

- Flume — это распределенная, надежная и высокодоступная система сбора, агрегации и передачи массовых журналов.
Flume — это распределенная система сбора журналов, предоставляемая Cloudera. Она поддерживает настройку различных отправителей данных в системе журналов для сбора данных. В то же время Flume обеспечивает простую обработку данных и запись в различные приемники данных (настраиваемые, Такие как текст, HDFS, MySQL, HBase и т. Д.).
Основные понятия Flume
- Agent: Используйте JVM для запуска Flume. На каждой машине работает агент, но в агент может быть включено несколько источников и приемников.
- Client: Производственные данные запускаются в отдельном потоке.
- Source: Соберите данные с Клиента и передайте на Канал.
- Channel: Подключите источники и приемники, это немного похоже на очередь.
- Sink: Соберите данные из канала и запустите в отдельном потоке.
- Events: Могут быть записи журнала, объекты Avro и т. Д.
Базовая структура
Основная структурная схема

FLUME’s Favourite Synth And Advice For Artists
- Flume принимает Agent как наименьшее независимое операционное устройство, а Agent — это JVM.
- Один агент состоит из трех основных компонентов: Source, Sink и Channel.
- Через эти компоненты Event может передаваться из одного места в другое, например, HDFS на рисунке.
- Проще говоря, Flume собирает журналы.
Подробные компоненты
- Агент содержит: Source、Channel、Sink。
Аналогично архитектуре производителей, складов и потребителей. - Исходный компонент: Он посвящен сбору бревен.
может обрабатывать различные типы данных журнала в различных форматах, включая Avro, Thrift, Spooling Directory, Syslog, HTTP и пользовательские. После того как компонент «Источник» соберет данные, они временно сохранятся в канале. - Компонент канала: Он предназначен для временного хранения данных в агенте и может храниться в памяти, JDBC, файле и настраиваться. Данные на канале будут удалены только после успешной отправки.
- Компоненты раковины: Это компонент, используемый для отправки данных в место назначения.Предназначение включает HDFS, Logger, Avro, Thrift, File, null, HBase, Solr и пользовательские.
Широкое использование Flume

-
Flume может поддерживать многоуровневые агенты Flume, то есть Flume может быть последовательно
Например, Sink может записывать данные в источник следующего агента, так что они могут быть связаны в строку и могут быть обработаны в целом.
- Fan-in означает, что источник может принимать несколько входов
- Fanout означает, что Sink может выводить данные в несколько пунктов назначения
Событие подробно
Ядро Flume
Ядром Flume является сбор данных из источника данных (источник), а затем отправка собранных данных в указанное место назначения (приемник). Чтобы гарантировать, что процесс доставки должен быть успешным, данные будут кэшироваться (канал) перед отправкой в пункт назначения (приемник). После того, как данные действительно достигают назначения (приемник), Flume удаляет кэшированные данные.
Flume — The Producer Disc: A Few Tips
- Последовательность передачи данных: источник (сборник) -> канал (кеширование данных для обеспечения успешной передачи) -> приемник
Диаграмма потока данных о событиях

- Во всем процессе передачи потоком событий является событие, то есть гарантия транзакции выполняется на уровне события.
- Событие инкапсулирует передаваемые данные, которые являются основной единицей передачи данных Flume. Если это текстовый файл, то обычно это строка записей. Событие также является основной единицей транзакций.
- Событие передается из источника в канал, а затем в приемник, который является байтовым массивом и может нести информацию заголовков (информации заголовка)
- Событие представляет собой наименьшую полную единицу данных из внешнего источника данных во внешний пункт назначения.
Состав мероприятия

- event headers
- event body
- Информация о событии (то есть однострочные записи в текстовом файле), то есть записи дневника, собранные Flume
Установка Flume 1.7.0
- 1. Предпосылки
Установите JDK1.7 и выше и настройте переменные среды. - 2. Загрузите установочный пакет
Официальный сайт:http://flume.apache.org
URL загрузки:http://www.apache.org/dyn/closer.lua/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz
Номер версии: apache-flume-1.7.0-bin.tar.gz - 3. Загрузите на сервер Linux и разархивируйте
Команда распаковки: tar -zxvf apache-flume-1.7.0-bin.tar.gz
[[email protected] software]$ cd apache-flume-1.7.0-bin/conf/
2. Скопируйте файл конфигурации
[[email protected] conf]$ cp flume-env.sh.template flume-env.sh
3. Отредактируйте файл конфигурации
[[email protected] conf]$ vim flume-env.sh

4. Измените значение переменной JAVA_HOME
5. Настройте переменные среды
1. Отредактируйте .bash_profile
[[email protected] ~]$ vim /home/theone/.bash_profile
2. Добавьте переменные FLUME_HOME и PATH
export FLUME_HOME=/home/theone/Desktop/software/apache-flume-1.7.0-bin export PATH=$PATH:$FLUME_HOME/bin
3. Сделайте конфигурационный файл незамедлительным
[[email protected] ~]$ source /home/theone/.bash_profil
flume-ng version
FLume связанные приложения
Случай 1: источник данных Avro (передача указанного файла)

- 1, сцена
Два компьютера или два терминала, один для клиента и один для агента, передают указанный файл на агенте на компьютер агента. - 2. Требования
Прослушивание указанного порта Avro, и файлы, отправленные клиентом Avro, можно получить через порт Avro. То есть, пока приложение отправляет файл через порт Avro, компонент Source может получать содержимое файла.
(Примечание: Avro и Thrift — это некоторые сериализованные сетевые порты, через эти сетевые порты можно получать или отправлять информацию, Avro может отправлять указанный файл в Flume, источник Avro использует AVRO RPC механизм).
- 3. Блок-схема
В этом случае Avro Source используется для получения внешнего источника данных, а Logger используется в качестве приемника, то есть вызов Avro RPC используется для кэширования данных в канале, а затем данные, отправленные вызовом, распечатываются через Logger.
Создайте avro.conf в каталоге FLUME_HOME / conf
[[email protected] conf]$ touch avro.conf
Или создайте файл конфигурации avro.conf в соответствии с шаблоном, предоставленным самой Flume
[th[email protected] conf]$ cp flume-conf.properties.template avro.conf
- (2) Отредактируйте файл конфигурации avro.conf
[[email protected] conf]$ vim avro.conf ## Name the components on this agent agent1.sources = avro_source1 agent1.channels = memory_ch1 agent1.sinks = log_sink1 ## Describe/configure the source agent1.sources.avro_source1.type = avro agent1.sources.avro_source1.channels = memory_ch1 # Источник avro должен указывать IP и номер порта контролируемого хоста # Отслеживаемое имя хоста или IP-адрес. 0.0.0.0 представляет все неясные хосты и сети назначения, что означает всю сеть, то есть все хосты в сети. agent1.sources.avro_source1.bind=0.0.0.0 # Номер порта прослушивания agent1.sources.avro_source1.port=4141 ## Describe the sink # Logger Sink Record Журнал уровня INFO, обычно используемый для отладки. agent1.sinks.log_sink1.type = logger agent1.sinks.log_sink1.channel = memory_ch1 ## Использовать канал, который буферизует события в памяти, канал — это пространство памяти agent1.channels.memory_ch1.type = memory # Емкость — это максимальная емкость, а transCapacity — это максимальное количество событий, каждый раз передаваемых Channel, Capacity> = transCapacity. agent1.channels.memory_ch1.capacity=1000 agent1.channels.memory_ch1.transactionCapacity=100
echo «hello theone» > /home/theone/Desktop/software/data/avro.txt

-
5. Используйте авро-клиент для отправки файлов
Поскольку текущая среда должна моделировать две машины на одной машине, выполните следующие команды непосредственно в новом терминале:
flume-ng avro-client -c conf -H 0.0.0.0 -p 4141 -F /home/theone/Desktop/software/data/avro.txt

Случай 2: источник данных Spooldir (прослушивание указанного каталога)
Следите за указанным каталогом, то есть до тех пор, пока приложение добавляет новый файл в указанный каталог, компонент Source может получать информацию, анализировать содержимое файла, затем записывать его в Channle и, наконец, загружать его в HDFS. После завершения записи пометьте файл как завершенный или удалите файл.
-
1. Отредактируйте файл конфигурации spooldir.conf
[software/data/[email protected] conf]$ vim spooldir.conf ## Name the components on this agent agent1.sources = spool_source1 agent1.channels = memory_ch1 agent1.sinks = hdfs_sink1 ## Describe/configure the source agent1.sources.spool_source1.type = spooldir # Настройте источник каталога, чтобы отслеживать изменения каталога (каталог должен быть создан заранее), а имя файла должно быть уникальным, иначе Flume сообщит об ошибке agent1.sources.spool_source1.spoolDir=/home/theone/Desktop/software/data/flumedata # Настроить передачу данных в memory_ch1 agent1.sources.spool_source1.channels = memory_ch1 # Добавлять ли имя файла в заголовок события, логический тип, по умолчанию false agent1.sources.spool_source1.basenameHeader = true # Если в событии есть заголовок (для basenameHeader установлено значение true), заголовок события будет хранить информацию имени файла, ключ по умолчанию — это имя базы, а значение — это имя файла (исключая часть каталога), а именно имя базы = Имя файла agent1.sources.spool_source1.basenameHeaderKey = basename ## Describe the sink agent1.sinks.hdfs_sink1.type = hdfs # Данные хранятся в каталоге на HDFS agent1.sinks.hdfs_sink1.hdfs.path=hdfs://hadoop01:9000/flumedata/%Y-%m-%d # Префикс имени использует имя файла перед загрузкой agent1.sinks.hdfs_sink1.hdfs.filePrefix = % # Формат потока данных, по умолчанию — sequenceFile, но содержимое внутри не может быть открыто непосредственно для просмотра agent1.sinks.hdfs_sink1.hdfs.fileType=DataStream # Формат записи файла включает в себя текст agent1.sinks.hdfs_sink1.writeFormat=TEXT # Прокрутка файлов по времени, единицам секунд, по умолчанию 30 секунд, 0 не прокручивается agent1.sinks.hdfs_sink1.hdfs.rollInterval=0 # Прокрутка файлов по размеру файла, в единицах байтов, 10M = 10485760B agent1.sinks.hdfs_sink1.hdfs.rollSize=10485760 # Когда число событий достигнет этого числа, сверните временный файл в целевой файл, по умолчанию 10, 0 не зависит от количества сообщений agent1.sinks.hdfs_sink1.hdfs.rollCount=0 # Закрыть недействительные файлы после тайм-аута, 0 запрещено автоматически закрывать пустые файлы agent1.sinks.hdfs_sink1.hdfs.idleTimeout=60 # HDFS Sink Использовать ли местное время, по умолчанию установлено значение false agent1.sinks.hdfs_sink1.hdfs.useLocalTimeStamp=true # Настроить получение данных из memory_ch1 agent1.sinks.hdfs_sink1.channel = memory_ch1 ## Использовать канал, который буферизует события в памяти, канал — это пространство памяти agent1.channels.memory_ch1.type = memory # Емкость — это максимальная емкость, а transCapacity — это максимальное количество событий, каждый раз передаваемых Channel, Capacity> = transCapacity. agent1.channels.memory_ch1.capacity=1000 agent1.channels.memory_ch1.transactionCapacity=100 Эта конфигурация будет генерировать много небольших файлов, потому что по умолчанию файл хранит 10 событий, эта конфигурация контролируется rollCount, по умолчанию 10. Кроме того, есть параметр для rollSize, который должен контролировать размер файла, если файл больше этого значения, это новый файл. Здесь мы устанавливаем rollSize равным 10M, то есть файл, загруженный в HDFS, будет другим файлом, который будет записан после того, как он превысит 10M; Все имена файлов по умолчанию начинаются с Event, потому что я хочу сохранить исходное имя файла, поэтому я использовал следующую конфигурацию (где basenameHeader относительно источника, filePrefix относительно приемника, после этого параметра загрузите в HDFS Имя файла станет «исходное имя файла. Отметка времени»).
- 3. Создайте каталог прослушивания
[[email protected] ~]$ mkdir /home/theone/Desktop/software/data/flumedata/

4. Запустите Flume Agent agent1.
flume-ng agent -n agent1 -c conf -f conf/spooldir.conf -Dflume.root.logger=INFO,console
[[email protected] flumedata]$ cd /home/theone/Desktop/software/data [[email protected] test]$ cp rating.json /home/theone/Desktop/software/data/flumedata/

6. Просмотр результатов
отслеживать производительность в каталоге 
Обнаружено, что имя файла становится «file name.COMPLATED», это означает, что файл был записан.
Эффект на HDFS 
Когда idleTimeout = 60, rollSize установлен в 10M, принцип таков, правила именования для каждого полученного файла, сгенерированного в Flume. Например: rating.json.1500274365422.tmp, .tmp указывает, что этот файл используется для получения событий. Когда его размер превышает 10 МБ, этот файл будет переименован в rating.json.1500274365422, удалите суффикс .tmp, но если вы остановите После приложения значение rating.json.1500274365422 составляет менее 10 м. Согласно значению по умолчанию idleTimeout = 0 (отключить автоматическое закрытие файлов в режиме ожидания), оно не будет переименовано, то есть используется суффикс .tmp, в результате чего этот файл будет использоваться. Одной из иллюзий является проблема: мы устанавливаем idleTimeout = 60, то есть файл не записывается в данные через 60 секунд, он закрывает его, а затем переименовывает, чтобы удалить .tmp, и новые входящие события будут открыты. Файл .tmp для получения.
На рисунке выше последний файл имеет размер только 1,6 МБ, поскольку после записи 1,6 МБ файлы в каталоге мониторинга были записаны.
Источник: russianblogs.com
Flume — управляем потоками данных. Часть 1

2016-03-29 в 15:44, admin , рубрики: big data, flume, Hadoop, Анализ и проектирование систем, Блог компании DCA (Data-Centric Alliance), разработка, хранение данных
Привет! В этом цикле статей я планирую рассказать о том, как можно организовать сбор и передачу данных с помощью одного из инструментов Hadoop — Apache Flume.

Первая статья посвящается основным элементам Flume, их настройкам и способам запуска Flume. На просторах Хабра уже имеется статья о том, как работать с Flume, поэтому некоторые базовые разделы будут во многом схожи с ней.
В продолжении цикла я постараюсь более подробно осветить каждый из компонентов Flume, рассказать о том, как настроить мониторинг для него, написать свою реализацию одного из элементов и многое другое.
1. Что такое Flume?
Flume представляет собой инструмент, позволяющий управлять потоками данных и, в конечном счете, передавать их на некоторый “пункт назначения” (например, в файловую систему или HDFS).
В целом, организация транспортировки данных посредством Flume напоминает создание эдакого “конвейера” или “водопровода”. Этот “конвейер” состоит из различных участков (узлов), на которых и происходит управление потоком данных (фильтрация, разделение потока и т.п.).
Flume является надежным и удобным инструментом для транспортировки данных. Надежность обеспечивается в первую очередь транзакционностью передачи данных. Т.е. при правильной настройке цепочки узлов Flume не может быть ситуации, при которой данные потеряются или будут переданы не полностью. Удобство же заключается в гибкости конфигурации — большинство задач решаются добавлением в конфигурацию нескольких параметров, а более сложные могут быть решены путем создания собственных элементов Flume.
Для начала обозначим основные термины, а затем мы рассмотрим структуру одиночного узла Flume.
2. Основные термины
- Событие (event) — единица данных с дополнительной мета-информацией. По структуре событие напоминает POST-запрос.
- Заголовки (headers) — мета-информация, набор пар “ключ”-”значение”.
- Содержимое (body) — собственно, данные, ради передачи которых всё затевается. Передается как byte[].
3. Структура узла Flume
Правильнее было бы назвать этот подраздел “Структура агента Flume”, т.к. узел Flume может состоять из нескольких агентов. Но в рамках данной статьи все примеры будут приводиться как “один узел — один агент”, поэтому я позволю себе вольность и пока не буду разделять эти понятия.
Рассмотрим несколько конфигураций для различных жизненных случаев.
Простой узел
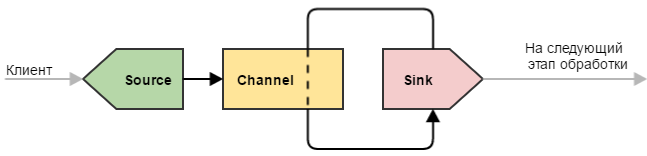
Под простым узлом я подразумеваю самую минималистичную конфигурацию Flume, которая только может быть: источник #8594 сток.
Такую конфигурацию можно использовать для простых целей — например, узел является замыкающим в цепочке узлов нашего «водопровода» и выполняет всего одну роль: принимает данные и записывает их в файл (непосредственно записью занимается сток). Или же узел является промежуточным и просто передает данные дальше (иногда это полезно делать для обеспечения отказоустойчивости — например, развернуть такой узел на машине с Flume-клиентом, чтобы избежать потери данных при проблемах с сетью).
Делитель
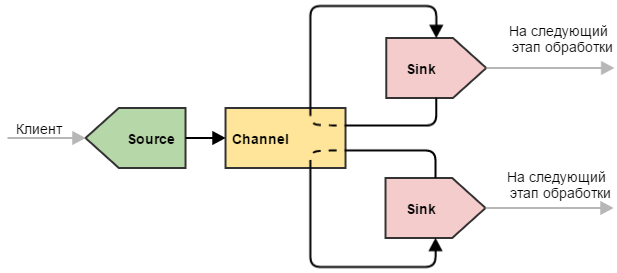
Более сложный пример, который может быть использован для разделения данных. Здесь ситуация немного другая по сравнению с одиночным стоком: наш канал опустошают два стока. Это приводит к тому, что поступающие события делятся между двумя стоками (не дублируются, а именно делятся). Такую конфигурацию можно использовать, чтобы разделить нагрузку между несколькими машинами.
При этом, если одна из конечных машин выйдет из строя и привязанный к ней сток не сможет отправлять на нее события, другие стоки продолжат работу в штатном режиме. Естественно, что при этом работающей машине придется отдуваться за двоих.
Примечание: Flume располагает более тонкими инструментами для балансировки нагрузки между стоками, для этого используются Flume Sink Processor’ы. О них речь пойдет в следующих частях цикла.
Дубликатор
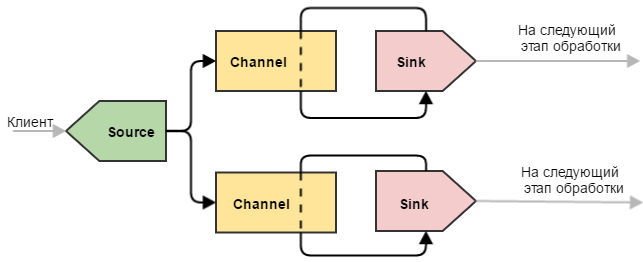
Такой узел Flume позволяет отправлять одни и те же события на несколько стоков. Может возникнуть вопрос — а зачем два канала, разве не может канал дублировать события сразу на два стока? Ответ — нет, поскольку не «канал раздает события», а «сток опустошает канал».
Даже если бы такой механизм и существовал, то выход из строя одного из стоков привел бы к неработоспособности других (т.к. каналу бы пришлось работать по принципу “либо все смогли, либо никто”). Это объясняется тем, что при сбое на уровне стока отсылаемая пачка событий не исчезает «в никуда», а остается лежать в канале. Ибо транзакция.
Примечание: в данном примере используется безусловное дублирование — т.е. в оба канала копируется все подряд. Flume позволяет не дублировать, а разделять события по некоторым условиям — для этого используется Flume Channel Selector. О нем речь также пойдет в следующих статьях цикла.
Универсальный приемник
Еще один полезный вариант конфигурации — с несколькими источниками. Крайне полезная конфигурация, когда необходимо “слить воедино” однотипные данные, полученные различными способами.
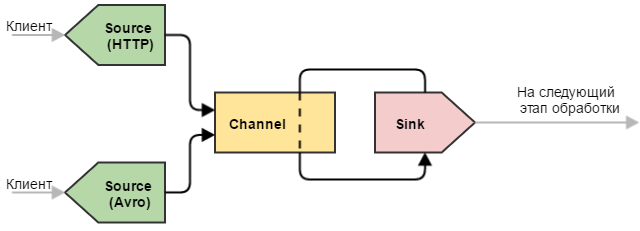
- Узел может иметь в своем составе множество источников, каналов и стоков.
- Один источник может складывать события в несколько каналов (дублировать или распределять по некоторому правилу).
- Несколько источников складывать события в один канал.
- Один сток может работать только с одним каналом.
- Несколько стоков могут забирать события из одного канала (равномерно или по некоторому правилу балансировки).
4. Конфигурация и запуск узла Flume
Думаю, пришло время практических примеров. Стандартный пакет Flume содержит множество реализаций источников/каналов/стоков для разных случаев жизни — описание по их настройке можно найти здесь. В рамках этой статьи я ограничусь самыми простыми реализациями компонентов:
- Memchannel (канал, использующий оперативную память для хранения событий).
- NetCat Source.
- Logger Sink (сток, выводящий события в консоль).
Пожалуй так выглядит самая простая конфигурация для узла Flume:
### ==================== Компоненты узла ==================== ### # Перечисляем все основные компоненты, из которых будет состоять наш узел: источники, каналы и узлы # .sources — имена источников, разделенные пробелом (в этом примере один источник: my_source) my_agent.sources = my_source # .channels — аналогично указываем имена каналов my_agent.channels = my_channel # .sinks — для стоков то же самое my_agent.sinks = my_sink ### ==================== Источник my_source ================== ### # Тип источника — netcat (источники из стандартной поставки Flume имеют зарезервированные имена-псевдонимы, # в общем случае здесь можно указать полное имя класса источника, в т.ч., вашего собственного) my_agent.sources.my_source.type = netcat # Указываем, куда биндить наш исчтоник my_agent.sources.my_source.bind = 0.0.0.0 my_agent.sources.my_source.port = 11111 # Указываем источнику канал (или список каналов, через пробел), куда отправлять полученные события my_agent.sources.my_source.channels = my_channel ### ==================== Канал my_channel ================== ### # Используем тип канала из пакета Flume — memory (как и с источником, здесь можно казать свой класс), который хранит события в памяти my_agent.channels.my_channel.type = memory # Вместимость канала, кол_во событий my_agent.channels.my_channel.capacity = 10000 # Число событий в одной транзакции (как на добавление, так и на «вытягивание») my_agent.channels.my_channel.transactionCapacity = 100 ### ==================== Сток my_sink ================== ### # Тип стока — логгер, пишуший события в консоль (и здесь также можно указать свой класс) my_agent.sinks.my_sink.type = logger # Из какого канала будем забирать события my_agent.sinks.my_sink.channel = my_channel # Настройка исключительно для стока типа logger — сколько первых байт тела события выводить в консоль my_agent.sinks.my_sink.maxBytesToLog = 256
Осталось теперь запустить узел с нашей конфигурацией. Сделать это можно двумя способами:
- На кластере Hadoop, через Cloudera Manager (в этой статье есть подробное описание того, как это сделать).
- Как Java-сервис, используя библиотеки Flume.
Поскольку процесс запуска Flume средствами Cloudera Manager освещен достаточно подробно, рассмотрим второй вариант — с помощью Java.
Прежде всего необходимо добавить зависимости Flume к нашему проекту. Для этого добавим в pom.xml репозиторий Clodera и два артефакта Flume — ng-sdk и ng-node.
cloudera https://repository.cloudera.com/artifactory/cloudera-repos/ org.apache.flume flume-ng-sdk 1.5.0-cdh5.3.0 org.apache.flume flume-ng-node 1.5.0-cdh5.3.0
После этого создадим класс с точкой входа:
package ru.flume.samples; import org.apache.flume.node.Application; public class FlumeLauncher < public static void main(String[] args) < // файл с конфигурацией Log4j я позволю себе указать прямо здесь System.setProperty(«log4j.configuration», «file:/flume/config/log4j.properties»); // Запускаем Flume с параметрами: Application.main(new String[]< «-f», «/flume/config/sample.conf», // путь до файла с конфигурацией «-n», «my-agent» // имя агента >); > >
Читатели, знакомые с Java, заметят, что можно вообще не создавать этот класс, а просто скопировать необходимые зависимости для Flume в отдельную папку и запустить Java с нужными аргументами командной строки. Но это уже дело вкуса — я предпочитаю, чтобы Maven сам подтягивал все необходимые зависимости, в том числе и разработанные нами компоненты Flume, и аккуратно всё это заворачивал в deb-пакет.
Если все пути указаны верно, а конфигурация не содержит ошибок, мы увидим в консоле вот такой лог от Flume.
Вывод Flume, если всё получилось
Чтобы убедиться, что всё работает корректно, отправим нашему NetCat-источнику небольшой тестовый файл test.txt, в котором содержится 4 строки:
Message 1 Message 2 Message 3
Важно, чтобы файл оканчивался переносом строки. Для NetCat-источника он является разделителем событий. Если мы не добавим в конец файла этот перенос строки, то источник будет считать, что последнее событие пришло не полностью. В результате этого он будет упорно ждать разделителя, который, естественно, никогда не придет. Итак, выполняем команду:
nc 127.0.0.1 11111 < test.txt
В результате этого NetCat должен вывести на экран три сообщения «ОК», как подтверждение того, что все строки файла благополучно отправлены и получены источником Flume. В это же время, сток должен вывести в консоль вот такие сообщения:
sink.LoggerSink — Event: < headers:<>body: 4D 65 73 73 61 67 65 20 31 0D Message 1. > sink.LoggerSink — Event: < headers:<>body: 4D 65 73 73 61 67 65 20 32 0D Message 2. > sink.LoggerSink — Event: < headers:<>body: 4D 65 73 73 61 67 65 20 33 0D Message 3. >
Примечание: Flume при запуске регистрирует свой shutdownHook, поэтому нет необходимости вручную высвобождать какие-либо ресурсы (соединения, открытые файлы и т.п.) — все компоненты узла самостоятельно завершат работу вместе с JVM.
5. Цепочка узлов Flume
Итак, мы разобрались, как настроить и запустить одиночный узел Flume. Однако для управления потоками данных одного узла явно маловато. Попробуем построить небольшую цепочку из трех узлов, выполняющих задачу деления (по сути — балансировка): первый узел Flume принимает информацию от клиента и отправляет события на два других узла. При этом события не дублируются на втором и третьем узлах, а равномерно распределяются между ними.
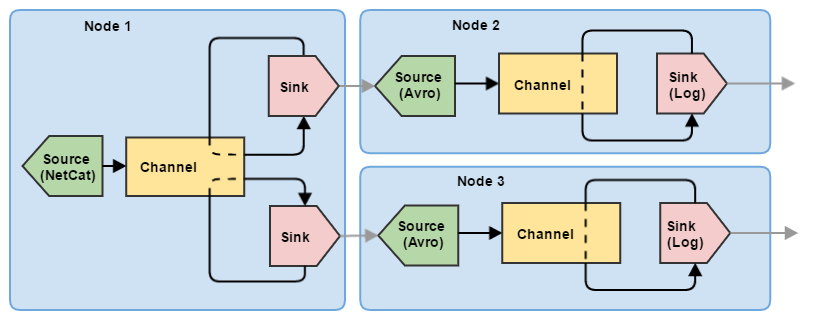
Соответственно, для такой схемы необходимо несколько конфигураций (для каждого узла — своя).
Конфигурация для узла 1 (node1.conf)
node1.sources = my-source node1.channels = my-channel # Теперь здесь 2 стока: node1.sinks = my-sink1 my-sink2 node1.sources.my-source.type = netcat node1.sources.my-source.bind = 0.0.0.0 node1.sources.my-source.port = 11111 node1.sources.my-source.channels = my-channel node1.channels.my-channel.type = memory node1.channels.my-channel.capacity = 10000 node1.channels.my-channel.transactionCapacity = 100 # Оба стока делаем с типом avro, они будут опустошать наш единственный канал вдвоем # Хосты принимающих узлов я оставлю локальными, чтобы всю эту цепочку можно было # попробовать запустить на одной машине node1.sinks.my-sink1.type = avro node1.sinks.my-sink1.channel = my-channel node1.sinks.my-sink1.hostname = 127.0.0.1 node1.sinks.my-sink1.port = 11112 node1.sinks.my-sink1.batch-size = 100 node1.sinks.my-sink2.type = avro node1.sinks.my-sink2.channel = my-channel node1.sinks.my-sink2.hostname = 127.0.0.1 node1.sinks.my-sink2.port = 11113 node1.sinks.my-sink2.batch-size = 100
Конфигурация для узла 2 (node2.conf)
node2.sources = my-source node2.channels = my-channel node2.sinks = my-sink # Поскольку на узле 1 сток имеет тип avro, здесь мы указываем источник типа avro node2.sources.my-source.type = avro node2.sources.my-source.bind = 0.0.0.0 node2.sources.my-source.port = 11112 node2.sources.my-source.channels = my-channel node2.channels.my-channel.type = memory node2.channels.my-channel.capacity = 10000 node2.channels.my-channel.transactionCapacity = 100 node2.sinks.my-sink.type = logger node2.sinks.my-sink.channel = my-channel node2.sinks.my-sink.maxBytesToLog = 256
Конфигурация для узла 3 (node3.conf)
node3.sources = my-source node3.channels = my-channel node3.sinks = my-sink # Поскольку на узле 1 сток имеет тип avro, здесь мы указываем источник типа avro node3.sources.my-source.type = avro node3.sources.my-source.bind = 0.0.0.0 node3.sources.my-source.port = 11113 node3.sources.my-source.channels = my-channel node3.channels.my-channel.type = memory node3.channels.my-channel.capacity = 10000 node3.channels.my-channel.transactionCapacity = 100 node3.sinks.my-sink.type = logger node3.sinks.my-sink.channel = my-channel node3.sinks.my-sink.maxBytesToLog = 256
Конфигурации для узлов 2 и 3 в данном примере идентичны, отличаются только номерами портов. Также для связи между узлами здесь используются стандартные компоненты Flume: Avro источник и Avro сток. Подробнее они будут описаны в следующих статьях, пока же нам достаточно того, что Avro Sink может отправлять по сети события, а Avro Source может их принимать.
Соответственно, запускаться каждый из узлов должен в отдельном процессе, а параметры запуска будут выглядеть следующим образом:
Application.main(new String[]); // для других узлов по аналогии: //Application.main(new String[]); //Application.main(new String[]);
Можно убедиться в работоспособности этой конфигурации, скормив первому узлу текстовый файл с сотней строк (маленькие порции данных могут пачкой отправиться на один из узлов и желаемого эффекта разделения данных мы не увидим).
Заключение
Эта статья является ознакомительной, приведенные здесь примеры конфигурации узлов Flume могут пригодиться лишь для отладки или знакомства с этим инструментом. В реальных проектах топология Flume выходит далеко за рамки одного-двух узлов, а конфигурации компонентов являются куда более сложными.
В следующей статье:
- Использование заголовков и канальных селекторов (Channel Selector).
- «Боевые» компоненты Flume:
- Avro Source;
- File Channel;
- Avro Sink;
- HDFS Sink;
- File Roll Sink.
Использованные источники и полезные ссылки
- Официальная страница Apache Flume
- Официальный гайд по настройке компонентов Flume
- Hadoop, часть 2: сбор данных через Flume | Блог компании Селектел — статья о настройке Flume средствами Cloudera.
- Hari Shreedharan: Using Flume — неплохая книга, описывающая возможности Flume.
Источник: www.pvsm.ru
Flume — управляем потоками данных. Часть 1
Привет, Хабр! В этом цикле статей я планирую рассказать о том, как можно организовать сбор и передачу данных с помощью одного из инструментов Hadoop — Apache Flume.

Первая статья посвящается основным элементам Flume, их настройкам и способам запуска Flume. На просторах Хабра уже имеется статья о том, как работать с Flume, поэтому некоторые базовые разделы будут во многом схожи с ней.
В продолжении цикла я постараюсь более подробно осветить каждый из компонентов Flume, рассказать о том, как настроить мониторинг для него, написать свою реализацию одного из элементов и многое другое.
1. Что такое Flume?
Flume представляет собой инструмент, позволяющий управлять потоками данных и, в конечном счете, передавать их на некоторый “пункт назначения” (например, в файловую систему или HDFS).
В целом, организация транспортировки данных посредством Flume напоминает создание эдакого “конвейера” или “водопровода”. Этот “конвейер” состоит из различных участков (узлов), на которых и происходит управление потоком данных (фильтрация, разделение потока и т.п.).
Flume является надежным и удобным инструментом для транспортировки данных. Надежность обеспечивается в первую очередь транзакционностью передачи данных. Т.е. при правильной настройке цепочки узлов Flume не может быть ситуации, при которой данные потеряются или будут переданы не полностью. Удобство же заключается в гибкости конфигурации — большинство задач решаются добавлением в конфигурацию нескольких параметров, а более сложные могут быть решены путем создания собственных элементов Flume.
Для начала обозначим основные термины, а затем мы рассмотрим структуру одиночного узла Flume.
2. Основные термины
- Событие (event) — единица данных с дополнительной мета-информацией. По структуре событие напоминает POST-запрос.
- Заголовки (headers) — мета-информация, набор пар “ключ”-”значение”.
- Содержимое (body) — собственно, данные, ради передачи которых всё затевается. Передается как byte[].
3. Структура узла Flume
Правильнее было бы назвать этот подраздел “Структура агента Flume”, т.к. узел Flume может состоять из нескольких агентов. Но в рамках данной статьи все примеры будут приводиться как “один узел — один агент”, поэтому я позволю себе вольность и пока не буду разделять эти понятия.
Рассмотрим несколько конфигураций для различных жизненных случаев.
Простой узел
Под простым узлом я подразумеваю самую минималистичную конфигурацию Flume, которая только может быть: источник → канал → сток.
Такую конфигурацию можно использовать для простых целей — например, узел является замыкающим в цепочке узлов нашего «водопровода» и выполняет всего одну роль: принимает данные и записывает их в файл (непосредственно записью занимается сток). Или же узел является промежуточным и просто передает данные дальше (иногда это полезно делать для обеспечения отказоустойчивости — например, развернуть такой узел на машине с Flume-клиентом, чтобы избежать потери данных при проблемах с сетью).
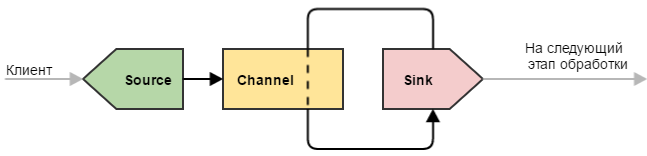
Делитель
Более сложный пример, который может быть использован для разделения данных. Здесь ситуация немного другая по сравнению с одиночным стоком: наш канал опустошают два стока. Это приводит к тому, что поступающие события делятся между двумя стоками (не дублируются, а именно делятся). Такую конфигурацию можно использовать, чтобы разделить нагрузку между несколькими машинами.
При этом, если одна из конечных машин выйдет из строя и привязанный к ней сток не сможет отправлять на нее события, другие стоки продолжат работу в штатном режиме. Естественно, что при этом работающей машине придется отдуваться за двоих.

Примечание: Flume располагает более тонкими инструментами для балансировки нагрузки между стоками, для этого используются Flume Sink Processor’ы. О них речь пойдет в следующих частях цикла.
Дубликатор
Такой узел Flume позволяет отправлять одни и те же события на несколько стоков. Может возникнуть вопрос — а зачем два канала, разве не может канал дублировать события сразу на два стока? Ответ — нет, поскольку не «канал раздает события», а «сток опустошает канал».
Даже если бы такой механизм и существовал, то выход из строя одного из стоков привел бы к неработоспособности других (т.к. каналу бы пришлось работать по принципу “либо все смогли, либо никто”). Это объясняется тем, что при сбое на уровне стока отсылаемая пачка событий не исчезает «в никуда», а остается лежать в канале. Ибо транзакция.
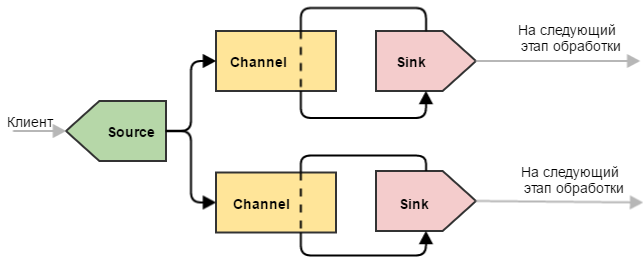
Примечание: в данном примере используется безусловное дублирование — т.е. в оба канала копируется все подряд. Flume позволяет не дублировать, а разделять события по некоторым условиям — для этого используется Flume Channel Selector. О нем речь также пойдет в следующих статьях цикла.
Универсальный приемник
Еще один полезный вариант конфигурации — с несколькими источниками. Крайне полезная конфигурация, когда необходимо “слить воедино” однотипные данные, полученные различными способами.
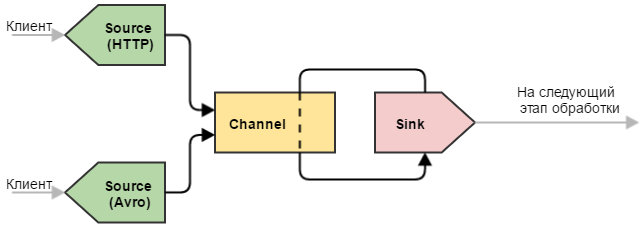
- Узел может иметь в своем составе множество источников, каналов и стоков.
- Один источник может складывать события в несколько каналов (дублировать или распределять по некоторому правилу).
- Несколько источников складывать события в один канал.
- Один сток может работать только с одним каналом.
- Несколько стоков могут забирать события из одного канала (равномерно или по некоторому правилу балансировки).
4. Конфигурация и запуск узла Flume
Думаю, пришло время практических примеров. Стандартный пакет Flume содержит множество реализаций источников/каналов/стоков для разных случаев жизни — описание по их настройке можно найти здесь. В рамках этой статьи я ограничусь самыми простыми реализациями компонентов:
- Memchannel (канал, использующий оперативную память для хранения событий).
- NetCat Source.
- Logger Sink (сток, выводящий события в консоль).
### ==================== Компоненты узла ==================== ### # Перечисляем все основные компоненты, из которых будет состоять наш узел: источники, каналы и узлы # .sources — имена источников, разделенные пробелом (в этом примере один источник: my_source) my-agent.sources = my-source # .channels — аналогично указываем имена каналов my-agent.channels = my-channel # .sinks — для стоков то же самое my-agent.sinks = my-sink ### ==================== Источник my_source ================== ### # Тип источника — netcat (источники из стандартной поставки Flume имеют зарезервированные имена-псевдонимы, # в общем случае здесь можно указать полное имя класса источника, в т.ч., вашего собственного) my-agent.sources.my-source.type = netcat # Указываем, куда биндить наш исчтоник my-agent.sources.my-source.bind = 0.0.0.0 my-agent.sources.my-source.port = 11111 # Указываем источнику канал (или список каналов, через пробел), куда отправлять полученные события my-agent.sources.my-source.channels = my-channel ### ==================== Канал my_channel ================== ### # Используем тип канала из пакета Flume — memory (как и с источником, здесь можно казать свой класс), который хранит события в памяти my-agent.channels.my-channel.type = memory # Вместимость канала, кол_во событий my-agent.channels.my-channel.capacity = 10000 # Число событий в одной транзакции (как на добавление, так и на «вытягивание») my-agent.channels.my-channel.transactionCapacity = 100 ### ==================== Сток my_sink ================== ### # Тип стока — логгер, пишуший события в консоль (и здесь также можно указать свой класс) my-agent.sinks.my-sink.type = logger # Из какого канала будем забирать события my-agent.sinks.my-sink.channel = my-channel # Настройка исключительно для стока типа logger — сколько первых байт тела события выводить в консоль my-agent.sinks.my-sink.maxBytesToLog = 256
Осталось теперь запустить узел с нашей конфигурацией. Сделать это можно двумя способами:
- На кластере Hadoop, через Cloudera Manager (в этой статье есть подробное описание того, как это сделать).
- Как Java-сервис, используя библиотеки Flume.
Прежде всего необходимо добавить зависимости Flume к нашему проекту. Для этого добавим в pom.xml репозиторий Clodera и два артефакта Flume — ng-sdk и ng-node.
cloudera https://repository.cloudera.com/artifactory/cloudera-repos/ org.apache.flume flume-ng-sdk 1.5.0-cdh5.3.0 org.apache.flume flume-ng-node 1.5.0-cdh5.3.0
После этого создадим класс с точкой входа:
package ru.flume.samples; import org.apache.flume.node.Application; public class FlumeLauncher < public static void main(String[] args) < // файл с конфигурацией Log4j я позволю себе указать прямо здесь System.setProperty(«log4j.configuration», «file:/flume/config/log4j.properties»); // Запускаем Flume с параметрами: Application.main(new String[]< «-f», «/flume/config/sample.conf», // путь до файла с конфигурацией «-n», «my-agent» // имя агента >); > >
Читатели, знакомые с Java, заметят, что можно вообще не создавать этот класс, а просто скопировать необходимые зависимости для Flume в отдельную папку и запустить Java с нужными аргументами командной строки. Но это уже дело вкуса — я предпочитаю, чтобы Maven сам подтягивал все необходимые зависимости, в том числе и разработанные нами компоненты Flume, и аккуратно всё это заворачивал в deb-пакет.
Если все пути указаны верно, а конфигурация не содержит ошибок, мы увидим в консоле вот такой лог от Flume.
Вывод Flume, если всё получилось
Чтобы убедиться, что всё работает корректно, отправим нашему NetCat-источнику небольшой тестовый файл test.txt, в котором содержится 4 строки:
Message 1 Message 2 Message 3
Важно, чтобы файл оканчивался переносом строки. Для NetCat-источника он является разделителем событий. Если мы не добавим в конец файла этот перенос строки, то источник будет считать, что последнее событие пришло не полностью. В результате этого он будет упорно ждать разделителя, который, естественно, никогда не придет. Итак, выполняем команду:
nc 127.0.0.1 11111 < test.txt
В результате этого NetCat должен вывести на экран три сообщения «ОК», как подтверждение того, что все строки файла благополучно отправлены и получены источником Flume. В это же время, сток должен вывести в консоль вот такие сообщения:
sink.LoggerSink — Event: < headers:<>body: 4D 65 73 73 61 67 65 20 31 0D Message 1. > sink.LoggerSink — Event: < headers:<>body: 4D 65 73 73 61 67 65 20 32 0D Message 2. > sink.LoggerSink — Event: < headers:<>body: 4D 65 73 73 61 67 65 20 33 0D Message 3. >
Примечание: Flume при запуске регистрирует свой shutdownHook, поэтому нет необходимости вручную высвобождать какие-либо ресурсы (соединения, открытые файлы и т.п.) — все компоненты узла самостоятельно завершат работу вместе с JVM.
5. Цепочка узлов Flume
Итак, мы разобрались, как настроить и запустить одиночный узел Flume. Однако для управления потоками данных одного узла явно маловато. Попробуем построить небольшую цепочку из трех узлов, выполняющих задачу деления (по сути — балансировка): первый узел Flume принимает информацию от клиента и отправляет события на два других узла. При этом события не дублируются на втором и третьем узлах, а равномерно распределяются между ними.
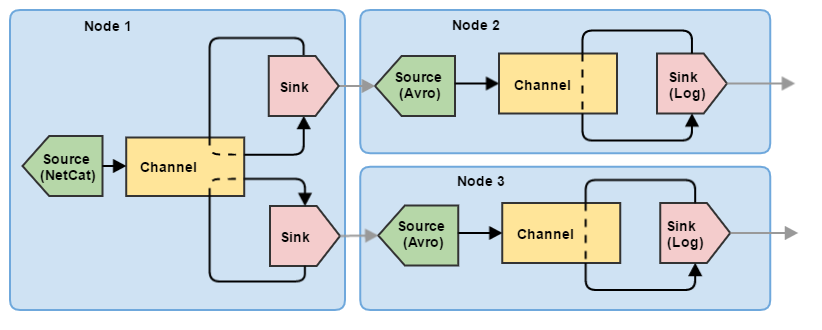
Соответственно, для такой схемы необходимо несколько конфигураций (для каждого узла — своя).
Конфигурация для узла 1 (node1.conf)
node1.sources = my-source node1.channels = my-channel # Теперь здесь 2 стока: node1.sinks = my-sink1 my-sink2 node1.sources.my-source.type = netcat node1.sources.my-source.bind = 0.0.0.0 node1.sources.my-source.port = 11111 node1.sources.my-source.channels = my-channel node1.channels.my-channel.type = memory node1.channels.my-channel.capacity = 10000 node1.channels.my-channel.transactionCapacity = 100 # Оба стока делаем с типом avro, они будут опустошать наш единственный канал вдвоем # Хосты принимающих узлов я оставлю локальными, чтобы всю эту цепочку можно было # попробовать запустить на одной машине node1.sinks.my-sink1.type = avro node1.sinks.my-sink1.channel = my-channel node1.sinks.my-sink1.hostname = 127.0.0.1 node1.sinks.my-sink1.port = 11112 node1.sinks.my-sink1.batch-size = 100 node1.sinks.my-sink2.type = avro node1.sinks.my-sink2.channel = my-channel node1.sinks.my-sink2.hostname = 127.0.0.1 node1.sinks.my-sink2.port = 11113 node1.sinks.my-sink2.batch-size = 100
Конфигурация для узла 2 (node2.conf)
node2.sources = my-source node2.channels = my-channel node2.sinks = my-sink # Поскольку на узле 1 сток имеет тип avro, здесь мы указываем источник типа avro node2.sources.my-source.type = avro node2.sources.my-source.bind = 0.0.0.0 node2.sources.my-source.port = 11112 node2.sources.my-source.channels = my-channel node2.channels.my-channel.type = memory node2.channels.my-channel.capacity = 10000 node2.channels.my-channel.transactionCapacity = 100 node2.sinks.my-sink.type = logger node2.sinks.my-sink.channel = my-channel node2.sinks.my-sink.maxBytesToLog = 256
Конфигурация для узла 3 (node3.conf)
node3.sources = my-source node3.channels = my-channel node3.sinks = my-sink # Поскольку на узле 1 сток имеет тип avro, здесь мы указываем источник типа avro node3.sources.my-source.type = avro node3.sources.my-source.bind = 0.0.0.0 node3.sources.my-source.port = 11113 node3.sources.my-source.channels = my-channel node3.channels.my-channel.type = memory node3.channels.my-channel.capacity = 10000 node3.channels.my-channel.transactionCapacity = 100 node3.sinks.my-sink.type = logger node3.sinks.my-sink.channel = my-channel node3.sinks.my-sink.maxBytesToLog = 256
Конфигурации для узлов 2 и 3 в данном примере идентичны, отличаются только номерами портов. Также для связи между узлами здесь используются стандартные компоненты Flume: Avro источник и Avro сток. Подробнее они будут описаны в следующих статьях, пока же нам достаточно того, что Avro Sink может отправлять по сети события, а Avro Source может их принимать.
Соответственно, запускаться каждый из узлов должен в отдельном процессе, а параметры запуска будут выглядеть следующим образом:
Application.main(new String[]); // для других узлов по аналогии: //Application.main(new String[]); //Application.main(new String[]);
Можно убедиться в работоспособности этой конфигурации, скормив первому узлу текстовый файл с сотней строк (маленькие порции данных могут пачкой отправиться на один из узлов и желаемого эффекта разделения данных мы не увидим).
Заключение
Эта статья является ознакомительной, приведенные здесь примеры конфигурации узлов Flume могут пригодиться лишь для отладки или знакомства с этим инструментом. В реальных проектах топология Flume выходит далеко за рамки одного-двух узлов, а конфигурации компонентов являются куда более сложными.
В следующей статье:
- Использование заголовков и канальных селекторов (Channel Selector).
- «Боевые» компоненты Flume:
- Avro Source;
- File Channel;
- Avro Sink;
- HDFS Sink;
- File Roll Sink.
Использованные источники и полезные ссылки
- Официальная страница Apache Flume
- Официальный гайд по настройке компонентов Flume
- Hadoop, часть 2: сбор данных через Flume | Блог компании Селектел — статья о настройке Flume средствами Cloudera.
- Hari Shreedharan: Using Flume — неплохая книга, описывающая возможности Flume.
Источник: habr.com