCR нужна совсем уж редко, ABBYY FineReader Online — отличный вариант для извлечения текста из небольших PDF-файлов.
Способ 2: Free Online OCR
Простой и удобный сервис для оцифровки текста. Без необходимости регистрации ресурс позволяет распознавать 15 полных PDF-страниц в час. Free Online OCR полноценно работает с документами на 46 языках и без авторизации поддерживает три формата экспорта текста — DOCX, XLSX и TXT.
При регистрации пользователь получает возможность обрабатывать многостраничные документы, однако бесплатное количество этих самых страниц ограничено 50 единицами.
- Чтобы распознать текст из PDF как «гость», без авторизации на ресурсе, воспользуйтесь соответствующей формой на главной странице сайта.
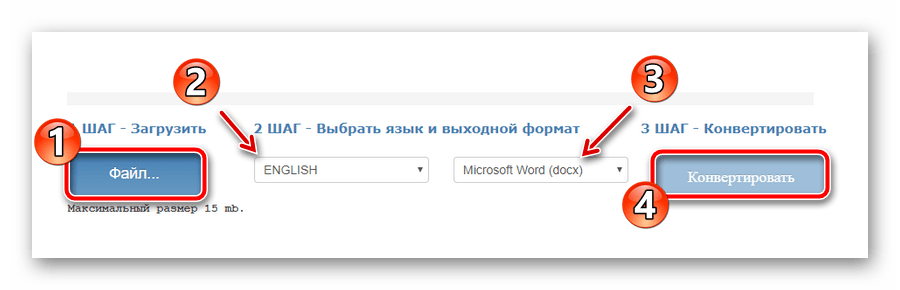
Выберите нужный документ с помощью кнопки «Файл», укажите основной язык текста, выходной формат, затем дождитесь загрузки файла и нажмите «Конвертировать». - По окончании процесса оцифровки нажмите «Скачать выходной файл» для сохранения готового документа с текстом на компьютере.
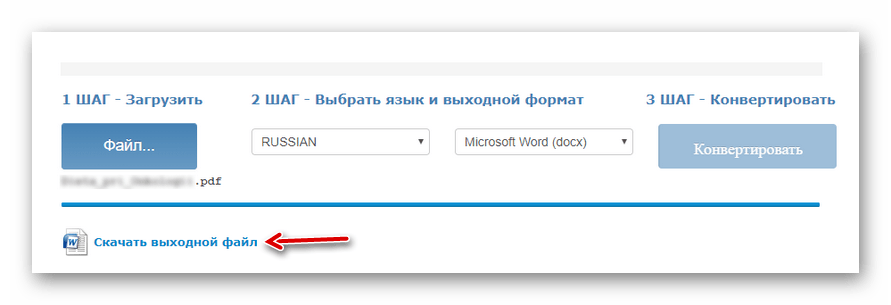
Для авторизованных же пользователей последовательность действий несколько иная.
- Воспользуйтесь кнопкой «Регистрация» или «Вход» в верхней панели меню, чтобы, соответственно, создать учетную запись Free Online OCR либо зайти в нее.
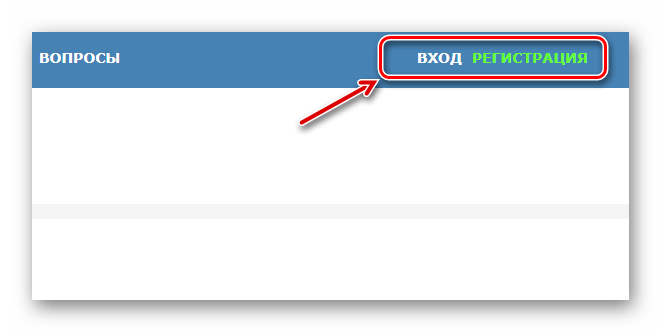
- После авторизации в панели распознавания, удерживая клавишу «CTRL», выберите до двух языков исходного документа из предложенного списка.
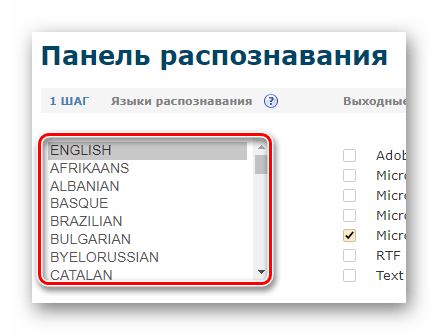
- Укажите дальнейшие параметры извлечения текста из PDF и нажмите кнопку «Выбрать файл» для загрузки документа в сервис.
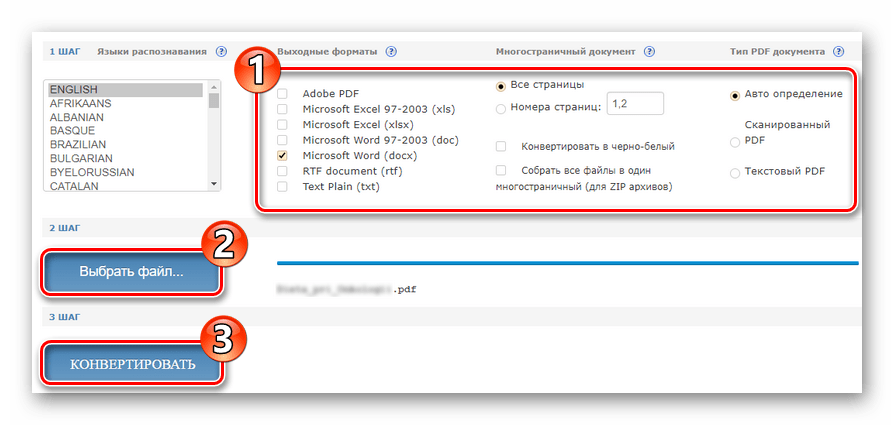
Затем, чтобы приступить к распознаванию, щелкните «Конвертировать». - По окончании обработки документа нажмите на ссылку с названием выходного файла в соответствующей колонке.
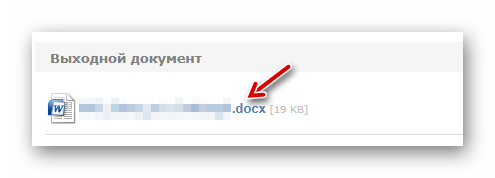
Результат распознавания сразу же будет сохранен в памяти вашего компьютера.
При необходимости извлечь текст из небольшого PDF-документа можно смело прибегать к использованию вышеописанного инструмента. Для работы же с объемными файлами придется купить дополнительные символы во Free Online OCR либо же прибегнуть к другому решению.
Способ 3: NewOCR
Полностью бесплатный OCR-сервис, позволяющий извлекать текст практически из любых графических и электронных документов вроде DjVu и PDF. Ресурс не накладывает ограничений на размер и количество распознаваемых файлов, не требует регистрации и предлагает широкий набор сопутствующих функций.
NewOCR поддерживает 106 языков и умеет корректно обрабатывать даже низкокачественные сканы документов. Есть возможность вручную выбирать область для распознавания текста на странице файла.
- Так, приступить к работе с ресурсом вы можете сразу, без необходимости выполнения лишних действий.
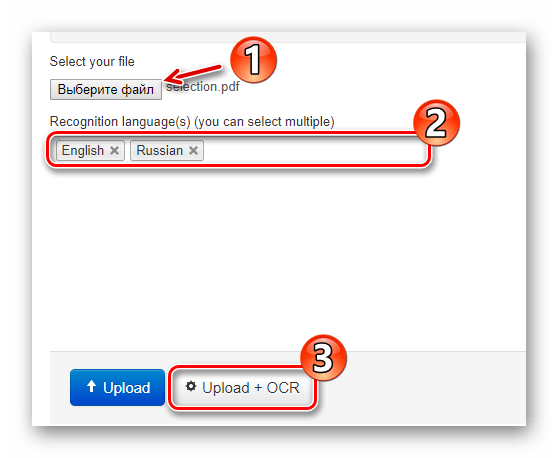
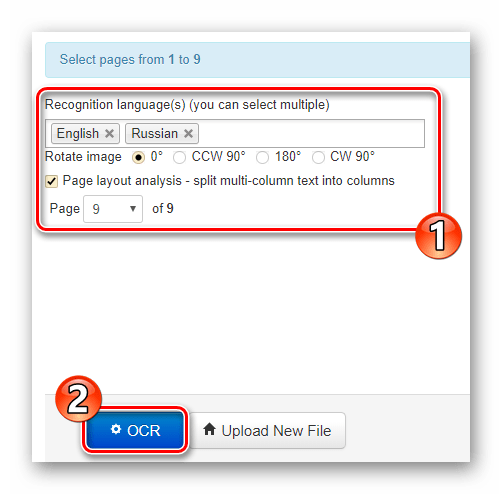
Прямо на главной странице размещена форма для импорта документа на сайт. Чтобы загрузить файл в NewOCR, воспользуйтесь кнопкой «Выберите файл» в разделе «Select your file». Затем в поле «Recognition language(s)» укажите один или более языков исходного документа, после чего нажмите «Upload + OCR». - Задайте предпочитаемые настройки распознавания, выберите нужную страницу для извлечения текста и щелкните по кнопке «OCR».
- Прокрутите страницу немного ниже и найдите кнопку «Download».
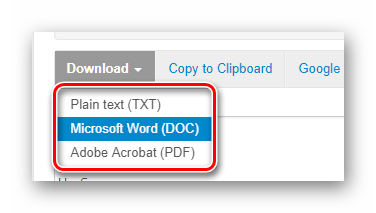
Щелкните по ней и в выпадающем списке выберите необходимый формат документа для скачивания. После этого готовый файл с извлеченным текстом будет загружен на ваш компьютер.
Инструмент удобный и достаточно качественно распознает все символы. Впрочем, обработку каждой страницы импортированного PDF-документа нужно запускать самостоятельно и выводится она в отдельный файл. Можно, конечно, сразу копировать результаты распознавания в буфер обмена и объединять их с другими.
Тем не менее, учитывая вышеописанный нюанс, большие объемы текста с помощью NewOCR извлекать весьма затруднительно. С малыми же файлами сервис справляется «на ура».
Способ 4: OCR.Space
Простой и понятный ресурс для оцифровки текста, позволяет распознавать PDF-документы и выводить результат в TXT-файл. Никаких лимитов по количеству страниц не предусмотрено. Единственное ограничение — размер входного документа не должен превышать 5 мегабайт.
- Регистрироваться для работы с инструментом не нужно.
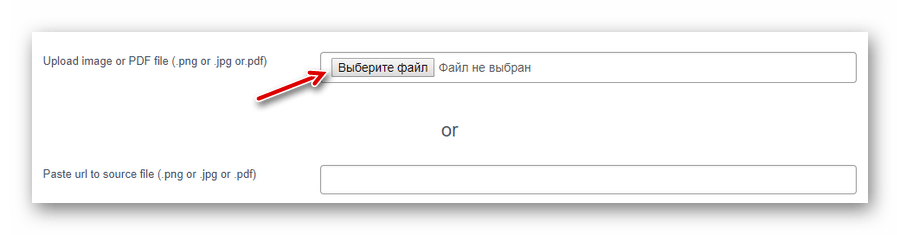
Просто перейдите по ссылке выше и загрузите PDF-документ на сайт с компьютера при помощи кнопки «Выберите файл» либо из сети — по ссылке. - В выпадающем списке «Select OCR language» выберите язык импортированного документа.
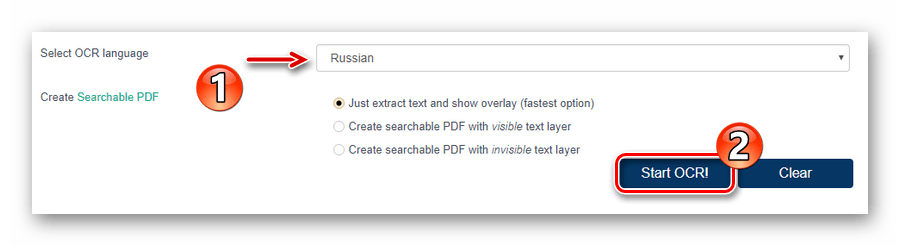
Затем запустите процесс распознавания текста, щелкнув по кнопке «Start OCR!». - По окончании обработки файла ознакомьтесь с результатом в поле «OCR’ed Result» и нажмите «Download», чтобы скачать готовый TXT-документ.
Если вам нужно просто извлечь текст из PDF и при этом финальное его форматирование совсем не важно, OCR.Space — хороший выбор. Единственное, документ должен быть «одноязычным», так как распознавание двух и более языков одновременно в сервисе не предусмотрено.
Оценивая онлайн-инструменты, представленные в статье, следует отметить, что наиболее точно и качественно с функцией OCR справляется FineReader Online от ABBYY. Если для вас важна именно максимальная точность распознавания текста, лучше всего рассмотреть конкретно этот вариант. Но и заплатить за него, скорее всего, также придется.
Если же нужна оцифровка небольших документов и вы готовы самостоятельно исправлять ошибки за сервисом, целесообразно использовать NewOCR, OCR.Space или Free Online OCR.
Мы рады, что смогли помочь Вам в решении проблемы.
Источник: lumpics.ru
Обзор онлайн-сервисов для оптического распознавания текстов

Обзор онлайн-сервисов для оптического распознавания текстов
Существуют ли надежные и качественные OCR-системы, доступные онлайн?
Для того чтобы отредактировать информацию, полученную со сканера, необходимо применить технологию, которая получила название OCR, что в расшифровке и в переводе на русский означает «оптическое распознавание символов». Мы задались вопросом, а существуют ли надежные и качественные OCR-системы, доступные онлайн?
На сегодняшний день техника шагнула достаточно далеко, и для получения фотокопии изображения уже не нужно искать сканер, достаточно просто достать телефон с фотокамерой и «щелкнуть» нужные страницы изображения. А уж если есть под рукой мало-мальски приличная «фотомыльница», то получить изображение нужной четкости и разрешения и вовсе не составляет труда. К слову, это стало настолько очевидно, что многие библиотеки, видимо, не желая терять заработок на услуге ксерокопирования, стали запрещать использование любой фототехники в читальном зале. Так что, прогресс налицо.
В области же оптического распознавания текста, к сожалению, никаких революций за последние пять лет не случилось, хотя определенные изменения все-таки произошли. Например, ощутимо сдвинулся баланс от настольных систем распознавания к применению веб-сервисов. Нельзя сказать, что OCR-рынок ушел в онлайн, но изменение самой концепции использования компьютера, распространение мобильной техники, Интернета, «облачных» сервисов — все это диктует ситуации, когда пользователь оказывается перед фактом, что стационарного компьютера под рукой нет.
Но в случае крайней необходимости можно сфотографировать и попытаться «скормить» фотоснимок одному из OCR-онлайн-сервисов. Вероятнее всего, со временем такой путь будет становиться все популярнее, и поэтому мы решили отправиться на исследование онлайн-просторов в поисках хорошего сервиса распознавания отсканированного текста.
Мы не ставили перед собой задачу найти непременно бесплатный сервис, предполагая, что таких может просто не быть. Однако некоммерческие ресурсы данного типа все-таки нашлись. Имеются также условно бесплатные, в которых можно распознать несколько страниц «на пробу». В любом случае сервис должен поддерживать русский язык и не требовать никакой установки на компьютер: иногда это просто невозможно на служебных машинах.
Для пробы мы приготовили несколько материалов, с которых OCR-сервисам предстояло «вытянуть» текст. Первый файл был получен путем сканирования на недорогом домашнем планшетном сканере с большим разрешением и настройками «по умолчанию». Второй кадр был в виде страницы из PDF-файла с разрешением, близким к экранному. Третий, уже посложнее, был снят с помощью фотоаппарата со штатива при максимально хорошем освещении. И наконец, четвертый файл был снят смартфоном среднего уровня с камерой 3 Мпикс, с применением встроенной вспышки.
Качество последнего файла было плохим как по разрешению, четкости, так и по геометрии изображения, зато ближе всего к полевым условиям. Снимки были сделаны с обычных страниц книги, с делового отчета и содержали кроме текста еще и несложную таблицу. Именно с таким вполне реалистичным набором данных предстояло разобраться испытуемым.
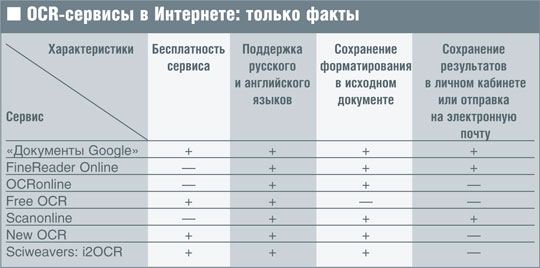
«Документы Google»
Первым на старт вышел Google со своими документами (docs.google.com). Не все знают, что помимо совместной работы над материалом сервис позволяет распознать документ, загруженный в виде изображения или PDF. Никаких особенных действий предпринимать не нужно, все получается автоматически. Однако размер файла ограничен 2 Мбайт, так что полноценный скан страницы книги отправить не удалось. Уменьшив размер, мы смогли «вытащить» редактируемый текст.
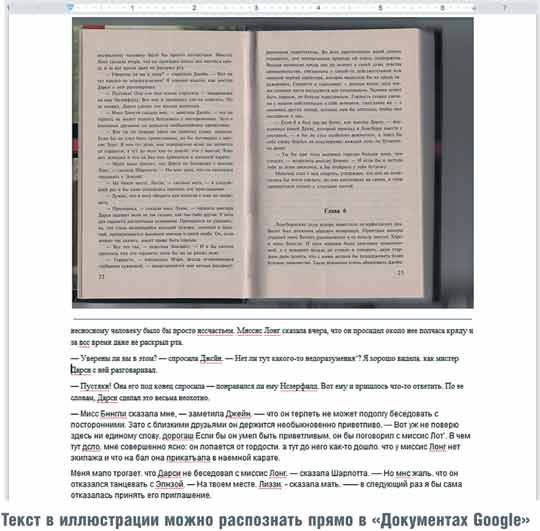
«Документы Google» легко распознали разворот страницы и справились с текстом. Качество работы можно оценить не выше, чем 4 балла из 5, потому что ни одного абзаца без ошибки не случилось. Однако это все же на порядок быстрее и легче, чем набирать текст с чистого листа.
Со сложными исходными файлами дело пошло хуже: качество распознавания упало до «тройки» по пятибалльной шкале и не вышло распознавание сложного форматирования и таблиц. Тем не менее удовлетворительный результат был зафиксирован, и ресурс вполне стоит взять на вооружение как действенный способ получить текст из PDF или картинки.
FineReader Online
Переходим к явному фавориту нашего тестирования. Компания Abbyy уже пару лет предлагает воспользоваться всей мощью своего OCR-механизма через веб-сервис (finereader.abbyyonline.com). Отличия от настольной версии, конечно, имеются. Прежде всего — в количестве поддерживаемых языков («всего» 49 против почти 200 в профессиональной версии FineReader), а также в отсутствии каких-либо дополнительных возможностей по обработке текста после распознавания.

Входным форматом может быть практически любой популярный графический формат или PDF без пароля, а выходным — DOC, XLS, ODT, TXT и PDF. Загружать можно документы размером до 30 Мбайт.
Как и ожидалось, сервис продемонстрировал отличную работу и очень хорошее качество распознавания на всех исходных изображениях. Даже на самой плохой картинке, снятой мобильным телефоном, FineReader Online узнал и направление текста (самостоятельно повернул картинку), и форматирование абзацев, и даже таблицу! Фактически даже при самом плохом «исходнике» исправить пришлось всего несколько ошибок.
За использование чудо-сервиса, однако, придется заплатить. Возможность сканирования покупается постранично, и за 100 стр. надо будет выложить 7 долларов. Однако качество того стоит — чистые 5 из 5!
OCRonline
На очереди у нас иностранный сервис и проверка того, как он справляется с русским языком. OCRonline (www.ocronline.com) работает с 14 самыми популярными европейскими языками. Услуга предоставляется не бесплатно, но при регистрации начисляется пять бесплатных «пробных» страниц и, кроме того, каждый понедельник ваш баланс пополняется бесплатно до тех самых пяти страниц. Дополнительные пакеты можно купить по цене от 8 долларов за 100 стр. и дешевле, если заказывать оптом.
Сам процесс распознавания мало чем примечателен. На выходе в вашем распоряжении будет текст в формате DOC, TXT, PDF или RTF. А вот результаты получились любопытные. Качественные изображения с фотоаппарата и со сканера с высоким разрешением были распознаны идеально, фактически без единой ошибки. Твердая пятерка!
С картинкой низкого качества сервис также справился на ура, даже таблица никуда не пропала! Но помарок было предостаточно, так что отличным такое распознавание назвать нельзя. Но 4 из 5 — это очень хороший показатель. Обязательно стоит взять этот ресурс на заметку для срочных задач.
Online OCR
Следующий веб-инструмент распознавания текста расположился в русскоязычной доменной зоне по адресу www.onlineocr.ru. Он также не бесплатный, и для получения выходного материала в одном из шести популярных форматов нужно купить «кредиты», за которые и осуществляется распознавание текста. В деморежиме получится увидеть только первую пару абзацев текста и то лишь в виде текста без форматирования. Исходный файл может быть размером до 20 Мбайт.

Пробы показали, что этот сервис очень чувствителен к качеству оригинала. Изображение со сканера в полном разрешении позволило получить очень хороший текст, практически без ошибок. А вот работа со сложным исходником не удалась. Качество текста оставляет желать лучшего, и исправлять опечатки в нем может быть сложнее, чем напечатать текст самому.
Free OCR
Многообещающее слово free в названии сервиса заставило нас обратить внимание на адрес www.free-ocr.com, в котором обитает следующий претендент на звание лучшего онлайн-механизма OCR.

Скажем сразу, победы не получилось. Не обращаем внимания на нарочито простой дизайн сайта, ведь мы не за этим сюда пришли. Максимальный размер загружаемого файла всего 2 Мбайт — маловато. Пусть поддерживаются основные форматы (но в PDF распознается только первая страница) и языков вполне впечатляющий набор, но на выходе только текст без форматирования. Кроме того, для загрузки каждого файла нужно вводить буквы с CAPTCHA.
Результат не на высоте, к сожалению. Текст даже с качественного изображения получился малопригодным к использованию — уж очень много ошибок. А фотография с мобильного телефона и вовсе распозналась как набор непонятных малочитаемых символов. Зато бесплатно. Вероятно, для простых текстов этот сайт можно применять, но рекомендовать его язык не поворачивается.
Scanоnline
Еще один русскоязычный OCR-сайт вы найдете по адресу www.scanonline.ru. Стартовые условия выглядят заманчиво — файл до 20 Мбайт, поддерживаются все популярные форматы изображений для распознавания, результаты работы будут высланы на указанный адрес электронной почты в виде текста, HTML или RTF. Ресурс владеет шестью языками.
Доступен бесплатный лимит на 5 Мбайт загружаемых изображений в день. Если нужно больше, то можно открыть доступ на сутки с помощью платной SMS по заявленной цене около 20 руб.
Качество распознавания хорошего исходного изображения можно оценить в 4 балла. Ошибок немного, скорость и качество распознавания на достойном уровне. А вот выявление текста на фотографии с телефона оказалось для данного ресурса непосильной задачей. Фактически полученный набор символов был малопригоден к дальнейшей работе. Таким образом, при его использовании нужно учитывать, что этот условно бесплатный сервис очень чувствителен к качеству изображения.
New OCR
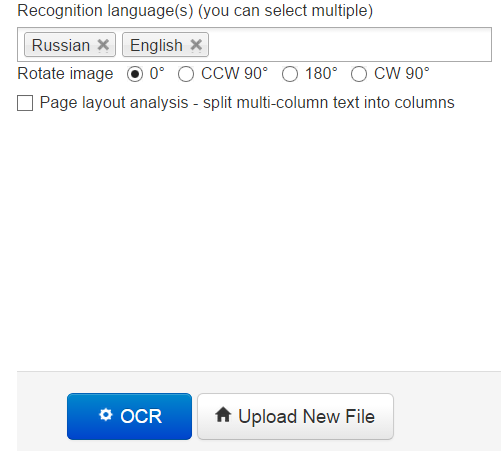
Ресурс New OCR (www.newocr.com) обещает совершенно бесплатное применение OCR-технологии к нашим отсканированным документам. И надо сказать, с неплохим функционалом — по своим возможностям данный сервис действительно неплох. Судите сами: 58 языков, два разных OCR-алгоритма на выбор, безлимитные загрузки без необходимости регистрации и бесплатно (!), все популярные форматы, в том числе многостраничные документы, и даже загрузки заархивированных файлов.
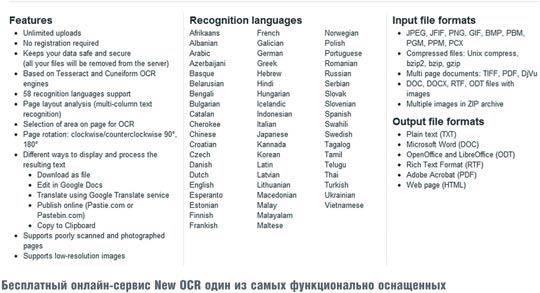
Для исходных изображений доступен целый букет сервисных функций. Во-первых, можно выбрать область распознаваемого текста, повернуть картинку, повысить контрастность и распознать текст колонками. Распознанный текст можно скачать во всех популярных текстовых форматах, включая ODT, отправить для публикации в «Документы Google» или, например, отправить напрямую в переводчик Google.
А что же с качеством непосредственно OCR? С качественными исходными материалами new OCR справился хорошо. Ошибок минимум, и лишь некоторая неразбериха с форматированием заставляет поставить минус к заслуженной пятерке. Можно попробовать улучшить результат, выбирая между двумя механизмами распознавания.
А вот с некачественным исходным материалом разобраться этому сервису не удалось. По существу, ничего полезного из картинки с низким разрешением и недостаточной четкостью извлечь ему не удалось. Несмотря на это, ресурс нам понравился, и рекомендуем занести его в закладки.
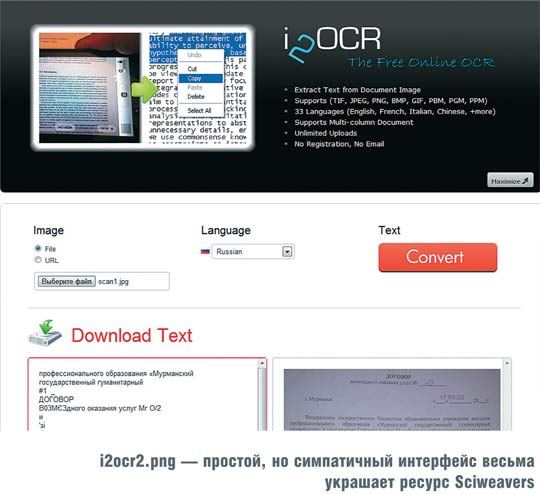
Sciweavers: i2OCR
Для полноты картины приведем еще один сайт. Ничего сверхвыдающегося он не обещает, зато бесплатен и имеет красивый интерфейс, в чем вы сможете убедиться сами, заглянув на www.sciweavers.org/free-online-ocr. Поддерживается 33 языка и все популярные графические форматы для исходного файла.
Качество распознавания не назовешь выдающимся, но на хорошей фотографии текст определяется с минимумом ошибок и почти не требует корректировки. С плохими изображениями беда, и от получающегося набора символов никакого толка. Зато бесплатно — это раз, и сопровождается целой охапкой других полезных сервисов по решению каждодневных задач конвертирования цифровых данных — это два.
Оценка по «чтению»
После ознакомления со всеми этими системами можно сделать некоторые выводы. Во-первых, — и это хорошая новость! — онлайн-сервисы по распознаванию текста есть, и они неплохо работают. Многие даже бесплатны, что, признаемся, стало приятным сюрпризом.
Во-вторых, снова подтвердился тезис, что в распознавании текста полдела — это качество снимка. Большинство OCR провалили тест на обработку изображения, сделанного мобильным телефоном. При этом материалы со сканера или качественный фотоснимок были обработаны неплохо. Значит, в «полевых» условиях необходимо обеспечить максимум света и разрешения при съемке, что обычно все-таки недоступно смартфонам даже выше среднего уровня.
Некоторые сервисы тем не менее справились и с «трудными» случаями, так что именно их мы уверенно ставим в лидеры обзора. Прежде всего это FineReader Оnline. Из бесплатных же онлайн-распознавателей лучше других себя показал New OCR. Поэтому именно этим двум сервисам мы присудили значок «Hard’n’Soft рекомендует».
Распознать и перевести!
В современном открытом мире часто бывает, что необходимо срочно понять, о чем идет речь на листе бумаги или в PDF-документе. Проблема в том, что он может быть на иностранном языке. Значит, в пару к OCR-ресурсу нужно найти онлайн-переводчик.
Рассмотренный нами в обзоре бесплатный сайт New OCR сразу после распознавания предлагает передать документ в Google Translate (translate.google.com). Это один из самых известных онлайн-переводчиков, который оперирует десятками языковых пар, при этом обладает простым интерфейсом и не содержит строгих ограничений на длину переводимого текста, так что отсканированный документ удастся прочитать сразу.
От автоматического перевода чудес в части совершенства ждать не приходится, тем не менее качество перевода Google Translate считается хорошим, и обычно именно этот сайт используют в первую очередь.
Альтернативное решение — это онлайн-сервис www.trans-late.ru отечественной компании ПРОМТ. Но здесь установлен лимит в 3 тыс. символов для единовременного перевода. Так что разворот книги пришлось переводить в два приема.
Используя эти или другие сервисы онлайн-переводов после оптического распознавания, проблема восприятия содержания материала на незнакомом языке должна просто сойти на нет. Еще бы объединить все самые лучшие достижения, да в одном интерфейсе, да бесплатно.
Источник: Hard’n’Soft
Автор: Роман Поликарпов
Источник: www.km.ru
Онлайн-сервисы и программы для оптического распознавания текста

С учётом переезда большинства информации, в том числе художественной и специальной литературы, в интернет, появилась необходимо в распознавании текста: скачать книгу не всегда возможно, а копировать фрагмент приходится через цитирования. Современные люди фотографируют нужные фрагменты, и чтобы не переписывать все от руки, были созданы специальные программы для распознавания текста.
Хорошие сервисы на бесплатной основе
Первый сервис — это Диск Гугл. Необходимо зарегистрироваться в браузере. Если пользователь имеет отношение к ведению блока на этом сервисе, ведению ютуб канала, то у него уже есть аккаунт.
Сервис позволяет распознавать изображения разных форматов, текстовые варианты. Главное условие — размер файла не может превышать 2 МБ.
Если для распознавания берётся текст в PDF, то система обработает только первые десять. Сохраняется работа в вордовском документе, блокноте, пдф-формате.

Второй сервис — i 2 OCR. Пользователю также придётся пройти регистрацию. Программа распознает следующие форматы:
Сервис позволяет загружать документы до 10 МБ. Результат преобразовывается в текстовый файл формата DOC.
Третий сервис — OCR CONVERT. Пользователю предоставляются услуги по распознаванию файлов на бесплатной основе и без регистрации. Поддерживаются различные форматы изображения. Результат сохраняется в виде интернет-ссылки, которая имеет расширение TXT. Пользователь может скопировать результат и вставить в любой файл.
На сервисе можно загружать одновременно пять документов, которые не превышают 5 МБ.
Четвёртый сервис — ONLINE OCR. Пользователю не нужно регистрироваться и платить деньги за работу программы. На сервисе можно распознать 15 изображений за час. Файлы принимаются разных форматов. Результат сохраняется в вордовском, текстовом формате, а также в таблице.
Минус сервиса — постоянная капча во время работы. Для распознавания доступно 32 языка
Пятый сервис — OcrOnline. Разработчики рекомендуют, чтобы изображения были в высоком качестве, формата JPG. Также можно использовать и другие форматы. Минус сервиса — за одну неделю распознаётся только 5 страниц.
Для расширения возможностей необходимо пройти регистрацию на сайте и заплатить символическую сумму. Результат работы сохраняется в различных текстовых форматах.
Программа FineReader
Файн ридер — это программа по оцифровке документов, разработанная компанией ABBYY. Какие услуги предоставляет компания:
Быстрым способом является оптическое распознавание текста онлайн. Это первый вариант, который предоставляется на сайте. Как это работает:
Система может распознавать текст не более 100 МБ. Можно загружать несколько файлов одновременно.
Основные возможности:
- Преобразование бумажных документов в текстовые форматы.
- Обработка сканов и фотографий на более чем 190 языках.
- Отправка документов на интернет-диск для хранения в течение 14 дней.
- Возможность скачивания программ для мобильных устройств и компьютера.
Сайт Convertio
Ещё одним способом распознавания текстов онлайн является сервис Convertio. Пользователь может бесплатно и без регистрации распознать 10 страниц, для увеличения количества придётся пройти регистрацию на сайте. Процедура распознавания текста:
- Выбрать файл. При помощи красной кнопки необходимо выбрать способ загрузки файла: с компьютера, ссылка интернета, Диск Гугл, из Dropbox.
- Выбрать язык. Есть четыре строки: для главного языка и три строки для дополнительного.
- Выбрать формат. Система предоставляет более пяти форматов.
- Ввести капчу.
- Выбрать вариант для сохранения результата.
- Преобразовать.

После чего можно скачать файл на компьютер или на интернет-диск.
Оцифровка текста с изображения
Первый сервис для сканирования текста с изображения — это IMG Online. Программа занимается опознаванием изображения в разных форматах — BMP, GIF, JPEG, PNG, TIFF.
Порядок действий:
Обработка данных длится около 20−60 секунд, после чего программа выдаст результат работы, который можно сохранить в удобном месте.
Ещё одним сервисом, который распознает текст с изображения, является Free online Ocr. На русский язык интернет-страница переводится автоматически. Распознаватель предоставляется бесплатно, также не нужна регистрация от пользователя. Порядок работы идентичный: необходимо загрузить файл с компьютера или ввести адрес сайта, выбрать язык и нажать на «Старт». После этого пользователю будет доступен файл для скачивания.
Можно воспользоваться сервисом NewOCR. Пользователю не нужно проходить регистрацию, предоставляется неограниченное количество загрузок. Обратить внимание необходимо и на cuneiform. Её нужно скачать напрямую или через торрент. Программа производит считывание текста со скриншотов.
Сервисов для распознавания текста достаточно. Работа с ними примерно одинаковая — загрузить файл, выбрать язык и формат полученного текста, скачать результат. С этой целью и нужны такие программы.
Originally posted 2018-04-07 11:51:15.
Источник: kompy.guru
Бесплатный онлайн инструмент OCR (Распознавание текста)
Преобразование отсканированных документов и изображений в редактируемые форматы Word, Pdf, Excel и Txt (простой текст)
Веб-сервис Free Online OCR

Free Online OCR – еще один бесплатный веб-сервис, очень похожий на предыдущий, но с расширенными функциями. Он:
- Он поддерживает 106 языков.
- Обрабатывайте многостраничные документы, в том числе на нескольких языках.
- Он распознает текст на отсканированных изображениях и фотодокументах многих типов. Помимо 10 форматов графических изображений, он управляет документами pdf, djvu, doxc, odt, zip-архивами и сжатыми файлами Unix.
- Сохраните выходные файлы в одном из 3-х форматов: txt, doc и pdf.
- Он поддерживает распознавание математических уравнений.
- Поворачивает изображение на 90–180 ° в обоих направлениях.
- Правильно распознает текст в нескольких столбцах на странице.
- Может распознать выбранный фрагмент.
- После обработки предлагает скопировать файл в буфер обмена, загрузить на компьютер, загрузить в сервис Google Docs или опубликовать в Интернете. Вы также можете мгновенно перевести текст на другой язык с помощью Google Translate или Bing Translator.
Мы должны отдать должное бесплатному онлайн-распознаванию текста за то, что оно хорошо читает изображения с низким разрешением и низкой контрастностью. Результат распознавания всех предоставленных ему русскоязычных текстов отказался быть стопроцентным или близким к нему.
Бесплатное онлайн-распознавание текста, на наш взгляд, является одной из лучших альтернатив FineReader, но оно обрабатывает бесплатно только 20 страниц (правда, на какой период не указано). Дальнейшее использование сервиса стоит от 0,5 доллара за страницу.
OCR CuneiForm

Бесплатная программа для чтения текстовой информации с изображений. Точность распознавания на порядок ниже, чем у предыдущей исследуемой программы. Но что касается бесплатной утилиты, то функциональность все равно отличная.
Интересный! CuneiForm распознает блоки текста, графики и даже различные таблицы. Также можно читать таблицы без строк.
Программа умеет читать и сохранять шрифт и размер распознанного текста. База шрифтов содержит большинство используемых гарнитур. Также поддерживается распознавание текста с пишущей машинки.
Для обеспечения точности к процессу распознавания прилагаются специальные словари, которые заполняют словарный запас отсканированных документов.
- бесплатное распространение;
- использовать словари для проверки правильности текста;
- отсканированные тексты с фотокопий плохого качества.
- относительно невысокая точность;
- поддерживается небольшое количество языков.
Веб-сервис Free-OCR.com

Free-OCR.com (OCR – Optical Character Recognition, Optical Character Recognition) – это бесплатный интернет-сервис для распознавания отсканированного или сфотографированного текста, сохраненного в формате графического изображения (jpg, gif, tiff, bmp) или pdf. Он поддерживает 29 языков, в том числе русский и украинский, причем пользователь может выбрать не один, а несколько, если исходный текст их содержит.
Free-OCR не требует регистрации и не имеет ограничений по количеству загружаемых документов. Ограничен только размер файла – до 6 Мб. Сервис не обрабатывает многостраничные документы, точнее игнорирует все, кроме первого листа.
Скорость распознавания отсканированного текста довольно высока. Лист формата А4 с фрагментом книги на русском языке обрабатывался примерно за 5 секунд, но качество было невысоким. Крупные шрифты – как в детских книжках их распознает на 100%, а средние и мелкие – примерно на 80%. Немного лучше обстоит дело с англоязычными документами: мелкий, малоконтрастный шрифт распознается правильно примерно на 95%.
Readiris

Программа Readiris от бельгийского разработчика IRIS действительно является настоящим конкурентом российской ABBYY FineReader. Мощный, быстрый, кроссплатформенный, основанный на запатентованном движке OCR, который используют производители Adobe, HP и Canon, он отлично распознает даже самые трудные для чтения тексты. Он поддерживает 137 языков, в том числе русский и украинский.
Возможности и функции Readiris:
- Самая высокая скорость обработки файлов среди приложений этого класса, рассчитана на большие объемы.
- Сохранение исходного форматирования текста (шрифты, размер, стиль письма).
- Обработка одиночных и пакетных файлов, поддержка многостраничных документов.
- Распознавание математических уравнений, специальных символов и штрих-кодов.
- Очистите текст от «шума» – линий, подтеков и т.д.
- Интеграция с различными облачными сервисами: Google Docs, Evernote, Dropbox, SharePoint и некоторыми другими.
- Поддержка всех современных моделей сканеров.
- Форматы входных данных: pdf, djvu, jpg, png и другие, в которых графические изображения сохраняются, а также принимаются непосредственно со сканера.
- Форматы выходных данных: doc, docx, xls, xlsx, txt, rtf, html, csv, pdf. Поддерживается преобразование в djvu.
Интерфейс программы русский, использование интуитивно понятно. Он не дает пользователям возможности редактировать содержимое pdf файлов, как FineReader, но с основной задачей: распознавание текста, на наш взгляд, отлично ладит.
Readiris доступен в двух платных версиях. Стоимость лицензии Pro составляет 99 евро, корпоративной – 199 евро. Почти как ABBYY.
Microsoft OneNote
Программа для создания заметок Microsoft OneNote, за исключением очень старой и более новой версии 17, также содержит функцию распознавания текста. Он не такой продвинутый, как в специализированных приложениях, но его можно использовать, даже если нет других вариантов.
Чтобы распознать текст на изображении с помощью OneNote, вставьте изображение в файл («Изображение» – «Вставить»), щелкните его правой кнопкой мыши и выберите «Копировать текст из изображения».

Затем вставьте скопированный текст в любое место заметки.
По умолчанию установлен английский язык распознавания. Если вам нужен русский или любой другой, пожалуйста, измените настройку вручную.
Качество распознавания русского текста в Microsoft OneNote оставляет желать лучшего, поэтому его нельзя назвать полноценной заменой FineReader. И обрабатывать в нем большие многостраничные документы очень неудобно.
SimpleOCR

Замечательная маленькая программа для распознавания текста по изображениям. Он также поддерживает чтение рукописей. Проблема в том, что русского нет ни в языковой пакет интерфейса, ни в список поддерживаемых языков для распознавания.
Однако, если вам нужно сканировать на английском, датском или французском языках, лучшего бесплатного варианта нет.
В своей области программа обеспечивает точное декодирование символов, удаление шума и извлечение графики. Кроме того, в интерфейс программы интегрирован текстовый редактор, практически идентичный WordPad, что значительно увеличивает удобство использования программы.
- точное распознавание текста;
- удобный текстовый редактор;
- убрать шум с изображения.
- полное отсутствие русского языка.
- https://convertio.co/ru/ocr/
- https://CompConfig.ru/software/programmy-i-servisy-dlya-skanirovaniya.html
- https://pomogaemkompu.temaretik.com/930401132721474208/5-besplatnyh-programm-dlya-skanirovaniya-i-raspoznavaniya-teksta/
Источник: www.dvenashka.ru